python舆情分析可视化系统 情感分析 微博 爬虫 scrapy爬虫技术 朴素贝叶斯分类算法大数据 计算机✅
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机专业毕业设计选题大全(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Django框架、数据库、Echarts可视化、scrapy爬虫技术、朴素贝叶斯分类算法(情感分类)
舆情分析+监测预警+情感分析+爬虫+可视化+论文
2、项目界面
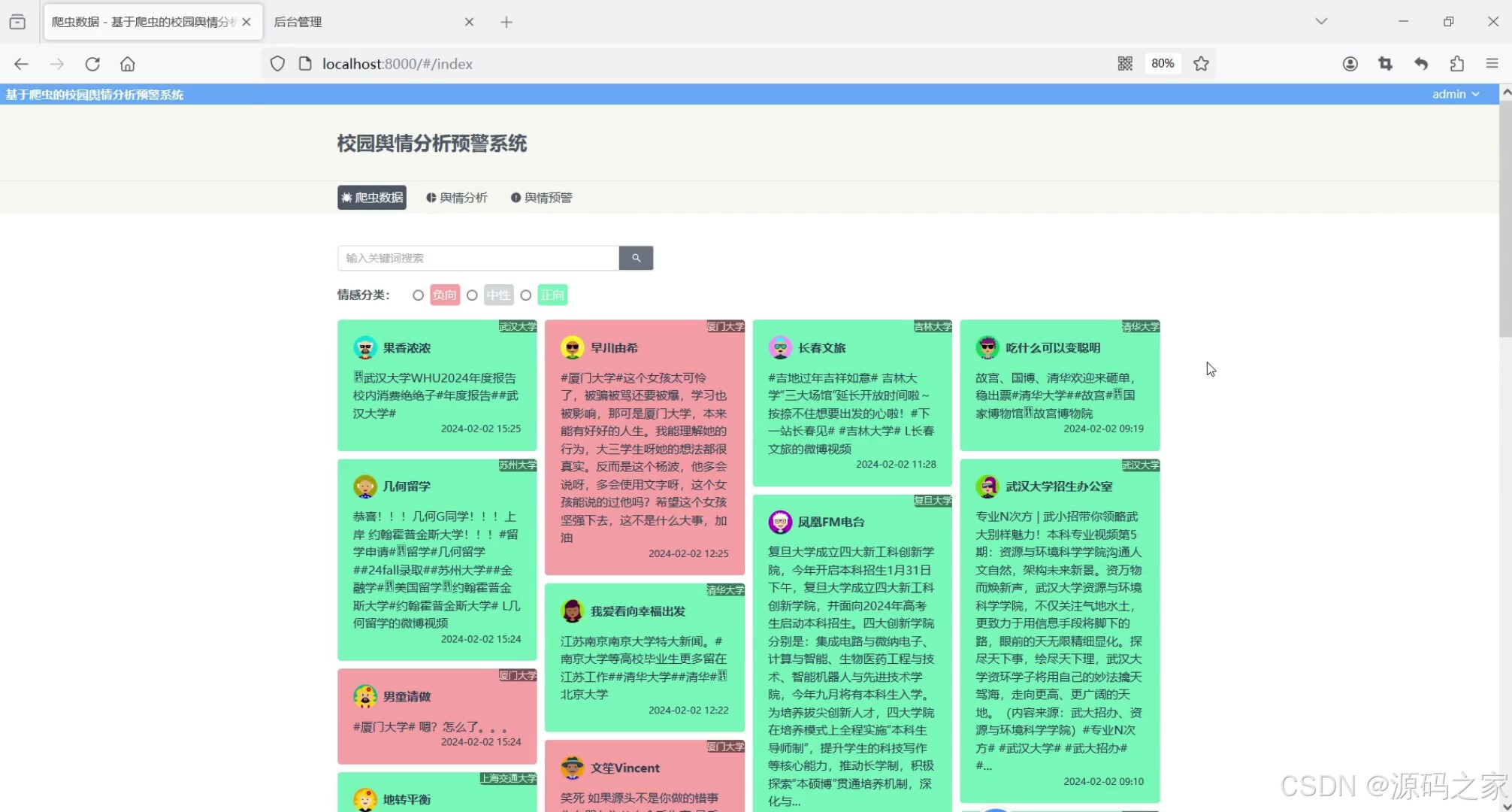
(1)数据中心
(2)舆情分析
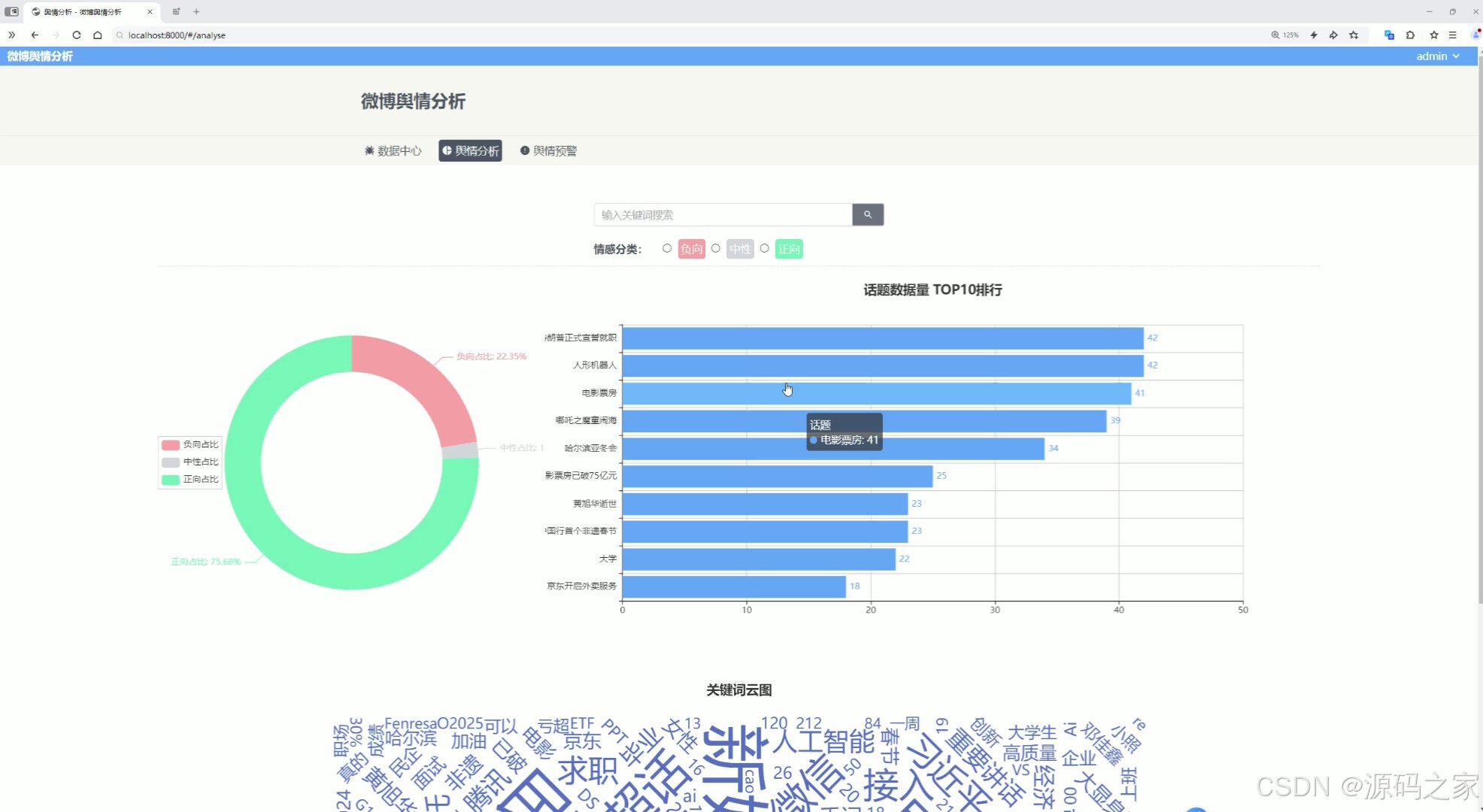
(3)舆情预警
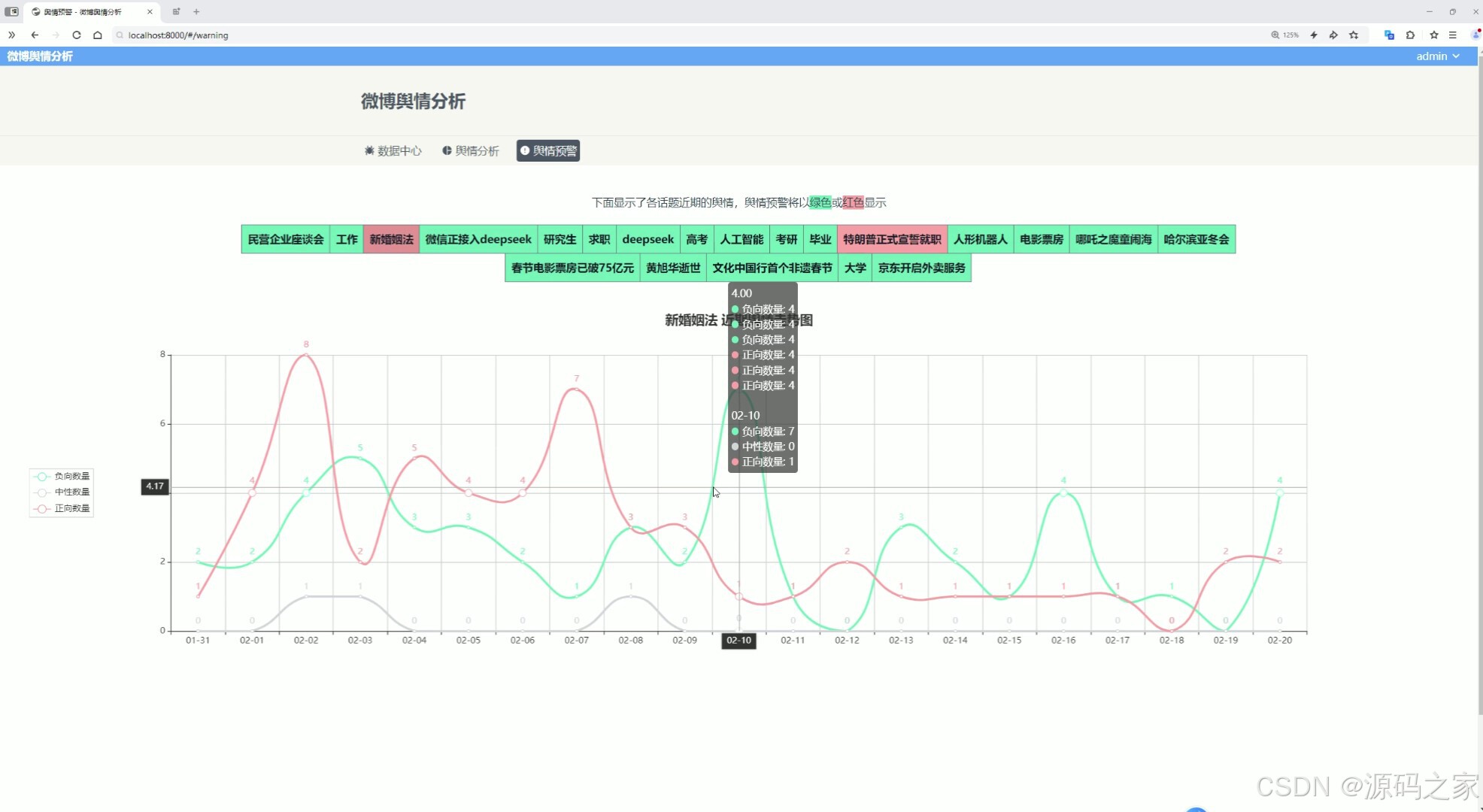
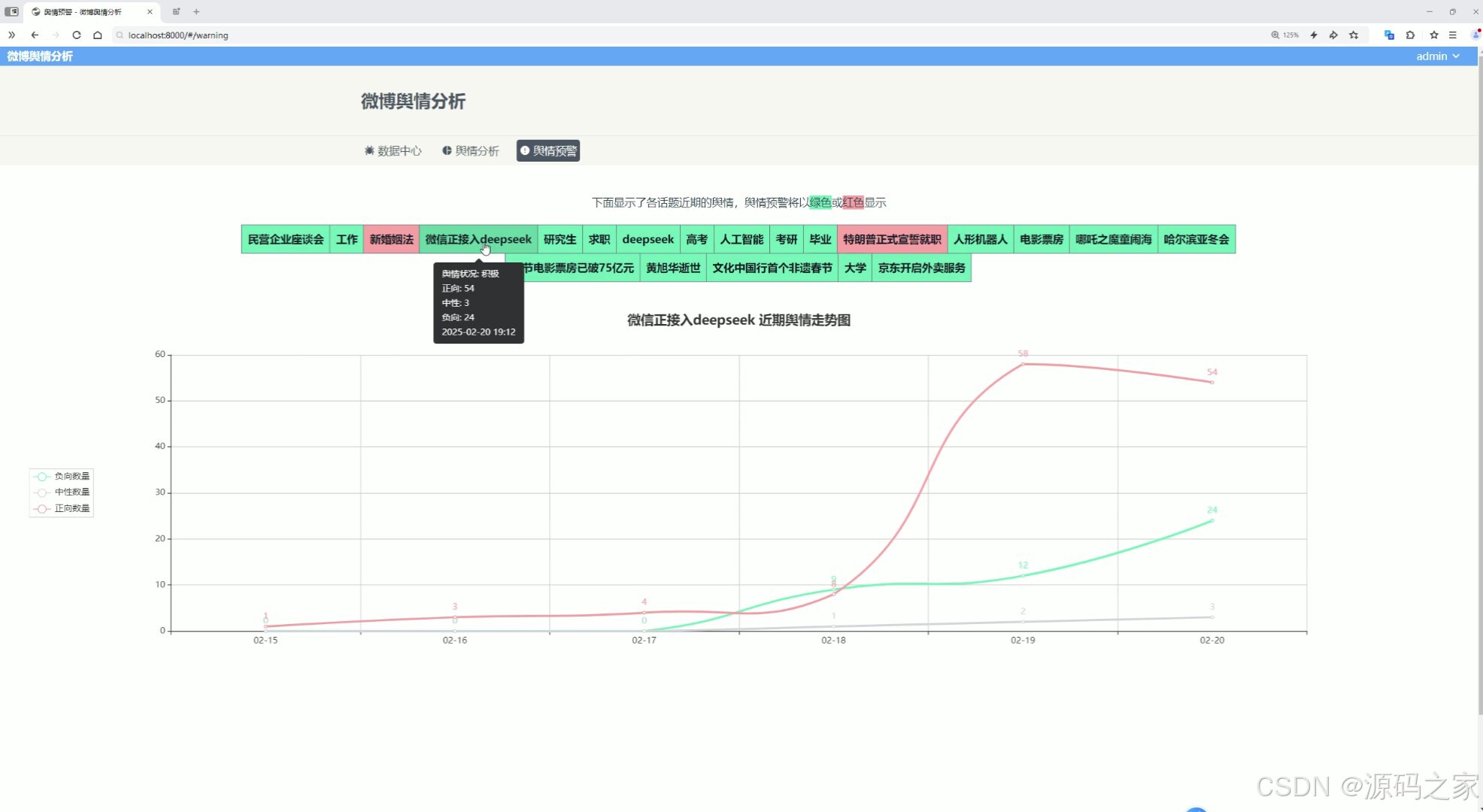
(4)情感分析
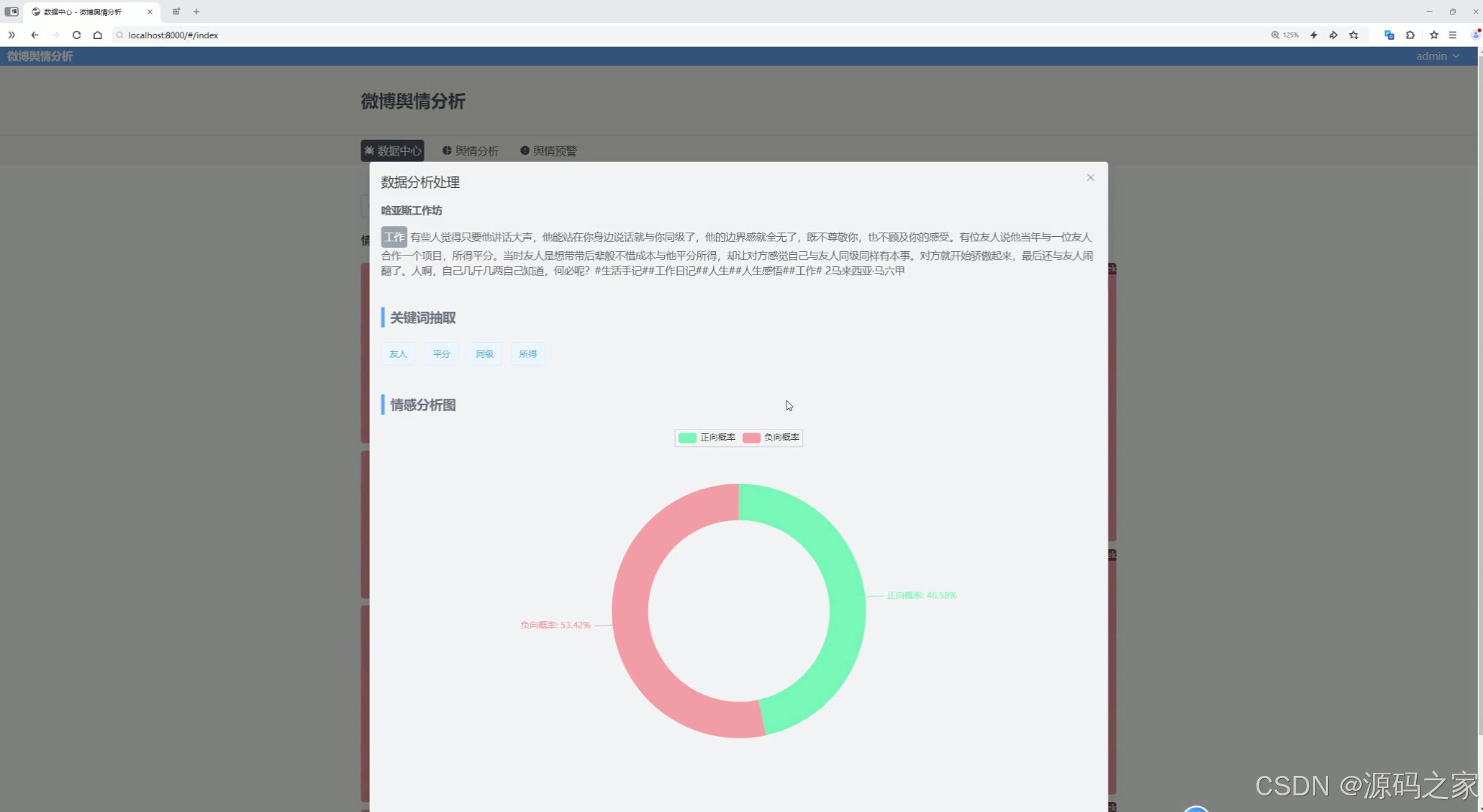
(5)词云图分析
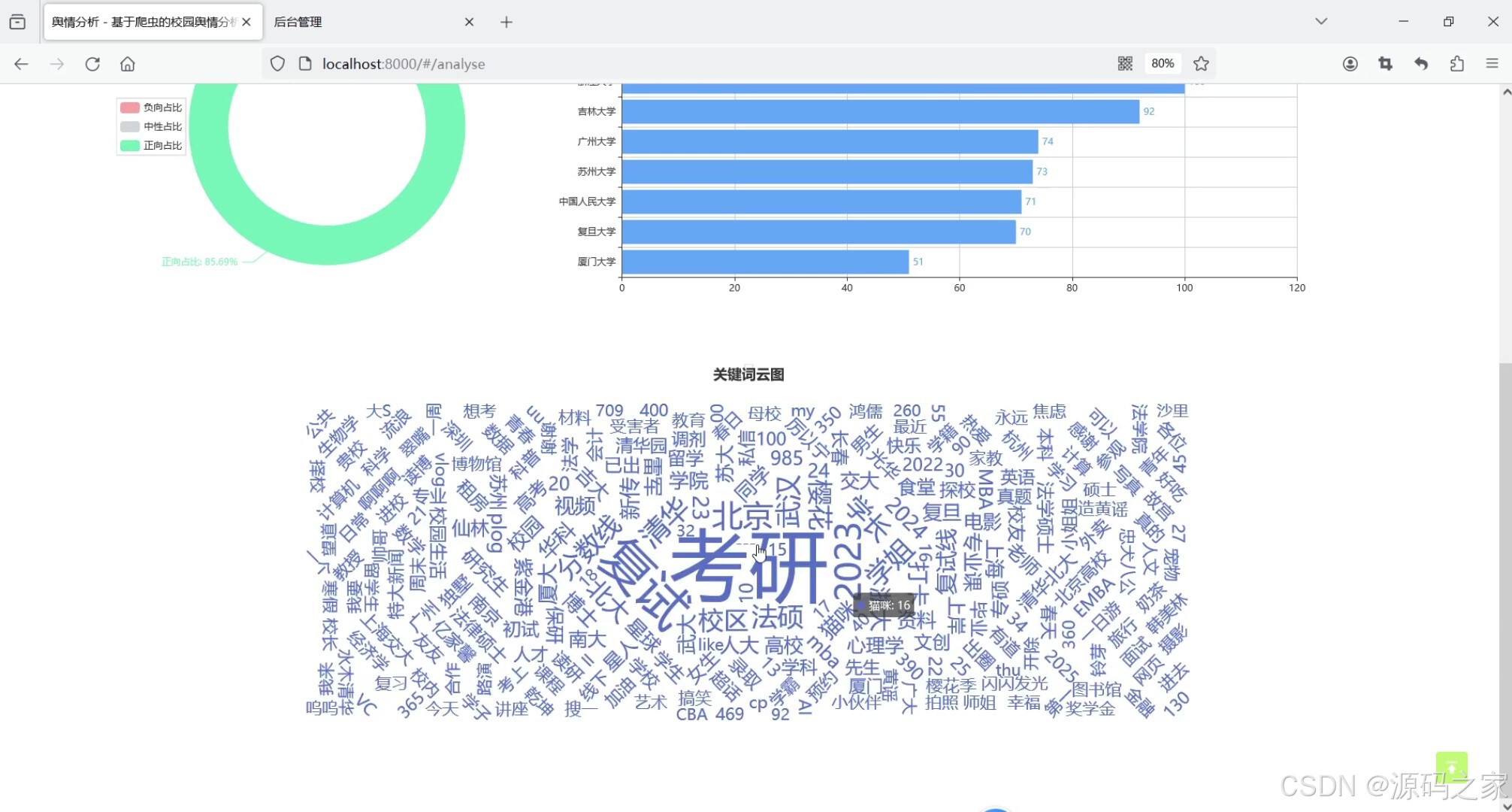
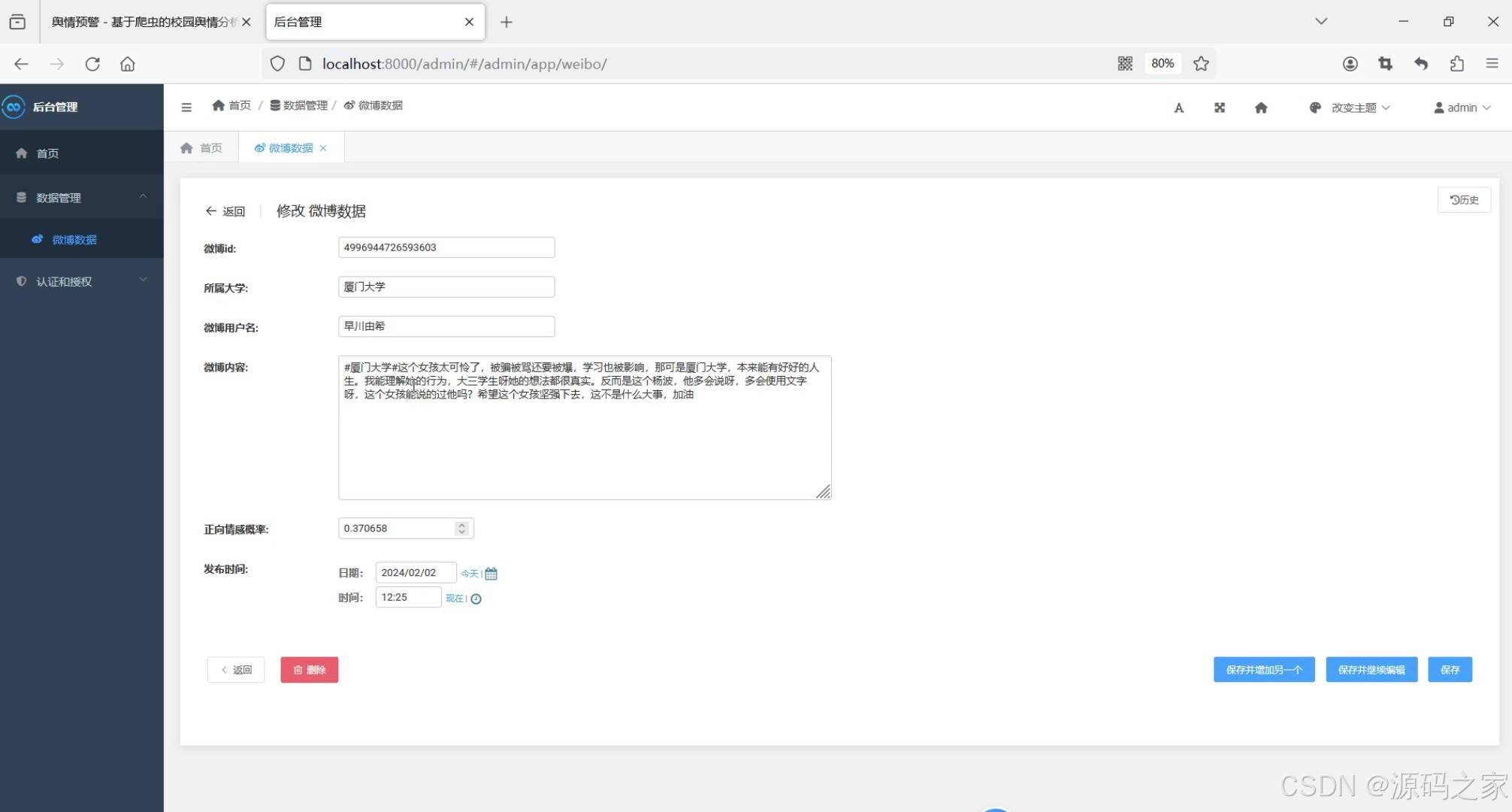
(6)后台数据管理
(7)注册登录
3、项目说明
摘要
随着社交媒体的迅猛发展和数据分析技术的进步,校园舆情监测变得尤为重要。高校管理部门长期依赖人工收集和分析舆情信息,效率低下,难以及时发现并应对潜在风险,导致危机处理滞后,影响学校形象。
本系统基于Python语言开发,后端采用Django框架,使用Scrapy爬取微博数据,并通过朴素贝叶斯分类算法进行情感分析。前端采用Vue框架,结合Element-Plus组件库、axios请求库和ECharts可视化工具,实现舆情数据展示、筛选和分析。
系统主要功能包括微博数据展示、舆情分析和预警。微博数据以瀑布流卡片形式呈现,颜色区分情感类别,点击卡片可查看详细分析。舆情分析模块通过饼图、柱状图和词云图展现情感占比、信息量排名及关键词分布。预警模块利用折线图追踪高校舆情趋势,负面情感超标时触发警示。系统提升了舆情监测的自动化和精准度,为高校管理提供有效决策支持。
关键词 舆情监测,情感分析,Python
系统总体架构分为四层:用户界面层、应用程序层、业务逻辑层、数据存储层。用户界面层使用Bootstrap和Layui,提供响应式设计和现代化界面,增强用户体验。用户通过浏览器访问系统,界面层负责展示信息和接收用户输入。应用程序层基于Django框架,处理请求与响应,路由管理和视图呈现。Django实现灵活性,易于扩展和维护,支持RESTful API设计。业务逻辑层包含核心业务处理逻辑,负责数据验证、用户认证和权限管理。数据存储层采用MySQL数据库,通过pymysql进行连接和操作。数据以表格形式存储,支持高效查询和事务管理。整个系统架构如图4-1所示。
4、核心代码
# -*- coding: utf-8 -*-
from __future__ import unicode_literalsimport sys
import gzip
import marshal
from math import log, expfrom ..utils.frequency import AddOneProbclass Bayes(object):def __init__(self):self.d = {}self.total = 0def save(self, fname, iszip=True):d = {}d['total'] = self.totald['d'] = {}for k, v in self.d.items():d['d'][k] = v.__dict__if sys.version_info[0] == 3:fname = fname + '.3'if not iszip:marshal.dump(d, open(fname, 'wb'))else:f = gzip.open(fname, 'wb')f.write(marshal.dumps(d))f.close()def load(self, fname, iszip=True):if sys.version_info[0] == 3:fname = fname + '.3'if not iszip:d = marshal.load(open(fname, 'rb'))else:try:f = gzip.open(fname, 'rb')d = marshal.loads(f.read())except IOError:f = open(fname, 'rb')d = marshal.loads(f.read())f.close()self.total = d['total']self.d = {}for k, v in d['d'].items():self.d[k] = AddOneProb()self.d[k].__dict__ = vdef train(self, data):for d in data:c = d[1]if c not in self.d:self.d[c] = AddOneProb()for word in d[0]:self.d[c].add(word, 1)self.total = sum(map(lambda x: self.d[x].getsum(), self.d.keys()))def classify(self, x):tmp = {}for k in self.d:tmp[k] = log(self.d[k].getsum()) - log(self.total)for word in x:tmp[k] += log(self.d[k].freq(word))ret, prob = 0, 0for k in self.d:now = 0try:for otherk in self.d:now += exp(tmp[otherk]-tmp[k])now = 1/nowexcept OverflowError:now = 0if now > prob:ret, prob = k, nowreturn (ret, prob)🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻