JavaEE开篇之计算机是如何工作的
JavaEE开篇之计算机是如何工作的
- 1. 简单了解Java的发展史
- 2. 计算机是如何工作的
- 2.1冯·诺依曼体系结构
- 1. CPU
- 2. 存储器
- 3. 输入设备
- 4. 输出设备
- 3. CPU执行指令的过程(简化版)
- 3.1 什么是指令?
- 3.2 CPU的工作周期
- 4. 操作系统
- 4.1 常见的操作系统
- 4.2 操作系统的核心功能
- 4.3 内核
- 5. 进程
- 5.1 进程管理
- 5.2 PCB
1. 简单了解Java的发展史
Java起源于一个嵌入式设备项目–Green Project,当时的开发团队由詹姆斯·高斯林领导,由于C++的语言特性不符合嵌入式设备项目的需求,因此创造出了一个新语言–Oak.后来发现"Oak"这个名字已经被另一种计算机语言使用了,于是更名为"Java".
嵌入式设备虽然没有开发出来,但是语言却开始流行了,网景公司在1995年与Sun合作,在其浏览器中集成了Java Applet技术。
然而好景不长,微软开发的IE浏览器如日中天,且微软也有自己的语言J++,两者竞争加剧,微软通过推广其不兼容的J++和后来的.NET战略,削弱了Java的跨平台一致性,并通过浏览器和操作系统的绑定优势挤压了Java(尤其是Applet)的市场。然而J++也没有抓住机会,反倒是另一门语言–JavaScript抢占了前端开发的市场,JavaScript一火火了30年,以至于目前JS仍然是前端开发最主力的语言.
Java开始继续寻求出路:
- 做服务器开发(后端)
- 做嵌入式开发
并在自身基础上划分出了几个版本.1999年Java 2平台发布,首次划分为J2SE, J2EE, J2ME,2006年,Sun为了简化品牌,将“J2”前缀去掉,改为Java SE, Java EE, Java ME。
- 标准版:J2SE==>Java SE(基石)
- 企业版:J2EE==>Java EE(服务器开发)
- 精简版:J2ME==>Java ME(嵌入式开发)
在2000年代初,PHP在中小型Web开发中极为流行,而Java(J2EE)则在大型企业级应用中占据重要地位。
随着手机(功能机)崛起,JavaME也获得了发展.
服务器开发和嵌入式开发这两方面的发展使Java重回主流,此时的Java已经不局限于前端了,变得更加综合.
然而时代推进,又出现了新的挑战:随着网站规模变大,以PHP为首的后端开发技术变得难以适应,Java EE发展受到重创.此外,移动端开发领域:2007年乔布斯发布了第一代iPhone,智能手机的时代开启了,iPhone的兴起摧毁了功能机市场和Java ME.
Java一时间两条腿都瘸了,Java开始寻求新的出路,结果找得还不错:
- 后端开发领域,Java逐渐摒弃了JSP,并诞生了新的王者—Spring,给Java带来了新的春天,Spring提供了后端开发的全套解决方案,非常好地适应了大规模网站开发.在Spring的加持下,Java反超PHP成为后端开发的No.1
- 移动端开发,虽然Java ME倒下了,但是新的王者Android(背后是Google)诞生了,Android选择Java作为其应用开发语言,这为庞大的Java开发者社区(包括Java ME开发者)提供了一个无缝过渡到移动开发新领域的绝佳机会。
Java重回巅峰,王者归来,一度冲到编程语言榜首.
2020年,Java再次面临新的挑战–Golang,由包括Unix和C语言先驱Ken Thompson在内的团队设计,也有人说Golang是C语言新时代的继任者.目前Java的市场份额仍比Go大,但是Java的危机已经存在.
前面的这么多分析,怎么没有涉及到C++呢?
C++可以看做是与世无争的高人,C++是始终在背后操盘的大佬,因为不论是谁赢了,最后都是C++赢了.
Java运行时的JVM(如HotSpot)、Python的主流解释器CPython、JavaScript的V8引擎,其核心都是用C/C++编写的。
可以说:如果Java,Python,Go,JavaScript等语言是高楼大厦,商店,办公楼,那么C和C++就是这座城市的地基,钢筋水泥和地下管网,无论这座城市的商业中心是变成金融区还是科技园区,或者是游乐场,都离不开C++构建的坚固地基.
2. 计算机是如何工作的
艾伦·图灵和约翰·冯·诺依曼并称为"计算机之父".
艾伦·图灵—计算机科学的理论奠基人,提出了"图灵机"的概念(现代计算机"存储程序"概念的理论雏形),以及图灵测试(提出了判断机器是否具有智能的标准,开启了人工智能的先河),定义了"可计算性".图灵描绘了计算机的"灵魂"和"终极形态",告诉我们什么是计算,以及一台完美的计算机应该具备什么能力.
图灵机是一个思想模型,并非一台实体机器,由一个读写头,一条无限长的纸带和一套控制规则组成,这台机器通过加载不同的"程序"(即纸带上的指令)就能完成各种不同的任务
约翰·冯·诺依曼—现代计算机的体系结构设计者,1945年提出了著名的冯·诺依曼体系结构,回答了"我们应该如何实际地构建一台通用计算机"这个工程问题.
计算机内部的构造大同小异,整体规则都是冯大佬提出的"冯·诺依曼"结构,接下来,简单讲解一下这个结构:
2.1冯·诺依曼体系结构
冯·诺依曼经典理论将计算机核心划分为:运算器+控制器+存储器+输入设备+输出设备这五个部分,现代常将运算器和控制器这两个核心部件合称为中央处理器(CPU)。所以简化模型是CPU + 存储器(内存) + 输入设备 + 输出设备。
1. CPU
中央处理单元,是一个计算机最核心的部分,进行算术运算和逻辑判断,核心参数有如下几个:
- 核心
核心(物理核心)是CPU内部独立的处理单元,可以看做是一个"工人",每个核心都能同时处理不同的任务.核心数越多,CPU同时处理任务的能力就越强,即并发能力越强.
- 线程
要让CPU算得快,如果竖向发展,就需要包含更多的运算单元,使CPU的集成程度更高,单个运算单元体积就得更小,这对CPU的制作工艺提出了更高的要求,提升越来越难了.竖向发展受挫,那就开始考虑横向发展,单核不行就双核,四核,八核…还搞出了超线程技术:
超线程:让单个CPU核心能同时处理多个任务,线程是个硬件层面的概念,在操作系统中这一概念的名字是:逻辑处理器.一般将一个核心划分为两个逻辑处理器.
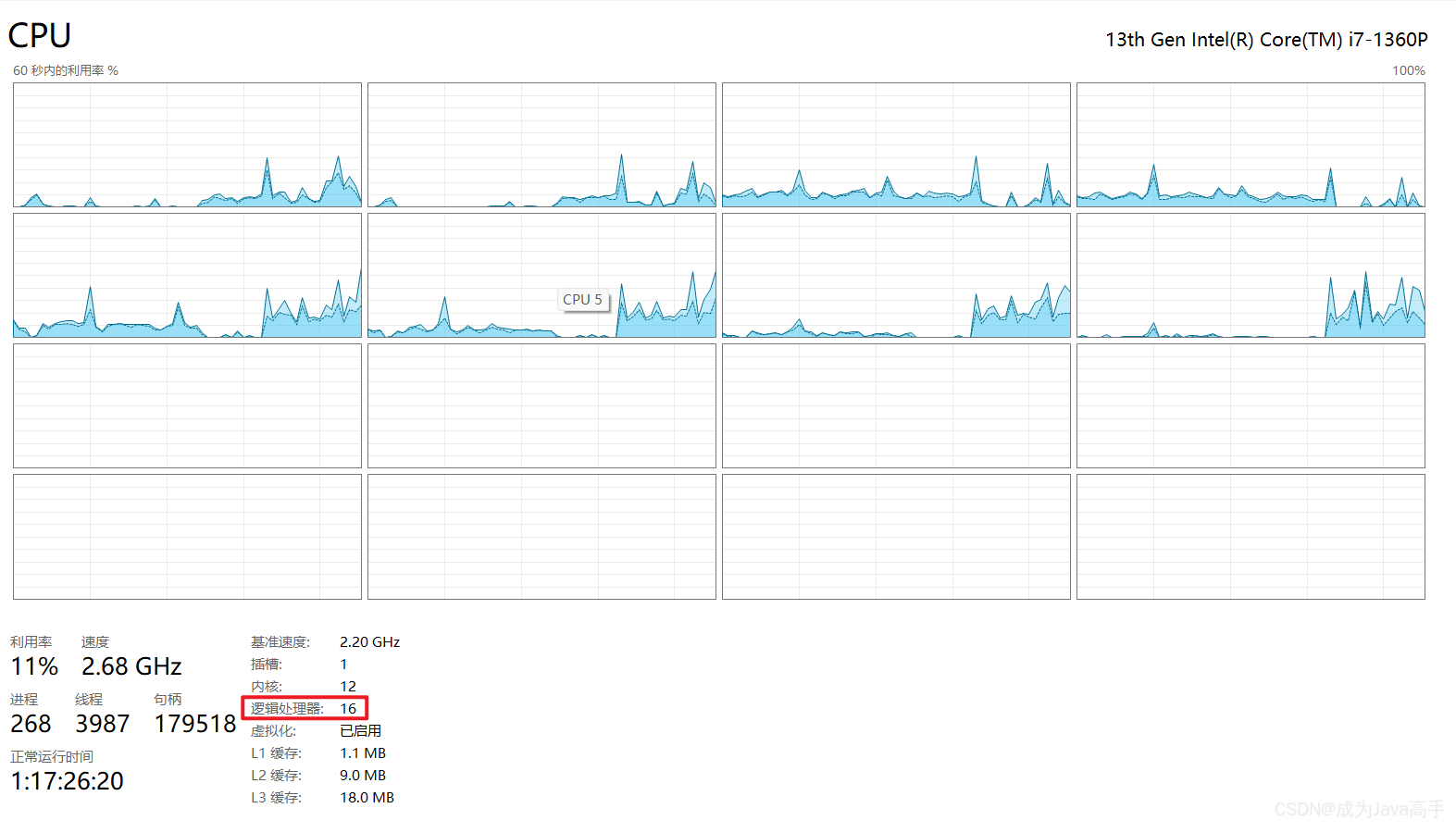
上图中有16个逻辑处理器,那么核心数就为8,即8核16线程.
超线程并没有增加物理上真正的执行单元,而是通过巧妙的调度,填充了一个物理核心内部原本可能限制的资源,从而提高了效率.
- 频率
频率是CPU运算速度的基准单位,通常以GHz(千兆赫兹)来表示.可以简单理解为1秒执行的指令数量.在核心/架构相同的情况下,频率越高,CPU处理单个任务的速度通常越快.
CPU频率是可以根据任务动态调整的:
- 基础频率:CPU在正常状态下的保证运行频率
- 加速频率:在散热和供电允许的情况下,CPU能达到的最高工作频率.这个参数对单核性能尤其重要。
- 缓存
缓存时CPU内部的高速内存,用于临时存储最常用的数据和指令.CPU从缓存读取数据的速度远快于从内存读取.缓存越大,CPU等待数据的时间就越少,效率越高.
通常分为L1,L2,L3三级,L1->L2->L3,越来越大,也越来越慢.
2. 存储器
计算机为了平衡速度、容量和成本,建立了一个多层次的存储系统,从上到下,速度变慢、容量变大、成本变低。
金字塔模型(从上到下,速度递减,容量递增):
- 寄存器:位于CPU内部,是速度最快的存储单元,用于存放当前正在执行的指令和数据。它的容量极小(以字节或比特计)。
- 高速缓存:也位于CPU内部或非常靠近CPU。分为L1、L2、L3等级别,作为内存和寄存器之间的缓冲,存放最常用的数据和指令,速度极快。
- 内存:存储空间小,访问速度快,成本高,掉电后数据丢失.
- 外存:硬盘,软盘,U盘,光盘都属于外存,存储空间大,访问速度慢,成本低,掉电后数据仍在.
3. 输入设备
用于将外部的程序和数据输入到计算机内存中,例子:键盘,鼠标,扫描仪,触摸屏等.
4. 输出设备
用于将计算机内存中的处理结果呈现给外部世界,例子:显示器,打印机,音响.
3. CPU执行指令的过程(简化版)
3.1 什么是指令?
首先,什么是指令?
在计算机内部,每条指令通常都由两部分组成:
- 操作码:指定"要做什么"的二进制代码,告诉CPU要执行什么操作,加法?减法?从内存加载数据?还是将数据存入内存?等等.
- 操作数:指定"对谁进行操作".提供操作需要的数据,或者数据所在的地址(比如在哪个寄存器里,在内存哪个位置).
我们平时写的C++,Python,Java等代码,CPU是看不懂的,它们需要被"翻译"成CPU能懂的指令,类似于:
| 指令 | 功能说明 | 4位操作码 | 4位操作数 |
|---|---|---|---|
| LOAD_A | 从RAM的指定地址,将数据加载到A寄存器 | 0010 | 4位RAM地址 |
| LOAD_B | 从RAM的指定地址,将数据加载到B寄存器 | 0001 | 4位RAM地址 |
| STORE_A | 将数据从A寄存器写入RAM的指定地址 | 0100 | 4位RAM地址 |
| ADD | 计算两个指定寄存器的数据的和,并将结果放入第二个寄存器 | 1000 | 2位的寄存器ID 2位的寄存器ID |
上表假设每个指令只有8bit,前4位是操作码,后四位是操作数.但实际上指令很更长,且更复杂,这里只是个简化版本.
3.2 CPU的工作周期
CPU执行指令的过程是一个循环,称为"指令周期",一个最基本的指令周期可以分为四个核心阶段:取指令->解析指令->执行指令->回写指令.
- 取指令
- 目标:从内存中拿到接下来要执行的那条指令
- 执行者:主要由控制器负责
- 详细过程
- 程序计数器:控制器内部有一个叫做"程序计数器"的寄存器,它里面要存储着下一条要执行的指令在内存中的位置.
- 发送地址:控制器将程序计数器中的地址通过地址总线发送给内存
- 获取指令:内存收到地址后,将该地址对应的指令内容通过数据总线发送给CPU
- 更新指针:程序计数器的值自动增加,指向下一条指令的地址,为下一个取指令阶段做好准备.
- 解析指令
- 目标:搞清楚刚刚拿到指令具体要"干什么"以及"对谁干".
- 执行者:控制器
- 详细过程:
- CPU拿到的指令实际上是一串二进制代码
- 控制器内部有一个"指令解析器",就像一本密码本,可以解析CPU拿到的二进制代码,确定需要执行的操作以及这个操作所需的操作数在哪里(是在CPU的寄存器里,还是在内存的某个地址里)
- 执行指令
- 目的:真正执行解析指令所确定的操作
- 执行者:运算器
- 详细过程:
- 控制器根据译码结果,向相关的部件发出控制信号
- 运算器根据指令,从寄存器或内存中获取操作数
- 运算器执行具体的操作
- 回写
- 目标:将执行阶段产生的结果保存起来
- 执行者:控制器和运算器协同
- 详细过程:将运算结果写入到指定的目的地,通常是CPU内存的寄存器,有时也会直接写回内存.
接下来举一个例子来说明一下执行过程:
假设有如下一些内存空间和数据,里面保存了一条条指令:
| 地址 | 数据 |
|---|---|
| 0 | 00101110 |
| 1 | 00011111 |
| 2 | 10000100 |
| 3 | 00000000 |
| 4 | 00000000 |
| 5 | 00000000 |
| 6 | 00000000 |
| 7 | 00000000 |
| 8 | 00000000 |
| 9 | 00000000 |
| 10 | 00000000 |
| 11 | 00000000 |
| 12 | 00000000 |
| 13 | 00000000 |
| 14 | 00000011 |
| 15 | 00001110 |
并且有如下的指令表:
| 指令 | 功能说明 | 4位操作码 | 4位操作数 |
|---|---|---|---|
| LOAD_A | 从RAM的指定地址,将数据加载到A寄存器 | 0010 | 4位RAM地址 |
| LOAD_B | 从RAM的指定地址,将数据加载到B寄存器 | 0001 | 4位RAM地址 |
| STORE_A | 将数据从A寄存器写入RAM的指定地址 | 0100 | 4位RAM地址 |
| ADD | 计算两个指定寄存器的数据的和,并将结果放入第二个寄存器 | 1000 | 2位的寄存器ID 2位的寄存器ID |
初始情况下,程序计数器值为0.
- 第一步:读取指令,读取地址为0的指令,数据是00101110
- 第二步:解析指令,指令前四位0010是操作码,通过查询指令表可知该二进制对应的是LOAD_A,操作数是1110->内存地址,LOAD_A的作用就是把1110这个地址的数据读取到寄存器A中.
- 第三步:执行指令,将1110地址的数据读取出来放到寄存器A中,1110按无符号二进制解释为十进制14,查询指令表,内存地址14对应的数据是00000011,按无符号二进制解释为十进制3
- 第四步:回写,将第三步算出的3放到寄存器A中.
至此,第一条指令执行完成,程序计数器自动+1,接下来执行地址为1的指令:
- 第一步:读取指令,地址为1的指令->数据是00011111
- 第二步:解析指令,指令前四位0001是操作码,通过查询指令表可知该二进制对应的是LOAD_B,操作数是1111->内存地址,LOAD_B的作用就是把1111这个地址的数据读取到寄存器B中.
- 第三步:执行指令,将1111地址的数据读取出来放到寄存器B中,1111按无符号二进制解释为十进制15,查询指令表,内存地址15对应的数据是00001110,按无符号二进制解释为十进制14
- 第四步:回写,将第三步算出的14放到寄存器B中.
至此,第二条指令执行完成,程序计数器自动+1,接下来执行地址为2的指令:
- 第一步:读取指令,地址为2的指令->数据是10000100
- 第二步:解析指令,指令前四位1000是操作码,通过查询指令表可知该二进制对应的是ADD,操作数是0100(4)->寄存器ID:01和00,STORE_A的作用是将寄存器01和寄存器00的值取出,求和,再放入00寄存器中.假设寄存器A的ID是00,寄存器B的ID是01,那么该指令就是将寄存器A和B的值取出,求和,再放入寄存器A中.
- 第三步:执行指令,寄存器A中值为3,寄存器B中值为14,3+14=17
- 第四步:回写,将上一步计算出的17放入寄存器A中
至此,第二条指令执行完成,程序计数器自动+1,接下来执行地址为3的指令:
-
第一步:读取指令,地址为3的指令->数据是00000000
-
第二步:解析指令,发现指令数据位0,这通常表示程序执行完成了.
通过上述4条指令,我们可以发现其实实现的就是一个加法操作,然而这对CPU来说,也并非是一件特别容易的事.
4. 操作系统
4.1 常见的操作系统
常见的操作系统有windows,Linux,Mac OS,安卓(实际上安卓内核也是基于Linux开发的,但是经过多年迭代,差异已经很大了),IOS等,这些系统在普通群众之间非常流行,还有一些小众系统,比如用于工业设备,航空航天等用途的操作系统.
在不同操作系统运行的程序大部分都是不同的,不能兼容,例如你在windows上写的程序大概率是不能直接拿到Linux等其他系统上运行的,而Java具有跨平台特性,虽然不同系统的JVM不同,但是都兼容字节码,Java程序员不必考虑系统差异.(实际上,Java的应用场景主要在安卓和服务器后端,很少会真的需要写一个程序跨不同平台执行).
4.2 操作系统的核心功能
操作系统的核心功能可以简单概括为以下几方面:
- 资源管理
- 计算机的CPU、内存、硬盘、网络等是有限的资源,而多个应用程序(进程)会竞争这些资源。操作系统就是这些资源的“超级管家”,负责公平、高效地分配它们。给软件提供稳定的运行程序
- 给软件提供稳定的运行环境
- 保护系统本身和各个应用程序不受恶意或错误程序的干扰,一个进程的崩溃不会影响操作系统和其他进程.
- 为用户提供接口
- 不能让用户和应用程序直接去操作晦涩难懂的硬件指令。操作系统提供了一层抽象的、易于使用的接口,接口主要有三种形式:
- 图形用户界面:如Windows的桌面、macOS的Finder、Linux的GNOME/KDE。
- 命令行用户界面:如Windows的CMD/PowerShell,Linux/macOS的Terminal。
- 应用程序接口:即系统调用,这是程序与操作系统交互的根本方式。
- 不能让用户和应用程序直接去操作晦涩难懂的硬件指令。操作系统提供了一层抽象的、易于使用的接口,接口主要有三种形式:
- 虚拟化
- 通过软件手段,为每个程序“变出”它独享的、统一的、无限资源的假象.
- CPU虚拟化:通过进程和线程调度,让每个程序都感觉自己在独占CPU.你同时打开音乐和浏览器,它们看起来在同时运行,这就是CPU时间片虚拟化的结果.
- 内存虚拟化:通过虚拟内存技术,让每个进程都认为自己拥有一块从0开始连续的、巨大的内存地址空间(如4GB),而实际上它们的物理内存是分散的,甚至一部分还在硬盘上。
- 通过软件手段,为每个程序“变出”它独享的、统一的、无限资源的假象.
4.3 内核
内核是操作系统的核心部分,它运行在内核态,负责管理系统的所有关键资源,上面提到的操作系统的四大功能,其具体实现最终都落在内核上.
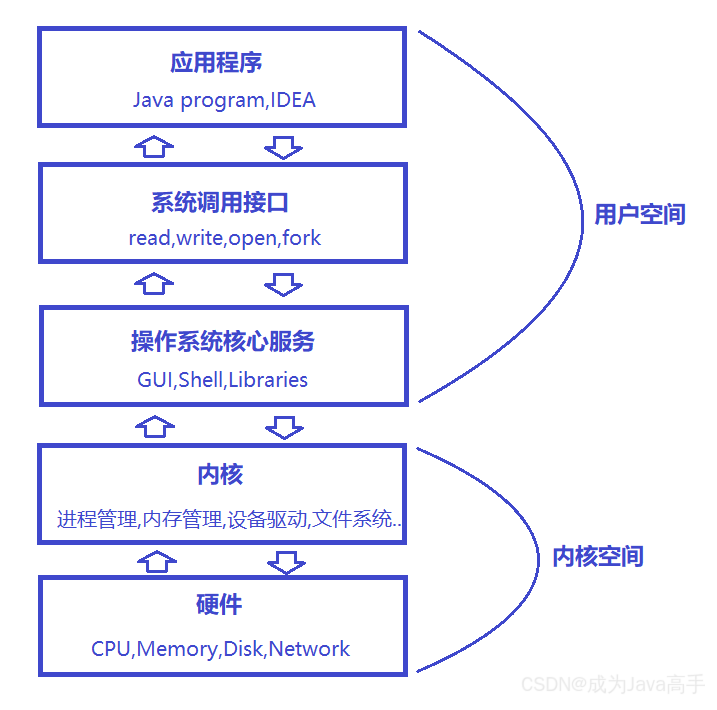
内核态 VS 用户态
内核态:CPU可以执行所有指令,可以访问所有硬件资源。内核代码运行在此态。
用户态:CPU只能执行非特权指令,无法直接访问硬件。应用程序代码运行在此态。
内核的核心功能:
-
进程管理
- 进程调度:决定下一个时间片哪个进程/线程在哪个CPU核心上运行。调度器是这里的核心组件。
- 进程间通信:提供信号、管道、消息队列、共享内存等机制,让进程之间能够安全地交换数据。
- 同步原语:提供锁、信号量等机制,防止多个进程/线程在访问共享资源时产生冲突。
-
内存管理
- 虚拟内存管理:为每个进程维护一张“地图”——页表,将进程的虚拟地址映射到物理地址。
- 内存分配和回收:当程序调用
malloc()或Java的new关键字时,最终是由内核来分配实际的物理页。 - 页面置换:当物理内存不足时,决定将哪些内存页换出到磁盘的交换分区/文件。
-
设备驱动与I/O管理
- 设备驱动:包含了控制特定硬件的代码。驱动是内核的一部分,或以内核模块的形式加载。
- 抽象接口:为上层应用提供统一的、抽象的I/O接口(如
read,write系统调用),隐藏不同硬件的复杂细节。 - 缓冲管理:使用缓冲区来平滑CPU和I/O设备之间的速度差异。
-
文件系统管理:
- 组织数据:定义如何在磁盘上存储文件、目录名、权限、创建时间等元数据。
- 提供操作接口:实现
open,read,write,close等文件操作的系统调用。 - 虚拟文件系统:提供一个抽象层,使得上层应用可以用统一的方式访问不同格式的文件系统
-
系统调用与中断处理
- 系统调用:当应用程序需要内核提供服务时(如创建进程、读写文件、申请内存),它执行一条特殊的指令(如
syscall)来“陷入”内核。内核验证请求后,代表应用执行操作,最后返回结果。 - 中断处理:当硬件设备需要CPU注意时(如网络包到达、磁盘读写完成),会发出一个中断信号。CPU会立即暂停当前工作,转而执行内核中对应的中断处理程序。这是异步I/O和事件驱动的基石。
- 系统调用:当应用程序需要内核提供服务时(如创建进程、读写文件、申请内存),它执行一条特殊的指令(如
5. 进程
一个应用程序,在没有运行时是位于硬盘上的exe文件,当你双击exe运行时,该文件就会被加载到内存中,执行CPU中的指令,此时的程序就是一个进程.进程是操作系统进行资源分配的基本单位.
操作系统的内核的核心功能之一就是进程管理.
5.1 进程管理
- 进程的描述:通过结构体/类,把进程的各种属性表示出来
- 进程的组织:通过多种链表或队列(如就绪队列、设备等待队列)将所有的PCB(进程控制块)组织起来,方便内核进行管理。
简单来说,就是通过链表的方式把PCB串到一起.运行程序就相当于创建了一个PCB结构体,并且插入到链表中;销毁进程就是把PCB从链表上删除,并且释放掉这个PCB结构体;查看进程列表就是在遍历这个列表,依次显示出对应的信息
5.2 PCB
PCB 是操作系统为了管理和描述一个进程而创建的数据结构。
PCB是个非常复杂的结构体,包含的属性非常多,此处只讨论一些关键信息.
- PID=>进程的标识符,同一时刻一个机器上不同进程的PID一定是唯一的,没有重复
- 内存指针=>描述进程依赖的指令和数据都存在内存的哪个区域.(侧面表现出,进程的执行需要一定的内存资源)
- 文件描述符=>描述进程打开了哪些文件(侧面表示出,进程的执行,需要一定的硬盘资源)
- 进程状态=>记录进程时RUNNABLE,RUNNING,BLOCKED还是DEAD
- 进程优先级=>根据优先级的高低来进行先后调度
- 进程上下文=>进程在执行中,某一时刻所处的状态和环境的集合,它包含了进程恢复运行所需的所有信息.
- 进程的记账信息=>记录进程占用的CPU时间,实际使用的内存等,用于统计和调度