Dify配置本地部署的音频识别模型
1. 部署本地音频模型(speech2text)
1.1. 部署vllm
部署vllm版本082。
1.2. 下载whisper-large-v3模型文件
网址:https://modelscope.cn/models/AI-ModelScope/whisper-large-v3/files
下载命令:
modelscope download --model AI-ModelScope/whisper-large-v3 --local_dir ./whisper-large-v3
1.3 运行
CUDA_VISIBLE_DEVICES=0 vllm serve /models/whisper-large-v3 --served-model-name whisper-large-v3 --trust-remote-code --dtype bfloat16 --swap-space 16 --port 8003 --gpu-memory-utilization 0.4 --api-key sk-123456 --task transcription
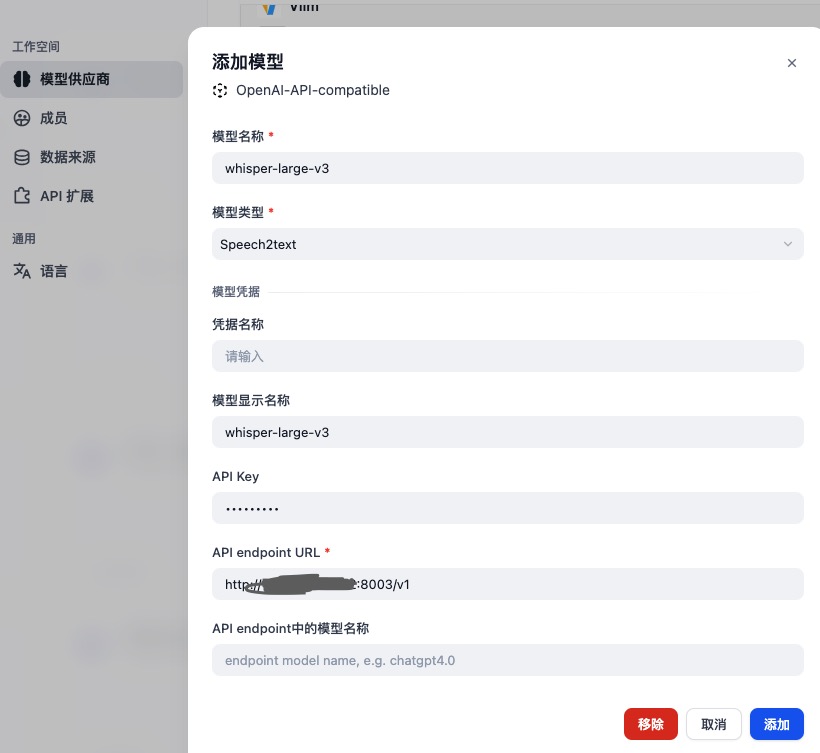
2. Dify配置本地部署的whisper-large-v3模型