Time Interval Aware Self-Attention for Sequential Recommendation
动机
推荐系统有两个重要的研究方向,时间推荐和序列推荐。
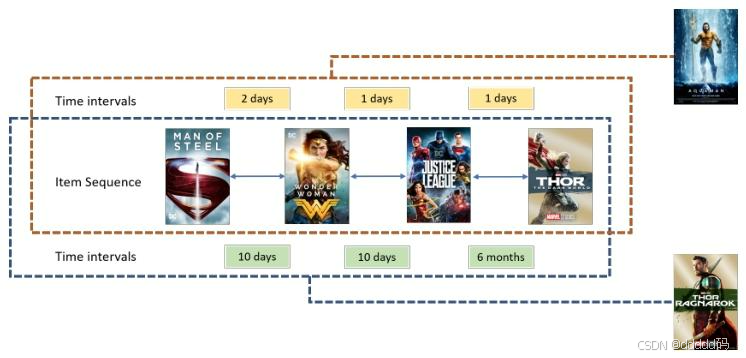
以前的序列推荐器会丢掉时间戳,只保留物品的顺序。然而,直观来看,时间戳更近的物品对下一个物品的影响会更大。例如,两个用户有相同的交互序列,但其中一个用户在一天内产生了这些交互,而另一个用户在一个月内完成了这些交互。因此,即使这两个用户的交互在序列中的位置相同,它们对下一个物品的影响也应该是不同的。然而,以前的序列推荐技术将这两种情况视为相同,因为它们只考虑了序列位置。
贡献
- 我们提议将用户的交互历史视为具有不同时间间隔的序列,并将不同的时间间隔建模为任意两次交互之间的关系。
- 我们结合了自注意力中绝对位置编码和相对时间间隔编码的优势,设计了一种新颖的时间间隔感知自注意力机制,以学习不同物品、绝对位置和时间间隔的权重,从而预测未来的物品。
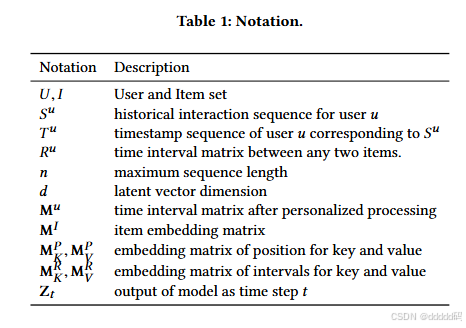
符号说明
问题公式化
设U和I分别表示用户集和项目集。在时间感知序列推荐的设定中,对于每个用户
,我们有该用户的动作序列,记为
,其中
,以及与该动作序列对应的时间序列
。在训练过程中,在时间步t,模型根据前t个项目以及项目i和j之间的时间间隔
来预测下一个项目。我们模型的输入是
以及序列中任意两个项目之间的时间间隔
,其中
。我们期望的输出是每个时刻的下一个项目:
。
个性化时间间隔
我们将训练序列
转换为固定长度的序列
,其中 n 表示我们所考虑的最大长度。如果序列长度大于 n,我们只考虑最近的 n 个动作。如果序列长度小于 n,我们在左侧填充占位项,直到长度达到 n。同样,对于时间序列
,我们也考虑一个固定长度的时间序列
。如果时间序列长度小于 n,我们用第一个非填充项
对应的时间戳
进行填充。否则,我们只考虑前 n 个时间戳。
我们将交互序列中的时间间隔建模为两个物品之间的关系。有些用户的交互更频繁,而有些用户则不然,并且我们只关心单个用户序列中时间间隔的相对长度。因此,对于所有的时间间隔,我们将用户序列中(非零)最短的时间间隔作为除数,从而得到个性化的时间间隔。
【不同用户的交互频率不同,直接使用原始时间间隔不利于模型捕捉用户序列中时间间隔的相对重要性。】
给定用户 u 的固定长度时间序列
,用户 u 的时间间隔集合(不包括 0)为
。缩放后的时间间隔为
,其中
。因此,用户 u 的关系矩阵
为:
我们将所考虑的两个物品之间的最大相对时间间隔截断为 k。我们假设超过某个阈值后,精确的相对时间间隔就不再有用了。对最大时间间隔进行截断还可以避免关系编码过于稀疏,并使模型能够推广到训练过程中未见过的时间间隔。因此,截断后的矩阵为
,其中矩阵的截断操作应用于每个元素
。
【裁剪操作可以避免关系编码过于稀疏,因为过大的时间间隔可能导致编码的稀疏性增加,不利于模型学习。同时,裁剪也能使模型更好地推广到训练过程中未见过的时间间隔,增强模型的泛化能力,提高在不同数据集上的表现】
嵌入层
我们为物品创建一个嵌入矩阵
,其中d是潜在维度。用常数零向量
作为填充项的嵌入。嵌入查找操作会检索前n个物品的嵌入,并将它们堆叠在一起,得到一个矩阵
:
我们分别使用两个不同的可学习位置嵌入矩阵
,用于自注意力机制中的键和值。这种方法更适合在自注意力机制中使用,无需额外的线性变换。检索后,我们得到嵌入
和
:
与位置嵌入类似,相对时间间隔嵌入矩阵为
、
,用于自注意力中的键和值。在检索经过裁剪的关系矩阵
后,我们得到嵌入矩阵
和
:
这两个相对时间间隔嵌入矩阵是对称矩阵,主对角线上的元素均为零。
时间间隔感知自注意力机制
仅考虑时间间隔是不够的,因为用户交互序列中可能存在许多具有相同时间戳的情况。在这种情况下,模型将变成没有任何位置或关系信息的自注意力机制。因此,我们还考虑了序列中物品的位置。
时间间隔感知自注意力层 对于由n个物品组成的每个输入序列
,其中
,计算一个新的序列
,其中
。每个输出元素
是通过对线性变换后的输入元素以及关系/位置嵌入进行加权求和得到的:
其中
是用于值的输入投影。 每个权重系数
是使用softmax函数计算的:
而
是使用一个考虑输入、关系和位置的兼容性函数计算的:
其中
、
分别是用于查询和键的输入投影。缩放因子
用于避免内积值过大,特别是在维度较高时。
因果性
由于序列的性质,模型在预测第(t + 1)个物品时,应该只考虑前t个物品。然而,时间感知自注意力层的第t个输出包含了所有的输入信息。因此,和[14]中一样,我们通过禁止
和
( j > i)之间的所有连接来修改注意力,其中
。
逐点前馈网络
尽管我们的时间间隔感知注意力层能够通过自适应权重整合所有先前物品、绝对位置和相对时间信息,但它是通过线性组合实现的。在每个时间感知注意力层之后,我们应用两个线性变换,并在中间使用ReLU激活函数,这可以为模型赋予非线性特性:
其中
,
。虽然不同物品的线性变换是相同的,但不同层使用不同的参数。 正如[14]中所讨论的,堆叠自注意力层和前馈层后,会出现更多问题,包括过拟合、训练过程不稳定(例如梯度消失)以及需要更多的训练时间。和[26]、[14]一样,我们也采用层归一化、残差连接和随机失活正则化技术来解决这些问题:
层归一化用于对输入特征进行归一化(即零均值和单位方差)。根据[1],这可以稳定并加速神经网络的训练。假设x是一个包含样本所有特征的向量,层归一化定义为:
其中
是逐元素乘积,
和
是x的均值和方差,
和
是学习到的缩放因子和偏差项。
模型推理
回顾一下,我们将物品序列
定义为给定时间和物品序列的预期输出。
中的元素
定义如下:
其中,
表示填充项。
由于用户交互数据是隐式数据,我们无法直接优化偏好得分
。我们模型的目标是提供一个物品排序列表。因此,我们采用负采样来优化物品的排序。对于每个预期的正输出
的物品中采样一个负样本
,生成一组成对的偏好序
。我们使用sigmoid函数
将模型输出分数转换到$(0, 1)$区间,并采用二元交叉熵作为损失函数:
其中,
是嵌入矩阵的集合,
表示Frobenius范数,
是正则化参数。注意,我们会屏蔽填充项的损失。 所提出的模型使用Adam优化器[15]进行优化。由于每个训练样本
