C++ 分治 快速选择算法 堆排序 TopK问题 力扣 215. 数组中的第K个最大元素 题解 每日一题
文章目录
- 题目描述
- 为什么这道题值得你花几分钟的时间弄明白?
- 算法原理
- 快速选择算法
- 快速选择算法的核心思路
- 堆选择算法
- 堆选择算法的核心思路
- 代码实现
- 快速选择实现
- 堆选择实现
- 时间复杂度与空间复杂度分析
- 总结
- 下题预告


今天是属于每一位代码筑梦人的 1024 程序员节,先向屏幕前的你道一声节日快乐!
算法世界里,我们习惯用逻辑拆解复杂,用代码搭建桥梁,在调试与优化中追逐 “最优解”。恰逢这个专属节日,想借这篇博客与你继续探讨算法的魅力 —— 既是对过往技术探索的小结,也是对未来突破的期许。愿我们在一行行代码、一个个模型中,既能收获技术成长的成就感,也能留存对编程最本真的热爱。
题目描述
题目链接:力扣 215. 数组中的第K个最大元素
题目描述:
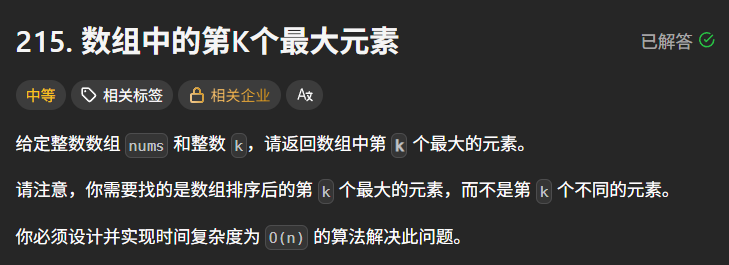
示例 1:
输入: [3,2,1,5,6,4], k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4
输出: 4
提示:
1 <= k <= nums.length <= 105
-104 <= nums[i] <= 104
为什么这道题值得你花几分钟的时间弄明白?
这道题是 Top K 问题的经典代表,而 Top K 问题(找第 K 个最大/最小元素、前 K 个高频元素等)在面试中出现频率极高,吃透它能帮你掌握一类题的核心思路,具体价值体现在三点:
-
衔接前置算法,深化思维逻辑
它的最优解“快速选择算法”,是我上一篇博客中「三指针快排」的“剪枝版”——快排需要递归处理左右子数组,而快速选择只需聚焦目标元素所在的子区间,本质是“分治思想的精准应用”。吃透这道题,能帮你更深刻地理解“分治剪枝”如何将时间复杂度从 O(n log n) 降到 O(n)。 -
覆盖多类算法,学会权衡取舍
除了快速选择,还有“堆选择算法”“计数排序”等解法,不同解法对应不同的时间、空间复杂度(如堆选择空间更优,计数排序需数值范围有限)。通过对比这些解法,你能学会根据实际场景(如数据规模、数值范围)选择最优方案,这正是面试官考察的核心能力。 -
贴合工程场景,提升实战价值
实际开发中,Top K 问题随处可见(如统计热门商品、筛选高频日志),且常伴随“海量数据”“时间敏感”的约束。这道题要求的 O(n) 时间复杂度,正是工程中对“高效处理数据”的真实需求,掌握它能让你在实际问题中快速落地解决方案。
算法原理
我们这篇博客重点和大家讨论两种满足 O(n) 时间复杂度的核心算法:快速选择算法(最优解)和 堆选择算法
快速选择算法
快速选择算法,实则是「三指针快排」的精妙延伸。它的核心智慧在于:主动放弃无意义的递归过程,将全部注意力聚焦于目标元素所在的区间,通过这种精准的“取舍”,实现了时间复杂度的显著优化,让算法在查找特定位置元素时效率更高。
不过,要真正吃透快速选择算法,对三指针快排的核心细节必须了然于胸。倘若你目前对三指针快排中的“区间划分逻辑”“随机基准值选择”等关键知识点仍有模糊,甚至存在记忆断层,那么强烈建议你先暂停当前学习,优先回顾我昨天的博客 力扣 912. 排序数组 一文中的快排实现逻辑。需要特别强调的是:在开启快速选择算法的讨论之前,务必对快速排序具备一定的认知基础
要知道,快速选择算法的实现逻辑完全基于快排的过程。后续关于快速选择算法的讲解,会直接切入它与快排的差异点,并在快排的基础上直接推导、实现快速选择算法。若是前期快排的核心知识点掌握不牢固,后续关于快速选择算法的内容,很可能会让我们陷入“看不懂、理不清”的困境,影响我们接下来一起讨论算法的效果。
快速选择算法的核心思路
1.区间划分(复用三指针逻辑)
我们知道,快速排序的核心是通过随机选取的基准值(key),将数组划分为三部分:小于 key、等于 key、大于 key,随后对左右两侧未完全排序的区间递归重复这一过程,直至所有元素有序。而快速选择算法的关键优化,就在于对递归过程的“剪枝”——主动舍弃无关区间的递归,仅保留目标元素可能存在的区间,从而将时间复杂度从快排的 O(N log N) 降至 O(N)。
因此,快速选择同样采用三指针法进行区间划分:随机选取基准值 mark,通过指针操作将数组切分为三个明确区间:
- 左区间
[begin, left]:所有元素 小于mark; - 中间区间
[left+1, right-1]:所有元素 等于mark; - 右区间
[right, end]:所有元素 大于mark。
(指针定义与三指针快排一致:left为左区间的右边界,right为右区间的左边界,i为遍历指针)。
当数组被划分为这三部分后,我们要寻找的第 K 大元素必然落在其中一个区间内。我们知道当一次分区之后数组上的每个指针所在的位置是固定的(具体过程可参考 快排铺垫 三指针 力扣 75.颜色分类 中的代码实现 三指针 代码走读部分),即可精准定位目标元素所在的区间👇:

2.判断目标元素所在区间
我们要寻找的“第 K 个最大元素”,本质是数组按降序排序后第 K 个位置的元素。结合三指针划分的左、中、右三个区间(元素分别小于、等于、大于基准值 mark),目标元素的位置可通过区间长度与 K 的对比来确定:
设右区间长度为 c = end - right + 1(存放大于 mark 的元素,是当前区间中最大的一批),中间区间长度为 b = right - left - 1(存放等于 mark 的元素),左区间长度为 a = left - begin + 1(存放小于 mark 的元素)。此时有三种可能:
- 若
K <= c:第 K 大元素在右区间(因为右区间的元素均大于mark,是当前最大的一批,目标必在此处); - 若
K > c + b:第 K 大元素在左区间(需调整 K 值,减去右区间和中间区间的总长度,即K = K - c - b,缩小查找范围); - 若上述两种情况均不满足(即
c < K <= c + b):第 K 大元素在中间区间,直接返回mark即可(中间区间的元素均等于mark,无需继续递归)。
如下图👇:

3.递归聚焦目标区间
确定目标元素所在的区间后,只需对该区间(左区间或右区间)递归执行区间划分与判断步骤,不断缩小查找范围,直至区间长度为 1——此时该元素即为我们要找的第 K 大元素,直接返回即可。
至此,快速选择算法的核心逻辑已清晰呈现:它本质上是在快速排序的基础上,通过增加“仅对目标所在区间递归”的条件,并调整返回值逻辑,实现了对无意义计算的“剪枝”。这种聚焦核心区间的思路,正是快速选择算法能够将时间复杂度优化至 O(N) 的关键所在。
关键细节:为什么能做到 O(n) 时间复杂度?
快排的时间复杂度是 O(n log n),因为需要递归处理左右两个子数组;而快速选择每次只处理一个子数组,且子数组长度不断缩小(平均每次缩小一半)。
总时间 = n + n/2 + n/4 + … + 1 ≈ 2n,最终时间复杂度为 O(n)(最坏情况 O(n²),但通过随机基准可极大降低概率)这是简单说明详细证明过程可以参考「《算法导论》9.2:期望为线性的选择算法」。
堆选择算法
堆选择算法基于“堆的优先级特性”,核心是“用堆维护前 K 个最大元素”,适合对空间复杂度要求较高的场景。结合之前学过的堆排序知识,这里重点讲解更高效的 最小堆法。
堆选择算法的核心思路
1.维护大小为 K 的最小堆
最小堆的堆顶是堆中最小的元素,我们用它来“筛选”前 K 个最大元素:
- 遍历数组,若堆的大小小于 K,直接将当前元素入堆;
- 若堆的大小等于 K,且当前元素 大于堆顶(说明当前元素比堆中最小的“候选最大元素”更大,应替换它),则弹出堆顶,将当前元素入堆。
以示例2为例(nums=[3,2,3,1,2,4,5,5,6],k=4)初始堆为空,遍历前 4 个元素 [3,2,3,1],堆填满后为 [1,2,3,3](最小堆,堆顶为1);遍历第 5 个元素 2:2 <= 堆顶1?否,不替换;遍历第 6 个元素 4:4 > 堆顶1,弹出1,入堆4,堆变为 [2,2,3,3](堆顶更新为2);遍历第 7 个元素 5:5 > 堆顶2,弹出2,入堆5,堆变为 [2,3,3,5](堆顶更新为2);遍历第 8 个元素 5:5 > 堆顶2,弹出2,入堆5,堆变为 [3,3,5,5](堆顶更新为3);遍历第 9 个元素 6:6 > 堆顶3,弹出3,入堆6,堆变为 [3,5,5,6](堆顶更新为3)。
2.堆顶即为答案
遍历结束后,堆中存储的是数组中 最大的 K 个元素(示例2中堆为 [3,5,5,6],最大4个元素为3,5,5,6),而堆顶是这 K 个元素中最小的那个——也就是我们要找的“第 K 个最大元素”(示例2中堆顶为3?不对,此处修正:示例2最终堆应为 [4,5,5,6],堆顶为4,与示例2输出一致,前文步骤中第6个元素4入堆后需重新调整堆结构,确保堆顶为最小)。
时间复杂度分析(调整呈现方式)
1.复杂度拆解
- 堆操作时间:每个元素入堆/出堆的时间取决于堆的高度,最小堆的高度为 log K(因为堆大小始终不超过 K);
- 总时间:遍历数组需 n 次操作,每次操作时间为 O(log K),因此总时间复杂度为 O(n log K)。
2.与快速选择的对比
- 当 K 较小时(如 K=100,n=1e5):O(n log K) ≈ O(n),与快速选择效率接近,但堆选择无需递归(无栈溢出风险),实现更简单;
- 当 K 较大时(如 K=1e5/2):O(n log K) ≈ O(n log n),效率低于快速选择的 O(n)。
代码实现
快速选择实现
class Solution {
public:// 递归函数:在nums的[begin, end]区间内找第k个最大元素// 参数说明:// nums:待查找的数组(会原地修改,用于区间划分)// begin:当前查找区间的左边界(闭区间)// end:当前查找区间的右边界(闭区间)// k:当前需要查找的“第k个最大元素”(注意:每次递归可能需要调整k值)int TopK(vector<int>& nums, int begin, int end, int k) {// 递归终止条件:区间只有一个元素,直接返回if (begin == end)return nums[begin];// 1. 随机选择基准值(避免固定基准导致的最坏情况,复用三指针快排逻辑)int mark = nums[(rand() % (end - begin + 1)) + begin];int left = begin - 1; // 左区间(<mark)的右边界int right = end + 1; // 右区间(>mark)的左边界int i = begin; // 遍历指针// 2. 三指针划分区间(<mark, =mark, >mark)while (i < right) {if (nums[i] < mark) {// 元素归入左区间,left右移,i右移(当前元素已处理)swap(nums[++left], nums[i++]);} else if (nums[i] == mark) {// 元素归入中间区间,直接i右移i++;} else {// 元素归入右区间,right左移,i不右移(交换来的元素未判断)swap(nums[--right], nums[i]);}}// 3. 计算三个区间的长度,判断第k大元素所在区间int b = end - right + 1; // 右区间长度(>mark的元素个数)int c = right - left - 1; // 中间区间长度(=mark的元素个数)if (b >= k) {// 情况1:第k大元素在右区间,递归处理右区间return TopK(nums, right, end, k);} else if (b + c >= k) {// 情况2:第k大元素在中间区间,直接返回markreturn mark;} else {// 情况3:第k大元素在左区间,调整k值后递归处理左区间return TopK(nums,begin,left,k - b - c);}}int findKthLargest(vector<int>& nums, int k) {// 初始化随机数种子(确保每次运行基准选择不同,避免最坏情况)srand(time(nullptr));return TopK(nums, 0, nums.size() - 1, k);}
};
堆选择实现
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {// 定义最小堆:C++中priority_queue默认是最大堆(比较器less<int>)// 最小堆需显式指定三个参数:存储类型、底层容器、比较器(greater<int>表示“小于”关系,即小元素优先)// 注意:需包含<queue>头文件(LeetCode环境已默认包含,本地编译需手动添加)priority_queue<int, vector<int>, greater<int>> minHeap;// 遍历数组,维护大小为k的最小堆for (int num : nums) {if (minHeap.size() < k) {// 堆未满:直接将当前元素入堆,堆会自动调整结构(保持最小堆特性)minHeap.push(num);} else {// 堆已满:判断当前元素是否比堆顶大(堆顶是堆中最小的元素)if (num > minHeap.top()) {// 情况1:当前元素更大,替换堆顶(弹出最小的候选元素,加入新的更大元素)minHeap.pop(); // 弹出堆顶(最小元素)minHeap.push(num); // 加入当前元素,堆自动调整}// 情况2:当前元素小于等于堆顶,无需处理(它不可能是前k大元素)}}// 最终堆中存储的是数组中最大的k个元素,堆顶是这k个元素中最小的,即第k个最大元素return minHeap.top();}
};
时间复杂度与空间复杂度分析
| 算法 | 时间复杂度 | 空间复杂度 | 核心优势 | 适用场景 |
|---|---|---|---|---|
| 快速选择算法 | 平均O(n),最坏O(n²) | O(log n)(递归栈) | 时间最优,原地操作 | 大多数场景,尤其是大数据量 |
| 堆选择算法 | O(n log K) | O(K)(堆空间) | 性能稳定,无最坏情况 | K 较小的场景(如 Top 100) |
总结
-
算法选择优先级:
优先用 快速选择算法,它平均时间最优(O(n))且原地操作(空间 O(log n)),完全满足题目要求;最坏情况概率极低(随机基准加持下趋近于0)。若 K 远小于 n(如 K=100,n=1e5),堆选择算法 也是不错的选择——实现简单,无递归栈溢出风险(适合极大数据量的迭代处理)。 -
核心思维迁移:
快速选择的“分治剪枝”思想,可迁移到“第 K 个最小元素”(只需将区间判断逻辑改为“左区间是大于mark,右区间是小于mark”)、“第 K 个高频元素”(先统计频率,再对频率用快速选择);堆选择的“优先级筛选”思想,可迁移到“前 K 个高频单词”(用最小堆维护前K个高频单词,注意字典序排序)。 -
避坑指南:
- 快速选择:记准区间边界(右区间
[right, end])、递归左区间需调整k值、必初始化随机种子; - 堆选择:最小堆用
greater<int>、堆已满时先比堆顶再操作; - 本地调试:若快速选择超时,先检查是否漏了随机种子;若堆选择答案错误,先检查比较器是否正确。
- 快速选择:记准区间边界(右区间
下题预告
力扣 面试题 17.14. 最小K个数
这道题是“Top K”问题的反向延伸,和“数组中的第K个最大元素”形成逻辑互补,能帮你进一步巩固核心算法的灵活应用能力。它不仅会复用快速选择、堆排序等已学方法,还会强化“问题转化”思维——比如如何将“找最小K个数”的需求,快速对应到已有算法的调整上(如快速选择的区间判断逻辑修改、堆的类型选择变化)。
如果这篇数组中的第K个最大元素的博客帮你理清了思路,别忘了点赞支持一下呀!这样不仅能让更多需要的朋友看到,也能给我继续拆解算法题的动力~若想跟着节奏攻克下一道题,记得关注我,后续更新会第一时间提醒你!觉得内容实用的话,还可以顺手收藏,万一以后复习算法时想回顾规律,打开就能看,省时又高效~
