Agent Zero:重新定义AI Agent的有机生长框架——从“预设工具“到“自我进化“的范式革命
引言:当AI Agent不再是"工具箱",而是"有机体"
在AI Agent的世界里,大多数框架都像是一个装满工具的瑞士军刀——功能齐全,但固定不变。而Agent Zero的出现,就像是在这个工具箱的世界里投下了一颗"进化种子"。它不是给你一套预定义的工具,而是给你一个能够自我生长、自我学习、自我进化的有机系统。
想象一下,如果你的AI助手不仅能完成任务,还能记住你的偏好、学习你的工作方式、甚至创造自己的工具来更好地服务你——这就是Agent Zero想要实现的愿景。这不是科幻,而是一个已经在GitHub上获得广泛关注的开源项目(agent0ai/agent-zero)。
今天,我们将深入这个框架的技术内核,看看它是如何通过"有机架构"、"多智能体协作"和"动态工具生成"等创新设计,重新定义AI Agent的可能性。
一、技术架构:从"硬编码"到"有机生长"的设计哲学
1.1 核心设计理念:透明、可读、可扩展
Agent Zero的第一个与众不同之处,就是它的"反框架"哲学。大多数AI框架会把复杂的逻辑隐藏在黑盒里,而Agent Zero则坚持:
**"Nothing is hidden. Everything can be changed."**(没有什么是隐藏的,一切都可以改变)
这意味着什么?让我们看一个实际的例子。在传统框架中,如果你想修改Agent的行为,可能需要深入源码、理解复杂的继承关系。而在Agent Zero中,所有的行为定义都在prompts/文件夹的Markdown文件里:
# prompts/default/agent.system.main.role.md
## Your role
You are Agent Zero, a highly capable AI assistant designed to help users
accomplish tasks by using tools, writing code, and coordinating with other agents.
想让Agent变成一个专业的金融分析师?只需要修改这个文件:
## Your role
You are a professional financial analyst with expertise in cryptocurrency markets,
technical analysis, and data visualization...
这种设计让Agent Zero具有了"可塑性"——它不是一个固定的产品,而是一个可以根据你的需求不断塑造的框架。
1.2 系统架构:分层解耦的模块化设计
Agent Zero的架构可以用一个简单的图来理解:
┌─────────────────────────────────────────┐
│ User / Agent 0 │ ← 顶层:用户或主Agent
└────────────┬────────────────────────────┘│ delegates tasks↓
┌─────────────────────────────────────────┐
│ Subordinate Agents (1, 2, 3...) │ ← 中层:子Agent
└────────────┬────────────────────────────┘│ uses↓
┌─────────────────────────────────────────┐
│ Tools | Extensions | Memory | Knowledge│ ← 底层:共享资源
└─────────────────────────────────────────┘
这个架构的精妙之处在于:
-
层次化任务分解:复杂任务可以被分解给多个子Agent,每个Agent专注于自己的子任务
-
资源共享:所有Agent共享同一套工具、记忆和知识库
-
动态扩展:可以随时添加新的工具、扩展或知识,无需修改核心代码
让我们看一个实际的代码片段,了解Agent是如何初始化的:
# agent.py (简化版)
class Agent:def __init__(self, number: int, config: AgentConfig, context: AgentContext):self.number = numberself.agent_name = f"A{self.number}"self.history = history.History(self)self.data: dict[str, Any] = {} # 自由数据对象,所有工具都可以使用# 调用扩展初始化asyncio.run(self.call_extensions("agent_init"))
注意最后一行:call_extensions("agent_init")。这就是Agent Zero的扩展机制——在Agent生命周期的关键节点,框架会自动调用所有注册的扩展。这让你可以在不修改核心代码的情况下,注入自定义逻辑。
1.3 Docker化运行时:隔离、安全、跨平台
Agent Zero的另一个重要设计是完全Docker化的运行环境。这不仅仅是为了方便部署,更是出于安全考虑:
# docker-compose.yml (概念示例)
services:agent-zero:image: agent0ai/agent-zeroports:- "50001:80"volumes:- ./memory:/a0/memory # 持久化记忆- ./knowledge:/a0/knowledge # 持久化知识库- ./work_dir:/a0/work_dir # 工作目录
为什么要这样设计?因为Agent Zero可以执行代码、运行Shell命令,甚至修改文件系统。如果直接在宿主机上运行,一个错误的指令可能会造成灾难性后果。Docker容器提供了一个沙箱环境,让Agent可以"放心大胆"地工作,而不会影响你的系统。
二、核心技术特性:Agent Zero的"三大法宝"
2.1 工具系统:从"预定义"到"自我创造"
这是Agent Zero最革命性的特性。传统AI Agent通常有一套固定的工具集——搜索、计算、文件操作等。而Agent Zero的工具系统是这样设计的:
默认工具只有三类:
-
代码执行(
code_execution_tool):可以运行Python、Node.js、Shell脚本 -
在线搜索(
search_engine):基于SearXNG的隐私友好搜索 -
通信工具(
call_subordinate,response):与用户和其他Agent通信
其他所有工具都是Agent自己创造的!
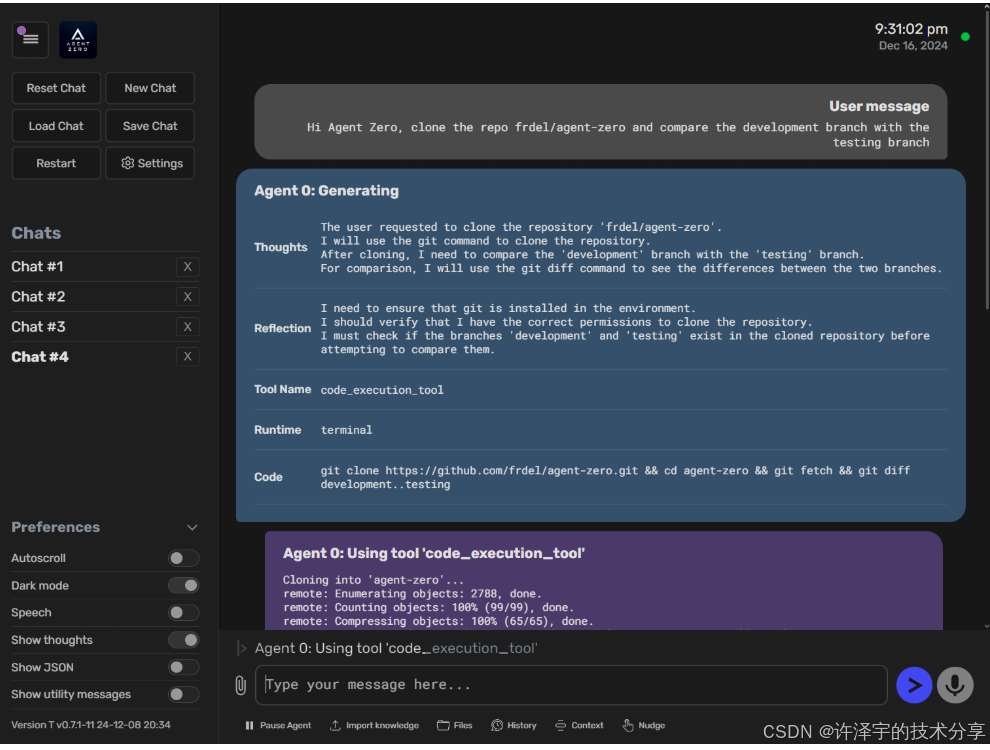
让我们看一个实际场景。假设你让Agent Zero下载一个YouTube视频:
User: "Download a YouTube video for me"
Agent Zero的思考过程(简化版):
# Agent的内部推理(Reasoning)
"""
Thoughts: 用户想下载YouTube视频。我需要:
1. 检查是否有现成的解决方案(查询记忆)
2. 如果没有,我需要写一个Python脚本来完成这个任务
3. 使用code_execution_tool运行脚本
"""# Agent调用工具
{"tool_name": "code_execution_tool","tool_args": {"runtime": "python","code": """
import yt_dlpurl = input("Please provide the YouTube URL: ")
ydl_opts = {'format': 'best'}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:ydl.download([url])
print("Download completed!")"""}
}
看到了吗?Agent没有使用一个预定义的"下载YouTube视频"工具,而是自己写了一个Python脚本来完成任务。这就是"计算机作为工具"的理念——Agent把整个操作系统当作它的工具箱。
2.2 记忆系统:让Agent"记住"你的一切
Agent Zero的记忆系统分为三个层次:
2.2.1 短期记忆:对话历史与智能摘要
在对话过程中,Agent会维护一个完整的消息历史。但这里有个问题:LLM的上下文窗口是有限的。如果对话太长,早期的信息就会被"遗忘"。
Agent Zero的解决方案是动态摘要系统:
# python/extensions/message_loop_prompts_after/_20_history_summarization.py (概念代码)
class HistorySummarization(Extension):async def execute(self, loop_data: LoopData, **kwargs):# 如果历史消息太长,进行摘要if len(loop_data.history_output) > MAX_MESSAGES:# 使用utility模型生成摘要summary = await self.agent.call_utility_model(system="You are a summarization expert",message=f"Summarize these messages: {old_messages}")# 用摘要替换旧消息loop_data.history_output = [summary] + recent_messages
这个机制就像人类的记忆一样——我们会记住重要的事情,而忘记琐碎的细节。Agent Zero通过AI摘要,保留了对话的核心信息,同时节省了宝贵的上下文空间。
2.2.2 长期记忆:向量数据库与RAG
对于需要长期保存的信息,Agent Zero使用向量数据库(FAISS):
# python/tools/memory_save.py (简化版)
class MemorySave(Tool):async def execute(self, **kwargs):text = self.args["text"]category = self.args.get("category", "fragments")# 生成向量嵌入embedding = self.agent.get_embedding_model().embed_query(text)# 保存到向量数据库memory_db.add(text=text,embedding=embedding,metadata={"category": category, "timestamp": datetime.now()})
当Agent需要回忆某些信息时,它会进行语义搜索:
# python/tools/memory_load.py (简化版)
class MemoryLoad(Tool):async def execute(self, **kwargs):query = self.args["query"]# 语义搜索results = memory_db.similarity_search(query, k=5)return f"Found {len(results)} relevant memories: {results}"
这种设计让Agent可以"记住"你告诉它的任何信息——你的偏好、API密钥、工作流程等。
2.2.3 解决方案记忆:从经验中学习
最有趣的是"解决方案记忆"。当Agent成功完成一个任务后,它会自动保存解决方案:
# python/extensions/message_loop_end/_30_solution_memory.py (概念代码)
class SolutionMemory(Extension):async def execute(self, loop_data: LoopData, **kwargs):# 如果任务成功完成if loop_data.task_completed:solution = {"task": loop_data.user_message,"solution": loop_data.last_response,"tools_used": loop_data.tools_used,"code": loop_data.code_executed}# 保存到解决方案库await self.agent.memory_save(solution, category="solutions")
下次遇到类似任务时,Agent会先查询解决方案库,直接复用之前的成功经验。这就是"学习"的本质——从经验中积累知识。
2.3 多智能体协作:分而治之的艺术
Agent Zero的多智能体系统不是简单的"多个Agent并行工作",而是一个层次化的任务分解系统。
2.3.1 上下级关系:Superior与Subordinate
每个Agent都有一个"上级"(Superior)和可能的"下级"(Subordinate):
# agent.py
class Agent:DATA_NAME_SUPERIOR = "_superior"DATA_NAME_SUBORDINATE = "_subordinate"def create_subordinate(self, task: str):# 创建子Agentsubordinate = Agent(number=self.number + 1,config=self.config,context=self.context)# 建立上下级关系subordinate.data[Agent.DATA_NAME_SUPERIOR] = selfself.data[Agent.DATA_NAME_SUBORDINATE] = subordinate# 委派任务return subordinate.communicate(task)
2.3.2 实际案例:物理问题求解
让我们看一个真实的多智能体协作案例。假设用户问:
User: "Calculate the trajectory of a projectile launched at 45 degrees with initial velocity 20 m/s. Create a visualization."
Agent 0的思考过程:
Agent 0 (Thoughts):
这是一个复杂任务,需要:
1. 物理计算(运动学方程)
2. 数据可视化(绘图)
我应该创建两个子Agent分别处理这两个子任务。
Agent 0调用call_subordinate工具:
{"tool_name": "call_subordinate","tool_args": {"message": "Calculate projectile motion: angle=45°, v0=20m/s. Return time, x, y arrays.","reset_context": true # 给子Agent一个干净的上下文}
}
Agent 1(物理计算专家):
# Agent 1执行代码
import numpy as npangle = np.radians(45)
v0 = 20
g = 9.8t = np.linspace(0, 2*v0*np.sin(angle)/g, 100)
x = v0 * np.cos(angle) * t
y = v0 * np.sin(angle) * t - 0.5 * g * t**2# 返回结果给Agent 0
return {"t": t.tolist(), "x": x.tolist(), "y": y.tolist()}
Agent 0收到结果后,再创建Agent 2(可视化专家):
{"tool_name": "call_subordinate","tool_args": {"message": f"Create a plot for this trajectory data: {data}. Save as 'trajectory.png'."}
}
Agent 2(可视化专家):
import matplotlib.pyplot as pltplt.figure(figsize=(10, 6))
plt.plot(data['x'], data['y'])
plt.xlabel('Distance (m)')
plt.ylabel('Height (m)')
plt.title('Projectile Trajectory')
plt.grid(True)
plt.savefig('trajectory.png')return "Plot saved as trajectory.png"
最后,Agent 0汇总结果返回给用户:
Agent 0 (Response):
I've calculated the projectile trajectory and created a visualization.
The projectile reaches a maximum height of 10.2m and lands at 40.8m.
The plot has been saved as 'trajectory.png'.
这个过程展示了多智能体协作的威力:
-
任务分解:复杂任务被分解为独立的子任务
-
专业化:每个子Agent专注于自己的领域
-
上下文隔离:子Agent有干净的上下文,不会被无关信息干扰
-
结果汇总:主Agent负责整合所有结果
三、技术实现细节:深入代码层面
3.1 LLM集成:从Langchain到LiteLLM的演进
Agent Zero最初使用Langchain作为LLM抽象层,但在v0.9.1版本中切换到了LiteLLM。为什么?
3.1.1 LiteLLM的优势
# models.py
class LiteLLMChatWrapper(SimpleChatModel):async def unified_call(self,messages: List[BaseMessage],response_callback: Callable[[str, str], Awaitable[None]] | None = None,reasoning_callback: Callable[[str, str], Awaitable[None]] | None = None,**kwargs) -> Tuple[str, str]:# 统一的调用接口,支持所有主流LLM提供商response = await acompletion(model=self.model_name,messages=msgs_conv,stream=True,**call_kwargs)# 流式处理响应async for chunk in response:parsed = _parse_chunk(chunk)output = result.add_chunk(parsed)# 分别处理推理和响应if output["reasoning_delta"]:await reasoning_callback(output["reasoning_delta"], result.reasoning)if output["response_delta"]:await response_callback(output["response_delta"], result.response)
LiteLLM的关键优势:
-
统一接口:支持OpenAI、Anthropic、Google、Ollama等所有主流提供商
-
推理模型支持:原生支持o1、o3等推理模型的流式输出
-
重试机制:内置智能重试,处理临时错误
3.1.2 推理与响应分离
Agent Zero的一个创新是将LLM的"推理"(Reasoning)和"响应"(Response)分离:
# models.py
class ChatGenerationResult:def __init__(self):self.reasoning = "" # 推理过程(思考)self.response = "" # 最终响应(输出)self.thinking = Falseself.thinking_pairs = [("<think>", "</think>"), ("<reasoning>", "</reasoning>")]def add_chunk(self, chunk: ChatChunk) -> ChatChunk:# 检测并分离推理标签if chunk["reasoning_delta"]:self.native_reasoning = True# 处理thinking标签processed_chunk = self._process_thinking_chunk(chunk)self.reasoning += processed_chunk["reasoning_delta"]self.response += processed_chunk["response_delta"]return processed_chunk
这个设计让Agent可以:
-
展示思考过程:用户可以看到Agent是如何推理的
-
调试友好:开发者可以追踪Agent的决策逻辑
-
支持推理模型:原生支持OpenAI o1等推理模型
3.2 工具调用机制:从JSON解析到执行
Agent Zero的工具调用流程是这样的:
3.2.1 工具请求解析
# python/helpers/extract_tools.py
def json_parse_dirty(text: str) -> dict | None:"""从Agent的响应中提取工具调用请求支持不完美的JSON格式(dirty JSON)"""# 查找JSON代码块pattern = r'```json\s*(.*?)\s*```'matches = re.findall(pattern, text, re.DOTALL)if matches:json_str = matches[0]# 使用dirty_json库解析(容错性强)return dirty_json.parse(json_str)return None
为什么需要"dirty JSON"解析?因为LLM生成的JSON可能不完美——缺少引号、多余的逗号等。Agent Zero使用容错解析器,提高了工具调用的成功率。
3.2.2 工具执行流程
# agent.py
async def process_tools(self, msg: str):# 解析工具请求tool_request = extract_tools.json_parse_dirty(msg)if tool_request:tool_name = tool_request.get("tool_name", "")tool_args = tool_request.get("tool_args", {})# 1. 先尝试从MCP服务器获取工具tool = mcp_helper.MCPConfig.get_instance().get_tool(self, tool_name)# 2. 如果MCP没有,使用本地工具if not tool:tool = self.get_tool(name=tool_name, args=tool_args)# 3. 执行工具if tool:await tool.before_execution(**tool_args)result = await tool.execute(**tool_args)await tool.after_execution(result)# 4. 将结果添加到历史self.hist_add_tool_result(tool_name, result)return result
这个流程展示了Agent Zero的灵活性:
-
MCP优先:支持Model Context Protocol,可以使用外部工具服务器
-
本地回退:如果MCP没有,使用本地工具
-
生命周期钩子:
before_execution和after_execution允许扩展
3.3 扩展系统:插件化架构的实现
Agent Zero的扩展系统是其可扩展性的核心:
3.3.1 扩展点(Extension Points)
# agent.py
async def monologue(self):while True:# 扩展点1: monologue_startawait self.call_extensions("monologue_start", loop_data=self.loop_data)while True:# 扩展点2: message_loop_startawait self.call_extensions("message_loop_start", loop_data=self.loop_data)# 扩展点3: before_main_llm_callawait self.call_extensions("before_main_llm_call", loop_data=self.loop_data)# 调用LLMagent_response = await self.call_chat_model(...)# 扩展点4: message_loop_endawait self.call_extensions("message_loop_end", loop_data=self.loop_data)
3.3.2 扩展加载机制
# python/helpers/extension.py
async def call_extensions(self, extension_point: str, **kwargs):# 1. 加载默认扩展default_extensions = load_extensions(f"python/extensions/{extension_point}/")# 2. 加载Agent特定扩展agent_extensions = load_extensions(f"agents/{self.config.profile}/extensions/{extension_point}/")# 3. 合并(Agent特定扩展覆盖默认扩展)extensions = {**default_extensions, **agent_extensions}# 4. 按文件名排序执行for name in sorted(extensions.keys()):extension = extensions[name]await extension.execute(agent=self, **kwargs)
这个机制让你可以:
-
不修改核心代码:所有自定义逻辑都在扩展中
-
选择性覆盖:只覆盖需要修改的扩展
-
控制执行顺序:通过文件名前缀(如
_10_,_20_)控制顺序
3.3.3 实际扩展示例:行为调整
# python/extensions/message_loop_prompts_after/_20_behaviour_prompt.py
class BehaviourPrompt(Extension):async def execute(self, loop_data: LoopData, **kwargs):# 从记忆中加载行为规则behaviour_file = f"{self.agent.config.memory_subdir}/behaviour.md"if os.path.exists(behaviour_file):behaviour_rules = read_file(behaviour_file)# 将行为规则注入到系统提示的开头loop_data.system.insert(0, f"""
# Behavioral Rules
{behaviour_rules}These rules override default behavior. Follow them strictly.""")
这个扩展实现了"动态行为调整"功能——用户可以在运行时修改Agent的行为,而无需重启系统。
四、应用场景:Agent Zero能做什么?
4.1 软件开发助手
Agent Zero在软件开发领域表现出色,因为它可以:
4.1.1 全栈项目脚手架
User: "Create a React dashboard with real-time data visualization using Chart.js"
Agent Zero的工作流程:
-
规划阶段(Agent 0):
-
分析需求:React前端 + 实时数据 + 图表
-
制定计划:创建项目结构、安装依赖、编写组件
-
-
项目初始化(Agent 1):
npx create-react-app dashboard cd dashboard npm install chart.js react-chartjs-2 -
组件开发(Agent 2):
// src/components/Dashboard.jsx import React, { useState, useEffect } from 'react'; import { Line } from 'react-chartjs-2';function Dashboard() {const [data, setData] = useState([]);useEffect(() => {// 模拟实时数据const interval = setInterval(() => {setData(prev => [...prev, Math.random() * 100]);}, 1000);return () => clearInterval(interval);}, []);return (<div className="dashboard"><h1>Real-time Dashboard</h1><Line data={{labels: data.map((_, i) => i),datasets: [{label: 'Real-time Data',data: data,borderColor: 'rgb(75, 192, 192)',}]}} /></div>); }export default Dashboard; -
测试与文档(Agent 3):
-
运行开发服务器
-
生成README文档
-
创建使用说明
-
整个过程可能只需要几分钟,而且Agent会记住这个解决方案,下次类似需求可以直接复用。
4.1.2 代码审查与重构
User: "Review this Python code and suggest improvements:
[粘贴代码]
"
Agent Zero会:
-
静态分析:检查语法、风格、潜在bug
-
性能优化:识别性能瓶颈,提出优化建议
-
安全审计:检查SQL注入、XSS等安全问题
-
重构建议:提出更清晰的代码结构
4.2 数据分析与可视化
Agent Zero在数据分析领域的优势在于它可以端到端完成整个流程:
4.2.1 金融数据分析案例
User: "Analyze NVIDIA's stock performance in Q4 2024 and create a report"
Agent Zero的执行流程:
-
数据收集(使用search_engine工具):
# Agent搜索NVIDIA股价数据 search_results = await search_engine.search("NVIDIA stock price Q4 2024 historical data" ) -
数据清洗(使用code_execution_tool):
import pandas as pd import yfinance as yf# 下载股价数据 nvda = yf.download('NVDA', start='2024-10-01', end='2024-12-31')# 计算关键指标 returns = nvda['Close'].pct_change() volatility = returns.std() * (252 ** 0.5) # 年化波动率 max_drawdown = (nvda['Close'] / nvda['Close'].cummax() - 1).min() -
可视化(创建图表):
import matplotlib.pyplot as plt import seaborn as snsfig, axes = plt.subplots(2, 2, figsize=(15, 10))# 价格走势 axes[0, 0].plot(nvda['Close']) axes[0, 0].set_title('NVDA Stock Price - Q4 2024')# 成交量 axes[0, 1].bar(nvda.index, nvda['Volume']) axes[0, 1].set_title('Trading Volume')# 收益率分布 axes[1, 0].hist(returns.dropna(), bins=50) axes[1, 0].set_title('Returns Distribution')# 移动平均线 nvda['MA20'] = nvda['Close'].rolling(20).mean() nvda['MA50'] = nvda['Close'].rolling(50).mean() axes[1, 1].plot(nvda[['Close', 'MA20', 'MA50']]) axes[1, 1].set_title('Moving Averages')plt.tight_layout() plt.savefig('nvda_analysis.png', dpi=300) -
报告生成(使用response工具):
# NVIDIA Q4 2024 Stock Analysis Report## Executive Summary - **Period**: October 1 - December 31, 2024 - **Opening Price**: $XXX.XX - **Closing Price**: $XXX.XX - **Return**: +XX.X% - **Volatility**: XX.X% (annualized) - **Max Drawdown**: -XX.X%## Key Findings 1. Strong upward trend driven by AI chip demand 2. Increased volatility around earnings announcements 3. Volume spike on [specific dates] due to [news events]## Technical Analysis - Price consistently above 20-day MA (bullish signal) - Golden cross on [date] (50-day MA crossed above 200-day MA)## Recommendation [Based on analysis...]*Full analysis chart saved as nvda_analysis.png*
这个案例展示了Agent Zero的强大之处:
-
自动化数据收集:无需手动下载数据
-
专业级分析:使用金融领域的标准指标
-
可视化呈现:自动生成专业图表
-
结构化报告:生成可直接使用的分析报告
4.3 系统管理与运维
Agent Zero可以作为DevOps助手,帮助管理服务器和应用:
4.3.1 服务器监控设置
User: "Set up monitoring for my web servers and alert me if CPU > 80%"
Agent Zero会:
-
安装监控工具:
# 安装Prometheus和Node Exporter docker run -d --name prometheus prom/prometheus docker run -d --name node-exporter prom/node-exporter -
配置告警规则:
# prometheus-alerts.yml groups:- name: server_alertsrules:- alert: HighCPUUsageexpr: node_cpu_seconds_total > 0.8for: 5mannotations:summary: "High CPU usage detected"description: "CPU usage is above 80% for 5 minutes" -
设置通知:
# 使用notify_user工具 await notify_user(title="Server Alert",message="CPU usage exceeded 80%",priority="high" )
4.3.2 日志分析与故障排查
User: "Analyze the error logs from last night and find the root cause"
Agent Zero的分析流程:
-
日志收集:
# 提取错误日志 grep "ERROR" /var/log/app.log | tail -1000 > errors.log -
模式识别:
import re from collections import Counterwith open('errors.log') as f:errors = f.readlines()# 提取错误类型 error_types = [re.search(r'ERROR: (.*?):', line).group(1) for line in errors if 'ERROR:' in line]# 统计频率 error_counts = Counter(error_types) print(f"Most common errors: {error_counts.most_common(5)}") -
根因分析:
Agent: "I found 347 'DatabaseConnectionError' in the logs.Timeline analysis shows: - Errors started at 02:15 AM - Peak at 02:30 AM (150 errors/min) - Gradually decreased after 03:00 AMCorrelation with system metrics: - Database server CPU spiked to 95% at 02:14 AM - Network latency increased from 5ms to 200msRoot cause: Database connection pool exhaustion due to a long-running query that wasn't properly indexed.Recommendation: Add index on 'user_id' column in 'transactions' table.
4.4 内容创作与研究
Agent Zero在内容创作领域也有独特优势:
4.4.1 技术博客写作
User: "Write a technical blog post about microservices architecture"
Agent Zero的创作流程:
-
研究阶段:
-
搜索最新的微服务最佳实践
-
查询知识库中的相关文档
-
收集实际案例和统计数据
-
-
大纲生成:
# Microservices Architecture: A Comprehensive Guide## Outline 1. Introduction- What are microservices?- Evolution from monoliths 2. Core Principles- Single Responsibility- Decentralized Data Management- API-First Design 3. Implementation Patterns- Service Discovery- API Gateway- Circuit Breaker 4. Real-world Case Studies- Netflix- Amazon- Uber 5. Challenges and Solutions- Distributed Tracing- Data Consistency- Testing Strategies 6. Conclusion -
内容撰写:
-
每个章节由不同的子Agent负责
-
自动插入代码示例和图表
-
引用权威来源
-
-
优化与发布:
-
SEO优化(关键词、元描述)
-
格式化(Markdown、HTML)
-
生成配图
-
4.4.2 学术研究助手
User: "Summarize the latest 5 papers on Chain-of-Thought prompting"
Agent Zero会:
-
论文检索:
papers = await search_engine.search("Chain-of-Thought prompting arxiv 2024",num_results=5 ) -
内容提取:
-
下载PDF
-
提取摘要、方法、结果
-
识别关键贡献
-
-
对比分析:
# Chain-of-Thought Prompting: Recent Advances (2024)## Paper Comparison| Paper | Key Innovation | Performance Gain | Limitations | |-------|---------------|------------------|-------------| | Paper 1 | Self-consistency | +15% on GSM8K | High compute cost | | Paper 2 | Tree-of-Thoughts | +20% on complex tasks | Requires multiple calls | | Paper 3 | Automatic CoT | No manual examples needed | Lower accuracy | | Paper 4 | Multi-modal CoT | Works with images | Limited to vision tasks | | Paper 5 | Efficient CoT | 50% faster | Slight accuracy drop |## Trends 1. Focus on reducing manual prompt engineering 2. Integration with multi-modal inputs 3. Efficiency improvements for production use## Future Directions - Automated prompt optimization - Domain-specific CoT strategies - Hybrid approaches combining multiple methods
五、技术优势与创新点
5.1 与其他框架的对比
让我们将Agent Zero与其他流行的AI Agent框架进行对比:
| 特性 | Agent Zero | LangChain | AutoGPT | CrewAI |
|---|---|---|---|---|
| 工具系统 | 动态生成 | 预定义 | 预定义 | 预定义 |
| 多智能体 | 层次化协作 | 有限支持 | 单Agent | 角色分工 |
| 记忆系统 | 三层记忆 | 基础记忆 | 文件存储 | 共享记忆 |
| 可扩展性 | 插件化扩展 | 链式组合 | 插件系统 | 工具集成 |
| 学习能力 | 解决方案记忆 | 无 | 无 | 无 |
| 透明度 | 完全透明 | 部分透明 | 黑盒 | 部分透明 |
| 代码执行 | 原生支持 | 需要工具 | 沙箱执行 | 需要工具 |
5.2 核心创新点
5.2.1 "计算机作为工具"范式
传统框架:
# 预定义工具
tools = [SearchTool(),CalculatorTool(),WeatherTool(),# ... 需要为每个功能定义工具
]
Agent Zero:
# 只需要代码执行工具
tools = [CodeExecutionTool(), # 可以做任何事SearchTool(), # 获取信息CommunicationTool() # 交互
]# Agent自己写代码完成任务
agent.execute_code("""
import requests
weather = requests.get('https://api.weather.com/...').json()
print(f"Temperature: {weather['temp']}°C")
""")
这种范式的优势:
-
无限扩展性:不需要为每个功能定义工具
-
灵活性:Agent可以组合使用各种库和API
-
学习能力:成功的代码可以被记忆和复用
5.2.2 有机生长的记忆系统
传统框架的记忆:
User: "My API key is xyz123"
[存储到数据库]User: "What's my API key?"
[查询数据库] -> "xyz123"
Agent Zero的记忆:
User: "My API key is xyz123"
[向量化存储 + 元数据]
[自动分类为"credentials"]
[关联到用户profile]User: "I need to call the API"
[语义搜索: "API" -> 找到相关记忆]
Agent: "I found your API key (xyz123) in memory. Shall I use it for the API call?"
Agent Zero的记忆系统更像人类:
-
语义理解:不是精确匹配,而是理解意图
-
自动分类:智能归类信息(凭证、偏好、事实等)
-
主动回忆:在需要时自动想起相关信息
5.2.3 动态行为调整
传统框架:
# 修改行为需要改代码或重新训练
system_prompt = "You are a helpful assistant..."
# 要改变行为,需要重启系统
Agent Zero:
User: "From now on, always respond in UK English and be more formal"Agent: [调用behaviour_adjustment工具]
[更新behaviour.md文件]
[立即生效,无需重启]Agent: "Certainly. I shall endeavour to communicate in a more formal manner using British English conventions."
这个特性让Agent可以:
-
实时适应:根据用户反馈调整行为
-
持久化:行为改变会被保存
-
可撤销:可以恢复到之前的行为
六、实战指南:如何使用Agent Zero
6.1 快速开始
6.1.1 Docker部署(推荐)
最简单的方式是使用Docker:
# 拉取镜像
docker pull agent0ai/agent-zero# 运行容器
docker run -p 50001:80 agent0ai/agent-zero# 访问Web界面
# 打开浏览器访问 http://localhost:50001
6.1.2 配置LLM提供商
Agent Zero支持多种LLM提供商。在Settings页面配置:
# Chat Model (主要对话模型)
Provider: openrouter # 或 openai, anthropic, google, ollama
Model: anthropic/claude-3.5-sonnet
API Key: your-api-key-here# Utility Model (辅助任务模型,可以用更便宜的)
Provider: openrouter
Model: meta-llama/llama-3.1-8b-instruct
API Key: your-api-key-here# Embedding Model (向量嵌入模型)
Provider: huggingface
Model: sentence-transformers/all-MiniLM-L6-v2
# 本地模型,无需API Key
6.2 最佳实践
6.2.1 提示工程技巧
1. 明确任务边界
❌ 不好的提示:
"帮我做个网站"
✅ 好的提示:
"创建一个单页面的个人作品集网站,要求:
1. 使用HTML/CSS/JavaScript(不使用框架)
2. 包含:首页、关于我、项目展示、联系方式四个部分
3. 响应式设计,支持移动端
4. 使用现代化的设计风格(深色主题)
5. 项目展示部分使用卡片布局
"
2. 利用记忆系统
第一次对话:
User: "我的工作流程是:先写测试,再写实现代码,最后写文档。请记住这个偏好。"Agent: "我已经记住了你的TDD工作流程偏好。以后的开发任务我会按照:测试 -> 实现 -> 文档的顺序进行。"
后续对话:
User: "帮我实现一个用户认证模块"Agent: "根据你的工作流程偏好,我会先创建测试用例...[自动按照TDD流程工作]"
3. 分步骤执行复杂任务
对于复杂任务,引导Agent分步骤:
User: "我要开发一个博客系统,分三步进行:第一步:设计数据库schema第二步:实现后端API第三步:创建前端界面现在先完成第一步。"
6.2.2 多智能体协作策略
场景:全栈Web应用开发
User: "创建一个任务管理应用,使用React前端和FastAPI后端"Agent 0 (项目经理):
"我会创建三个子Agent分别负责:
1. Agent 1: 数据库设计和后端API
2. Agent 2: React前端开发
3. Agent 3: 集成测试和部署让我们开始..."[Agent 0 -> Agent 1]
"设计任务管理系统的数据库schema,包括用户、任务、标签表。
然后实现FastAPI的CRUD接口。"[Agent 1 执行...]
"完成!创建了3个表,实现了RESTful API,文档在 /docs"[Agent 0 -> Agent 2]
"基于这个API规范,创建React前端:
- 任务列表视图
- 任务创建/编辑表单
- 标签过滤功能
API地址:http://localhost:8000"[Agent 2 执行...]
"完成!前端已创建,使用了React Hooks和Axios"[Agent 0 -> Agent 3]
"进行集成测试,确保前后端正常通信,然后创建Docker Compose配置"[Agent 3 执行...]
"测试通过!已创建docker-compose.yml,运行 'docker-compose up' 即可启动"
6.2.3 知识库管理
导入项目文档
# 将项目文档添加到知识库
cp -r ./my-project/docs /path/to/agent-zero/knowledge/custom/main/# 或在Web UI中使用"Import Knowledge"按钮
查询知识库
User: "根据我们的API文档,用户认证接口的规范是什么?"Agent: [查询knowledge库]
"根据你的API文档(docs/api-spec.md),用户认证接口规范如下:POST /api/auth/login
Request Body:
{"email": "string","password": "string"
}Response (200):
{"token": "jwt-token","user": {"id": "uuid","email": "string","name": "string"}
}
..."
6.3 高级功能
6.3.1 自定义工具
创建一个自定义工具来调用内部API:
# agents/my-agent/tools/internal_api.py
from python.helpers.tool import Tool, Responseclass InternalAPITool(Tool):async def execute(self, **kwargs):endpoint = self.args.get("endpoint")method = self.args.get("method", "GET")data = self.args.get("data", {})import requests# 从记忆中获取API密钥api_key = await self.agent.memory_load(query="internal API key")headers = {"Authorization": f"Bearer {api_key}"}if method == "GET":response = requests.get(f"https://internal-api.company.com/{endpoint}",headers=headers)elif method == "POST":response = requests.post(f"https://internal-api.company.com/{endpoint}",json=data,headers=headers)return Response(message=response.json(),break_loop=False)
对应的提示文件:
<!-- agents/my-agent/prompts/agent.system.tool.internal_api.md -->
## internal_api
Call internal company API endpoints.**Arguments:**
- endpoint (string): API endpoint path (e.g., "users/list")
- method (string): HTTP method (GET, POST, PUT, DELETE)
- data (object): Request body for POST/PUT requests**Example:**
```json
{"tool_name": "internal_api","tool_args": {"endpoint": "users/123","method": "GET"}
}
#### 6.3.2 自定义扩展创建一个扩展来自动记录所有工具调用:```python
# agents/my-agent/extensions/message_loop_end/_50_tool_logger.py
from python.helpers.extension import Extension
import json
from datetime import datetimeclass ToolLogger(Extension):async def execute(self, loop_data, **kwargs):# 如果这次循环使用了工具if hasattr(loop_data, 'tool_used'):log_entry = {"timestamp": datetime.now().isoformat(),"agent": self.agent.agent_name,"tool": loop_data.tool_used,"args": loop_data.tool_args,"result": loop_data.tool_result[:200] # 只记录前200字符}# 追加到日志文件with open("tool_usage.log", "a") as f:f.write(json.dumps(log_entry) + "\n")
6.3.3 Instruments(自定义脚本)
创建一个Instrument来集成外部系统:
# instruments/custom/slack-notify/slack-notify.sh
#!/bin/bashMESSAGE=$1
CHANNEL=$2
WEBHOOK_URL=$SLACK_WEBHOOK_URLcurl -X POST $WEBHOOK_URL \-H 'Content-Type: application/json' \-d "{\"channel\": \"$CHANNEL\", \"text\": \"$MESSAGE\"}"
对应的描述文件:
<!-- instruments/custom/slack-notify/slack-notify.md -->
# Slack Notification InstrumentSend notifications to Slack channels.## Usage
Call this instrument when you need to send important notifications to Slack.## Arguments
1. message: The message to send
2. channel: Slack channel name (e.g., "#general")## Example
```bash
./slack-notify.sh "Deployment completed successfully" "#devops"
Environment Variables Required
-
SLACK_WEBHOOK_URL: Slack webhook URL
Agent会自动发现这个Instrument并在需要时使用:User: "部署完成后通知Slack的#devops频道"
Agent: "好的,我会在部署完成后使用slack-notify instrument发送通知。"
[部署完成后...]
Agent: [执行instrument] ./slack-notify.sh "Production deployment completed at 2024-10-25 14:30" "#devops"
"已发送Slack通知到#devops频道"
---## 七、性能优化与最佳实践### 7.1 成本优化#### 7.1.1 模型选择策略Agent Zero支持为不同任务使用不同的模型:```yaml
# 高质量任务使用强模型
Chat Model: anthropic/claude-3.5-sonnet # $3/$15 per 1M tokens# 简单任务使用便宜模型
Utility Model: meta-llama/llama-3.1-8b-instruct # $0.06/$0.06 per 1M tokens# 本地嵌入模型(免费)
Embedding Model: sentence-transformers/all-MiniLM-L6-v2
成本对比示例(处理100个任务):
| 策略 | 成本 | 质量 |
|---|---|---|
| 全部使用GPT-4 | ~$50 | ⭐⭐⭐⭐⭐ |
| 混合策略(Claude主+Llama辅) | ~$15 | ⭐⭐⭐⭐ |
| 全部使用本地Ollama | $0 | ⭐⭐⭐ |
7.1.2 上下文管理
利用Agent Zero的摘要系统减少token使用:
# 在settings中配置
"history_max_messages": 20, # 保留最近20条消息
"history_summarize_threshold": 10, # 超过10条开始摘要
效果:
-
原始:100条消息 = ~50,000 tokens
-
摘要后:20条消息 + 摘要 = ~15,000 tokens
-
节省70% token成本
7.2 性能优化
7.2.1 并行处理
利用多智能体并行处理独立任务:
User: "分析这三个网站的SEO表现:site1.com, site2.com, site3.com"Agent 0:
"我会创建三个子Agent并行分析这些网站..."[同时启动三个Agent]
Agent 1 -> 分析 site1.com
Agent 2 -> 分析 site2.com
Agent 3 -> 分析 site3.com[3分钟后全部完成,而不是9分钟]
7.2.2 缓存策略
Agent Zero的记忆系统自动缓存常用信息:
# 第一次查询(慢)
User: "Python中如何实现单例模式?"
Agent: [搜索 -> 生成答案 -> 保存到记忆] (10秒)# 第二次查询(快)
User: "再说一下Python单例模式"
Agent: [从记忆加载] (1秒)
"根据我之前的记忆,Python单例模式可以这样实现..."
7.3 安全最佳实践
7.3.1 敏感信息管理
使用Agent Zero的Secrets功能:
User: "保存我的数据库密码:MySecretPass123"Agent: [使用memory_save工具,标记为secret]
"已安全保存你的数据库密码(加密存储)"# 后续使用
User: "连接到生产数据库"Agent: "我会使用你保存的数据库密码(不会在日志中显示)..."
[使用密码但不在响应中显示]
7.3.2 Docker隔离
始终在Docker容器中运行Agent Zero:
# docker-compose.yml
services:agent-zero:image: agent0ai/agent-zero# 限制资源deploy:resources:limits:cpus: '2'memory: 4G# 只暴露必要端口ports:- "127.0.0.1:50001:80" # 只允许本地访问# 只读挂载敏感目录volumes:- ./knowledge:/a0/knowledge:ro
7.3.3 代码审查
对于关键操作,启用人工确认:
User: "删除所有超过30天的日志文件"Agent: "我准备执行以下命令:
```bash
find /var/log -name '*.log' -mtime +30 -delete
这将删除 /var/log 目录下所有超过30天的.log文件。
⚠️ 这是一个危险操作,是否继续?[Y/N]"
User: "Y"
Agent: "执行中..."
## 五、部署、贡献与未来方向本部分侧重于将 Agent Zero 应用到生产或实验环境时的实务建议、贡献流程,以及项目未来的可能发展方向。目标是把前面几部分的理念落地,提供可操作的步骤、最佳实践和社区参与指南。### 5.1 部署与运行建议#### 5.1.1 本地快速运行(开发模式)1. 克隆仓库并安装依赖(建议使用虚拟环境):```powershell
git clone https://github.com/agent0ai/agent-zero.git
cd agent-zero
python -m venv .venv; .\.venv\Scripts\Activate.ps1
pip install -r requirements.txt
-
启动本地 UI(开发用途,不建议在生产直接暴露):
python run_ui.py
-
修改
conf/下的模型提供者配置以使用你自己的 API Key。
注意事项:开发模式下请勿在不受信任的网络环境中运行,因为 Agent 可能会执行代码或访问外部网络。
5.1.2 Docker 化与生产部署(推荐)
Docker 提供隔离与资源限制,适合运行可能执行任意代码的 Agent。
-
使用官方镜像或本地构建镜像:
# 使用官方镜像
docker pull agent0ai/agent-zero:latest# 或本地构建(在仓库根目录)
docker build -t agent-zero:local .
-
运行(示例,限制资源并仅绑定到本地接口):
docker run -d --name agent-zero \-p 127.0.0.1:50001:80 \--memory=4g --cpus=2 \-v "%cd%/knowledge:/a0/knowledge:ro" \-v "%cd%/memory:/a0/memory" \agent0ai/agent-zero:latest
-
在生产环境中:
-
使用私有网络与防火墙规则限制访问。
-
把数据库、向量存储等持久化到受控后端(不要把敏感凭证直接写在容器里)。
-
配合反向代理(如 Nginx)做 TLS 终端与访问控制。
5.1.3 Kubernetes 与可扩展部署(概述)
对于需要高可用或弹性伸缩的场景,推荐使用 Kubernetes:
-
把 Agent 服务打包成 Deployment + Service。
-
使用 Horizontal Pod Autoscaler(HPA)基于 CPU/内存或自定义指标伸缩。
-
使用 PersistentVolume 持久化 memory/knowledge 数据。
-
把模型提供者的密钥保存在 Kubernetes Secret 中,并使用 RBAC 限制访问。
(这里不包含完整 manifest 示例;若需要我可以添加一个 Kubernetes 示例清单。)
5.2 CI/CD 与自动化测试
为了保持代码质量并保证在向仓库提交时不破坏运行环境,建议:
-
使用 GitHub Actions / GitLab CI 在 PR 时执行 lint、单元测试与安全扫描(例如 bandit、safety)。
-
为关键路径(例如 tools、extensions)添加单元测试和集成测试示例,确保工具调用流程不会回归。
-
对于可执行代码路径(Agent 会运行的代码),在 CI 中使用沙箱或模拟(mock)机制,而非直接执行真实外部调用。
一个最小的 GitHub Actions 流程:
name: CI
on: [push, pull_request]
jobs:test:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v4- name: Set up Pythonuses: actions/setup-python@v4with:python-version: '3.11'- name: Installrun: |python -m pip install --upgrade pippip install -r requirements.txt- name: Run testsrun: |pytest -q
5.3 安全、隐私与合规性
Agent Zero 的能力很强(执行代码、访问网络、调用工具),因此安全策略必须优先:
-
最小权限原则:仅为 Agent 提供运行所需的最少权限与网络访问。
-
Secrets 管理:所有 API Key/凭证必须放在受管控的 Secret 存储中(例如 Vault、Kubernetes Secret),不要直接写入仓库或明文配置。
-
输入校验与人工确认:对于高危操作(删除文件、执行破坏性命令),启用人工确认流程。
-
日志与审计:记录工具调用、执行结果与调用者信息,便于事后审计与回溯(注意脱敏)。
-
定期安全扫描:对 Python 包进行 SCA,检测已知漏洞;对生成的脚本保留审查记录。
5.4 开发者与贡献指南
欢迎社区贡献。下面给出简要流程与建议:
5.4.1 贡献流程
-
Fork 仓库并新建分支:
git checkout -b feat/my-feature
-
在本地添加测试并实现功能:
-
为修改添加单元测试或示例用例。
-
修改对应
prompts/、agents/或python/extensions/下的文件时,保持格式与现有风格一致。
-
提交 PR:
-
在 PR 描述中说明改动目的、测试方法以及对运行时的影响。
-
CI 通过后由维护者审查并合并。
5.4.2 代码风格与质量要求
-
遵循项目已有的代码风格(PEP8 为主),保持函数短小、职责单一。
-
对于对外暴露的工具或扩展,请添加简要文档(prompts/md、示例 JSON)。
-
涉及安全与隐私的改动请在 PR 中特别标注风险评估。
5.5 路线图与未来方向
下面列出一些可行且有价值的发展方向,社区和维护者可以据此作为后续优先级参考:
-
多模态能力:集成更丰富的视觉与音频理解模块,支持图片/文档中的上下文推理。
-
边缘/离线部署:优化模型与嵌入支持,使一些功能可以在离线或受限网络环境中运行。
-
更强的安全沙箱:引入语言级或容器级沙箱(例如 Firecracker、gVisor)来隔离代码执行。
-
扩展工具市场:建立社区工具市场,用户可以分享和评分自定义工具与 Instruments。
-
企业级集成:提供对接 SSO、审计日志和合规部署模版(HIPAA/GDPR 等场景)。
如果你希望我为上述任意一项生成详细设计、示例实现或 CI/CD 清单,请告诉我优先级,我可以把它们逐项实现为 PR 模板或示例文件。
5.6 参考资料与致谢
-
项目仓库:https://github.com/agent0ai/agent-zero
-
文档与使用指南(仓库内 docs/ 目录)
-
感谢社区贡献者与早期用户的反馈,特别感谢那些提交 tools、extensions 与本地化文档的贡献者。
更多AIGC文章
RAG技术全解:从原理到实战的简明指南
更多VibeCoding文章