AI研究-112 DeepSeek-OCR 发展背景 走红原因 新型任务与潜在研究方向 详细分析 附最小运行测试
TL;DR
- 场景:需要把成千上万页 PDF/扫描件转 Markdown/表格,并希望少 Token、快吞吐。
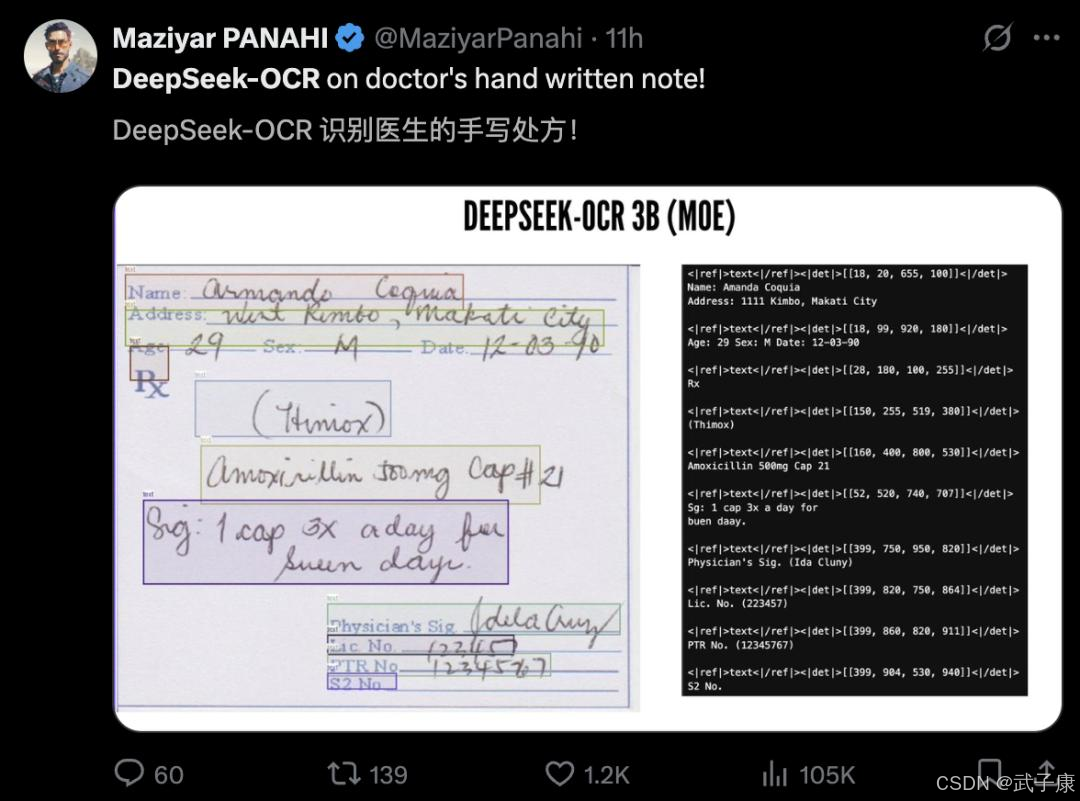
- 结论:DeepSeek-OCR 以“上下文光学压缩”把文本映射到图像 Token,<10× 压缩时 OCR 精度≈97%;A100-40G 实测≈2500 tok/s,支持 vLLM 与 HF Transformers 推理。 
- 产出:最小可跑脚本(单图 / 批量 PDF)、模式与参数表、踩坑与回滚清单。

DeepSeek-OCR是什么?谁开发的?初衷是什么?
DeepSeek-OCR是由中国初创团队 DeepSeek(深度求索)开发的一款革命性OCR模型 。它于2025年10月20日在开源社区正式发布,立即在GitHub和Hugging Face平台上引发轰动 。该模型参数规模约30亿(3B),采用了“上下文光学压缩(Contexts Optical Compression)”的创新思路,将大量文本信息以视觉形式压缩,使模型通过“看图”来重建文本 。
DeepSeek团队希望借此突破大型语言模型在处理超长文本时的算力和长度瓶颈,用视觉感知手段来提升效率。模型的主要研发者包括魏浩然(曾主导GOT-OCR2.0的开发)、孙耀峰和李宇琨等人,他们均深耕多模态和OCR领域 。DeepSeek-OCR开源发布时还提供了MIT开源许可证和完整模型权重,体现了该团队开放共享的理念 。
何时及因何事件突然走红?
DeepSeek-OCR在2025年10月下旬开源后的短短数天内便迅速走红。发布当日,GitHub仓库一夜之间收获了数千星标(一天内突破3.3K星 ;次日超过4.4K星),Hugging Face模型页跃居热度榜第二。

更夸张的是,硅谷技术圈对这一模型赞誉有加:前特斯拉AI总监、OpenAI创始成员Andrej Karpathy在社交媒体表示对DeepSeek-OCR的论文“非常喜欢”,称图像输入或许比纯文本更适合LLM,非常妙 。

有人将其称作“AI的JPEG时刻”,认为通过视觉压缩文本的方案打开了AI长时记忆的新路径。甚至有传言猜测,DeepSeek-OCR的方案可能泄露了谷歌下一代模型Gemini的核心机密。
总之,一系列社交媒体传播(Karpathy等大咖背书)、模型性能突破以及完全开源可用的特性,让DeepSeek-OCR在发布后瞬间引爆了社区关注度。

爆火原因分析

社区热度与传播节点
DeepSeek-OCR爆火的直接原因是开源即引爆的传播效应。模型开源后,技术大V在Twitter/X、Reddit等平台争相讨论其意义。从Karpathy高调点赞 到各种技术社区分析文章迅速涌现,形成了“明星效应+自来水”的传播链条。
一夜之间,GitHub星标和下载量猛增,Hugging Face上众多开发者搭建了演示Demo供大家免费体验。与此同时,国内外媒体也竞相报道:如36氪、南华早报等强调这款中国团队模型如何刷新OCR认知。
可以说,高性能开源模型遇上活跃技术社区,加之“大语言模型上下文极限”这一痛点话题,自然引爆了讨论热潮。
技术优势对比
DeepSeek-OCR从技术上相较其他OCR框架有多方面显著优势,令其备受瞩目。
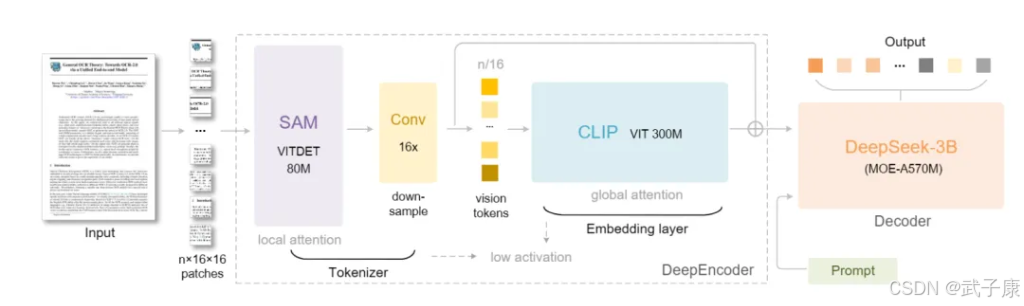
上下文压缩效率
颠覆性的10×压缩能力是其杀手锏。传统OCR或视觉模型处理文本,往往需要大量视觉tokens(图像patch)才能覆盖整页文本信息,甚至多于纯文本tokens。DeepSeek-OCR则通过特殊设计,实现了用更少的视觉tokens表示相同文本内容。
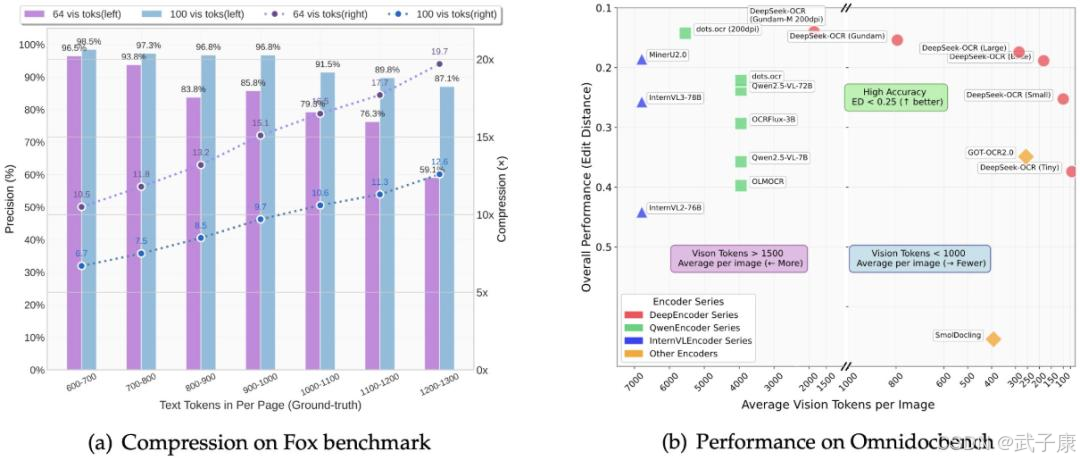
实验显示,若文本token数量是视觉token的10倍以内(压缩率<10×)时,DeepSeek-OCR重建文本的准确率高达97%;即便压缩到20×,还有约60%的精度。这一点远超其他OCR框架:例如,在OmniDocBench基准上,DeepSeek仅用100个视觉token就超越了GOT-OCR2.0使用256 token的效果,<800个token即可大幅领先MinerU2.0平均近7000 token的水平。
换言之,性能/效率比极高,这一优势在需要处理长文档、大批量文档时价值巨大。
模型能力和适用范围
DeepSeek-OCR不仅识别准确率高,且具备更强的广谱文档解析能力。它在训练中加入了丰富的数据类型,因而能够识别普通印刷体文字之外的复杂要素,如表格和图表(可解析成HTML表格)、化学分子式(输出SMILES字符串)、数学公式和几何图形(理解为结构化表示)等 。同时模型天然支持近100种语言的OCR(多语言文档) 。
这一点使其适用场景远超传统OCR框架:过去处理文档中的混合内容(文本+公式+图表)需要多模型配合,DeepSeek-OCR则有望“一网打尽”,成为通用文档理解引擎。
端到端与指令可控
与PaddleOCR等传统管线不同,DeepSeek-OCR采用端到端架构,不需要独立的文本检测和识别步骤。它的视觉编码器+文本解码器直接从图像输出文本或结构结果,避免了繁琐的后处理。
此外,借助其解码器的大语言模型特性,DeepSeek-OCR还能理解指令:开发者可以在提示中要求模型按特定格式输出结果(例如“将文档转换为Markdown” ),模型就会按照要求组织文字。这种指令可控的OCR为下游应用提供了极大便利,是传统OCR很难实现的。
性能和部署
虽然DeepSeek-OCR模型较大(3B参数),但由于其高压缩率,推理速度并未牺牲。官方数据显示在单张40GB显存A100卡上可达每秒约2500 token的处理 throughput,推理一页文档只需数秒甚至更快。此外模型提供了多种分辨率模式以兼顾速度与精度(后文详述),并支持FlashAttention等优化加速 。
部署方面,由于完全开源且基于PyTorch实现,开发者可自由在本地GPU、服务器甚至浏览器插件中运行(据报道百度的PaddleOCR-VL 0.9B版甚至能在CPU/浏览器上运行)。
DeepSeek-OCR虽算不上“轻量”,但在高端GPU上运行良好,开放代码也方便定制优化。这种可用性降低了尝鲜门槛。
易用性和社区推动
DeepSeek-OCR的火爆也离不开其开源友好度和社区生态。模型开源即提供了详细的使用文档、模型权重下载、示例代码和推理函数封装 。只要具备基础的PyTorch环境,开发者几行代码即可加载模型并运行OCR,大幅降低了试用门槛。
另外,Hugging Face上众多用户迅速搭建了在线Demo(Gradio应用等)供大众测试。这种良好的社区氛围使DeepSeek-OCR的亮点被快速验证传播,用得越多人就越有人愿意尝试,形成了正向循环。
此外,DeepSeek团队在发布时强调了模型MIT许可(商业可用)和感谢了业界相关开源项目,展现出开放合作的态度。这些都提升了开发者对其的认可度,进一步助推了流行。
新型任务与潜在研究方向
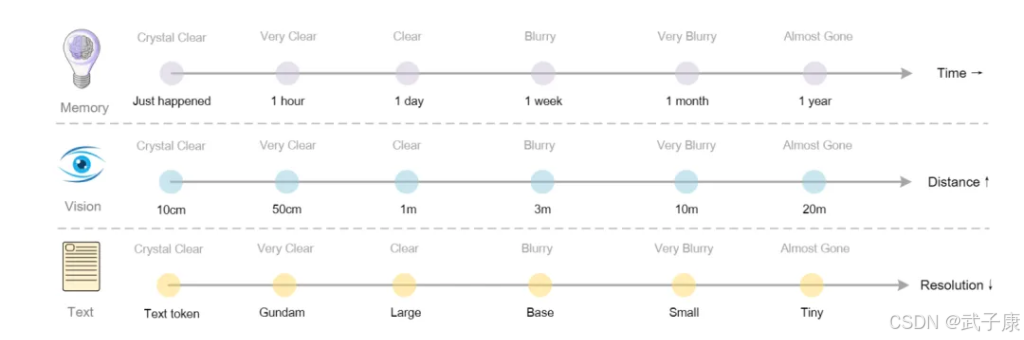
无限长上下文的记忆机制
DeepSeek-OCR提出的上下文光学压缩为扩展LLM记忆提供了新思路 。未来研究可以基于此探索“无限上下文”模型:模拟人类记忆,将旧对话压缩成模糊图像存储,新的信息用清晰图像保留,模型动态决定何时解压细读。
这涉及构建分层记忆模块、研究压缩级别与任务性能的关系,可能催生出类人记忆的对话系统架构。
跨模态信息抽取
利用DeepSeek-OCR的能力,可以研究图文混合信息抽取任务。例如给模型输入一份年报的图表页面,直接让它输出结构化的数据表。或者读取化学实验报告,提取试剂和结果。这需要模型进一步理解视觉中的非文字元素(图表曲线、示意图形状)并关联到文本描述。
目前DeepSeek-OCR已经展现了一定潜力,未来可以在此基础上加入专门loss或后处理,提高对复杂文档的“读懂”程度,实现从“识字”到“读懂”。
更大规模与专业领域模型
3B参数的DeepSeek-OCR已经性能惊艳,但深度学习的一般规律是模型更大效果可能更好。未来可研究更大参数的视觉压缩模型,比如30亿、100亿参数甚至稀疏Mixture of Experts进一步扩充。此外,针对特定领域(医疗、法律)的文档,训练专门的OCR-VL模型也是方向。
例如“医疗OCR大模型”可融合同位素图像、心电图曲线的解析能力;“法律文档OCR大模型”则对版面和行文格式有特殊优化。这些领域模型可以在DeepSeek-OCR基础上微调得到,用较少资源达到专业级表现。
模型压缩与蒸馏
反过来,对于应用受限于算力的情况,可以研究如何将DeepSeek-OCR的能力蒸馏到小模型上。
例如训练一个5亿参数的Tiny版OCR模型,保证压缩能力比传统OCR高2-3倍且精度接近,从而能在边缘设备部署。这涉及知识蒸馏、多任务训练等技术,平衡模型大小和性能,是很有价值的工程研究课题。
视觉压缩的理论探索
从更基础的角度看,DeepSeek-OCR引出了一个有趣的科学问题:视觉表示为何能如此高效地编码语言? 未来研究可从信息论角度量化视觉token的信息量,或者分析模型attention层的权重看看它如何在图像空间定位文字。
甚至可以探索不同的“光学压缩”方式,比如用更紧致的视觉字体渲染文本、用颜色/深度等额外通道嵌入信息等,看是否进一步提升压缩率。这样的研究将深化我们对多模态表示的理解。
最小运行示例
vLLM
# 环境(CUDA 11.8 + torch 2.6.0 + vLLM 0.8.5)
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCR
conda create -n dpsk-ocr python=3.12.9 -y && conda activate dpsk-ocr
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt flash-attn==2.7.3 --no-build-isolation# 单图 / PDF 批处理(官方脚本,改 config.py 的输入/输出路径)
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm
python run_dpsk_ocr_image.py
python run_dpsk_ocr_pdf.py # A100-40G 约 2500 tok/s
Transformers
from transformers import AutoModel, AutoTokenizer
import torch
m = 'deepseek-ai/DeepSeek-OCR'
tok = AutoTokenizer.from_pretrained(m, trust_remote_code=True)
mdl = AutoModel.from_pretrained(m, trust_remote_code=True,use_safetensors=True,_attn_implementation='flash_attention_2').eval().cuda().to(torch.bfloat16)
res = mdl.infer(tok,prompt="<image>\n<|grounding|>Convert the document to markdown.",image_file="demo.jpg",output_path="./out",base_size=1024, image_size=640, crop_mode=True,save_results=True, test_compress=True)
print(res)
输入→期望输出→核验
Step 1|选模式
先用 Small(640,100t);页复杂/公式多再切 Base(1024,256t);极复杂用 Large/Gundam。核验:统计生成长度、错误率与耗时。
Step 2|提示工程
-
文档转 Markdown:\n<|grounding|>Convert the document to markdown.
-
只做 OCR:\nFree OCR.
-
表格抽取/图解析也有示例 Prompt(见 README)。
Step 3|批量 PDF
run_dpsk_ocr_pdf.py;基线吞吐记录 tok/s、页/秒。
Step 4|校验
随机抽样 100 页,计算 字符级/词级准确率 与结构保真度(表格/公式)。
Step 5|回滚
压缩过高→降级到 Base/Small;显存吃紧→降低 image_size 或关闭 Gundam。
错误速查
| 症状 | 可能根因 | 快速定位 | 处置 |
|---|---|---|---|
| flash-attn 编译/导入失败 | CUDA/torch 版本不匹配 | pip show torch; nvcc -V | 固定 torch=2.6.0 + cu118,重装 flash-attn |
| vLLM 起不来/导入冲突 | vLLM 与 transformers 版本耦合 | pip freeze | grep vllm | 调整 vLLM 或 transformers 版本至兼容状态 |
| 显存爆/吞吐异常 | 分辨率/模式选太大 | 监控显存使用情况 | 从 Small(640) 起测,降分辨率/关 Gundam/增批量与流水线优化 |
信息来源
- 36氪-文本已死,视觉当立,Karpathy狂赞DeepSeek新模型,终结分词器时代
- wallstreetcn-DeepSeek-OCR
其他系列
Ollama 本地部署实战 | 3 分钟安装 & 多卡GPU部署 & 运行实战 【2025版】
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接