Redis之String 类型入门与实战,由基础语法快速掌握再到缓存加速/验证码防刷/计数统计场景应用
文章目录
- 本篇摘要
- 一.Redis常用数据类型
- **Redis基础数据结构与底层优化**
- Redis底层实现细节与单线程模型
- 单线程模型速度高 效率快原因
- 二.Redis数据类型之string字符串
- Redis字符串类型核心要点总结
- 1.SET命令(核心字符串设置)
- SET系列其他命令
- 2.GET命令(核心字符串设置)
- 3.数值增减类命令(针对存储数字的 String)
- 4. APPEND 命令
- 5.截取与范围操作类命令
- 6.长度命令
- 其他实用场景与注意事项
- 7. Redis内部编码方式
- 8.典型使⽤场景
- 缓存
- 计数(Counter)功能
- 共享会话(Session)
- ⼿机验证码
- 三.本篇小结
本篇摘要
- Redis 提供字符串等 5 种基础数据类型,采用动态编码优化存储;单线程模型借内存与 I/O 多路复用实现高效,核心功能精简且支持丰富操作命令。

欢迎拜访: 点击进入博主主页
本篇主题: Redis数据类型+String类型详解
制作日期: 2025.10.24
隶属专栏: 点击进入所属Redis专栏
一.Redis常用数据类型
Redis基础数据结构与底层优化
- 核心数据类型
Redis提供5种基础数据结构(键值对形式),对应常见编程语言类似结构:
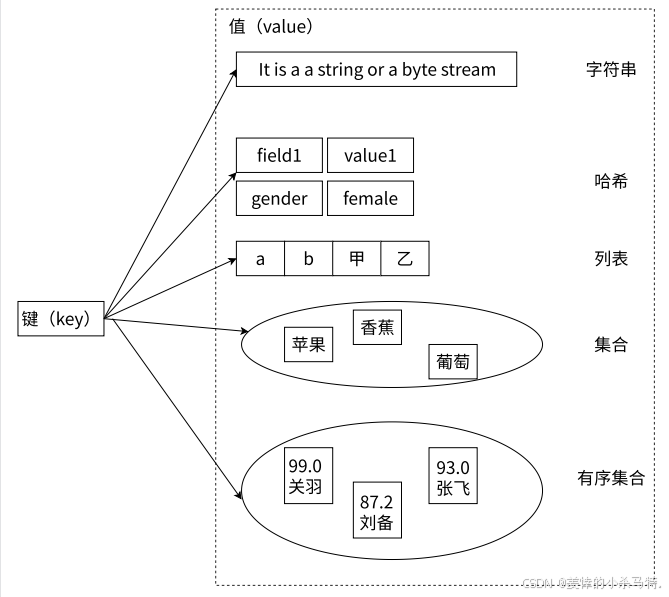
- 字符串(String):C++的字符数组,用于存储文本或数字。
- 哈希(Hash):C++的
unordered_map,存储字段-值对(如用户信息的键值集合)。 - 列表(List):C++的
deque,有序存储元素(如消息队列)。 - 集合(Set):C++的
set,无序且唯一的元素集合。 - 有序集合(Sorted Set):元素按分数排序的唯一集合。
- 底层优化机制

- 编码优化:Redis承诺提供上述数据类型接口,但底层会根据场景自动选择最优实现(用户通常无需关心)。例如:
- 哈希表在元素较少时,可能优化为**压缩列表(ziplist)**以节省空间;
- 列表元素为整数时,可能采用特殊编码减少内存占用(如int);
- 字符串长度不同时,可能选择短字符串编码(如
embstr)或长字符串编码(如raw)。
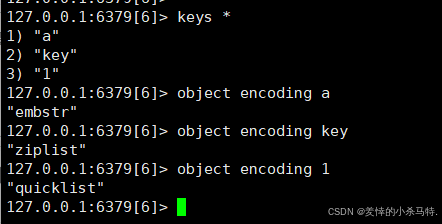
- 动态调整:通过
object encoding key命令可查看某个key对应value的完整编码方式(如ziplist、hashtable等),实际存储结构可能因数据特征变化而自动转换。
- 优化目标
核心是通过底层编码调整,在保证操作时间复杂度不变的前提下,节省存储空间和计算时间(如减少内存碎片、提升访问效率)。
Redis底层实现细节与单线程模型
-
关键数据结构扩展
- Quicklist:从Redis 3.2引入的新结构,结合双向链表与压缩列表(ziplist)优势——每个节点是一个小型的ziplist,而大链表又是个Quicklist,既保留链表的灵活插入/删除能力,又通过ziplist压缩存储提升空间效率。
- 编码转换示例:哈希对象根据元素数量和大小,可能在
ziplist(小规模)和hashtable(大规模)之间自动切换,平衡查询速度与存储成本。
-
单线程处理模型
- 核心逻辑:Redis用单个线程处理所有命令请求(虽然服务进程可能有多线程,但命令执行是单线程的),通过I/O多路复用技术(如epoll/kqueue)高效管理大量并发连接。
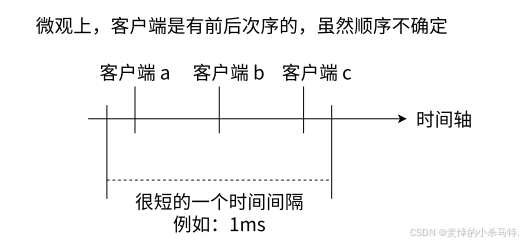
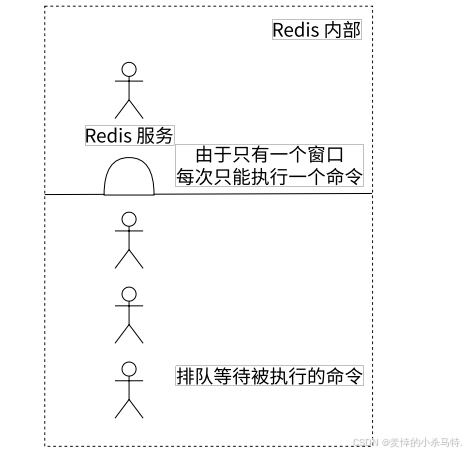
- 并发特性:多个客户端的命令操作宏观上并发执行,但微观上排队处理(类似食堂排队取餐)。若某个命令执行时间过长(如复杂计算或大key操作),会阻塞后续命令,影响整体性能。
单线程模型速度高 效率快原因
Redis访问内存,而传统数据库(如MySQL、Oracle、SQL Server)访问硬盘。内存的读写速度远快于硬盘,这是Redis性能好的硬件基础层面原因。
1. 核心功能复杂度更低:
- Redis核心功能比数据库简单。数据库需支持数据插入、删除、查询等复杂功能(如各类约束、事务机制),这些额外功能会带来性能开销;Redis“干得活少”,功能相对精简,减少了不必要的消耗。
2. 单线程模型的优势:
- 单线程避免了线程竞争带来的开销。Redis基本操作是“短平快”的内存数据操作,并非高CPU消耗型任务。即便改用多线程,也难大幅提升性能,反而可能因线程切换、竞争等增加额外开销,因此单线程更高效。
3.IO多路复用机制(处理网络IO的核心)
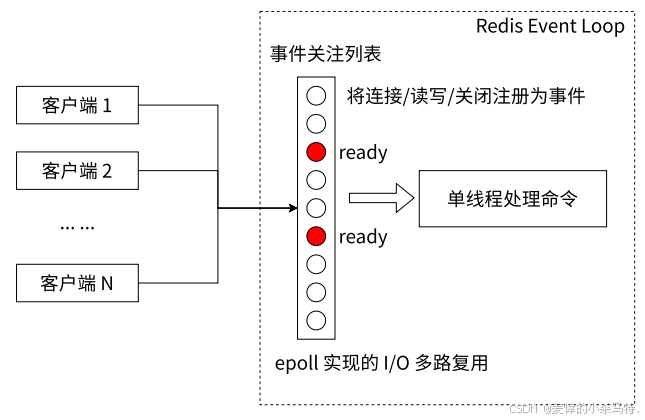
- 原理:Redis用
epoll实现IO多路复用,一个线程可管理多个socket。 - TCP场景示例:服务器为每个客户端分配socket,服务大量客户端时socket众多,但多数socket并非时刻传输数据(大部分时间“静默”)。
- 多路复用的价值:同一时刻仅少数socket活跃,IO多路复用让单线程就能高效处理多个socket,无需为每个socket开线程,极大提升IO效率。
简言之,Redis单线程高效的核心是内存存储、功能精简、单线程避竞争、IO多路复用这几个因素共同作用的结果。
二.Redis数据类型之string字符串
Redis字符串类型核心要点总结
-
基础地位
- 字符串是Redis最基础的数据类型,所有键的类型均为字符串。
- 其他四种数据结构(哈希、列表、集合、有序集合)均基于字符串构建,例如它们的元素或值本质也是字符串类型,因此掌握字符串类型是学习其他数据结构的基础。
-
值的多样性
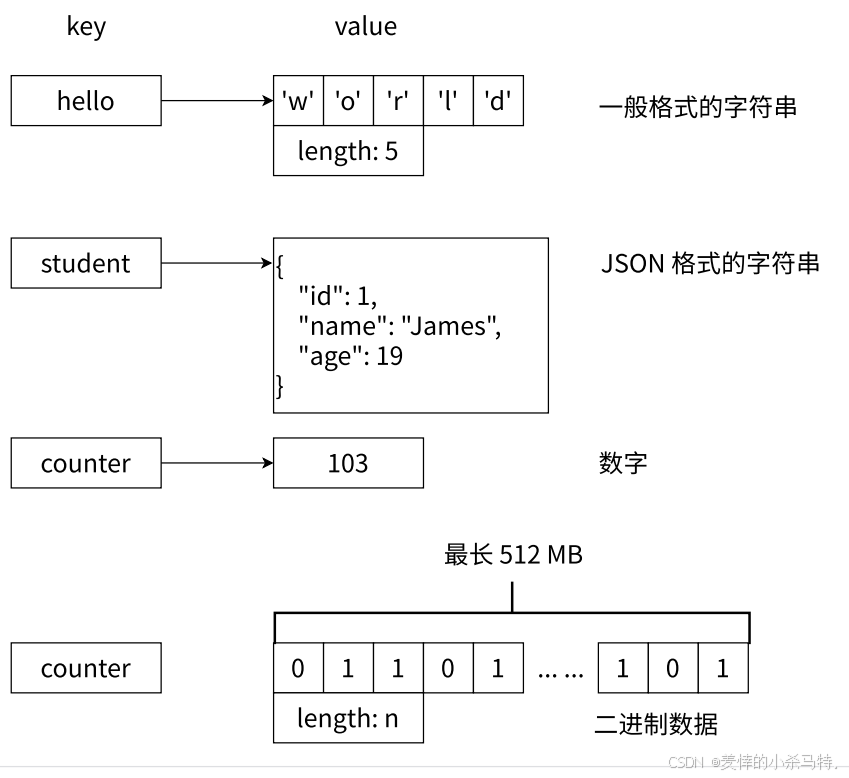
- 字符串类型的值支持多种格式:
- 普通字符串:常规文本或类似JSON、XML的结构化字符串。
- 数字类型:包括整型和浮点型(如计数器场景)。
- 二进制流数据:支持图片、音频、视频等任意二进制内容。
- 单值大小限制:单个字符串值的最大容量为 512MB。
- 字符串类型的值支持多种格式:
-
二进制安全存储
- Redis内部直接按二进制流形式存储字符串,不处理字符集编码问题。
- 客户端传入命令时使用何种字符编码(如UTF-8、GBK等),Redis就原样存储该编码,不做任何转换或校验(就比如我们输入汉字默认就是16进制编码)。
如:
1.SET命令(核心字符串设置)
-
功能
- 将字符串类型的value设置到指定的key中;若key已存在,则覆盖原有值(无论原数据类型是什么),且原key的TTL(生存时间)会失效。
- 若key不存在,则创建新的键值对。
-
基础语法
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]- 必选参数:
key(键名)、value(值,字符串类型)。 - 可选参数:通过选项控制行为和过期时间。
- 必选参数:
-
有效版本:Redis 1.0.0 及以上版本支持。
-
时间复杂度:O(1)(单次操作效率高)。
-
选项说明
- 过期时间设置:
EX seconds:以秒为单位设置key的过期时间(如EX 60表示60秒后过期)。PX milliseconds:以毫秒为单位设置key的过期时间(如PX 5000表示5000毫秒/5秒后过期)。- 条件设置:
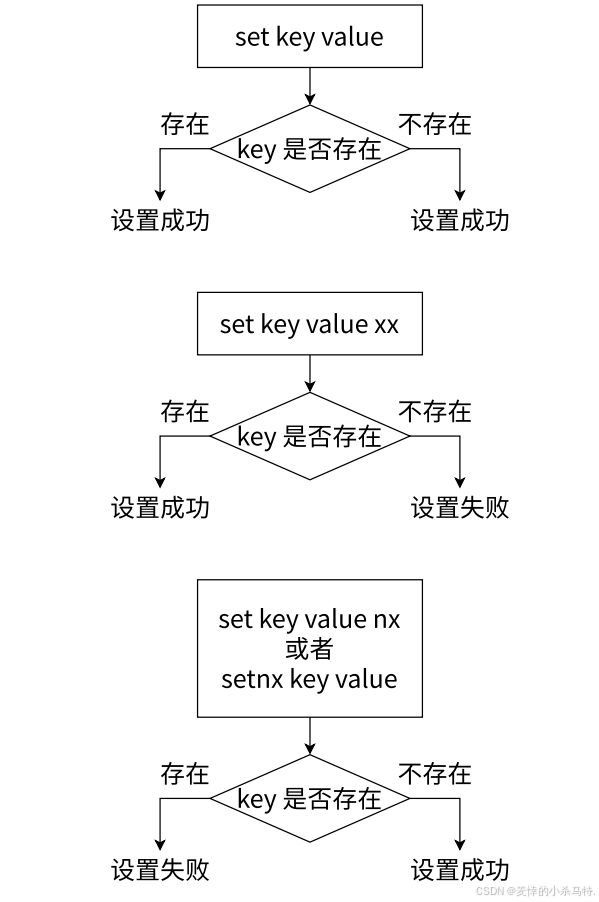
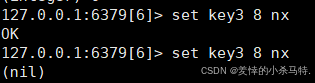
NX:仅当key不存在时才执行设置操作(若key已存在,则不执行,返回(nil))。

XX:仅当key存在时才执行设置操作(若key不存在,则不执行,返回(nil))。
- 注意事项
- 带选项的SET命令功能可被其他命令替代(如
SETNX替代NX、SETEX替代EX),未来Redis版本可能合并相关命令。 - 若通过选项设置条件(如
NX/XX)但条件不满足,SET不会执行,返回(nil);若设置成功,返回OK。
- 带选项的SET命令功能可被其他命令替代(如
SET系列其他命令
-
SETNX(仅当key不存在时设置)
- 功能:当key不存在时,设置键值对;若key已存在,则不执行任何操作(相当于
SET key value NX)。 - 语法:
SETNX key value - 返回值:设置成功返回
1,key已存在未执行则返回0。
- 功能:当key不存在时,设置键值对;若key已存在,则不执行任何操作(相当于
-
SETEX(设置值并指定秒级过期时间)
- 功能:设置key的字符串值,并同时设置过期时间(单位:秒)。
- 语法:
SETEX key seconds value - 等价于:
SET key value EX seconds。
-
SETPX(设置值并指定毫秒级过期时间)(也可以是PSETEX)
- 功能:设置key的字符串值,并同时设置过期时间(单位:毫秒)。
- 语法:
SETPX key milliseconds value - 等价于:
SET key value PX milliseconds。
-
SETXX(仅当key存在时设置)
- 功能:当key存在时,设置键值对;若key不存在,则不执行任何操作(相当于
SET key value XX)。 - 语法:
SETXX key value - 返回值:设置成功返回
OK,key不存在未执行则返回(nil)。 - 说明:
SETXX是通过SET key value XX实现的显式命令形式(与NX对应),用于确保仅更新已存在的键,避免误创建新键。
- 功能:当key存在时,设置键值对;若key不存在,则不执行任何操作(相当于
-
MSET(批量设置多个键值对)

- 功能:一次性设置多组键值对,提升操作效率,减少网络开销。
- 语法:
MSET key1 value1 key2 value2 ... - 时间复杂度:O(N)(N为当前命令中的key数量,通常视为O(1),因N仅针对本次命令的key数)。
- 示例:
# 批量设置多个键值对(如用户信息) MSET user:1:name "Alice" user:1:age 25 user:1:role "admin" - 对比优势:相比多次执行
SET(需多次网络请求),MSET通过单次请求完成批量操作,显著降低延迟。
2.GET命令(核心字符串设置)
-
GET命令(获取字符串值)
- 功能:获取指定key的字符串类型值;若key不存在或值非字符串类型,则报错。
- 限制:仅支持字符串类型的value(如key对应的值是哈希、列表等,使用GET会返回类型错误)。
-
MGET(批量获取多个键的值):
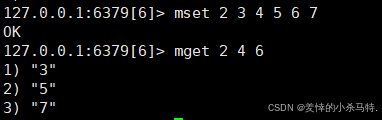
- 语法:
MGET key1 key2 ... - 功能:一次性获取多个key对应的字符串值,减少网络开销。
- n次GET vs 单次MGET效率对比
- n次GET:客户端需多次发送请求/接收响应,网络开销大(每次get命令单独执行)。
- 单次MGET:客户端一次性发送请求,服务端批量处理后返回所有结果,网络开销小、效率更高(如图中流程所示)。
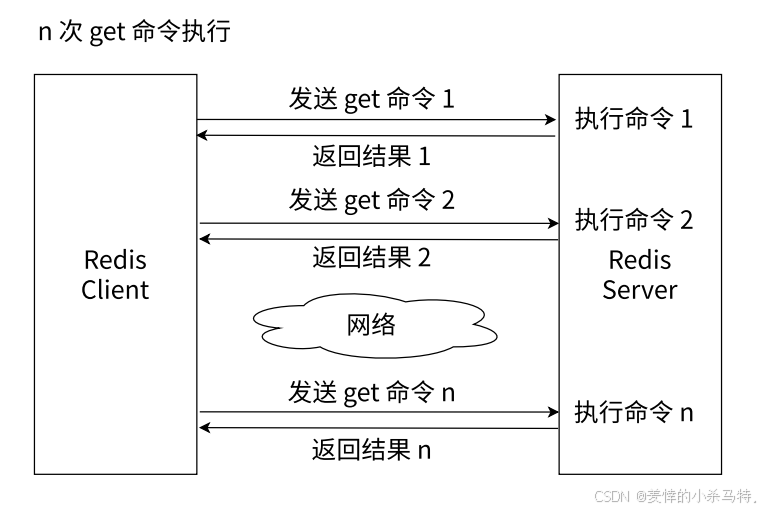
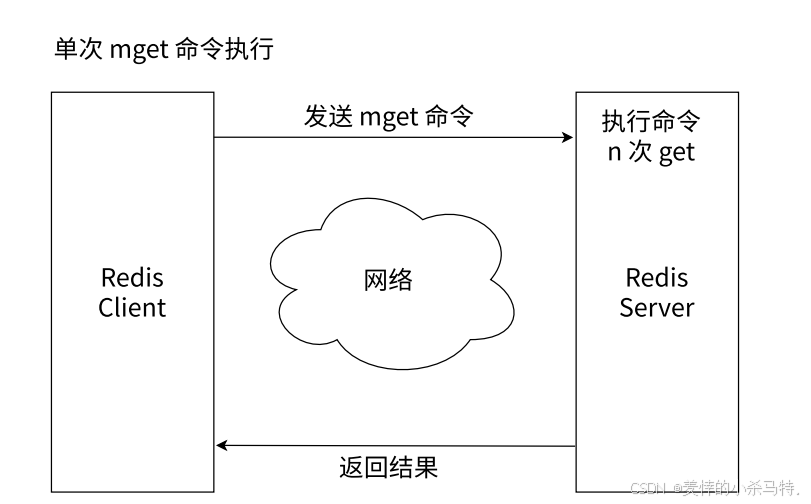
- 学会使⽤批量操作,可以有效提⾼业务处理效率,但是要注意,每次批量操作所发送的键的数量也不是⽆节制的,否则可能造成单⼀命令执⾏时间过⻓,导致Redis阻塞。
注意:高危操作警告(FLUSHALL)
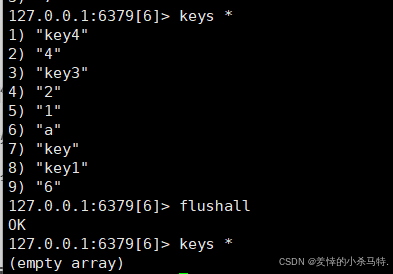
- 功能:清空Redis中所有键值对(类似数据库的
DROP DATABASE)。 - 风险:生产环境使用会导致数据全部丢失,务必谨慎!
- 提示:
FLUSHALL是一个快速但危险的命令,会清除Redis上所有的数据,就像删除MySQL中的整个数据库一样。
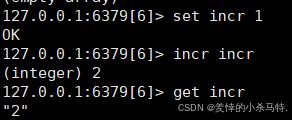
3.数值增减类命令(针对存储数字的 String)
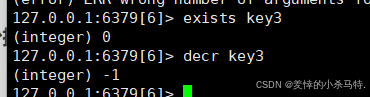
- INCR key(可加负等于DECR key)
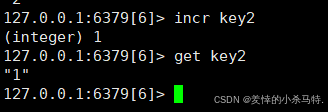
如果减不存在就从0开始:
- 作用:将
key中存储的数字值 原子性递增 1。若key不存在,先初始化为0再递增。 - 要求:
key对应的值必须是整数(或可转为整数的字符串),否则报错。
- DECR key
- 作用:将
key中存储的数字值 原子性递减 1。逻辑同INCR,只是方向相反。
- INCRBY key increment(可加负等于ECRBY key decrement)
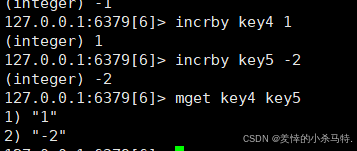
- 作用:将
key对应的数字值 原子性增加指定的increment(可以是正/负整数)。 - 示例:
INCRBY counter 5让counter的值 +5;INCRBY views -2则是 -2。
-
DECRBY key decrement
- 作用:将
key对应的数字值 原子性减少指定的decrement,逻辑与INCRBY对应递减场景。
- 作用:将
-
INCRBYFLOAT key increment(可加正可加负,无DECRBYFLOAT)
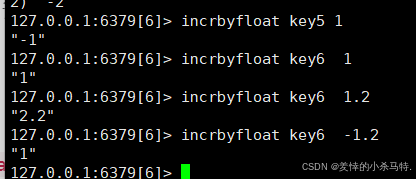
- 作用:将
key对应的数字值 原子性增加指定的浮点数increment(支持小数),逻辑与INCRBY对应浮点数递增场景。若key不存在,先初始化为0再执行增加操作。 - 要求:
key对应的值必须是数字(整数或浮点数,或可转为数字的字符串),否则报错。 - 示例:
INCRBYFLOAT price 1.5将price的值增加 1.5(如原值为 10.0,则变为 11.5);INCRBYFLOAT score 0.1可用于精确分数累计。

(**说明:**与 INCRBY 仅支持整数增减不同,INCRBYFLOAT 专为浮点数设计,适用于需要小数精度的场景,如价格计算、评分累加等;当然了都是有对应操作范围的,不能无限进行操作(incrbyfloat行但是incby不行(2的64位))。)
4. APPEND 命令
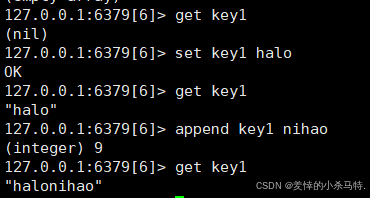
- 作用:如果
key已存在且是字符串,就把value追加到原值的末尾;若key不存在,则等同于SET key value。 - 返回值:追加后字符串的总长度。
- 示例:
SET greeting "Hello"→APPEND greeting " World!"后,greeting变为 “Hello World!”,返回 12。
5.截取与范围操作类命令
- GETRANGE key start end

- 作用:返回
key对应字符串值中,从start到end(包含两端)的子字符串。 - 索引规则:和大多数编程语言类似,
0表示第一个字符;负数表示从末尾开始(如-1是最后一个字符)。 - 示例:
SET sentence "Redis is awesome"→GETRANGE sentence 0 4返回 “Redis”;GETRANGE sentence -7 -1返回 “esome”。
- SETRANGE key offset value

- 作用:从
key对应字符串的offset位置开始,用value覆盖后续字符;若offset超出原长度,原字符串会被“填充”(用\x00补齐到offset位置后再覆盖)。 - 注意:
offset必须 ≥ 0;若key不存在,会先创建一个空字符串再操作。 - 示例:
SET hello "world"→SETRANGE hello 1 "ello"后,hello变为 “wello”(原第 1 位o被覆盖,后面也跟着改了)。
6.长度命令
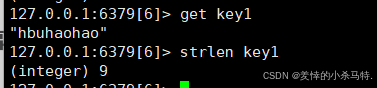
STRLEN key
- 作用:返回
key对应字符串值的 字节长度(注意:对非 ASCII 字符,如中文,一个汉字可能占 3 字节,需留意编码影响)。 - 示例:
SET name "张三"→ 若 UTF-8 编码下每个汉字 3 字节,STRLEN name可能返回 6。
其他实用场景与注意事项
-
原子性与并发安全
Redis 的 INCR/DECR 等操作是单线程 + 原子性执行,所以在高并发下计数、库存扣减等场景可以直接用,无需额外加锁。 -
String 的“二进制安全”与编码
这里比如我们放入汉字看看会咋样:
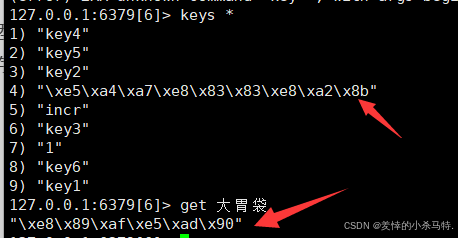
发现是16进制的存储方式(utf8一个汉字3个字节),我们只需要给它启动的时候--raw(保持原态)一下:
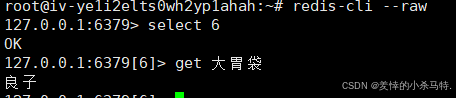
当我们截取的时候会遇到问题,这里还是都按照三字节截取吧:
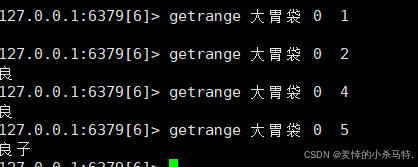
Redis String 是二进制安全的,可以存储任意二进制数据(如图片、序列化对象等);但如果是文本,要注意编码(UTF-8 等)对长度、截取的影响。
- 过期时间配合
很多时候会给 String 类型的 key 设置过期时间(如EXPIRE key seconds),常用于缓存、限流令牌等场景。
4.对应表格
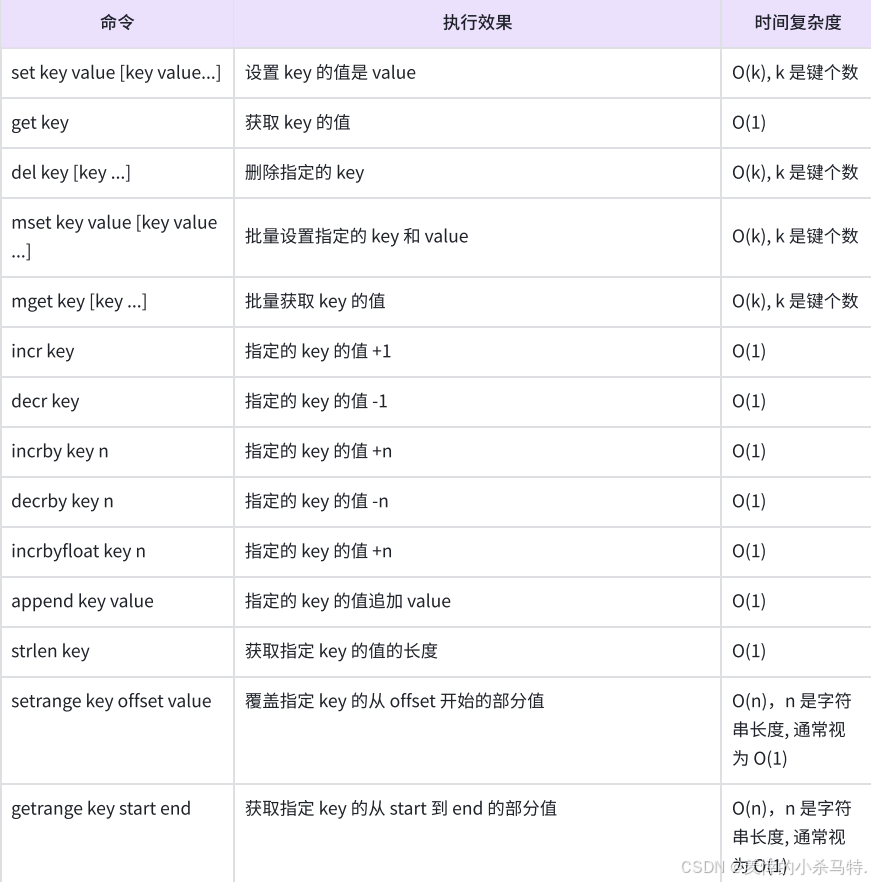
7. Redis内部编码方式
字符串类型的内部编码有3种:
- int:8个字节的⻓整型。
- embstr:⼩于等于39个字节的字符串。
- raw:⼤于39个字节的字符串。
Redis会根据当前值的类型和⻓度动态决定使⽤哪种内部编码实现。
如下:

8.典型使⽤场景
典型应用场景包括高频数据缓存、会话管理和计数器功能。
缓存
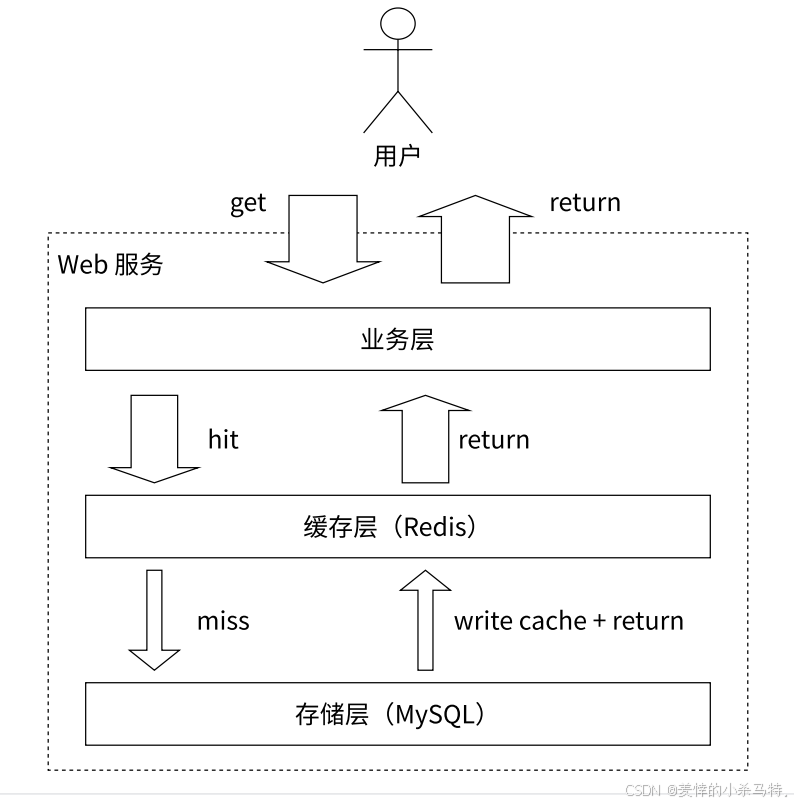
-
用户请求首先到达Web服务层。
-
高频/临时数据优先从Redis缓存层读取,大幅提升响应速度。
-
缓存未命中时,回源至MySQL持久化存储查询,并将结果回填至Redis。
-
通过精心设计的缓存更新策略(如失效策略、双删策略)确保数据的最终一致性。
具体做法:
- 业务假设:根据用户uid获取用户信息。
- 从Redis获取信息:根据uid生成Redis键“user:info:”,尝试从Redis中获取对应的值。若缓存命中(value不为null),将获取到的JSON格式值反序列化为UserInfo对象并返回。
- 从MySQL获取信息:若Redis缓存未命中(value为null),从MySQL数据库中根据uid查询用户信息。若数据库中也不存在该uid对应的用户信息,返回404;若存在,将查询到的UserInfo对象序列化为JSON格式,写入Redis缓存并设置过期时间为1小时(3600秒),然后返回该用户信息。
计数(Counter)功能
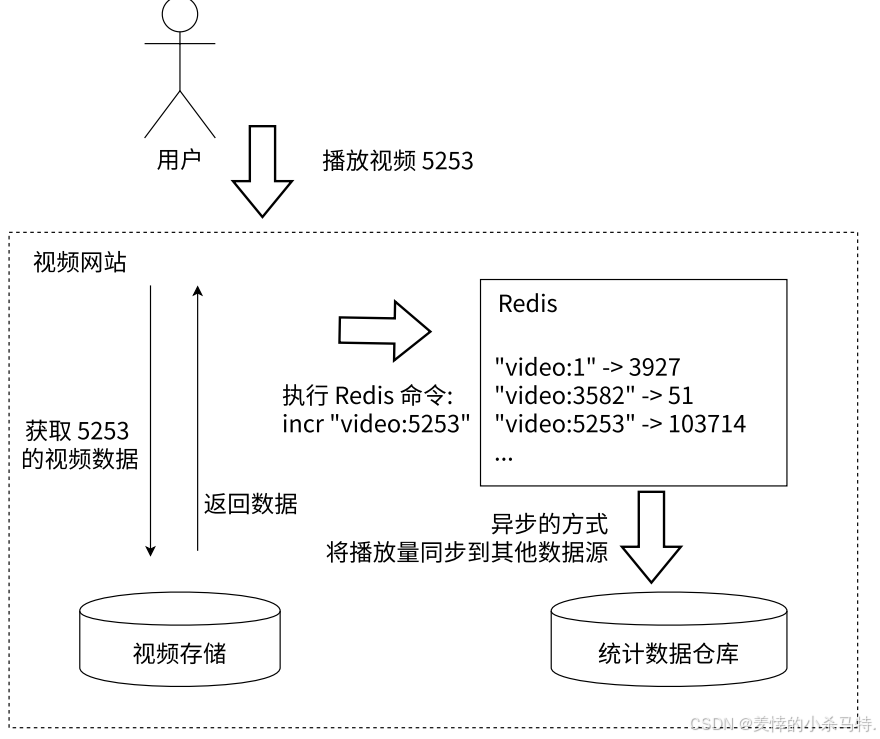
- 用户播放视频后,视频网站获取视频数据,同时执行Redis的incr命令增加对应视频播放计数,之后以异步方式将播放量同步到统计数据仓库。
共享会话(Session)
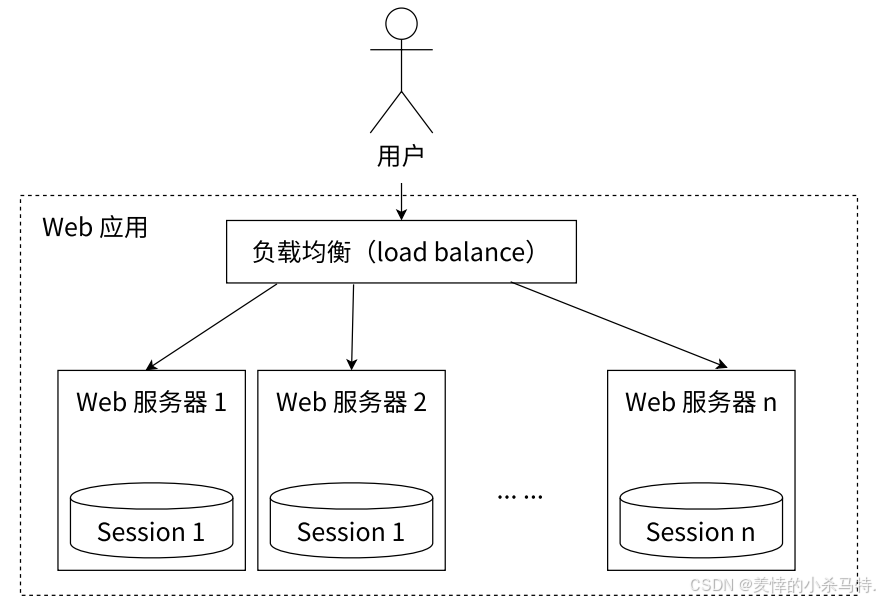
-
Session分散存储问题:在分布式Web服务中,用户Session信息(如登录信息)保存在各自服务器。但因负载均衡,用户请求可能被分配到不同服务器,无法保证每次请求都在同一台,导致用户刷新访问时可能需重新登录,影响体验。
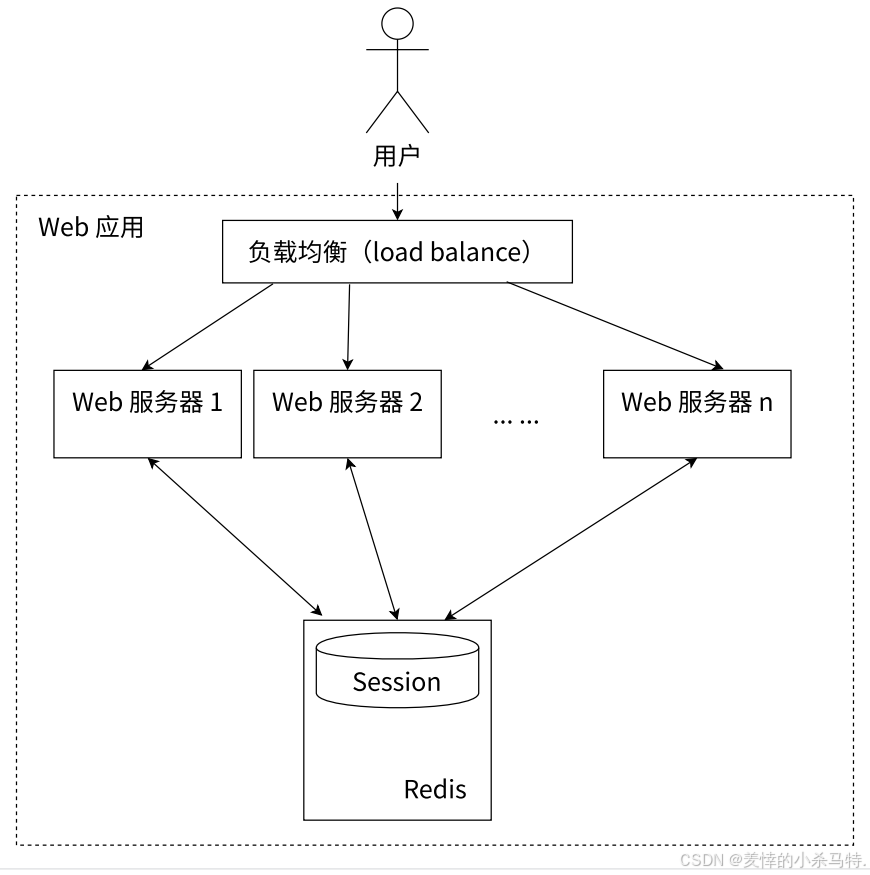
-
Redis集中管理Session方案:使用Redis集中管理用户Session信息,只要保证Redis高可用和可扩展性,无论用户请求被负载均衡到哪台Web服务器,都能从Redis查询、更新Session信息,解决上述问题。
⼿机验证码

一分钟失效原理
当把验证码存到 Redis 时,同时给这个数据设置一个 60 秒(一分钟)的过期时间。用 SET 命令加 EX 参数就能实现,比如 SET 验证码键 手机验证码值 EX 60。时间一到,Redis 就会自动把这个验证码数据从内存里删掉,之后再查就查不到了,也就失效了。
一分钟不得超过 5 次原理
用 Redis 的计数功能,以手机号等能标识用户的信息作为键。每次用户请求验证码,就用 INCR 命令让这个键对应的数字加 1,代表请求次数加 1。同时给这个键设置 60 秒过期时间,比如用 EXPIRE 命令。每次请求时,先 INCR 加 1,再用 GET 命令看看当前数字。要是数字大于 5,就说明一分钟请求超 5 次了,拒绝请求;小于等于 5 就正常处理。等一分钟过了,Redis 自动删掉这个键,下次请求又重新开始计数。
过程如下(伪代码):
String 发送验证码(phoneNumber) {String key = "shortMsg:limit:" + phoneNumber;// 设置过期时间为1分钟 (60秒)// 使用 NX, 只在不存在 key 时才能设置成功boolean r = Redis 执行命令: set key 1 ex 60 nx;if (r == false) {// 说明之前设置过该手机的验证码了long c = Redis 执行命令: incr key;if (c > 5) {// 说明超过了一分钟5次的限制了// 限制发送return null;}}// 说明要么之前没有设置过手机的验证码; 要么次数没有超过5次String validationCode = 生成随机的6位数的验证码();String validationKey = "validation:" + phoneNumber;// 验证码5分钟 (300秒) 内有效Redis 执行命令: set validationKey validationCode ex 300;// 返回验证码, 随后通过手机短信发送给用户return validationCode;
}// 验证用户输入的验证码是否正确
boolean 验证验证码(phoneNumber, validationCode) {String validationKey = "validation:" + phoneNumber;String value = Redis 执行命令: get validationKey;if (value == null) {// 说明没有这个手机的验证码记录, 验证失败return false;}if (value == validationCode) {return true;} else {return false;}
}
请记住:
技术是工具,业务是目标——好方案既要懂技术实现,更要理解业务需求(甚至通过优化业务解决技术瓶颈)。
三.本篇小结
本文围绕Redis核心功能展开,首先介绍了其五大基础数据类型(字符串、哈希、列表、集合、有序集合)及底层优化机制(如编码自适应调整、Quicklist结构等),重点讲解了单线程模型的高效原理(内存存储、I/O多路复用、避免线程竞争)。随后深入解析字符串类型的核心操作(SET/GET/MSET、数值增减、追加截取等)、内部编码(int/embstr/raw)及典型应用场景(缓存加速、计数器、分布式Session、手机验证码防刷)。通过伪代码示例演示了验证码“一分钟失效+限次5次”的实战逻辑,并强调“技术需服务于业务需求”的核心思想——理解业务场景才能设计出高效合理的技术方案。