数据结构---优先级队列(堆)
1.优先级队列
1.1概念
通过前面的学习,知道了队列是一种先进先出的一种数据结构,但是在一些情况下,在出队列的时候,需要让优先级高的元素先出队列,此时一个普通队列就满足不了这个操作了
在这种情况下,就需要使用到一种新的数据结构,而这种新的数据结构应该满足两个最基本的操作,一个是优先返回最高优先级的对象,一个是插入新的对象,这种新的数据结构就是优先级队列(PriorityQueue)
2.优先级队列的模拟实现
要想模拟实现一个优先级队列,就要知道优先级队列底层的数据结构是什么?
在JDK1.8中的PriorityQueue底层使用了堆这种数据结构,而堆就是完全二叉树的另一种表达方式,在之前二叉树的学习中,所了解到的完全二叉树是一种链式结构的,而堆就是一种用数组的结构来表达一个完全二叉树
2.1堆的概念
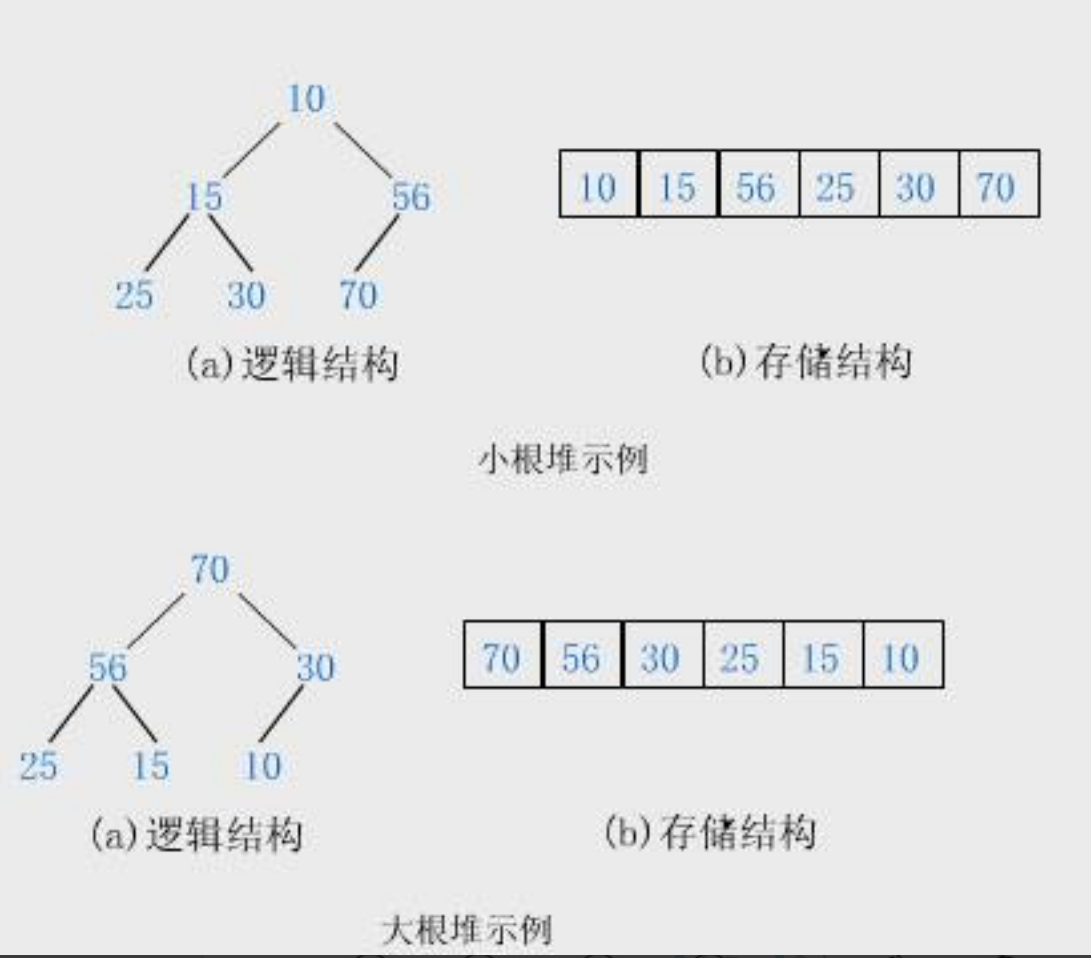
堆是一种特殊的完全二叉树的数据结构,假设有一个集合K={K0,K1......Kn-1},将集合中的所有元素以完全二叉树的形式放到一个一个一维数组elem,并且要满足下面的两种情况的其中一种情况
第一种情况:elem[i]<=elem[2*i+1]&&elem[i]<=elem[2*i+2],这一种情况的堆就是一个小根堆,在小根堆中,root节点的值是最小值,且左右孩子节点的值一定大于等于父母节点的值
第一种情况:elem[i]>=elem[2*i+1]&&elem[i]>=elem[2*i+2],这一种情况的堆就是一个大根堆,在大根堆中,root节点的值是最大值,且左右孩子节点的值一定小于等于父母节点的值
2.2堆的特性
特性1:假设父节点在数组中的下标为i,此时左右孩子的节点对应到数组中的下标分别为2*i+1和2*i+2
特性2:假设知道了左右孩子节点的下标,i不论是左孩子节点的下标还是右孩子节点的下标,父节点的下标都是 (i-1)/2
特性3:如果通过父节点的下标在计算左孩子节点的下标时,如果此时左孩子节点的下标越界了,说明该树没有左子树,如果计算右孩子节点的下标时也越界了,说明该树没有右子数
2.3 模拟实现堆的创建
创建一个类
public class TestHeap {public int[] elem;public int usedSize;//堆中的元素个数public TestHeap(){elem = new int[10];}public void initElem(int[] array){for (int i = 0; i < array.length; i++) {this.elem[i] = array[i];this.usedSize++;}}
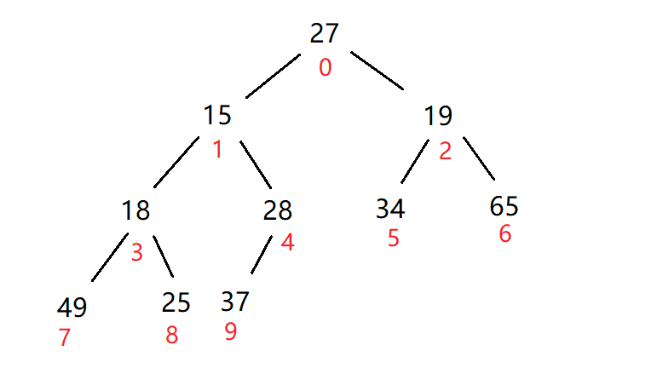
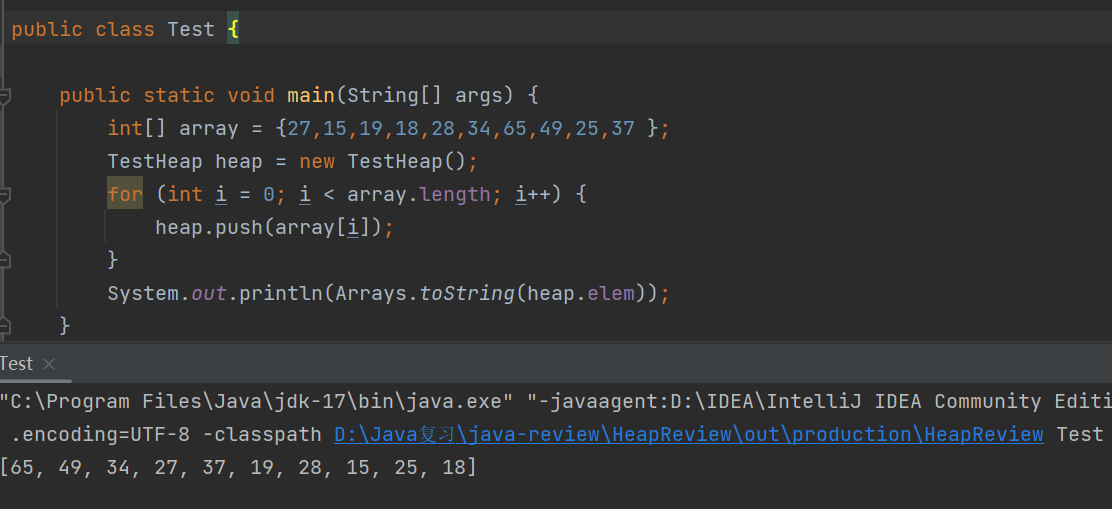
}将以数组={ 27,15,19,18,28,34,65,49,25,37 }为例,如何将集合中的元素构建成一个大根堆呢?
先将数组以完全二叉树的形式表达出来,如下图
第一步:先找出最后一棵树的父节点的下标
如何寻找最后一棵树的父节点的下标,可以通过usedSize来最后一棵树的父节点的下标,此时usedSize-1是最后一个树的最后一个孩子节点的下标,此时知道了孩子节点的下标为usedSize-1了,此时父节点的下标就是(usedSize-1-1)/2
第二步:找出左右孩子节点的最大值
此时要在左右孩子节点中找出最大值,此时会遇到两种情况:
第一种情况:如果左右孩子节点中的最大值大于父节点的值,此时要交换父节点和左右孩子中的最大值进行交换。
第二种情况:如果左右孩子节点中的最大值小于等于父节点的值,此时说明该树已经是一个大根堆,不用调整,直接break即可
第三步:每调整完一个树,就让父节点的小标--,去调整下一棵树
但是怎么让才能算是调整完一个树呢?
此时,在进行第二步时,由于我们是从最后一棵树开始,将其调整为大根堆,此时就会有一个问题
这个问题就是:由于是从最后一个树开始调整,如果在这个完全二叉树中,已经将某一层的二叉树都调整为大根堆了,此时让父节点--,此时父节点的位置有可能会跑到上一层去,此时将这一层的树调整为大根堆时,可能会影响到下面的树,此时下面的树就有可能因为上一层的树调整为大根堆后,下面的树就不是大根堆
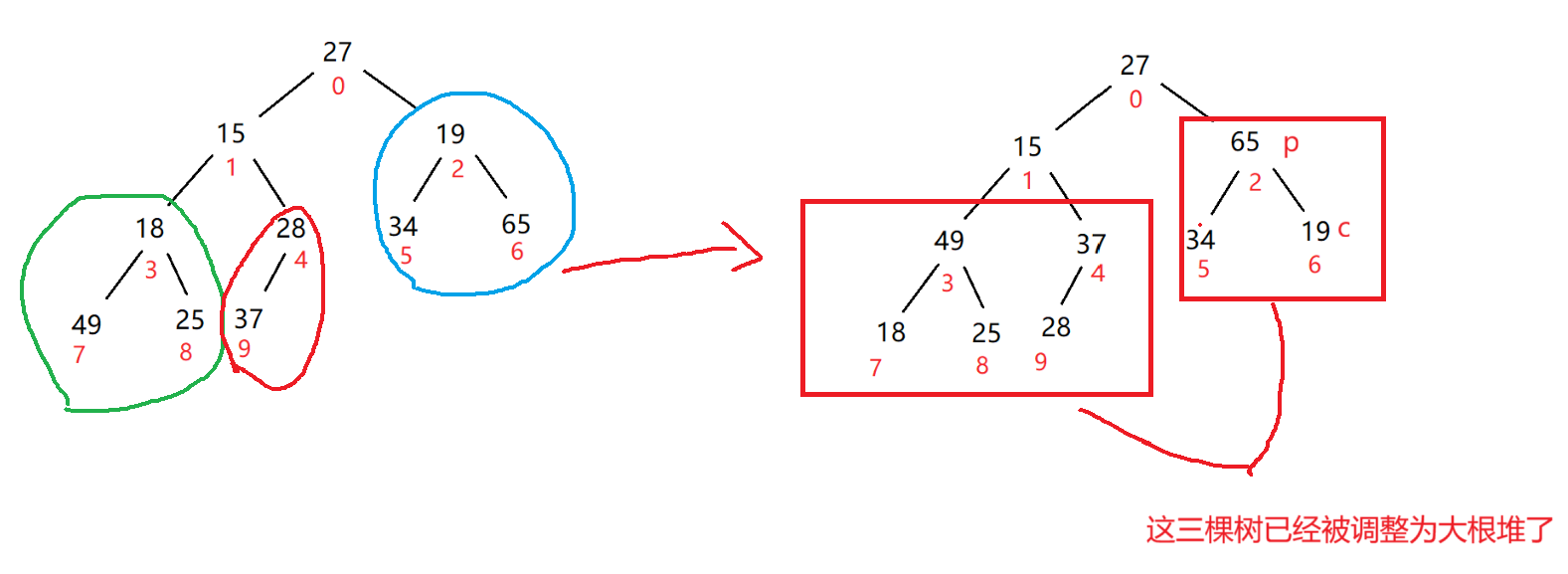
此时就去调整下一个树,即让p--
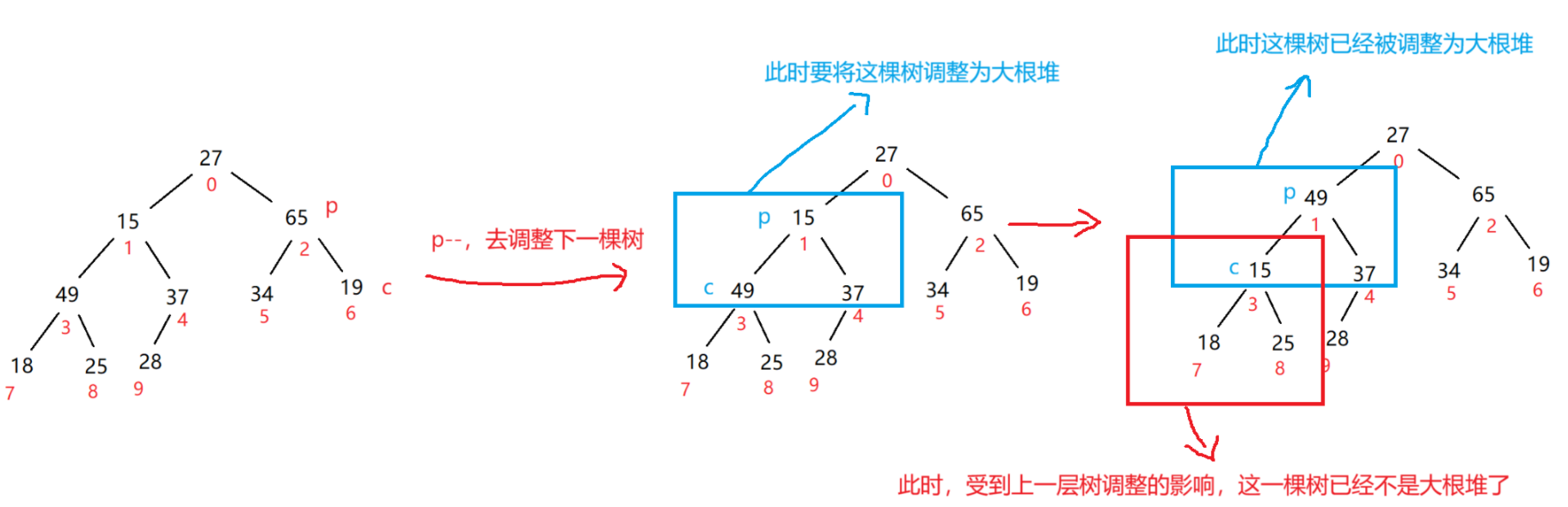
所以此时为了解决这个问题,每次调整完一棵树,我们都要继续向下调整,直到调整到有一个树没有左树即可,就说明这棵树已经被调整完了
如何向下跳整呢?
此时让p=c,c=2*p+1即可,c是左右节点中,值最大的那个节点的下标,p是父节点的下标
为什么不让p跳向值较小的那个节点呢?
因为是从最后一个树开始调整,也就是说调整到更高一层的树时,比这一层更低中的所有树都已经被调整为大根堆了,此时值较小的节点没有发生值的变化,没有发生变化且原本已经被调整为大根堆了,此时就不用让p跳到这个节点去调整了
p跳到那个节点取决于下一层的一棵树有于在上一层的某一棵树的调整中,导致下一层的那棵树收到影响,导致下一层的那棵树的大根堆结构被破坏了,此时就要让p跳到大根堆结构被破坏的那棵树,重新调整这棵树
代码实现:
public class TestHeap {public int[] elem;public int usedSize;public TestHeap(){elem = new int[10];}//初始化elempublic void initElem(int[] array){for (int i = 0; i < array.length; i++) {this.elem[i] = array[i];this.usedSize++;}}public void createHeap(){//先找出最后一个树的父节点下标,从最后一棵树开始创建堆//最后一个树的父节点的下标: (usedSize-1-1)/2for (int parent=(usedSize-1-1)/2;parent>=0;parent--){//一个parent代表调整一棵树shiftDown(parent,this.usedSize);}}private void shiftDown(int parent, int usedSize) {int child = parent*2+1;while (child<usedSize){//先找出左右子树的最大值if (child+1<usedSize && elem[child+1]>elem[child]){child=child+1;}if (elem[child]>elem[parent]){swap(elem,child,parent);//交换完,继续向下调整parent=child;child=parent*2+1;} else {break;}}}private void swap(int[] elem, int child, int parent) {int tmp = elem[parent];elem[parent]=elem[child];elem[child]=tmp;}
}测试:
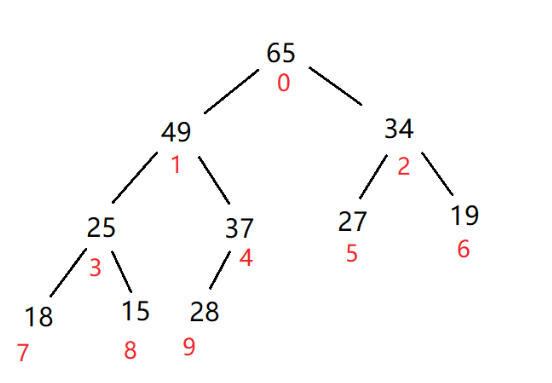
将代码运行结果转换成完全二叉树,如下图,发现结果正确
2.4 推算建堆的时间复杂度
首先假设一棵数高为h,由于在调整一个树为大根堆时,是向下调整的,所以,在最坏情况下,在向下调整时,该层的所有节点都要向下调整到最后一层,此时就需要将调整每一树为大根堆的时间计算出来,然后都加起来即可。
此时,如何计算调整一棵树为大根堆的时间复杂度呢?
很简单,假设树高为h,每一层的节点的个数N=2^(h-1)个,此时最坏情况下,调整每一个树时都要向下调整到最后一层,如下图

此时只要将h层的结果加起来即可,通过错位相减来求出T(N),如下图

此时建堆的时间复杂度为O(N),而不是我们凭感觉的O(NlogN)
2.5堆的插入
如何实现堆的插入呢?
此时只需要将插入的数据放到最后一个树的最后一个节点即可,也就是将插入的元素放到usedSize的位置,将插入的元素放到usedSize的位置之后。
此时也会有两种情况:
第一种情况:插入的的数据大于父节点的值,此时最后一棵树就不构成大根堆了,此时就需要向上调整,知道调整到root节点那棵树即可
为什么要一直调整到root节点那棵树呢?
原因还是和向下调整时的原因相似,因为在调整时,会涉及到父节点的值和子节点的值的交换,但是这棵树的父节点有可能是另一棵树的子节点,由于是从下往上调整,所以在调整一棵树为大根堆时,此时就有可能出现将下面的一棵树调整为大根堆时,会影响到上面的树,导致上面的树不是大根堆结构了,所以,为了解决这个问题,我们要一直调整到root节点那棵树,保证插入后,所有的树还是大根堆结构。
第二种情况:插入的数据小于等于最后一棵树父节点的值,此时就无需向上调整,直接break即可
代码实现:
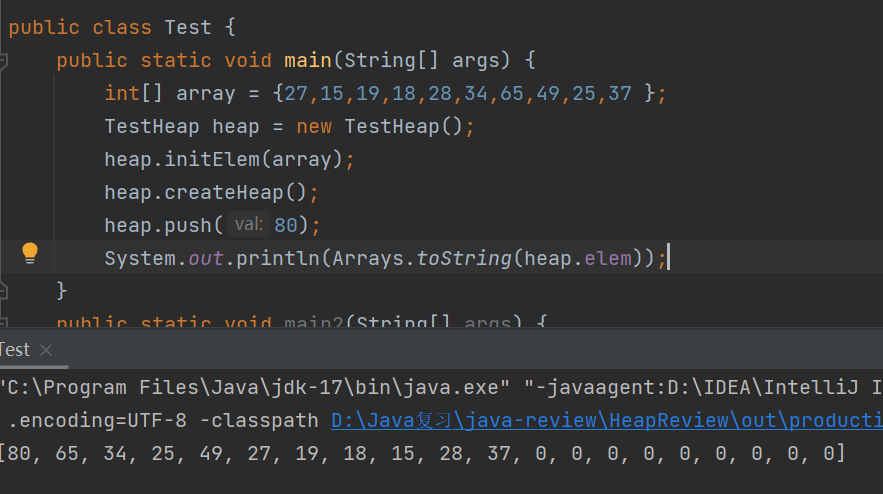
public class TestHeap {public int[] elem;public int usedSize;public TestHeap(){elem = new int[10];}public void initElem(int[] array){for (int i = 0; i < array.length; i++) {this.elem[i] = array[i];this.usedSize++;}}public void createHeap(){//先找出最后一个树的父节点下标,从最后一棵树开始创建堆//最后一个树的父节点的下标: (usedSize-1-1)/2for (int parent=(usedSize-1-1)/2;parent>=0;parent--){//一个parent代表调整一棵树shiftDown(parent,this.usedSize);}}private void shiftDown(int parent, int usedSize) {int child = parent*2+1;while (child<usedSize){//先找出左右子树的最大值if (child+1<usedSize && elem[child+1]>elem[child]){child=child+1;}if (elem[child]>elem[parent]){swap(elem,child,parent);//交换完,继续向下调整parent=child;child=parent*2+1;} else {break;}}}//向堆中插入元素//时间复杂度(logN)public void push(int val){//判满if (isFull(this.elem)){elem = Arrays.copyOf(elem,2*elem.length);}elem[usedSize]=val;//向上调整shiftUp(usedSize);usedSize++;}private void shiftUp(int usedSize) {int child = usedSize;int parent = (usedSize-1)/2;while (parent>=0){if (elem[child]>elem[parent]){swap(elem,child,parent);child=parent;parent=(child-1)/2;} else {break;}}}private void swap(int[] elem, int child, int parent) {int tmp = elem[parent];elem[parent]=elem[child];elem[child]=tmp;}测试:结果正确
此时在实现堆的插入时,同时我们也实现了以向上调整的方式来创建大根堆,测试
需要注意的是:向上调整创建堆的时间复杂度是高于向下调整创建堆的时间复杂度的

2.6堆的删除
实现堆的删除,此时有了上面的基础,就很简单了
首先,堆的删除就是删除堆顶元素,此时将根节点的值与最后一个树的最后一个节点的值交换,然后让usedSize--,就完成了删除操作,如下图
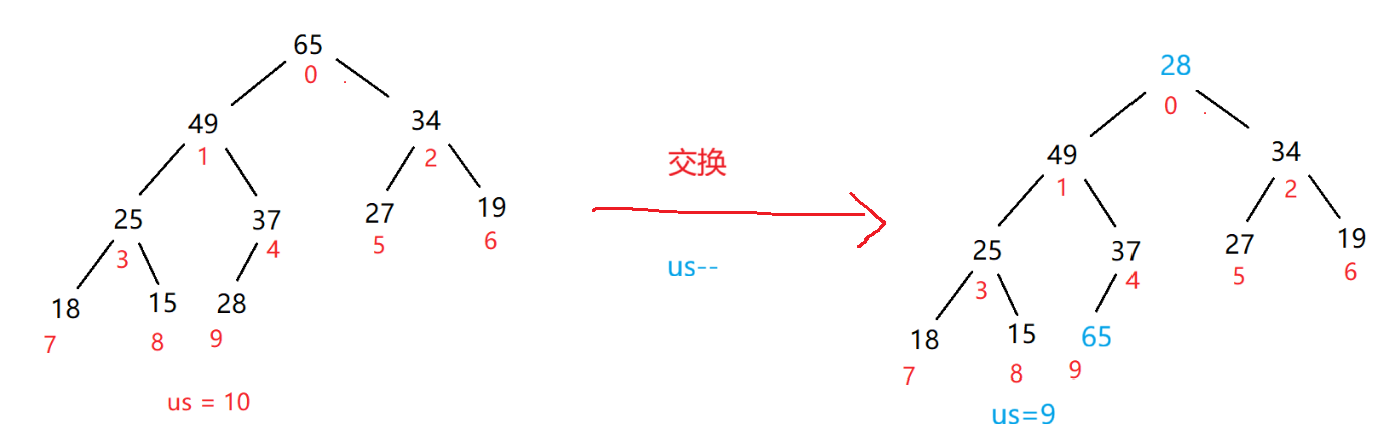
此时发现一个特点,此时只有根节点那棵树不是大根堆,其他的树都是大根堆,所以,此时在交换完值之后,进行依次向下调整为大根堆即可
代码实现:
public class TestHeap {public int[] elem;public int usedSize;public TestHeap(){elem = new int[10];}public void initElem(int[] array){for (int i = 0; i < array.length; i++) {this.elem[i] = array[i];this.usedSize++;}}public int poll(){if (isEmpty()){throw new RuntimeException("Heap is Empty");}int val = elem[0];swap(elem,0,usedSize-1);shiftDown(0,usedSize-1);return val;}private boolean isEmpty() {return usedSize==0;}private void shiftDown(int parent, int usedSize) {int child = parent*2+1;while (child<usedSize){//先找出左右子树的最大值if (child+1<usedSize && elem[child+1]>elem[child]){child=child+1;}if (elem[child]>elem[parent]){swap(elem,child,parent);//交换完,继续向下调整parent=child;child=parent*2+1;} else {break;}}}}测试:发现结果正确
2.7堆排序
堆排序有两种情况:
当我们想对一个数组进行升序排序时,此时就可以借助大根堆来实现。
当我们想对一个数组进行降序排序时,此时就可以借助小根堆来实现。
下面以升序来解释:
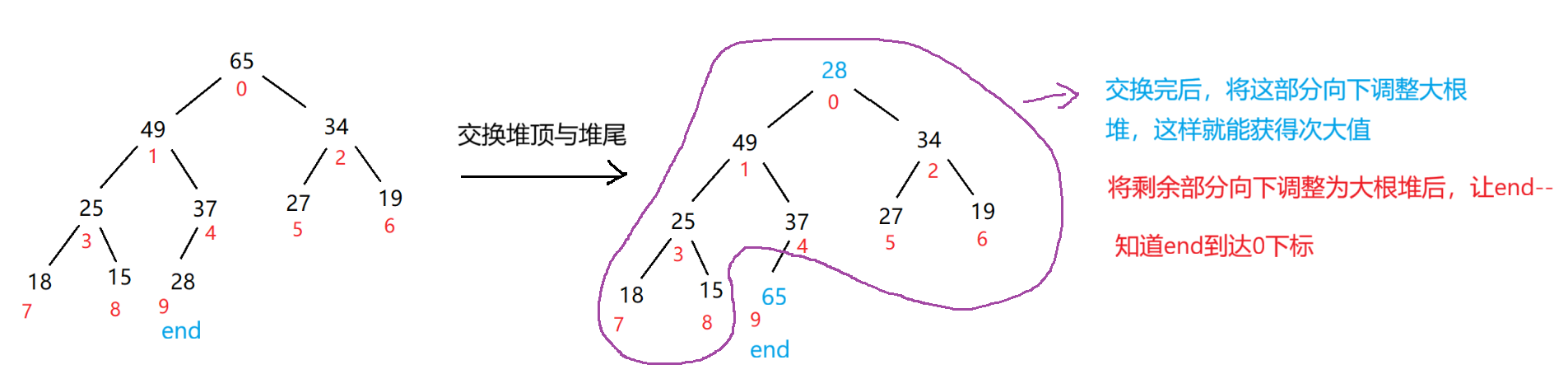
原理:将待排序的数组构建成一个大根堆。此时整个数组中的最大值就是堆顶元素,然后将堆顶元素与堆尾元素交换,此时堆中的,末尾元素就是最大值,然后将除了堆尾元素之外的剩余的n-1个序列重新构成成一个大根堆,这样就可以得到剩下的没排序的序列中的次大值,反复此操作,便能得到一个有序序列,如下图
为什么不用小根堆呢?
因为小根堆有一个问题,就是小根堆只能保证堆顶数据是最小的,无法确定左右子树值的大小。什么意思呢?假设此时已经将小根堆的第一小的数据排序好了,此时这个第一小的数据肯定是要放在堆顶了,此时在这之后,因为要将除了堆顶元素之外的所有元素调整为大根堆,但是因为不能调整堆顶元素,此时就无法将剩余的节点看做一部分来调整为小根堆,而是被划分为了左右两部分。
此时可能左边的部分有存在比右边的部分大值,此时先调整左边部分为小根堆去排序的话,此时就会将大的值排在了前面,后续在去调整右边部分为小根堆排序的后,此时就会出现一个较小的值排在较大的值的后面
同理,此时可能右边的部分有存在比左边的部分大值,如果此时先调整右边部分为小根堆去排序的话,此时就会将大的值排在了前面,后续在去调整左边部分为小根堆排序的后,此时就会出现一个较小的值排在较大的值的后面

代码实现:
public class TestHeap {public int[] elem;public int usedSize;public TestHeap(){elem = new int[10];}public void initElem(int[] array){for (int i = 0; i < array.length; i++) {this.elem[i] = array[i];this.usedSize++;}}public void createHeap(){//先找出最后一个树的父节点下标,从最后一棵树开始创建堆//最后一个树的父节点的下标: (usedSize-1-1)/2for (int parent=(usedSize-1-1)/2;parent>=0;parent--){//一个parent代表调整一棵树shiftDown(parent,this.usedSize);}}//堆排//时间复杂度(OlogN)public void sort(){int end = usedSize-1;while (end>0){swap(elem,0,end);shiftDown(0,end);end--;}}private void shiftDown(int parent, int usedSize) {int child = parent*2+1;while (child<usedSize){//先找出左右子树的最大值if (child+1<usedSize && elem[child+1]>elem[child]){child=child+1;}if (elem[child]>elem[parent]){swap(elem,child,parent);//交换完,继续向下调整parent=child;child=parent*2+1;} else {break;}}}
}测试:
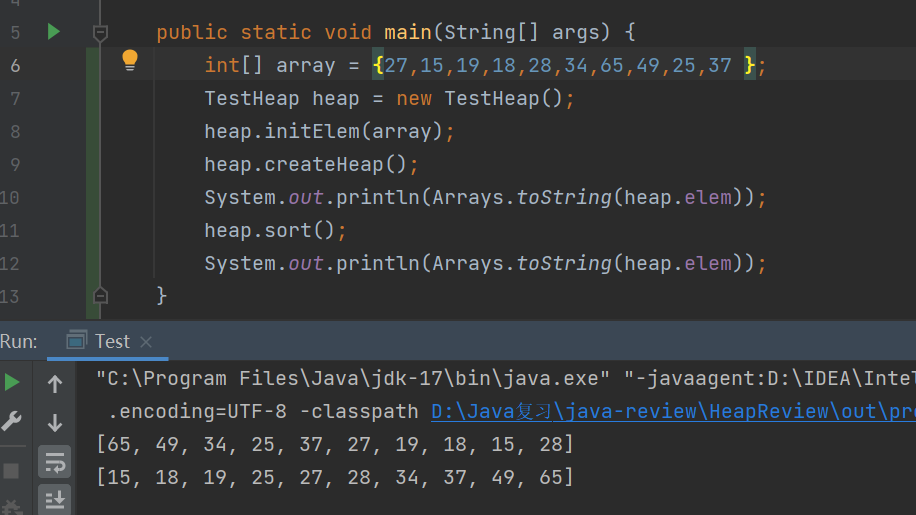
借助堆来排序,无论是升序还是降序,都是依靠堆顶是最值的思想,不断将堆顶元素往堆的最后一个位置,逐步的构建有序序列
2.8TopK问题
Tok问题有两种:
第一种:获取前k个最大的元素或者获取前k个最小的元素
第二种:获取第k大的元素或者获取第k小的元素
获取前k个最大的元素和获取第k大的元素会用到小根堆
获取前k个最小的元素或者第k小的元素会用到大根堆
下面以获取前k个最小的元素和获取第k个最小的元素为例子来解释
1.获取前K个最小的元素
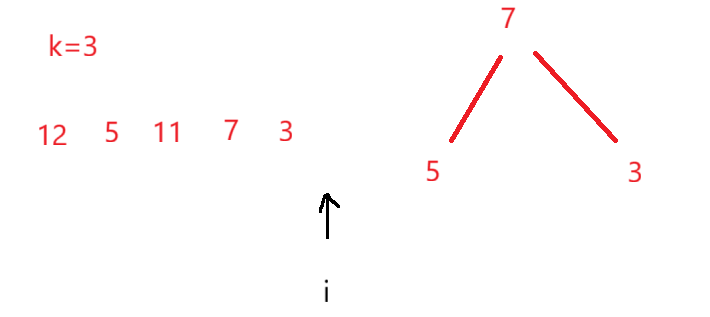
首先找出数组中前k个元素,用前k个元素构建一个大根堆,如下图

然后从从第k个位置开始遍历原数组,将遍历的数字arr[i]与堆顶数字top进行比较,如果发现arr[i]<top,说明此时的top不是前k个最小的元素,此时要将top出堆,将arr[i]入堆,一种重复此操作直到将原数组遍历完,最终将剩余的N-K个数据依次与堆顶元素进行比较之后,发现堆中的数字就是前k个最小的数字
此时也可以发现最终,堆顶元素也是第k小的元素
题目链接:面试题 17.14. 最小K个数 - 力扣(LeetCode)
代码实现:
class Solution {public int[] smallestK(int[] arr, int k) {int[] ret=new int[k];//创建大根堆PriorityQueue<Integer> queue = new PriorityQueue<>((a,b)->(b-a));for(int i=0;i<k;i++){queue.offer(arr[i]);}for(int index=k;index<arr.length;index++){if(!queue.isEmpty()&&arr[index]<queue.peek()){queue.poll();queue.offer(arr[index]);}}for(int i=0;i<k;i++){ret[i]=queue.poll();}return ret;}
}第二种解法:以小根堆来解决
先创建一个小根堆,现将数组中的数据全部放进小根堆中,最后在对小根堆去k次堆顶元素放到结果数组中即可
class Solution {public int[] smallestK(int[] arr, int k) {int[] ret=new int[k];PriorityQueue<Integer> queue = new PriorityQueue<>();for(int x:arr){queue.offer(x);}for(int i=0;i<k;i++){ret[i]=queue.poll();}return ret;}
}时间复杂度分析:
堆中有k个节点,此时树的高度为logk
将前k个元素转成大根堆的时间复杂度:O(K*logK)
依次将剩余的(N-K)个节点转成大根堆的时间复杂度:O((N-K)*logK)
将两者相加:得到N*logK,约等于O(N)
这比先对数组直接排序后再去获取前k个最小的元素更快,因为排序最快的时间复杂度为O(N*logN)
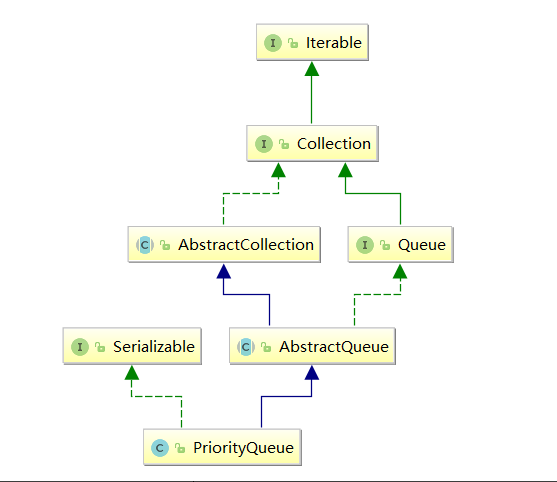
3.Java集合类中的PriorityQueue
在Java中的PriorityQueue其底层是一个小根堆
3.1构造方法
PriorityQueue提供了三种构造方法,如下图

注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器,如一下代码
import java.util.Comparator;
import java.util.PriorityQueue;class IntComparator implements Comparator<Integer> {@Overridepublic int compare(Integer o1, Integer o2) {return o2.compareTo(o1);}
}public class Test {public static void main(String[] args) {IntComparator intComparator = new IntComparator();PriorityQueue<Integer> p = new PriorityQueue<>(intComparator);p.offer(4);p.offer(3);p.offer(2);p.offer(1);p.offer(5);System.out.println(p.peek());}
}3.2常用接口介绍
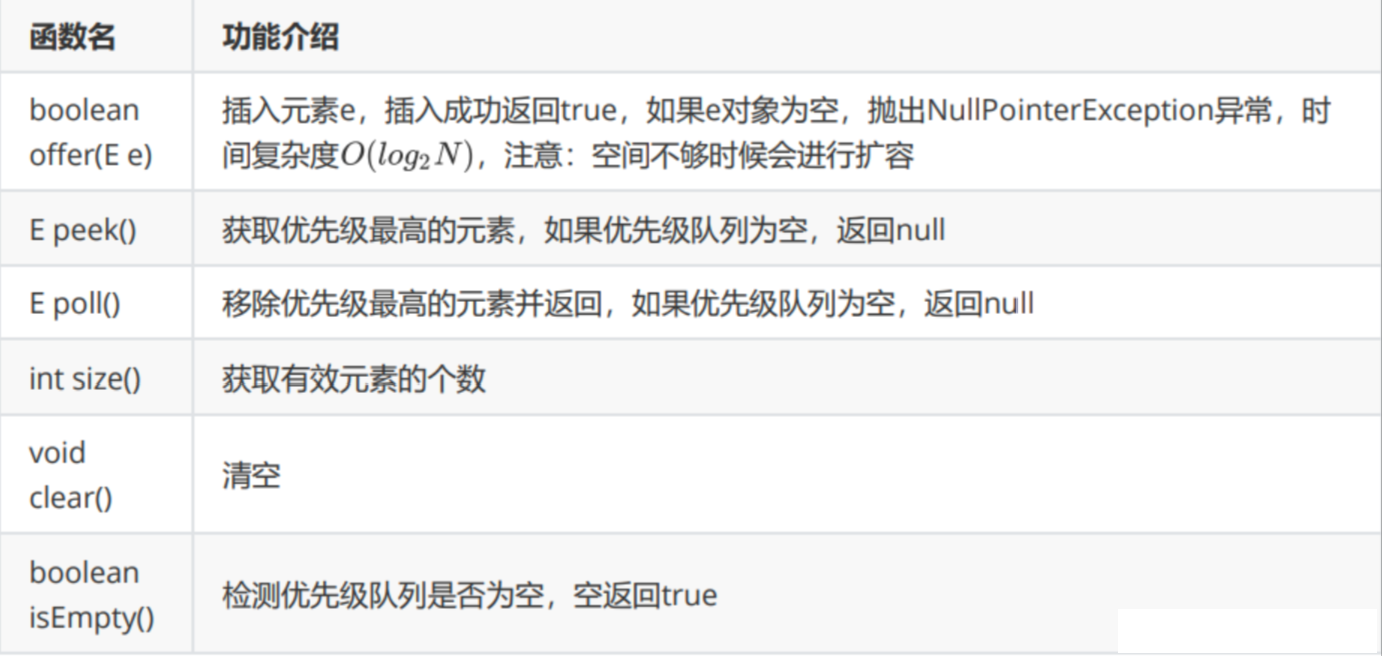
3.2使用PriorityQueue的注意事项
1.PriorityQueue中放置的元素必须能够比较大小,不能插入无法比较大小的对象,否则会抛出ClassCastException异常
2.PriorityQueue不能插入null对象
3.PriorityQueue没有容量限制,可以插入任意多个元素,其内部自动扩容
4.插入和删除的元素的时间复杂度为O(logN)
5.PriorityQueue底层使用了堆数据结构
6.PriorityQueue默认情况下是小根堆