《Python 正则表达式完全指南:从入门到精通》(AI版)
一、引言
正则表达式(Regular Expression,简称 regex 或 regexp)是一种用于匹配字符串中字符组合的模式。在文本处理、数据清洗、网络爬虫、日志分析等领域,正则表达式都是不可或缺的利器。
Python 通过内置的 re 模块提供了对正则表达式的支持,同时也有第三方库如 regex 提供了更强大的功能。掌握正则表达式,将极大提升你处理文本数据的效率。
本文将从基础语法到高级技巧,从理论讲解到实战案例,全面介绍 Python 中正则表达式的使用方法。
二、正则表达式基础
2.1 正则表达式语法速览
普通字符与特殊字符
-
普通字符:包括大小写字母、数字、汉字等,匹配自身
-
特殊字符(元字符):具有特殊含义的字符
常用元字符

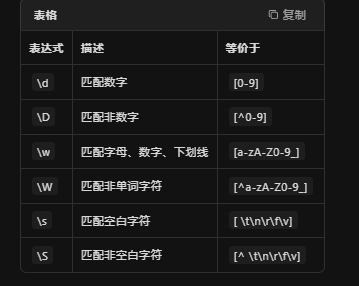
预定义字符类
2.2 Python 中的正则入口:re 模块
Python 通过 re 模块提供正则表达式功能:
import re# 查找所有数字
pattern = r"\d+"
text = "There are 123 apples and 45 oranges."
matches = re.findall(pattern, text)
print(matches) # 输出: ['123', '45']三、Python 正则核心函数详解
3.1 主要函数对比

3.2 函数详解与示例
re.match() - 从开头匹配
import repattern = r"hello"
text = "hello world"match = re.match(pattern, text)
if match:print("匹配成功:", match.group()) # 输出: hello
else:print("匹配失败")re.search() - 搜索第一个匹配
import repattern = r"world"
text = "hello world"match = re.search(pattern, text)
if match:print("找到:", match.group()) # 输出: worldre.findall() - 查找所有匹配
import re# 提取所有邮箱地址
text = "Contact us at support@example.com or sales@example.co.uk"
emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", text)
print(emails) # 输出: ['support@example.com', 'sales@example.co.uk']re.sub() - 替换文本
import re# 将日期格式从 MM/DD/YYYY 改为 YYYY-MM-DD
text = "Today is 10/24/2025"
new_text = re.sub(r"(\d{2})/(\d{2})/(\d{4})", r"\3-\1-\2", text)
print(new_text) # 输出: Today is 2025-10-24re.split() - 分割字符串
import re# 按多个分隔符分割
text = "apple,banana;orange|grape"
fruits = re.split(r"[,;|]", text)
print(fruits) # 输出: ['apple', 'banana', 'orange', 'grape']四、分组与捕获
4.1 基本分组
分组使用圆括号 () 实现,可以提取匹配的特定部分:
import re# 提取日期中的年、月、日
pattern = r"(\d{4})-(\d{2})-(\d{2})"
text = "Today is 2025-10-24"match = re.search(pattern, text)
if match:print("完整匹配:", match.group(0)) # 2025-10-24print("年:", match.group(1)) # 2025print("月:", match.group(2)) # 10print("日:", match.group(3)) # 24print("所有组:", match.groups()) # ('2025', '10', '24')4.2 命名分组
命名分组使代码更易读:
import repattern = r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})"
text = "2025-10-24"match = re.search(pattern, text)
if match:print("年:", match.group("year")) # 2025print("月:", match.group("month")) # 10print("日:", match.group("day")) # 244.3 非捕获分组
使用 (?:...) 创建非捕获分组,提高性能
import re# 匹配URL中的域名部分,但不捕获协议
pattern = r"(?:https?://)?(www\.\w+\.\w+)"
text = "Visit https://www.example.com or www.test.org"matches = re.findall(pattern, text)
print(matches) # 输出: ['www.example.com', 'www.test.org']4.4 反向引用
在同一表达式中引用之前的分组
import re# 匹配重复的单词
pattern = r"\b(\w+)\s+\1\b"
text = "This is is a test"matches = re.findall(pattern, text)
print(matches) # 输出: ['is']高级技巧
5.1 零宽断言(前瞻与后顾)
零宽断言用于匹配位置,而不是字符本身。
正向前瞻 (?=...)
import re# 匹配后面是"元"的数字
text = "这本书售价是88元,运费12元"
prices = re.findall(r"\d+(?=元)", text)
print(prices) # 输出: ['88', '12']负向前瞻 (?!...)
import re# 匹配后面不是"元"的数字
text = "88元买了12个苹果"
numbers = re.findall(r"\d+(?!元)", text)
print(numbers) # 输出: ['12']正向后顾 (?<=...)
import re# 匹配前面不是"$"的数字
text = "Price is $99 and 88 items"
numbers = re.findall(r"(?<!\$)\b\d+\b", text)
print(numbers) # 输出: ['88']负向后顾 (?<!...)
import re# 匹配前面不是"$"的数字
text = "Price is $99 and 88 items"
numbers = re.findall(r"(?<!\$)\b\d+\b", text)
print(numbers) # 输出: ['88']5.2 贪婪 vs 非贪婪匹配
import rehtml = "<div><span>text</span></div>"# 贪婪匹配
greedy = re.findall(r"<.*>", html)
print("贪婪:", greedy) # 输出: ['<div><span>text</span></div>']# 非贪婪匹配
non_greedy = re.findall(r"<.*?>", html)
print("非贪婪:", non_greedy) # 输出: ['<div>', '<span>', '</span>', '</div>']5.3 多行模式与标志
import retext = """line1 starts here
line2 starts here
line3 ends here"""# 匹配每行开头的单词
matches = re.findall(r"^\w+", text, flags=re.MULTILINE)
print(matches) # 输出: ['line1', 'line2', 'line3']六、实战案例
6.1 提取网页中的链接
import re
import requests# 获取网页内容
url = "https://example.com"
response = requests.get(url)
html = response.text# 提取所有HTTP/HTTPS链接
links = re.findall(r'href="(https?://.*?)"', html)print(f"找到 {len(links)} 个链接:")
for link in links[:5]: # 显示前5个print(link)6.2 日志分析:提取IP和状态码
import re# 示例日志行
log_line = '192.168.1.1 - - [24/Oct/2025:10:00:00 +0000] "GET /index.html HTTP/1.1" 200 512'# 提取IP和状态码
pattern = r"(\d+\.\d+\.\d+\.\d+).*?\".*?\" (\d{3})"
match = re.search(pattern, log_line)if match:ip = match.group(1)status = match.group(2)print(f"IP: {ip}, 状态码: {status}") # 输出: IP: 192.168.1.1, 状态码: 2006.3 数据清洗:提取和验证手机号
import re# 提取手机号
text = """
联系人:张三,手机号:13812345678
联系人:李四,手机号:15987654321
客服电话:400-123-4567
"""# 提取11位手机号
phones = re.findall(r"1[3-9]\d{9}", text)
print("提取的手机号:", phones)# 验证手机号格式
def validate_phone(phone):pattern = r"^1[3-9]\d{9}$"return re.match(pattern, phone) is not Noneprint("验证13812345678:", validate_phone("13812345678")) # True
print("验证12345678901:", validate_phone("12345678901")) # False6.4 密码强度验证
import redef check_password_strength(password):"""验证密码强度"""checks = {"长度至少8位": len(password) >= 8,"包含大写字母": bool(re.search(r"[A-Z]", password)),"包含小写字母": bool(re.search(r"[a-z]", password)),"包含数字": bool(re.search(r"\d", password)),"包含特殊字符": bool(re.search(r"[!@#$%^&*(),.?\":{}|<>]", password))}score = sum(checks.values())print(f"密码强度检查 (得分: {score}/5):")for check, passed in checks.items():status = "✓" if passed else "✗"print(f" {status} {check}")return score >= 4# 测试
check_password_strength("MyP@ssw0rd")总结与拓展阅读
-
从简单开始:先掌握基本匹配,再学习高级特性
-
多练习:实际项目中遇到文本处理问题,优先考虑正则
-
使用工具:利用 regex101 等工具调试复杂表达式
-
注意性能:复杂正则可能影响性能,必要时考虑其他方案
-
写注释:复杂正则表达式添加详细注释,方便维护