(论文速读)InteractVLM: 基于2D基础模型的3D交互推理
论文题目:InteractVLM: 3D Interaction Reasoning from 2D Foundational Models(基于2D基础模型的3D交互推理)
会议:CVPR2025
摘要:我们介绍了一种新的方法InteractVLM,它可以从单个野外图像中估计人体和物体上的三维接触点,从而实现精确的人体-物体关节三维重建。由于遮挡、深度模糊和物体形状的广泛变化,这是具有挑战性的。现有的方法依赖于通过昂贵的动作捕捉系统或繁琐的手动标记收集的3D接触注释,限制了可扩展性和泛化。为了克服这个问题,InteractVLM利用大型视觉语言模型(vlm)的广泛视觉知识,对有限的3D接触数据进行微调。然而,直接应用这些模型并非易事,因为它们“只能”在2D中进行推理,而人与物体的接触本质上是3D的。因此,我们引入了一种新颖的“渲染-定位-提升”模块:(1)通过多视图渲染将3D物体和物体表面嵌入到2D空间中,(2)训练一种新的多视图定位模型(MV-Loc)来推断2D中的接触,(3)将这些提升到3D。此外,我们提出了一个新的任务,称为语义人类接触估计,其中人类接触预测明确地以对象语义为条件,从而实现更丰富的交互建模。InteractVLM在接触估计方面优于现有的工作,并且还有助于从野外图像进行3D重建。为了估计3D人体和物体姿态,我们推断初始身体和物体网格,然后通过InteractVLM推断两者上的接触,最后利用这些网格拟合图像证据。结果表明,我们的方法在野外表现良好。
代码和模型可在https://interactvlm.is.tue.mpg.de上获得。
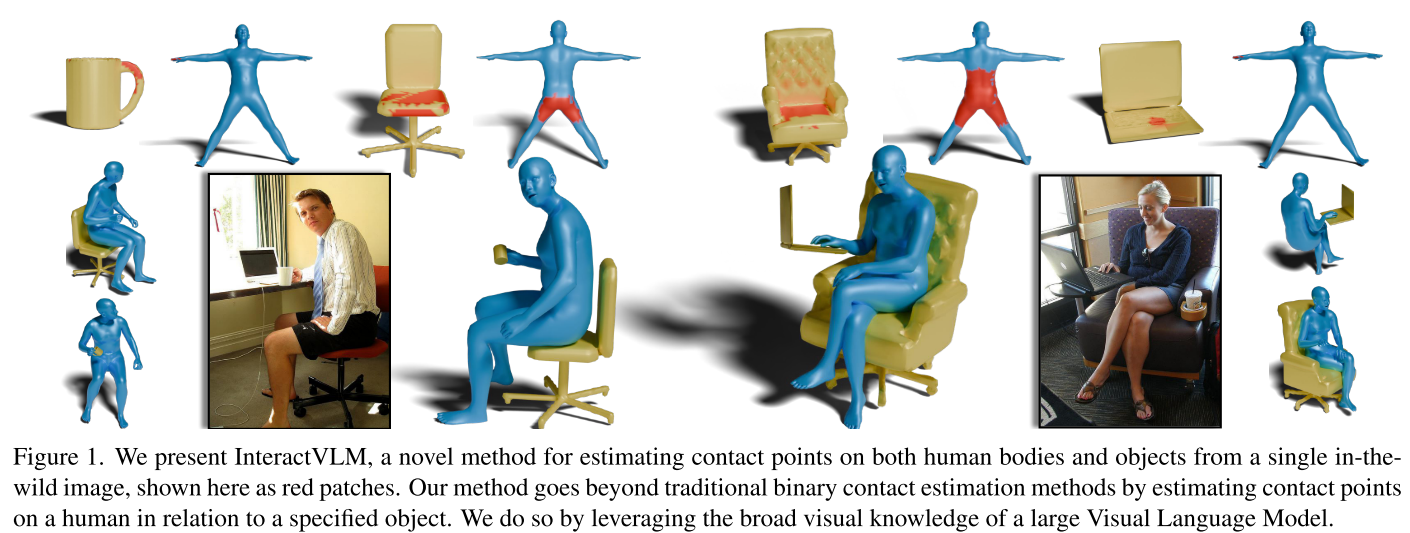
当AI学会"触摸":InteractVLM如何理解人与物体的交互
想象一下,给AI看一张你坐在椅子上用笔记本电脑的照片,它不仅能识别出你和这些物体,还能精确告诉你哪只手在触摸键盘,哪部分身体在接触椅子。这不是科幻,而是CVPR 2025上InteractVLM带来的突破。
🎯 为什么这个问题很重要?
人类每天都在与无数物体交互——握手机、坐椅子、拿杯子。对于机器人、混合现实、人机交互等应用,理解这些交互至关重要。但从单张照片重建3D人-物交互极具挑战:
- 遮挡问题:手可能被物体挡住
- 深度模糊:2D图像缺乏深度信息
- 数据稀缺:获取3D接触标注需要昂贵的动捕系统
💡 核心创新:让2D基础模型做3D推理
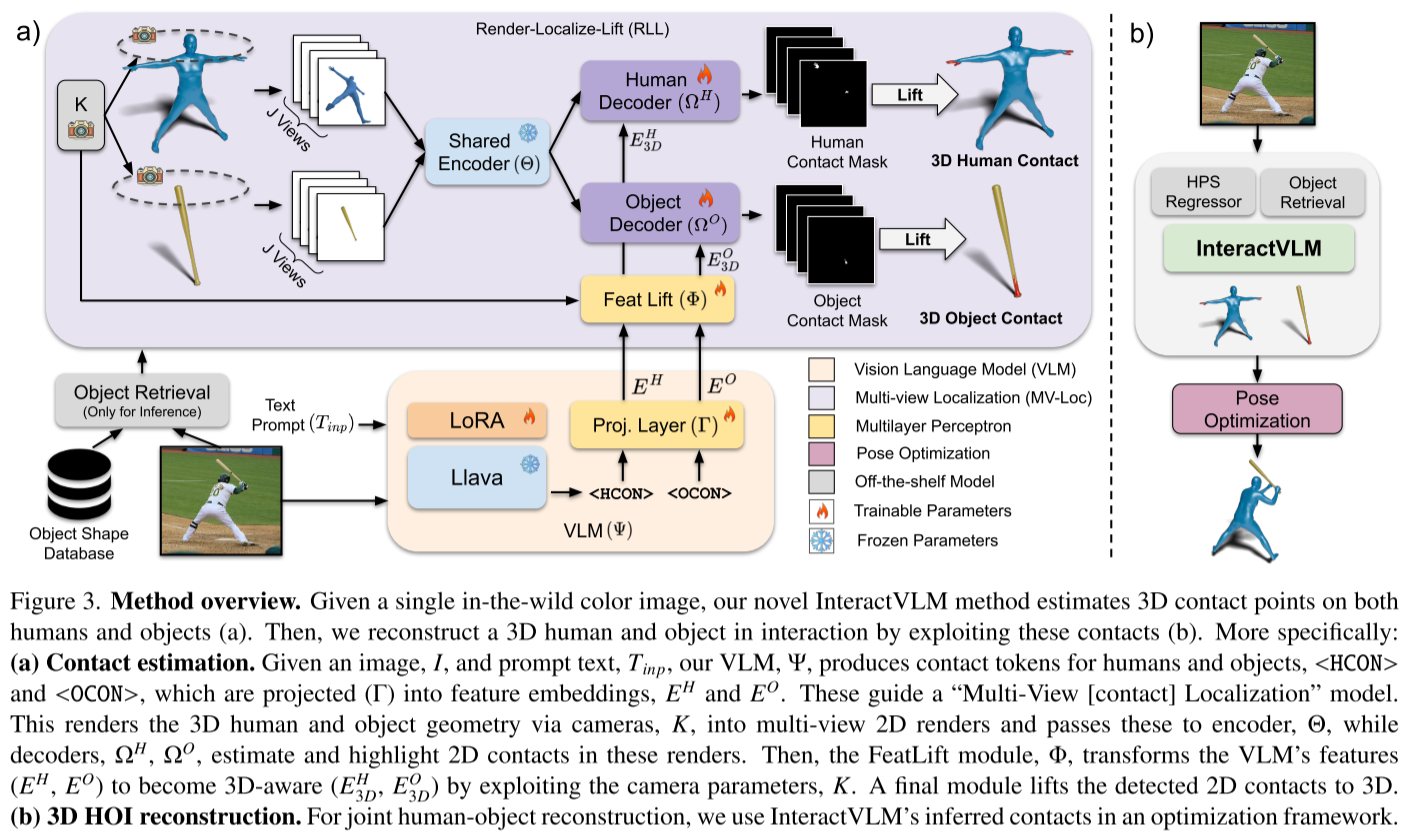
InteractVLM最巧妙之处在于借用VLM的"常识"。研究团队观察到:
大型视觉-语言模型在互联网规模数据上训练,已经"见过"无数人类交互的例子。即使它们只能在2D推理,这种常识知识也极具价值。
但如何让只会2D推理的模型解决3D问题?答案是**"Render-Localize-Lift"框架**:
🔄 三步走策略
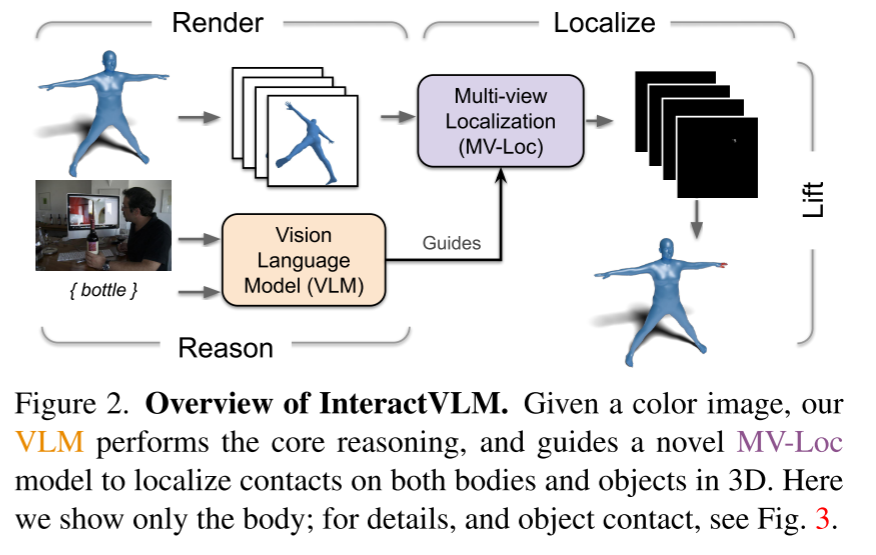
3D几何体 → (Render) → 多视图2D渲染 → (Localize) → 2D接触掩码 → (Lift) → 3D接触点
1. Render(渲染)
- 将3D人体(SMPL+H模型)和物体从多个角度渲染成2D图像
- 使用法线着色使渲染图看起来像真实图像
2. Localize(定位)
- VLM生成"推理token"(<HCON>和<OCON>)指导接触定位
- 关键创新:FeatLift模块将VLM的2D特征"提升"为3D感知特征
- MV-Loc模型确保多视图一致性
3. Lift(提升)
- 通过反向投影将2D接触掩码提升回3D
- 因为知道原始3D几何体,2D点可以精确映射到3D表面
🆕 新任务:语义人体接触
传统方法只回答"这个身体部位接触了东西吗?"
InteractVLM能回答"这个身体部位接触了哪个物体?"
这在现实场景中至关重要。想象你坐在咖啡厅:
- 臀部和背部接触椅子
- 双手接触笔记本键盘
- 杯子接触桌面
传统方法会混淆这些接触,而InteractVLM能精确区分。
📊 令人惊叹的数据效率
最震撼的结果来自数据效率实验:
- 仅用1%训练数据,InteractVLM达到F1=0.53
- 而DECO使用100%数据只达到0.55
- 用5%数据就超越了DECO
这意味着什么?大幅降低标注成本! 原本需要1000张标注图像,现在只需50张就能达到更好效果。
🏆 性能表现
二元接触估计(DAMON数据集)
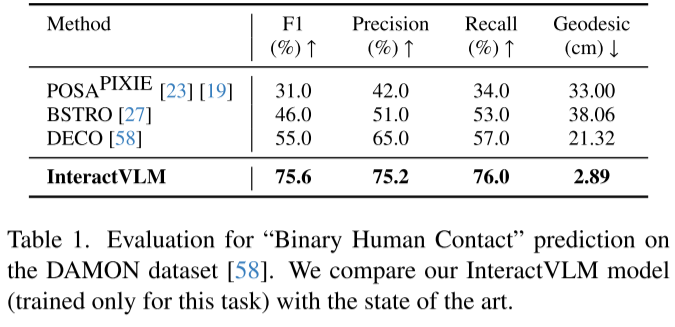
- F1分数:75.6%(提升20.6%)
- 测地距离:2.89cm(原21.32cm)
语义接触估计(新任务)

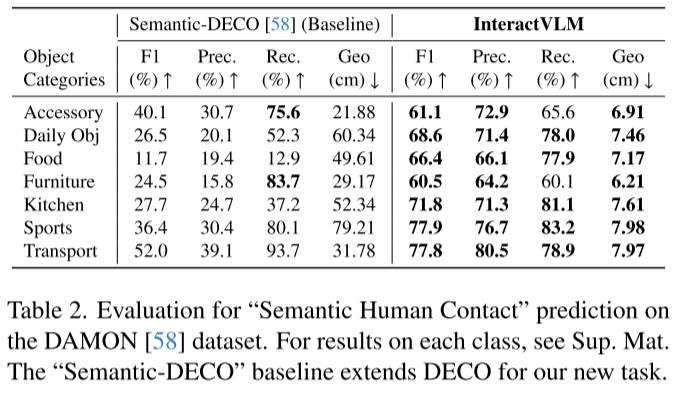
- 运动器材:77.9%(基线36.4%)
- 交通工具:77.8%(基线52.0%)
物体负担性预测(PIAD数据集)
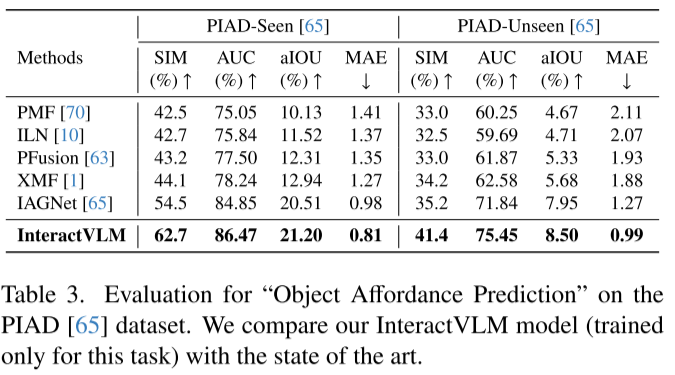
- 已见物体:62.7%(SotA 54.5%)
- 未见物体:41.4%(SotA 35.2%)
🎨 实际应用:3D重建

论文展示了如何用推断的接触点重建3D人-物交互:
- 初始化:用OSX估计人体姿态,用OpenShape检索物体
- 对齐:用ICP算法将物体接触点对齐到人体接触点
- 优化:联合优化物体姿态、掩码匹配和接触约束
用户研究显示,62%的受试者更喜欢InteractVLM的重建结果。
🔧 技术架构亮点
VLM部分
- 基于LLaVA,用LoRA高效微调
- 扩展词汇表增加特殊token
MV-Loc部分
- SAM作为分割基础
- 共享编码器 + 独立人体/物体解码器
- FeatLift网络实现3D感知
损失函数设计
- Focal Loss + Dice Loss:处理稀疏接触区域
- 3D一致性损失:确保多视图协调
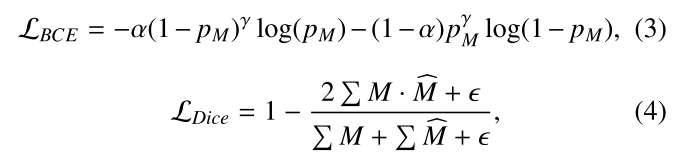
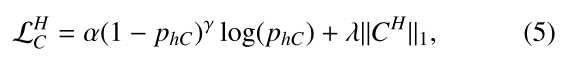
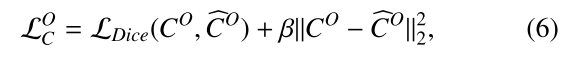
💭 研究启示
InteractVLM的成功揭示了几个重要趋势:
- 基础模型的迁移潜力:通过巧妙设计,2D模型可以解决3D问题
- 数据效率革命:常识知识能大幅减少标注需求
- 任务重定义的价值:从二元到语义接触,更符合现实需求
🚀 未来展望
虽然InteractVLM已经很强大,但仍有提升空间:
- 实时性能:多视图渲染和优化需要加速
- 极端遮挡:严重遮挡场景的鲁棒性
- 动态交互:从静态图像扩展到视频序列
- 物理合理性:引入物理约束确保重建合理
📚 总结
InteractVLM代表了视觉理解的一个重要进展——不仅识别"是什么",还理解"如何交互"。通过创造性地结合大型基础模型的常识知识和精心设计的3D推理模块,它在数据稀缺的情况下达到了令人印象深刻的性能。
这项工作为机器人学、AR/VR、人机交互等领域打开了新的可能性。想象未来的机器人能像人类一样理解物体如何被使用,AR眼镜能实时理解你的手势与物体的交互——InteractVLM正是通往这个未来的重要一步。