HCL-MTC、HiTIN
1. HCL-MTC复现
开源:https://github.com/hanggun/HCL-MTC.git
数据不太好
2. HiTIN
论文:HiTIN:Hierarchy-aware Tree Isomorphism Network for Hierarchical Text Classification
开源:https://github.com/Rooooyy/HiTIN.git
发表会议:ACL 2023
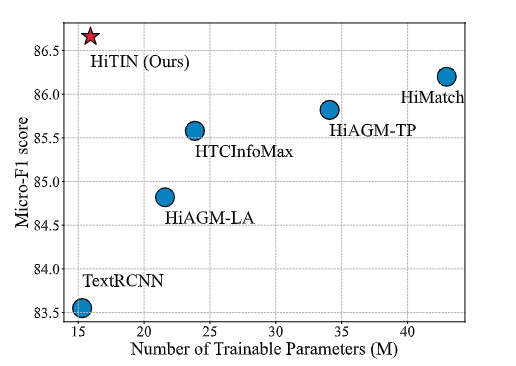
HiTIN 在训练参数量不显著增加的情况下,实现了最优的 Micro-F1 性能
说明 HiTIN 效果好,模型更轻量、更高效
2.1. 简略解读
2.1.1. 处理图示
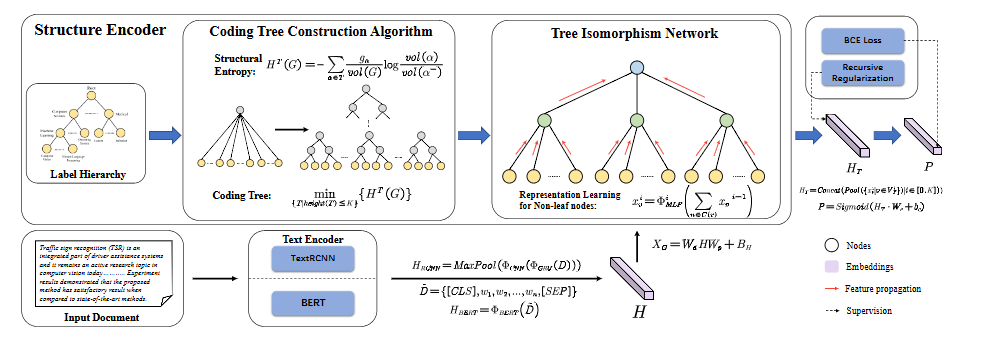
图1 HiTIN 的一个示例,其中 K=2。
- 输入文档首先被输入到文本编码器中以生成文本表示
- 接下来,标签层次结构通过编码树构建算法转换为编码树
-
- 图示原始标签层次为三层
- 本例设定k=2,根据CIRCA 算法压缩构建编码树使得标签体系为两层
- 文本表示被映射到编码树的叶节点,并迭代更新非叶节点的嵌入
- 最后,生成整个编码树的特征向量,并通过sigmoid 函数计算分类概率
- 此外,HiTIN 由二元交叉熵损失和递归正则化进行监督
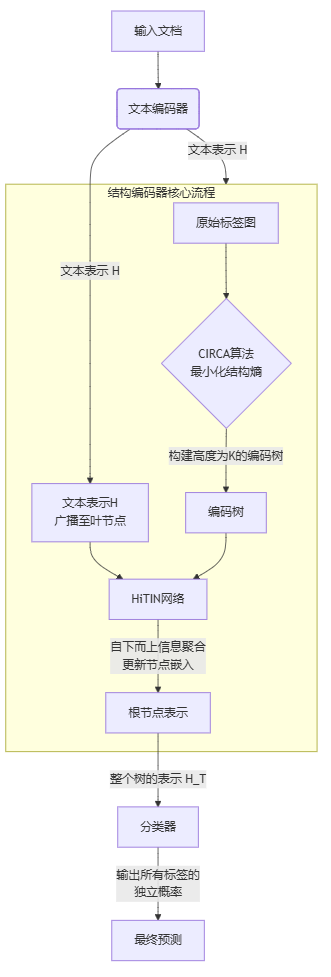
2.1.2. 构建编码树CIRCA 算法
以最小化结构熵为目标,将标签层级转化为固定高度的无权重编码树
- 输入是原始的标签层次结构,看作一个图 GL
- 使用 CIRCA 算法,通过最小化 K 维结构熵来构建一个高度为 K的编码树 TL,论文中 实验结果证明K=2时 效果最佳
2.1.3. 模型对比

图2 使用 TextRCNN 编码器的主要实验结果
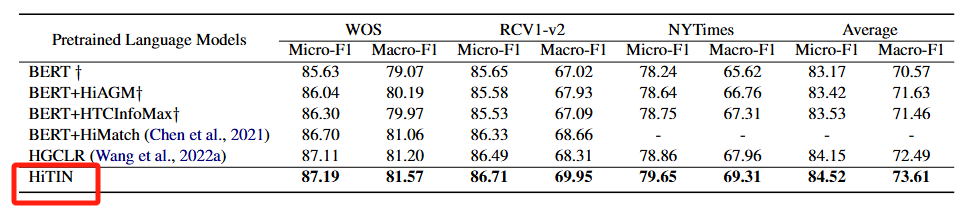
图3 使用 BERT 编码器的主要实验结果
HiTIN 模型在不同文本编码器TextRCNN 、 BERT下,比现有基线模型在层级文本分类任务上的性Macro-F1 指标数据更显著,说明HiTIN在捕捉标签层级关系和平衡不同频率标签分类性能上的效果。
2.1.4. 编码树的最佳高度
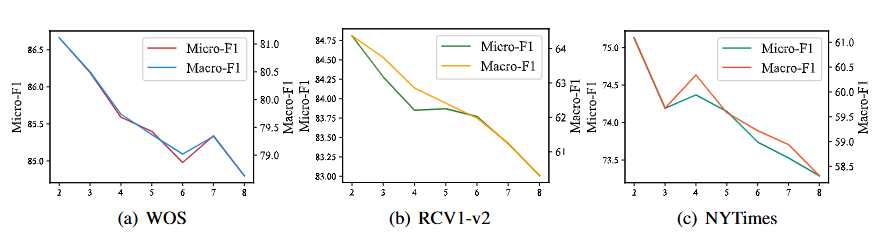
图4 展示了 WOS、RCV1-v2 和 NYTimes 上不同高度编码树的测试性能
随着 K 的增长,HiTIN 的性能严重下降。尽管三个数据集的标签层次深度不同,但编码树的最佳高度始终为 2。
2.1.5. 局限性
模型性能依赖文本编码器,BERT 等预训练模型虽表现更优,但在非预训练数据领域,如 BERT 未适配的学术文本 WOS提升有限。
3. 总结
本周一开始任务是复现HCL-MTC这个模型,但是失败。重新查找相关模型,找到了HiTIN模型,能够实现多层级多标签任务,可以适配本问答系统,且该模型不仅仅适配两层级的多标签任务,对之后的可能扩展有帮助。本周只做到了简略解读论文,了解基本的处理步骤。