【项目与八股】复习整理笔记
【项目与八股】复习整理笔记
- 智能安防监控系统
- 工厂模式与观察者模式
- RKMPI库的视频处理RTSP、LCD、OSD、PTZ、Onvif
- V4L2
- LCD
- 线程安全队列
- 环形缓冲区
- CAS原子操作
- SPSC队列
- MPMC无锁队列
- OSD叠加
- 云台追踪
- onvif协议总结
- RTSP协议总结
- RTP包结构
- 视频封装(以H.264为例)
- 视频编码器 Video Encoder
- 视频卡顿花屏 GOP
- QT客户端
- MVVM
- 线程池的设计
- 线程池整体工作流程
- 设计细节与常考问题
- 概念问题
- 同步与互斥
- FFmpeg
- 智能家居项目
- C语言的面向对象编程
- 单例模式
- hash_map
- 自定义堆区动态内存配置机制
- epoll并发服务器
- 环形缓冲区与粘包问题
- xv6操作系统内核
- 系统调用
- 页表
- 惰性分配与缺页
- 大文件与软链接
- 线程切换实现用户态协程
- C语言
- 指针 数组 函数 常量
- 大端序、小端序
- 内存对齐
- C语言关键字 staic const extern volatile预处理
- sizeof 与 strlen
- malloc与calloc的区别
- 数组与链表的区别
- 栈与队列的区别
- 使用指针需要注意什么?
- 野指针、段错误
- 内存泄漏
- 内存管理
- 内存分布模型
- C语言堆栈分区理解与区别
- 内存碎片
- 分段、分页、段页式、请求式分页
- 内存池
- 虚拟内存与页表
- 虚拟内存的好处
- 页表的作用是什么?
- 地址映射
- 缺页异常与置换
- 缺页中断
- 中断和异常的区别
- 页面置换算法
- LRU算法
- 文件访问方式
- C++
- new/delete/delete[]与malloc/free的区别,allocator
- 指针与引用的区别
- const关键字的使用
- static关键字的用处
- 面对对象的三大特性
- 菱形继承
- 多态
- vector动态数组
- 迭代器失效问题
- 深拷贝与浅拷贝
- inline
- 类的大小
- C++内存泄漏有哪些
- STL
- 红黑树/B树与B+树
- C++11新特性
- 左值与右值及右值引用
- C++类型转换
- 函数模板与模板函数
- function/lambda/bind
- 类型推导
- 智能指针
- 进程
- 进程与线程的区别
- 进程的控制
- 进程和线程的创建与结束
- 进程的创建
- 进程的结束
- 线程的创建
- 线程的结束
- 线程栈
- 默认栈
- 进行线程切换的区别
- 僵死守护孤儿
- fork的作用
- fork与vfork的区别
- 父进程创建子进程,有哪些资源共享
- 进程间通信
- 进程的调度机制
- Linux内核中的调度
- 线程
- 互斥锁、信号量、自旋锁
- Futex机制
- 读写、条件变量
- 死锁
- 用户线程和内核线程
- 操作系统
- 用户态和内核态
- 上下文
- 动态库与静态库的区别
- 软链接与硬链接
- DMA技术
- 计算机网络
- TCP与UDP的区别
- 接收数据包流程
- 宕机是否丢失
- 三次握手 四次挥手相关
- 判断断开
- TCP可靠机制
- TCP粘包/半包现象
- TCP的ACK机制,有什么好处?
- TIME_WAIT
- 长短连接、全连接、半连接
- socket编程
- HTTP与HTTPS
- 常用的指令
- Linux常用指令
- git、cmake、makefile
- 文件系统
- 文件系统的组成
- 文件系统的结构
- 虚拟文件系统
- 连续空间存储
- 非连续空间存储
- 空闲空间管理
- 空闲表法
- 空闲链表法
- 位图法
- 目录的存储
- 软链接和硬链接
- Linux内核与驱动
- Linux操作系统在开发板的启动流程
- Linux内核结构框图
- Bootloader的两个阶段的启动过程。
- linux的内核是由bootloader装载到内存中的?
- 为什么需要BootLoader
- bootloader内核和根文件的关系
- 系统调用read()/write(),内核具体做了哪些事情?
- 内核态,用户态的区别
- 树莓派Linux源码配置
- 移植内核至树莓派
- 字符设备驱动
- 单片机
- IIC SPI UART的区别
- 键盘敲入字母A时,发生了什么
- 一帧数据的传递
- 输入URL到页面展示发生了什么
- 有了IP地址如何找到对端
- 动态路由协议有哪些
- 外部网关协议 - BGP
- 内部网关协议OSPF,ISIS,RIP
- BGP
- 基础概念
- BGP建邻
- 路由属性与策略
智能安防监控系统
-
难点1: 项目的框架搭建,各模块的解耦合,各模块间的数据传输,使得具备高扩展性,添加模块功能方便,同时模块机的数据传输耦合度降低
-
QT界面: 代码设计与业务逻辑的分离,降低耦合度,信号传输深度过深
-
难点2: 摄像头的视频采集、编码、传输功能的实现以及视频出现的花屏卡顿,LCD显示屏的驱动与显示,
-
QT界面的视频编解码: 通过ffmpeg库对视频进行编解码,对视频的接收,环形缓冲区,16路视频解码,窗口的不断创建与释放,对象池
-
难点3: Onvif协议的应用与接口的封装
-
移植到RK3588,交叉编译QT库,ffmpeg库,以及后面利用硬件GPU加速进行对图像进行解码操作
-
摄像头视频采集与传输,利用RKMPI库,API文档,官方app例程,移植一些功能函数模块与流程
-
添加功能模块,舵机PT控制,LCD显示,onvif协议,降低系统的耦合度的集成与扩展,无参考,网络框架学习与参考源码
-
RV1106 是一款专门用于人工智能相关应用的高度集成 IPC 视觉处理器 SoC。它基于单核 ARM Cortex-A7 32 位内核,集成了 NEON 和 FPU,并内置 NPU 支持 INT4 / INT8 / INT16 混合运算,RV1106G2 计算能力高达 0.5TOPS,RV1106G3计算能力高达 1TOPS
工厂模式与观察者模式
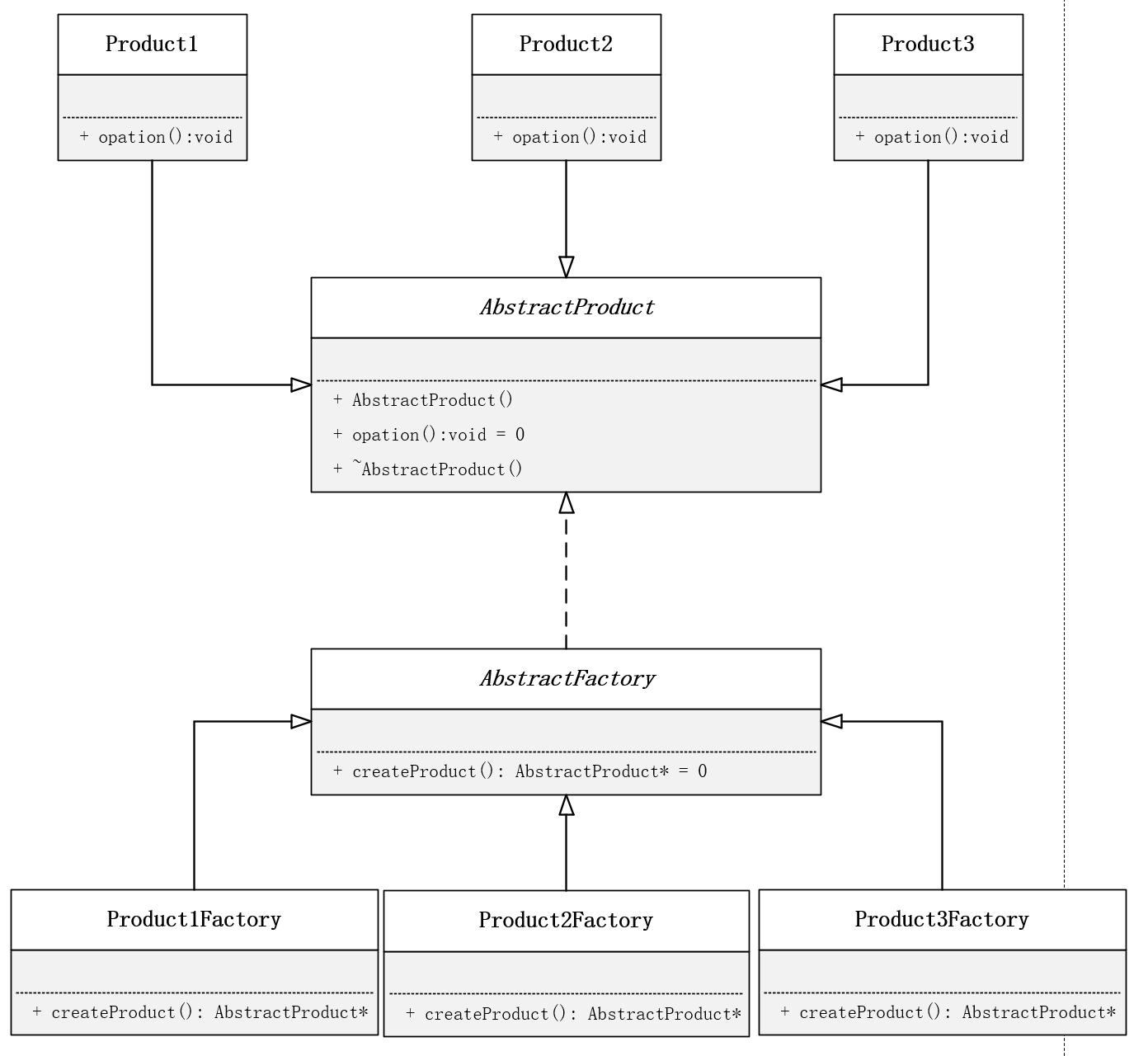
工厂模式: 设计基类工厂,各个模块的具体工厂创建对应的每一个类,最后通过基类指针访问每个具体工厂创建的对象
简单工厂模式与工厂模式的区别:
简单工厂模式是只有一个工厂类,而工厂模式是有很多的工厂类:
- 工厂模式:
- 一个基类,包含一个虚工厂函数,用于实现多态。
- 多个子类,重写父类的工厂函数。每个子工厂类负责生产一种产品的实例对象,这相当于再次解耦,将工厂类的职责再次拆分
通过基类指针实现运行时多态,统一管理不同视频流处理方式
采用抽象工厂模式(VideoStreamFactory)来创建具体的视频流对象,提高系统的可扩展性,这种设计实现了:
- 接口统一化:通过基类规范所有视频流处理的操作
- 功能模块化:各子类专注实现特定功能
- 扩展灵活性:新增处理方式只需添加新子类
- 创建解耦:工厂模式隔离对象创建和使用

观察者模式:
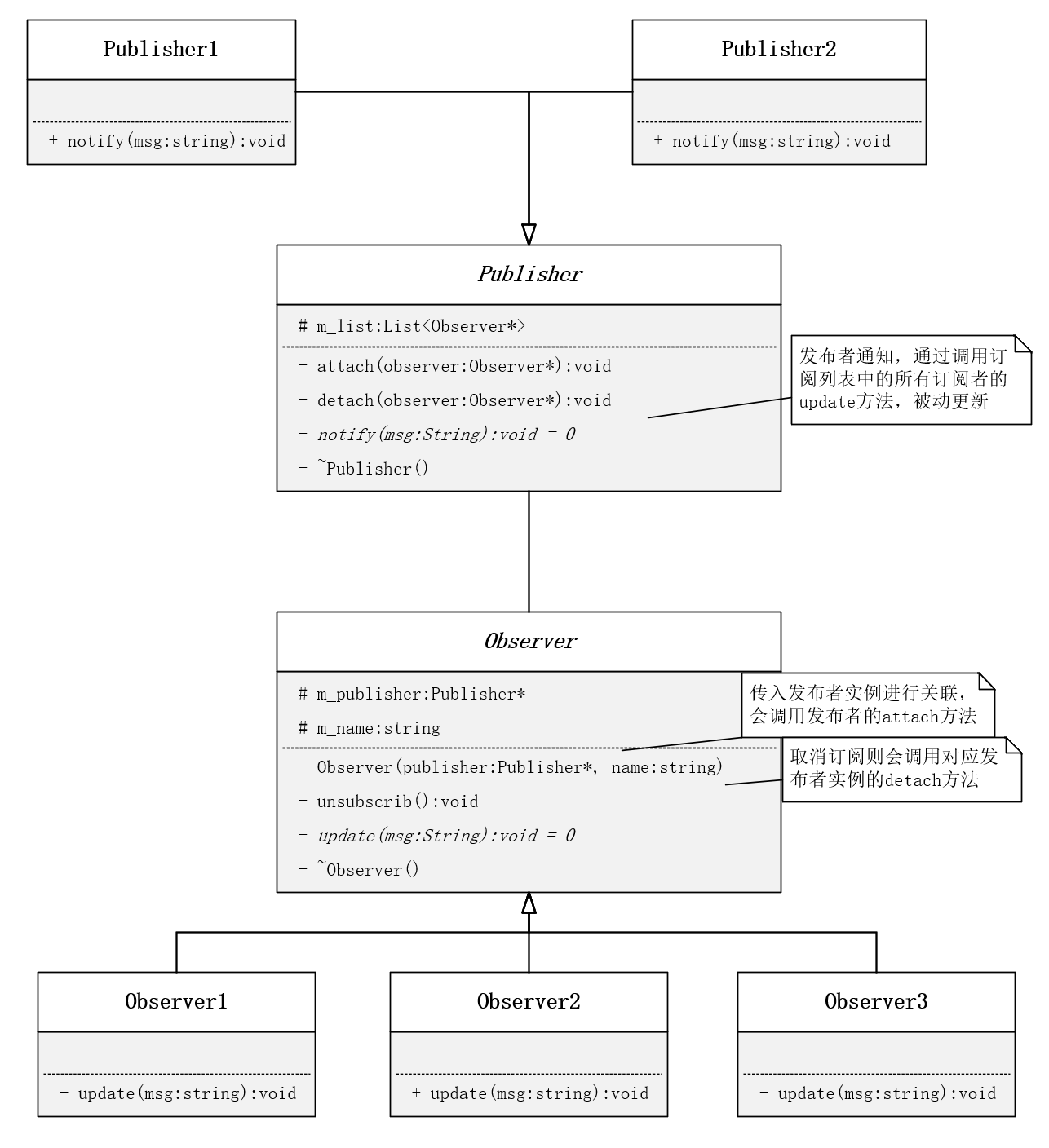
class Publisher
{
public:Publisher();virtual ~Publisher() {} // 基类,虚析构,多态时能通过基类指针析构各个子类的析构函数// 1. 添加订阅者void attach(Observer* observer) {m_observers.push_back(observer);}// 2. 删除订阅者void detach(Observer* observer) {m_observers.remove(observer);}// 3. 通知订阅者 不同子类发送消息不一样,定义为存虚,要求必须重写notify函数virtual void notify(string msg) = 0; {for(const auto &observer : m_observers) {// 观察者更新数据 这句话是关键,理解是如何更新观察者的数据的,观察者的方法在下面定义,可先跳过// observer->update(msg);}}
protected:// 订阅者列表 添加删除效率高list<Observer*> m_observers;
};// 抽象观察者类
class Observer {
public:// 和发布者进行关联 - 通过构造函数实现 - 初始化列表Observer(Publisher* publisher, string name) : m_publisher(publisher), m_name(name) {m_publisher->attach(this); // 发布者添加该观察者}// 和发布者进行解除关联 - 取消订阅void unsubscribe() {m_publisher->detach(this); // 发布者取消该观察者}// 更新消息virtual void update(string msg) = 0; {cout << "Observer " << m_name << " received msg: " << msg << endl;}virtual ~Observer() {cout << "Observer " << m_name << " is destroyed" << endl;}protected:Publisher* m_publisher; // 订阅的的发布者string m_name; // 当前观察者的名字
};
优点:
- 降低了类与类之间的耦合度,把耦合关系在基类中处理
- 观察者模式实现了稳定的消息更新和传递的机制,通过引入抽象层可以扩展不同的具体观察者角色;
- 支持广播通信 ,所有已注册的观察者(添加到目标列表中的对象)都会得到消息更新的通知, 简化了一对多设计的难度;
- 符合开闭原则 ,增加新的观察者无需修改已有代码,在具体观察者与观察目标之间不存在关联关系的情况下增加新的观察目标也很方便。
缺点:
- 代码中观察者和发布者相互引用 ,存在循环依赖,观察目标会触发二者循环调用,有引起系统崩溃的风险
- 如果一个发布者有很多直接和间接观察者,将所有的观察者都通知到会耗费大量时间。
适用环境:
- 一个对象的改变会引起其他对象的联动改变,但并不知道是哪些对象会产生改变以及产生什么样的改变;
- 如果需要设计一个链式触发的系统,可是使用观察者模式;
- 广播通信、消息更新通知等场景。
虚函数与纯虚函数
使用纯虚函数
- 当你希望所有派生类都必须实现某个功能时
- 当你希望基类成为抽象类,不能直接实例化时
- 确保所有子类都实现特定接口,避免遗漏
使用虚函数的情况
- 当你希望提供一个默认实现,子类可以选择是否重写时,使用虚函数
- 当你希望子类可以选择是否重写某个函数时,使用虚函数
- 允许子类选择是否实现某个功能
RKMPI库的视频处理RTSP、LCD、OSD、PTZ、Onvif
面试简答版: 视频采集的原理是:摄像头传感器把光信号转成电信号,经 ISP 处理后通过接口传给主机。软件侧通过 V4L2 驱动访问 /dev/videoX 设备节点,使用环形缓冲区管理采集到的帧,应用程序再进行显示、编码或传输。整个过程核心是“驱动采集—缓冲区交互—应用处理”的循环
V4L2
V4L2:
用户空间:┌──────────────────────────────────────┐│ while(1): ││ DQBUF → 取帧 ││ 处理数据(显示/编码/发送) ││ QBUF → 重新入队 │└──────────────────────────────────────┘↑ ↓
内核驱动:┌──────────────────────────────────────┐│ 驱动 DMA 写入缓冲帧 ││ 中断通知帧完成 ││ 管理缓冲队列状态 │└──────────────────────────────────────┘
V4L2 常用控制接口
| 步骤 | 调用接口 | 说明 |
|---|---|---|
| 1. 打开设备 | open() | /dev/videoX |
| 2. 查询能力 | VIDIOC_QUERYCAP | 检查是否支持视频采集 |
| 3. 设置格式 | VIDIOC_S_FMT | 分辨率、像素格式 |
| 4. 申请缓冲 | VIDIOC_REQBUFS | 分配队列缓冲 |
| 5. 映射缓冲 | VIDIOC_QUERYBUF + mmap | 映射到用户空间 |
| 6. 启动采集 | VIDIOC_STREAMON | 开始视频流 |
| 7. 获取帧 | VIDIOC_DQBUF / VIDIOC_QBUF | 不断采集帧 |
| 8. 停止采集 | VIDIOC_STREAMOFF | 释放资源 |
在 V4L2 中,重新入队(VIDIOC_QBUF)是为了:
✅ 让驱动重新使用这块缓冲区采集下一帧数据。
如果不重新入队会怎样?
如果用户只出队 (DQBUF),不再入队 (QBUF),那么:
- 驱动缓冲区会越用越少;
- 最后没有空闲缓冲区;
- 驱动无法继续采集新帧;
VIDIOC_DQBUF调用将阻塞(等待新帧但永远不会来)。
结果就是:
📉 画面卡死、帧率掉为 0。
| 问题 | 答案 |
|---|---|
| V4L2 怎么知道哪些缓冲可用? | 每个缓冲区有状态机(IDLE、QUEUED、ACTIVE、DONE),驱动自动管理 |
| 谁是生产者?谁是消费者? | 驱动(生产者)采集帧,用户(消费者)处理帧 |
| 多线程怎么保护? | 内核用自旋锁/mutex保护 vb2 队列,用户用 mutex + 条件变量同步 |
| 为什么环形? | 使用索引循环复用缓冲,提高采集效率并实现零拷贝 |
视频采集-编码-传输:
采集:
-
RKMPI_SYS_INIT()
-
SAMPLE_COMM_ISP_INIT():启动ISP 算法实现自动校正与增强,坏点修复(修复死点)、白平衡、曝光控制、自动增益控制、色彩校正等操作,保证捕获图像的质量
-
vi_dev_init:启动VI设备,配置设备属性,绑定管道,
- 帧率:每秒采集多少帧图像
- 码分辨率:图像的大小
-
编码器初始化:获取编码器属性,通道,编码类型,VPSS 通道,格式
- 空间冗余,时间冗余,信息熵冗余
-
RTSP实例,创建接口,设置RTSP属性,同步时间戳
调用瑞芯微的RKMPI库,实现视频的采集、编码与RTSP传输,我的任务是设计了三路视频码流,分别实现RTSP推流,本地LCD显示,以及一路低帧率码流用于AI识别,三路线程的视频处理,同时搭建onvif服务端与QT客户端进行数据传输。
LCD
-
修改设备树,添加TFT节点
dts文件
- LCD相关配置关: 1. 包括背光控制(LCD_BL)、数据/命令选择(LCD_DC)、复位信号(LCD_RES)。 2. 使用GPIO引脚实现对LCD显示屏的控制
- 引脚控制器(Pinctrl)配置: 配置了具体的GPIO引脚功能,包括背光、数据/命令选择、复位信号以及SPI控制器的引脚。
- SPI控制器配置: 启用SPI0控制器,并定义了相关的引脚组和设备节点。
dtsi文件
- 模块功能概述:主要定义了SPI控制器(spi0)及其相关的设备节点配置,包括一个通用SPI设备(spidev@0)和一个LCD显示屏驱动(fbtft@0)
-
SPI控制器配置:引脚组配置、地址单元和大小单元、通用spi节点配置
- LCD显示屏驱动配置:屏幕兼容性、基本配置、高级配置,GPIO配置
线程安全队列
1. 什么是线程安全队列
线程安全队列是一种能够在多线程环境下安全使用的队列数据结构。在多线程环境中,多个线程可能会同时对队列进行插入和删除操作,如果不进行适当的同步控制,可能会导致数据不一致、竞争条件或死锁等问题。它通过同步机制(如互斥锁、条件变量、原子操作等)来防止多个线程同时修改队列的状态,从而避免数据竞争和不一致的问题。
2. 线程安全队列的实现方式
- 使用互斥锁: 使用互斥锁保护队列的插入和删除操作,确保同一时间只有一个线程可以修改队列
- 使用读写锁: 使用读写锁允许多个线程同时读取队列,但写操作是独占的
- 使用无锁算法: 使用原子操作(如CAS操作)实现无锁队列,避免使用互斥锁,提高并发性能。
3. 线程安全队列的应用场景
- 生产者-消费者问题:多个生产者线程将数据放入队列,多个消费者线程从队列中取出数据进行处理。示例:任务调度、消息队列系统。
- 并发任务处理: 在多线程环境中,多个线程可以安全地将任务放入队列,其他线程从队列中取出任务执行。示例:线程池中的任务队列。
- 异步编程: 在异步编程模型中,线程安全队列用于存储待处理的事件或请求。
示例:事件循环中的任务队列。 - 缓存系统: 线程安全队列用于管理缓存中的数据,确保多线程环境下的数据一致性。示例:LRU 缓存。
4. 线程安全队列的注意事项
- 性能开销: 同步机制(如互斥锁)会引入一定的性能开销,特别是在高并发环境下。
- 死锁风险: 不正确的锁使用可能导致死锁,需要谨慎设计锁的获取和释放顺序。
- 公平性: 一些同步机制(如互斥锁)可能不保证公平性,导致某些线程长时间无法获取锁。
- 内存管理: 在实现线程安全队列时,需要注意内存的分配和释放,避免内存泄漏。
5. 常见的线程安全队列实现
- C++ STL 中的 std::queue:std::queue 本身不是线程安全的,但可以通过组合使用 std::mutex 和 std::condition_variable 来实现线程安全队列。
- C++11 中的 std::atomic:使用原子操作实现无锁队列,提高并发性能
环形缓冲区
RingBuffer,中文名是环形缓冲区,也被叫做循环缓冲区 ,从名字就能看出它的独特之处。简单来说,它是一种固定大小、头尾相连的缓冲区,通过头尾指针实现 “环形” 复用空间,避免内存碎片。
优势: 固定大小、内存连续、无需频繁扩容、读写效率高,适合生产者 - 消费者模型
环形缓冲区如何判断 “满” 和 “空”?有哪些实现方式?
- 预留一个空元素(牺牲 1 个位置),
(head + 1) % size == tail表示满,head ==tail 表示空; - 用计数器记录元素数量,
count == size为满,count == 0为空; - 用两个独立的读写指针 + 标志位区分满 / 空(if_full), 若写入后,读写索引相等说明队列已满,读取后一定不满
常见问题:
-
线程安全的环形缓冲区: 单生产者单消费者可通过原子操作实现无锁;多生产者 / 消费者需加锁或使用 CAS 等同步机制
-
读写的流程: 写操作先判断是否满,再写入并移动 tail;读操作先判断是否空,再读取并移动 head;需处理指针越界(模运算)
-
为什么大小是1024,是2的幂:
% size 运算可转化为 & (size-1),提升计算效率,尤其在嵌入式 / 高性能场景
应用场景: 传感器数据采集、音视频数据处理、多线程网络数据传输、日志缓存
缺点: 固定大小易溢出,不适合数据量动态变化大的场景;扩容困难,需重新分配内存并拷贝数据
线程安全:
- 互斥锁: 避免了竞争条件,但锁机制也有缺点,它会带来额外的开销,而且如果锁使用不当,还可能会导致死锁。
- 原子操作则是利用硬件提供的原子指令,保证对数据的操作是不可分割的,不会被其他线程打断
- 无锁数据结构则是一种更高级的解决方案,它通过巧妙的设计,避免了使用锁,从而提高了并发性能。像一些基于 CAS 算法实现的无锁 RingBuffer,在高并发场景下表现出色。但无锁数据结构的实现难度较大,需要对底层原理有深入的理解 。
解决方案:
- 单生产者单消费者场景下:头尾指针分别由生产者和消费者独立修改,通过原子变量保证可见性,无需加锁
- 多生产者多消费者场景下: 多个线程竞争读写指针,需用锁或无锁算法(如 CAS)保证操作原子性,可能引入性能开销
当多个线程同时进行读写操作时,需要通过同步机制来保证数据操作的正确性。但存在一种特殊场景:当只有一个读线程和一个写线程时,可以实现无锁的线程安全环形缓冲区。这种情况下,通过特定的指针操作设计,无需额外的锁机制就能避免数据竞争,确保读写操作的安全性。其核心思路是利用单生产者 - 单消费者模型的特性,通过指针间的逻辑关系来控制读写边界,从而在无锁情况下保证线程安全,代码如下:
#include <vector>template<typename T>
class RingBuffer
{
private:std::vector<T> elements;int head; // 写指针:指向 next 要写入的位置int tail; // 读指针:指向 next 要读取的位置bool is_full; // 用于区分满和空的状态public:RingBuffer(size_t cap) : elements(cap), head(0), tail(0), is_full(false) {}bool isEmpty() const {return !is_full && (head == tail);}bool isFull() const {return is_full;}// 总是接受新数据,必要时覆盖旧数据void push(const T& element) {// 如果缓冲区满了,移动读指针(相当于覆盖最旧的数据)if (isFull()) {tail = (tail + 1) % elements.size();}// 写入新数据elements[head] = element;head = (head + 1) % elements.size();// 更新满状态is_full = (head == tail);}bool pop(T &element) {if (isEmpty())return false; // 没有数据可读// 读取数据element = elements[tail];tail = (tail + 1) % elements.size();is_full = false; // 读取后一定不满return true;}size_t size() const {if (isFull())return elements.size();if (head >= tail)return head - tail;elsereturn elements.size() - tail + head;}size_t capacity() const {return elements.size();}
};
- tail 指针仅由读线程修改,head 指针仅由写线程修改,且始终维持单一的读写线程,不存在多个线程同时写入或同时读取的情况,因此不会产生并发写冲突。
- 不过需要注意,读写操作本身并非原子性的,读操作可能穿插在写操作过程中,反之亦然。这理论上可能引发两个问题:读线程在缓冲区为空时,可能读取到尚未写入完成的数据;写线程在缓冲区已满时,可能覆盖尚未读取的数据。
- 设计了特定的操作顺序 —— 写操作时先更新数据元素再移动 head指针,读操作时先读取数据元素再移动 tail指针 —— 这就从根本上避免了上述问题。因此,这种 RingBuffer 不仅是线程安全的,还实现了无锁设计,能获得更高的性能表现
要实现 RingBuffer 的读写操作,需要以下 4 个关键信息:
- 内存中的实际开始位置:它可以是一片内存的头指针,也可以是数组的第一个元素指针,用于确定缓冲区在内存中的起始地址。
- 内存中的实际结束位置:或者通过缓冲区实际空间大小,结合开始位置来计算出结束位置,以此定义缓冲区的边界。
- 写索引值: 在缓冲区中进行写操作时的索引值,标记下一个要写入数据的位置。
- 读索引值: 在缓冲区中进行读操作时的索引值,标记下一个要读取数据的位置。
CAS原子操作
比较并交换,通过硬件级别的原子指令,在无锁的情况下保证操作的安全性。CAS 是一个原子操作(不可被中断的操作),其目标是判断内存中的某个值是否与预期值一致,若一致则更新为新值,否则不做任何操作。
- 内存地址 V:需要操作的内存位置,读取内存地址 V 中的当前值;
- 比较currentValue与预期值 A 是否相等:
- 若相等:将内存地址 V 的值更新为新值 B,操作成功;
- 若不相等:不做任何修改,操作失败;
- 返回操作结果(成功或失败,部分实现会返回更新前的旧值)。
依赖CPU 的底层原子指令, CPU 会通过总线锁定或缓存锁定机制保证指令执行的原子性
CAS 操作失败本身不会导致程序错误或数据不一致,它仅仅是一个 “操作未成功执行” 的信号。实际行为完全由上层逻辑控制:
- 多数场景下(如原子类、无锁数据结构)会选择自旋重试,直到成功;
- 特殊场景下可能放弃操作或执行替代逻辑。
局限性:需注意的问题
ABA 问题:
- 若内存值从 A 被其他线程修改为 B,再改回 A,CAS 会误认为值未变(因为预期值 A 与当前值 A 一致),导致错误更新。
- 解决方式:引入版本号(如AtomicStampedReference),每次更新时版本号 + 1,CAS 同时比较值和版本号。
自旋开销
- 若并发冲突频繁,CAS 会陷入长时间自旋(循环重试),持续占用 CPU 资源,反而降低性能。
- 优化方式:限制自旋次数(如自适应自旋),或冲突严重时升级为锁。
只能保证单个变量的原子性
只能保证单个变量的原子性
- CAS 仅支持单个内存地址的原子操作,若需对多个变量进行原子操作,需通过其他方式(如合并变量为对象,或使用锁)实现。
SPSC队列
在 SPSC 场景中,原子操作的应用非常广泛,尤其是在实现高效的 SPSC 队列时。SPSC 队列是一种数据结构,它允许一个生产者线程将数据放入队列,同时允许一个消费者线程从队列中取出数据。由于只有一个生产者和一个消费者,因此可以使用一些特殊的技巧来实现高效的线程安全。
一种常见的实现方式是使用环形缓冲区(Circular Buffer)。环形缓冲区是一个固定大小的数组,它被视为一个环形结构。生产者和消费者通过移动指针来访问缓冲区中的数据。当生产者向缓冲区中写入数据时,它会将数据写入当前写指针指向的位置,然后将写指针向后移动一位。如果写指针到达了缓冲区的末尾,它会回到缓冲区的开头。
#include <atomic>
#include <iostream>
#include <type_traits>
#include <thread>template<typename T, size_t Capacity>
class SPSCQueue {
private:// 使用 Capacity + 1 来区分满和空状态static constexpr size_t kActualCapacity = Capacity + 1;T buffer[kActualCapacity];std::atomic<size_t> m_read_idx{0};std::atomic<size_t> m_write_idx{0};public:SPSCQueue() = default;~SPSCQueue() = default;// 禁止拷贝和赋值SPSCQueue(const SPSCQueue&) = delete;SPSCQueue& operator=(const SPSCQueue&) = delete;// 生产者线程调用:向队列中添加元素bool enqueue(const T& item) {size_t write_idx = m_write_idx.load(std::memory_order_relaxed);size_t next_idx = (write_idx + 1) % kActualCapacity;// 检查队列是否已满if (next_idx == m_read_idx.load(std::memory_order_acquire)) {return false; // 队列已满}buffer[write_idx] = item;m_write_idx.store(next_idx, std::memory_order_release);return true;}// 生产者线程调用:移动版本的入队操作bool enqueue(T&& item) {size_t write_idx = m_write_idx.load(std::memory_order_relaxed);size_t next_idx = (write_idx + 1) % kActualCapacity;// 检查队列是否已满if (next_idx == m_read_idx.load(std::memory_order_acquire)) {return false; // 队列已满}buffer[write_idx] = std::move(item);m_write_idx.store(next_idx, std::memory_order_release);return true;}// 消费者线程调用:从队列中取出元素bool dequeue(T& item) {size_t read_idx = m_read_idx.load(std::memory_order_relaxed);// 检查队列是否为空if (read_idx == m_write_idx.load(std::memory_order_acquire)) {return false; // 队列为空}item = std::move(buffer[read_idx]);size_t next_idx = (read_idx + 1) % kActualCapacity;m_read_idx.store(next_idx, std::memory_order_release);return true;}// 检查队列是否为空(仅由消费者线程调用)bool empty() const {return m_read_idx.load(std::memory_order_acquire) == m_write_idx.load(std::memory_order_acquire);}// 获取队列中元素的数量(仅由消费者线程调用)size_t size() const {size_t read_idx = m_read_idx.load(std::memory_order_acquire);size_t write_idx = m_write_idx.load(std::memory_order_acquire);if (write_idx >= read_idx) {return write_idx - read_idx;} else {return kActualCapacity - read_idx + write_idx;}}// 获取队列最大容量size_t capacity() const {return Capacity;}
};// 示例使用
int main() {SPSCQueue<int, 10> queue;// 生产者线程逻辑auto producer = [&queue]() {for (int i = 0; i < 20; ++i) {while (!queue.enqueue(i)) {// 队列满了,可以短暂等待或执行其他操作std::this_thread::sleep_for(std::chrono::microseconds(1));}std::cout << "Enqueued: " << i << std::endl;}};// 消费者线程逻辑auto consumer = [&queue]() {for (int i = 0; i < 20; ++i) {int item;while (!queue.dequeue(item)) {// 队列空了,可以短暂等待或执行其他操作std::this_thread::sleep_for(std::chrono::microseconds(1));}std::cout << "Dequeued: " << item << std::endl;}};// 创建并启动线程std::thread producer_thread(producer);std::thread consumer_thread(consumer);// 等待线程完成producer_thread.join();consumer_thread.join();return 0;
}
MPMC无锁队列
在上述SPSC队列中,当入队缓存已满或出队缓存为空时,采用简单的索引比较来判断队列状态,这种实现方式可能出现以下问题:
- 在多生产者或多消费者环境下会发生竞态条件(Race Condition):多个生产者可能同时读取 m_write_idx,然后都判断队列未满,导致多个线程尝试写入同一个位置。
- 此外也没有解决ABA问题,索引是循环使用的,可能出现不同状态但索引值相同的情况
LockFreeQueue的MPMC支持机制
- 使用compare_exchange_weak 进行原子操作,这确保了只有成功更新写索引的线程才能继续执行写入操作,避免了多个生产者写入同一位置的问题。
- 使用额外的标志位(flag)标记元素状态
两阶段检查机制: LockFreeQueue在写入前进行了两次检查:
- 检查队列是否已满(通过索引比较)
- 检查目标位置是否已被占用(通过flag)
这种双重检查机制确保了在并发环境下的数据一致性。
template<typename T, size_t N = 1024>
class LockFreeQueue{
public:// 定义队列的元素struct Element{// 定义元素是否存在,存在才可以读写std::atomic_bool flag;T data;};LockFreeQueue() : m_data(N), m_write_idx(0), m_read_idx(0) {}~LockFreeQueue() = default;// 入队// 满的条件 write_idx = read_idx + data.size()bool Enqueue(T value) {int write_idx = 0;Element *e = nullptr;do{// 获取当前读位置write_idx = m_write_idx.load(std::memory_order_acquire);// 检查队列是否已满(写位置 >= 读位置 + 队列容量)if(write_idx >= m_read_idx.load(std::memory_order_acquire) + m_data.size())return false;// 计算在循环数组中的实际索引size_t index = write_idx % m_data.size();e = &m_data[index]; // 取出队头元素// 检查该位置是否已被占用(flag为true表示已被写入但未读取)if(e->flag.load(std::memory_order_acquire))return false;}while (!m_write_idx.compare_exchange_weak(write_idx, // 输入:预期值;输出:实际值(比较失败时)write_idx + 1, // 当预期值与原子变量当前值相等时,要设置的新值std::memory_order_release, // 比较并交换成功时的内存序std::memory_order_relaxed)); // 比较并交换失败时的内存序// CAS成功,执行实际写入操作e->data = std::move(value); // 转移所以权e->flag.store(true, std::memory_order_release); // 标记已占用return true;}bool Dequeue(T& val){int read_idx = 0;Element *e = nullptr;do{// 只是取出数据,不考虑内存序,这里条件宽松read_idx = m_read_idx.load(std::memory_order_acquire);// 队列已经满了if(read_idx >= m_write_idx.load(std::memory_order_acquire))return false;// 获取当前可以使用的下标size_t index = read_idx % m_data.size();// 取出队头元素e = &m_data[index];// 考虑位置是否能被读出来if(!e->flag.load(std::memory_order_acquire))return false;}while (!m_read_idx.compare_exchange_weak(read_idx, read_idx + 1,std::memory_order_release,std::memory_order_relaxed));// 弱交换, 性能更好val = std::move(e->data); // 转移所以权e->flag.store(false, std::memory_order_release); // 标记该位置目前被使用了return true;}private:std::vector<Element> m_data;std::atomic_int m_read_idx;std::atomic_int m_write_idx;
};
-
compare_exchange_weak:可能会出现伪失败,即在比较成功的情况下仍然返回 false -
compare_exchange_strong:不会出现伪失败,比较成功就一定返回 true -
锁队列实现中使用
compare_exchange_weak是非常合适的选择,因为代码已经包含了重试循环 do-while,可以很好地处理伪失败的情况,同时还能获得更好的性能表现。 -
伪失败是指
compare_exchange_weak函数在比较实际上是成功的情况下,仍然返回 false 的现象。
OSD叠加
将yolo模型转RKNN模式并部署至摄像头平台,完成识别后采用OSD异步的形式一批一批的绘制识别结果在主码流上,同时控制云台的自动追踪功能
- 直接调用例程比较卡,重新开一路低分辨率的码流供AI识别,由于识别非串行,通过批量化处理,一批一批的显示,异步显示,将OSD结果叠加到主码流,推流不卡顿,OSD自动叠加。
OSD步骤:
- 步骤1: 调用RK_MPI_RGN_Create 填充区域属性并创建区域。
- 步骤2:调用RK_MPI_RGN_AttachToChn 将画布绑定到通道特定区域上。
- 步骤3:调用RK_MPI_RGN_GetCanvasInfo 获取画布信息。
- 步骤4:将位图数据写入画布信息中。
- 步骤5:调用RK_MPI_RGN_UpdateCanvas 更新画布。
- 更新画布信息时重复步骤3 ~ 步骤5。
- 步骤6:不用时调用 RK_MPI_RGN_DetachFromChn 将画布从绑定通道中解绑。
- 步骤7:调用 RK_MPI_RGN_Destroy 销毁区域。
YUV420 是一种广泛应用于视频存储、传输和处理的色彩编码格式,它通过分离**亮度(Y)和色度(UV)**信息
-
亮度(Y,Luminance):代表图像的明暗信息,对应黑白图像的灰度值,人眼对其变化更敏感。
-
色度(UV,Chrominance):包含色彩的色调(U,蓝色分量与亮度的差值)和饱和度(V,红色分量与亮度的差值)信息,人眼对其细节敏感度较低。
-
比例定义:在每 4 个连续的 Y 像素(通常构成 2×2 的像素块)对应的区域中,只保留 1 个 U 像素和 1 个 V 像素。
-
直观理解:
- Y 分量:每个像素都保留完整信息(数据量最大)。
- U 和 V 分量:水平和垂直方向上的分辨率均为 Y 的 1/2(即每 2×2 的 Y 块共享一组 UV 值)。
-
数据量优势:相比 RGB 格式(每个像素 3 个分量均完整存储),YUV420 的数据量仅为其 3/8(RGB:3 字节 / 像素;YUV420:1 + 0.25 + 0.25 = 1.5 字节 / 像素),大幅节省存储和带宽。
2bpp(Bits Per Pixel,每像素位数)图像具有以下特征:
- 颜色深度: 2bpp 图像每个像素使用 2 位来表示颜色,因此,每个像素可以表示 (2^2 = 4) 种不同的颜色。
- 颜色调色板: 由于每个像素只能表示 4 种颜色,通常会使用一个颜色调色板(Color Palette)来定义这 4 种颜色, 调色板中的每个颜色通常用 RGB 值表示。
- 存储效率: 2bpp 图像的存储效率较高,因为每个像素只需要 2 位。
- 内存访问: 由于每个字节可以存储 4 个像素(2 位/像素),在处理 2bpp 图像时,通常需要按字节访问内存,并在字节内进行位操作来提取或设置单个像素的值,例如,一个字节
0b10100101可以表示 4 个像素,分别为10、10、01和01。
云台追踪
- 计算当前目标与上一个目标与视频中心的偏移
- 计算当前目标与上个目标的面积
- 计算两次得分 = 置信度 + 面积 * 权重
- 更新目标的坐标和置信度
- 计算目标中心位置与图像中心的偏移量
- 是否在感兴趣区域内、偏移吃否超过容忍值
- 将像素偏移量转换为云台角度调整量,左右 90°,俯仰 45°
onvif协议总结
基于ONVIF协议的摄像头开发总结
什么是onvif
ONVIF规范中设备管理和控制部分所定义的接口均以Web Services的形式提供,设备作为服务提供者为服务端。ONVIF规范涵盖了完全的基于XML及WSDL的定义。每一个支持ONVIF规范的终端设备均须提供与功能相应的Web Service。服务端与客户端的数据交互采用SOAP协议。ONVIF中的其他部分比如音视频流则通过RTP/RTSP进行
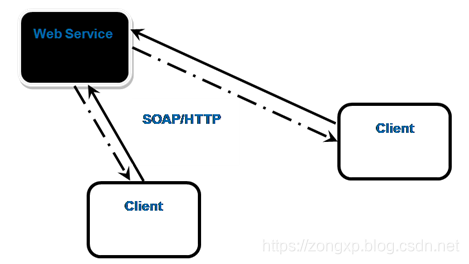
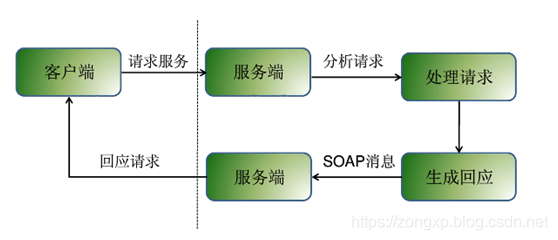
客户端根据 WSDL 描述文档,会生成一个 SOAP 请求消息,该请求会被嵌入在一个HTTP POST请求中,发送到Web Services 所在的Web 服务器。Web Services 请求处理器解析收到的 SOAP 请求,调用相应的 Web Services。然后再生成相应的SOAP 应答。Web 服务器得到 SOAP 应答后,会再通过 HTTP应答的方式把信息送回到客户端。

Web Service能为视频监控什么
- 设备的无关性,任何一个设备接入系统,不会对其他系统造成影响。
- 设备的独立性,每一个设备只负责对接收到的请求做出反馈,甚至不需要知晓控制端的存在。
- 管理的集中性,所有的控制由客户端来发起。
ONVIF规范能为视频监控带来什么
- 抽象了功能的接口。统一了对设备的配置以及操作的方式。
- 控制端关心的不是设备的型号,而是设备所提供的Web Service。
- 规范了视频系统中Web Service范围之外的行为。
- ONVIF提供了各个模块的WSDL,拥有效率非常高的开发方式。
ONVIF规范的内容
- 设备发现,设备管理,实时流媒体,事件处理,PTZ,接收端配置,显示服务,设备输入输出服务
WSDL: WSDL是Web services 描述语言的缩写。是一种基于xml的网络服务描述语言,用来描述Web服务和说明如何与Web服务通信的XML语言,为用户提供详细的接口说明书。
SOAP:
SOAP是Simple Object Access Protocol的缩写。是基于XML的一种协议。一条SOAP 消息就是一个普通的XML 文档,包含下列元素:
- 必需的 Envelope 元素,可把此 XML 文档标识为一条 SOAP 消息
- 可选的 Header 元素,包含头部信息
- 必需的 Body 元素,包含所有的调用和响应信息
- 可选的 Fault 元素,提供有关在处理此消息所发生错误的信息
RTSP协议总结
RTSP关键信令交互流程
- 建立连接:客户端通过 TCP(默认端口554) 或 UDP 与服务器建立连接。
- 选择协商: 客户端->服务器、服务器->客户端:返回支持的RTSP方法
- 获取媒体描述: 客户端请求媒体资源的SDP描述,服务器返回SDP描述
- 建立传输通道: 客户端协商传输方式(RTP over UDP/TCP)和端口,服务器传输参数并返回会话ID
- 开始播放: 客户端请求开始传输流、服务器确认播放
- 终止会话: 客户端终止会话、服务器确认终止
RTSP概述
- rtsp协议是国际标准,里面使用了sdp协议, rtp协议,rtcp协议, sdp协议叫做会话描述协议, rtp协议叫做实时传输协议,rtcp为实时传输控制协议。
RTSP:应用层,控制媒体流的播放、暂停、终止
SDP:会话描述层:
- 声明媒体流的格式(如H.264)、传输方式(TCP/UDP)、端口号等
- sdp是一个文本描述协议,用于声明会话参数
RTP over UDP:
- 延时低、不可靠(容忍丢包)、协议开销小,实时音视频、直播、视频会议
- 在网络弱、需穿透防火墙时需要over TCP
- 5004 是 RTP 的常见默认端口
RTCP:
- RTCP 强制使用TCP: RTSP协议本身的控制命令必须通过TCP传输(默认端口554),确保信令的可靠性和有序性。
- 主流选择: 大多数实时流媒体(如摄像头监控)使用RTP over UDP传输音视频数据,搭配RTCP进行质量控制
- 追求低延迟选UDP,追求可靠性选TCP
RTCP控制信号的具体功能
- 网络质量反馈(RR/SR) 丢包率 接收端RR报文告知发送端SR,
- 延迟与抖动:计算网络延迟(DLSR字段)和抖动(包到达时间波动)
- RTCP的“控制信号”是针对媒体流传输的实时反馈机制,核心目标是动态优化QoS(服务质量)
- RTCP:通过SR(Sender Report)和RR(Receiver Report)报告传输质量(丢包率、延迟等)
RTP包结构

RTP Header字段:
- V 版本 固定为2
- 是否有填充字节
- 扩展头
- CSRC计数 CC
- 标记关键帧
- 负载类型
- 序列号
- 时间戳
- SSRC:同步标识符
视频封装(以H.264为例)
- NAL单元(Network Abstraction Layer Unit):H.264的基本数据单元
NAL头(1字节):F|NRI|Type,其中:
- F(Forbidden):错误位,通常为0。
- NRI(重要性):0~3,值越大表示越重要。
- Type:NAL单元类型(如7=SPS,8=PPS,5=IDR帧)
(1)单NAL单元模式:一个RTP包包含一个完整的NAL单元。
±--------±---------------+
| RTP头 | NAL单元(如IDR)|
±--------±---------------+
(2)分片模式(FU-A):大NAL单元分片传输
±--------±------±--------------±--------------+
| RTP头 | FU头 | FU负载起始部分 | …后续分片…|
±--------±------±--------------±--------------+
FU头(1字节):S|E|R|Type,其中:
- S(Start):是否为分片起始。
- E(End):是否为分片结束。
- R(Reserved):保留位.
- Type:原NAL单元类型。
(3)组合模式(STAP-A):多个小NAL单元合并到一个RTP包。
视频编码器 Video Encoder
H.264/AVC 帧间预测、CAVLC/CABAC熵编码 直播、视频监控、蓝光光盘
H.265/HEVC: 4K/8K超高清、VR、医疗影像
AV1 2018 流媒体(YouTube、Netflix)
帧类型(Frame Types)
-
I帧:独立编码帧,关键帧,解码不依赖其他帧(压缩率低,质量高,保真度)。
-
P帧:预测帧,参考前一帧(I或P帧)进行运动补偿预测。
-
B帧:双向预测帧,参考前后双向帧,压缩率更高,但增加延迟。
| 帧类型 | 参考帧 | 编码方式 | 核心作用 | 优点 | 缺点 |
|---|---|---|---|---|---|
| I 帧 | 无(自参考) | 帧内编码 | 作为后续帧的参考基准,随机访问点 | 画质最高,可独立解码 | 压缩率最低,数据量大 |
| P 帧 | 1 个前向参考(I/P 帧) | 帧间预测 + 残差 | 利用前帧冗余,降低数据量 | 压缩率高于 I 帧 | 依赖前帧,出错会扩散 |
| B 帧 | 2 个参考(前 + 后 I/P 帧) | 双向预测 + 残差 | 最大化利用帧间冗余 | 压缩率最高(比 P 帧低 30%+) | 依赖前后帧,解码延迟高,不可作为参考帧 |
参数优化:
CRF: 动态码率控制(x264/x265常用,值越小质量越高)。 CRF=23(默认平衡点)
- CRF通过动态调整量化参数控制压缩强度:
- RF↓ → QP↓:减少量化步长,系数舍入误差越小 → 重建图像更接近原始帧,保留更多细节 质量与体积的平衡
GOP结构: I帧间隔(如GOP=30)、B帧数量(如–bframes 4)。
- GOP大小与丢包恢复能力: GOP小→I帧多→恢复快,因此可能减少花屏;但若导致码率波动引起丢包增加,反而增加花屏
- GOP调小能缩短丢包恢复时间 GOP=1~2秒 禁用B帧
视频卡顿花屏 GOP
-
定义: GOP是一组连续的图像帧序列,以I帧(关键帧)开始,后面跟若干P帧(预测帧)或B帧(双向预测帧)
-
I帧:完整编码的帧,解码时不依赖其他帧。
-
P/B帧:基于参考帧(如I帧或前序帧)压缩,解码依赖前文。
-
调小GOP: 即缩短I帧间隔,例如从300帧(10秒)调整为30帧(1秒),增加关键帧密度
-
花屏常见的原因之一是丢包导致参考帧缺失。如果GOP太大,关键帧帧间隔时间长,那么在网络差的时候,丢失的P/B帧可能无法正确参考之前的I帧,导致后续画面出错,直到下一个关键帧帧出现才恢复。
-
调小GOP可能导致码率波动更大,因为I帧的压缩率较低,体积较大
GOP大小与丢包恢复能力: GOP小→I帧多→恢复快,因此可能减少花屏;但若导致码率波动引起丢包增加,反而增加花屏
GOP调小能缩短丢包恢复时间
QT客户端
MVVM
在MVVM架构中,ViewModel作为Model和View之间的桥梁,主要承担以下职责:
- 数据转换与格式化:将Model层的数据转换为View层可直接使用的格式
- 业务逻辑处理:包含与UI相关的业务逻辑,但不包含视图操作
- 状态管理:维护视图状态(如加载中、错误状态等)
- 命令处理:处理来自View的用户交互命令
- 数据验证:对输入数据进行验证
响应式编程是实现实时更新的核心:
- 当数据变化时自动通知所有观察者
线程池的设计

线程池整体工作流程
- 用户通过
submitTask提交一个任务,抢锁,condNotFull.wait_for,如果任务队列未满,任务入队,如果任务队列满了,等待1秒(wait_for),return Result(task, false);notEmpty.notify,唤醒阻塞的线程来消费了- 设置设置了
cached模式,且 任务队列长度 > 当前可用线程的数量,并且当前线程数量又小于最大线程数,扩容 - 返回Result类型,并支持类型参数类型,
return Result(task);
- 线程函数:抢锁,
condNotEmpty.wait,如果线程池有线程(tasiSize > 0),唤醒一个线程,从任务队列中取一个任务来执行notFull.notify,通知用户可以提交任务了if taskSize > 0,notEmpty.notify,任务队列还有任务,通知其他线程可是继续来消费cached模式下,如果任务队列为空,获取当前时间与上一次运行这个线程的时间:auto now = std::chrono::high_resolution_clock().now();,如果,则回收当前这个线程- 任务队列为空了
- 两个时间的差值大于60s
- 当前线程数量 > 核心线程数量
- 资源回收,如果
quit_flag,- 析构函数,
condNotEmpty.notify,唤醒等待任务中的线程, - 线程函数释放线程池函数后,
condExit.notify_all();,唤醒析构函数中的Exit条件变量(pool.size())
- 析构函数,
设计细节与常考问题
- 线程池中没有线程处理用户提交的任务了怎么办,用户不是阻塞了吗
- 加入用户加入的任务的生命周期比较短怎么办呢
- 怎么设计返回值表示任意类型Any,如何设计Result机制,如果线程还没有处理完获取结果会怎么样(如果提交成功则阻塞,如果提交失败)
submitTask返回结果是task->getResult()还是Result(task)比较好- 随着task被执行完,task对象没了,线程池中会 pop(),然后析构了,所以需要在Result中保存 task
- 对于get方法,如果任务提交失败,是否还需要阻塞
- setVal,如何获取任务run的返回值,exec()封装run(),在run完保存run结果,setVal(Any),但原来是Result中包含task,用裸指针,1. 避免循环引用 2. Result的生命周期是大于task的,然后在Result里面执行 task->setResult(this);
- get,用户调用这个方法,获任务执行的返回值
step1
-
对于每个任务
run()函数执行完毕,自动释放资源,希望自动释放资源,并且还要考虑用户传入的对象的生命周期std::queue<std::shared_ptr<Task>> taskQue; // 任务队列 -
线程函数设计,从任务队列(非空)中取一个任务给线程消费,结果如果queSzie > 0,notEmp通知,notFull一定会通知
-
用户提交函数用智能指针管理,极端情况,如果任务队列满了,会提交失败,等待1秒wait_for返回false
-
线程函数thread_function定义在ThreadPool中,但需要绑定到Thead中
step2 资源回收与后处理
- 线程池的资源回收
- 析构函数等待正在执行的线程,执行完再通知析构函数的条件变量
- 析构函数函数唤醒阻塞线程,
- 线程池结束后,如何处理任务队列中的任务,队列为空exitCond.notify
step3 线程池支持cached模式
-
用户自定义设置工作模式,默认Fixed
-
提交任务函数中,任务数 > 空闲线程数,需要创建空闲线程
-
线程函数中,如果有过多的空闲线程,并且空闲时间超过了60s,回收空闲线程
- 时间相关与判断(high_resolution_clock)
- 如何找到这个线程函数对应的是哪个线程,thread_id > 线程对象 > 删除
step4
如何获取线程任务返回值,并接收任意参数类型
Result res = pool.submitTask(std::make_shared<MyTask>());
int data = res.get().cast_<int>();
接收任意参数类型,定义Any类
- 定义一个抽象基类
Base,作为所有类型的共同接口。 - 定义模板派生类
Derived<T>,用于存储具体类型T的数据,并继承自Base。 Any类通过持有Base的智能指针,间接存储任意类型的Derived<T>对象,从而实现 “存储任意类型” 的能力。- 通过
dynamic_cast实现类型的安全转换,确保提取数据时的类型正确性。
类层次结构:
Base:纯接口基类,仅定义默认构造函数和虚析构函数(虚析构函数确保Derived对象能被正确销毁)。Derived<T>:模板类,继承自Base,内部用data_存储具体类型T的数据。
Any类的关键成员:
std::unique_ptr<Base> basePtr:智能指针,指向Derived<T>对象,实现对任意类型数据的存储。- 禁用拷贝构造和拷贝赋值(
= delete),允许移动构造和移动赋值(= default),确保资源管理的安全性(unique_ptr不可拷贝)。
核心功能:
- 构造函数模板:接收任意类型
T的数据,通过std::make_unique创建Derived<T>对象,并用basePtr持有。 cast_<T>()方法模板:通过dynamic_cast将basePtr转换为Derived<T>*,若成功则返回存储的数据,否则抛出异常。
#include<memory>
class Base{
public:Base() = default;virtual ~Base() = default;
};template<typename T>
class Derived : public Base{
public:Derived(T data) : data_( data) {}~Derived() = default;T data_;
};class Any
{
public:Any() = default;~Any() = default;Any(const Any& ) = delete;Any& operator=(const Any&) = delete;Any( Any&& ) = default;Any& operator=( Any&&) = default;//构造函数接收任意其他类型的数据template<typename T>Any(T data) : basePtr(std::make_unique<Derived<T>>(data)) {}// cast_提取任意其他类型的数据template<typename T>T cast_() {auto ptr = dynamic_cast<Derived<T>*>(basePtr.get());if(ptr != nullptr)return ptr->data_;elsethrow "type error";}
private:std::unique_ptr<Base> basePtr;
};
封装Any类与Task,run的结果,定义一个Resul类
-
是task.getResult()还是Result(task)。随着task被执行完,task对象没了,线程池中会 pop(),然后析构了,所以需要在Result中保存 task。
- 对于get方法,如果任务提交失败,是否还需要阻塞
- setVal,如何获取任务run的返回值,exec()封装run(),在run完保存run结果,setVal(Any),但原来是Result中包含task,用裸指针,1. 避免循环引用 2. Result的生命周期是大于task的,然后在Result里面执行 task->setResult(this);
- get,用户调用这个方法,获任务执行的返回值
- Result如何获取task的结果的,Task中封装run(),在exec中
设计一个Resul类,有成员变量:
- taskPtr:保存用户用户提交的任务指针
- isValid:保存用户提交任务成功与否
- 信号量sem:等待任务执行完毕
- 数据类型 Any
Result类设计
class Result {
public:Result() : taskPtr(nullptr) {}~Result() = default;Result(std::shared_ptr<Task> task, bool flag = true) : taskPtr(task), isValid(flag){if (taskPtr) {taskPtr->setResult(this);}}// 设置结果void setVal(Any any) {this->any = std::move(any);sema.post();} // 获取结果Any get() {if(!isValid) return ""; // 用户提交任务失败sema.wait(); // 等待用户任务完成return std::move(any);}private:Any any;std::shared_ptr<Task> taskPtr;std::atomic_bool isValid;Semaphore sema;
};
Task类设计
// 前向声明 Result 类
class Result;
class Task
{
private:Result* result;
public:virtual Any run() = 0;void exec() {if(result)result->setVal(run());}void setResult(Result* res){this->result = res;}
};
Semaphore类设计
#include <mutex>
#include <condition_variable>
#include <atomic>class Semaphore
{
private:std::atomic_bool isExit;int cnt;std::mutex mtx;std::condition_variable cond;public:Semaphore(int szie = 0) : cnt(szie), isExit(false) { }~Semaphore() {isExit = true;}void post() {if(isExit)return;std::unique_lock<std::mutex> lock(mtx);cnt++;// linux下condition析构什么也没做,没有释放任何东西// 导致cond无效cond.notify_all();}void wait() {if(isExit)return;std::unique_lock<std::mutex> lock(mtx);cond.wait(lock, [=]()->bool{return cnt > 0;});cnt--;}
};
step5 项目优化
- 现需要定义派生类,继承于Task对象,然后重写run()方法,并通过构造函数传入参数,提交任务应该更简单,直接传递函数名称
- 为了获得返回值,任务比较大Any类,Semaphore类,Result类
- 解决方案:
- 可编程模板编程
- packaged_task(函数对象)和future(相当于Result)机制来节省线程池代码
概念问题
核心作用:
- 降低资源消耗: 减少线程创建 / 销毁的性能开销(线程是稀缺资源,创建需分配内存、上下文切换等)。
- 提高响应速度: 任务到达时无需等待线程创建,直接复用空闲线程。
- 便于管理控制: 统一管理线程生命周期,可控制并发数、监控线程状态等。
线程池的优势
线程池的优势就是,在服务进程启动之初,就事先创建好线程池里面的线程,当业务流量到来时需要分配线程,直接从线程池中获取一个空闲线程执行task任务即可,task执行完成后,也不用释放线程,而是把线程归还到线程池中继续给后续的task提供服务。
频繁创建线程存在明显缺陷:
- 性能开销大: 线程创建需向 OS 申请资源(如栈空间,默认 1MB),销毁需回收资源,频繁操作会导致 CPU 资源浪费。
- 资源耗尽风险: 无限制创建线程可能导致内存溢出(OOM)或系统资源耗尽(如句柄不足)。
- 难以管理: 无法统一控制并发数,可能因线程过多导致上下文切换频繁,反而降低效率。
线程池的核心参数与作用
| 核心参数 | 作用 |
|---|---|
| 核心线程数 | 线程池长期保留的最小线程数(初始化线程数),即使空闲也不会销毁 |
| 最大线程数 | 程池允许创建的最大线程数(核心线程 + 非核心线程(动态创建)的上限) |
| 非核心线程空闲存活时间 | 当非核心线程空闲超过该时间(60s),会被销毁释放资源 |
| 任务阻塞队列 | 当核心线程都在忙时,新任务会进入该队列等待,每次提交也先都提交到队列中 |
| 拒绝策略 | 当线程池、队列都满时,对新任务的处理策略 |
线程池的两种模式:
- fixed模式:线程池里面的线程个数是固定不变的,一般是ThreadPool创建时根据当前机器的CPU核心数量进行指定。
- cached模式: 线程池里面的线程个数是可动态增长的,根据任务的数量动态的增加线程的数量,但是会设置一个线程数量的阈值,任务处理完成,如果动态增长的线程空闲了60s还没有处理其它任务,那么关闭线程,保持池中最初数量的线程即可。
并发与并行:
- 并发: 在单核CPU,一个流水线上,运行多个任务,每个任务占用一定的时间片,相当于一个时间片轮转,每一个时刻还是只有一个任务在执行

-
并行: 对于多CPU,每个CPU上有一条流水线,每条流水线上又有不同的任务在并发执行,比如task1在第一条流水线上执行,task2在第二天流水线上执行,同一时刻是有多个任务在同时执行的。

IO密集与CPU密集:
- CPU密集型: 程序内部主要是做计算用的,如深度学习、1+2+…+到10亿
- IO密集型: 程序的指令涉及IO操作,文件操作、设备、网络操作(等待客户端接入,IO操作可以把进程阻塞住的),再分配给他CPU的时间片,CPU相当于是空闲下来了

多线程编程是否一定好
- 对于多核CPU都是适合的
- 单核的CPU密集型不适合多线程: 因为多个线程的调度会频繁的上下文切换,线程栈保存相关上下文寄存器,保存到内核栈,调度时候还要访问另一个线程的内核栈,花销高
- 单核的IO密集型还是适合的,IO会有阻塞队列,不在就绪队列中,不会被调度,阻塞的时候会让出CPU的时间片
线程的消耗
- 线程的创建和销毁都是非常"复杂"的操作(空间切换,PCB,内核栈,页表,页目录,地址空间数据结构vm_struct,又要回到用户空间,还要销毁)
- 线程栈(保存函数信息)本身占用大量内存,用户空间3G,一个线程栈8M,380个左右的线程
- 线程的调度,线程的上下文切换要占用大量时间
- 大量线程同时唤醒(同一时间很多IO操作准备好了)会使系统经常出现锯齿状负载或者瞬间负载量很大导致宕机
上下文切换: 线程的调度,保存上下文,保存CPU寄存器信息保存到线程栈上
线程数的确定
1. CPU 密集型任务
- 特点: 任务主要消耗 CPU 资源(如复杂计算、数据处理等),线程运行时很少阻塞,CPU 利用率接近 100%。
- 核心问题: 线程数过多会导致 CPU 频繁进行上下文切换(保存 / 恢复线程状态),反而增加额外开销,降低整体效率。
设置原则:
- 核心线程数 ≈ CPU 核心数 或 CPU 核心数 + 1。
- 最大线程数 = 核心线程数(无需额外创建非核心线程,避免上下文切换损耗)。
示例: 若服务器为 4 核 CPU,核心线程数可设为 4 或 5(+1 是为了应对偶尔的线程阻塞,如极短的 IO 操作);最大线程数同样设为 4 或 5。
2. IO 密集型任务(IO-bound)
- 特点: 任务大部分时间处于阻塞状态(如数据库查询、网络请求、文件 IO 等),CPU 利用率较低(线程等待 IO 时 CPU 空闲)。
- 核心问题: 线程阻塞时 CPU 空闲,需要更多线程 “填充” 空闲时间,提高 CPU 利用率。
设置原则:
- 核心线程数 ≈ CPU 核心数 × 2 (基础参考)。-
- 最大线程数:根据 IO 阻塞时间调整,阻塞时间越长,可设置越大(但需避免无限制增大)。
进阶公式:
理想线程数 = CPU核心数 × (1 + IO等待时间 / CPU执行时间)- 例如: 若任务的 IO 等待时间是 CPU 执行时间的 3 倍,4 核 CPU 的理想线程数为 4 × (1 + 3) = 16。
同步与互斥
互斥锁mutex
- 看这段代码是否存在竞态条件,称作临界区代码段,代码不可重入的,需要保证它的原子操作,通过互斥锁来保证他的原子操作
lock_guard:自动加锁与加锁,通过构造函数加锁,析构函数解锁,不支持手动的加锁与解锁。unique_lock: 提供手动的lock与unlock,可以手动加锁与解锁,可以配合条件变量使用
atomic原子类型
-
使用的是CAS操作(比较与交换),效率性能会比较高,但也会有一定的问题,比如ABA问题
-
生产者/消费者操作容器,都要先获取一把锁,因为容器不是线程安全的
-
生产者先检测容器是否已满,如果满
wait,发生以下事情- 改变线程的状态,改变等待状态
- 释放互斥锁,让消费者去获取锁
-
生产者生产完后把数据存入容器,然后
notify,唤醒等待在这个条件上的线程,等待在这个条件变量的线程从等待状态转化为阻塞状态。 -
消费者消费之前检查容器是否为空,如果为空则
wait,同理发生以上两件事情 -
消费者如果收到很生产者的
notify,从等待到阻塞,获取到锁互就就绪,等待调度

信号量 semaphore
- 可以看成资源记数没有限制的互斥锁,互斥锁可以看成资源记数只有0,1的信号量

互斥锁与信号量的区别:
- 互斥锁是独占的,信号量是共享的
- mutex由哪个线程获取,必须由哪个线程来解锁,信号量的post/wait可以由不同的线程操作
- 互斥锁不能直接unlock(无意义),信号量可以直接post或wait
FFmpeg
设计一个基于 FFmpeg 和 Qt 的视频解码器类VideoDecoder,主要功能是打开视频流、解码视频帧,并将解码后的帧转换为 Qt 的QImage格式用于显示。核心流程包括:初始化 FFmpeg、打开视频源、查找视频流、初始化解码器、读取并解码帧、格式转换为 RGB(适配 QImage)
FFmpeg 的核心库及其作用:
libavformat:处理媒体格式(封装 / 解封装),支持 RTSP、MP4、MKV 等格式。libavcodec:提供编解码器(如 H.264、H.265、AAC),负责编码和解码。libswscale:处理像素格式转换和尺寸缩放(如 YUV→RGB、1080P→720P)。libavutil:提供工具函数(如内存管理、数学运算),是其他库的基础。
核心结构体及其作用
AVFormatContext:格式上下文,用于管理媒体文件 / 流的整体信息(如流数量、格式类型等),是 FFmpeg 处理媒体的 “总入口”。AVStream:媒体流结构体,每个AVFormatContext包含多个AVStream(如视频流、音频流),存储流的具体信息(如解码器参数、时长等)。AVCodecContext:解码器上下文,存储解码器的详细参数(如宽高、像素格式、比特率等),是解码器的 “控制中心”。AVCodec:解码器 / 编码器结构体,封装了具体的编解码算法(如 H.264、H.265 解码器)。AVPacket:编码数据包,存储从流中读取的编码数据(如 H.264 的 NALU 单元),是解码的输入。AVFrame:原始帧结构体,存储解码后的原始数据(如 YUV/RGB 像素数据),是解码的输出。SwsContext:像素格式转换上下文,用于不同像素格式(如 YUV420P 转 RGB24)或尺寸的转换。
解码流程:
-
1. 初始化 FFmpeg 网络模块:
avformat_network_init()启用网络功能 -
2. 打开 RTSP 流
- 分配
AVFormatContext(avformat_alloc_context())。 - 调用
avformat_open_input()
- 分配
-
3. 查找流信息
调用avformat_find_stream_info(pFormatCtx, NULL)获取流的详细信息(如帧率、编码格式)。 -
4. 初始化解码器
- 从视频流
AVStream中获取解码器上下文AVCodecContext(stream->codec)。 - 查找对应解码器(
avcodec_find_decoder(pCodecCtx->codec_id))。 - 打开解码器(
avcodec_open2(pCodecCtx, pCodec, NULL))。
- 从视频流
-
5. 准备帧存储与格式转换
-
分配
AVFrame(pFrame)存储解码后的原始帧(如 YUV 格式)。 -
分配
AVFrame(pFrameRGB)存储转换后的 RGB 帧,并用av_image_alloc()分配像素缓冲区。 -
创建格式转换上下文(
sws_getContext()),指定源格式(如 YUV420P)、目标格式(RGB24)、宽高和缩放算法(如SWS_BILINEAR)。
-
-
6. 循环读取并解码帧
- 调用
av_read_frame()读取AVPacket(编码数据)。 - 过滤视频流的包(
packet.stream_index == videoStream)。 - 发送数据包到解码器(
avcodec_send_packet())。 - 接收解码后的帧(
avcodec_receive_frame())。 - 调用
sws_scale()将原始帧(YUV)转换为 RGB 帧。
- 调用
-
7. 转换为 QImage 显示
将pFrameRGB的像素数据(data[0])转换为QImage(格式QImage::Format_RGB888),用于 Qt 界面显示。 -
8. 资源释放 解码结束后,释放所有 FFmpeg 资源:
- 释放格式转换上下文(
sws_freeContext())。 - 释放帧缓冲区(
av_frame_free())。 - 关闭解码器(
avcodec_free_context())。 - 关闭流并释放格式上下文(
avformat_close_input())
- 释放格式转换上下文(
编码流程:
-
1. 初始化 FFmpeg 库
- 网络模块初始化:调用
avformat_network_init(),启用 FFmpeg 的网络功能(必需,否则无法解析 RTSP 流)。 - 注册组件:通过
avcodec_register_all()和av_register_all()注册编解码器和格式(旧版本 FFmpeg 必需,新版本可省略)。
- 网络模块初始化:调用
-
2. 打开 RTSP 输入流并解析信息
- 打开输入:调用
avformat_open_input()打开 RTSP URL(如rtsp://172.32.0.93/live/0),创建并填充输入格式上下文i_fmt_ctx。 - 解析流信息:调用
avformat_find_stream_info()读取流的详细数据(如编码格式、码率),完善i_fmt_ctx中的流信息。 - 查找视频流:遍历输入流
i_fmt_ctx->nb_streams,筛选出类型为AVMEDIA_TYPE_VIDEO的视频流,保存到i_video_stream。
- 打开输入:调用
-
3. 初始化输出上下文与输出流-
- 创建输出上下文:调用
avformat_alloc_output_context2(),根据输出文件路径(../output/1.mp4)自动推断输出格式(MP4),创建输出格式上下文o_fmt_ctx。 - 创建输出流:调用
avformat_new_stream()为输出上下文创建新的视频流o_video_stream。 - 复制流参数:通过
avcodec_parameters_copy()将输入视频流的编码参数(如宽高、像素格式、 codec_id)复制到输出流(确保输入输出编码格式一致,避免重新编码,仅做封装转换)。 - 补充输出参数:手动设置输出流的比特率(
out_codecpar->bit_rate = 400000),适配 MP4 封装要求。
- 创建输出上下文:调用
-
4. 打开输出文件并写入文件头
- 打开输出文件:调用
avio_open()打开输出文件(../output/1.mp4),绑定输出上下文的 IO 缓冲区(o_fmt_ctx->pb)。 - 写入文件头:调用
avformat_write_header(),向输出文件写入 MP4 的文件头(包含封装格式信息、流参数等,是 MP4 文件的 “元数据”)。
- 打开输出文件:调用
-
5. 循环读取 RTSP 帧并写入输出文件
- 读取编码帧:通过
av_read_frame()从 RTSP 流中读取编码数据包(AVPacket,包含 H.264/H.265 等编码数据)。 - 时间戳转换:调用
av_packet_rescale_ts()将输入流的时间戳(基于输入流的time_base)转换为输出流的时间戳(基于输出流的time_base),确保时间戳在输出流中有效。 - 时间戳修正:手动调整 PTS(显示时间戳)和 DTS(解码时间戳)
- 写入帧数据:调用
av_interleaved_write_frame()将处理后的AVPacket写入输出文件(自动处理流的交织,确保 MP4 封装顺序正确)。
- 读取编码帧:通过
-
6. 收尾与资源释放
- 写入文件尾:调用
av_write_trailer(),向输出文件写入 MP4 的文件尾(包含索引信息,确保文件可正常播放)。 - 释放资源:依次关闭输入流(
avformat_close_input())、输出文件 IO(avio_close())、释放输出上下文(av_free(o_fmt_ctx))及流资源,避免内存泄漏。
- 写入文件尾:调用
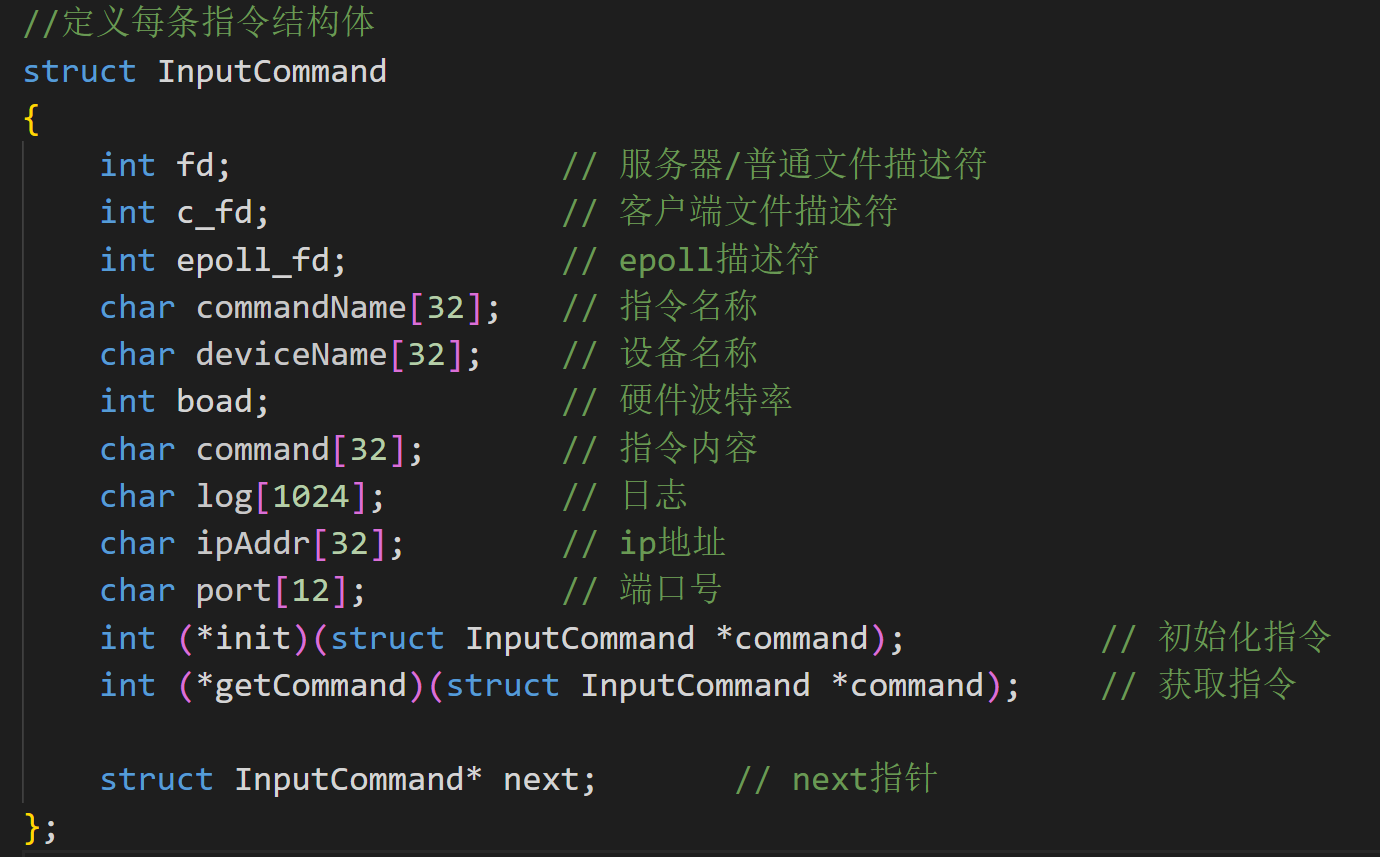
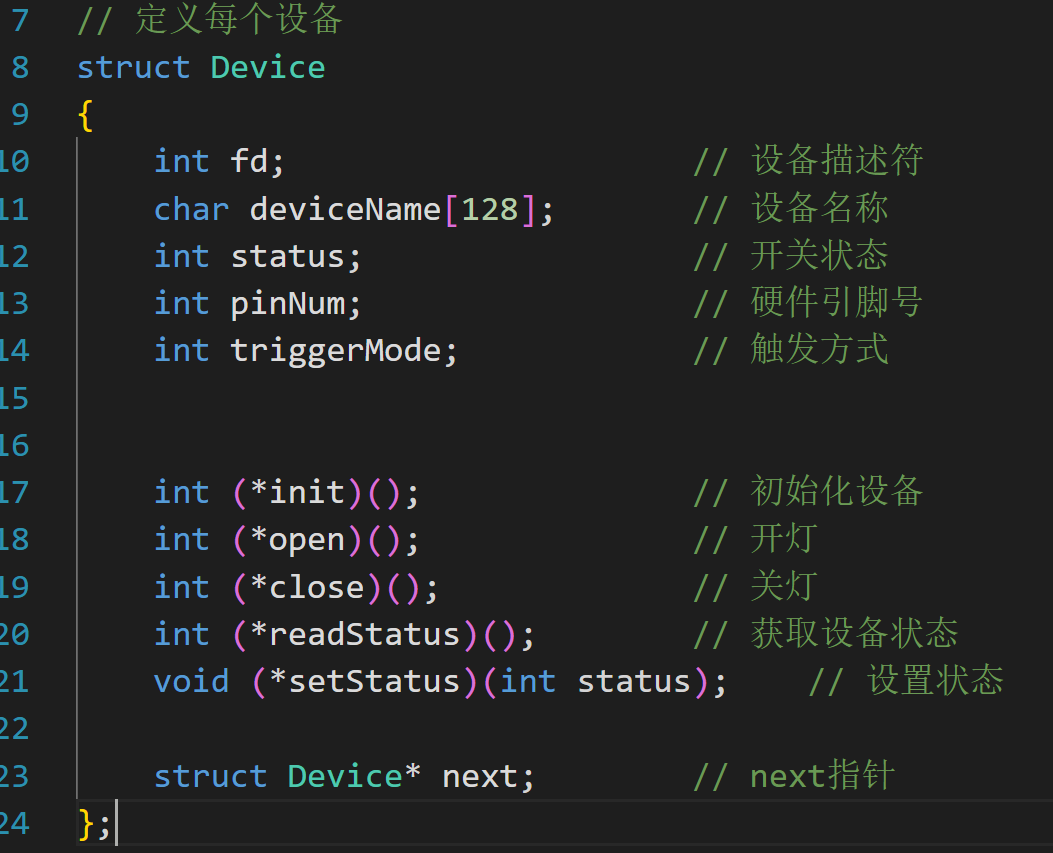
智能家居项目
C语言的面向对象编程
- 存在设备工厂与指令工厂,通过将每个设备的一些参数和功能进程封装成类似的类对象,通过创建实体设备,同时通过保存函数指针调用不同设备的方法
- 每个工厂中的实力通过hash_map的方式存储
单例模式

单例模式的型号控制器,确保一个类仅有一个实例,并提供全局访问点。适用于需要全局唯一对象的场景,层次深,开销大。
-
饿汉模式就是在类加载的时候立刻进行实例化,这样就得到了一个唯一的可用对象
-
懒汉模式在类加载的时候不去创建这个唯一的实例,而是在需要使用的时候再进行实例化,相比饿汉式,节省内存空间
// 定义类的时候创建单例对象
class Singleton
{
public:// = delete 代表函数禁用, 也可以将其访问权限设置为私有Singleton(const Singleton& obj) = delete;Singleton& operator=(const Singleton& obj) = delete;// 饿汉式static Singleton* getInstance(){return m_obj;}// 懒汉式static Singleton* getInstance(){if(m_obj == nullptr)m_obj = new Singleton();return m_obj;}private:Singleton() = default; // 构造函数私有化,饿汉式构造函数不能删除,必须私有并默认static Singleton* m_obj; // 单例对象
};
// 初始化静态成员变量 懒汉式就为nullptr
Singleton* Singleton::m_obj = new Singleton;// 简化的宏定义
#define SINGLETON(Class) \private: \Class(); \~Class(); \friend class Singleton<Class>;
单例模式: 确保一个类只有一个实例,并提供一个全局访问点来访问这个唯一实例。
(1)构造函数的设计(为什么私有?除了私有还可以怎么实现(进阶)?)
- 防止外部实例化, 私有构造函数确保只有类自身能够创建实例,外部代码无法通过new关键字创建新对象,防止无意中创建多个实例,破坏单例约束。
- 采用奇异递归模板模式
-
创建基类模板,并将基类构造函数设置为保护类型,防止直接实例化
-
派生类的构造函数可以是公共或保护
-
声明基类为友元,允许基类访问派生类的构造函数
-
(2)对外接口的设计(为什么这么设计?)
- 提供一个全局访问点来访问这个实例,使用static确保这个访问是类级别的访问
(3)单例对象的设计(为什么是static?如何初始化?如何销毁?(进阶))
-
全访问点,利用static保证该访问数据类级别,由于静态成员属性只能访问静态成员变量,因此需要将成员变量的实例也设置为static
-
私有化构造函数,删除拷贝构造函数与拷贝赋值操作符重载函数,并且在类外对类的静态成员变量进行初始化
-
设置实例对象为静态局部变量,自动销毁,或者手动delete删除,或者利用智能指针管理
(4)懒汉模式和恶汉模式的实现(判空!!!加锁!!!),并且要能说明原因(为什么判空两次?)
- 恶汉模式无线程安全问题,因为一开始就创建了实例对象,多线程获取对象的时候只做返回静态成员变量
- 懒汉模式在使用的时候才创建实例对象,在多线程中存在线程安全问题,多个线程第一个进入创建实例,存在创建了多个实例的隐患,因此需要加互斥锁,保证当前只有一个线程在创建实例对象。
- 这把锁又影响了效率,这样一来只有一个线程运行,其他线程阻塞,因此需要2次判空
- 第一次判空,在大多数情况下,实例已经存在,直接返回,避免了不必要的互斥开销
- 同步互斥块:确保只有一个线程能进入创建实例的代码段
- 第二次判空:防止多个线程同时通过第一次判空后,在互斥块内重复创建实例
(5)对于C++编码者,需尤其注意C++11以后的单例模式的实现(为什么这么简化?怎么保证的(进阶))
-
静态局部变量方式
-
在C++11标准中有如下规定,并且这个操作是在编译时由编译器保证的:如果指令逻辑进入一个未被初始化的声明变量,所有并发执行应当等待该变量完成初始化。
-
双重检查锁的问题所在: 一条语句的机器指令分为3步
- 第一步:分配内存用于保存类对象。
- 第二步:在分配的内存中构造一个 类对象(初始化内存)
- 第三步:使用 对象指针指向分配的内存
该顺序可能被重排变成1,3,2,可以使用原子操作来解决,或者使用C++11以上的静态局部变量解决
hash_map
// 哈希节点(键为fd,值为结构体指针)
typedef struct HashNode {int fd; // 键:文件描述符Device* value; // 值:结构体指针struct HashNode* next; // 处理哈希冲突的链表
} HashNode;// 哈希表结构
typedef struct HashMap {HashNode** buckets; // 桶数组size_t capacity; // 容量(桶数量)size_t size; // 实际存储的键值对数量float load_factor; // 负载因子(触发扩容阈值)pthread_rwlock_t rwlock; // 读写锁
} HashMap;// 哈希函数(针对整数fd优化)
static uint64_t hash_func(int fd, size_t capacity) {// 整数哈希:简单映射避免负fd(fd通常非负,此处兼容特殊情况)uint64_t key = (uint64_t)(fd < 0 ? -fd : fd);// 乘以一个大质数减少哈希冲突key = key * 1099511628211ULL;return key % capacity;
}
| 方法 | 主要特点 | 查询效率 | 插入效率 | 空间效率 | 备注 |
|---|---|---|---|---|---|
| 线性探测 | 简单,易聚集 | 一般 | 一般 | 高 | 容易产生主聚集 |
| 平方探测 | 减少聚集 | 一般 | 一般 | 高 | 可能失败(循环) |
| 双重哈希 | 分布更好 | 较好 | 较好 | 高 | 函数设计复杂 |
| 开链法 | 插入灵活,支持扩容 | 稳定 | 稳定 | 较低 | 缓存不友好 |
| 溢出区 | 存储独立,结构分离 | 不稳定 | 不稳定 | 较低 | 很少使用 |
关于哈希
- 为什么选择哈希表而不是其他数据结构来存储设备节点?
- 通过 fd 查找设备需要 O(1) 平均时间复杂度,比红黑树的 O(log n) 更快
- 备节点主要通过 fd 访问,哈希表最适合基于键的快速查找
- 如何解决哈希冲突? 这里采用了什么策略?
- 使用链地址法(拉链法),每个桶是一个链表(hashMap中保存二级指针)
- 冲突元素通过 next 指针链接在同一桶中
- 负载因子的作用是什么?为什么设置为0.75?
- 负载因子控制扩容时机,避免过多冲突
- 0.75 是空间和时间的平衡点,冲突概率较低且内存利用率高
- 扩容时为什么要重新哈希所有元素?
- 容量变化后,哈希函数结果会改变
- 必须重新计算每个元素在新桶数组中的位置
关于性能与复杂度
- 什么情况下哈希表的性能会退化?
- 哈希函数质量差导致大量冲突
- 极端情况下退化为链表,查找复杂度变为 O(n)
- 当前实现的时间复杂度是多少?
- 查找、插入、删除:平均 O(1),最坏 O(n)
- 如果有大量设备同时连接,这个实现能应对吗?
- 能,通过动态扩容和负载因子控制,可适应大规模数据
- 扩容过程中如果内存分配失败会怎样?
- 新桶分配失败时保留原表,但可能处于不一致状态
- 为什么使用头插法插入链表?
- 实现简单,插入操作为 O(1)
关于线程安全
- 采用查找和操作分离的策略,hasp只用于查找,并且更多的用于查找,因为设置的是一个全局读写锁,适用于读多写少的场景,而且性能开销比互斥锁、分段锁小
- 内存分配失败时锁未释放,确保所有退出路径都释放锁
- 多线程同时触发扩容,添加扩容标志和双重检查(扩容标志与大小)
- 死锁解决:put调用resize_internal(不加锁函数)
- resize调用resize_internal(不加锁函数)
- 当前实现的局限性
- 所有操作都使用全局锁,可能成为性能瓶颈
- 扩容期间所有操作都会被阻塞
- 没有实现迭代器的安全遍历机制
关于实际应用
- 如果需要遍历所有设备,这个实现的效率如何?
- 效率较低,需要遍历所有桶和链表节点
- 如何处理设备断开连接的情况?
- 调用 hash_map_remove 删除对应 fd 的节点
自定义堆区动态内存配置机制
设计一套基于静态内存池的自定义堆内存管理机制,主要用于嵌入式系统或实时系统场景,标准库的malloc/free存在明显缺陷:
- 依赖操作系统动态内存管理,分配 / 释放时间不确定(不符合实时系统 “确定性” 要求);
- 容易产生内存碎片(小空闲块无法合并,导致大内存请求失败);
- 可能因误操作导致堆溢出(无边界检查),且内存使用状态不可控。
1. 堆区结构体与函数指针(对象方法)
typedef struct _MY_HEAP
{void * (*malloc)(uint32_t xWantedSize); // 分配堆区内存void (*free)(void *pv); // 释放堆区内存 uint32_t(*get_free_heapsize)(void); // 获取当前可用堆大小uint32_t(*get_min_ever_free_heapsize)(void); // 获取历史最小可用堆大小
}c_my_heap;
2. 创建实体对象,并为函数指针确定指向的具体实现函数
const c_my_heap my_heap = {.malloc = my_heap_malloc,.free = my_heap_free,.get_free_heapsize = my_heap_get_free_heapsize, .get_min_ever_free_heapsize = my_heap_get_min_ever_free_heapsize
};
// 获取单例实例的函数
const c_my_heap* get_my_heap_instance(void) {return &my_heap;
}
3. 内存对齐核心变量
// 对齐字节数
#define portBYTE_ALIGNMENT 8
// 对齐字节掩码 用于内存对齐
#define portBYTE_ALIGNMENT_MASK (portBYTE_ALIGNMENT - 1)
// 对一个字节或者内存进行对齐 ******核心操作******
uint32_t address = (address + portBYTE_ALIGNMENT_MASK) & ~portBYTE_ALIGNMENT_MASK
4. 空闲内存块设计
// 定义块链接结构体
typedef struct A_BLOCK_LINK {struct A_BLOCK_LINK *pxNextFreeBlock; // 指向下一个空闲块 size_t xBlockSize; // 空闲块的大小
} BlockLink_t;// 空闲块也必须做内存对齐
static const uint32_t xHeapStructSize = (sizeof(BlockLink_t) + portBYTE_ALIGNMENT_MASK) & (~portBYTE_ALIGNMENT_MASK);// 定义一个最小块,因为后期获取的空闲内存块可能可以分成两块,即可以分割的最小块大小
#define heapMINIMUM_BLOCK_SIZE (size_t)((xHeapStructSize << 1)) // 最小块大小
5. 其他核心变量
// 内存池区域 从数组的起点地址开始维护一段 4096 字节的内存
static uint8_t ucHeap[ configTOTAL_HEAP_SIZE ];
// 空闲内存块头尾指针,都是哨兵节点
static BlockLink_t xStart, *pxEnd = NULL;// 获取 uint32_t 类型的最高位。
// 当该位在 BlockLink_t 的 xBlockSize 成员中被设置时,块属于应用程序。
// 当该位未设置时,该块仍然是自由堆空间的一部分。
static uint32_t xBlockAllocatedBit = 0; // 初始化函数中初始化为0x80000000 (1 << 31)// 记录剩余可用字节数,但不能显示内存碎片
static uint32_t xFreeBytesRemaining = 0U;
static uint32_t xMinimumEverFreeBytesRemaining = 0U;
私有函数实现
-
堆区内存初始化:

- 起始内存对齐 -> 确定头尾哨兵节点(尾指针内存对齐) -> 初始化唯一空闲内存块 -> 统计内存剩余信息 -> 初始化内存分配标记位
static void my_heap_init( void ) {BlockLink_t *pxFirstFreeBlock; // 指向第一个空闲内存块的指针uint8_t *pucAlignedHeap; // 对齐后的堆起始地址uint32_t uxAddress;uint32_t xTotalHeapSize = configTOTAL_HEAP_SIZE; // 调整后的实际可用堆大小// 1. 地址对齐开始处理uxAddress = (uint32_t)ucHeap;if ((uxAddress & portBYTE_ALIGNMENT_MASK) != 0){// (1) 先加上对齐边界减1的值, 确保跨越下一个对齐边界uxAddress += (portBYTE_ALIGNMENT - 1);// (2) 通过与操作清除低位,实现向下对齐uxAddress &= ~( (uint32_t) portBYTE_ALIGNMENT_MASK );// (3) 调整总堆大小xTotalHeapSize -= uxAddress - (uint32_t)ucHeap;}pucAlignedHeap = (uint8_t *)uxAddress;// 2. 初始化链表头尾节点:// xStart 用于持有空闲块链表的第一个元素的指针xStart.pxNextFreeBlock = (void *)pucAlignedHeap;xStart.xBlockSize = (uint32_t)0;// pxEnd 用于标记空闲块链表的结束,并插入在堆空间的末尾。uxAddress = ((uint32_t)pucAlignedHeap) + xTotalHeapSize;uxAddress -= sizeof(BlockLink_t); // 留出一块做内存对齐,并防止越界访问uxAddress &= ~( (uint32_t) portBYTE_ALIGNMENT_MASK );pxEnd = (void *)uxAddress; // 设置 pxEnd 为堆的末尾pxEnd->xBlockSize = 0; // 结束块的大小设置为0pxEnd->pxNextFreeBlock = NULL; // 下一个指针设为NULL// 3. 初始化唯一空闲块 开始时只有一个空闲块,该块的大小为整个堆空间pxFirstFreeBlock = (void *)pucAlignedHeap;pxFirstFreeBlock->xBlockSize = uxAddress - (uint32_t)pxFirstFreeBlock; // 计算空闲块大小pxFirstFreeBlock->pxNextFreeBlock = pxEnd; // 链接到结束块// 4. 初始化统计信息:仅有一个块,覆盖整个可用堆空间。xMinimumEverFreeBytesRemaining = pxFirstFreeBlock->xBlockSize; // 初始化最小可用xFreeBytesRemaining = pxFirstFreeBlock->xBlockSize; // 初始化可用字节// 5. 分配标志位初始化 uint32_t 变量中顶位的位置。xBlockAllocatedBit = ((uint32_t) 1) << ((sizeof(uint32_t) * heapBITS_PER_BYTE) - 1 ); } -
内存分配 my_heap_malloc
初始化检查 -> 参数检查 -> 调整大小(+xHeapStructSize)并对齐 -> 空闲块检查, 遍历空闲链表寻找合适块 -> 标记返回指向的内存空间,跳过 BlockLink_t 的结构体 -> 块分割处理 -> 创建新块(更新两个块的大小) -> 把新块插入到空闲块链表void *my_heap_malloc( uint32_t xWantedSize ) {BlockLink_t *pxBlock, *pxPreviousBlock, *pxNewBlockLink;void *pvReturn = NULL;// 1. 初始化检查if( pxEnd == NULL ) my_heap_init();// 2. 参数校验// 检查请求的块大小是否过大,最高位应设置为 0if( ( xWantedSize & xBlockAllocatedBit ) == 0 ) {if( xWantedSize > 0 ){// 3. 大小调整xWantedSize += xHeapStructSize; // (1) 增加块头大小// (2) 进行内存对齐处理if((xWantedSize & portBYTE_ALIGNMENT_MASK ) != 0)xWantedSize = (xWantedSize + portBYTE_ALIGNMENT_MASK) & (~portBYTE_ALIGNMENT_MASK);}// 4. 空闲内存检查: 确认有足够剩余内存if((xWantedSize > 0 ) && (xWantedSize <= xFreeBytesRemaining)){// 5. 空闲块查找:遍历空闲链表寻找合适块 // 从低地址块开始遍历链表,直到找到合适大小的块。pxPreviousBlock = &xStart;pxBlock = xStart.pxNextFreeBlock;while((pxBlock->xBlockSize < xWantedSize ) && (pxBlock->pxNextFreeBlock != NULL)){pxPreviousBlock = pxBlock;pxBlock = pxBlock->pxNextFreeBlock;}// 如果到达了结束标志,则未找到合适大小的块。if( pxBlock != pxEnd ){// 6. 标记返回指向的内存空间,跳过 BlockLink_t 的结构体pvReturn = (void *)((( uint8_t *) pxPreviousBlock->pxNextFreeBlock) + xHeapStructSize);// 此块正在被返回使用,因此必须将其从空闲块列表中移除。pxPreviousBlock->pxNextFreeBlock = pxBlock->pxNextFreeBlock;// 7. 块分割处理:如果找到的块过大,进行分割if( ( pxBlock->xBlockSize - xWantedSize ) > heapMINIMUM_BLOCK_SIZE ){// 该块要拆分为两个块。创建在请求的字节之后的新块。pxNewBlockLink = ( void * ) (((uint8_t *)pxBlock) + xWantedSize );// 更新后面一块与前面分配内存的一个块的大小pxNewBlockLink->xBlockSize = pxBlock->xBlockSize - xWantedSize;pxBlock->xBlockSize = xWantedSize;// 将新块插入空闲块列表中。 my_heap_insert_block_into_freelist( pxNewBlockLink );}// 更新剩余字节数xFreeBytesRemaining -= pxBlock->xBlockSize;if( xFreeBytesRemaining < xMinimumEverFreeBytesRemaining ){xMinimumEverFreeBytesRemaining = xFreeBytesRemaining;}// 此块正在被返回 - 它已分配并归应用程序所有,并且没有“下一个”块。 */pxBlock->xBlockSize |= xBlockAllocatedBit;pxBlock->pxNextFreeBlock = NULL; // 设置下一个块指针为 NULL}}}return pvReturn; } -
往空闲块链表中插入一个空闲块
- 找合适的位置,从头开始,找到第一个pxIterator->next > Insert的地址,Interator是Insert前面一个块的地址,这里数字当然是为了便于理解,实际的是内存对齐的

-
找到合适的空闲块插入的前一个块起始地址Interator
// 遍历链表,找到适合插入的新块位置 BlockLink_t *pxIterator = &xStart; while(pxIterator->pxNextFreeBlock < pxBlockToInsert){pxIterator = pxIterator->pxNextFreeBlock } -
前序合并
// 可能与前一个块合并 puc = (uint8_t *)pxIterator; if ((puc + pxIterator->xBlockSize) == (uint8_t *)pxBlockToInsert) {pxIterator->xBlockSize += pxBlockToInsert->xBlockSize; // 合并块pxBlockToInsert = pxIterator; // 更新插入块 } // 这里可能先与前面的块合并后继续与后续的块合并,走下面的逻辑 -
后续合并
// 可能与后一个块合并 puc = (uint8_t *)pxBlockToInsert; if ((puc + pxBlockToInsert->xBlockSize) == (uint8_t *)pxIterator->pxNextFreeBlock) {if (pxIterator->pxNextFreeBlock != pxEnd) {/* 合并两个块 */pxBlockToInsert->xBlockSize += pxIterator->pxNextFreeBlock->xBlockSize;pxBlockToInsert->pxNextFreeBlock = pxIterator->pxNextFreeBlock->pxNextFreeBlock; // 更新链表} else {pxBlockToInsert->pxNextFreeBlock = pxEnd; // 更新结束块} } // 插入新块 insert->next else {pxBlockToInsert->pxNextFreeBlock = pxIterator->pxNextFreeBlock; }
-
完整插入空闲块代码
static void my_heap_insert_block_into_freelist(BlockLink_t *pxBlockToInsert){BlockLink_t *pxIterator;uint8_t *puc;// 遍历链表,找到适合插入的新块位置pxIterator = &xStart;while(pxIterator->pxNextFreeBlock < pxBlockToInsert){pxIterator = pxIterator->pxNextFreeBlock;}// 可能与前一个块合并puc = (uint8_t *)pxIterator;if ((puc + pxIterator->xBlockSize) == (uint8_t *)pxBlockToInsert) {pxIterator->xBlockSize += pxBlockToInsert->xBlockSize; // 合并块pxBlockToInsert = pxIterator; // 更新插入块}/* 可能与后一个块合并 */puc = (uint8_t *)pxBlockToInsert;if ((puc + pxBlockToInsert->xBlockSize) == (uint8_t *)pxIterator->pxNextFreeBlock) {/* 合并两个块 */if (pxIterator->pxNextFreeBlock != pxEnd) {// 更新块大小pxBlockToInsert->xBlockSize += pxIterator->pxNextFreeBlock->xBlockSize;// 更新链表pxBlockToInsert->pxNextFreeBlock = pxIterator->pxNextFreeBlock->pxNextFreeBlock; } else {pxBlockToInsert->pxNextFreeBlock = pxEnd; // 更新结束块}} // 插入新块 insert->nextelse {pxBlockToInsert->pxNextFreeBlock = pxIterator->pxNextFreeBlock;}// 如果未发生合并,插入块 前面连接 insertif (pxIterator != pxBlockToInsert) {pxIterator->pxNextFreeBlock = pxBlockToInsert;}} -
内存释放
void my_heap_free( void *pv ) {uint8_t *puc = ( uint8_t * ) pv;BlockLink_t *pxLink;if( pv != NULL ){/* 被释放的内存会在它前面有一个 BlockLink_t 结构。 */puc -= xHeapStructSize;if( ( pxLink->xBlockSize & xBlockAllocatedBit ) != 0 ){/* 该块正在返回给堆 - 它不再属于已分配块。 */pxLink->xBlockSize &= ~xBlockAllocatedBit;/* 将该块添加到空闲块列表。 */xFreeBytesRemaining += pxLink->xBlockSize;my_heap_insert_block_into_freelist( ( ( BlockLink_t * ) pxLink ) );}} }
结合代码细节,该实现的核心优势如下:
- 内存使用可控
- 堆大小由
configTOTAL_HEAP_SIZE固定(基于静态数组ucHeap),避免堆无限制增长导致的内存溢出; - 通过
xFreeBytesRemaining和xMinimumEverFreeBytesRemaining跟踪内存使用,便于调试和资源监控。
- 堆大小由
- 分配效率与确定性
- 基于链表管理空闲块,遍历和插入操作逻辑简单,避免标准库复杂的系统调用开销;
- 分配 / 释放时间可预测(无复杂算法),符合实时系统对 “操作耗时固定” 的要求。
- 减少内存碎片
- 释放内存时通过
my_heap_insert_block_into_freelist实现双向合并(与前 / 后空闲块合并),减少外部碎片; - 分配时若空闲块过大,会拆分出多余部分重新加入空闲链表(
pxNewBlockLink逻辑),提高内存利用率。
- 释放内存时通过
- 适配硬件要求
- 强制内存对齐(
portBYTE_ALIGNMENT处理),确保分配的内存地址符合硬件访问要求(如某些 CPU 需 4 字节 / 8 字节对齐); - 无动态内存依赖(基于静态数组),适合无操作系统或资源受限的嵌入式芯片(如 MCU)。
- 强制内存对齐(
- 可维护性与安全性
- 封装为单例模式(
c_my_heap结构体),避免多实例冲突,便于全局管理; - 通过
xBlockAllocatedBit标记块是否分配,防止重复释放或非法访问。
- 封装为单例模式(
常见问题与解答
1. 为什么不使用标准库的malloc/free,而要自定义堆管理?
- 标准库
malloc/free分配时间不确定(依赖系统内存管理策略),不适合实时系统; - 容易产生内存碎片,且无法控制堆大小(可能溢出到其他内存区域);
- 嵌入式系统资源有限(如小容量 RAM),自定义堆可基于静态数组固定大小,避免内存滥用。
2. 内存对齐是如何实现的?为什么需要内存对齐?
- 通过
(xWantedSize + portBYTE_ALIGNMENT_MASK) & (~portBYTE_ALIGNMENT_MASK)调整大小,通过uxAddress &= ~portBYTE_ALIGNMENT_MASK调整地址,确保满足portBYTE_ALIGNMENT对齐要求; - 原因:硬件限制(如 CPU 访问非对齐地址可能报错或性能下降),同时保证
BlockLink_t结构体成员(如指针)的正确访问。
3. 如何处理内存碎片?代码中具体做了哪些操作?
- 主要通过空闲块合并解决外部碎片:
- 释放内存时,
my_heap_insert_block_into_freelist先检查前序块(pxIterator)是否相邻,若相邻则合并; - 再检查后序块(
pxIterator->pxNextFreeBlock)是否相邻,若相邻则合并;
- 释放内存时,
- 分配时若空闲块过大(剩余空间 > 最小块大小
heapMINIMUM_BLOCK_SIZE),会拆分出多余部分重新加入空闲链表,避免大空闲块被浪费。
4. 代码中用链表管理空闲块,为什么选择链表而不是其他数据结构(如树)
- 嵌入式系统对内存和计算资源敏感,链表实现简单(仅需指针和大小字段),内存开销小;
- 代码中空闲块按地址有序排列(遍历插入时保证
pxIterator->pxNextFreeBlock < pxBlockToInsert),线性遍历即可满足需求,无需更复杂的树结构(如二叉树); - 实时系统更关注 “确定性” 而非极致性能,链表的固定操作耗时更符合要求。
5. 堆初始化(my_heap_init)主要做了哪些工作?
- 地址对齐:调整
ucHeap的起始地址,确保满足对齐要求; - 初始化链表:创建哨兵节点
xStart和pxEnd,将整个ucHeap初始化为一个大空闲块,加入链表; - 初始化统计信息:设置
xFreeBytesRemaining(初始为总大小)和xMinimumEverFreeBytesRemaining(跟踪最小剩余内存); - 初始化分配标志位:计算
xBlockAllocatedBit(uint32_t的最高位)。
6.xBlockAllocatedBit的作用是什么?如何避免重复释放?
- 作用:
xBlockAllocatedBit是xBlockSize的最高位,用于标记块是否被分配(置位表示已分配,清零表示空闲); - 避免重复释放:
my_heap_free中先检查(pxLink->xBlockSize & xBlockAllocatedBit) != 0,仅当块处于 “已分配” 状态时才执行释放,防止重复释放导致的链表错乱。
7. 代码是否支持多线程?若不支持,如何改进?
- 不支持。当前代码无互斥机制,多线程同时调用
my_heap_malloc或my_heap_free可能导致链表指针错乱(如同时修改pxNextFreeBlock); - 改进:添加互斥锁(如嵌入式中的
vTaskSuspendAll/xTaskResumeAll,或 POSIX 的pthread_mutex),确保内存操作的原子性。
8. xStart是BlockLink_t变量而非指针,为什么这样设计?
- xStart是哨兵节点(dummy node),作为空闲链表的固定头部,简化链表操作:
- 遍历从
&xStart开始,无需判断 “头指针是否为 NULL”(避免空指针检查); - 插入新块时,
pxIterator从xStart开始遍历,确保总能找到前序节点,统一处理边界情况(如链表为空时)。
epoll并发服务器
为什么在 “多连接少活跃” 场景下选择 epoll 而不是 select/poll?
- select/poll 采用 “轮询” 机制,每次需遍历所有注册的文件描述符(fd),时间复杂度为 O (n),连接数增多时效率急剧下降;
- epoll 基于 “事件通知” 机制,通过红黑树管理注册的 fd(O (1) 增删),就绪事件通过就绪链表返回(仅遍历活跃 fd),时间复杂度为 O (1),适合多连接但活跃少的场景;
- 此外,select 有 fd 数量上限(受限于 FD_SETSIZE),而 epoll 无此限制(仅受系统内存限制)。
触发方式,你用了什么,为什么
-
水平触发 模式:只要 fd 缓冲区有数据未读,就会持续触发 EPOLLIN 事件;
-
边缘触发 模式:仅在 fd 状态由 “无数据” 变为 “有数据” 时触发一次 EPOLLIN 事件(需一次性读完所有数据,否则可能丢失事件);
-
多连接少活跃场景使用水平触发 模式:因为活跃连接少,LT 的 “重复通知” 不会带来明显性能损耗,且编程更简单(无需处理 “一次性读完” 的逻辑,减少漏读风险);边缘触发 适合高活跃场景,但需更复杂的读写逻辑(如循环读直到 EAGAIN)。
epoll如何管理多连接,接入流程是什么
-
流程:创建监听 socket(socket ())→ 绑定端口(bind ())→ 监听(listen ())→ 创建 epoll 实例(epoll_create ())→ 将监听 socket 注册到 epoll(epoll_ctl (EPOLL_CTL_ADD, EPOLLIN))→ 进入事件循环(epoll_wait ());
-
新连接处理:当监听 socket 触发 EPOLLIN 事件时,调用 accept () 获取新连接的 fd,设置新 fd 为非阻塞(避免 IO 阻塞),将其注册到 epoll(关注 EPOLLIN 事件),并为该连接分配环形缓冲区等资源。
如何避免 epoll 的 “惊群效应”?
-
惊群效应指多个线程阻塞在 epoll_wait () 时**,一个事件触发会唤醒所有线程**,但最终只有一个线程处理,导致资源浪费;
-
单线程处理 epoll 事件(适合多连接少活跃场景,避免线程切换开销);
-
若用多线程,可通过 “EPOLLONESHOT” 标记:事件触发后自动禁用该 fd 的事件通知,处理完后重新启用,确保一个事件仅被一个线程处理。
如何管理每个连接的状态?连接超时如何检测和处理?
- 连接状态管理:为每个连接维护结构体(包含 fd、环形缓冲区、最后活跃时间、状态(连接中 / 关闭中)等),用哈希表(fd→连接结构体)快速索引;
- 超时检测:
- 定期轮询(如每隔 10 秒遍历所有连接,检查最后活跃时间与当前时间差,超过阈值则关闭);
- 结合 epoll 的 EPOLLRDHUP 事件检测对方主动关闭,避免僵尸连接;
- **处理流程:**超时连接→从 epoll 中移除(epoll_ctl (EPOLL_CTL_DEL))→关闭 fd→释放环形缓冲区和连接结构体资源。
区分 “新连接事件” 和 “已连接的 IO 事件”?如何处理读写事件?
- 区分事件:监听 socket 的 fd 是固定的,事件循环中通过 fd 是否为监听 fd 判断:是则处理新连接(accept ()),否则处理已连接的 IO 事件;
- 读事件(EPOLLIN):从 fd 读取数据到环形缓冲区,调用粘包解析逻辑提取完整数据包,交给业务层处理;
- 写事件(EPOLLOUT):仅在有数据待发送时注册(避免空轮询),从发送缓冲区写数据到 fd,写完后取消 EPOLLOUT 注册。
如何处理 “连接断开” 的情况?如何避免资源泄漏?
- 断开检测:通过 read () 返回 0(正常断开)或 - 1 且 errno 为 ECONNRESET(异常断开)判断;
- 处理流程:
- 从 epoll 中删除该 fd(epoll_ctl (EPOLL_CTL_DEL));
- 关闭 fd(close ());
- 释放环形缓冲区、连接结构体等资源;
- 从哈希表中移除该连接的索引,避免后续操作访问无效指针。
如何优化 epoll 的性能?(如减少系统调用、降低开销)
- 减少 epoll_ctl 调用:连接建立后尽量不频繁修改事件(如用 EPOLLONESHOT 时仅在处理完事件后重新启用);
- 合理设置 epoll_wait 超时时间:避免无限阻塞(便于处理定时任务,如超时检测);
- 使用非阻塞 IO:所有 socket(监听和连接)设为非阻塞(fcntl (F_SETFL, O_NONBLOCK)),避免 IO 操作阻塞事件循环;
- 批量处理事件:epoll_wait 返回的事件列表一次性处理,减少循环次数。
如果场景变为 “多连接高活跃”,你的框架需要做哪些调整?
- 触发模式:从 LT 改为 ET(减少重复通知,降低 CPU 开销),需实现 “循环读直到 EAGAIN” 的逻辑;
- 多线程:引入线程池,将数据包处理任务分发到业务线程(IO 线程仅负责读写,避免阻塞);
- 缓冲区:增大环形缓冲区大小,或引入动态扩容机制;
- 负载均衡:若单机压力过大,可引入多机分布式架构(如用 Nginx 代理 TCP 连接)。
环形缓冲区与粘包问题
TCP 粘包 / 半包的原因是什么?如何通过环形缓冲区解决?
-
粘包原因:TCP 是 “流协议”,无消息边界,数据会按 MTU(数据链路层规定的帧大小) / 滑动窗口拆分或合并发送(如连续小数据包合并,或大数据包拆分);
-
环形缓冲区作用:暂存读取的字节流,通过 “数据包解析逻辑” 从缓冲区中提取完整消息;
-
解决流程:
- 读取数据到环形缓冲区(保证数据不丢失);
- 按协议格式(如 “头部 + 长度”)解析缓冲区:先读头部获取包长度,判断缓冲区数据是否足够;
- 若数据足够,提取完整数据包并处理;若不足,等待下一次数据到来后继续解析。
环形缓冲区的核心结构是什么?如何实现 “环形”(避免内存碎片)?
-
核心结构:固定大小的数组(或内存块)+ 读指针(read_idx)+ 写指针(write_idx)+ 缓冲区大小(size);
-
环形实现:通过 “取模运算” 让指针在到达末尾后回到起点(如
write_idx = (write_idx + 1) % size); -
空 / 满判断:
- 空:
read_idx == write_idx; - 满:
(write_idx + 1) % size == read_idx(预留一个空位置区分空和满)。
- 空:
环形缓冲区满了怎么办?如何设置缓冲区大小?
- 缓冲区满时策略:
- 丢弃新数据(适合非核心场景,需记录丢弃计数用于监控);
- 阻塞等待(不适合非阻塞 IO 框架,会导致线程挂起);
- 动态扩容 括1次,设置最大容器大小(环形缓冲区通常固定大小,扩容需拷贝数据,适合低频扩容场景);
- 大小设置:根据业务平均包大小和最大并发连接数估算,例如:若单连接最大包为 16KB,并发 1000 连接,单个缓冲区可设为 32KB(留冗余),总内存可控。
环形缓冲区如何保证线程安全
- 若单线程处理 epoll 事件(读写同一连接的缓冲区),无需加锁(线程内串行);
- 若多线程(如 IO 线程读缓冲区,业务线程写缓冲区),需轻量级同步:
- 用互斥锁(mutex)保护读写指针;
- 或用原子操作(atomic)标记指针状态(如 CAS 操作更新读写位置);
- 避免用重量级锁,否则可能抵消 epoll 的性能优势。
环形缓冲区在高并发下可能出现什么问题?如何优化?
- 可能问题:读写指针竞争(多线程下锁开销)、缓冲区过小导致频繁丢弃数据、内存拷贝过多;
- 优化:
- 单线程读写(IO 线程内处理,避免锁);
- 预分配足够大的缓冲区(根据业务峰值估算);
- 减少拷贝:用分散读(readv)直接将数据读入缓冲区,避免中间缓冲区;
- 对齐内存:缓冲区大小设为 2 的幂次,用位运算替代取模(
idx % size→idx & (size-1)),提高运算效率。
除了环形缓冲区,还有哪些解决粘包的方案?它们的优缺点是什么?
- 固定长度:每个数据包大小固定,不足补空。优点:解析简单;缺点:灵活性差(不适合动态长度数据),空间浪费。
- 分隔符:用特殊字符(如 ‘\r\n’)标记包结束。优点:实现简单;缺点:需避免数据中包含分隔符(需转义,增加复杂度)。
- 头部 + 长度:数据包前加固定长度的头部(含数据长度)。优点:灵活支持任意长度数据;缺点:需先读头部再读数据(两次解析),环形缓冲区可优化此流程(一次读入后解析)。
xv6操作系统内核
系统调用

alarm 系统调用
- 添加新的系统调用
- 保存 sigalarm 的报警间隔与 handler 指针,保存在 struct proc 中新的字段,并在proc.c中allocproc初始化字段
sys_sigalarm:
获取用户参数
argint(0, &ticks);
argaddr(1, &handler);
// 保存参数
p->ticks = ticks;
p->handler = handler;
p->ticks_count = 0;sys_sigreturn:
p->is_handling = 0; 清空中断标记位
memmove(p->trapframe, p->save_trap_frame, PGSIZE); 中断返回 保存现场的地址
页表
页表(Page Table)是操作系统中用于实现虚拟内存管理的核心数据结构,它负责将进程的虚拟地址(Virtual Address)转换为实际的物理地址(Physical Address)。通过分页机制,操作系统能够更高效、安全地管理内存资源。
1. 页表的核心作用
- 地址映射: 每个进程“看到”的是一个连续的虚拟地址空间(如0x0000 ~ 0xFFFF)。实际上,物理内存可能分散且不连续。页表记录了 虚拟页号 → 物理页框号 的映射关系,由CPU的 内存管理单元(MMU) 自动完成地址转换。
- 内存保护: 页表中的每个条目(页表项)包含权限标志位,如:
- 简化内存管理: 以分页的方式管理内存,支持动态内存分配和释放。当某个虚拟页未在物理内存中时,触发触发缺页中断(Page Fault),操作系统会从磁盘(如Swap分区)加载所需页面到内存,并更新页表。这使得物理内存成为磁盘的缓存,突破了内存容量限制。
- 实现虚拟内存: 页表是虚拟内存管理的基础支持。借助页表,操作系统能够将程序需要的内存部分保存在磁盘上(例如交换空间),并在需要时动态加载到内存中,从而使得程序可以使用更大的内存空间,提升系统的扩展能力和性能。
虚拟内存和物理内存通常被划分为固定大小的块,称为“页”(Page)和 “页框号”(Frame)。每个页面由相同数量的连续字节组成,常见的页面大小有4KB、8KB等。
页表的结构: 页表主要包含每个 虚拟页号(VPN) 对应的 物理页框号(PPN)
地址转换过程: 在访问内存时 ,CPU会将虚拟地址划分为页号和页内偏移(offset),具体步骤如下:
- 获取虚拟页号: 从虚拟地址中提取页号部分。
- 查找页表: 使用虚拟页号查询相应的页表项,获取物理页框号。
- 构建物理地址: 将物理页框号与原虚拟地址中的页内偏移结合,生成物理地址,访问实际的内存。
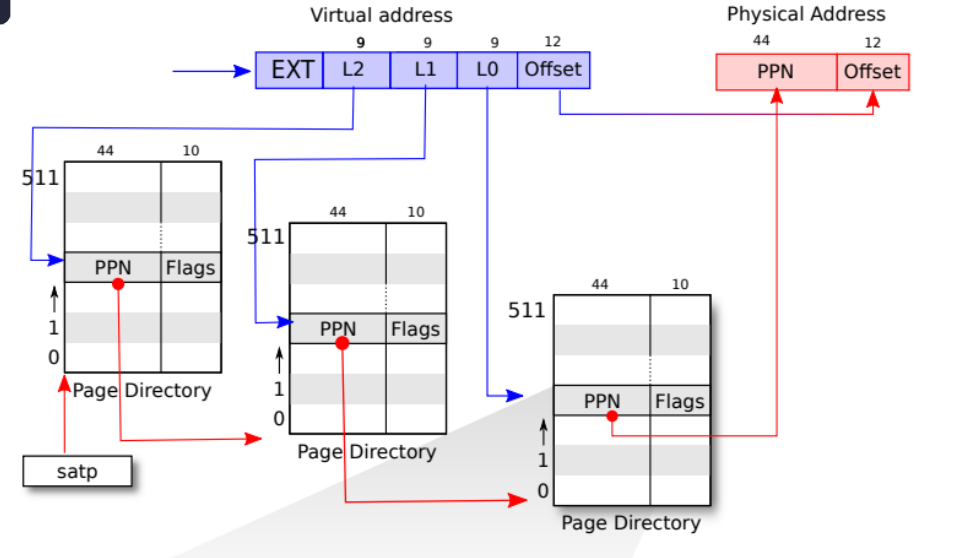
- 页表page table: 记录从VPN→PPN的映射关系表
- 页表项 PTE: 页表中的每一项,具体内容如上述中的解释
- 虚拟页号VPN: virtual page number
- 物理页号PPN/PFN: physical page number
- 页内偏移量offset: 偏移量的位数决定了一页的大小,一般是12位,即4KB
- 虚拟地址va: virtual address相当于VPN与offset的组合
- 物理地址pa: physical address相当于PFN/PPN与offset的组合
- 物理页帧: page frame
一、为每个进程分配一个页表
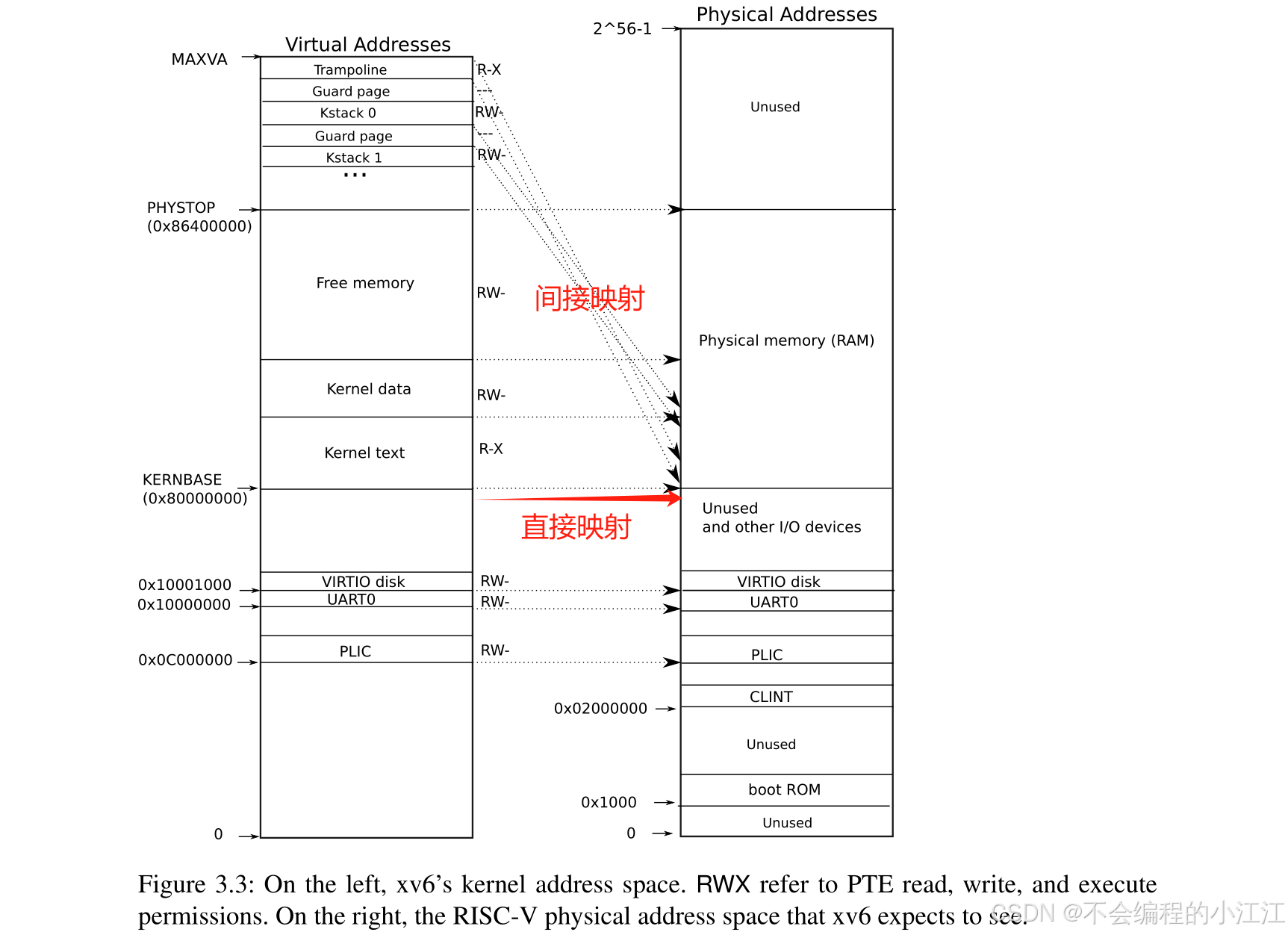
当前xv6操作系统中,在用户态下的每个用户进程都使用各自的用户态页表。一旦进入了内核态(例如系统调用)就会切换到内核态页表。然而这个内核态页表是全局共享的。如果一个进程因为 bug 或恶意操作访问了内核中的敏感数据,它可能会影响其他进程或系统的整体稳定性。

- 创建内核页表: 普通进程也可以通过调用 kvm_map_pagetble 函数来创建自己的内核页表了,此时在内核态中就有两种页表:一种是内核进程独享的页表,另一种是其他进程各自独享的页表
- 重映射内核栈: 原本的 xv6 设计中,所有处于内核态的进程都共享同一个页表,即意味着共享同一个地址空间。由于 xv6 支持多核/多进程调度,同一时间可能会有多个进程处于内核态,所以需要对所有处于内核态的进程创建其独立的内核态内的栈,也就是内核栈,供给其内核态代码执行过程。
- 在已经添加的新修改中,每一个进程都会有自己独立的内核页表。而现在需要每个进程只访问自己的内核栈,所以可以把每个进程的内核栈映射到各自内核页表的固定位置(不同页表内的同一逻辑地址,指向不同物理内存)
- 资源释放: 先释放进程的内核栈,再释放进程的内核页表。这里不能使用 proc_freepagetable 函数直接释放页表,因为该函数会释放掉内核进程必要的映射,导致内核崩溃。这里释放的只是内核页表中的所有映射,不释放其指向的物理页。 因为物理页的资源不是这一个进程独享的
二、简化copyin / copyinstr:将用户页表中的映射同步到每个进程的内核页表中。这样,内核可以直接使用硬件页表机制来访问用户空间的内存,而不需要手动解析页表。
- 页表复制和缩减内存函数: 首先在 kernel/vm.c 实现一个复制页表函数,将 src 页表的一部分页映射关系拷贝到 dst 页表中。只拷贝页表项, 不拷贝实际的物理页内存
- 处理内存映射捏的冲突
- 用户态页表修改,同步数据到内核页表
惰性分配与缺页
- 缺页异常:应该是指操作系统在分配内存时不会立即分配物理内存,仅分配虚拟地址空间,不分配物理页。
惰性机制优点: 应用程序往往请求比实际需要更多的内存,通过性分配,系统仅在真正使用内存时才进行分配,避免了大量内存浪费
当出现缺页异常,需调入新页面内存已满时,选择被置换的物理页面,也就是说选择⼀个物理页面换出到磁盘,然后把需要访问的页面换入到物理页。
- 引起page fault的内存地址 STVAL寄存器
- 引起page fault的原因类型 SCAUSE寄存器
写时拷贝
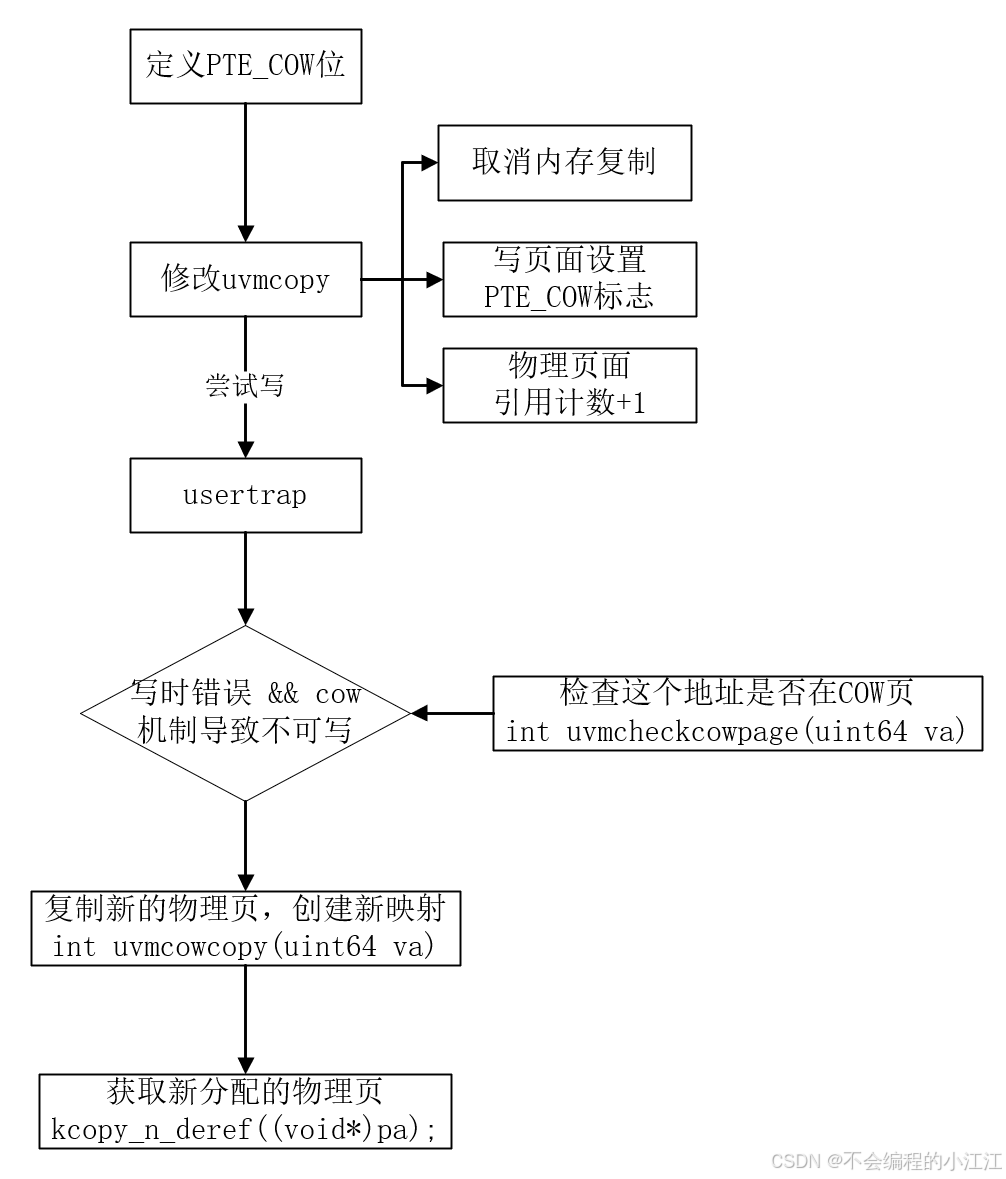
在原始的XV6中,fork函数是通过直接对进程的地址空间完整地复制一份来实现的。但是,拷贝整个地址空间是十分耗时的,并且在很多情况下,程序立即调用 exec 函数来替换掉地址空间,导致 fork 做了很多无用功。
该实验的改进:
- COW fork() 为子进程创建一个页表,让子进程和父进程都一起映射到父进程的物理页
- 禁止写权限,因为一旦子进程想要修改这些内存的内容,相应的更新应该对父进程不可见,因此需要将这里的父进程和子进程的PTE的标志位都设置成只读的
- 当任一进程试图写入其中一个COW页时,CPU将强制产生页面错误。内核页面错误处理程序检测到这种情况,将为出错进程分配一页物理内存,将原始页复制到新页中,并修改出错进程中的相关PTE指向新的页面,将PTE标记为可写。
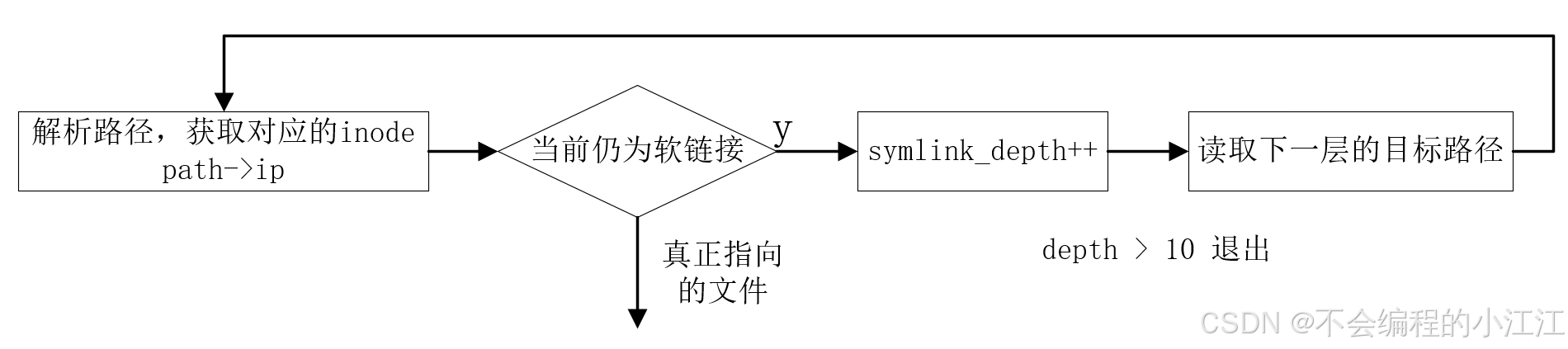
大文件与软链接
xv6文件系统层次: 从上至下分别为 文件描述符、路径名、目标、索引节点、日志、缓冲区高速缓存、磁盘
索引节点 inode:
-
type字段: 文件类型,表明inode是文件还是目录
-
nlink字段:,也就是link计数器,用来跟踪究竟有多少文件名指向了当前的inode
-
size字段: 文件大小。表明了文件数据有多少个字节
-
12个直接块编号,这些直接块编号直接指向文件的前 12 个磁盘块。当文件较小时,直接块可以满足文件存储的需求,每个块的大小在 xv6 中是 1KB,因此使用 12 个直接块意味着最多可以存储 12*1KB=12KB 的数据
-
1个间接块编号,指向一个间接块,间接块本身是一个磁盘块,其中包含了 256 个条目,每个条目存储一个数据块编号,这些编号依次指向文件的数据块
添加二级链接块,实现超大文件存储
-
修改 inode 的结构:,修改成11个直接块,1个一级间接块,1个二级间接块。
-
修改逻辑块号与物理块号的映射: 原xv6文件系统中逻辑块号与物理块号的映射关系: 先判断逻辑块号与直接映射的物理块号来确定是否为直接映射,若否则建立间接映射
-
释放节点映射的所有数据块
软链接设计 设计一个软链接系统调用
- 实现具体的 sys_symlink: 使用 create 创建一个加了锁的指向源文件的inode,再将链接目标文件地址通过 writei 写入inode,操作完之后使用 iunlockput 解锁创建的inode并使其引用计数-1,表示创建软链接的操作结束,释放锁。

- 修改
sys_open函数,通过循环调用 namei 获取对应的inode,如果指向的仍是软链接,就继续循环读取,直到找到真正指向的文件,或者超过了一定的链接深度
硬链接 多个目录项中的**「索引节点」指向一个文件,也就是指向同一个 inode**,但是 inode 是不可能跨越文件系统的,每个文件系统都有各自的 inode 数据结构和列表,所以硬链接是不可用于跨文件系统的。由于多个目录项都是指向一个 inode,那么只有删除文件的所有硬链接以及源文件时,系统才会彻底删除该文件。
软链接 相当于重新创建一个文件,这个文件有独立的inode,但是这个文件的内容是另外一个文件的路径,所以访问软链接的时候,实际上相当于访问到了另外一个文件,所以软链接是可以跨文件系统的,其目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已
线程切换实现用户态协程
- 设计用户级线程系统的上下文切换机制,设计一个方法来创建线程,并保存/恢复寄存器以在线程之间切换,
- 添加线程切换上下文数据类型: 上下文结构体寄存器,成员变量-上下文,定义用户线程切换uthread_switch.S中进行保存上下文,恢复上下文
- 汇编thread_switch函数实现保存上下文寄存器
- 在线程切换时候,通过uthread_switch函数切换到汇编,进行上下文切换
1. 添加线程换上下文数据类型(这里的操作模仿进程的context结构体)
-
定义线程上下文结构体寄存器
-
定义线程结构体成员变量-上下文,
-
定义用户线程切换uthread_switch.S中进行保存上下文,恢复上下文
-
定义上下文数据结构
// 用户线程的上下文结构体 struct context {uint64 ra; // return addressuint64 sp; // 栈指针// callee-saveduint64 s0;uint64 s1; }; -
添加上下文至线程成员变量
struct thread {struct context context; // 添加成员变量char stack[STACK_SIZE]; /* the thread's stack */int state; /* FREE, RUNNING, RUNNABLE */ }; -
汇编
thread_switch函数实现保存上下文寄存器thread_switch:/* YOUR CODE HERE */sd ra, 0(a0)sd sp, 8(a0)sd s0, 16(a0)sd s1, 24(a0)ret /* return to ra */
2. 在线程切换时候,通过uthread_switch函数切换到汇编,进行上下文切换: uthread.c / thread_schedule函数
thread_switch(&t->context, &next_thread->context);
if (current_thread != next_thread) { /* switch threads? */next_thread->state = RUNNING;t = current_thread;current_thread = next_thread;// 上下文切换thread_switch(&t->context, &next_thread->context);} elsenext_thread = 0;
3. 创建线程时,初始化线程
// 返回地址, thread_switch线程切换执行完后返回到ra,
// 设置成线程函数func, 就可以切换后执行func
t->context.ra = (uint64)func;
// 栈指针,将线程的栈指针指向其独立的栈,
// 栈的生长是从高地址到低地址,所以要将 sp 设置为指向 stack 的最高地址
t->context.sp = (uint64)t->stack + STACK_SIZE;
C语言
指针 数组 函数 常量
- 数组指针: 数组指针是指向数组的指针变量
int (*p)[5] - 指针数组: 指针数组是一个数组,数组的元素都是指针
int *p[5] - 指针函数: 指针函数是一种返回指针类型的函数,记得malloc
- 函数指针: 函数指针是指向函数的指针变量
void (*p)(Devide *) - 指针与数组名的区别:
- 本质不同: 变量,地址常量
- sizeof大小不同
- 运算不同
- 作为函数参数时的行为
- 取地址(&)行为不同
- 指针常量: 指针常量其实就是一个常量,他的地址是不可的,即指向的对象是不变的,但指向的对象的内容是可变的,因为在指针名前面加上了一个const,地址是个常量
int* const ptr; - **常量指针: ** 指常量指针就是一个指针,常量指的是指针的所指内容。
const int* ptr,但指针可以指向其他不同的常量对象
大端序、小端序
- 大端序: 数据的高位字节存在内存的低地址,数据的低位字节存在内存的高地址
- 小端序: 数据的低位字节存在内存的低地址,数据的高位字节存在内存的高地址
如何判断字节序:
int main()
{int num = 1; // 0x00000001char* ptr = (char*)#if(*ptr == 1)cout << "小端序";else cout << "大端序";
}
为什么要字节序:
- 跨平台兼容性: 不同架构的计算机可能使用不同的字节序方式。
- 网络通信:通过网络传输数据时,不同计算机可能采用不同的字节序,使用网络字节序可以确保数据正确传输
- 硬件差异: 一些硬件平台(如x86、ARM)采用小端序,而一些平台(如某些 RISC系统)采用大端序,标准化字节序能够提高
网络字节序: 网络字节序是为了确保在网络中不同计算机间传输数据时,能够统一数据的存储顺序。它采用的是大端序。
在编程中,为了保证数据的正确性,可以使用一些库函数来进行字节序转换。例如,htonl() 和 ntohl() 用于将数据从主机字节序转换为网络字节序,反之亦然。
htonl():主机到网络字节序(32位)ntohl():网络到主机字节序(32位)
内存对齐
内存对齐是计算机系统中一种重要的内存访问优化机制,它要求数据在内存中的存储地址必须满足特定对齐要求。
元素的起始地址放在其类型大小整数倍的位置上,不满足则需要填充字节
提高性能,高效的读取/写入内存
基本数据:
char 1字节 short 2字节 int 4字节 float 4字节 double 8字节 指针 4/8字节
结构体(struct)对齐
- 规则 1:成员按自身大小对齐。
- 规则 2:结构体成员按其内部最大成员对齐。
- 规则 3:整个结构体大小补齐为最大成员大小的整数倍。
- 编译器可以设置最大对齐值,类型的实际对齐值是该类型的对齐值与默认对齐值取最小值
- GCC 64位 最大对齐值为 8
#pragma pack(show)来显示

应用场景: 嵌入式系统中硬件寄存器访问,网络协议解析, 高性能计算
为什么要这样:
- 硬件优化: 现代CPU(如x86、ARM)通常以对齐的字长(如4字节、8字节)为单位读写内存,未对齐访问可能导致性能下降或硬件异常。
- 缓存效率: 对齐数据能更好利用CPU缓存行(通常64字节),增大缓存命中率
- 减少内存碎片

C++额外注意点:
- 虚基表指针(菱形继承)
- 虚函数表指针(多态)
C语言关键字 staic const extern volatile预处理
static: 声明静态变量(当前文件),声明静态函数(当前文件),声明静态成员变量与成员函数(属于类,多个对象共享)
const: 一旦常量被赋值后,其值将保持不变,不能再对其进行修改,编译时确定,运行时不变,作用域限制
- 应用:声明常量变量,使用 const 参数声明函数,使用 const 修饰函数返回值
const与deifine的区别:
- const是一种编译器关键字,而#define是预处理器指令。const在编译阶段进行处理,而#define在预处理阶段进行处理
- const定义的常量具有类型,而define没有。const在声明时需要指定常量的类型,编译器会进行类型检查。而#define只是简单的文本替换,没有类型检查
- define定义的常量没有作用域限制,整个程序中都有效。
extern: 声明一个在其他文件中定义的外部变量或函数,允许在当前文件中使用这些外部变量或函数而不需要重新定义
volatile: volatile声明的变量是指可能会被意想不到地改变的变量,这样编译器就不会轻易优化该变量
- 多线程中的共享变量
- 中断程序中修改的供其他程序检测的变量
- 并行设备的硬件寄存器
预处理:
- 宏定义
- 文件包含
- 条件编译
它的主要作用是对源代码进行文本级别的处理,为后续的编译阶段做好准备
sizeof 与 strlen
| 对比项 | sizeof | strlen |
|---|---|---|
| 类型 | 编辑期运算符 | 运行时函数(#include) |
| 返回类型 | size_t(表示字节序) | size_t (表示字符串长度) |
| 参数要求 | 变量 / 类型 | const char* |
| 是否包含 \0 | 包含(数组大小) | 不包含(仅字符个数) |
| 计算时间点 | 编辑阶段完成 | 运行阶段,从到遍历直到 \0 |
malloc与calloc的区别
- malloc 分配的内存是未初始化的,calloc 分配的内存会被初始化为全0
- 如果内存分配失败,malloc 返回一个空指针 NULL,通过返回判断是否分配成功,calloc 在分配失败时会自动抛出错误(异常),可以使用异常处理机制来捕获和处理错误。
数组与链表的区别
用链表的目的是什么?省空间还是省时间?
线性表与数组
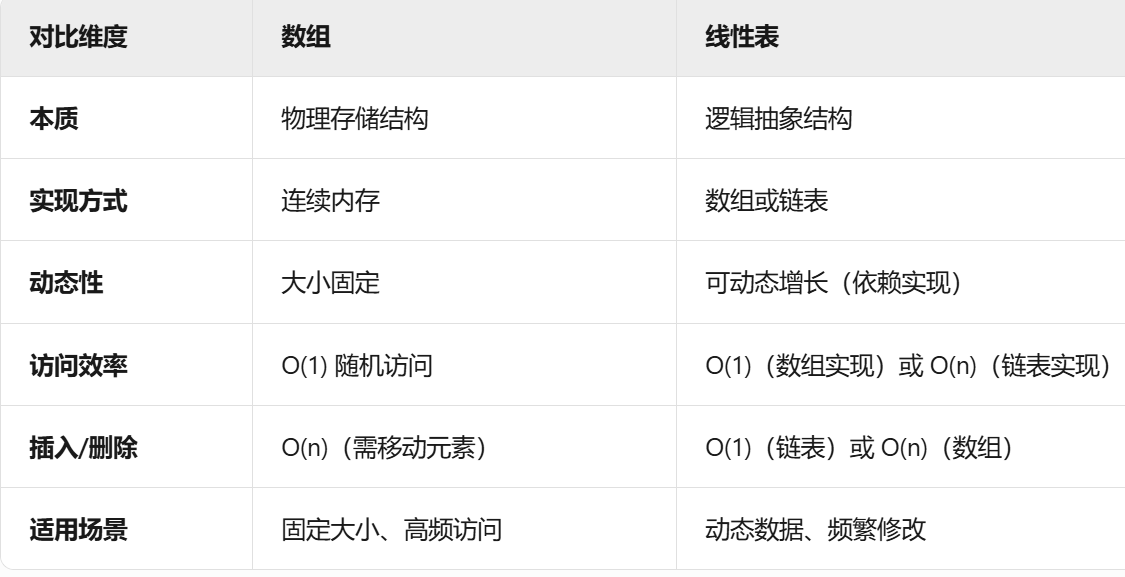
数组与链表
- 存储方式: 数组是连续的,而链表是非连续的
- 内存使用情况: 数组的大小通常是固定的,内存会预先分配好,而链表的大小是动态的,并且除数据外,还需要额外的内存存储next指针,内存相对较大。
- 访问效率: 数组支持随机访问,通过索引可以直接定位到任意元素,时间复杂度为 O(1)。链表只能顺序访问,需要从头节点开始逐个遍历才能找到目标节点,时间复杂度为 O(n)。
- 操作复杂度:数组的插入删除操作位O(n),链表的插入删除操作时间复杂度为O(1)
适用场景
- 数组:适合需要频繁随机访问元素的场景,例如查找某个特定位置的值,数组是更好的选择,例如矩阵运算、图像处理、排序算法等。
- 链表:适合需要频繁插入和删除元素的场景,或内存大小未知、需动态分配、内存不连续等环境更适合用链表,或更复杂的数据结果,例如双向链表、二叉树、图的邻接表, LRU 缓存等等。
有哪些链表:
- 单向链表: 需要从头到尾顺序遍历数据,不需要反向遍历,插入删除频繁
- 双向链表: 需要双向遍历数据,
- 循环链表: 实现循环队列或约瑟夫环问题,需要从任意节点开始遍历整个链表
- 带头节点的链表: 在链表的头部添加一个特殊的节点(哨兵节点),该节点不存储实际数据,简化边界条件的处理,例如插入或删除头节点时的操作
- 静态链表: 使用数组模拟链表,每个数组元素包含数据部分和指向下一个节点的索引,资源受限(嵌入式系统),需要利用数组的连续性优势场景。内存连续,灵活性差
- 跳表: 是一种多层链表结构,每一层包含部分节点,高层节点用于快速跳过中间节点,类似于平衡树,通过概率实现, 需要高效的查找、插入和删除操作。
栈与队列的区别
存取方式、操作位置
栈的应用场景:
- 函数调用(递归)
- 撤销与恢复操作
- 深度优先搜索
- 线程管理:上下文切换
队列的应用场景:
- 任务调度和资源分配,先来先服务算法
- 消息传递 - 消息队列
- 缓存淘汰策略:淘汰最早进入的缓存数据
- 广度优先搜索
- LRU缓存
使用指针需要注意什么?
- 定义指针时,最好将其初始化为 NULL,这样可以避免使用未初始化的指针。
- 在使用 malloc 或 new 分配内存之后,应该立即检查指针的值是否为 NULL,以防止在使用指针值为 NULL 的内存时出现问题。在 C++11 及更高版本中,使用 new 分配内存的时候,如果发生错误,会抛出异常,因此不需要显示判空。
- 当使用指针指向数组或者动态分配的内存时,一定要记得为其赋初值,避免使用未被初始化的内存作为右值。
- 小心避免数字或指针的下标越界,特别是一些常见的“多1”或者“少1”错误。
- 在释放动态分配的内存时,务必确保申请和释放是配对的,以防止内存泄漏。
- 使用 free 或 delete 释放内存后,立即将指针设置为 NULL,以避免出现悬空指针(野指针)。
- 避免指针的多重间接性:多重间接性指的是通过多个指针进行连续的解引用操作。尽量避免过多的间接性,以提高代码的可读性和维护性。
- 注意浅拷贝和深拷贝:如果指针指向的是动态分配的内存,涉及到对象的拷贝或赋值时,需要注意浅拷贝和深拷贝的区别。深拷贝会复制整个对象及其指向的内存,而浅拷贝只是复制指针本身,可能导致多个指针指向同一块内存。
野指针、段错误
野指针
-
野指针是指向不可用内存的指针,当指针被创建时,指针不可能自动指向NULL,这时,默认值是随机的,此时的指针成为野指针。
-
当指针被free或delete释放掉时,如果没有把指针设置为NULL,则会产生野指针,因为释放掉的仅仅是指针指向的内存,并没有把指针本身释放掉。
-
第三个造成野指针的原因是指针操作超越了变量的作用范围
段错误
段错误是 C/C++ 程序中最常见的运行时错误之一,通常是由于非法内存访问导致的。
段错误的原因:
| 段错误的原因 | 避免 |
|---|---|
| 访问未初始化的指针 | 初始化指针 |
| 解引用野指针或空指针, 访问已释放的内存 | 检查指针有效性,避免野指针,释放后置空 |
| 数组越界 | 避免数组越界 |
| 修改只读内存 | 使用 const 保护只读数据 |
| 栈溢出 | 注意递归返回 |
调试段错误的工具 gdb
- run:运行程序
- backtrace(bt):查看调用栈
- print(p):打印变量值
- break(b):设置断点
- next(n):单步执行(不进入函数)
- step(s):单步执行(进入函数)
- continue(c): 跳到下个断点
- info threads
- thread
内存泄漏
内存泄漏: 内存泄漏指程序在动态分配内存(如 malloc、new)后,未能正确释放已不再使用的内存,程序失去对该内存的控制。导致系统可用内存逐渐减少,最终可能引发程序崩溃或系统性能下降
内存泄漏了怎么办:
- 审查代码,malloc与free,new delete是否成对出现
- 点击 VSCode 调试 > 窗口 > 显示诊断工具,运行程序,查看 内存使用量 图表和泄漏报告
- valgrind --tool = memerycheck --leak_check = full
如何预防内存泄漏?
- 检查malloc与free,new delete成对出现
- 使用容器(如 std::vector、std::string)替代原生数组
- 将资源(内存、文件句柄)封装在对象中,析构时自动释放。
- 使用C++的智能指针,unique_ptr独占所有权,自动释放,shared_ptr + weak_ptr:避免循环引用
三者的联系
- 野指针 → 段错误
野指针解引用是段错误的常见原因之一(如访问已释放的内存)。 - 内存泄漏 → 间接问题
内存泄漏虽不直接导致段错误,但可能耗尽内存,导致后续new或malloc失败(抛出异常或返回空指针),若未检查空指针则可能引发段错误。 - 共同根源:手动内存管理
内存管理
内存分布模型
- 代码段: 存放程序的机器指令(即二进制代码)。通常是只读的,因为程序的指令在执行过程中不应该被修改。
- 常量区: 字符串、数字等常量存放在常量区,const修饰的全局变量存放在常量区
- 全局区
- 数据段: 存放已初始化的全局变量和静态变量。这些变量在程序开始运行时已经赋予了初始值。
- BSS 段: 存放未初始化的全局变量和静态变量。它们在程序开始运行时会自动初始化为0或者空指针。
- 堆区: 动态分配的内存空间,用于存放程序运行时动态申请的内存。(程序员可以通过函数(如malloc、calloc等)或者操作系统提供的接口来申请和释放堆内存,堆从低地址向高地址增长)
- 栈区: 存放函数的局部变量、函数参数值以及函数调用和返回时的相关信息。栈区是按照“先进后出”的原则进行管理,内存的分配和释放是自动进行的,栈从高地址向低地址增长。是一块连续的空间。
- 文件映射:也称为共享内存,用于实现不同进程之间的内存共享

C语言堆栈分区理解与区别
- 分配与释放: 栈区由编译器自动管理,自动释放,堆区变量需要手动的创建与释放
- 生命周期: 栈区的变量的生命周期与函数调用绑定,堆区变量内存由程序员控制,可跨函数使用
- 大小: 默认栈大小较小,通常最多为2MB,超过则会报溢出错误.堆区内存比较大,由虚拟内存决定,理论上可以接近3GB(对于32位程序来说)
- 连续性: 栈区内存分配遵循内存分配遵循后进先出(LIFO)原则,地址连续的,堆区的内存块通过链表管理,地址不连续
- 内存碎片: 栈操作遵循"后进先出"的原则,不会有内存块从栈中弹出,因此不会产生碎片。堆是通过动态分配内存的方式进行分配和释放,频繁的申请和释放内存可能会引发内存碎片问题。
- 生长方向: 堆:从低地址向高地址生长
- 缓存方式: 栈使用的是一级缓存,调用完成立即释放,速度比较快,堆使用的是二级缓存与主存,速度相对慢
栈区的使用场景: 函数内部局部变量、函数调用信息、递归调用,注意栈溢出。每个线程独享独立栈空间(与线程同生命周期(线程创建时分配,退出时释放))
堆:整个进程共享同一堆空间
- 存储全局或共享数据
- 动态数据结构(链表、树等)
- 跨线程共享的数据(需同步机制保护)。
为什么堆的空间是不连续的? 堆包含一个链表来维护已用和空闲的内存块。申请和释放许多小的块可能会产生如下状态:在已用块之间存在很多小的空闲块。进而申请大块内存失败,虽然空闲块的总和足够,但是空闲的小块是零散的,不连续的,不能满足申请的大小,这叫做**“堆碎片”**
堆分配的空间在逻辑地址(虚拟地址)上是连续的,但在物理地址上是不连续的
用户栈和内核栈
内核栈: 内存中属于操作系统空间的一块区域。1. 保存中断现场,对于嵌套中断 2. 保存操作系统程序相互调用的参数
用户栈: 用户进程空间的一块区域,用于保存用户空间子程序间调用的参数,返回值以及局部变量
为什么不能共用:
- 大小问题: 如果只用系统栈,系统栈一般大小有限,用户程序调用次数可能很多
- 安全性问题: 如果只用用户栈,系统程序需要在某种保护下运行
内存碎片
内存碎片是指在内存管理过程中产生的未被有效利用的零散、不连续的内存空间。主要分为两种类型:内部碎片和外部碎片。
-
内部碎片: 是由于固定大小的内存分配方式或对齐要求等原因导致的未被利用的小空间。当分配给进程的内存块大于所需的大小时,其中的剩余空间就成为了内部碎片。需要举例子说明,比如malloc分配了20字节,但实际只用15字节,剩下的5字节就是内部碎片。
-
外部碎片: 是由于存在未分配的连续内存空间太小而不能满足分配请求,从而导致这些内存无法被有效利用。比如系统有100字节空闲,但分散成多个30字节的小块,这时申请40字节就会失败。 解决外部内存碎⽚的问题就是内存交换
消除外部碎片:
- 紧凑技术: 操作系统会不时将进程在内存中的位置移动,移动和整理过程开销大,效率较低
- 内存交换: 256MB→临时写到硬盘→读回时不放在原来的位置,而是紧跟已有的 512MB 内存块之后
- 空闲块合并: 内存释放时,尽可能将相邻的空闲空间合并成更大的连续内存块,减少碎片。
消除内部碎片:
- 分页机制(Paging):把内存划分为固定大小的页框,进程按页分配,每一页为4K,避免因连续空间不足而产生外部碎片,但最后仍可能有页内的 内部碎片
- 使用内存池: 内存池是一种动态内存分配与管理技术。存池则是在真正使用内存之前,先申请分配一大块内存(内存池)留作备用**,**当我们申请内存时,从池中取出一块动态分配的内存,释放内存时,再将我们使用的内存释放到我们申请的内存池内,再次申请内存池也可以再取出来使用。并且,尽量与周边的内存块合并。若内存池不够时,则自动扩大内存池,从操作系统中申请更大的内存池
- 伙伴系统(Buddy System):通过二叉分割和合并空闲块,快速找到合适的空闲内存,减少内外部碎片。
分段、分页、段页式、请求式分页
-
分区式内存管理: 将整个程序一次性加载到内存的一个连续区域中,会产生 外部碎片,导致内存利用率低
-
分页式内存管理: 将内存划分为固定大小的页框(4KB),程序被切分成同样大小的页(Page),逻辑上连续,物理上可以离散。提高内存利用率,不产生外部碎片,只会产生少量 内部碎片(最后一页用不完的部分)
-
分段式内存管理: 根据逻辑模块(如代码段、数据段、堆、栈等)划分为多个段,每个段连续分配物理内存。更符合程序的逻辑结构,方便实现信息共享与保护。但段长不固定,容易产生 外部碎片,且为大段分配连续空间较困难。
-
段页式内存管理: 先按照逻辑模块划分为段,再对每个段进行分页,逻辑地址 = 段号 + 页号 + 页内偏移量。既支持逻辑模块化,也避免外部碎片,但地址转换过程更复杂(段表 + 页表)
-
请求式分页与虚拟内存: 程序并不一次性加载,而是 按需加载页面。依赖 局部性原理(程序运行时只会频繁访问少量数据)。若访问的页面不在内存,会触发 缺页异常,操作系统从磁盘调入相应页面。
| 管理方式 | 特点 | 碎片情况 | 优缺点 |
|---|---|---|---|
| 分区式 | 整个程序一次性装入内存 | 外部碎片严重 | 简单,但浪费空间 |
| 分页式 | 固定大小页,物理地址离散 | 少量内部碎片 | 内存利用率高,不利共享 |
| 分段式 | 按逻辑模块划分 | 外部碎片 | 方便共享与保护,难以分配大段 |
| 段页式 | 分段后再分页 | 减少外部碎片 | 结合两者优点,开销较大 |
| 请求分页 | 按需调入页面 | 几乎无碎片 | 支持虚拟内存,提高利用率 |
内存池
内存池(Memory Pool)是一种动态内存分配与管理技术。当程序长时间运行时,由于所申请的内存块大小不定,频繁使用时会造成大量的内存碎片从而降低程序和操作系统的性能。内存池则是在真正使用内存之前,先申请分配一大块内存(内存池)留作备用,当我们申请内存时,从池中取出一块动态分配的内存,释放内存时,再将我们使用的内存释放到我们申请的内存池内,再次申请内存池也可以再取出来使用。并且,尽量与周边的内存块合并。若内存池不够时,则自动扩大内存池,从操作系统中申请更大的内存池
为什么要做内存池?
- 性能优化:
- 减少动态内存分配的开销:系统调用 malloc/new和free/delete 涉及复杂的内存管理操作(如内存查找、碎片整理),导致性能较低,而内存池通过预分配和简单的逻辑管理提高分配和释放的效率。
- 避免内存碎片: 动态分配内存会产生内存碎片,尤其在大量小对象频繁分配和释放的场景中,导致的后果就是: 当程序长时间运行时,由于所申请的内存块的大小不定,频繁使用时会造成大量的内存碎片从而降低程序和操作系统的性能。内存池通过管理固定大小的内存块,可以有效避免碎片化。
- 降低系统调用频率: 系统级内存分配(如malloc)需要进入内核态,频繁调用会有较高的性能开销。内存池通过减少系统调用频率提高程序效率。
- 确定性: 稳定的分配时间,使用内存池可以使分配和释放操作的耗时更加可控和稳定,适合实时性有严格要求的系统。
应用场景?
- 高频小对象分配: 游戏中大量小对象的动态分配与释放、网络编程中大量的请求和响应
- 实时系统: 嵌入式设备或实时控制系统中,动态分配内存延时可能影响实时性,内存池提供了确定的性能
- 服务器开发: 数据库服务器、web服务器等需要管理大量连接和请求,这些连接涉及大量内存分配,内存池能有效提升服务器性能。
内存池在代码中的应用
- 对 new/malloc/delete/free 等动态开辟内存的系统调用进行替换
- 对STL众多容器中的空间配置器 std::allocator 进行替换
#include <iostream>
#include <cstdlib>class SimpleMemoryPool {
private:char* pool; // 内存池起始地址size_t blockSize; // 内存块大小size_t numBlocks; // 内存块数量char* freeList; // 空闲节点链表头节点
public:SimpleMemoryPool(size_t blockSize, size_t numBlocks) : blockSize(blockSize), numBlocks(numBlocks) ;~SimpleMemoryPool();void* allocate();void deallocate(void* block);
};
内存池的缺点
- 初始内存占用: 内存池需要预先分配较大的内存区域,可能浪费一些内存。
- 复杂性: 实现和调试内存池代码比直接使用malloc/new更复杂。
- 不适合大型对象: 对于大对象的分配可能并不划算。
虚拟内存与页表
直接访问物理内存的缺点: 碎片化导致利用率低,缺乏访问控制,无法隔离进程,安全性差,内存不足时效率低下。
虚拟内存的好处
虚拟内存是一种抽象的内存概念,它为每个进程提供了一个独立的地址空间,这个地址空间被称为虚拟地址空间。虚拟内存的大小可以超过物理内存的容量。
物理内存是计算机系统中实际存在的内存硬件,由RAM(Random Access Memory)组成。物理内存存储着正在运行的程序和数据。
为什么要使用虚拟内存?以下是虚拟内存的几个好处:
- 扩展内存容量: 虚拟内存允许进程访问超过物理内存容量的虚拟地址空间。当物理内存不足以容纳所有进程的数据时,操作系统可以将不常用的页面置换到磁盘上,从而释放物理内存空间给其他进程使用。
- 内存隔离: 每个进程都有独立的虚拟地址空间,使得不同进程之间的内存彼此隔离,互不干扰。这提高了系统的安全性和稳定性,一个进程的错误不会影响其他进程。
- 简化程序设计: 虚拟内存使得程序设计人员可以将内存视为连续的地址空间,而不需要关注物理内存的限制和分配。程序可以使用大量的虚拟内存,而不必担心物理内存的实际大小。
- 提高性能: 虚拟内存通过提供更大的地址空间和内存管理机制,可以提高系统的性能。它允许操作系统将常用的页面保留在物理内存中,减少了磁盘访问次数,提高了访问速度。
- 按需调页,提升内存利用率:程序的虚拟地址空间被划分为 页(Page),这些页并不需要全部映射到物理内存,而是 按需加载,当程序访问到不在物理内存的页时,会触发 缺页异常。
页表的作用是什么?
页表 简化 user/kernel 间数据传递流程
页表(Page Table)是操作系统中的一种数据结构,用于管理虚拟内存和物理内存之间的映射关系。它记录了进程的页(Page)与物理页框(Page Frame)之间的对应关系。
页表的作用是实现虚拟内存与物理内存之间的映射关系,并提供对内存访问的控制和管理。具体作用包括:
- 映射关系:通过页表,操作系统可以根据进程的虚拟地址将其转换为实际的物理地址。这样,进程就可以使用连续的虚拟地址空间而不需要关心物理内存的布局。
- 内存管理: 页表可以帮助操作系统有效地管理内存。它可以将进程的虚拟地址空间分割成小的固定大小的页,同时将物理内存分割成与页大小相同的块。这样,操作系统可以根据需要进行页面调度,将进程所需的虚拟页加载到物理内存中,并保持合理的内存利用率。
- 内存保护: 页表中可以记录访问权限和保护位等信息,用于控制进程对内存的访问权限。通过页表,操作系统可以实现内存的保护,确保进程只能访问到其所拥有的内存空间,防止越界访问和非法操作。
- 虚拟化技术支持: 在虚拟化环境下,页表可以实现虚拟机对物理内存的访问和管理。虚拟机监控程序(Hypervisor)会维护独立的页表,将虚拟机的虚拟地址转换为物理地址,隔离不同虚拟机之间的内存空间。
地址映射
-
内存被划分为固定大小的 页(Page),通常 4KB。
-
物理内存也划分为同样大小的 页帧(Page Frame)。
-
页表记录 虚拟页号 → 物理页帧号 的映射。
-
虚拟地址到物理地址的映射是通过页表(Page Table)来实现的。页表是一种数据结构,记录了虚拟页和物理页之间的映射关系。
-
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址

虚拟地址 到物理地址 三个步骤:
- 把虚拟内存地址,切分成页号和偏移量;
- 根据页号,从页表里面,查询对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
缺页异常与置换
-
虚拟页的数量 > 物理页帧数量 → 有些虚拟页不在物理内存,而是存放在磁盘中。
-
当 CPU 访问一个虚拟地址时:
- 调用内核的缺页处理程序。
- 选择一个物理页帧(可能采用 LRU 等页面置换算法)换出到磁盘。
- 从磁盘调入所需页面,更新页表项(有效位 = 1,并写入新的物理页号)。
- 返回原指令重新执行,此时命中物理内存。
-
查询页表:如果页表有效位 = 1 → 命中 → 直接访问物理内存。
若有效位 = 0 → 缺页异常:
缺页中断

缺页异常: malloc和mmap函数在分配内存时只是建立了进程虚拟地址空间,并没有分配虚拟内存对应的物理内存。当进程访问这些没有建立映射关系的虚拟内存时,处理器自动触发一个缺页异常,引发缺页中断。
缺页中断: 缺页异常后将产生一个缺页中断,此时操作系统会根据页表中的外存地址在外存中找到所缺的一页,将其调入内存。
操作系统中的缺页中断(Page Fault)是指当程序访问的页不在物理内存中时发生的一种中断机制。当程序需要访问一个虚拟页,但该页当前不在物理内存中时,CPU会触发一个缺页中断,将控制权交给操作系统。
惰性分配与缺页
缺页中断的处理过程大致如下:(大致了解)
- 当程序访问一个缺页时,CPU会暂停当前的指令执行,并产生一个异常或中断,即缺页中断。
- 操作系统的内核捕获到缺页中断,并开始处理中断。
- 操作系统首先会检查发生缺页中断的原因。如果该页是无效的或不可访问的,操作系统会终止该进程,因为这可能是非法访问。否则,如果该页是合法的但不在物理内存中,操作系统需要将该页加载到内存中。
- 操作系统根据页表信息确定要替换的物理页框,并根据需要从磁盘中获取相应的页。
- 如果物理内存中有空闲的页面,操作系统将被替换的页面清除并将新的页面加载到物理内存中。如果物理内存没有空间,则必须选择一个页面进行替换,通常会使用一些页面置换算法,如最近最少使用(LRU)或先进先出(FIFO)。
- 操作系统更新页表,将新加载的页与对应的虚拟页建立映射关系,并标记该页为已加载到物理内存中。
- 最后,操作系统恢复中断点,并将控制权返回给触发缺页中断的程序,让它继续执行。
缺页中断的目的是实现了虚拟内存的概念,允许程序使用比实际物理内存更大的地址空间,并将常用的页存放在物理内存中,而将不常用的页放在磁盘上。通过缺页中断处理,操作系统能够根据需求将所需的虚拟页从磁盘加载到内存中,实现了透明的内存管理和动态的页面调度。
中断和异常的区别
| 中断 | 异常 | |
|---|---|---|
| 触发方式 | 由外部设备或其他特殊事件触发,如时钟、IO | 由当前执行的指令引发,表示当前指令无法正常执行或发生了错误,如除零错误、越界访问、非法指令等 |
| 异步性 | 异步事件,与当前程序的执行无关,可在任何时刻发生 | 同步事件,由当前执行的指令引发,与当前执行步骤相关 |
| 处理机制 | 发生中断时,处理器立即中断当前正在执行的程序,保存当前程序的上下文,并跳转到中断处理程序来处理中断事件。处理完中断后,处理器恢复之前被中断的程序的上下文,并继续执行。 | 发生异常时,处理器立即中断当前指令的执行,保存当前程序的上下文,并跳转到异常处理程序来处理异常情况。处理完异常后,处理器根据异常处理程序的指示继续执行。 |
| 类型 | 没有明确的类型,可根据中断源进行分类,如外部设备中断、时钟中断 | 异常可以分为故障(Fault)、陷阱(Trap)和终止(Abort)三种类型。Fault表示可以被修复的异常,Trap用于实现系统调用和调试功能,Abort表示无法恢复的异常。 |
| 优先级 | 中断可以具有不同的优先级,处理器按照优先级处理中断事件,高优先级的中断会打断低优先级的中断处理 | 异常没有明确的优先级概念,处理器通常按照异常的严重程度来处理 |
页面置换算法
- 缺页异常:应该是指操作系统在分配内存时不会立即分配物理内存,仅分配虚拟地址空间,不分配物理页。
当出现缺页异常,需调入新页面内存已满时,选择被置换的物理页面,也就是说选择⼀个物理页面换出到磁盘,然后把需要访问的页面换入到物理页。
目的:尽量减少页面换入换出的次数
- 最佳页面置换算法(OPT) 置换未来最长时间不会被访问的页面(理论最优,但无法实际实现)
- 先进先出置换算法(FIFO) 队列维护
- 最近最久未使用的置换算法(LRU) 通过时间戳或计数器记录页面访问时间
- 时钟页面置换算法(Lock) LRU的近似实现,使用引用位标记页面是否被访问过,页面组织成环形链表
- 最不常用置换算法(LFU) 置换访问频率最低的页面,维护页面访问计数器

LRU算法
LRU(Least Recently Used)算法是一种用于页面置换的算法,用于决定哪些页面应该被置换出内存。这个算法的基本思想是,当需要置换页面时,选择最近最少被使用的页面进行替换。
LRU 算法: 实现 LRU 算法的方式可以利用一个数据结构来记录页面的访问历史,可以使用链表或者队列来实现。下面是一种基于双向链表的 LRU 算法实现方式:
- 维护一个双向链表。链表的头部表示最近使用的页面,尾部表示最久未使用的页面。
- 当访问一个页面时,如果页面在链表中存在,将其从原位置删除,并插入到链表头部。
- 当访问一个页面时,如果页面不在链表中,且缓存未满,则直接将该页面插入到链表头部。
- 当访问一个页面时,如果页面不在链表中,且缓存已满,则删除链表尾部的页面,并将新页面插入到链表头部。
- 缓存的数据通过哈希表 cache 来进行快速查找,键为键值,值为节点指针
总结: 使用了一个结构体 ListNode 表示双向链表的节点,通过指针 prev 和 next 连接节点。缓存的数据通过哈希表 cache 来进行快速查找,键为键值,值为节点指针。LRU 缓存的容量由变量 capacity 控制。每次访问或插入新数据时,通过操作链表的头部指针和节点的连接关系来更新缓存的访问顺序,同时使用哈希表来查询快速访问指定键值的节点。
class LRUCache{
private:struct ListNode{int key;int val;ListNode* prev;ListNode* next;ListNode(int k, int v):key(k), val(v), prev(nullptr),next(nullptr){}};ListNode* head;ListNode* tail;unordered_map<int, ListNode*> cache;int capacity;public:LRUCache(int capacity) ; // 构造函数void addToHead(ListNode* node); // 往头节点添加一个节点void deleteNode(ListNode* node); // 删除一个节点int get(int key); // 根据键获取值void put(int key, int val); // 添加一个页面
};
优缺点: LRU算法的优点是可以充分利用程序的局部性原理,将最近被访问的页面保留在内存中,从而提高缓存命中率和访问效率。 但它也存在一些缺点,如实现复杂度较高和需要额外的数据结构来记录页面访问历史等。
文件访问方式
1. 顺序访问(Sequential Access):
-
顺序访问是按照数据在文件中的顺序进行访问的方式。
-
读取数据时,必须从文件的开头开始,依次读取每个数据项,直到达到目标位置。
-
写入数据时,新的数据将追加到文件的末尾。
-
顺序访问适用于顺序处理数据的场景,如读取日志文件或批量处理数据。
2. 随机访问(Random Access):
-
随机访问允许根据数据在文件中的位置进行直接访问。
-
读取数据时,可以通过指定数据在文件中的位置或偏移量来读取特定位置的数据。
-
写入数据时,可以将数据直接写入文件的指定位置。
-
随机访问适用于需要快速访问文件中特定位置的数据的场景,如数据库系统或索引文件。
3. 直接访问(Direct Access):
-
直接访问允许通过记录的标识符(如文件中的记录号)直接访问文件中的数据。
-
读取数据时,可以通过记录的标识符来定位和读取特定记录的数据。
-
写入数据时,可以将数据直接写入文件中指定记录的位置。
-
直接访问适用于需要根据记录标识符快速访问文件中数据的场景,如数据库系统或索引文件。
C++
new/delete/delete[]与malloc/free的区别,allocator
new/delete与mallooc/free区别
- new、delete是C++中的操作符,而malloc和free是标准库函数。
- new 自动计算所需分配内存大小,malloc需要手动计算
- new 直接返回对象类型的指针,malloc是void*, 需要类型的强转
- new 失败是抛出异常,malloc异常时返回NULL
- new 是在 free store上分配,malloc多在堆上分配虚拟内存 -> 页表 -> 缺页异常来分配
- operator new
- 申请内存空间
- 调用构造函数,初始化成员变量,已经拥有了物理内存
- delete需要的是对象类型指针(因为要先调用析构函数),free是 void*
- 先调用析构
- operator delete
- 释放空间
malloc底层原理
- 当开辟的空间小于 128K 时,内存池分配,如果内存池为空,调用 brk函数,malloc 的底层实现是系统调用函数 brk,其主要移动指针 _enddata(堆段的末尾地址)
- 当开辟的空间大于 128K 时,mmap()系统调用函数来在虚拟地址空间中(堆和栈中间,称为“文件映射区域”的地方)找一块空间来开辟。
delete与delete[]的区别
- delete: 首先调用该对象的析构函数(如果存在的话),然后释放该对象所占用的内存
- delete[]: 先逐个调用数组中每个元素的析构函数(如果存在的话),然后再释放整个数组的内存
delete如何知道有几个函数:
- new[] 分配内存时,会多分配 size_t大小的空间,用于存储数组元素个数;
- delete[]p:指针左偏移 sizeof(size_t)就可以拿到数组元素个数,从而知道析构多少元素;
常见问题:
- malloc 是怎么分配空间的? 128K为界
- malloc 分配的物理内存还是虚拟内存?
- malloc 调用后是否立刻得到物理内存? 虚拟内存
- free§怎么知道该释放多大的空间? 看图
- free 释放内存后,内存还在吗? <128K在,>128K不在
allocator
allocator 是 C++ 标准库中的一个组件,用于管理内存的分配和释放。它提供了一种抽象的方式来分配和释放内存
内存分配和释放:
-
allocate(size_t n): 分配n个元素所需的内存,并返回指向该内存的指针。 -
deallocate(void* p, size_t n): 释放之前通过allocate分配的内存 -
内存分配: 仅分配内存,不调用构造函数。
-
内存释放: 仅释放内存,不调用析构函数
使用场景:
-
new: 适用于简单的内存分配和对象创建,固定的内存分配和对象创建方式 -
allocator: 适用于需要精细控制内存管理的场景,可以通过自定义分配器实现更复杂的内存管理策略(更灵活)
具体实现
- 当调用 malloc(size) 时,它首先计算需要分配的内存块大小,包括请求大小和内存管理所需要的额外空间
- malloc 会遍历一个数据结构(空闲块列表或空闲链表),查找合适大小的空闲内存块
- 找到合适的内存块,malloc 会将其标记为已分配,并返回一个指向该内存块的指针给用户
- 如果没有足够大的空闲内存块可用,malloc 可能需要扩展程序的虚拟内存空间。它通过系统调用(例如 brk 或 mmap)向操作系统请求更多的连续内存空间。
- 当操作系统提供了更多的内存空间后,malloc 可以从新的空间中分配出合适大小的内存块,并将其标记为已分配
- 在内存块被释放时,通过调用 free 函数,malloc 将其标记为未分配,并将该内存块添加到空闲内存块的列表中
指针与引用的区别
指针(Pointer):
- 定义:指针是一种变量,存储了一个地址,该地址指向内存中的另一个变量。
- 特点:可以修改指针的指向,使其指向其他变量或空地址。可以进行指针运算,如指针加法和减法。可以通过解引用(Dereference)操作符 * 来访问指针所指向的变量。
引用(Reference):
- 定义:引用是变量的别名,它引用了同一块内存空间。
- 特点:引用一旦绑定到一个变量,便无法更改其引用的目标。操作引用和操作原变量是等价的,对引用的修改会反映在原变量上。引用不能指向空地址。
指针和引用的区别:
- 指针是一个实体,而引用仅是个别名
- 指针和引用的自增(++)运算意义不一样,指针是对内存地址的自增,引用是对值的自增;量或对象的地址)的大小;
- 引用使用时无需解引用(*),指针需要解引用;
- 引用只能在定义时被初始化一次,之后不可变;指针可变;
- 引用不能为空,指针可以为空;
- 指针在独立内存,引用不额外占内存
应用场景:
- 引用的场景: 函数参数传递(避免拷贝开销),运算符重载,范围for循环
- 指针的场景: 动态内存管理,可空对象,继承和多态,低级内存操作
C++为什么引入引用:
- 作为函数参数避免拷贝(尤其大对象)
- 实现操作符重载(如 cout << obj)
- 比指针更安全(无空引用、无内存泄漏风险)
const关键字的使用
const int a = 10; → 常量,值不可修改- 修饰函数参数,函数参数不可修改
- 修饰函数返回类型不可修改
- int * const ptr → 指针常量,指针地址不可变
- const int *ptr → 常量指针,内容不可变,指针可变
- 修饰类成员变量
- 修饰类的成员函数:
int getValue() const;// 承诺不修改对象状态 - 修饰实例对象,这样使得该对象只能凋用const修饰的方法
- const 成员函数中能修改 mutable 变量吗? ✅ 可以!mutable 用于突破 const 限制(如缓存机制)
static关键字的用处
-
静态局部变量 生命周期延长至程序结束,仅初始化一次
-
全局变量/函数 限制作用域为当前文件(避免命名冲突)
-
类内静态成员变量 所有对象共享的变量(需类外初始化)
-
类内静态成员函数 无 this 指针,只能访问静态成员
-
静态成员变量如何初始化?
- 头文件中声明:
class MyClass { static int count; }; - 源文件中定义并初始化(必须!)
int MyClass::count = 0;
- 头文件中声明:
面对对象的三大特性
- 封装: 设置权限,隐藏细节,实现模块化
- 继承: 复用代码,扩展父类功能,通过权限来设置,破坏继承:friend, using,通过虚继承解决菱形继承
- 多态: 函数重载,虚函数重写
菱形继承
定义: 一个子类继承多个父类,这些父类又继承自相同的父类,从而造成了菱形继承
问题: 浪费空间,二义性
解决方案: 虚继承,子类只继承一次父类的父类,继承的时候带上virtual关键字
虚继承底层原理: 虚基表和虚基指针
- 核心逻辑是:间接基类的成员不直接存储在派生类对象中,而是通过指针间接访问。
- 虚基指针:当类虚继承某个基类时,编译器会在该类的对象中插入一个虚基指针(vbptr),指向虚基表。
- 虚基表:虚基表是一个存储偏移量的数组,记录当前类对象到其虚基类实例的内存偏移
多态
静态多态
- 编译时确定
- 函数重载
动态多态
虚函数表:
- 每个含有虚函数的类都会自动生成一个虚函数表,指针数组,表中存放所有虚函数的地址。
- 在编译的时候生成,这个虚函数表在内存中的位置通常是在**.rodata**(磁盘),运行时映射到代码段(.text)中,而不是在对象的实际内存中
虚表指针
-
每个对象中存储指向虚函数表的指针(vptr),他们的地址是不同的,需要深拷贝,运行时通过该指针调用对应虚函数
-
类对象的构造的时候,把类的虚函数表地址赋值给vptr,没有构造函数,默认生成构造函数
-
这个指针通常位于对象最开始的位置,也就是对象的 vptr(虚表指针)
-
继承的情况下,先调用基类的构造函数,把虚函数表地址赋值给vptr,然后调用子类的构造函数,把虚函数表地址赋值给vptr
多重继承对vtable的影响: 多重继承时,对象内存在多个vptr,分别指向每个基类对应的vtable。
虚继承: 虚继承可以解决菱形继承中的重复性问题, 虚继承底层原理: 虚基表和虚基指针
-
核心逻辑是:间接基类的成员不直接存储在派生类对象中,而是通过指针间接访问。
-
虚基指针:当类虚继承某个基类时,编译器会在该类的对象中插入一个虚基指针(vbptr),指向虚基表。
-
虚基表:虚基表是一个存储偏移量的数组,记录当前类对象到其虚基类实例的内存偏移
析构函数一般写成虚函数
- 多态性支持:通过将析构函数声明为虚函数,可以实现指向派生类对象的基类指针或引用在运行时调用正确的析构函数,这样做可以确保派生类的析构函数得到调用
- 动态绑定:当基类指针或引用指向派生类对象时,将析构函数声明为虚函数可以实现动态绑定,即在运行时根据对象的类型选择正确的函数实现。如果析构函数不是虚函数,当删除一个基类指针时,只会调用基类的析构函数,而不会调用派生类的析构函数。这可能导致派生类对象的资源没有得到正确释放,引发资源泄漏问题。
构造函数为什么一般不定义为虚函数
- 虚函数的调用依赖于对象的类型,而在构造函数执行期间,对象的类型尚未完全确定。
- 在构造函数执行期间,对象的虚函数表(vtable)尚未被填充。因此,如果将构造函数声明为虚函数,虚函数调用将无法正确地解析到派生类的实现,因为派生类的虚函数表尚不存在。
构造函数或析构函数中调用虚函数会怎样
- 构造函数中虚函数的调用会使用当前类的实现,即使被派生类重写了该虚函数。
- 析构函数中虚函数的调用也会使用当前类的实现,即使该对象被派生类实例化。在析构函数期间,对象的动态类型已经丧失,只能使用当前类的实现,因为派生类的部分已经被销毁。
- 因此,构造函数和析构函数中调用虚函数的实际执行版本是根据当前类的类型决定的,无论对象的动态类型是什么。这也是为什么在构造函数和析构函数中调用虚函数被视为一种不良实践,可能导致未定义的行为或意外的结果
vector动态数组
一. 扩容机制 指数增长策略,每次扩容约为当前的1.5 - 2 倍
- 申请更大内存(通常为当前capacity的1.5-2倍)
- 拷贝或移动旧数据到新内存
- 释放旧内存
二、emplace back() 与 push back()的区别是什么? 为什么emplace_back()更高效
emplace_back(args...)原地构造对象,避免不必要的拷贝/移动,- 相比push_back(a)更高效,特别适用于存储复杂对象。
- 对于简单数据类型,push back()和emplace back()差别不大
- 对于复杂对象,优先使用emplace back()以提升性能!
三、clear()后capacity是否会改变? 如何确保 vector释放多余的内存?
- clear() 仅删除元素但不会释放 capacity。
- 如果希望释放多余内存,可使用shrink_to_fit(),但不保证立即生效。
- 可以与一个空容器进行交换
总结: clear() 只清空数据但不释放内存,shrink_to _fit() 可尝试释放多余容量
迭代器失效问题
| 容器 | 插入操作导致失效 | 删除操作导致失效 |
|---|---|---|
| vector | 扩容时全部失效,否则插入点后失效 | 删除点及之后失效 |
| deque | 首尾插入可能失效,中间插入全部失效 | 首尾删除部分失效,中间删除全部失效 |
| list | 永不失效(链表结构) | 仅删除点失效 |
| map | 永不失效(红黑树) | 仅删除点失效 |
深拷贝与浅拷贝
浅拷贝: 拷贝对象的成员变量,但如果成员变量是指针,仅拷贝指针地址,而非指针指向的内容。
深拷贝: 不仅拷贝对象的成员变量,还会申请新内存空间,并复制指针所指向的内容。
class ShallowCopy
{
public:int* data;// 浅拷贝ShallowCopy(int val) {data = new int(val);}// 深拷贝ShallowCopy(const ShallowCopy& other) {data = new int(*other.data);}
};
inline
- 提示编译器内联展开函数,减少函数的调用开销,适合小型,高频、简单的函数,主要用于get与set
- inline 只是建议,最终由编译器决定是否展开
inline失效:
- 递归调用 次数未知,编译器无法展开
- 虚函数: 因为虚函数是动态绑定,编译的时候还未知运行那个函数,无法内敛
- 函数指针调用: 编译的时候,无法确定具体的目标函数
- 动态库中的inline: 共享库函数的地址运行时确定
- 函数体过大或者复杂的循环控制等流,代码膨胀,影响性能
类的大小
- 非静态成员变量的大小,静态变量是在全局数据区的,不占类的内存大小
- 内存对齐与填充,而且与成员变量的顺序有关
- 虚函数的影响,虚表指针,8字节,
- 继承的影响,虚继承,还会加上虚基类指针
- 空类的大小为1,为了区别不同的空类,保存地址
C++内存泄漏有哪些
- 堆内存泄漏: new/delete,malloc/free
- 数组内存泄漏: 使用new [],如果使用delete释放就造成了内存泄漏,new[] 在分配内存时,会在实际数据之前存储数组大小信息,delete[] 知道需要读取这个信息来确定要调用多少次析构函数,delete 不会读取这个信息,直接当作单个对象处理。
- 实际:会提示不匹配,对于int类型仍然没有内存泄漏,因为int没有析构函数,编译器实现细节,某些编译器这两内部底层相似,但这仍然是未定义的危险行为,对于类的话只会调用第一个类的析构。
- 循环引用导致的内存泄漏,把其中一个shared_ptr改为weak_ptr
- 系统资源内存泄漏(文件、网络、线程),文件调用fstream,自动调用析构
如何避免:
一、编码阶段的预防策略
- 保持分配/释放对称
- 每一个
malloc/calloc/realloc→ 必须有free - 每一个
new/new[]→ 必须有delete/ `delete[]
- RAII(C++ 推荐)在构造函数里分配资源,析构函数里释放,确保作用域结束时自动释放。
- 使用智能指针/容器
- 避免“资源泄漏” 不仅仅是内存,Linux 上还要注意:
open→closesocket→closemmap→umnmappthread_mutex_init→pthread_mutex_destroy
STL
Deque(双端队列)和 Vector之间的区别可以概括如下:
- 插入和删除操作:Deque支持在头部和尾部高效地插入和删除元素,而Vector只能在尾部进行高效操作。
- 内部实现:Deque采用分段的数据结构,而Vector是一块连续的存储空间。
- 内存分配方式:Deque在扩容时能更高效地利用内存,并避免频繁的重分配,而Vector需要重新分配整块连续的内存空间。
- 随机访问性能:Vector的随机访问性能更好,而Deque的随机访问相对较低。
底层实现及插入删除与查找时间复杂度
| 容器 | 底层实现 | 增删 | 查询 |
|---|---|---|---|
| vector | 数组 快速随机访问和动态大小调整 | O(1) | O(1) |
| List | 链表 快速插入和删除 | O(1) | O(n) |
| set | 红黑树 有序且不重复 | O(log n) | O(log n) |
| map | 红黑树 有序的键值对集合,键不重复 | O(log n) | O(log n) |
| deque | 中央控制器和多缓冲区 ,快速的首尾插入和删除 | O(1) | O(1)/O(n) |
| stack | 一般使用list或deque实现 封装头部操作 | O(1) | O(1)/O(n) |
| queue | 一般使用list或deque实现 封装头部操作 | O(1) | O(1)/O(n) |
| unordered_set /map | 哈希表 | O(1) | O(1) |
| priority_queue | vector,通过堆来管理底层容器实现优先级 | O(logN) | O(1)/O(n) |
红黑树/B树与B+树
map是如何实现的,查找效率是多少
map容器通常使用红黑树作为底层数据结构实现键值对的存储和查找。红黑树是一种自平衡的二叉搜索树,它具有一些特性:
红黑树特性
- 每个节点要么是红色,要么是黑色。根节点是黑色的。
- 每个**叶子节点(NULL节点,空节点)**都是黑色的。
- 如果一个节点是红色的,那么它的两个子节点都是黑色的。(红树生黑娃)
- 对于每个节点,从该节点到其所有后代叶子节点的简单路径上,包含相同数量的黑色节点。
- 插入节点默认是红色的(插入黑色一定破坏黑路同)
**口诀:**左根右、根叶黑、不红红、黑路同
通过这些特性,红黑树能够保持树的平衡,以提供较好的查找性能。在map容器中,红黑树的平衡性质保证了插入、查找和删除操作的时间复杂度为O(logN),其中N是容器中元素的数量。
另外,红黑树的特性也使得map容器成为一种有序结构,即按照键的大小进行排序。这使得map容器可以高效地进行范围查找和遍历。
红黑树的缺点之一是空间占用较高。因为每个节点需要保存额外的父节点、孩子节点和红黑树的性质信息,导致每个节点占用较多的空间。不过对于大部分应用来说,这种额外的空间开销是可以接受的,因为红黑树为map容器提供了高效的查找和排序能力。
B树的基本特征
- 平衡:所有的叶节点都在同一层
- 有序:从小到大,任一元素的左子树都小于它,右子树都大于它
- 多路:m阶B树,最多m个分支,最少一半个分支(上取整),元素个数 = 分数树 - 1
访问节点是在硬盘上进行的,节点内的查找是在内存中进行的
B+树的基本特征

基本特性
-
多路性与平衡性: 继承 B 树的多路性和平衡性,叶子节点位于同一层,节点的阶数定义与 B 树类似。
-
关键字与数据的分离
- 非叶子节点仅存储关键字(索引),不存储实际数据,仅用于索引导航。
- 所有实际数据(关键字及对应值)仅存储在叶子节点中,且叶子节点按关键字有序排列。
-
叶子节点的链表结构: 所有叶子节点通过指针连接成一个有序链表(通常是双向链表),便于范围查询(如 “查询 key> 100 且 key < 200 的数据”)。
-
关键字的冗余性
- 非叶子节点的关键字是叶子节点中关键字的副本(冗余存储),用于索引导航。
- 例如:叶子节点的关键字
[10,20,30],其上层非叶子节点可能包含20作为索引,指示 “左侧子树关键字≤20,右侧≥20”。
-
**插入与删除特性:**插入和删除的分裂、合并逻辑与 B 树类似,但由于数据仅在叶子节点,调整更集中于叶子层和索引层的关键字同步。
支持查找方式
- 顺序查找
- 随机查找
- 范围查找
B 树与 B + 树的核心区别:
| 特征 | B 树 | B + 树 |
|---|---|---|
| 数据存储位置 | 所有节点(叶子 + 非叶子)均可存储数据 | 仅叶子节点存储数据,非叶子节点仅存索引 |
| 叶子节点连接 | 无链表结构 | 叶子节点通过链表连接 |
| 关键字冗余 | 无冗余,每个关键字仅出现一次 | 非叶子节点关键字是叶子节点的副本 |
| 范围查询效率 | 较低,需回溯父节点 | 高效,通过叶子链表直接遍历 |
| 磁盘 I/O 效率 | 较低(非叶子节点存储数据,单次加载关键字少) | 较高(非叶子节点仅存索引,单次加载关键字多) |
| 适用场景 | 随机查询为主的场景(如文件系统) | 范围查询频繁的场景(如数据库索引) |
C++11新特性

左值与右值及右值引用
左值:
- 具有地址,存储在内存中
- 可是出现在赋值号 = 的左侧
- 可以取地址 &
- 变量、对象、数组元素都是左值
int x = 10; // x 是左值 x = 20; // 左值可以出现在赋值号的左侧 int* p = &x; // 可以取地址 const int&& y = std::move(x); // 现在这个move(x)是右值,触发移动构造,避免深拷贝
右值
- 通常没有地址,存在在寄存器或临时内存中,除非利用move()
- 不能出现在赋值号 = 的左侧
- 不能取地址 & (除非绑定到 const 左值引用)
- 自变量、表达式计算结果都是右值
int y = 10 + 5; // (10 + 5) 就是右值 10 = y; // ❌ 右值不能在 `=` 的左侧 int &red = 10; // ❌ 普通引用不能绑定右值 const int& cref = 10; // ✔️ const 引用可以绑定右值
右值转为左值:
- 通过左值变量:
int a = 10; - 通过右值引用变量
int&& rref = 10; rref = 20; - 通过const 左值引用绑定右值,但不可修改:
const int& cref = 10;
左值转为右值:
- 通过move,这时候就有了地址,但左值变成了亡值,亡值可以取地址,但不能赋值
int a = 10; // a 是左值 int&& rref = std::move(a); // 用 std::move 将 a 转为右值引用
左值引用:
- 避免不必要的拷贝: 通过标识和操作右值,可以避免在操作临时对象时进行不必要的拷贝操作,提高程序的性能。
右值引用的作用主要体现在以下几个方面:
- 实现移动语义: 通过右值引用和移动操作,可以在对象的资源拷贝过程中,将资源所有权从一个对象转移给另一个对象,避免了不必要的资源拷贝。
- unique_ptr
- 移动构造与移动拷贝构造
- STL中
- std::function
- 支持完美转发: 通过右值引用,可以保持传递参数的值类别,实现参数的完美转发,避免了临时对象的额外拷贝操作。
move移动语义 与 forward完美转发
move的作用:
-
将左值转化为为右值,以触发移动语义(上述案例中)
-
不会真正移动数据,只是改变对象的属性, 转移堆上的资源
-
用于触发移动构造和移动赋值,避免深拷贝,提高性能
int main() {// 假设字符串很长std::string str1 = "hello world";std::string str2;str2 = move(str1);std::cout << "str1:" << str1 << std::endl;std::cout << "str2:" << str2 << std::endl; return 0; }
完美转发
- 高效传递参数的方式,保持参数的原始特性(左值或右值),避免不必要的拷贝或移动
std::forward<T>(arg)通过 引用折叠 和 类型推导 来决定参数是否应该保留右值特性。
为了实现完美转发,通常要使用两个重要的特性:
- 模板类型推导: 函数模板使用模板参数来承载传递的参数,通过类型推导来确定参数的类型。
- 万能引用: 转发引用是指使用 std::forward 函数来将参数转发给其他函数。std::forward 的原理是根据参数的值类别和是否为左值引用来决定将参数转发为左值引用或右值引用。
引用折叠规则:
- 模板推导中,若传入左值
int x,T会被推导为int&,此时T&&折叠为int&(左值引用); - 若传入右值
5,T会被推导为int,此时T&&就是int&&(右值引用) - std::forward(t) 的内部实现会根据 T 的类型(int& 或 int),分别返回 static_cast<T&>(t)(左值)或 static_cast<T&&>(t)(右值),确保转发后的类型与原始参数一致,避免丢失。
完美转发demo:
void process(int &x) {std::cout << "LVaule reference" << std::endl;
}
void process(int&& x) {std::cout << "RVaule reference" << std::endl;
}
// 泛型函数,使用完美转发
template<typename T>
void forwardExample(T&& arg){ // 万能引用 = 模板 + 万能引用process(std::forward<T> arg);
}
int main(){int a = 10;forwardExample(a);forwardExample(10);return 0;
}
面试考点:
1. forward 和 move 的区别
move无条件将参数转换为右值引用(T&&),本质是一个类型转换函数(static_cast<T&&>(t))- forward有条件地转发参数的原始类型,仅用于模板参数的完美转发。它会根据模板参数的推导结果,决定将参数转为左值引用还是右值引用
2. T&&是万能引用还是右值引用
- 当 T 是模板参数且发生类型推导时,T&& 是万能引用,可以绑定到左值或右值。
- 其他情况(T 非模板参数,或未发生类型推导),T&& 是右值引用,仅能绑定到右值。
3. 为什么 forward 可以避免参数类型丢失
- 引用折叠
- 模板推导中,若传入左值
int x,T会被推导为int&,此时T&&折叠为int&(左值引用); - 若传入右值
5,T会被推导为int,此时T&&就是int&&(右值引用) - std::forward(t) 的内部实现会根据 T 的类型(int& 或 int),分别返回 static_cast<T&>(t)(左值)或 static_cast<T&&>(t)(右值),确保转发后的类型与原始参数一致,避免丢失。
4. 如何用 forward 实现高效的 构造函数参数传递
通过完美转发,forward 可将构造函数的参数原封不动地传递给成员变量的构造函数,避免不必要的拷贝(尤其适合临时对象或可移动对象)
C++类型转换
-
static_cast:一种编译时,静态转化类型,主要用于已知安全的转化,比C风格更安全。- 基础数据类型转换,int,double
- 子类指针转化为基类指针,向上转换,子类多的部分会做对象切割
- 不能向下转化,static_cast 访问不到子类的其他变量,那就需要
dynamic_cast
-
dynamic_cast- 用于基类与派生类的转化,主要用于向下转化,会检测类型是否安全,例如
Any类中的Derive与Base,Derive *ptr = dynamic_cast<Derive<T>*>(basePtr.get()); - 基类必须有虚函数,否则则 dynamic_cast 无法执行正确的运行时检查,结果将是未定义。
- 用于基类与派生类的转化,主要用于向下转化,会检测类型是否安全,例如
-
const_cast:如果对象本身不是const,通过const_cast去除指针的const属性,如果本身就是const的话,那是不可以的void modify(const char *str) {char *p = const_cast<char*>(str);p[0] = 'H'; }int main() {char str[] = "hello";modify(str);std::cout << str << std::endl; } -
reinterpret_cast重解释转换int main() {int a = 42;//将指针转换为整数uintptr_t addr = reinterpret_cast<uintptr_t>(&a);int* p= reinterpret_cast<int*>(addr);std::cout << "*p " << *p << std::endl; //输出:42 }
函数模板与模板函数
函数模板是一种通用的函数模板声明,其中函数的参数和返回类型可以使用通用的模板参数来表示。函数模板的定义通常以 template 或 template 开始,后跟函数的声明或定义。
下面是一个简单的函数模板的示例:
- 在这个例子中,add 是一个函数模板,它可以接受相同类型的参数 a 和 b,并返回它们的和。
- 模板参数 T 是一个占位符,表示函数中的类型。在函数调用时,编译器会根据实际的参数类型来实例化函数模板。
template<typename T> T add(T a, T b) {return a + b; }int intResult = add(5, 10); // 实例化为 add<int>(5, 10),返回 15 double doubleResult = add(3.14, 2.71); // 实例化为 add<double>(3.14, 2.71),返回 5.85
模板函数
是对特定模板参数进行特化的函数定义。特化是指针对特定的模板参数类型编写的特殊版本。特化函数可以提供对特定数据类型的定制化行为。
下面是一个函数模板特化的示例:
template<typename T>
T max(T a, T b) {return (a > b) ? a : b;
}template<>
const char* max<const char*>(const char* a, const char* b) {return strcmp(a, b) > 0 ? a : b;
}
在这个例子中,max 是一个函数模板,用于比较两个值并返回较大的值。然后,通过模板特化 template<> 来定义 max 函数针对 const char* 类型的特殊版本。这个特殊版本使用了 strcmp 函数来比较两个 C 字符串并返回较大的字符串。
不同点:
- 函数模板是一个通用的模板声明,可以用于多种数据类型,根据实际参数类型来实例化。
- 模板函数是对特定模板参数进行特化的函数定义,提供了对特定数据类型的定制化行为。
function/lambda/bind
std::function 类模板,抽象了函数以及函数返回值的类模板,用来保存所有函数对象
方式:通过函数返回值以及参数列表来描述函数对象
抽象:把任意一个函数包装成一个对象,该可对象可以保存,传递以及复制,也是一个动态绑定,只需修改该对象,实现类似多态的效果。
用途: 保存函数,为了统一的抽象
- 保存普通函数,类的静态成员函数
- 保存仿函数
- 保存类成员函数
- 保存lambda表达式
- 保存bind返回的函数对象
仿函数:
- 重载了操作符
()的类 - 可以有状态,通过成员变量进行存储
- 有状态的函数对象称为闭包
lambda表达式
Lambda 表达式是 C++11 引入的匿名函数,可捕获周围作用域中的变量,常用于简化代码
[capture-list](parameters) mutable -> return-type { body }
按值捕获与按引用捕获的区别:
| 特性 | 按值捕获([var]) | 按引用捕获([&var]) |
|---|---|---|
| 访问的对象 | 原始变量的副本(独立内存) | 原始变量本身(共享内存) |
| 修改的影响 | 修改副本不影响外部原始变量 | 修改会直接影响外部原始变量 |
| 默认可修改性 | 副本是const的,默认不可修改(需加mutable) | 引用可直接修改(原始变量的常量性决定权限) |
| 生命周期依赖 | 不依赖原始变量生命周期(副本独立存在) | 依赖原始变量生命周期(避免悬垂引用) |
lambda原理
- 编译的时候,把lambda表达式转化为一个函数对象
bind: 函数适配器,模板函数,返回一个函数对象,通过函数和参数列表进行绑定
总结: functon 用来描述函数对象的类型,lambda 表达式用来生成函数对象(可以访问外部变量的匿名函数),bind 也是用来生成函数对象(函数和参数进行绑定生成函数对象);
类型推导
模板参数类型的推导
auto: 用于推导变量类型,通过强制声明一个变量的初始值,编译器会初始化值来自动推导
规则:
- 定义时进行初始化
- 如果用auto定义多个变量,这些变量必须为同一类型
- 类型推导时,会丢失引用或者cv属性(const, volitle)
- 需要保留属性,就要用引用auto &
- **万能引用auto &&,**根据初始化属性判断左值引用还是右值引用
- auto 不能推导数组类型,推导出指针类型
- c++14 可以推导函数返回值类型
auto的用处
-
迭代器
-
容器的遍历
-
线程池设计
auto submitTask(Func&& func, Args&&...args) -> std::future<decltype(func(args...))> {// 打包任务,放入任务队列using reType = decltype(func(args...));auto task = std::make_shared<std::packaged_task<reType()>>(std::bind(std::forward<Func>(func), std::forward<Args>(args)...));std::future<reType> result = task->get_future(); }
decltype用于推导表达式的类型,不会对表达式进行计算,只分析表达式类型
-
一个普通表达式,推导表达式类型
-
函数调用,推导函数返回值
-
左值,推导出左值引用
主要用于泛型编程
智能指针
- 利用栈上的对象出作用域自动析构这个特点,在智能指针的析构函数中保证释放资源
- 自定义删除器
unique_ptr<int, function<void (int*)>> ptr1(new int[10], [](int *p)->void{std::cout << "in intDelteor" << endl;delete[] p; });std::unique ptr<T>(独占指针)- 不能被复制,只能移动(std::move)
- 适用于独占资源管理(如文件、网络连接)。
- 用
std::make_unique<T>(args...)创建(C++14+)
std::shared ptr<T>(共享智能指针)
- 共享所有权,采用 引用计数,多个
shared_ptr可共享同一对象,最后一个销毁时释放资源。 - 存在循环引用风险,可配合
std::weak_ptr解决。 - 用
std::make_shared<T>(args...)创建,减少内存分配开销
std::weak ptr<T> (弱引用)
- 依赖
shared_ptr,不会增加引用计数 - 用于解决
shared_ptr循环引用问题 - 他只是个观察者,只能观察,但不能使用,但可通过
lock()提升shared_ptr,然后判断对象是否仍然有效,可使用对象 - 主要用于多线程的线程安全,通过引用wark_ptr,在线程中监测对象是否存活,并调用对象的方法。
- 一般定义对象的时候使用强智能指针,引用对象的时候使用弱智能指针
二、std::shared_ptr 原理是什么?,请手动实现
- 每个
shared_ptr实例指向同一对象的其他 shared_ptr,实例共享一个计数器 - 当创建新
shared_ptr或拷贝现有shared_ptr时,计数器增加。 - 当
shared_ptr被销毁(例如通过析构函数)或重置(通过 reset 方法)时,计数器减少。 - 当计数器为零时,对象被自动删除,通常通过调用
delete操作符。
这种机制确保了对象在最后一个 shared ptr 销毁时被释放,防止了内存泄漏。特别适合多线程或复杂数据结构中需要共享对象的场景。
shared_ptr代码实现:
#include <iostream>
#include <atomic>using namespace std;// 共享引用计数类
template<typename T>
class SharedCount{
private:T* ptr; // 指向同一对象的指针atomic_int count; // 引用计数SharedCount(const SharedCount& ) = delete;SharedCount& operator=(const SharedCount& ) = delete;
public:SharedCount(T *p) : ptr(p),count(1) {}~SharedCount() {delete ptr;}// 增加引用计数void increment(){count++;}// 减少引用计数void decrement(){if(--count == 0)delete this;}T* get() const {return ptr;}
};template<typename T>
class shared_ptr{
private:T* ptr; // 指向管理的对象SharedCount<T>* countPtr; // 指向引用计数类对象
public:// 构造函数shared_ptr(T *p = nullptr) : ptr(p) {if(p) {countPtr = new SharedCount<T>(p);} }// 拷贝构造shared_ptr(const shared_ptr& other) : ptr(other.ptr), countPtr(other.countPtr) {if(countPtr)countPtr->increment();}// 移动构造shared_ptr(shared_ptr&& other) : ptr(other.ptr), countPtr(other.countPtr) {// 清空原内存other.ptr = nullptr;other.countPtr = nullptr;}~shared_ptr() {if(countPtr)countPtr->decrement();}T* operator->() const{return ptr;}T& operator*() const{return *ptr;}void reset(T *p = nullptr) {if(p == ptr) return ;if(countPtr)countPtr->decrement();ptr = p;if(p) {countPtr = new SharedCount<T>(p);}elsecountPtr = nullptr;}T* get() {return ptr;}
};int main()
{shared_ptr<int> ptr1(new int(10));shared_ptr<int> ptr2 = ptr1;cout << "ptr1: " << *ptr1 << endl;cout << "ptr2: " << *ptr2 << endl;ptr1.reset();cout << "ptr2: " << *ptr2 << endl;shared_ptr<int> ptr3 = move(ptr2);// cout << "ptr2: " << *ptr2 << endl;cout << "ptr3: " << *ptr3 << endl;
}
三、make_shared 相 比 shared_ptr(newT(args…))有什么好处?
1. 避免额外的内存分配
std::make_shared会在一次内存分配中同时分配对象本体和引用计数,并且是连续的,而std::shared ptr<T>(new T(args...))需要两次分配(一次给T,一次给shared_ptr的控制块,而且不连续)。- 这不仅减少了
malloc/free的开销,还能提高缓存命中率。
2. 减少异常安全问题
std::shared ptr<T>(new T(args...))是两个独立的操作,new T(args...)可能会抛出异常,而shared_ptr还未成功构造,导致内存泄漏。std::make shared进行的是原子操作,不存在这个问题。
3. 更高效的引用计数管理
- 由于
std::make_shared在一个内存块中存储对象和引用计数,指针访问时可以减少额外的缓存访问,提高运行效率。 std::shared_ptr<T>(new T(args...))由于分开分配对象和控制块,会导致额外的指针间接访问。
4.代码更简洁
auto ptr = std::make_shared<T>(args...)比auto ptr = std::shared ptr<T>(new T(args...))更简短,可读性更好。
进程
进程与线程的区别
进程是操作系统中资源分配的基本单位,线程是进程中执行的基本单位,进程拥有独立的内存空间,而线程共享进程的内存空间和资源。
-
基本定义: 进程是操作系统中资源分配的最小单位,线程是程序执行的最小单位
-
内存分配: 每个进程拥有独立的虚拟地址空间(代码段、数据段、堆等),线程共享进程的内存空间,代码段、数据段、堆区,但每个进程也有自己独立的线程栈、寄存器、PC指针等。
-
资源开销: 进程创建和切换开销比较大,线程比较小
-
调度与上下文切换: 进程的上下文切换需要切换页表、刷新 TLB,涉及内核态到用户态的切换,保存进程控制块PCB;线程的调度与上下文切换无需切换页表和 TLB,因为线程共享进程的内存空间,只需保存线程私有数据:线程控制块(TCB)中的栈指针、寄存器状态
-
通信方式: 进程的通信需要使用进程间通信方式,如管道、消息队列、共享内存,线程可直接读写全局变量和堆区数据,但需要做同步和互斥操作,否则可能引起数据的竞争和不一致
-
并发性: 进程适合多任务的并发,进程间隔离性好;线程适合多线程并发,资源共享效率高
-
生命周期: 线程依附于进程存在,进程终止会强制销毁所有线程,而线程终止不会影响同进程的其他线程
-
应用场景: 进程应用于高隔离性任务,比如浏览器多个标签,多核并行计算,容错率比较高。线程则应用于需要高效协作的高并发与实时任务(高并发服务器、实时数据请求),IO密集型任务(web服务器),容错率比较低,线程崩溃可能导致整个进程终止。
进程的控制
1. 进程的创建: 通过系统初始化,fork()、exec(),或者用户交互创建新的进程,分配资源(PID,虚拟地址空间)、初始化上下文(代码段、数据段、堆数据),设置权限
2. 进程运行: 进入就绪队列,等待调度去调度,然后在运行、阻塞、就绪核心三态之间切换
3. 进程终止: exit正常终止、kill异常终止,释放资源(打开的文件描述符、释放内存、解除内存映射),通知父进程(若父进程通过wait等待),若父进程未回收,变成僵死进程
4. 特殊情况处理
进程和线程的创建与结束
进程的创建
1. 用户态调用 fork() / vfork() / clone()
fork()创建一个几乎完全独立的子进程vfork()创建子进程并阻塞父进程,子进程共享父进程地址空间直到 execclone()可精细控制资源共享(线程库 pthread_create 底层使用它)
2. 系统调用进入内核
fork()→sys_fork()→do_fork(flags)→copy_process()- 内核分配新的 task_struct,初始化内核栈、寄存器、父子关系
- 设置子进程状态,加入就绪队列
3. 用户态返回
- 父进程返回子进程 PID
- 子进程返回 0

Linux创建进程或线程的方式都是采用克隆方式,子进程或子线程会直接继承父进程的信息。从内核的角度来看,内核会创建一个新的task_struct对象,并将父进程的task_struct对象的成员信息复制给新的task_struct对象。
task_struct对象有很多成员,进程和线程的复制过程存在差异。注意,这里所说的父进程指的是当前正在执行的用户程序。创建进程和线程都是通过clone系统调用完成,具体是创建进程还是线程,需要根据传入的函数参数区分。
如图1所示,用户程序通过fork函数创建进程,fork函数是glibc库中的一个函数,其底层依赖clone系统调用。 调用fork函数后,内核首先会获取父进程的task_struct对象,然后,内核会创建一个新的task_struct对象(子进程),接着,内核会将父进程task_struct对象的成员直接复制给子进程task_struct对象。
进程的结束
1. 调用 exit()
- 用户态调用 exit 系列函数(如
_exit()) - 内核释放用户空间资源、关闭文件、清理信号
2. 变为僵尸进程
- 子进程结束后,内核保留 task_struct 以便父进程获取退出状态
- 父进程调用
wait()/waitpid()收集退出状态
3. 完全回收
- 内核释放 task_struct、内存、文件等资源
线程的创建
1. 用户态调用 pthread_create()
- 底层调用
clone()系统调用 - 设置
CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND | CLONE_THREAD等标志
2. 内核创建任务
clone()→do_fork()→copy_process()- 共享父线程的大部分资源(地址空间、文件描述符表等)
- 分配独立栈和寄存器上下文
3. 线程就绪
- 内核调度器将线程加入就绪队列
- CPU 调度线程执行

Linux通过pthread_create函数来创建线程,pthread_create函数底层同样是依赖clone系统调用。线程的创建过程和线程的创建过程基本类似,不同点在于复制mm成员(虚拟地址空间)。创建线程时,内核会直接将mm(指针成员)指向父进程的mm_struct对象,这样子线程就会共享父进程的mm_struct对象了。
线程为什么被称为轻量级进程?原因在于子线程通常会直接共享父进程的资源,不会单独创建新的资源。
父进程和子线程共享虚拟空间,意味着二者访问的是相同的物理内存(数据和代码都是用的同一份)。这种方式虽然比较高效和节约系统资源,但是存在数据安全和资源竞争问题。多线程开发需要通过锁机制来保证数据安全和顺序访问。
值得注意的是,父进程和子线程有一块内存区域不能共享,那就是栈。栈用于存储函数调用时的局部变量、函数参数和返回地址等信息。如果父进程和子线程共用一个栈,那么父进程和子线程的函数调用链将会被破坏,程序将会跑飞。怎么解决这个问题呢?我们得给每个线程单独分配一个栈,这就是线程栈。
线程的结束
1. 调用 pthread_exit()
- 内核标记线程结束
- 回收线程栈和寄存器上下文
- 如果是主线程退出,整个进程也会退出
2. 线程同步
- 其他线程可以通过线程连接
pthread_join()获取退出状态(需要结果或同步) - 内核释放线程占用资源
- 通过线程分离
pthread_detach()将线程设置为分离状态,自动回收资源
线程栈
默认栈
线程栈是操作系统为每个线程分配的私有内存区域,用于存储函数调用时的局部变量、参数、返回地址及临时数据。其数据结构遵循后进先出(LIFO)原则,确保函数调用链的顺序执行。
子线程共享父进程的虚拟地址空间,虚拟地址空间能够用来分配线程栈的区域就只有内存映射区和堆了。
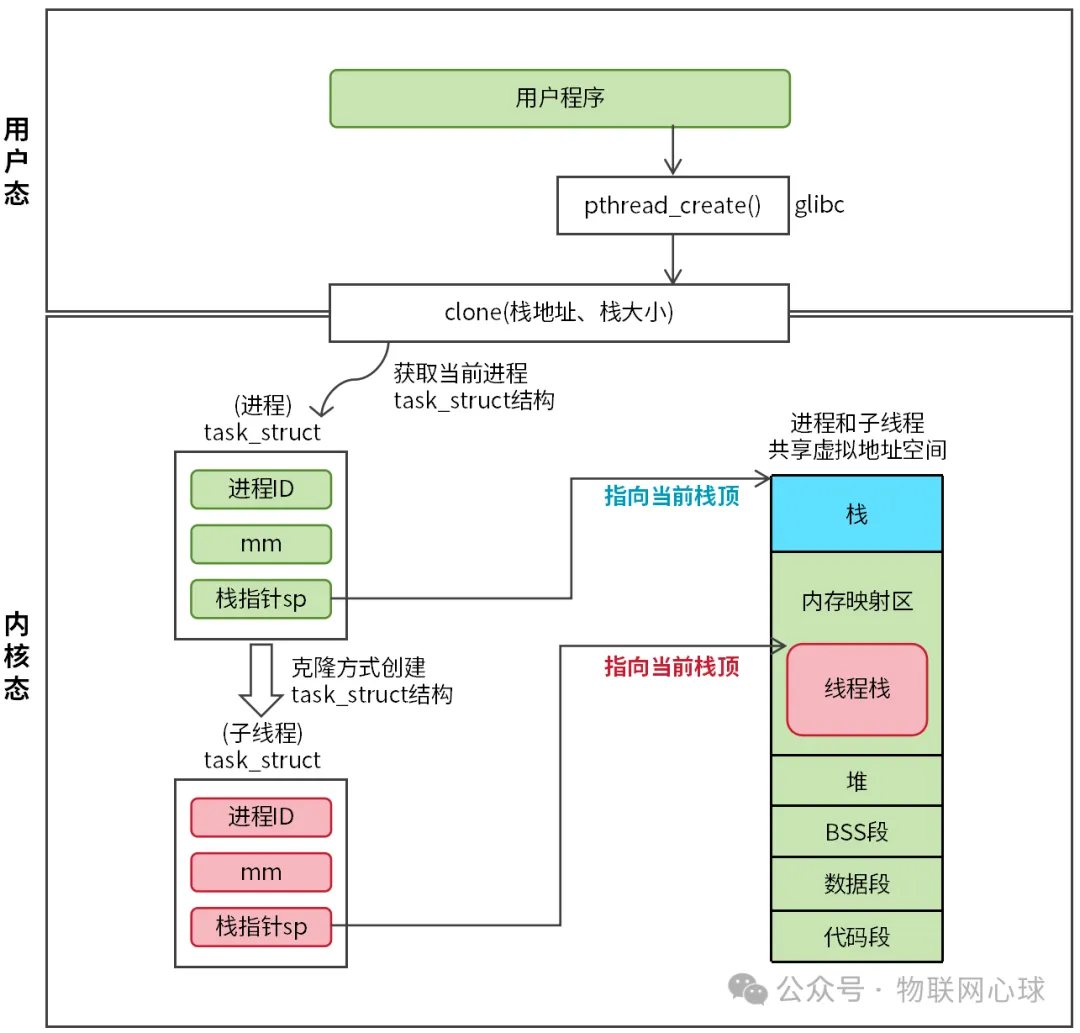
如图所示,task_struct结构(进程或线程)中有一个sp(栈指针),sp用于记录当前栈顶地址,sp指向的地址就是进程栈或线程栈所在的位置。
创建进程时,内核会将父进程的sp直接复制给子进程,所以子进程使用的进程栈就是虚拟地址空间的栈。而通过clone系统调用创建子线程时,需要传入栈地址和栈大小,内核会根据传入的参数设置sp和栈大小。也就是说线程栈是由用户程序来设置。
进行线程切换的区别
切换过程
- 保存当前进程的硬件上下文 task_struct->v_stack
- 修改当前进程的PCB,修改运行状态(阻塞或就绪),存储数据的保存,内存,寄存器,状态
- 修改被调度进程的PCB,将状态修改为就绪态,存入就绪队列
- 存储管理数据的切换
- 恢复硬件上下文,让PC指针指向被调度的进程代码
进程线程切换区别
-
切换内容不同
- 进程切换:需要切换整个进程的上下文,包括进程控制块(PCB)、内存地址空间、打开的文件描述符、信号处理机制等。操作系统需要保存当前进程的所有状态,并加载新进程的状态。
- 线程切换:只需切换线程的上下文(如线程控制块 TCB、寄存器状态、程序计数器等),无需切换内存空间和全局资源(因为同一进程的线程共享这些资源)。
-
开销不同
- 进程切换开销大:涉及内存地址空间切换(可能触发 TLB 刷新)、寄存器状态保存等,耗时较长。
- 线程切换开销小:仅需保存和恢复少量线程私有数据,效率更高。
-
资源隔离性
- 进程切换是不同地址空间之间的切换,进程间资源完全隔离。
- 线程切换是同一地址空间内的切换,线程共享进程的资源。
同一进程内的线程切换: 线程共享内存空间、文件句柄、信号处理,无需修改内存映射,仅需保存当前线程的寄存器、栈指针等私有数据。
不同进程内的线程切换: 相当于进程的切换,切换整个上下文(内存空间、PCB),原进程不可见
系统调用是否引发线程切换

僵死守护孤儿
- 孤儿进程: 父进程先于子进程结束运行,子进程成为孤儿进程并由init进程接管。
- 僵尸进程: 子进程已经终止,但父进程尚未调用wait()或waitpid()来获取子进程的终止状态,子进程进入僵尸进程状态。
- 守护进程: 在后台运行的特殊进程,通常以init进程为父进程,独立于终端或控制终端,用于执行常驻任务,创建守护进程时有意把父进程结束,然后被1号进程init收养
僵死进程的危害: 占用资源,大量的僵死进程可能导致系统不能产生新进程或崩溃
如何清理僵尸进程? 在父进程中通过 wait() 避免产生僵死进程,一旦出现,无法通过kill杀死僵死进程,但可以杀死父进程变成孤儿进程,让init进程去管理进程的回收工作
fork的作用
- fork是一个系统调用,用于创建新的进程。
- 调用fork会生成一个新的子进程,该子进程几乎与父进程完全相同。
- 子进程从父进程继承了代码、数据、堆栈以及其他进程上下文信息。
- 子进程还会拥有父进程打开的文件描述符和其他系统资源。
- fork的返回值不同:在父进程中,返回子进程的进程ID;在子进程中,返回值为0。
- 通过fork,实现了进程的复制和创建,提高了系统的并发性。
- 父进程和子进程在fork之后会同时执行代码,但由于返回值不同,可以进行逻辑分支选择。
fork与vfork的区别
- 内存共享:
fork():子进程会拷贝父进程的数据段和代码段(实际是通过写时复制机制实现),vfork():子进程与父进程共享数据段,不进行拷贝 - 执行顺序: fork 执行顺序不确定,由系统调度策略决定,vfork保证子进程先运行,在子进程调用
exec()或exit()之前,父进程阻塞 - 资源开销: fork()需要为子进程分配独立的内存空间,vfork() 不需要为子进程分配新的内存空间,因为它直接共享父进程的地址空间,因此更高效
- 适用场景:
fork()适用于需要创建一个完整的子进程并独立运行的场景,vfork()适用于子进程创建后立即调用 exec 系列函数替换自身程序的场景,通常用于节省资源。 - vfork() 常用于shell命令执行,快速生成子进程,然后加载新的程序,不需要复制父进程的大量内存页
父进程创建子进程,有哪些资源共享
在 Unix/Linux 系统中,父进程通过 fork() 系统调用创建子进程时,操作系统会采用写时复制(Copy-On-Write, COW) 机制处理资源继承,即默认情况下子进程会共享父进程的大部分资源,但当资源被修改时会触发复制
共享的资源(未修改时共享,修改时触发复制)
- 代码段
- 全局变量与静态变量
- 文件描述符: 子进程会复制父进程的文件描述符表(指向相同的打开文件表),因此共享已打开的文件、管道、网络连接(如 socket) 等。
- 信号处理方式:子进程继承父进程的信号处理函数(如
SIGINT的处理方式) - 共享内存、信号量、消息队列等进程间通信(IPC)资源
不共享的资源(子进程独立拥有)
-
进程 ID(PID)和父进程 ID(PPID) 子进程有唯一的 PID,且其 PPID 为父进程的 PID,与父进程完全独立。
-
内存页表(部分) 虽然代码段、数据段初始共享,但父子进程的页表项独立,写时复制的触发由各自的页表控制。
-
信号 pending 集 子进程不会继承父进程未处理的信号(pending signals),两者的信号 pending 集完全独立。
-
计时器和统计信息 如进程的 CPU 使用时间、创建时间等,父子进程各自独立记录。
-
锁资源 父进程持有的文件锁(如
flock())不会被子进程继承,子进程需重新获取锁。
进程间通信
1. 匿名管道:
- 匿名管道是特殊文件只存在于内存,没有存在于文件系统中
- shell命令中的「
|」竖线就是匿名管道,通信的数据是无格式的流并且大小受限 - 通信的方式是单向的,半双工,数据只能在一个方向上流动,如果要双向通信,需要创建两个管道
- 再来匿名管道是只能用于存在父子关系的进程间通信
- 匿名管道的生命周期随着进程创建而建立,随着进程终止而消失。
2. 命名管道 突破了匿名管道只能在亲缘关系进程间的通信限制,因为使用命名管道的前提,需要在文件系统创建一个类型为 p 的设备文件,那么毫无关系的进程就可以通过这个设备文件进程通信。
- 不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取
- 同时通信数据都遵循先进先出原则,不支持 lseek 之类的文件定位操作。
- FIFO有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中(缓存在内核中)。
- FIFO可以在无关进程之间的交换数据,与无名管道不同
3. 消息队列 克服了管道通信的数据是无格式的字节流的问题,消息队列实际上是保存在内核的「消息链表」,消息队列的消息体是可以用户自定义的数据类型,发送数据时,会被分成一个一个独立的消息体,当然接收数据时,也要与发送方发送的消息体的数据类型保持一致,这样才能保证读取的数据是正确的。但消息队列通信的速度不是最及时的,并且数据块也有一定的大小限制,毕竟每次数据的写入和读取都需要经过用户态与内核态之间的拷贝过程。
- 内核维护:消息队列存在于内核空间,进程通过系统调用访问。
- 消息有格式:每条消息包含 类型(mtype) 和 正文(mtext)。
- 支持选择性接收:接收进程可以按消息类型取消息,而不是只能 FIFO。
- 有边界:一次发送/接收是一条完整消息,不会像管道一样出现粘包/拆包。
- 持久性:即使所有进程退出,消息队列仍存在,直到显式删除。
- 异步通信:发送方和接收方不需要同步执行。
- 受系统限制:消息大小、队列容量受内核参数约束(如
/proc/sys/kernel/msgmax)。 - 相关接口:有SystemV和POSIX两类。
4. 共享内存 可以解决消息队列通信中用户态与内核态之间数据拷贝过程带来的开销
- 它直接分配一个共享空间,每个进程都可以直接访问 ,就像访问进程自己的空间一样快捷方便,不需要陷入内核态或者系统调用,大大提高了通信的速度,享有最快的进程间通信方式之名。
- 但是便捷高效的共享内存通信,带来新的问题,多进程竞争同个共享资源会造成数据的错乱。
5. 信号量 解决了共享资源造成的数据错乱
- 做到了对共享资源的保护,以确保任何时刻只能有一个进程访问共享资源 ,这种方式就是互斥访问。
- 信号量不仅可以实现访问的互斥性,还可以实现进程间的同步。
- 信号量其实是一个计数器,表示的是资源个数,其值可以通过两个原子操作来控制,分别是 P 操作和 V 操作
6. 信号 虽然与信号量名字十分相似,但功能一点儿都不⼀样。
- 信号是进程间通信机制中异步通信机制,不承载数据。信号可以在应用进程和内核之间直接交互,内核也可以利用信号来通知用户空间的进程发生了哪些系统事件
- 信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令)
- 在 Linux 操作系统中, 为了响应各种各样的事件,提供了几十种信号,分别代表不同的意义。我们可以通过
kill -l命令,查看所有的信号: - 一旦有信号生,进程有三种方式响应信号 1. 执行默认操作、2. 捕捉信号、3. 忽略信号。
- 有两个信号是应用进程无法捕捉和忽略的,即
SIGKILL和SEGSTOP,这是为了方便我们能在任何时候结束或停止某个进程。
7. 前面说到的通信机制,都是工作于同一台主机,如果要与不同主机的进程间通信,那么就需要 Socket 通信了 。Socket 实际上不仅用于不同的主机进程间通信,还可以用于本地主机进程间通信。可根据创建Socket 的类型不同,分为三种常见的通信方式,一个是基于TCP 协议的通信方式,一个是基于 UDP 协议的通信方式,一个是本地进程间通信方式。
进程的调度机制
-
先来先服务,长作业运行,短作业不利
-
最短作业优先算法: 长作业饿死
-
最高响应比优先调度算法: 响应比 = (等待时间 + 要求服务时间)/ 要求服务时间,简单的较为公平
-
时间片轮转: 时间短上下文切换频繁,时间长,短作业响应长,20~50ms
-
最高优先级: 低优先级得不到执行
-
多级反馈队列调度算法

-
优点:综合考虑 响应速度 和 吞吐量,是 通用调度策略。
-
缺点:实现复杂,调参(队列数、时间片大小、降级策略)困难。
-
应用:现代操作系统(Linux CFS 算法也受它影响)。
非抢占式调度算法
| 算法 | 思想 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| 先来先服务 | 按进程到达顺序调度(FIFO) | 公平、简单 | 对短作业不利,平均等待时间可能长 | 批处理系统 |
| 短作业优先 | 优先选择执行时间最短的进程 | 平均等待时间最小 | 长作业可能饥饿;需预知运行时间 | 批处理系统,适合任务长度已知的情况 |
| 高响应比优先 | 计算响应比 R = (等待时间 + 服务时间) / 服务时间,取 R 最大的进程 | 平衡了长短作业,避免饥饿 | 需估计服务时间,计算复杂 | 批处理系统 |
抢占式调度算法
| 算法 | 思想 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| 优先级调度 | 按优先级执行,高优先级优先 | 可处理紧急任务 | 低优先级进程可能长期饿死 | 实时系统;可配合 Aging 技术 |
| 时间片轮转 | 每个进程按固定时间片轮流执行 | 公平,适合交互式任务 | 时间片太小开销大;太大响应慢 | 分时系统,交互式系统 |
| 多级反馈队列 | 多队列+逐级降级;短作业在高优先级优先完成 | 综合兼顾响应和吞吐量;适合通用场景 | 实现复杂,参数调优难 | 通用操作系统(Linux、Windows) |
Linux内核中的调度
1、O(1) 调度器(Linux 2.6 以前)
- 时间复杂度 O(1),适合 SMP 系统。
- 优缺点:简单高效,但不够公平。
2、CFS(Completely Fair Scheduler,Linux 2.6.23+)
- 核心思想:每个进程应该公平地获得 CPU 时间。
- 优点:公平性好,适合多任务环境。
- 缺点:实时性较弱。
- 实现:
- 基于红黑树(rbtree),用 虚拟运行时间 vruntime 衡量。
- 选择 vruntime 最小的进程执行。

3、实时调度(RT Scheduling)
- SCHED_FIFO(先来先服务,不会被抢占,除非更高优先级 RT 任务出现)。
- SCHED_RR(时间片轮转)。
- SCHED_DEADLINE(基于 EDF,Earliest Deadline First)。
Linux内核调度
| 算法 | 思想 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| O(1) 调度器 (Linux 2.6 前) | 时间复杂度 O(1),就绪队列按优先级 | 简单高效,适合 多处理器系统(SMP) | 公平性差 | 早期 Linux |
| CFS 完全公平调度 (2.6.23+) | 红黑树,按 vruntime(虚拟运行时间)公平分配 CPU | 公平,适合多任务 | 实时性不足 | 现代 Linux 默认调度器 |
| 实时调度 | SCHED_FIFO、SCHED_RR、SCHED_DEADLINE | 实时性强 | 可能饿死普通任务 | 实时任务场景 |
线程
互斥锁、信号量、自旋锁
互斥锁
- 目的: 主要用于保护共享资源,确保同一时间只有一个线程或进程可以访问该资源,加锁解锁操作
- 工作原理:线程尝试获取锁时,若锁被占用,则主动阻塞并让出CPU,进入睡眠状态,由内核调度其他线程运行,可抢占
- 阻塞行为:线程睡眠,释放CPU资源,直到锁被释放后被唤醒
- 适用场景:锁持有时间较长、用户态编程、单核或多核系统均可
- 开销:上下文切换带来较高延迟,但无忙等待浪费CPU
- 示例:多线程共享一个队列时的保护。
- 互斥锁是“独占”访问
互斥锁的底层本质是原子操作 + 调度协作:
- 硬件层:提供原子指令(CAS/TAS)保障锁状态修改的原子性。
- 内核层:通过futex等机制管理阻塞/唤醒,减少CPU浪费。
CAS的工作流程: 比较内存中的值和预期值,如果一致则更新为新值,否则不操作
信号量
-
工作原理:基于计数器实现,允许多个线程同时访问资源(取决于信号量的初始值),适用于需要限制并发访问数量的场景
-
信号量可以是二元的,也可以是计数的。二元信号量类似于互斥锁,计数信号量用于控制多个资源的访问。
-
可抢占: 信号量在等待时会将线程阻塞,并让出CPU。操作系统可以调度其他线程运行,从而避免CPU资源的浪费
- P操作: 将sem减1,相减后,如果
sem < 0,进程/线程进入阻塞等待,否则继续,P操作可能或阻塞 - V操作: 将sem加1,相加后,如果
sem <= 0,唤醒其中一个等待中的进程/线程,V操作不会阻塞
- P操作: 将sem减1,相减后,如果
-
适用场景:线程池管理、生产者-消费者
-
开销:类似互斥锁,需内核介入调度。
-
关键区别: 互斥锁是“独占”访问,信号量是“配额”访问。
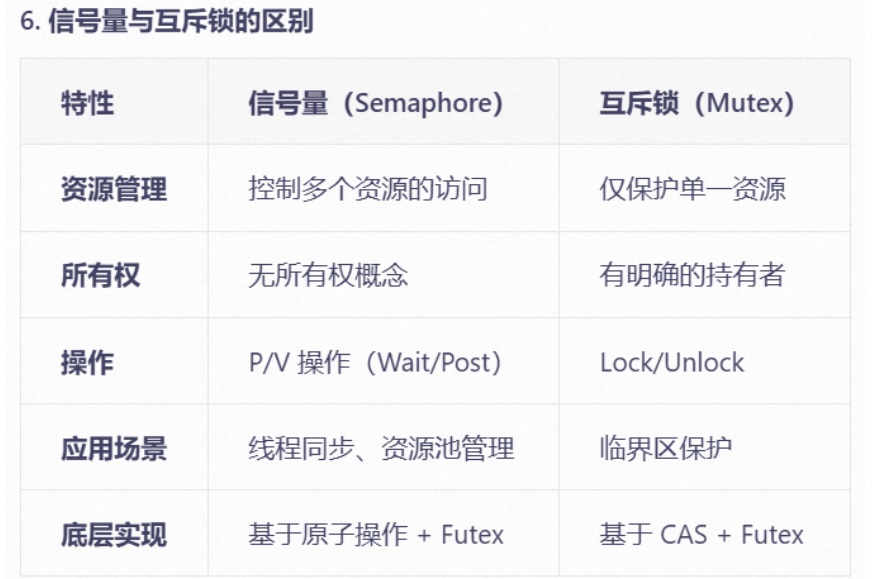
自旋锁
-
工作原理:线程通过循环用户态 忙等待检查锁是否可用,直到获取锁,会一直循环等待,直到CPU可用
-
阻塞行为:不可抢占,不主动让出CPU,线程持续占用CPU资源循环等待,直到获取锁
-
让出执行权,运行态到就绪态
-
适用场景:锁持有时间极短(几行代码),多核系统(单核自旋无意义,因为会浪费CPU时间片,在单处理器上,需要抢占式的调度器,否则,自旋锁在单 CPU 上无法使⽤),中断上下文(不可睡眠的场景)
-
开销:低延迟(自旋锁的开销较小,避免了线程切换的开销),但高CPU占用(空转)
-
示例:Linux内核中的短临界区保护。
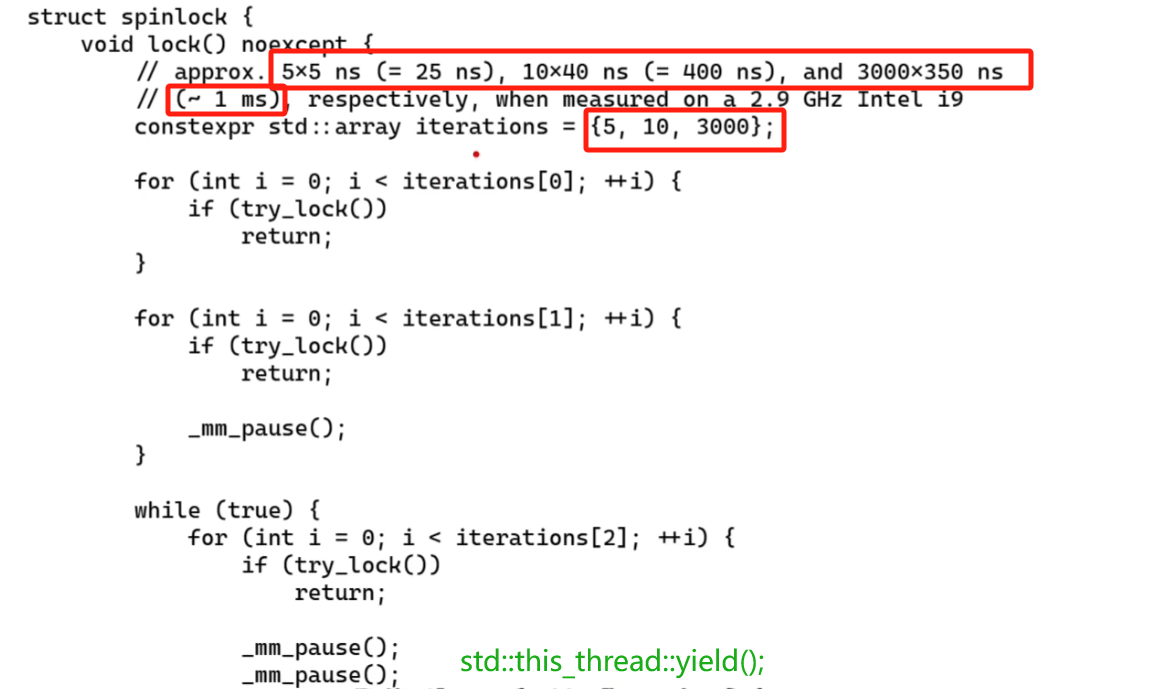
TestAndSet
typedef struct lock_t {int flag;
}lock_t;
int testAndSet(int* oldPtr, int newVal){int old = *oldPtr;*oldPtr = newVal;return old;
}
// 自旋
void lock(lock_t *lock) {while (testAndSet(&lock->flag, 1) == 1);
}
void unlock(lock_t *lock) {lock->flag = 0;
}
互斥锁和自旋锁区别总结:
- 等待策略: 互斥锁让出CPU,运行态 -> 阻塞态,互斥锁是在用户态忙等待,最后通过yield()让出CPU,运行态 -> 就绪态,CPU随时可调度
- 开销: 互斥锁的主要开销来自于两次上下文切(换睡眠一次,唤醒一次),自旋锁的开销是CPU空转的时间
线程等待锁的策略: 对于互斥锁如果线程拿不到锁,它会阻塞休眠(futex机制)。对于自旋锁如果线程拿不到锁,它会在一个循环里不停地尝试获取(用户态忙等待)
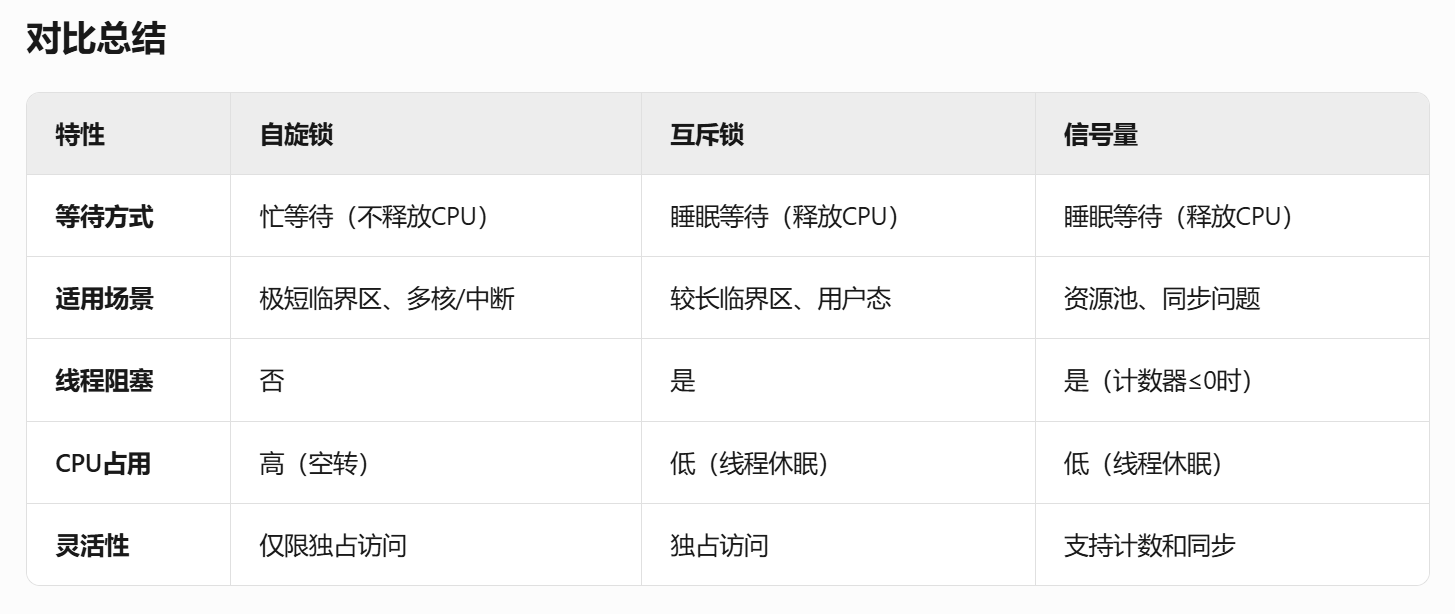
- 优点:上下文切换开销小,适合锁持有时间极短的场景。
- 缺点:浪费CPU资源,可能导致性能下降(尤其在单核CPU)。
选择建议
-
自旋锁: 适用于锁持有时间非常短的情况(小于1ms),例如保护非常小的临界区,如内核中断处理。自旋锁避免了线程切换的开销,但可能会导致CPU资源的浪费。
-
互斥锁: 适用于锁持有时间较长的情况(IO操作,CPU密集型),需要线程睡眠等待的独占访问(如用户态代码)。互斥锁在等待时会将线程阻塞并让出CPU,避免了CPU资源的浪费,提高了系统的整体效率。
-
信号量: 适用于需要限制并发访问数量的场景,需要控制资源数量或线程间同步(如生产者-消费者)。信号量可以控制多个线程同时访问资源的数量,避免资源过度竞争。
用户态尽量使用mutex,IO操作,CPU密集都用mutex,通过工具bpf知道有性能瓶颈,考虑使用自旋锁优化,mutex设置为adptiva,,自适应,先在用户态忙等待(自旋4us),再陷入内核
无锁等待:
typedef struct lock_t {int flag;queue<uint64_t> *thread; // 等待队列
}lock_t;void lock(lock_t *lock)
{// 等待while (testAndSet(&lock->flag, 1) == 1) {// 保存现场 TCB// 将线程保存到等待队列 TCB// 将线程设置为等待// 调度}
}
无锁编程
- 特点:不使用传统锁,而是通过原子操作实现并发安全 atomic
- 适用于高性能低延迟场景(如高频交易、无锁队列)
如何选择合适的锁?
临界区长度:
- 极短(<1µs)→ 自旋锁
- 较长(>1ms)→ 互斥锁
读写比例:
- 读多写少 → 读写锁 / RCU
- 读写均衡 → 互斥锁
是否需要等待条件:
- 是 → 条件变量 + 互斥锁
自旋锁和信号量可以睡眠吗?
- 自旋锁不可以睡眠,信号量可以
- 自旋锁自旋锁禁止处理器抢占;而信号量允许处理器抢占
- 自旋锁-睡眠-不抢占唤不醒(除多核/中断),信号量抢占运行并唤醒
- 多核/中断:当前核睡眠,其他核运行,有可能唤醒;中断程序可运行,但中断程序通常不唤醒睡眠锁
自旋锁和信号量可以用于中断吗?
- 信号量不能用于中断中: 因为信号量会引起休眠(阻塞等待,线切调度和上下文切换),中断不能休眠。
- 自旋锁可以用于中断:,自旋锁在尝试获取锁时会持续循环等待,但不会进入休眠状态,中断处理程序通常需要快速执行。在获取锁的时候一定要先禁止本地中断(本CPU中断),对于多核机来说,否则可能导致锁死现象的发生。
Futex机制
Linux内核中futex锁原理及应用
futex技术分享
Fast Userspace Mutex(Futex)机制:
经研究发现,很多同步是无竞争的,即某个进程进入互斥区,到再从某个互斥区出来这段时间,常常是没有进程也要进这个互斥区或者请求同一同步变量的。但是在这种情况下,这个进程也要陷入内核去看看有没有人和它竞争,退出的时还要陷入内核去看看有没有进程等待在同一同步变量上。这些不必要的系统调用(或者说内核陷入)造成了大量的性能开销。为了解决这个问题,Futex就应运而生。
futex是一种快速的用户级别的锁,他其实是由用户态和内核态协助完成
它的核心思想是:在无竞争时完全在用户态处理锁操作,仅在发生竞争时进入内核态进行阻塞和唤醒管理。
- 在无竞争的情况下,应用程序会自动更改锁状态字,而无需进入内核。
- 在有竞争环境下,应用程序需要等待锁的释放,或者在解锁操作的情况下需要唤醒等待任务。此时需要一个内核对象以及等待队列。
1. 用户态原子操作
- 无竞争时无需系统调用:线程通过原子指令(如
CAS或atomic_inc)尝试获取锁。 - 原子变量控制状态:使用共享内存中的原子变量(如
int)表示锁状态(0=未锁,1=已锁)。 - 自旋优化:在尝试失败后,可能短暂自旋等待(如
pause指令),减少上下文切换开销。
2. 内核态阻塞与唤醒
当锁竞争激烈时,Futex 通过内核介入管理阻塞线程:
- 等待队列:无法获取锁的线程通过
futex_wait()系统调用进入内核等待队列。 - 唤醒机制:释放锁时通过
futex_wake()唤醒等待队列中的线程。 - 避免惊群效应:
futex_wake()可指定唤醒一个或多个线程,而非广播所有等待者。
目标:
- 尽可能避免系统调用,因为系统调用通常会消耗几百个指令。
- 避免不必要的上下文切换: 上下文切换会使TLB无效等相关的开销,保存内核和用户态的栈
原理: 考虑到更加方便的管理锁对象,所以futex直接通过虚拟地址来处理锁,而不是像以前一样创建一个需要初始化和以及跨进程全局句柄的内核句柄。
2.1 三个关键点
- 我们为每个futex使用一个唯一的标识符(内核)(它可以在不同的地址空间中共享,所以每个空间中可能有不同的虚拟地址):这个标识符是“strcut page”指针和该page中的偏移量
- 该结构体可以表示进程放在哈希表中的futex对象。多个进程可能占用多个futex对象,需要一个队列来管理阻塞在该进程上的任务,根据key查找任务
- 给上层提供一个简单的唯一标识符
2.2 具备的功能:
- 支持一种锁粒度的睡眠与唤醒操作,多个进程,对应多个不同的fute,不同的futex操作不一样,所以需要futex锁粒度的睡眠与唤醒操作.
- 管理进程挂起时的等待队列,多个进程同时阻塞在一个futex
2.3具体实现
数据结构
- futex在用户空间只是一个地址对齐的整形—>uaddr。
- 内核中的futex系统设计了三个基本结构。futex_key,futex_q, 以及futex_queues。
- futex_key: 是一个用户空间中futex的地址+地址映射对象,作为键的标识,调用futex系统调用时,必须传入futex的地址uaddr,同时才能标识出这个futex。它也是futex可以在进程间共享使用的保证。
- futex_queues: 是一个等待队列。
- futex_q: 代表一个任务(进程或线程)在某个futex上的等待关系,链入到futex_queues队列中。

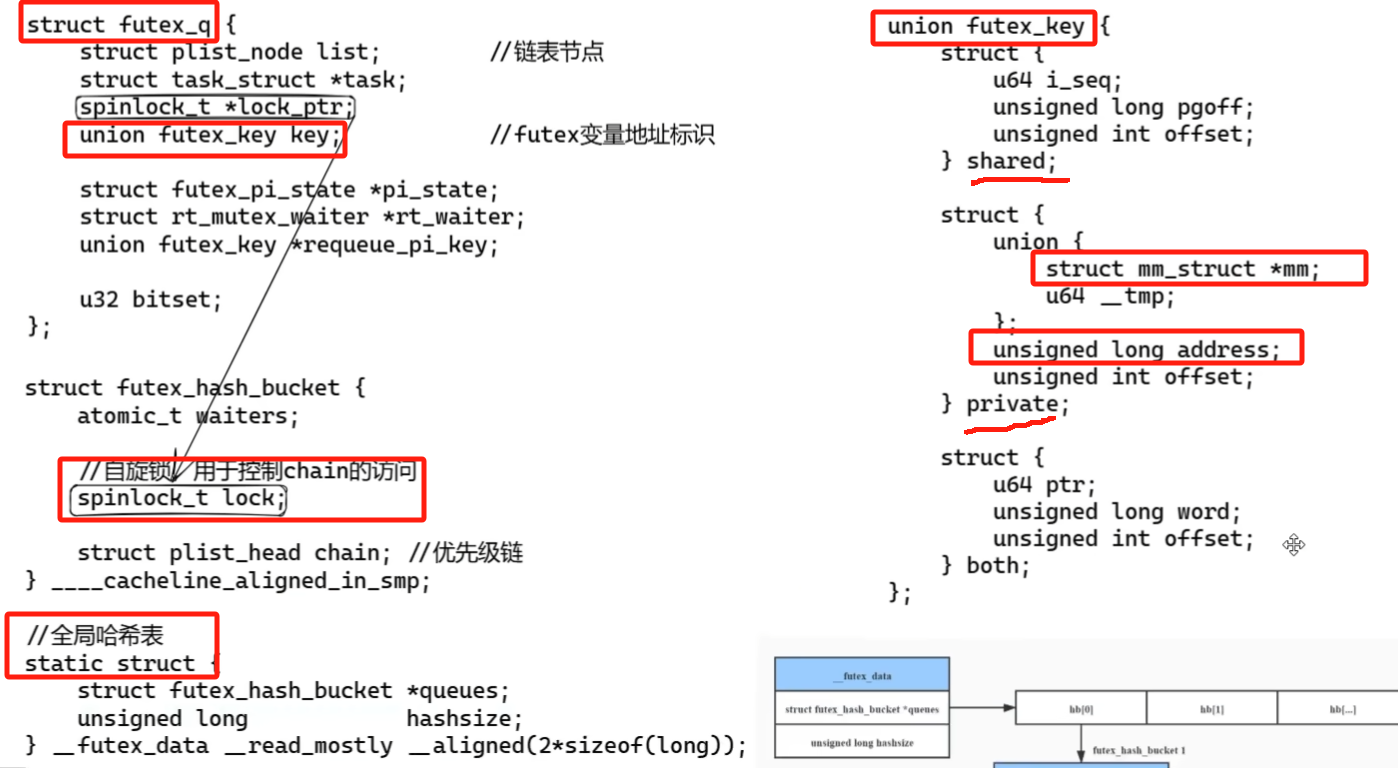
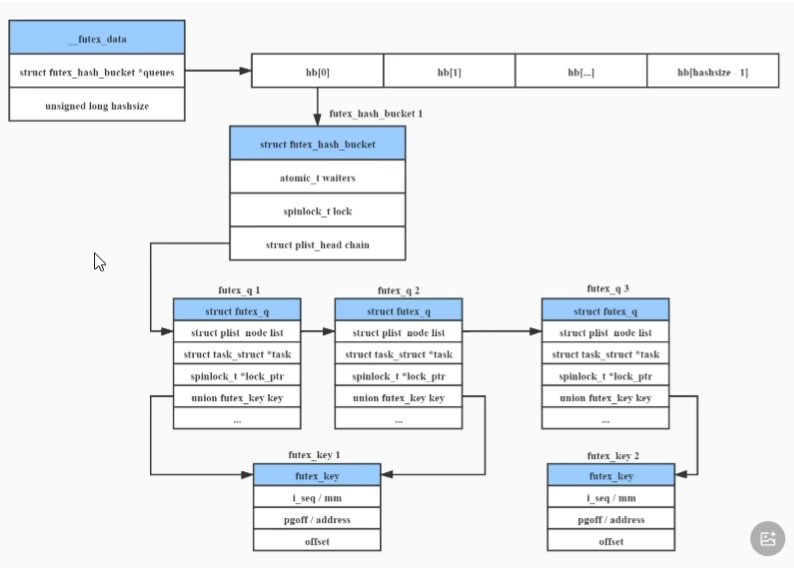
futex_wait:
- 插入等待队列,挂当前进程
- 创建任务超时,创建定时任务,定时去唤醒进程
futex_wake: 遍历等待队列,唤起等待线程
// 在uaddr指向的这个锁变量上挂起等待(仅当*uaddr==val时)
int futex_wait(int *uaddr, int val);// 唤醒n个在uaddr指向的锁变量上挂起等待的进程
int futex_wake(int *uaddr, int n);
- uaddr:就是用户态下共享内存的地址,里面存放的是一个对齐的整型计数器。
uaddr参数的比较 - 通过支持虚拟地址的内存对象和该对象中的偏移来定义锁标识。我们用元组[B,O]来标记这一点。可以区分三种基本的记忆类型来表示B:(a)匿名内存(/dev/zero),(b)共享内存段,和(c)内存映射文件。虽然(b)和(c)可以在多个进程之间使用,但(a)只能在同一个进程的线程之间使用。利用锁的虚拟地址作为内核句柄也提供了一种集成的访问机制,可以自动将虚拟地址与其内核对象联系起来。
val:FUTEX_WAIT: 原子性的检查uaddr中计数器的值是否为val,如果是则让进程休眠,
n:FUTEX_WAKE: 最多唤醒n个等待在uaddr上进程。
3. 上层应用
3.1 mutex

lock:变量的值有3种:
- 0 代表当前锁空闲
- 1 代表有线程持有当前锁
- 2 表示有竞争
owner: 当前线程id
kind: 普通、自适应、递归等等
lock:

unlock:

3.2 Semaphore
| 函数名 | 用途 |
|---|---|
| sem_init(&sem,0,1); | 初始化 |
| sem_wait(&sem); | 挂起当前进程,直到semaphore的值为非0,它会原子性的减少semaphore计数值。加锁操作 |
| sem_post(&sem); | 走出临界区,释放semaphore的时候,将其值由0改 1,解锁操作 |
int sem_wait (sem_t *sem)
{int *futex = (int *) sem;if (atomic_decrement_if_positive (futex) > 0) //如果大于0,那么说明已经拿到锁了return 0;int err = lll_futex_wait (futex, 0);return -1;
}
int sem_post (sem_t *sem)
{int *futex = (int *) sem;int nr = atomic_increment_val (futex);int err = lll_futex_wake (futex, nr);return 0;
}
- 当线程退出临界区后,执行sem_post(),释放semaphore的时候,将其值由0改 1,并不知道是否有线程阻塞在这个semaphore上,所以只好不管怎么样都执行futex(uaddr, FUTEX_WAKE, 1)尝试着唤醒一个进程。而相反的,当sem_wait(),如果semaphore由1变0,则意味着没有竞争发生,所以不必去执行futex系统调 用。
读写、条件变量
读写锁
读写锁允许多个读线程共享访问资源,但写线程独占访问资源。其核心目标是最大化并发性,同时保证写操作的互斥性。
1. 状态表示与原子操作
- 读者计数(Reader Count) :当前持有读锁的线程数。
- 写者状态(Writer Flag) :是否已有写者持有锁。
- 等待写者队列:记录等待获取写锁的线程。
2. 读锁的获取与释放
- 获取读锁
- 原子检查,state是否允许读,有无写者
- 如果允许,通过CAS递增读者计数
- 如果失败,内核等待或自旋
- 释放读锁
- CAS原子递减
- 如果读者计数为0,唤醒等待的写者(若有)
3. 写锁的获取与释放
- 获取写锁
- 原子设置写者标志
- 确保读者计数为0
- 如果失败,进入等待或自旋
- 释放写锁
- 清除写者标志
- 环形所有等待的读者和写者
4. 阻塞与唤醒机制
- 等待队列:通过 Futex(Linux)或类似机制管理等待线程。
- 公平性策略:
- 读优先:允许新读者不断加入,可能导致写者饥饿。
- 写优先:阻塞新读者,优先唤醒写者。
- 唤醒逻辑:释放锁时,根据状态决定唤醒读者还是写者。
条件变量
条件变量通常与互斥锁配合使用,用于线程间的等待/通知机制。其核心目标是安全地释放锁并阻塞线程,直到其他线程发出信号。
1. 核心操作
wait():- 原子释放互斥锁。
- 将线程加入条件变量的等待队列。
- 进入内核阻塞状态。
notify_one()/notify_all():- 唤醒一个或所有等待线程。
- 被唤醒线程重新尝试获取锁。
wait()的实现
void cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex) {// 1. 原子释放互斥锁(需与加入等待队列原子化)pthread_mutex_unlock(mutex);// 2. 将线程加入条件变量的等待队列(如 futex_wait)futex_wait(&cond->futex, current_value);// 3. 重新获取互斥锁pthread_mutex_lock(mutex);
}
notify()的实现:
void cond_signal(pthread_cond_t *cond) {// 1. 唤醒一个等待线程(如 futex_wake)futex_wake(&cond->futex, 1);
}

- 生产者-消费者模型,线程池任务调度
死锁
死锁: 是指多个进程在执行过程中,因争夺资源而造成了互相等待。此时系统产生了死锁。比如两只羊过独木桥,若两只羊互不相让,争着过桥,就产生死锁。
- 互斥,持有并等待,不可剥夺,循环等待
预防死锁:
- 互斥: 尽可能地共享资源,使用原子操作替代锁,实现 无锁(Lock-Free)数据结构,消除锁的互斥性,简单状态管理
- 持有并等待:请求资源时先释放已占有的资源,再请求所需的资源,以避免持有资源的阻塞情况。
- 不可剥夺:引入资源抢占机制,使得系统可以对进程已获取的资源进行剥夺
- 循环等待:剥夺锁的顺序一致
避免死锁:
系统在进行资源分配之前,预先计算资源分配的安全性。若此次分配不会导致系统进入不安全状态,则将资源分配给进程;否则,
进程等待。其中最具有代表性的避免死锁算法是银行家算法
它通过模拟银行家在贷款时确保银行不会因为贷款而破产的方式来确保系统不会因为资源分配而进入死锁状态
银行家算法是一种死锁避免算法,通过预判资源分配的安全性,确保系统始终处于安全状态,从而避免死锁
- 1. 初始化: 记录系统总资源、已分配资源、剩余可用资源,以及每个进程的最大需求和已占用资源。
- 2. 安全性检查:
- 假设所有进程立即请求其最大需求,检查是否存在一个安全序列。
- 若存在,系统安全;否则拒绝请求。
- 3. 资源请求处理:
- 若进程请求资源 ≤ 剩余可用资源,且 ≤ 其最大需求,则模拟分配并执行安全性检查。
- 安全则分配;不安全则阻塞请求(避免死锁)。
核心思想:预判分配后是否仍能保证所有进程安全完成,避免循环等待。
排查死锁: 我们可以使用 pstack + gdb ⼯具来定位死锁问题。
多次执行pstack 命令查看线程的函数调⽤过程,多次对比结果,确认哪几个线程一直没有变化,且是因为在等待锁,那么大概率是由于死锁问题导致的。
解锁死锁:
- 终止一个或多个进程: 通过终止一个或多个参与死锁的进程来打破死锁。简单直接,资源释放。资源浪费,影响性能与稳定性
- 强制回收资源: 从一个或多个参与死锁的进程中回收资源,分配给其他进程。回收资源可以提高资源利用率,减少资源浪费,不需要终止进程。仔细选择,防止导致其他问题,,或者回收后仍然无法打破死锁。
- 撤销请求: 撤销一个或多个参与死锁的进程的资源请求,使其等待资源。通过撤销请求可以灵活地调整资源分配。仔细撤销,撤销请求可能无法打破死锁。
- 资源分配图简化: 构建资源分配图,通过图的简化操作(如删除边)来打破死锁。提供了直观的可视化工具,构建和简化资源分配图需要一定的复杂操作。
单核机器上写多线程程序,是否需要考虑加锁?
在单核机器上写多线程程序,仍然需要线程锁。因为线程锁通常用来实现线程的同步和互斥。在单核机器上的多线程程序,仍然存在线程同步的问题。因为在抢占式操作系统中,通常为每个线程分配一个时间片,当某个线程时间片耗尽时,操作系统会将其挂起,然后运行另一个线程。如果这两个线程共享某些数据,不使用线程锁的前提下,可能会导致共享数据修改引起冲突
用户线程和内核线程
| 用户级线程 | 内核态线程 | |
|---|---|---|
| 定义 | 线程由用户态的线程库实现,内核不可见 | 由操作系统内核直接支持和调度,内核对线程可见 |
| 优点 | 1. 调度在用户态完成,开销小,切换速度快。 2. 可以在不支持线程的操作系统上实现。 3. 创建、撤销线程无需内核参与,效率高。 | 1. 适合多核 CPU,一个进程的多个线程可并发执行。 2. 内核负责调度,线程阻塞不会导致整个进程阻塞。 3. 切换速度较快,数据结构小,能支持真正的并行。 |
| 缺点 | 1. 一个线程阻塞,整个进程都会阻塞 2. 无法利用多核 CPU 并行,同一时刻一个进程只能有一个线程运行 | 1. 切换需要从用户态到内核态再回到用户态,模式切换成本高。 2. 线程的调度和管理由内核负责,会占用更多的系统资源。 |
关联性与区别
-
内核感知:内核级线程由 OS 内核调度,用户级线程对内核不可见。
-
调度单位:
- 用户级线程:OS 仍以“进程”为调度单位,线程调度由用户线程库实现。
- 内核级线程:OS 以“线程”为调度单位,调度由内核完成。
-
阻塞行为
- 用户级线程:一个线程阻塞会导致整个进程阻塞。
- 内核级线程:线程阻塞只影响该线程,不影响同进程其他线程。
-
性能差异:
- 用户级线程切换快、开销小,但受限于单核执行。
- 内核级线程可真正并行,但模式切换带来较大开销。
-
程序实体:
- 用户级线程:运行在用户态下的程序实体。
- 内核级线程:既可运行在用户态,也可运行在内核态。
混合模型(M:N):结合两者优势,用 N 个用户级线程映射到 M 个内核级线程,实现高效调度和多核并行。
线程切换: 线程使用的是一套栈还是一对栈
-
用户级线程(ULT)切换: 完全在用户态,没有线程只有一个用户栈,TCB(线程控制块)保存寄存器和栈信息,一个用户到另一个用户,由线程库完成,不陷入内核,开销小,内核不感知
-
内核级线程切换: 运行在内核态+用户态的,用户栈运行应用层代码时使用;内核栈陷入内核(系统调用、中断)时使用,TCB 由 内核维护,调度器负责保存和恢复线程的执行环境,开销就相对较大。
操作系统
用户态和内核态
如果没有用户态和内核态的区分,应用程序可以 直接访问硬件资源和整个内存空间。一旦程序写错地址(例如覆盖系统关键内存),可能会导致 系统崩溃。内核态(Kernel Mode)拥有最高权限,可以访问受保护的内存和硬件设备;用户态(User Mode)只能访问受限的空间,通过系统调用进入内核完成操作。这种设计保证了 系统稳定性和安全性,防止用户程序直接破坏内核。
-
32 位 CPU 地址线为 32 → 最大寻址空间为 4GB (2^32)。
-
Linux 通常将虚拟地址空间划分为:
- 每个进程私有,用户程序只能访问这一部分。
-
所有进程共享,存放内核代码、数据结构、内核栈、内核缓冲区。
-
高 1GB (3G–4G) → 内核空间(Kernel Space)
低 3GB (0–3G) → 用户空间(User Space)
-
用户态:只能访问用户空间,权限受限,需要通过系统调用访问内核。
-
内核态:可访问所有资源,包括内核空间和硬件。
-
内存划分:
- 用户空间(3GB,进程私有)
- 内核空间(1GB,所有进程共享)
-
好处:保护内核安全、保证系统稳定、增强进程隔离性
上下文
上下文简单说来就是一个环境。
用户空间的应用程序,通过系统调用,进入内核空间。所谓的“进程上下文”,可以看作是用户进程传递给内核的这些参数以及内核要保存的那一整套的变量和寄存器值和当时的环境等。
一个进程的上下文可以分为三个部分: 用户级上下文、寄存器上下文以及系统级上下文。
- 用户级上下文: 正文、数据、用户堆栈以及共享存储区;
- 寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP),PC指针
- 系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈
当发生进程调度时,进行进程切换就是上下文切换(context switch).操作系统必须对上面提到的全部信息进行切换,新调度的进程才能运行。而系统调用进行的模式切换(mode switch)。模式切换与进程切换比较起来,容易很多,而且节省时间,因为模式切换最主要的任务只是切换进程寄存器上下文的切换。
硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。所谓的“ 中断上下文”,其实也可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境(主要是当前被打断执行的进程环境)
为什么会有这种概念?
内核空间和用户空间是现代操作系统的两种工作模式,不同的级别和不同的访问权限。
其中,处理器总处于以下状态中的一种:
-
内核态,运行于进程上下文,内核代表进程运行于内核空间;
-
内核态,运行于中断上下文,内核代表硬件运行于内核空间;
-
用户态,运行于用户空间。
操作物理设备 -> 设备地址映射到user -> 系统调用(提供给用户的接口)
什么情况下进行用户态到内核态的切换?
- 进程上下文主要是异常处理程序和内核线程。系统调用,tarp机制
- 中断上下文是由于硬件中断时会触发中断信号请求,请求系统处理中断,执行中断服务子程序
用户栈和内核栈
内核栈: 内存中属于操作系统空间的一块区域。1. 保存中断现场,对于嵌套中断 2. 保存操作系统程序相互调用的参数
用户栈: 用户进程空间的一块区域,用于保存用户空间子程序间调用的参数,返回值以及局部变量
上下文切换过程
- 保存处理机上下文: 保存当前进程的 程序计数器 PC、寄存器内容等。
- 更新 PCB(进程控制块): 将保存的上下文信息写入当前进程的 PCB。
- 调整进程队列: 把当前进程的 PCB 移入合适的队列(就绪队列、阻塞队列等)。
- 选择新进程: 调度程序从就绪队列中选出下一个进程,并更新其 PCB。
- 更新内存管理数据结构: 切换到新进程的页表,保证它访问的虚拟地址正确映射到物理内存。
- 恢复处理机上下文: 从新进程的 PCB 中恢复寄存器、程序计数器等内容,加载到 CPU。
- 重新执行: CPU 跳转到新进程的程序计数器位置,继续运行。
动态库与静态库的区别
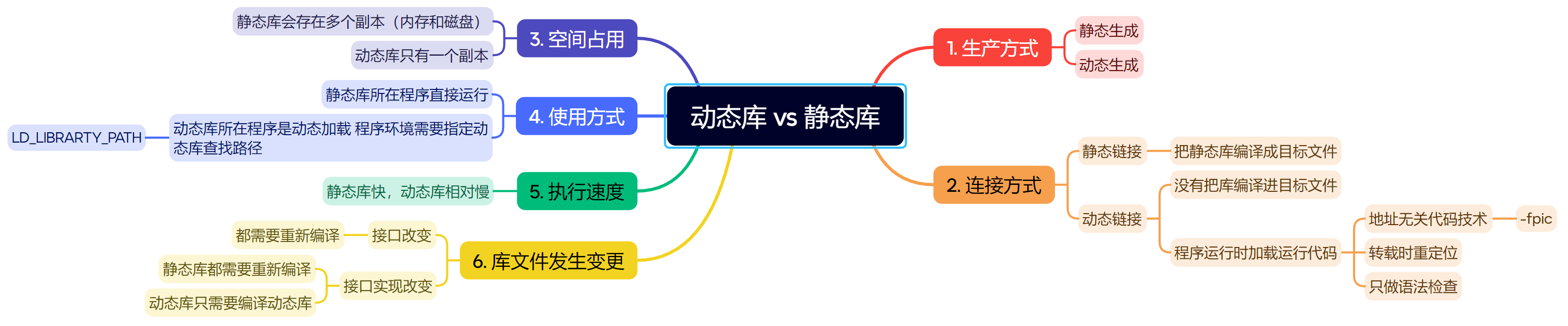
- 加载时机: 动态库在程序运行的时候加载动态库,静态库是在编译时候进行链接,把库文件复制到可执行文件中
- 大小: 加载动态库的可执行文件比较小,并且可供多个可执行文件加载动态库,静态库的可执行文件不依赖外部文件
- 维护: 动态库维护比较方便,静态库的维护需要更新函数的编译和发布可执行文件
使用场景和优缺点:
- 动态链接适合节省资源、可升级和灵活性要求高的场景。但在运行时有一定开销。
- 静态链接适合独立部署和简化依赖关系的场景。但可执行文件较大且维护复杂。
软链接与硬链接
- 硬链接是多个目录项中的「索引节点」指向一个文件,也就是指向同一个inode,但是 inode 是不可能跨越文件系统的,每个文件系统都有各自的 inode 数据结构和列表,所以硬链接是不可用于跨文件系统的,由于多个目录项都是指向一个 inode,那么只有删除文件的所有硬链接以及源文件时,系统才会彻底删除该文件。
- 软链接相当于重新创建一个文件,这个文件有独立的inode,至目标文件被删除了,但是这个文件的内容是另外一个文件的路径,所以访问软链接的时候,实际上相当于访问到了另外一个文件,所以软链接是可以跨文件系统的,链接文件还是在的,只不过指向的文件找不到了而已。
| 特性 | 静态库(.a / .lib) | 动态库(.so / .dll) |
|---|---|---|
| 链接时机 | 编译期 | 程序运行期 |
| 文件大小 | 较大(包含库代码) | 较小(只保存符号引用) |
| 内存占用 | 多份拷贝 | 多进程共享一份 |
| 更新维护 | 需重新编译应用程序 | 替换库文件即可 |
| 运行速度 | 快(直接执行) | 略慢(运行时加载) |
| 发布方式 | 只需发布一个可执行文件 | 需随程序发布库文件 |
DMA技术
直接内存访问 简单理解就是,在进行 I/0 设备和内存的数据传输的时候,数据搬运的工作全部交给DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。

零拷贝技术
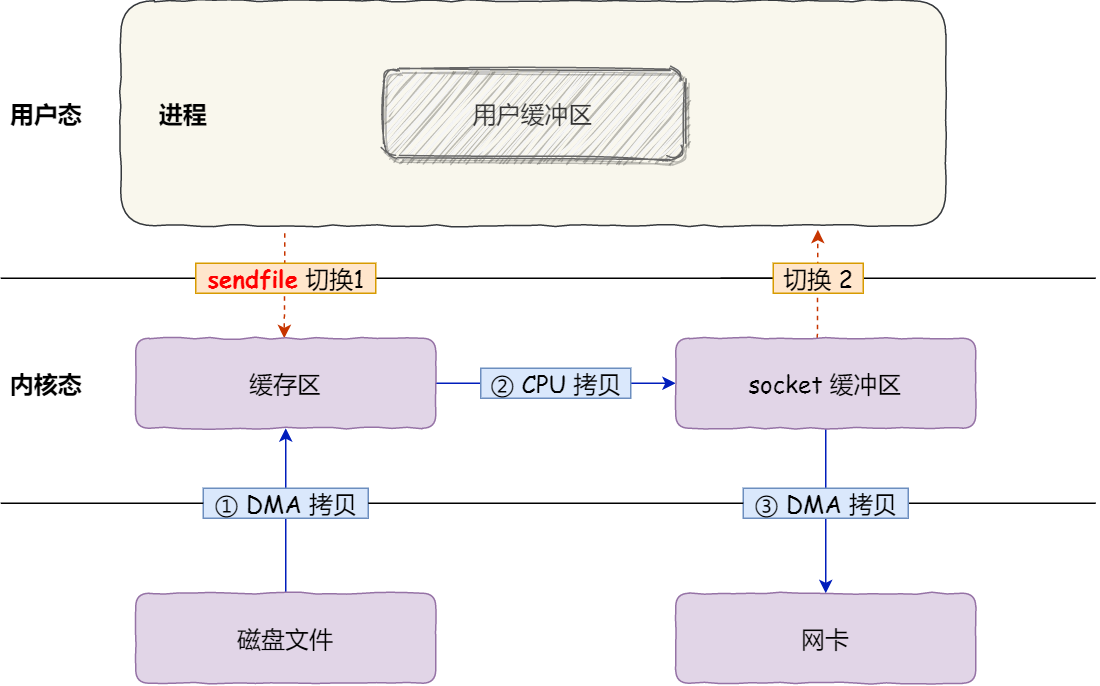
全程没有通过CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了2次上下文切换和数据拷贝次数,只需要2次上下文切换和数据拷贝次数,就可以完成文件的传输,而且2次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
计算机网络
TCP与UDP的区别
| 维度 | TCP | UDP |
|---|---|---|
| 是否连接 | 面向连接:三次握手建立、四次挥手释放 | 无连接:直接发报文 |
| 可靠性 | 序列号 + ACK + 重传 → 可靠、有序、不丢不重 | 可能丢、乱序、重复,不保证送达 |
| 传输粒度 | 字节流(Stream) | 报文(Datagram),一次send()= 一次完整包 |
| 流量 / 拥塞控制 | 滑动窗口 + 拥塞算法(慢启动、拥塞避免、BBR…) | 无流控、无拥塞控制,发得快丢得多 |
| 传输速度 | 稳定但握手 + 拥塞控制 → 首包慢、稳中求胜 | 低延迟、抖动小,但需应用自行容错 |
| 消息边界 | 无,需要应用层自行划分 | 保留边界,一包一消息 |
| 适用场景 | HTTP/HTTPS、FTP、数据库、电子邮件… | DNS、VoIP、直播、在线游戏、DHCP… |
| 首部开销 | 20字节起,带选项可到 40-60 Byte | 固定8字节,源端口、目的端口、长度、校验和 |
| 定性成本 | 端口占用多、FD 常驻、握手耗 RTT | 资源占用低、无状态,服务端易做并发 |
| 组播 / 广播 | 不支持 | 原生支持单播 / 组播 / 广播 |
TCP的优点: 可靠、连接前要三次握手、数据传递时可靠机制,数据传递后断开连接节约系统资源
UDP的优点: 快,但不可靠、网络质量不好容易丢包
TCP的优点:
- 可靠性: TCP 提供可靠的数据传输,通过序列号、确认机制、重传机制等保证数据的可靠性,丢包,自动重传机制
- 顺序性: TCP 保证数据的顺序传输,接收方会按照发送方的顺序重新组装数据包
- 流量控制: TCP 使用滑动窗口机制进行流量控制,根据接收方的接收能力来控制发送方的发送速度,避免了数据的丢失和拥塞。
- 拥塞控制: TCP 使用拥塞窗口机制进行拥塞控制,通过动态调整发送速率来减少网络拥塞,并避免网络崩溃。
UDP的优点:
- 低延迟: UDP 不进行连接的建立和维护,没有额外的开销,因此在速度和效率方面比 TCP 更高,并且能够实现低延迟传输。
- 简单轻量: UDP 的头部较小,并且没有复杂的机制
TCP使用场景: 效率要求相对低、对准确性要求高的场景。文件传输,Web 浏览,电子邮件,文件下载和上传,远程访问
UDP使用场景: 效率要求相对高,对准确性要求相对低的场景。实时游戏,视频和音频流媒体
IP帧结构:

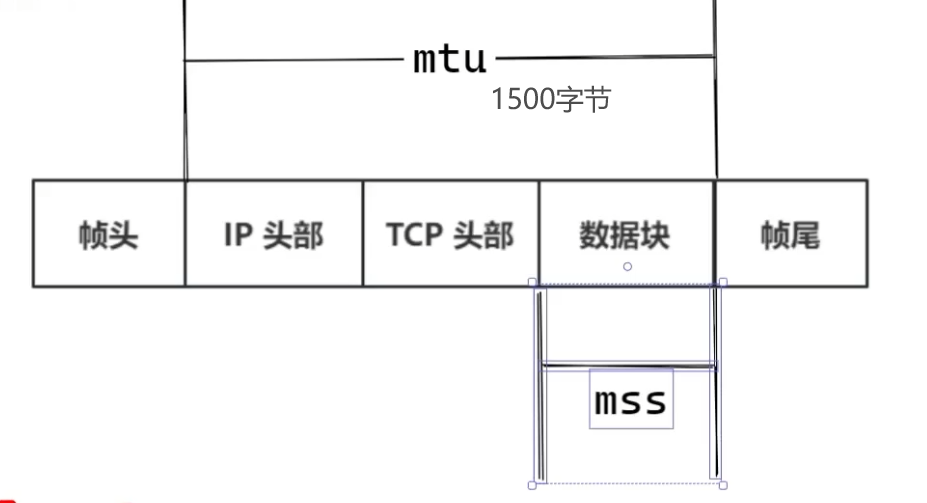
TCP报文:
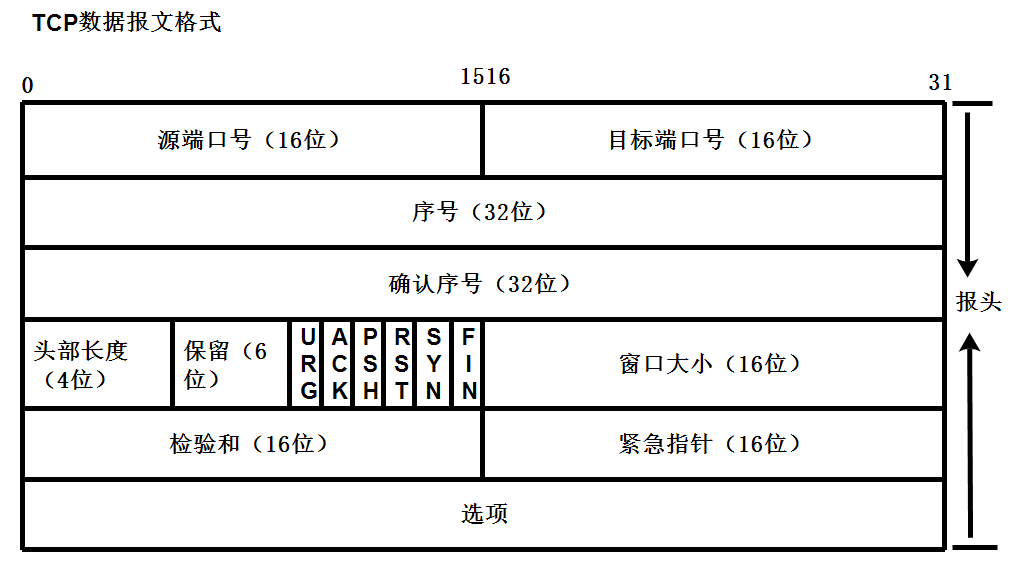
接收数据包流程

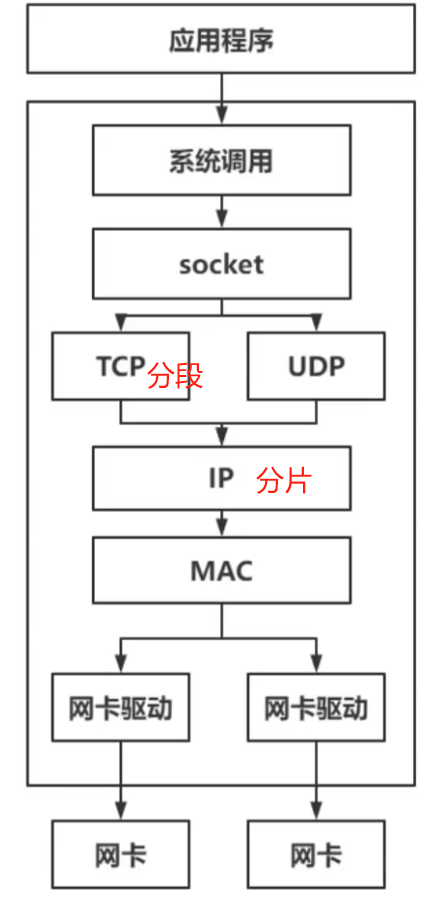
宕机是否丢失

三次握手 四次挥手相关
TCP三次握手是为了确保双方都做好了发送和接收数据的准备工作,建立了全双工的连接
- 第一次握手(SYN):客户端向服务器发送一个包含SYN(同步序列号) 标志的报文段。这表示客户端请求建立连接。
- 第二次握手(SYN+ACK):服务器收到客户端的请求后,会返回一个包含SYN和ACK(确认应答)标志的报文段。ACK应答号为客户端请求的序列号加1,表示服务器已经接受了客户端的请求,并希望建立连接。
- 第三次握手(ACK):客户端收到服务器的应答后,会发送一个确认报文段给服务器,确保服务器收到了自己的确认应答。
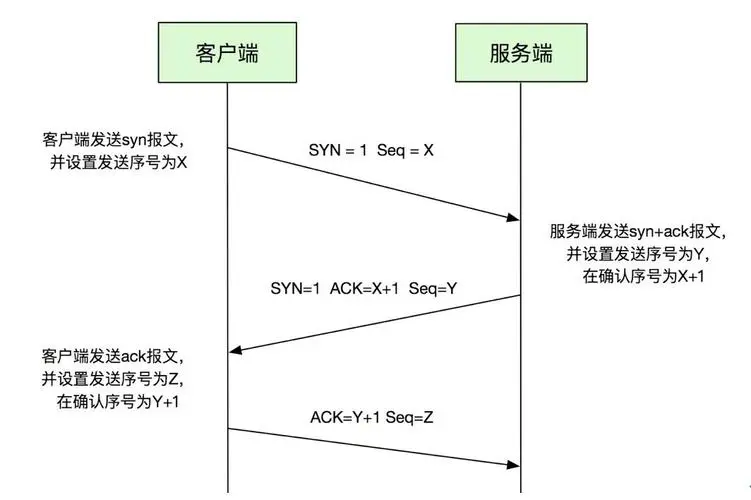
四次挥手是用于关闭连接的过程,通过交换FIN(结束)和ACK报文段完成
- 第一次挥手(FIN):当客户端决定关闭连接时,发送一个FIN(结束)标志的报文段给对方。这表示该方不会再发送数据,但仍然可以接收数据
- 第二次挥手(ACK): 服务器收到FIN后,发送一个确认报文段给对方,确认收到了关闭请求
- 第三次挥手(FIN):服务器也准备关闭连接,发送一个FIN标志的报文段给客户端,表示服务器也不会再发送数据
- 第四次挥手(ACK):接收到第三次挥手的客户端,发送一个确认报文段给服务器,确认收到了关闭请求。

可以二次握手吗
- 采用三次握手是为了确认客户端也具有收的能力。
- 防止失效的连接请求报文段突然又传送到服务器,从而发生错误。考虑这样一种特殊情况,客户端第一次发送的连接请求并没有丢失,而是因为网络问题导致延迟到达服务器,服务器以为是客户端又发起的新连接,于是服务器同意连接,并向客服端发回确认,但是此时客户端不予理会,服务器就一直等待客户端发送数据,导致服务器的资源浪费。那么第一次发送的连接请求报文段就称为失效的连接请求报文段,避免半连接状态的歧义
- 协议设计的严谨性:虽然在某些理想情况下可能可行,但会降低协议的通用性和鲁棒性
为什么挥手要四次,三次可以吗
-
四次挥手的目的: 将发送FIN的控制权限交给网络应用程序去处理
-
当收到对方的FIN 报文通知时,它仅仅表示对方没有数据发送给你了,但未必你所有的数据都全部发送给对方了,所以你未必会马上关闭socket,也即你可能还需要发送一些数据给对方之后,再发送 FIN报文给对方来表示你没有数据发送给对方了,针对每个FIN报文,都需要ack 报文,故需要四次挥手
-
合并 ACK 和 FIN 可能导致不可靠关闭,四次挥手确保了双方都能安全关闭,而三次挥手可能导致数据丢失
-
时间不确定性,状态的分离,协议的鲁棒性
为什么三次握手可以一起发 这是因为 TCP 不允许连接处于半打开状态时就单向传输数据,所以在三次握手建立连接时,服务器会把 ACK 和SYN 放在一起发给客户端(但是当连接处于半关闭状态时,TCP 是允许单向传输数据的
判断断开
- 发送shutdown: 只关闭写端,不关闭读端
- close:关闭读写,FIN -> ACL -> reset
- 程序异常退出:关闭读写,FIN -> ACL -> reset
read =0: 读端关闭
write == -1 && error = EPIPE: 写端关闭
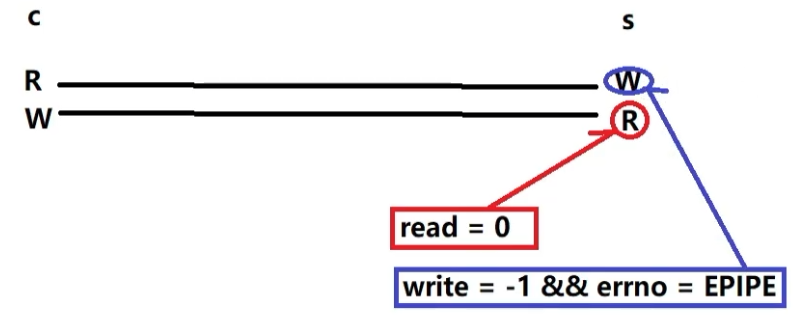
IO多路复用模型:
- EPOLLRDHUP :read = 0 关闭读端
- EPOLLHUP:读写端都关闭
TCP可靠机制
(1) 序列号和确认机制
TCP报文使用序列号和确认号字段来实现数据的可靠传输。发送方的TCP将每个字节的数据进行编号,并按序发送。接收方根据接收到的字节进行确认,并回复确认号,表示期望接收的下一个字节的序列号。如果发送方未收到确认,或者收到的数据有丢失、重复或损坏,发送方将重传数据。
(2) 超时重传机制
TCP使用超时重传机制来处理丢失的数据或确认。发送方设置一个定时器,在发送数据后等待一段时间,如果在该时间内未收到确认,发送方会假设数据丢失,并重传数据。接收方通过确认号来判断是否有丢失的数据,如果接收到重复的数据,将丢弃并发送确认。
- 快速重传,超时之前收到三个相同的数据包确认,直接重传丢失的数据。
- SACK机制头部的选项中表明只重传丢失的数据,解决了重传哪些问题
- DSACK,把重复收到的包通过sack告知对方,用时解决了(发送方)的数据包丢失、ack丢失以及网络超时

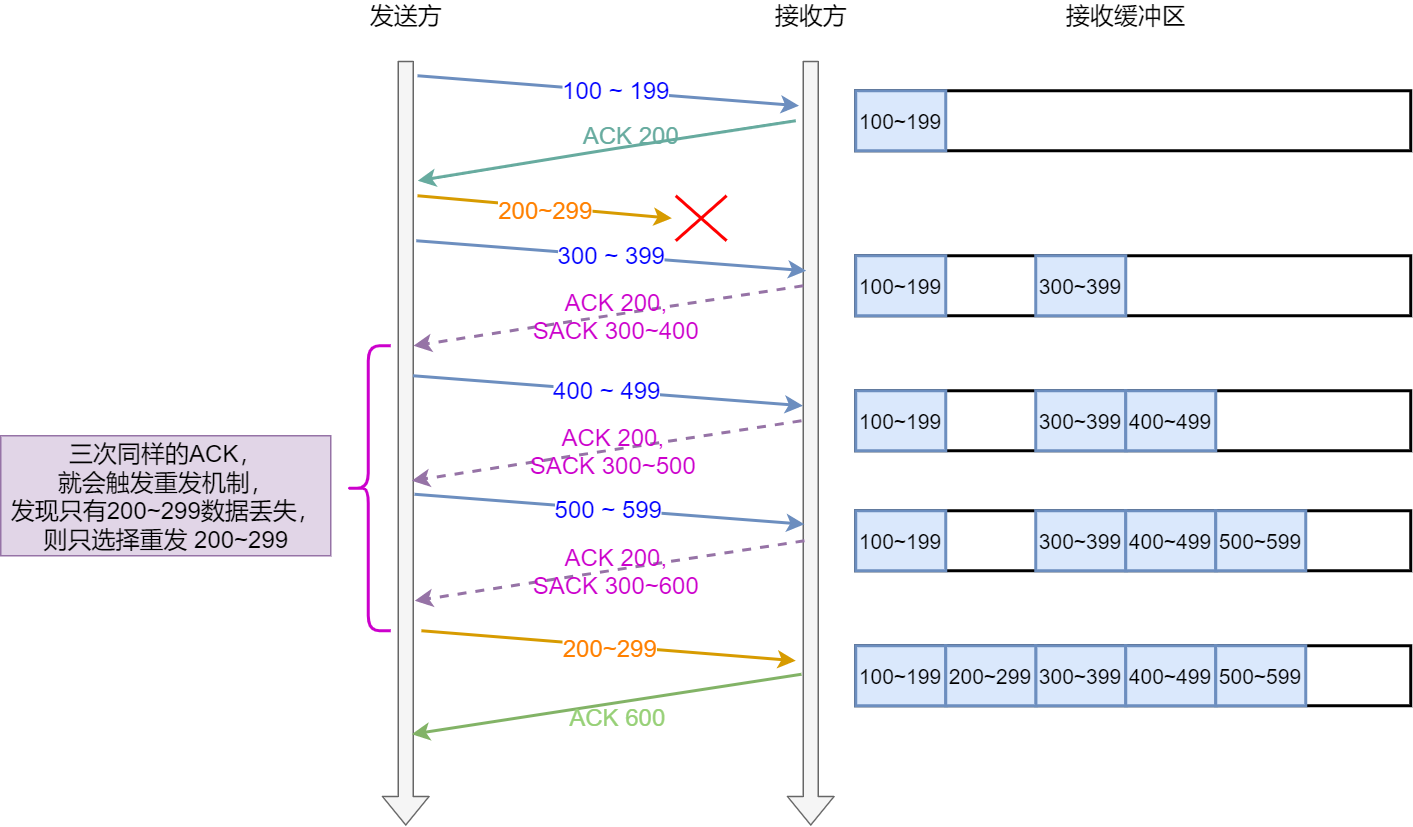
(3) 滑动窗口
TCP使用滑动窗口机制来进行流量控制。解决无需为每个数据包应答,没有应答可以发送多个数据,收到确认包进行移动。每个TCP报文中包含一个窗口大小字段,发送方根据接收方的窗口大小来控制发送的数据量。接收方根据自身处理能力和可用缓冲区大小来设置窗口大小,发送方根据接收方窗口大小来调整发送速率,以避免数据的拥塞和丢失。
(4)流量控制:解决通过接受方的处理能力来限制发送的数据量,避免丢包。先收缩窗口,再缩小缓冲区
(5) 拥塞控制机制
TCP使用拥塞控制机制来适应网络拥塞情况。通过动态调整发送速率和窗口大小,TCP可以避免网络拥塞并提供公平共享带宽。TCP使用拥塞窗口和慢启动、拥塞避免、快速重传、快速恢复等算法来控制拥塞,并根据网络状况进行自适应调整。发送窗口 = min(拥塞窗口, 接收缓冲区)
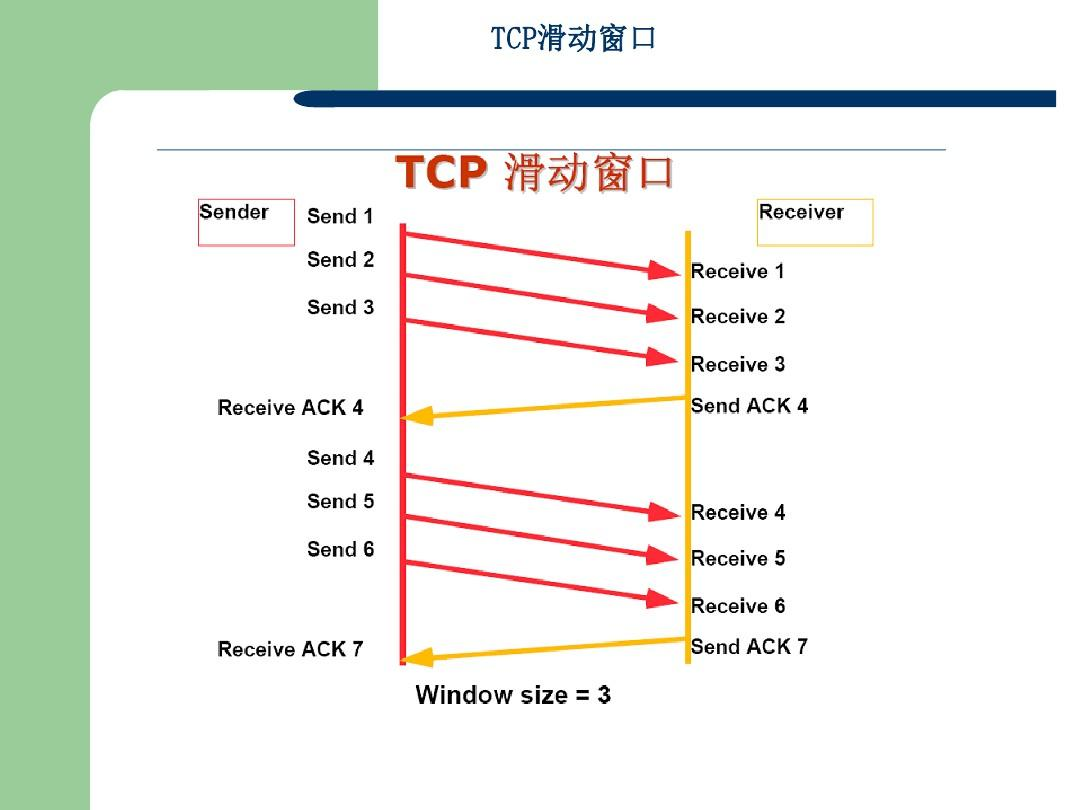
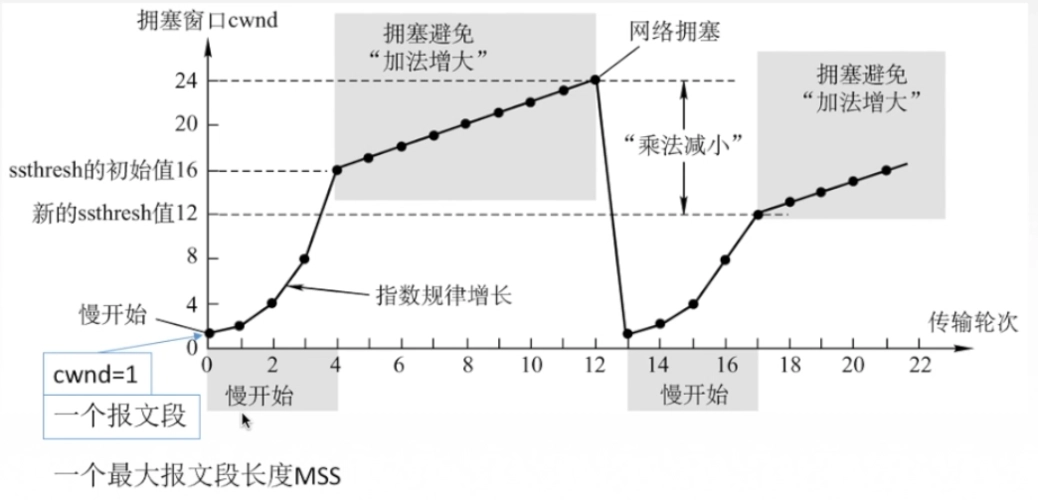
(5) 数据校验和错误检测
TCP使用校验和字段来检测数据在传输过程中的错误。接收方在接收到TCP报文后计算校验和,如果校验和不匹配,则认为数据出现错误,并请求发送方重新发送数据
TCP粘包/半包现象
TCP是能保证顺序且不丢失的。
tcp粘包是指:发送方发送的若干包数据到接收方接受时粘成一包,从接收缓冲去看,后一包数据的头紧接着前一包数据的尾。
原因:
发送方原因:发送方每次写入数据<内核缓冲区大小,导致多次写入数据都放入缓冲区,发送的时候把多个小的数据包都发送出去,接收方收到粘包
接收方原因:当tcp接收方读取内核缓冲区不够及时,多个包就会被存至缓存,应用程序读时,就会读到多个首尾相接粘到一起的包。网卡不是实时读取数据的,读多个消息。
处理:
- 发送方:通过TCP_NODELAY选项关闭Nagle算法
- 接收方:在应用层进行粘包处理
根本的原因:TCP 是面向字节的,消息无边界
根本手段: 找出消息的边界
-
固定长度:简单,但是浪费空间,不推荐
-
分隔符:比如使用回车符(\n) 作为分隔符(HTTP报文-回车换行),简单,空间也不浪费,推荐使用,缺点:本身就有分隔符就要进行转义
-
固定长度字段存储内容的长度信息:消息格式 = 数据长度 + 数据内容
- 精确定位数据内容,内容不需要转义,推荐
- 缺点:数据内容长度有限制,需要提前知道可能的最长的消息的字节数
半包解释及原因: 一个消息分多次接收,应用进程无法从一个半包中解析出数据
出现半包的原因:
- 发送方写入数据>内核缓冲区大小
- 发送方数据大于 MTU(数据链路层规定的帧大小),必须拆包
TCP的ACK机制,有什么好处?
TCP的ACK(确认)机制是指在TCP连接中,接收方通过发送ACK报文来确认已成功接收到发送方的数据。ACK机制的主要作用是保证数据的可靠传输和实现流量控制。
好处如下:
- 可靠性确认:接收方通过发送ACK报文来确认已成功接收到发送方的数据。发送方收到ACK报文后,可以确认数据已经正确传输到接收方,如果没有收到ACK报文,发送方会认为数据丢失,会进行重传,保证数据可靠性。
- 流量控制:ACK机制可以帮助控制数据发送的速率。在接收方的ACK报文中,会包含一个窗口字段(接收窗口),表示接收方所能接收的数据量。发送方根据接收窗口的大小来调整发送数据的速率,以避免发送方持续发送过多的数据,导致接收方无法及时处理和接收,从而实现流量控制,避免网络拥塞和数据丢失。
- 乱序处理:ACK机制可以用于处理乱序到达的数据包。接收方在收到乱序的数据包后,可以通过发送ACK报文来通知发送方已经接收到哪些数据包,以便发送方进行数据包的重排和重传,确保数据的顺序性。
- 建立和维护连接:通过ACK机制,发送方和接收方可以相互确认对方的存在和可达性,进而建立和维护TCP连接。
- 拥塞控制:ACK机制可以用于拥塞控制。当网络发生拥塞时,接收方的ACK报文会延迟发送或丢失,从而减少发送方的数据传输速率,避免进一步加剧网络拥塞。
TIME_WAIT
TIME_WAIT是TCP连接断开时的一个必经状态,当TCP连接的一方(通常是主动关闭方)发送完最后一个ACK后,会进入TIME_WAIT状态,持续2MSL(Maximum Segment Lifetime,最大报文段生存时间)
1. 可靠地终止连接(确保最后一个ACK到达)
- 如果最后一个ACK丢失,被动关闭方会重传FIN(ACK不会重传)
- TIME_WAIT确保有足够时间处理这些重传
2. 防止旧连接数据混淆(消除"迷途报文")
- 网络中可能存在延迟的旧连接报文
- 2MSL时间确保所有旧连接的报文都会从网络中消失
- 避免新建立的相同四元组(源IP、源端口、目标IP、目标端口)连接收到旧数据
长短连接、全连接、半连接
长连接与短连接
**长连接:**客户端与服务器建立TCP连接后,多次通信复用同一个连接,完成后不会立即关闭,而是保持连接一段时间以便后续复用。
短连接: 每次通信都新建一个TCP连接,传输完成后立即关闭(四次挥手),下次通信需重新建立连接。
**长连接特点: ** 减少握手开销,连接会占用服务器资源(如内存、文件描述符),需合理管理闲置连接(如超时关闭)。适用场景:高频、小数据量的交互场景
短连接特点: 高开销、频繁握手;无状态性,服务器不需要维护连接状态、资源释放快,避免长时间占用资源。应用场景为低频、一次性请求。
维持机制: 长连接需要通过心跳检测(Heartbeat) 维持活性:
- 通信双方定期发送小数据包(如 “Ping”),若接收方未回应 “ping”,则判定连接失效并主动断开
| 维度 | 短连接(Short Connection) | 长连接(Long Connection) |
|---|---|---|
| 连接生命周期 | 单次数据传输后立即断开 | 多次数据传输后仍保持,按需 / 超时断开 |
| 连接开销 | 频繁建立 / 断开,开销高 | 一次建立多次复用,开销低 |
| 资源占用 | 临时占用资源,利用率高 | 长期占用资源,需控制连接数量 |
| 实时性 | 较低(每次交互需重新建连) | 较高(连接就绪,数据可即时传输) |
| 典型协议 / 场景 | HTTP 1.0、普通网页访问、单次 API 调用 | HTTP 1.1(默认长连接)、WebSocket、即时通讯、在线游戏 |
-
全连接: 指的是通信双方(如客户端和服务器)通过协议(通常是 TCP)完成了完整的连接建立过程,双方都确认彼此的连接状态有效,且能双向正常收发数据的状态
-
半连接: 在连接建立过程未完全完成,或连接一方已异常断开但另一方仍未感知的状态,本质上是 “单向有效” 或 “未确认” 的连接状态。
- 在 TCP 连接建立时,服务器收到客户端的
SYN报文后,会回应SYN+ACK报文,但在等待客户端发送最后一个ACK报文的过程中,连接处于 “半连接” 状态。服务器会将这类未完成的连接暂存在 半连接队列(SYN Queue) 中。 - 当连接一方(如客户端)因崩溃、网络中断等原因异常断开,但另一方(如服务器)未收到断开通知(如
FIN报文),此时服务器仍认为连接有效,处于 “半开(Half-Open)” 状态。 - 例如:客户端进程崩溃后未发送
FIN报文,服务器仍维持ESTABLISHED状态,直到发送数据超时或通过心跳检测发现异常。 - 资源浪费:服务器的半连接队列容量有限,若大量恶意
SYN报文(如 SYN Flood 攻击)导致队列满,会阻塞正常连接建立(即 “SYN 泛洪攻击”)。
- 在 TCP 连接建立时,服务器收到客户端的
socket编程
Socket(套接字)是一种在计算机网络中进行通信的抽象概念。它提供了一种机制,使得不同计算机之间能够建立连接并进行数据交换。
在网络通信中,Socket可以被视为一个端点,它通过网络连接与其他应用程序进行通信。Socket可以分为两种类型:服务器端套接字(Server Socket)和客户端套接字(Client Socket)
Socket是应用程序和网络传输层之间的接口,它提供了一套编程接口,允许应用程序通过传输协议(如TCP或UDP)进行网络通信。通过Socket,应用程序可以创建连接、发送和接收数据

socket (int __domain, int __type, int __protocol)
地址类型(ipV4, IPV6),协议族(SOCK_STREAM),协议,成功返回网络描述符,失败返回-1
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
int listen(int sockfd, int n);
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);// 客户端
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);close(fd);send/recv:仅用于socket,支持 flags(如 MSG_DONTWAIT、MSG_OOB、MSG_NOSIGNAL),更适合需要精细控制 socket 还可外带数据
HTTP与HTTPS
- HTTP: 一种明文传输的超文本传输协议
- HTTPS: 基于 HTTP 的加密版本,通过 SSL/TLS 协议实现数据加密和身份认证
HTTP: 全称超文本传输协议,HTTP 是一种应用层协议,是基于 TCP/IP 通信协议来传递数据的,HTTP3.0 基于 UDP 实现。现主流使用 HTTP1.0 和 HTTP3.0
Socket与HTTP的应用场景
Socket的应用场景: Socket适用于需要实时、双向通信的场景,例如实时聊天、实时游戏、视频流传输等。它可以在网络上直接传输数据,可以自定义通信协议,适用于各种特定需求的应用
HTTP的应用场景: HTTP适用于客户端与服务器之间的通信,特别是在Web应用中。它用于在浏览器和服务器之间传输HTML页面、图像、视频、音频等资源。HTTP还广泛应用于RESTful API,用于实现不同系统之间的数据交换和通信。
一次完整的HTTP请求所经历几个步骤?
- 解析URL:客户端解析目标URL,提取出主机名、端口号、路径等信息。
- 建立TCP连接:客户端使用目标主机的IP地址和端口号,通过三次握手建立与服务器的TCP连接。
- 发起请求:客户端向服务器发送HTTP请求,包括请求方法(GET、POST等)、请求头(包含用户代理、内容类型等信息)和请求体(POST请求时携带的数据)。
- 服务器处理请求并返回响应:服务器接收到请求后,根据请求的路径和方法,执行相应的处理逻辑
- 接收响应:客户端接收到服务器的响应,包括响应状态码、响应头和响应体。
- 处理响应:客户端根据响应的内容进行处理,可能包括解析响应头、读取响应体中的数据等。
- 关闭连接:客户端和服务器根据需要决定是否关闭TCP连接,如果需要继续通信,可以发送更多的HTTP请求。
http的请求体
- 请求方法(HTTP Method):指示服务器应该执行的操作类型。常见的HTTP请求方法包括:GET获取资源,POST提交数据,创建资源,PUT更新资源,DELETE删除资源。
- URL: 指定要请求的资源的地址。URL由协议、主机名、端口号和路径组成,例如:http://example.com/api/users。
- 请求首部字段:包含了请求的附加信息,以键值对的形式出现。常见的请求首部字段包括:Host指定服务器的主机名和端口号,User-Agent标识客户端的用户代理信息,Content-Type指定请求体的数据类型,Content-Length:指定请求体的长度,Cookie包含客户端的Cookie信息,Accept指定客户端能够接受的响应内容类型
- 请求体:可选的,包含了请求的数据内容。它通常在POST、PUT等请求方法中使用,用于向服务器提交数据。
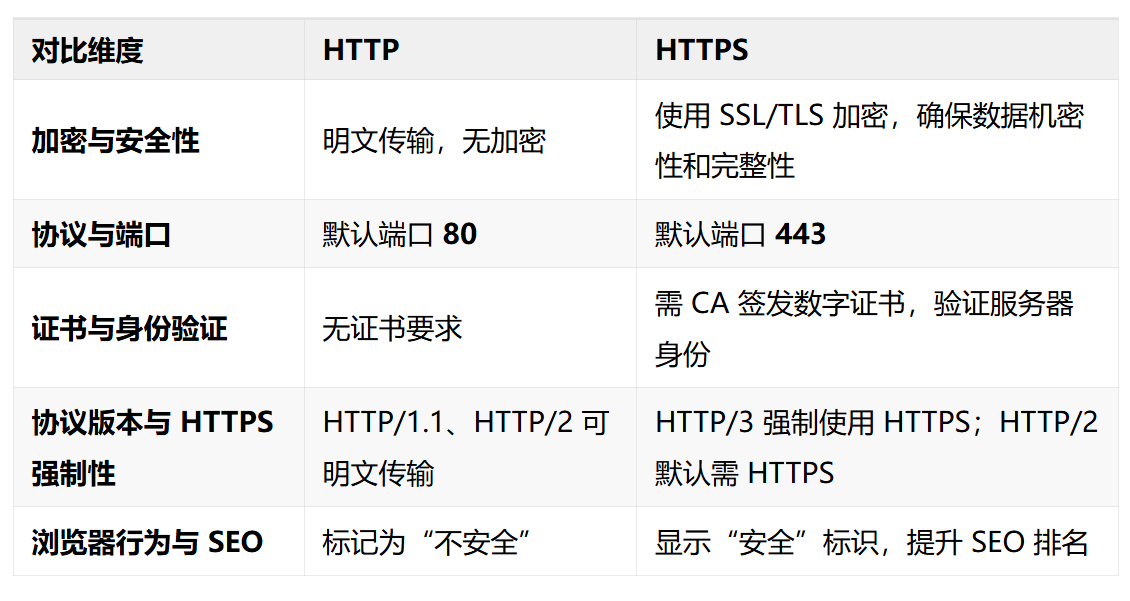
HTTPS加密方式
- 对称加密: 加密和解密使用同一密钥,速度快,适合大量数据加密
- **非对称加密:**用于传输对称加密的密钥(安全性高), 有公钥(公开)和私钥(保密),公钥加密的数据仅私钥可解密,反之亦然;速度慢,适合小数据(如对称密钥)传输。
- 哈希加密: 用于验证数据完整性(防篡改)和生成数字签名,将任意长度数据转换为固定长度哈希值(摘要),不可逆
HTTPS 的工作原理:
HTTPS 通过在 HTTP 协议和 TCP 协议之间加入 SSL/TLS 协议层来实现安全传输。它确保数据在客户端和服务器之间的传输过程中得到加密、身份验证和完整性保护,使得数据在传输过程中无法被窃听或篡改,HTTPS 默认使用443端口。

HTTPS通信过程
- 客户端发起HTTPS请求:客户端(通常是Web浏览器)向服务器发送HTTPS请求。
- 服务器配置和证书验证:服务器需要配置支持HTTPS的相关软件,并且通常会申请和安装数字证书。
- 服务器发送证书:服务器在建立连接时会将数字证书发送给客户端。证书包含了服务器的公钥和其他相关信息。
- 客户端验证证书:客户端收到服务器发送的证书后,会验证证书的有效性。验证包括检查证书的签名是否有效、证书是否过期、证书中的域名是否与访问的域名匹配等。
- 客户端生成对称密钥:如果证书验证通过,客户端会生成一个用于对称加密的随机对称密钥,并使用服务器的公钥进行加密。
- 服务器使用私钥解密:服务器收到客户端发送的加密的对称密钥后,使用自己的私钥进行解密,得到对称密钥。
- 建立加密通信: 客户端和服务器现在都拥有相同的对称密钥,可以使用该密钥对后续的通信进行加密和解密。双方之间的数据传输都会使用对称密钥进行加密。
通过这个过程,HTTPS确保了通信的机密性和完整性。客户端和服务器之间的数据在传输过程中经过加密保护,使得第三方无法窃听或篡改通信内容。同时,通过证书验证,确保了客户端与服务器之间的身份认证和安全性。
HTTP中get和post的方法的区别有哪些
| 特性 | GET 方法 | POST 方法 |
|---|---|---|
| 语义 | 获取资源 | 提交数据/创建资源 |
| 数据位置 | URL 查询字符串 (Query String) | 请求体 (Request Body) |
| 数据可见性 | 明文显示在 URL 中 | 隐藏在请求体中 |
| 数据长度限制 | 受 URL 长度限制 (通常 2048字符) | 理论上无限制 |
| 安全性 | 较低 (不适合敏感数据) | 相对较高 |
| 缓存 | 可被缓存 | 通常不被缓存 |
| 幂等性 | 幂等 (多次请求结果相同) | 非幂等 (可能产生不同结果) |
| 浏览器历史 | 保留在历史记录 | 通常不保留 |
| 书签 | 可收藏为书签 | 不可收藏 |
| 编码类型 | 只支持 URL 编码 | 支持多种编码 (如 multipart/form-data) |
常用的指令
Linux常用指令
文件相关: mkdir cd ls pwd mv cp tar remove | grep
进程线程: ps kill pstack gdb -p
编译相关: vi :wq gcc make ./configure --prefix export
网络相关: ping ifconfig scp nfs
内核相关: insmod,rmmod, lsmod, dmesg
其他: df -h
git、cmake、makefile



gdb
| 场景 | 常用指令 |
|---|---|
| 启动调试 | gdb a.out,run,quit,gdb -p 《pid》(附加到正在运行的进程) |
| 断点管理 | b main,b 10,b test.c:10,d 1《断点编号,从开始》 |
| 执行控制 | c(下个断点),next(不进入函数),step(进入函数) |
| 调用栈 | bt(查看当前调用栈) ,info threads(查看所有线程) thread <线程ID>(切换到指定线程) |
| 变量内存操作 | info locals,info args,p x,p address |
文件/类查找
- 查找
/home下所有.txt文件:find /home -name "*.txt" - 查找当前目录下以
config开头的文件:find . -name "config*" - 在某个目录下每个文件中查找特定的内容:
grep -rnw . -e 'Observer'
内存泄漏: valgrind --tool=memcheck --leak-check=full
文件系统
大文件与软链接
文件系统的组成
文件系统是操作系统中负责管理持久性数据的子系统,说简单点,就是负责把用户的文件存到磁盘硬件中,断电不丢失,可以持久性保存文件
🚩Linux文件系统会为每个文件分配两个数据结构:索引节点(index node)和 目录项(directory entry)
- 索引节点,也就是
inode,⽤来记录文件的元信息,比如inode编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间。 - 目录项,也就是
dentry,用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。
由于索引节点唯一标识一个文件,而目录项记录着文件的名,所以目录项和索引节点的关系是多对一,也就是说,一个文件件可以有多个别字。比如,硬链接的实现就是多个⽬录项中的索引节点指向同一个文件。
注意,目录也是文件,也是用索引节点唯一标识,和普通文件不同的是,普通文件在磁盘里面保存的是文件数据,而目录文件在磁盘里面保存子目录或文件
目录项和目录是一个东西吗?
-
目录是个文件,持久化存储在磁盘,而目录下项是内核一个数据
结构,缓存在内存。 -
如果查询目录频繁从磁盘读,效率会很低,所以内核会把已经读过的目录用目录项这个数据结构缓存在内存,下次再次读到相同的目录时,只需从内存读就可以,大大提高了文件系统的效率。
注意,目录项这个数据结构不只是表示目录,也是可以表示文件
文件数据是如何存储在磁盘的呢?
- 磁盘读写的最小单位是扇区,扇区的大小只有
512B大小,很明显,如果每次读写都以这么小为单位,效率会非常低。 - 所以,文件系统把多个扇区组成了衣蛾个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux 中的逻辑块大小为 4KB ,也就是一次性读写 8 个扇区,这将大大提高了磁盘的读写的效率。
- 文件系统的基本操作单位是数据块

文件系统的结构

- 超级块: 包含的是文件系统的重要信息,比如inode 总个数、块总个数、每个块组的 inode 个数、每
个块组的块个数等等。 - 块组描述符 :包含文件系统中各个块组的状态,比如块组中空闲块和 inode 的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」
- 数据位图和 inode 位图: 用于表示对应的数据块或 inode 是空闲的,还是被使用中。
- inode 列表: 包含了块组中所有的 inode,inode 用于保存文件系统中与各个文件和目录相关的所有元数据。
数据块: 包含文件的有用数据。
超级块和块组描述符表,这两个都是全局信息,而且非常的重要,这么做是有两个原因:
- 如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
- 通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能
虚拟文件系统
-
文件系统的种类众多,而操作系统希望对用户提供的统一的接口,于是在用户层与文件系统层引入了中间层,这个中间层就称为虚拟文件系统(Virtual File System , VFS)。
-
VFS 定义了一组所有文件系统都⽀持的数据结构和标准接⼝,这样程序员不需要了解⽂件系统的工作原理,只需要了解 VFS 提供的统一接口即可。
-
在 Linux 文件系统中,用户空间、系统调用、虚拟机文件系统、缓存、文件系统以及存储之间的关系如下图:
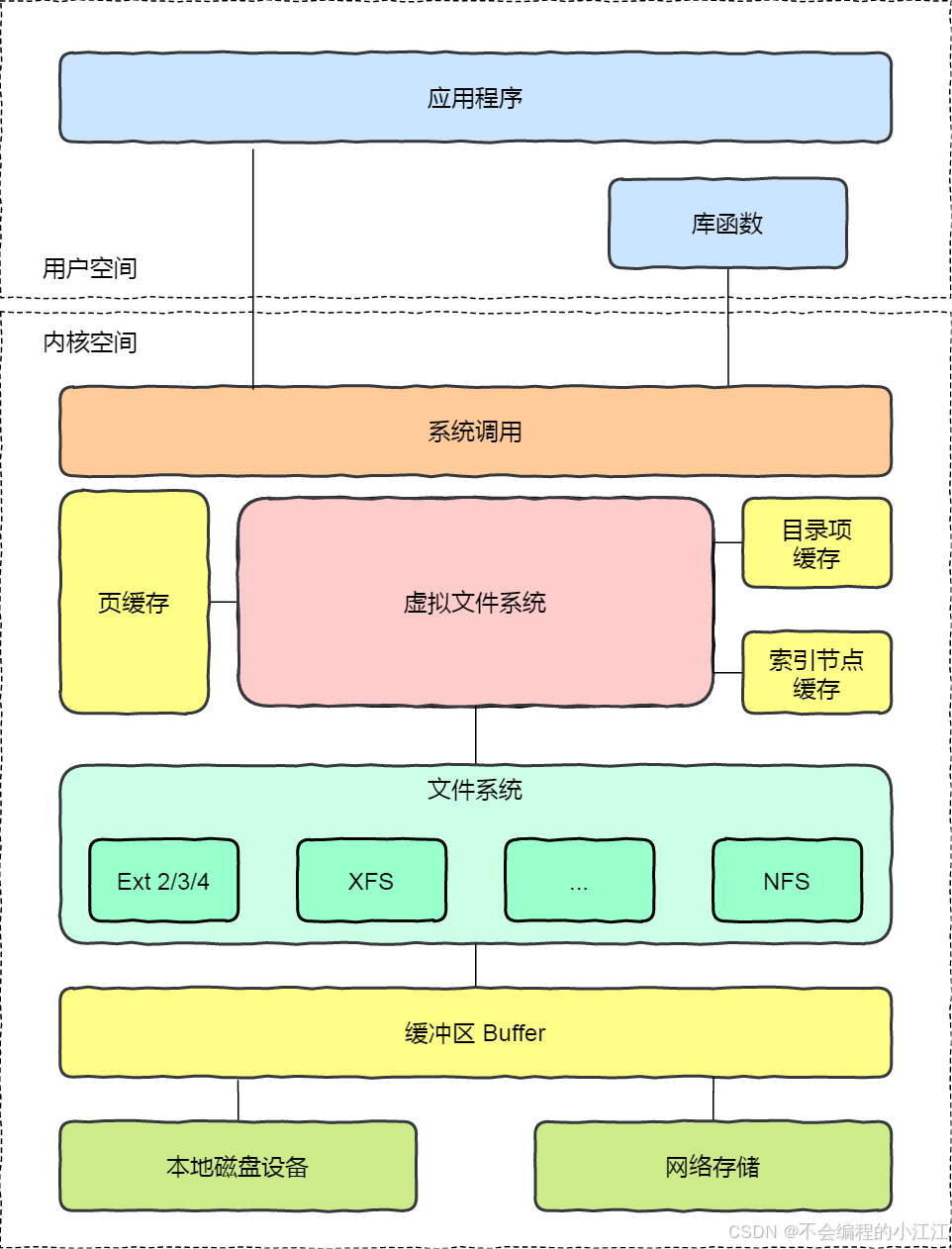
连续空间存储
连续空间存放方式顾名思义,文件存放在磁盘「连续的」物理空间中。这种模式下,文件的数据都是紧密相连,读写效率很高,因为一次磁盘寻道就可以读出整个文件。
使用连续存放的方式有一个前提,必须先知道一个文件的大小,这样文件系统才会根据文件的大小在磁盘上找到一块连续的空间分配给文件。
所以,文件头里需要指定「起始块的位置」和「长度」,有了这两个信息就可以很好的表示文件存放方式是一块连续的磁盘空间。
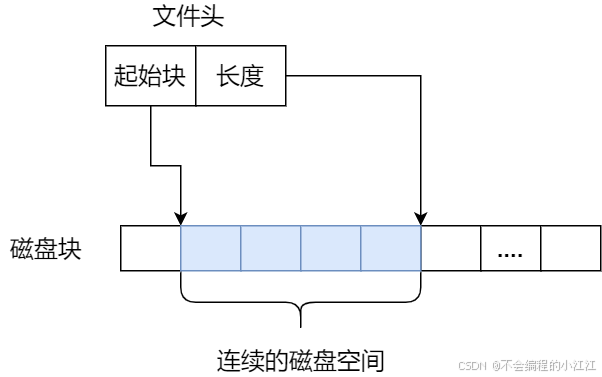
连续空间存放的方式虽然读写效率高,但是有「磁盘空间碎片」和「文件长度不易扩展」的缺陷。
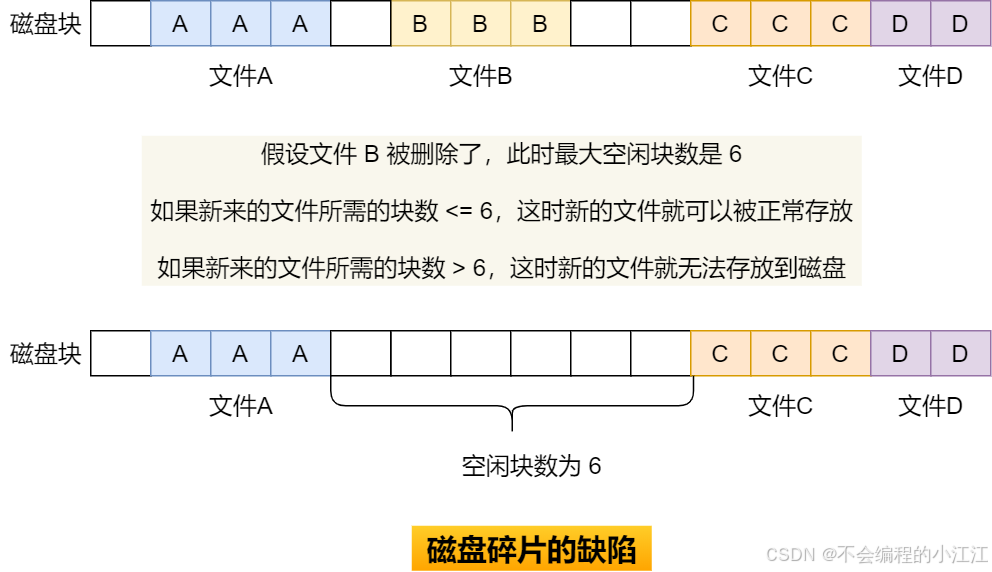
-
磁盘空间碎片: 如果文件 B 被删除,磁盘上就留下一块空缺,这时,如果新来的文件小于其中的一个空缺,可以将其放在相应空缺里。但如果该文件的大小大于所有的空缺,但却小于空缺大小之和,则虽然磁盘上有足够的空缺,但该文件还是不能存放。当然可以通过将现有文件进行挪动来腾出空间以容纳新的文件,但这在磁盘挪动文件非常耗时,太现实。
-
文件长度扩展不方便: 文件A 要想扩大一下,需要更多的磁盘空间,唯一的办法就只能是挪动的方式,这种方式效率是非常低的
非连续空间存储
非连续空间存放方式又可以分为「链表方式」和「索引方式」
「链表方式」
链表的方式存放是离散的,不用连续的,于是就可以消除磁盘碎片,可大大提高磁盘空间的利⽤率,同时文件的长度可以动态扩展。根据实现的方式的不同,链表可分为「隐式链表」和「显式链接」两种形式
-
「隐式链表」
- 实现的方式是文件头要包含「第一块」和「最后一块」的位置,并且每个数据块里面留出一个指针空间,用来存放下⼀个数据块的位置,
- 缺点:
- (1)无法直接访问数据块,只能通过指针顺序访问文件
- (2)数据块指针消耗了一定的存储空间
- (3)稳定性较差,由于软件或者硬件错误导致链表中的指针丢失或损坏,会导致文件数据的丢失
-
「显式链接」
它指把用于链接文件各数据块的指针,显式地存放在内存的一张链接表中,该表在整个磁盘仅设置一张,每个表项中存放链接指针,指向下一个数据块号。
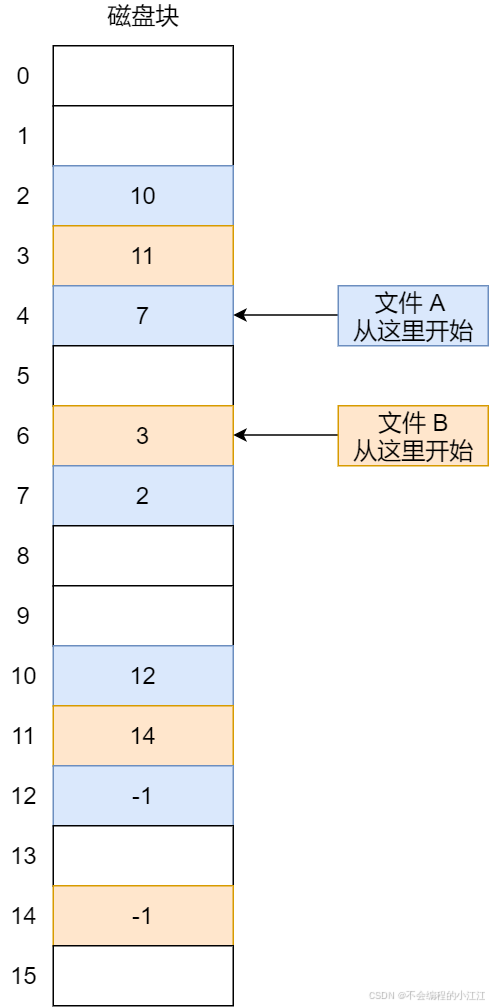
-
优点:不仅显著地提高了检索速度,⽽且大大减少了访问磁盘的次数
-
缺点:不适用于大磁盘
「索引方式」
-
链表的方式解决了连续分配的磁盘碎片和文件动态扩展的问题,但是不能有效支持直接访问
-
索引的实现是为每个文件创建一个**「索引数据块」,里面存放的是指向文件数据块的指针列表**,就像书的目录⼀样,要找哪个章节的内容,看目录查就可以

-
优点:
- 文件的创建、增大、缩小很方便;
- 不会有碎片的问题;
- 支持顺序读写和随机读写;
-
缺点: 由于索引数据也是存放在磁盘块的,如果文件很小,明明只需⼀块就可以存放的下,但还是需要额外分配一块来存放索引数据,所以缺陷之一就是存储索引带来的开销
「链式索引块」
-
在索引数据块留出一个存放下一个索引数据块的指针
-
缺点:万一某个指针损坏了,后面的数据也就会⽆法读取了
「多级索引块」
-
通过一个索引块来存放多个索引数据块,一层套一层索引
空闲空间管理
空闲表法
-
表内容包括空闲区的第一个块号和该空闲区的块个数,这个方式是连续分配的
-
这种方法仅当有少量的空闲区时才有较好的效果。因为,如果存储空间中有着大量的小的空闲区,则空闲表变得很大,这样查询效率会很低

空闲链表法
- 每一个空闲块里面有一个指针指向下一个空闲块
- 其特点是简单,但不能随机访问,工作效率低,因为每当在链上增加或移动空闲块时需要做很多 I/O 操作,同时数据块的指针消耗了一定的存储空间。
位图法
- 位图是利⽤二进制的一位来表示磁盘中一个盘块的使用情况
- 不仅用于数据空闲块的管理,还用于 inode 空闲块的管理,因为 inode 也是存储在磁盘的
目录的存储
-
目录其实也是个文件,就是一项一项地将目录下的文件信息列在表里。
-
列表中每一项就代表该目录下的文件的文件名和对应的 inode,通过这个 inode,就可以找到真正的文件
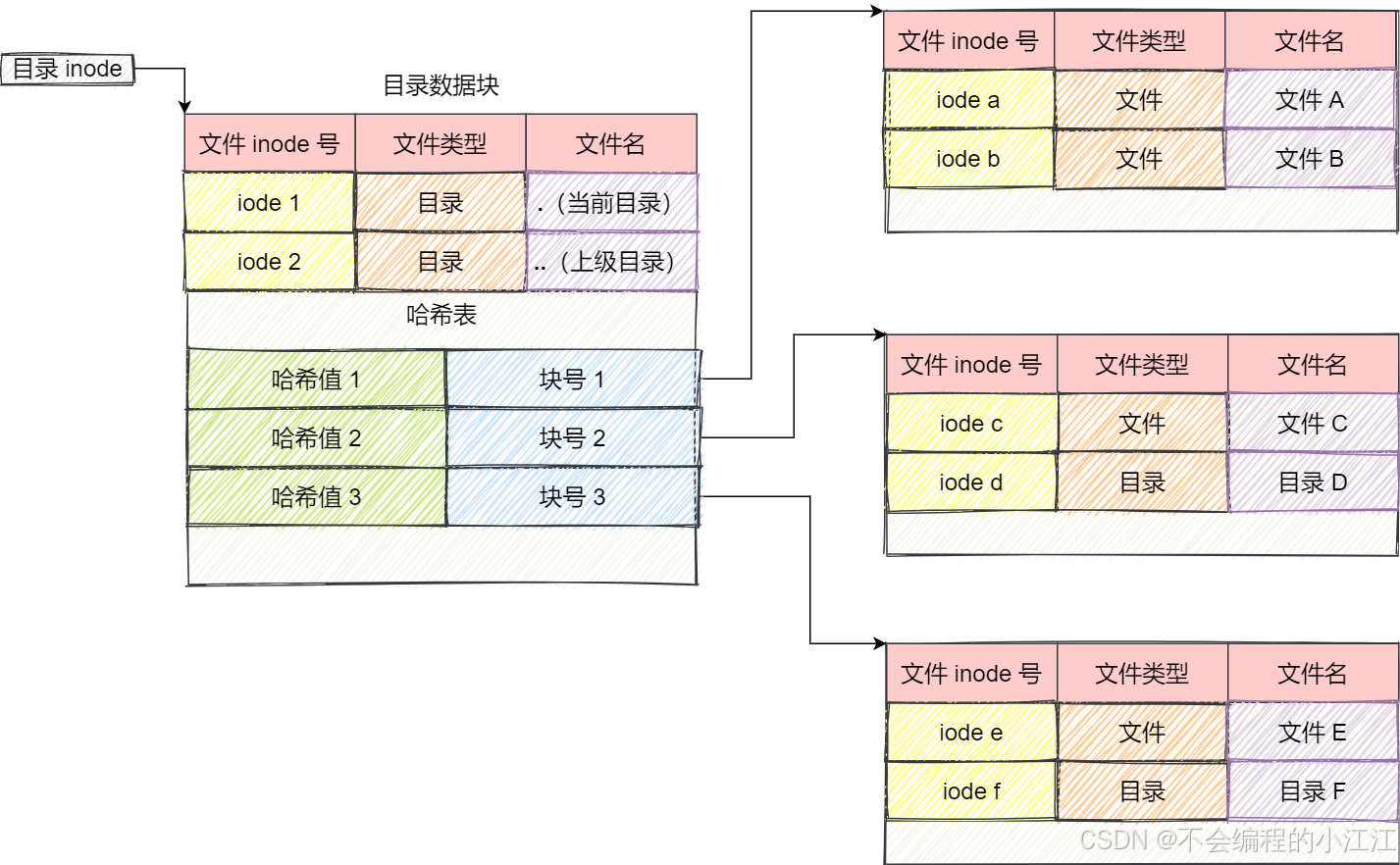
-
通常,第⼀项是「
.」,表示当前⽬录,第⼆项是「..」,表示上⼀级⽬录,接下来就是一项一项的文件名和 inode。 -
如果一个目录有超级多的文件,我们要想在这个目录下找文件,按照列表一项一项的找,效率就不高了。
-
于是,保存目录的格式改成哈希表,对文件名进行哈希计算,把哈希值保存起来,如果我们要查找一个目录下面的文件件名,可以通过名称取哈希。
软链接和硬链接
硬链接: 硬链接是多个目录项中的「索引节点」指向一个文件,也就是指向同一个 inode,但是 inode 是不可能跨越文件系统的,每个文件件系统都有各自的 inode 数据结构和列表,所以硬链接是不可用于跨文件系统的。由于多个目录项都是指向一个 inode,那么只有删除文件的所有硬链接以及源文件时,系统才会彻底删除该文件。
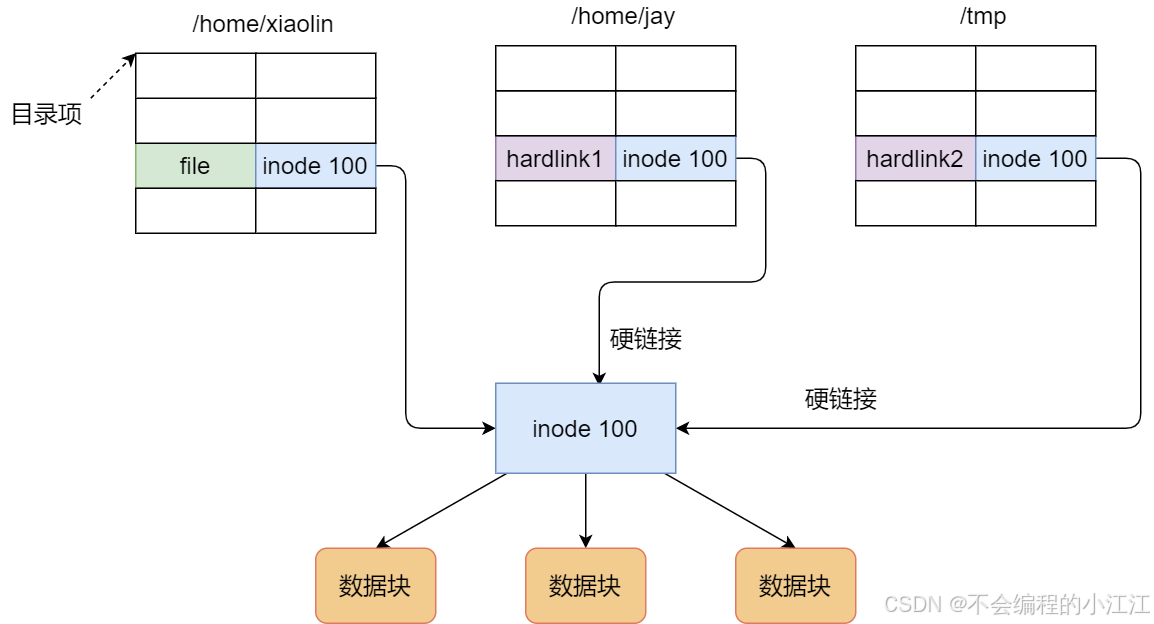
硬链接: 相当于重新创建一个文件,这个文件有独立的 inode,但是这个文件的内容是另外一个文件的路径,所以访问软链接的时候,实际上相当于访问到了另外一个文件,所以软链接是可以跨文件系统的,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。

Linux内核与驱动
Linux操作系统在开发板的启动流程
- BootROM(芯片内置ROM) 芯片上电后首先执行固化在ROM中的代码,初始化CPU基础环境,根据启动模式(如SD卡、eMMC、USB、UART)加载下一阶段引导程序(如SPL或U-Boot)到内存
- SPL: 当U-Boot过大时,SPL作为精简版引导程序,负责加载完整U-Boot,初始化关键硬件(内存、时钟、串口),读取SD卡读取完整U-boot,并跳转到U-boot运行
- U-Boot(通用引导程序):加载内核并传递参数。初始化硬件(MMU、外设、环境变量,读取内核镜像和设备树到内存,通过bootm或bootz命令跳转到内核入口,并传递设备树地址和启动参数
Linux内核启动
- 内核解压与初始化(汇编阶段),解压内核,初始化页表,跳转到C语言入口。
- 核心初始化(C语言阶段):初始化调度器,内存管理、解析设备树、初始化外设驱动,挂载根文件系统
根文件系统
- 内核尝试挂载根文件系统(如ext4)
- 若根文件系统在存储设备(如eMMC),需依赖对应驱动(SD卡驱动)
用户空间初始化
- 内核启动第一个用户进程init(PID=1)
- 执行初始化脚本:解析/etc/inittab配置文件,/etc/init.d/rcS
- 应用程序启动:根据配置启动守护进程或图形界面
Linux内核结构框图
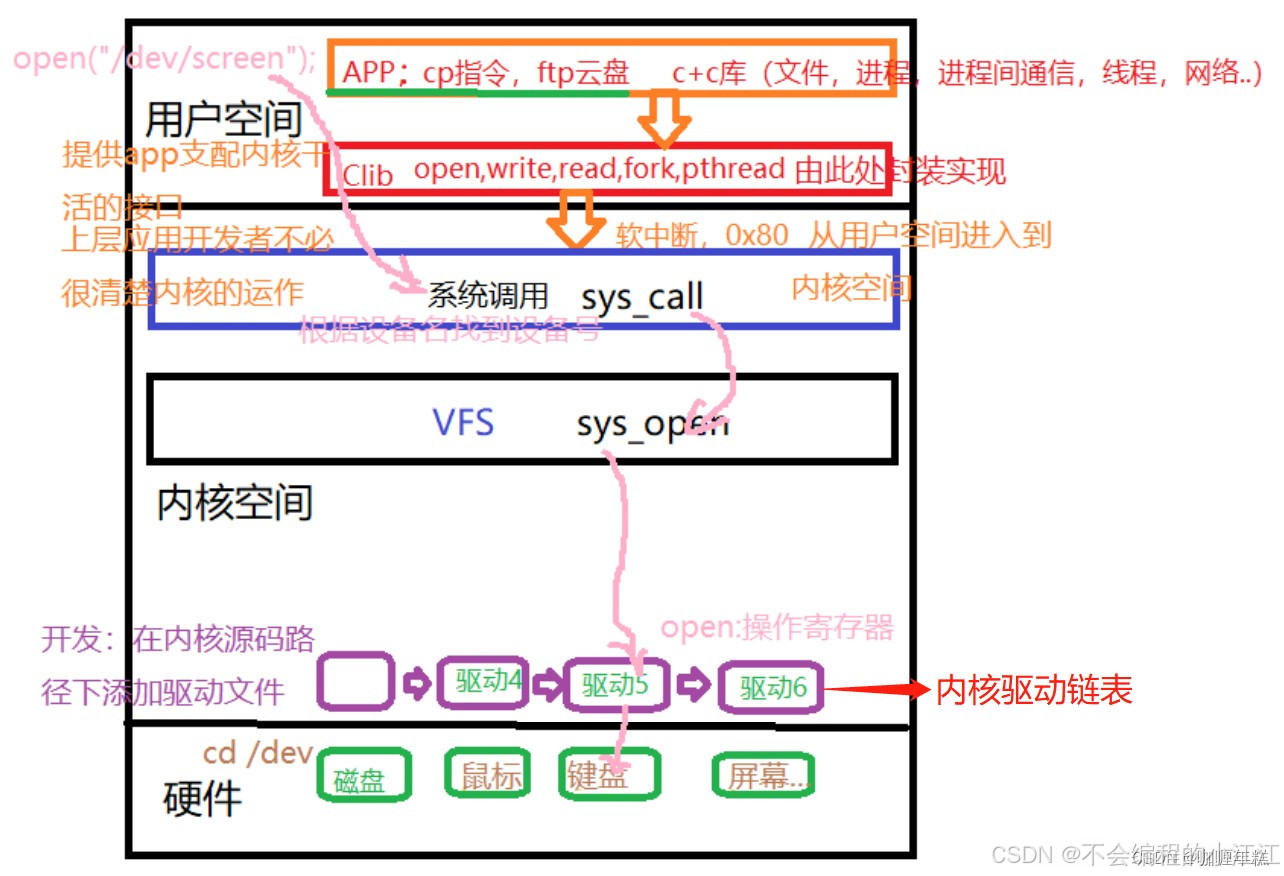

- 进程管理:负责创建、管理和调度进程,包括进程的创建、销毁和调度等功能。
- 内存管理:负责管理内存资源,包括物理内存的分配与释放、虚拟内存的映射与管理等。
- 文件系统:提供对存储设备和文件的访问接口,支持各种文件系统格式。
- 设备驱动:提供对硬件设备的抽象和控制接口,支持各种设备驱动程序。
- 网络协议栈:实现了各种网络协议,提供网络通信的功能。
- 系统调用:提供用户空间程序与内核之间的接口,允许应用程序调用内核提供的功能和服务。
Bootloader的两个阶段的启动过程。
预引导阶段(Pre-boot Stage):
- 第一阶段: 该阶段也被称为硬件初始化阶段。在此阶段,Bootloader负责进行硬件初始化和基本系统设置。这包括检测和初始化处理器、内存、时钟、总线和其他外设的操作。
- 第二阶段: 在此阶段,Bootloader负责加载第二阶段的Bootloader代码。此代码位于存储介质上(例如闪存、硬盘等),并负责执行更高级的系统配置和初始化,包括加载文件系统驱动程序等。这一阶段还可以提供用户界面、bootloader配置和固件升级等功能。
操作系统加载阶段(Operating System Load Stage):
- 该阶段是引导加载程序加载并启动操作系统(通常是Linux内核)的阶段。Bootloader会加载操作系统内核的映像文件,并执行一系列操作,例如设置内核参数、初始化设备树等。然后,它将控制权转移到操作系统的入口点,使操作系统接管系统的控制和管理。
通过这两个阶段的启动过程,引导加载程序能够在启动过程中对硬件进行初始化和配置,并加载操作系统,以使嵌入式系统能够正常运行。这种分阶段的启动过程为系统提供了灵活性和可扩展性
linux的内核是由bootloader装载到内存中的?
Linux内核是由引导加载程序(Bootloader)装载到内存中的。在系统启动过程中,引导加载程序负责加载Linux内核,将其从存储介质(如磁盘或闪存)读取到内存中的指定位置。
具体的步骤如下:
- 引导加载程序首先初始化硬件环境,例如处理器、内存和外设等。
- 引导加载程序根据特定规则(如配置文件或参数)确定Linux内核的位置,通常是指定内核映像文件在存储介质上的位置。
- 引导加载程序从存储介质中加载Linux内核的映像文件到内存中的指定位置。这个过程涉及到读取映像文件的内容,并将其复制到内存中的指定位置。
- 引导加载程序还可能对内核进行一些预处理或修正,如设定内核启动参数、修改映像文件的头部信息等。
- 加载完成后,引导加载程序将控制权转移到Linux内核的入口点,以开始内核的执行。
为什么需要BootLoader
- 硬件初始化: Bootloader负责初始化嵌入式系统的硬件环境。它通过设置处理器、内存、时钟和外设等硬件的初值,确保它们处于正确的状态以便后续的系统操作。
- 加载操作系统: Bootloader的主要任务是加载操作系统,如Linux内核,将其从存储介质(如闪存、磁盘等)中读取到内存中。这个过程包括读取映像文件、解压缩(如果有必要)以及将内核映像文件复制到内存的指定位置。
- 系统配置和参数设置:Bootloader可以提供用户界面或配置文件,允许用户或系统管理员对系统进行配置和参数设置。这包括设置内核启动参数、设置设备树、选择启动选项等。通过这些配置和参数设置,Bootloader可以根据特定需求进行个性化定制。
- 多引导选择: 在某些情况下(如双重引导或多系统引导),系统可能有多个可选的操作系统或内核映像文件。Bootloader可以提供菜单或交互界面,允许用户选择启动哪个操作系统或内核映像文件。这提供了灵活性和可扩展性,使系统能够根据需求选择不同的操作系统或配置。
- 系统维护和升级: Bootloader还可以用于系统维护和固件升级。它可以提供功能,如备份和还原系统、加载和更新固件等。通过这些功能,系统的维护和升级可以更加方便、安全和可靠。
bootloader内核和根文件的关系
嵌入式Linux系统从软件角度可以分为四个主要部分:引导加载程序(Bootloader)、Linux内核、文件系统和应用程序。这些部分共同构成了完整的嵌入式系统。
- 引导加载程序(Bootloader):引导加载程序是系统启动的第一个执行代码,负责系统的引导和初始化。它可以包括固化在固件中的boot代码和Bootloader程序。引导加载程序的主要任务是初始化硬件、加载Linux内核、配置系统参数,并将控制权传递给内核。
- Linux内核:Linux内核是嵌入式系统的核心,负责管理系统的硬件资源、提供各种设备驱动程序和执行系统的核心功能。它提供了任务管理、内存管理、进程调度、设备管理等基本功能,并提供了丰富的系统调用接口供应用程序使用。
- 文件系统:嵌入式系统通常会有一个或多个文件系统。根文件系统是其中最重要的,它包含了操作系统所需的基本文件和目录结构。此外,嵌入式系统还可以建立在闪存或其他存储设备上的文件系统,用于存储应用程序、配置文件和数据等。
- 应用程序:应用程序是嵌入式系统中运行在用户空间的程序,利用Linux内核提供的服务和资源完成特定的功能需求。应用程序可以包括各种应用、服务和驱动程序,用于实现各种功能,如通信、控制、数据处理等。
系统调用read()/write(),内核具体做了哪些事情?
- 用户空间发起read()/write()系统调用,并将参数传递给内核。
- 内核根据系统调用号找到相应的内核函数进行处理,如sys_read()/sys_write()。
- 内核根据文件描述符找到对应的文件对象,并执行读取或写入操作。
- 在读取操作中,内核将数据从文件或设备读取到内核空间,并通过页缓存层进行管理。
- 在写入操作中,内核将数据从用户空间拷贝到内核空间,并通过文件系统层将数据写入文件或设备。
- 内核可能会通过缓存管理、块设备管理和驱动程序等层次对数据进行处理和传输。
- 处理完成后,内核将结果返回给用户空间,并用户空间继续执行下一步操作
内核态,用户态的区别
内核态和用户态的区别主要在于权限和安全性。
- 权限: 内核态拥有最高的权限,可以访问和执行所有的系统指令和资源,而用户态的权限相对较低,只能访问受限的指令和资源。 内核态能够执行特权指令,如修改内存映射、管理硬件设备等,而用户态不能直接执行这些特权指令。
- 安全性:由于内核态具有较高的权限,错误的操作或滥用权限可能会导致系统崩溃或不安全。为了保护系统的稳定性和安全性,将操作系统的核心部分放在内核态下运行,限制用户态的权限。 用户态的应用程序必须通过系统调用的方式向内核请求操作系统提供的服务和资源,这样可以有效地控制用户程序对系统的影响范围。
- 进入内核态的方式: 进入内核态有三种方式,分别是系统调用、异常和设备中断。系统调用是应用程序主动向内核请求服务的方式;异常是由应用程序中的错误或异常情况触发的,如非法指令、内存访问越界等;设备中断是外部设备产生的中断信号,需要内核处理。
树莓派Linux源码配置
驱动代码的编写: 驱动代码的编译需要一个提前编译好的内核
编译内核就必须配置,配置的最终目标会生成 .config文件,该文件指导Makefile去把有用东西组织成内核
厂家配linux内核源码,比如说买了树莓派,树莓派linux内核源码
第一种方式: cp 厂家.config .config
- 指定ARM架构 : ARCH=arm
- 指定编译器 : CROSS_COMPILE=arm-linux-gnueabihf-
- 树莓派 : KERNEL=kernel7
- 主要核心指令 : make bcm2709_defconfig
第二种方式: make menuconfig 一项项配置,通常是基于厂家的config来配置
驱动两种加载方式:
- *表示编译进内核 zImage包含了驱动
- M 模块方式生成驱动文件xxx.ko 系统启动后,通过命令inmosd xxx.ko 加载
- 【】表示略过的,不参与编译,也就是需要裁剪的东西
第三种方式: 完全自己来配置树莓派的Linux内核
- -j4: 指定用多少电脑资源进行编译
- zImage: 生成内核镜像
- modules: 要生成驱动模块
- dtbs: 生成配置文件
移植内核至树莓派
- STEP 1:打包zImage文件
- STEP 2:挂载U盘
- sdb1即data1是fat分区,是boot相关的内容,kernel的img文件在此分区
- sdb2即data2是ext4分区,也就是系统的根目录分区。
- STEP 3 :安装modules
- STEP 4:更新 kernel.img 文件
- STEP 5:在源码树中复制其它配置文件到fat分区(data1)
- STEP 6: 将配置玩的内存卡放入树莓派中键入uname -r查看更换后的内核版
字符设备驱动
- 在Linux文件系统中,每个文件都用一个 struct inode结构体来描述,这个结构体记录了这个文件的所有信息,例如文件类型,访问权限等。
- 在linux操作系统中**,每个驱动程序在应用层的/dev目录或者其他如/sys目录下都会有一个文件与之对应。**
- 在linux操作系统中, 每个驱动程序都有一个设备号。 主设备号与次设备号
- 在linux操作系统中,每打开一次文件,Linux操作系统会在VFS层分配一个struct file结构体来描述打开的文件。
open函数打开设备文件时,可以根据设备文件对应的struct inode结构体描述的信息,struct inode结构体里面记录的设备号,可以找到对应的驱动程序。
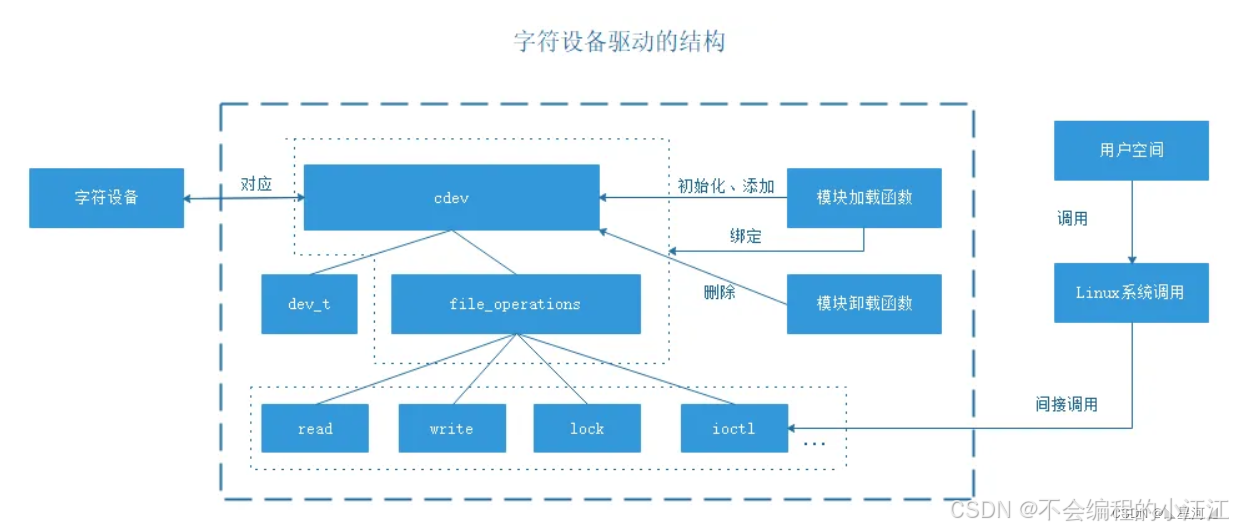
在Linux字符设备驱动:
- 模块加载函数通过
register_chrdev_region( )或alloc_chrdev_region( )来静态或者动态获取设备号 - 通过
cdev_init( )建立cdev与file_operations之间的连接 - 通过
cdev_add( )向系统添加一个cdev以完成注册。 - 模块卸载函数通过
cdev_del( )来注销cdev - 通过
unregister_chrdev_region来释放设备号。
用户空间访问该设备的程序通过Linux系统调用,如open( )、read( )、write( ),用 file_operations 来定义字符设备驱动提供给VFS的接口函数。
一般来说,编写一个 linux 设备驱动程序的大致流程如下:
-
查看原理图、数据手册,了解设备的操作方法;
-
在内核中找到相近的驱动程序,以它为模板进行开发,有时候需要从零开始;
-
实现驱动程序的初始化:比如向内核注册这个驱动程序,这样应用程序传入文件名时,内核才能找到相应的驱动程序;
-
设计所要实现的操作,比如 open、close、read、write 等函数;
-
实现中断服务(中断并不是每个设备驱动所必须的);
-
编译该驱动程序到内核中,或者用 insmod 命令加载;
-
测试驱动程序;
//变量定义 static struct class *pin4_class; static struct device *pin4_class_dev;static dev_t devno; // 设备号 static int major = 231; // 主设备号 static int minor = 0; // 次设备号 static char* module_name = "pin4"; // 模块名static int pin4_open(struct inode *inode, struct file *file) static int pin4_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos) static int pin4_read(struct file* file, char __user * buf, size_t count, loff_t *ppos)static struct file_operations pin4_fops = {.owner = THIS_MODULE,.open = pin4_open,.write = pin4_write,.read = pin4_read };// 真实驱动入口 int __init pin4_drv_init(void) void __exit pin4_drv_exit(void)module_init(pin4_drv_init); //入口, 内核加载该驱动的时候,这个宏会被调用 module_exit(pin4_drv_exit);
单片机
在数字电路或通信协议中,CP信号可能指 时钟脉冲(Clock Pulse) 或 控制脉冲
在嵌入式文件系统或数据传输中,CP信号可能表示 复制进度反馈,数据复制进度信号(Copy Progress)
I2C与SPI
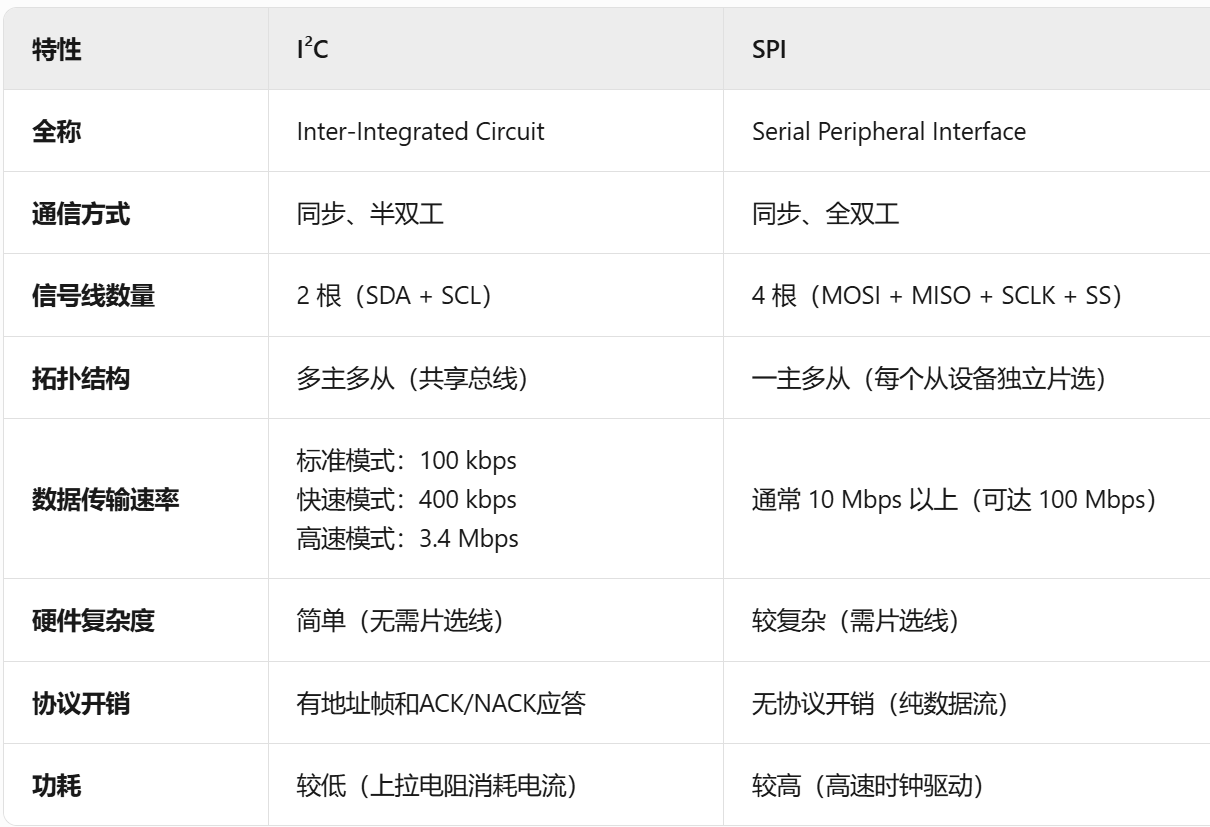
IIC SPI UART的区别
| 对比维度 | UART (通用异步收发传输器) | SPI (串行外设接口) | IIC (集成电路总线) |
|---|---|---|---|
| 通信方式 | 异步通信(无时钟线) | 同步通信(有独立时钟线) | 同步通信(时钟线复用) |
| 信号线数量 | 2 线(TX 发送、RX 接收) | 4 线(SCLK 时钟、MOSI 主发从收、MISO 主收从发、SS 片选),SS 可省略(多从机需) | 2 线(SDA 数据线、SCL 时钟线) |
| 拓扑结构 | 点对点(1 主 1 从,多设备需额外硬件) | 主从结构(1 主多从,需 SS 区分从机) | 主从结构(1 主多从,通过地址区分从机,无需片选) |
| 速率 | 低速(典型 < 115200 bps,最高约 1 Mbps) | 高速(典型 1 - 50 Mbps,部分芯片支持 > 100 Mbps) | 中速(标准模式 100 kbps、快速模式 400 kbps、高速模式 3.4 Mbps) |
| 地址机制 | 无(点对点无需地址) | 无(通过 SS 硬件片选区分从机) | 有(7 位 / 10 位地址,从机需配置唯一地址) |
| 硬件成本 | 低(仅需 TX/RX,可通过软件模拟) | 中(需额外 SCLK/MISO/MOSI,部分场景需 SS) | 低(仅 2 线,支持多从机,硬件简化) |
| 抗干扰能力 | 弱(异步无时钟,易受噪声影响,需校验位补偿) | 强(同步时钟采样,噪声对时序影响小) | 中(同步但线复用,长距离易受干扰) |
| 双向通信支持 | 支持(全双工,TX/RX 独立) | 支持(全双工,MOSI/MISO 独立) | 支持(半双工,SDA 线复用,需分时传输) |
| 典型应用场景 | 串口调试、GPS 模块、蓝牙模块、PC 与外设通信 | 高速数据传输(如 LCD 屏、ADC/DAC、Flash 存储) | 多从机低速通信(如传感器、EEPROM、实时时钟 RTC) |
二、核心特性拆解(深入理解差异)
1. 通信方式:异步 vs 同步
- UART:异步通信无需时钟线,通过「波特率」(发送端与接收端预先约定的速率,如 9600 bps、115200 bps)同步数据。数据帧格式固定(如 1 位起始位 + 8 位数据位 + 1 位校验位 + 1 位停止位),接收端通过起始位检测数据开始,再按波特率采样数据。缺点:波特率偏差超过 5% 会导致数据错误,抗干扰能力弱;无法直接实现多设备通信(需额外加多路开关或转成其他协议)。
- **SPI:同步通信(独立时钟)**由主机(如 MCU)生成独立的 SCLK 时钟信号,从机(如传感器)严格按 SCLK 的上升沿 / 下降沿采样数据,速率由 SCLK 频率决定。主从设备通过 MOSI(主机发、从机收)和 MISO(主机收、从机发)实现全双工通信,多从机时需通过 SS 线(片选)指定当前通信的从机(未被选中的从机高阻态)。优点:时钟独立,时序稳定,速率远高于 UART;全双工通信效率高。
- **IIC:同步通信(时钟复用)**仅用 SDA(数据线)和 SCL(时钟线)两根线,时钟由主机生成,数据在 SCL 的高电平 / 低电平期间传输(需遵守「时钟拉伸」机制:从机可拉低 SCL 暂停通信,等待自身准备好)。多从机通过「地址」区分(主机发送从机地址后,只有地址匹配的从机响应),无需片选线,硬件更简洁;但 SDA 是半双工(同一时间只能发或收),需分时传输。优点:拓扑简洁(2 线挂多个设备),适合资源受限的场景;支持「多主设备」(需仲裁机制避免冲突)。
2. 速率与效率:高速、中速、低速的定位
- SPI 最快:无地址开销,时钟直接控制传输,速率可达几十 Mbps,适合需要高速传输的场景(如 LCD 屏刷新、Flash 数据读写)。
- IIC 居中:受限于线复用和地址机制,最高速率 3.4 Mbps(高速模式),但多数场景用 100 kbps/400 kbps,适合传感器、RTC 等低速数据交互。
- UART 最慢:受异步波特率限制,实际应用中很少超过 1 Mbps,主要用于低速、短距离的指令 / 调试信息传输(如 MCU 与 PC 的串口调试)。
3. 拓扑与多设备支持:灵活性差异
-
UART:仅点对点
1 个 TX 对应 1 个 RX,若要连接多个设备,需额外硬件(如 RS485 芯片转差分通信,或用串口多路开关),软件复杂度高。
-
SPI:1 主多从(需 SS 线)
多从机时,每增加 1 个从机需增加 1 根 SS 线(若 MCU 引脚足够),或通过「菊花链」拓扑(部分芯片支持)减少 SS 线,但兼容性差。
-
IIC:1 主多从(无 SS 线)
所有设备挂在 SDA/SCL 总线上,通过地址区分,理论上可挂 127 个 7 位地址的设备(实际受总线电容限制,一般不超过 10 个),硬件最简洁,适合多设备密集部署(如物联网传感器节点)。
三、协议选择策略:4 步确定最优方案
选择的核心逻辑是:匹配「传输需求」与「协议特性」,可按以下 4 个步骤判断:
步骤 1:明确「数据速率」需求
- 高速传输(> 1 Mbps):优先选 SPI(如 LCD 显示、高速 ADC 数据采集、Flash 存储读写)。
- 中速传输(100 kbps ~ 1 Mbps):选 IIC(如传感器数据交互、EEPROM 读写)。
- 低速传输(< 100 kbps):选 UART(如串口调试、GPS 定位信息输出、蓝牙模块指令交互)。
步骤 2:明确「设备数量与拓扑」需求
- 仅 2 个设备通信:UART(硬件最简单)、SPI(需 4 线,速率高)均可,按速率选。
- 3 个及以上设备通信
- 若设备数量少(3-5 个)、速率需求高:选 SPI(需增加 SS 线,时序稳定)。
- 若设备数量多(>5 个)、速率需求低:选 IIC(2 线即可,无需片选,硬件成本低)。
步骤 3:明确「硬件资源」限制
- MCU 引脚紧张:优先选 IIC(仅需 2 个引脚),其次是 UART(2 个引脚),最后是 SPI(至少 4 个引脚)。
- 成本敏感(无额外芯片):UART 或 IIC(可通过 GPIO 软件模拟,无需专用硬件模块);SPI 软件模拟较复杂,更适合用硬件 SPI 模块。
步骤 4:明确「抗干扰与可靠性」需求
- 强干扰环境(如工业场景、长距离传输)
- 短距离(<1 米):选 SPI(同步时钟抗干扰强)。
- 长距离(>1 米):UART 需搭配 RS485/RS232 芯片转差分信号,IIC 需加总线 extender(如 PCA9548),SPI 需加差分驱动芯片(成本更高)。
- 低干扰环境(如消费电子内部):UART、IIC 均可,按速率和拓扑选。
四、典型应用场景示例
| 应用场景 | 推荐协议 | 选择理由 |
|---|---|---|
| MCU 与 PC 串口调试 | UART | 低速需求(9600/115200 bps),点对点通信,硬件简单(USB 转 TTL 即可) |
| 手机主板上的 RTC 时钟 | IIC | 低速(100 kbps),多设备(RTC、EEPROM 共总线),引脚少(2 线) |
| 单片机驱动 LCD 显示屏 | SPI | 高速需求(>10 Mbps),需快速刷新画面,SPI 速率满足,全双工效率高 |
| 物联网节点(多个传感器) | IIC | 8 个温湿度传感器挂在同一总线,低速(400 kbps),2 线简化硬件设计 |
| 蓝牙模块与 MCU 通信 | UART | 蓝牙模块多提供 UART 接口,低速指令交互(如 AT 指令配置),点对点即可 |
总结
- UART:「简单低速的点对点」,适合调试、低速指令传输,硬件成本最低。
- SPI:「高速全双工的主从」,适合高速数据传输(如屏、存储),时序稳定但引脚多。
- IIC:「简洁多从机的中低速」,适合多设备密集部署(如传感器),2 线拓扑灵活。
I²C: 适合低速、多设备、引脚受限的场景,如传感器网络。
SPI: 适合高速、点对点、实时性要求高的场景,如存储或图像传输。
IIC时序:
- 起始信号: 当 SCL 为高电平期间,SDA 由高到低的跳变
- 停止信号: 当 SCL 为高电平期间,SDA 由低到高的跳变;
- 应答信号: 发送器每发送一个字节,就在时钟脉冲期间释放数据线,由接收器反馈一个应答信号。应答信号为低电平时,规定为有效应答位(ACK 简称应答位),表示接收器已经成功地接收了该字节。
- 数据有效性: IIC 总线进行数据传送时,时钟信号为高电平期间,数据线上的数据必须保持稳定,只有在时钟线上的信号为低电平期间,数据线上的高电平或低电平状态才允许变化。
- 数据传输: 在 IIC 总线上传送的每一位数据都有一个时钟脉冲相对应(或同步控制),即在 SCL 串行时钟的配合下,在 SDA 上逐位地串行传送每一位数据。数据位的传输是边沿触发。
- 空闲状态: IIC 总线的 SDA 和 SCL 两条信号线同时处于高电平时,规定为总线的空闲状态。
快排:
int partition(vector<int>& array, int left, int right)
{int pivot = (right + left) / 2;int pival = array[pivot];swap(array[pivot], array[right]);int idx = left;for (int i = left; i < right; i++){if(array[i] < pival) {swap(array[i], array[idx]);idx++;}}swap(array[right], array[idx]);return idx;
}
键盘敲入字母A时,发生了什么


- 那当用户输入了键盘字符,键盘控制器就会产生扫描码数据,并将其缓冲在键盘控制器的寄存器中,紧接着键盘控制器通过总线给 CPU 发送中断请求。
- CPU 收到中断请求后,操作系统会保存被中断进程的 CPU 上下文,然后调用键盘的中断处理程序
- 键盘的中断处理程序是在键盘驱动程序初始化时注册的,那键盘中断处理函数的功能就是从键盘控制器的寄存器的缓冲区读取扫描码,再根据扫描码找到用户在键盘输入的字符,如果输入的字符是显示字符,那就会把扫描码翻译成对应显示字符的 ASCI 码,比如用户在键盘输入的是字母 A,是显示字符,于是就会把扫描码翻译成 A 字符的 ASCII 码。
- 得到了显示字符的 ASCI码后,就会把 ASCI码放到**「读缓冲区队列」**,接下来就是要把显示字符显示屏幕了
- 显示设备的驱动程序会定时从**「读缓冲区队列」读取数据放到「写缓冲区队列」,最后把「写缓冲区队列」**的数据一个一个写入到显示设备的控制器的寄存器中的数据缓冲区,最将这些数据显示在屏幕里。
- 显示出结果后,恢复被中断进程的上下文
一帧数据的传递
发送端:
应用层:
- 应用程序生成数据,数据被封装为应用层协议格式(如HTTP头部+正文)
传输层:
- 分段: 数据被拆分为适合传输的TCP段
- 封装: 添加TCP头部,包含(源/目的端口,序列号、确认号、窗口大小,标志位)
- 可靠性处理: 通过滑动窗口、超时重传机制确保可靠性。
网络层:
- 封装IP包: 添加IP头部(包含源/目的地IP地址、协议字段)
- 路由选择: 通过路由表确定下一条
数据链路层
- 封装帧: 添加帧头部和尾部(源/目的MAC地址、IPV4/6字段类型)
- 物理寻址
物理层:
- 将编码、调制、转化为比特流,通过物理介质传输
接收端:
-
物理层: 解调比特流、还原为数据链路层帧
-
数据链路层: 校验MAC地址,解封装后传到网络层
-
网络层: 检查IP头部,若目的IP匹配则解封装,向上传递至传输层
-
传输层: 校验TCP头部,按序列号重组数据,发送ACK确认,处理丢包重传
-
应用层: 应用层解析数据,传递给用户进程
输入URL到页面展示发生了什么
URL 解析 → DNS 解析 → 建立连接(TCP/HTTPS) → 发送请求 → 服务器响应 → 浏览器渲染。
1. 用户输入与 URL 解析
- 输入处理:用户在浏览器地址栏输入 URL(如
https://www.example.com/path?query=1),浏览器首先判断输入是否为合法 URL(若不是,可能当作搜索词发送给默认搜索引擎)。 - URL 拆分,解析 URL 的各组成部分:
- 协议:如
http、https(决定传输层安全策略); - 域名:如
www.example.com(需转换为 IP 地址); - 端口:默认 HTTP 为 80,HTTPS 为 443(可省略);
- 路径:如
/path(服务器资源路径); - 查询参数:如
?query=1(传递给服务器的额外信息)
- 协议:如
2. DNS 域名解析(将域名转换为 IP 地址)
浏览器无法直接通过域名访问服务器,需先通过 DNS(域名系统)将域名解析为服务器的 IP 地址(如 192.168.1.1)。解析流程遵循 “缓存优先,逐级查询” 原则:
- 本地缓存查询:
- 先查浏览器缓存(浏览器会缓存近期解析过的域名,有效期由 DNS TTL 决定);
- 若未命中,查操作系统缓存(如 Windows 的
hosts文件、Linux 的/etc/hosts); - 再查路由器缓存、本地 DNS 服务器缓存(如运营商的 DNS 服务器)。
- 递归查询(本地 DNS 服务器)
- 若本地缓存无结果,本地 DNS 服务器会向根域名服务器(
.)发起查询,根服务器返回顶级域名服务器(如.com)地址; - 本地 DNS 向顶级域名服务器查询,得到二级域名服务器(如
example.com)地址; - 最终向目标域名的权威 DNS 服务器查询,获取对应 IP 地址,逐级返回给浏览器。
- 若本地缓存无结果,本地 DNS 服务器会向根域名服务器(
3. 建立网络连接(TCP 三次握手 / HTTPS TLS 握手)
获取 IP 地址后,浏览器需与服务器建立网络连接,核心是TCP 协议(HTTP/HTTPS 基于 TCP),若为 HTTPS 还需额外的TLS 安全握手。
- TCP 三次握手(建立可靠连接)
- 客户端发送
SYN报文(请求建立连接); - 服务器返回
SYN+ACK报文(同意连接,并确认收到请求); - 客户端发送
ACK报文(确认收到服务器响应),连接建立。
- 客户端发送
- HTTPS 的 TLS 握手(加密通信)
- 客户端发送支持的 TLS 版本、加密套件列表;
- 服务器选择加密套件,返回数字证书(含公钥);
- 客户端验证证书有效性(通过 CA 机构),生成随机对称密钥,用服务器公钥加密后发送;
- 服务器用私钥解密,得到对称密钥;
- 双方确认使用该对称密钥进行后续通信(数据加密传输)。
4. 发送 HTTP 请求 连接建立后,浏览器向服务器发送HTTP 请求报文,请求获取目标资源。请求报文结构包括:
- 请求行:
方法(GET/POST等) + URL路径 + HTTP版本(如GET /path HTTP/1.1); - 请求头:键值对形式,包含浏览器信息(
User-Agent)、接受的数据类型(Accept)、Cookie、缓存控制(Cache-Control)等; - 请求体:仅 POST 等方法有,用于传递表单数据、JSON 等(GET 方法参数在 URL 中)。
5. 服务器处理请求并返回响应
- 接收与解析:解析请求报文,确定目标资源(如静态文件、动态接口);
- 处理逻辑
- 若为静态资源(HTML/CSS/JS/ 图片),直接从服务器文件系统读取;
- 若为动态资源(如 PHP/JSP 接口),由后端程序(如 Java、Python)处理(可能查询数据库、调用其他服务);
- 可能经过负载均衡(如 Nginx)分发到具体业务服务器。
- 返回响应,生成HTTP 响应报文
- 状态行:
HTTP版本 + 状态码 + 状态描述(如HTTP/1.1 200 OK,常见状态码:200 成功、301 永久重定向、404 未找到、500 服务器错误); - 响应头:内容类型(
Content-Type,如text/html)、内容长度(Content-Length)、缓存策略(Cache-Control、Expires)、Cookie 设置等; - 响应体:实际资源数据(如 HTML 文本、JSON 字符串、二进制图片等)。
- 状态行:
6. 浏览器处理响应数据
浏览器接收响应后,根据响应内容类型(Content-Type)进行处理:
- 判断资源类型
- 若为 HTML:进入渲染流程;
- 若为 CSS/JS/ 图片:缓存到本地(按响应头的缓存策略),并在渲染时使用;
- 若为 JSON:由 JS 解析处理(如异步请求的数据)。
- 缓存处理:资源存入缓存
7. 页面渲染
浏览器解析 HTML 并将其渲染为可视化页面,核心流程由渲染引擎(如 Chrome 的 Blink、Firefox 的 Gecko)完成,分为以下阶段:
- 解析HTML
- 解析CSS,构建CSS的对象树
- 生成渲染树
- Layout布局
- 按一定的顺序排列 Painting
8. 连接关闭(可选)
- 若为 HTTP/1.1 且开启
Connection: keep-alive(默认),TCP 连接会保持一段时间,供后续请求复用(减少握手开销); - 否则,通过 TCP 四次挥手关闭连接。
有了IP地址如何找到对端
IP 地址→子网判断→MAC 地址(ARP)→路由转发(网关 / 路由器)
- 本地IP地址与目标IP地址和本地掩码同时做与运算,判断是否在同一个网段下面
- 如果目标 IP 在本地子网(同一局域网),本地主机无需经过路由器,直接通过ARP 协议(地址解析协议) 获取目标主机的MAC 地址(物理地址),即可 “找到对端”。
- 若目标 IP 不在本地子网,本地主机无法直接与目标通信,需将数据发送给网关(本地子网的出口设备,如家用路由器),由网关逐层转发至目标网络。本地主机通过 ARP 获取网关的 MAC 地址
- 网关通过路由表转发数据(跨网络传输),网关(通常是路由器)收到数据后,会根据自身的路由表决定 “下一跳”
- 当数据经过多跳转发到达目标 IP 所在的子网后,最后一跳的路由器会判断 “目标 IP 在本子网内”,此时通过 ARP 协议获取目标主机的 MAC 地址,将数据直接发送到目标主机
动态路由协议有哪些
外部网关协议 - BGP
外部网关协议用于不同自治系统之间的路由信息交换
BGP
内部网关协议OSPF,ISIS,RIP
OSPF(Open Shortest Path First,开放式最短路径优先)
- 类型:链路状态路由协议(基于 “链路状态” 计算最优路径,而非跳数)。
- 核心原理
- 每个路由器会向自治系统内所有其他路由器广播 “链路状态信息”(如自身与相邻路由器的连接带宽、延迟等);
- 所有路由器通过这些信息构建统一的 “网络拓扑图”,再用Dijkstra 算法计算到各目标网络的最短路径(基于链路成本,如带宽、延迟等)。
- 特点
- 无跳数限制,支持大型网络(可划分区域,减少路由信息交换量);
- 收敛速度快(路由变化时快速更新),适合企业级网络。
IS-IS(Intermediate System to Intermediate System,中间系统到中间系统)
- 类型:链路状态路由协议(与 OSPF 原理类似,但最初为 ISO 的 OSI 模型设计,后适配 TCP/IP)。
- 特点
- 支持更大规模的网络(比 OSPF 更灵活,常用于运营商骨干网);
- 路由计算效率高,适合复杂拓扑结构。
RIP(Routing Information Protocol,路由信息协议)
- 类型:距离矢量路由协议(基于 “跳数” 计算最优路径)。
- 核心原理
- 路由器定期(如每 30 秒)向相邻路由器广播自己的路由表,共享 “目标网络 + 跳数” 信息;
- 跳数越少,路径越优(最大跳数 15,超过视为不可达,适合小型网络)。
- 版本
- RIPv1:不支持子网掩码,广播发送路由信息;
- RIPv2:支持子网掩码,组播发送,安全性更高(可认证)。
- 适用场景:小型局域网(如家庭、小型办公室),配置简单但效率低
| 议类型 | 典型协议 | 适用范围 | 核心算法 / 原理 | 特点总结 |
|---|---|---|---|---|
| 内部网关协议 | RIP | 小型局域网 | 距离矢量(跳数) | 简单,跳数限制(≤15) |
| 内部网关协议 | OSPF | 中大型企业网 | 链路状态(Dijkstra) | 无跳数限制,收敛快,支持区域 |
| 内部网关协议 | IS-IS | 大型骨干网 | 链路状态 | 灵活,适合运营商网络 |
| 外部网关协议 | BGP | 自治系统间(互联网) | 路径矢量(属性选路) | 策略性强,支撑互联网路由 |
BGP
BGP——基本概念1
基础概念
基本概念:
- BGP 是路径矢量协议,是自治系统间的路由协议
- BGP采用TCP 179号端口,工作在应用层的协议,BGP路由器之间基于TCP建立BGP会话
- 运行BGP的路由器称为BGP Spearker,他们之间建立对等体关系后(邻居关系)才可以交换路由,进行路由学习
- BGP具有大量丰富的路径属性和强大的策略工具
- BGP主要用来传递IGP/静态协议计算出来的路由,不会计算路由
自治系统
- 我们通常使用AS号来表示不同的自治系统
- 在同一个自治系统内,一般使用相同内部路由协议——IGB协议(OSPF、IS-IS等)
- 自治系统间使用外部路由协议——通常是BGP协议
- 一台路由器只能运行在同一个AS内
BGP建邻
BGP基础(一)BGP邻居建立
BGP六种状态机详解:
BGP六种状态机详解:
-
ldle (空闲) : ldle是建立BGP连接的第一个状态,空闲状态,BGP在等待一个启动事件,启动事件出现以后,BGP初始化资源,复位连接重试计时器(Connect-Retry,缺省32秒),发起**一条TCP连接,同时转入Connect(连接)**状态。
-
Connect(连接)︰ 在Connect 状态,BGP发起第一个TCP连接,如果**连接重试计时器(Connect-Retry)**超时,就重新发起TCP连接,并继续保持在Connect 状态,如果TCP连接成功,就转入OpenSent状态,如果TCP连接失败,就转入Active 状态。如果搜索到了,则开始建立TCP连接,如果成功的话,邻居状态则进入"connect"状态。
-
Active (活跃)︰在Active状态,BGP总是在试图建立TCP连接,如果连接重试计时器(Connect-Retry))超时,就退回到Connect 状态,如果TCP连接成功,就转入OpenSent状态,如果TCP连接失败,就继续保持在Active状态,并继续发起TCP连接,没有收到对open-send报文的确认报文。
-
OpenSent(open消息已发送)︰在OpenSent 状态,TCP连接已经建立,BGP也已经发送了第一个Open报文,剩下的工作,BGP就在等待其对等体发送Open 报文。并对收到的Open报文进行正确性检查,如果有错误,系统就会发送一条出错通知消息并退回到ldle状态,如果没有错误,BGP就开始发送Keepalive报文,并复位Keepalive 计时器,开始计时。同时转入OpenConfirm状态。
-
OpenConfirm (open消息已确认):在OpenConfirm状态,BGP发送一个Keepalive 报文,同时复位保持计时器,如果收到了一个Keepalive报文,就转入Established阶段,BGP邻居关系就建立起来了。如果TCP连接中断,就退回到ldle状态。
- 此状态代表收到邻居的open报文,并发送keepalive报文,和等待接收邻居的keepalive。
- 如果参数协商成功,就会发送keepalive报文,进行隐式确认,收到该报文后,就进入到open-confirm状态。
- 如果在5s之内依然是没有收到keepalive报文的话,就进入到active状态。
-
Established (连接已建立)︰表示收到keepalive报文,在Established状态,BGP 邻居关系已经建立,这时,BGP将和它的邻居们交换Update报文,同时复位保持计时器。
另外,在除ldle 状态以外的其它五个状态出现任何Error的时候,BGP状态机就会退回到ldle 状态。

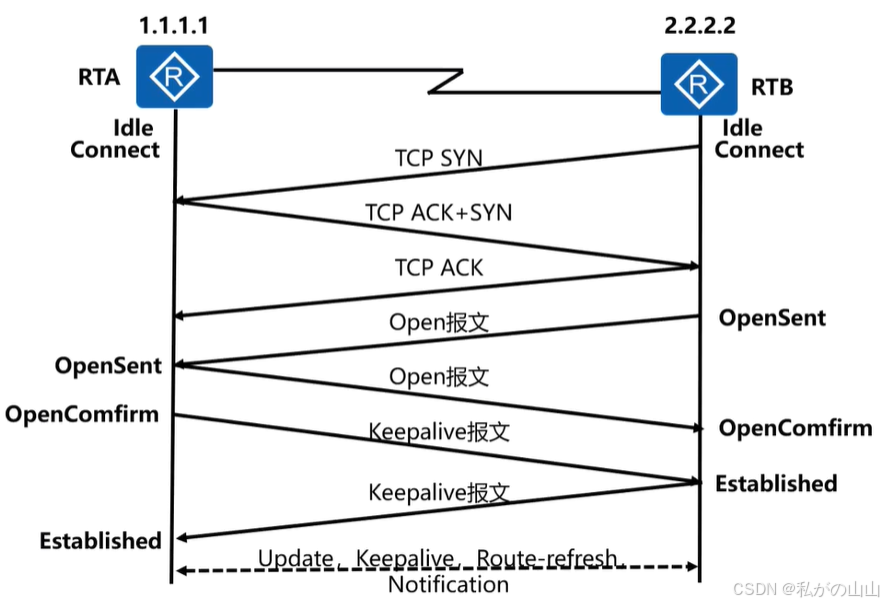
BGP五种报文详解:
- Open报文: Open报文由TCP发起者首先发送,进行邻居建立和能力、参数的协商。
- 自身AS号:要和邻居指定的AS号一致,否则邻居无法建立BGP 。
- router id :不能相同,否则会冲突,导致邻居关系无法建立。
- hold time :邻居失效时间,默认180s,如果不一致,则协商小的。
- BGP version :默认目前运行的是BGPv4,一般不存在版本不同的情况。
- 地址族协商一致,不一致邻居无法建立,默认 IPv4 单播地址族,还有IPv4组播地址族、VPNv4地址族
- 路由刷新能力,即手动触发更新能力,当BGP策略发生变化同步时,手动立即更新的能力。
- 是否支持4字节AS号的能力
open报文,负责邻居建立过程中的参数和能力协商(至少有一个地址族能力要一致,其他两个不打紧)。
-
keepalive报文
- keepalive报文作为open报文协商成功的标志,收到open报文,并且参数、能力协商一致,则发送keepalive报文给对方,对方收到后,转到establish状态。
- eepalive报文,默认每隔60s周期性发送,如果180s没有收到keepliave报文,则认为BGP邻居失效,断开TCP连接。
-
update报文: update报文,用于BGP路由传递以及撤销,也就是在BGP对等体之间交换路由信息。
-
route-refresh报文: route-refresh报文,用于手动进行BGP路由的触发更新,或者用于ORF功能。
-
notification报文: notification报文,通知报文 ,用于报错,收到该报文只有一个结果就是断开TCP连接。

路由属性与策略
Origin 路由起源属性: 源属性用来定义路由的来源,通过修改此属性可以控制BGP路径的选择
-
i (internal) 代表通过Network宣告学到的路由
-
? (incomplete) 代表通过Import-route引入学习到的路由
-
e (EGP) 代表通过EGP协议引入的路由 --EGP已淘汰
-
3种起源属性的优先级为:i>e>?(network>EGP协议引入>import-route引入)
Next_Hop 下一跳: Next_Hop下一跳属性主要用于路由选路,用于指定到达目的网络的下一跳地址
- 默认情况下,凡是自身起源的BGP路由,在传递给任何BGP邻居时,都会更改路由的下一跳为邻居的更新源地址
- 默认情况下,在向EBGP邻居传送BGP路由时,其下一跳会更改,会更改为邻居的更新源地址;可以通过命令实现不更改
- 默认情况下,从EBGP邻居得到的BGP路由再传送给IBGP邻居时,此BGP路由的下一跳不会更改;可以通过命令配置实现更改
Local_Pref 本地优先级 本地优先级主要用于路由选路
- 只在AS内传递,不会传递给其它AS,用于判断流量离开AS时的最佳路由
- 该优先级越大越优先(华为锐捷设备默认优先级为100)
- BGP设备将路由传递给IBGP邻居是保留该属性
- BGP设备将路由传递给EBGP邻居时不携带Local_Pref属性
MED(Multi_Exit_Disc) 多出口区分符 MED是一种度量值,主要用户路由选路
- 仅在相邻两个AS之间传递(或某个AS内传递),并且收到此属性的AS不会再将其通告给任何第三方AS
- 一般用于判断流量进入AS时的最佳路径,优先级越小越优
通告规则:
- 默认从EBGP/IBGP邻居学到的路由再通告给EBGP邻居时,MED会被清除,即不发送此属性(除非手动指定可以传给的EBGP邻居)
- 默认从EBGP/IBGP邻居学到的路由再通告给IBGP邻居,会保留MED属性
- 默认本地引入的直连、静态、IGP路由如果有MED值,那么可以直接传递给EBGP邻居或IBGP邻居
- 默认从联盟EBGP邻居或联盟内始发的路由,其MED值在整个联盟内保持传递
路由反射器与BGP联盟
Originator_ID-----起源ID 用于防止集群内产生路由环路
当一条路由第一次被RR反射的时候,RR将Originator_ID属性加入这条路由,标识这条路由的发起设备。如果一条路由中已经存在了Originator_ID属性,则RR将不会创建新的Originator_ID属性
Cluster_List-------集群列表 用于防止集群间产生路由环路
- 当一条路由第一次被RR反射的时候,RR会把本地Cluster ID添加到Cluster List的前面。如果没有Cluster_List属性,RR就创建一个。
- 当RR接收到一条更新路由时,RR会检查Cluster List。如果Cluster List中已经有本地Cluster ID,丢弃该路由;如果没有本地Cluster ID,将其加入Cluster List,然后反射该更新路由。
**AS_Path AS路径属性:**AS路径属性,主要用来进行路由防环、路由选路
从EBGP邻居得到路由时,会检查该路由的AS_Path属性,如果此属性存在自身的AS号,则丢弃此路由——用于AS之间防环
经过AS数量越少的路径越优——用于BGP路由选路
AS_Path多种体现形式
-
AS_Path 有序的
-
As_Set 无序的(聚合路由时产生的)
-
联盟内的AS_Path 有序的
-
联盟内的AS_Set 无需的(聚合时产生的)