USP-(DeepSpeed-Ulysses-Attention and Ring-Attention)
目前在做Dit相关工作,看到xDit框架中的USP策略很不错,记录一下,有问题欢迎批评指正,正在更新中...
进入大模型时代,如何训练和推理超长序列上下文成为大家关注的焦点,23年出现了DeepSpeed-Ulysses-Attention 和 Ring-Attention,24年USP又将其组合起来,并在xDit框架中实现,下面详细解释下三种方法,并参考xDit的源码对USP进行详细解释。
DeepSpeed-Ulysses-Attention
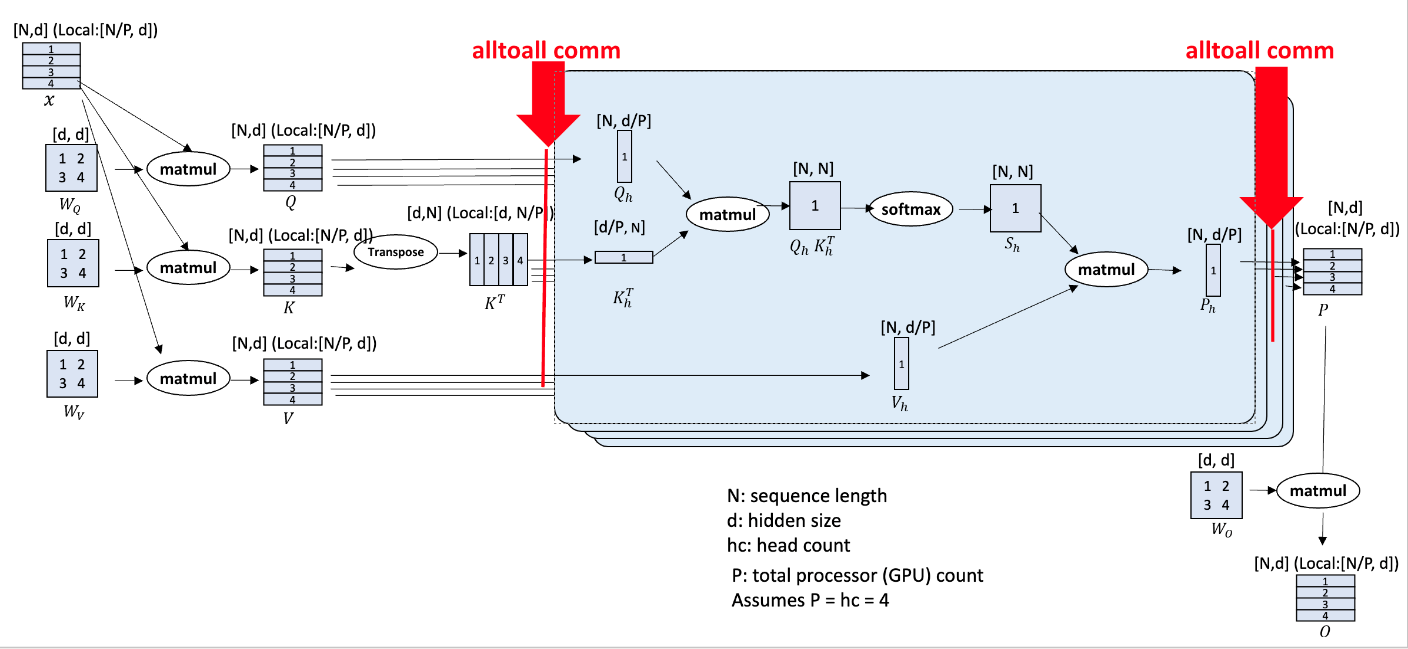
首先输入序列x在N维度上被切为P份,分别加载到对应的GPU上,这里简单假设有P个GPU,然后x与、
、
权重矩阵matmul得到QKV矩阵,K矩阵再做转置,所有GPU进行一次alltoall通信,每一个GPU就得到了全部的QKV矩阵,然后在d维度进行切分,而且切分时期望在hc维度进行切分, 也就是这里限制hc需要被P整除,将每个head均匀分布到每个GPU上,以便于每个GPU上都能进行完整的Attention计算,从而可以使用FlashAttention等技术进行单卡内的加速;
按照d维度切分完成后,就是进行Attention计算了,计算完成之后需要再进行一次alltoall通信,每个GPU又拿到了全部的result矩阵,然后再按照N切分,平均分到每个GPU上,最后乘;
可以看出,这里限制就在于 hc%P == 0 ;对于GQA和MQA模型不太友好。
Ring-Attention
总体是FlashAttention的思想,并采用online softmax,让计算与通信折叠;
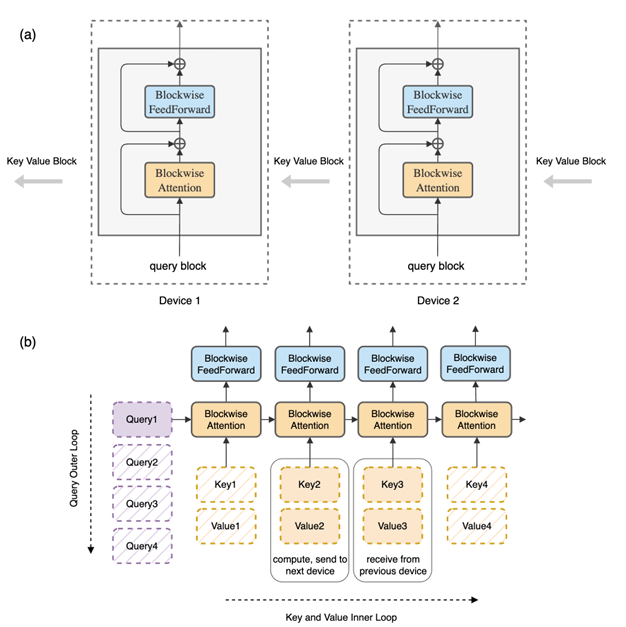
对于Q1来说,每个卡上都存在,对于KV来说,每个卡都维护一部分的KV,当完成Attention计算之后,将当前的KV发送给下一张卡,同时接受上一张卡的KV,知道所有的KV都遍历完成,这里进行设计可以在计算KV的同时进行KV的通信,从而实现通信计算掩盖,使得每个卡上都像有全部的KV矩阵一样,然后进行Q2,以此类推,这里Q就作为外层循环,KV作为内层循环。
USP-Unified Sequence Parallelism
将上面2种方案协同融合,同时克服并行度<=num_head的限制,和避免P2P低效带宽利用
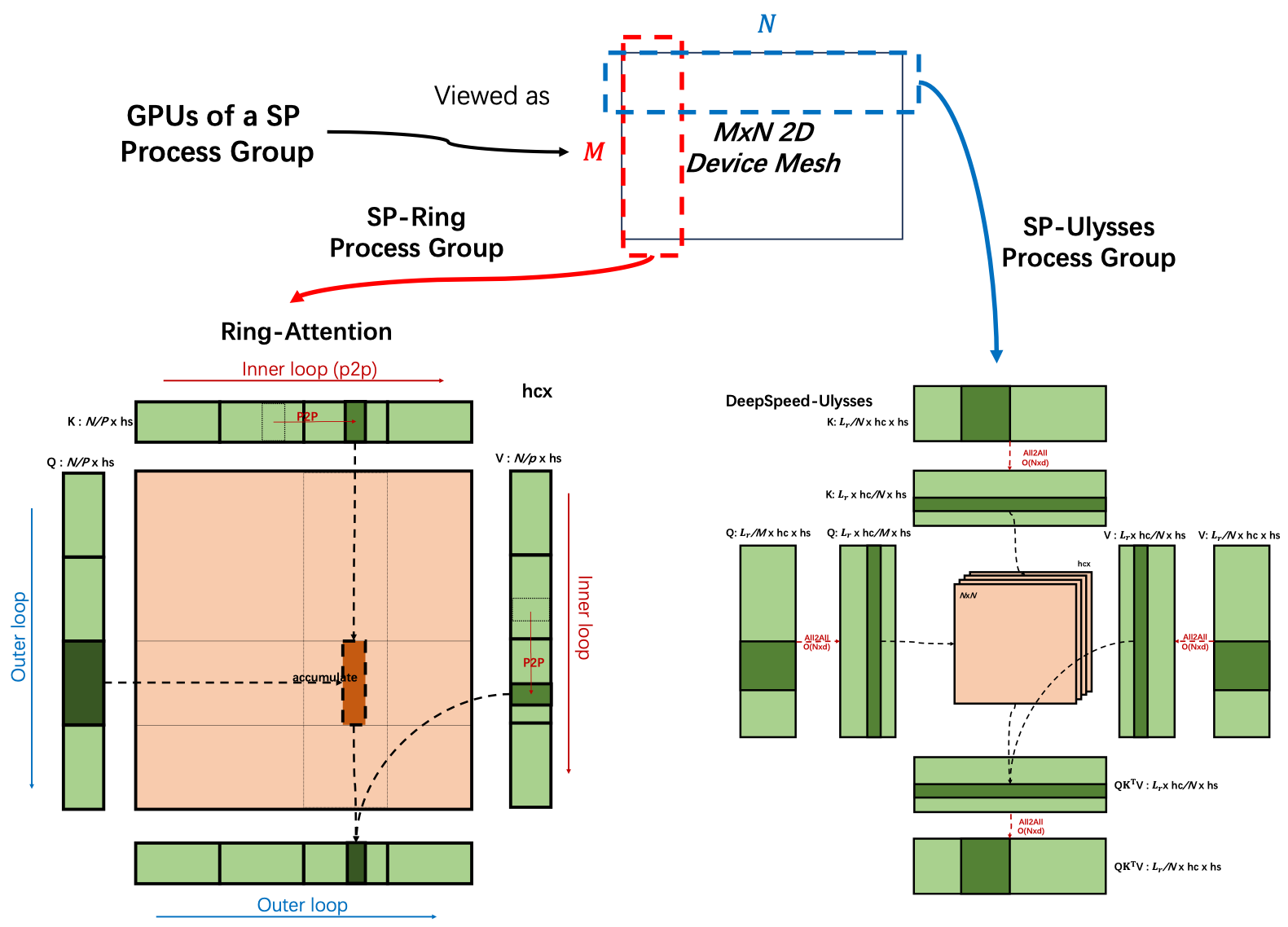
参考:
[2405.07719] USP: A Unified Sequence Parallelism Approach for Long Context Generative AI
[2310.01889] Ring Attention with Blockwise Transformers for Near-Infinite Context
DeepSpeed/blogs/deepspeed-ulysses/media/image3.png at master · deepspeedai/DeepSpeed
(57 封私信 / 15 条消息) 大模型训练之序列并行双雄:DeepSpeed Ulysses & Ring-Attention - 知乎
(57 封私信 / 21 条消息) 图解大模型训练系列:序列并行3,Ring Attention - 知乎