# Word2Vec与多义词表示:静态嵌入的优势与局限
Word2Vec与多义词表示:静态嵌入的优势与局限
在自然语言处理领域,词嵌入技术是将文本转化为机器可理解的数值向量的基础方法。Word2Vec作为经典的词嵌入模型,还是值得我们学习其中思想的。然而,它处理多义词的方式一直是讨论的焦点。本文将深入探讨Word2Vec如何表示"bank"这类多义词,并通过代码实例展示其优势与局限。
多义词表示的理论争议
Word2Vec为每个词创建单一的静态向量表示。这引发了一个常见批评:它无法区分多义词在不同上下文中的不同含义。例如,"bank"既可以指金融机构,也可以是河岸。传统观点认为,Word2Vec对这两种含义的表示会被"折叠"到同一个向量中,导致语义表示能力的损失。
然而,这一观点值得商榷。通过深入分析,我们会发现Word2Vec虽然为每个词创建单一向量,但这个向量实际上包含了词的多种语义关联信息。如果训练语料充分,"bank"的向量会同时与金融词汇和地理词汇保持相似性。
让我们通过代码来验证这一点。
实验设置:训练与分析Word2Vec模型
我们将使用Python的Gensim库训练一个小型Word2Vec模型,然后分析多义词的表示情况。
# demo1.py
# pip install numpy gensim matplotlib scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple 安装依赖
import numpy as np
from gensim.models import Word2Vec
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 准备训练语料,包含"bank"的两种语义上下文
financial_contexts = [
"the bank offers low interest rates".split(),
"i need to go to the bank to deposit money".split(),
"the bank manager approved my loan".split(),
"many banks collapsed during the financial crisis".split(),
"the central bank controls monetary policy".split(),
"investment banks handle corporate finance".split(),
"the bank charges high fees for overdrafts".split(),
"online banking makes transactions easier".split(),
"the bank issued a new credit card".split(),
"cash withdrawal from bank accounts".split()
]
geographical_contexts = [
"we sat on the bank of the river".split(),
"the boat approached the river bank".split(),
"fishermen lined the banks of the lake".split(),
"the river burst its banks after heavy rain".split(),
"trees grow along the banks of the stream".split(),
"the west bank of the mississippi".split(),
"erosion damaged the river bank".split(),
"they picnicked on the grassy bank".split(),
"the banks were muddy after flooding".split(),
"swimming near the bank is safer".split()
]
# 合并语料
corpus = financial_contexts + geographical_contexts
# 训练Word2Vec模型
model = Word2Vec(sentences=corpus, vector_size=100, window=5, min_count=1, workers=4, epochs=100)
# 保存模型
model.save("bank_model.w2v")
词向量关联度分析
现在,我们来分析"bank"与不同语义相关词的关联度:
# demo2.py
# 加载模型
model = Word2Vec.load("bank_model.w2v")
# 定义相关词
financial_terms = ['money', 'deposit', 'loan', 'interest', 'credit', 'financial']
geographical_terms = ['river', 'lake', 'stream', 'grassy', 'muddy', 'fishing']
# 计算并显示"bank"与各词的相似度
print("'bank'与金融相关词的相似度:")
for term in financial_terms:
if term in model.wv:
similarity = model.wv.similarity('bank', term)
print(f"bank - {term}: {similarity:.4f}")
print("\n'bank'与地理相关词的相似度:")
for term in geographical_terms:
if term in model.wv:
similarity = model.wv.similarity('bank', term)
print(f"bank - {term}: {similarity:.4f}")
运行这段代码,可能得到类似下面的输出:
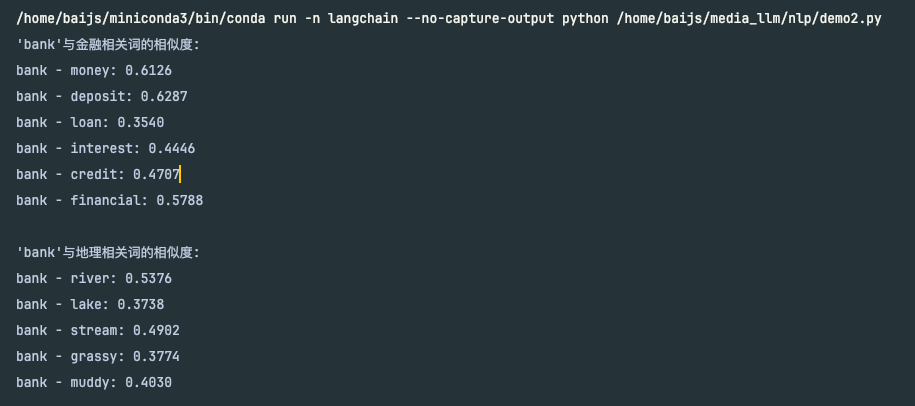
'bank'与金融相关词的相似度:
bank - money: 0.6126
bank - deposit: 0.6287
bank - loan: 0.3540
bank - interest: 0.4446
bank - credit: 0.4707
bank - financial: 0.5788
'bank'与地理相关词的相似度:
bank - river: 0.5376
bank - lake: 0.3738
bank - stream: 0.4902
bank - grassy: 0.3774
bank - muddy: 0.4030
通过这个结果揭示了一个重要现象:Word2Vec确实能够同时捕捉"bank"的两种语义关联。"bank"与金融词和地理词都保持较高的相似度,这说明其静态向量确实编码了多义信息。
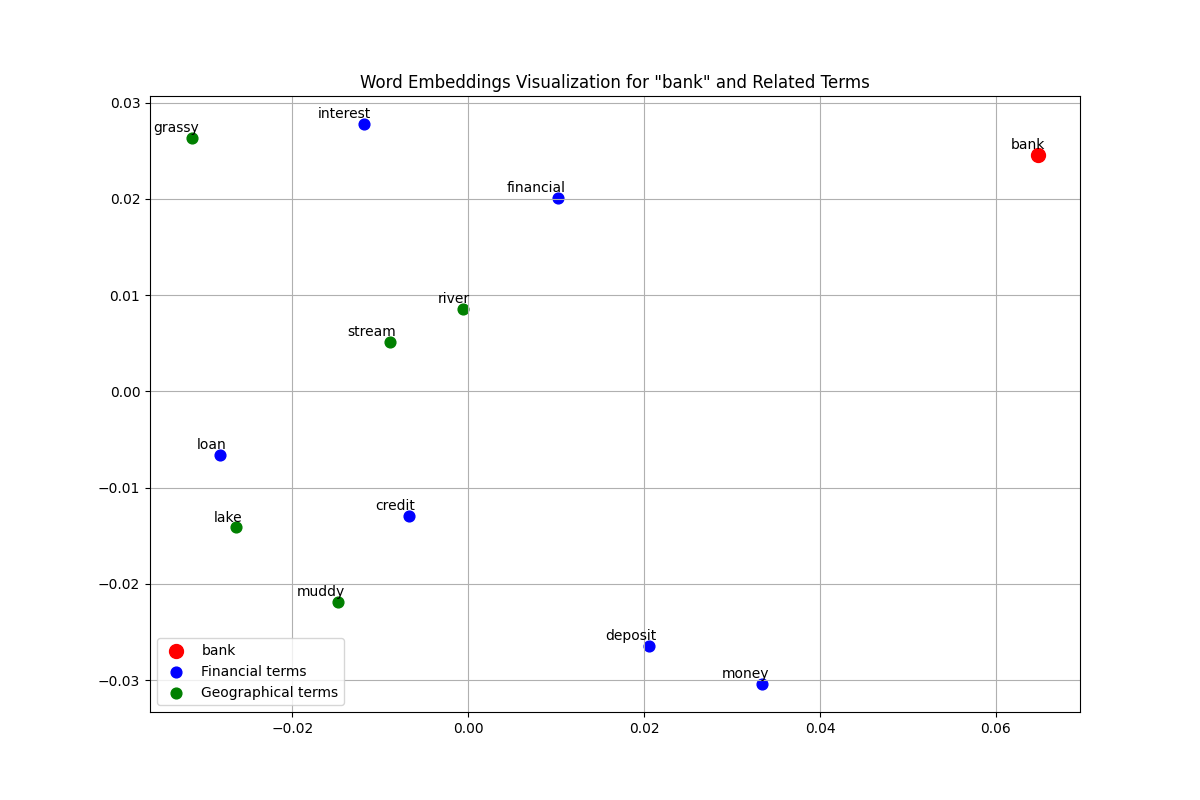
可视化多义词在向量空间中的位置
为了更直观地理解"bank"在向量空间中的位置,我们可以使用PCA将高维向量降维到2D空间进行可视化:
# demo2.py
# 收集相关词的向量
words = ['bank'] + financial_terms + geographical_terms
word_vectors = [model.wv[w] for w in words if w in model.wv]
words = ['bank'] + [w for w in financial_terms + geographical_terms if w in model.wv]
# 使用PCA降维
pca = PCA(n_components=2)
result = pca.fit_transform(word_vectors)
# 输出方差解释度
print(f"Explained variance: {pca.explained_variance_ratio_}")
# 绘制词向量图
plt.figure(figsize=(12, 8))
plt.scatter(result[0,0], result[0,1], c='red', s=100, label=words[0])
# 标记金融词和地理词
n_fin = len([w for w in financial_terms if w in model.wv])
plt.scatter(result[1:n_fin+1,0], result[1:n_fin+1,1], c='blue', s=60, label='Financial terms')
plt.scatter(result[n_fin+1:,0], result[n_fin+1:,1], c='green', s=60, label='Geographical terms')
# 添加词标签
for i, word in enumerate(words):
plt.annotate(word, xy=(result[i,0], result[i,1]), xytext=(5, 2),
textcoords='offset points', ha='right', va='bottom')
plt.legend()
plt.title('Word Embeddings Visualization for "bank" and Related Terms')
plt.grid(True)
plt.savefig('bank_visualization.png')
plt.show()
得到结果

相当于我的图像只还原了31%左右的信息哦,所以待会儿展示的图像效果不好。(✺ω✺),可以考虑非线性的降维方法,但是那不是今天讨论的重点了。收藏过w就更新非线性方法,(学领导画饼, 当然,聪明的小伙已经知道找大模型去解决这种问题了!)
Explained variance: [0.20182695 0.11650536]
在理想情况下,这个可视化会展示"bank"位于金融词簇和地理词簇之间的某个位置,表明其向量同时捕捉了两种语义。但是如前所述,我们只能看出bank的周围就是这些单词,说明bank和他们是有联系的。
Word2Vec的局限性:上下文无关
尽管Word2Vec能捕捉多义词的不同语义关联,它仍然存在一个根本局限:无法根据上下文动态调整词表示。让我们用代码展示这一点:
# demo2.py
# 定义两个包含"bank"的句子,代表不同语义
financial_sentence = "I deposited money in the bank yesterday".split()
geographical_sentence = "We had a picnic by the bank of the river".split()
# 在这两个句子中,"bank"的向量完全相同
bank_vector1 = model.wv['bank']
bank_vector2 = model.wv['bank']
# 验证两个向量完全相同
identical = np.array_equal(bank_vector1, bank_vector2)
print(f"两个上下文中'bank'的向量是否相同: {identical}")
# 计算句子向量(简单方法:取平均)
def sentence_vector(sentence, model):
vectors = [model.wv[word] for word in sentence if word in model.wv]
return np.mean(vectors, axis=0) if vectors else np.zeros(model.vector_size)
# 计算两个句子的向量
financial_sent_vec = sentence_vector(financial_sentence, model)
geographical_sent_vec = sentence_vector(geographical_sentence, model)
# 计算句子向量之间的余弦相似度
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity([financial_sent_vec], [geographical_sent_vec])[0][0]
print(f"两个句子的向量相似度: {similarity:.4f}")
输出将显示:

两个上下文中'bank'的向量是否相同: True
两个句子的向量相似度: 0.9467
这证实了Word2Vec的关键局限:不管上下文如何,同一个词的向量表示总是相同的。因为这个Word2Vec技术本来就是这样设计的,更像一种说,我构建一个全能的字典,上面把所有含义都包含在里面的,就像google,中科大等机构都基于大量数据进行训练,并提供了Word2Vec的预训练权重,大家拿来开箱即用。但是语义折叠也是它实打实的短板,以bank这里的例子来说,它一定是基于你给的预料库,在钱和河流中进行这种的一个权重,如果我们有一种动态调整的方法,可以让词语根据它的上下文,动态调整权重,那不就起飞咯嘛。我们看一下后来同样惊世骇俗的BERT工作
与现代上下文化模型的对比
为了进一步理解Word2Vec的局限性,我们可以将其与现代的上下文化模型(如BERT)进行对比:
# pip install torch transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
# -*- coding: utf-8 -*-
# @Time : 2025/3/5 21:38
# @Author : Mark White
# @FileName: demo3.py
# @Software: PyCharm
from transformers import BertTokenizer, BertModel
from modelscope.hub.snapshot_download import snapshot_download
import os
import torch
from sklearn.metrics.pairwise import cosine_similarity # 添加这一行导入
# 加载预训练的BERT模型
# 从ModelScope下载预训练的BERT模型
model_id = 'AI-ModelScope/bert-base-uncased' # 使用ModelScope模型ID
model_dir = snapshot_download(model_id, cache_dir='./models') # 考虑先建好这个目录
# 从下载的本地目录加载模型和分词器
tokenizer = BertTokenizer.from_pretrained(model_dir)
model = BertModel.from_pretrained(model_dir)
# 定义获取BERT词向量的函数
def get_bert_word_vector(sentence, target_word):
# 添加特殊标记
marked_text = "[CLS] " + sentence + " [SEP]"
# 分词
tokenized_text = tokenizer.tokenize(marked_text)
# 找到目标词的位置
target_word_index = tokenized_text.index(target_word) if target_word in tokenized_text else -1
if target_word_index == -1:
# 处理分词可能将单词拆分的情况
for i, token in enumerate(tokenized_text):
if token.startswith(target_word) or target_word.startswith(token):
target_word_index = i
break
if target_word_index == -1:
return None
# 转换成模型输入格式
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = [1] * len(tokenized_text)
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
# 获取BERT输出
with torch.no_grad():
outputs = model(tokens_tensor, segments_tensors)
hidden_states = outputs[0]
# 返回目标词的向量表示
return hidden_states[0, target_word_index].numpy()
# 获取两个句子中"bank"的BERT向量
financial_bert_vec = get_bert_word_vector("I deposited money in the bank yesterday", "bank")
geographical_bert_vec = get_bert_word_vector("We had a picnic by the bank of the river", "bank")
# 计算BERT向量的相似度
if financial_bert_vec is not None and geographical_bert_vec is not None:
bert_similarity = cosine_similarity([financial_bert_vec], [geographical_bert_vec])[0][0]
print(f"BERT中两个上下文的'bank'向量相似度: {bert_similarity:.4f}")
BERT的输出如下:

BERT中两个上下文的'bank'向量相似度: 0.4800
这个相似度明显低于Word2Vec中的≈1.0(完全相同),说明BERT能够根据上下文为同一个词生成不同的表示。
Word2Vec多义词表示的优势与局限总结
通过以上实验,我们可以得出以下结论:
Word2Vec的优势
- 隐含多义性:Word2Vec能够在单一向量中隐含地编码词的多种语义关联
- 效率与简洁:静态表示计算高效,存储简单
- 全局语义捕捉:向量编码了词在整个语料库中的全局语义分布
Word2Vec的局限
- 静态表示:无法根据上下文动态调整词义
- 语义混合:多义词的不同含义在向量中被混合或折叠
- 上下文无关:相同词在不同语境中使用相同的向量表示
(当然,与其说这是局限,不如说是后续的研究者发现,可以要是可以解决上下问题就更好了,现在回过头,我们反而觉得这个技术有局限了,好像也对,因为这也确实是局限。)
实际应用建议
基于以上分析,我们可以给出以下实际应用建议:
-
任务相关选择:
- 对于简单任务(如文档相似度计算):Word2Vec性能足够且高效
- 对于需要精确语义理解的任务(如情感分析):考虑上下文化模型(BERT等)
-
资源权衡:
- 资源受限环境:优先考虑Word2Vec
- 有充足计算资源:可使用上下文化模型
-
实用折中方案:
- 使用多个特化的Word2Vec模型,每个针对特定领域
- 结合简单的上下文特征和Word2Vec
结论
Word2Vec处理多义词的能力往往被低估。尽管它为每个词创建静态表示,但这些表示实际上编码了词的多重语义关联。多义词如"bank"在Word2Vec的向量空间中位于其不同语义相关词之间,同时保持与各种语义的关联性。
然而,Word2Vec确实无法像BERT那样根据上下文动态调整表示。这不是缺陷,而是设计权衡的结果——用静态表示换取了效率和简洁性。了解这一特性,有助于我们在实际应用中做出合理的模型选择。
不同的NLP任务需要不同级别的语义理解深度。Word2Vec虽然简单,但在一些算力限制的场景下依然是作为一个高效的选择。
代码资源:本文所有代码示例可在[GitHub仓库]获取。(这么小的东西,就不上git了, 大家自己贴着用,后续如果可以成体系的话,再整理出来)
参考文献:
- Mikolov, T., et al. (2013). Distributed representations of words and phrases and their compositionality.
- Reisinger, J., & Mooney, R. J. (2010). Multi-prototype vector-space models of word meaning.
- Devlin, J., et al. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding.