软件设计师知识点总结:操作系统
一. 操作系统概述
1.1 操作系统的作用
- 通过资源管理提高计算机系统的效率
- 改善人机界面向用户提供友好的工作环境
1.2 操作系统的特征
- 并发性
- 共享性
- 虚拟性
- 不确定性
1.3 操作系统的功能
- 进程管理
- 存储管理
- 文件管理
- 设备管理
- 作业管理
1.4 操作系统的分类
- 批处理操作系统
- 分时操作系统(轮流使用 CPU 工作片)
- 实时操作系统(快速响应)
- 网络操作系统
- 分布式操作系统(物理分散的计算机互联系统)
- 微机操作系统(Windows)
- 嵌入式操作系统
1.5 计算机启动的基本流程
BIOS--> 主引导记录 --> 操作系统
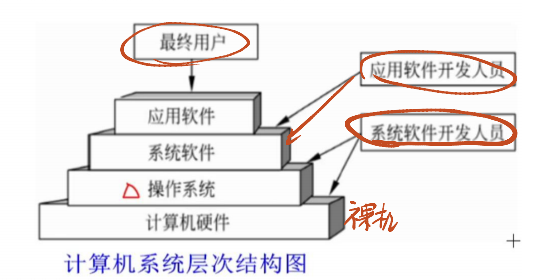
1.6 操作系统的地位
2. 进程管理
2.1 进程的组成和状态
2.1.1 进程的组成
- 进程控制块 PCB(唯一标志)
- 程序(描述进程要做什么)
- 数据(存放进程执行时所需数据)
2.1.2 进程的状态
- 基础三态:
- 运行态:进程正在占用 CPU,执行程序指令。单 CPU 系统中,同一时刻只有一个进程处于运行态;多 CPU 系统中,每个 CPU 对应一个运行态进程。
- 就绪态:进程已具备运行条件(如已分配内存、打开必要文件),但因 CPU 被其他进程占用,暂时无法运行,处于 “等待 CPU 调度” 的状态。例如,同时打开多个软件后,除了正在运行的进程,其他进程都处于就绪态,排队等待 CPU 时间片。
- 阻塞态(等待态):进程因等待某个事件发生(如等待键盘输入、等待磁盘 I/O 完成、等待信号量),暂时无法执行,即使有 CPU 资源也不能运行。例如,程序执行 “读取文件” 操作时,需等待硬盘读取完成,此时进程处于阻塞态;文件读取完成后,进程转为就绪态,等待 CPU 调度。
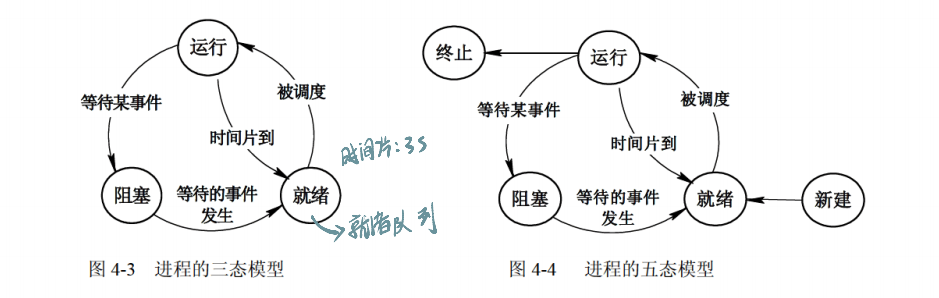

- 五态(含人为操作):运行、活跃就绪(就绪)、活跃阻塞(阻塞)、静止就绪、静止阻塞(需人为操作进入对应状态,人为激活后恢复为活跃状态,后续本质仍为三态转换)
2.2 前趋图
- 用途:表示哪些任务可以并行执行,哪些任务之间有顺序关系
- 示例:A、B、C 可并行执行,需 A、B、C 都执行完后才能执行 D,明确任务间的并行与先后顺序
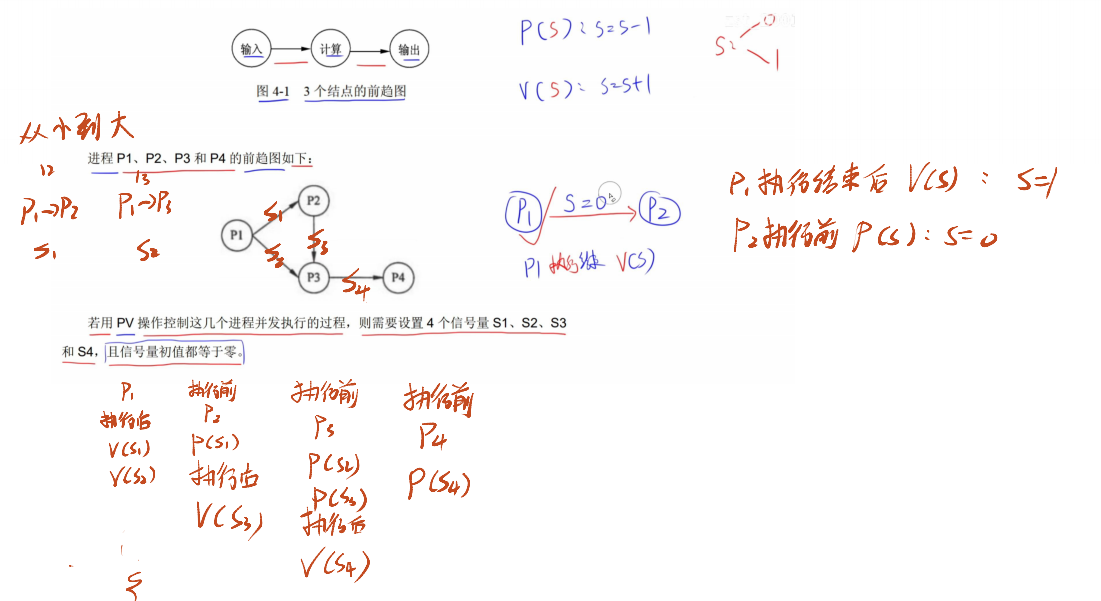
2.3 程序并发执行和前驱图
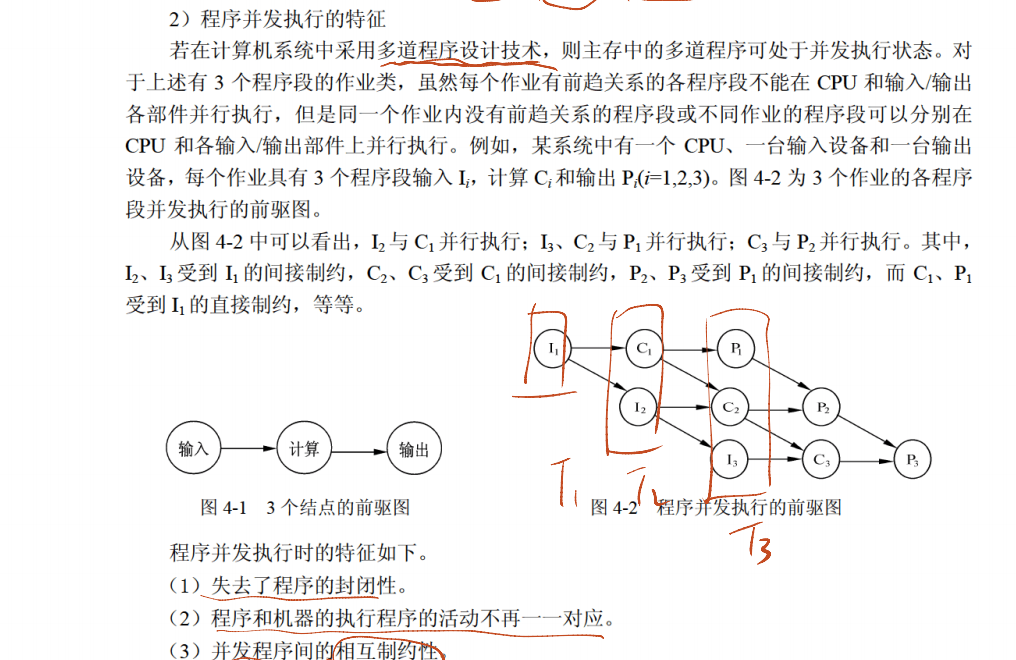
2.4 进程间的通信
进程间需通过 “同步与互斥” 协调资源使用,通过 “信号量操作” 实现控制,典型场景为 “生产者 - 消费者问题”,具体如下:
2.4.1 同步与互斥
- 互斥:某类资源(称为 “临界资源”)同一时间只能被一个进程使用,需通过 “加锁 - 解锁” 控制。例如,打印机是临界资源 —— 进程使用打印机前 “加锁”,防止其他进程同时使用;使用完成后 “解锁”,允许其他进程使用。
- 同步:多个进程并发执行时,因速度差异需 “等待配合”,确保执行顺序合理。例如,“数据写入进程” 和 “数据读取进程”—— 写入进程需先写入数据,读取进程才能读取,若读取进程速度过快,需等待写入进程完成后再执行。
- 关键术语:
- 临界资源:需互斥访问的资源(如打印机、共享内存)。
- 临界区:进程中操作临界资源的代码段(如 “打印文件” 的代码段)。
- 互斥信号量:控制临界资源互斥访问的信号量,初值为 1—— 进程申请资源时 “P 操作”(信号量减 1),释放资源时 “V 操作”(信号量加 1),确保同一时间只有一个进程进入临界区。
- 同步信号量:控制进程同步的信号量,初值为 “共享资源的数量” 或 “0”(如控制 “空缓冲区数量” 的同步信号量,初值为缓冲区总数)。
2.4.2 信号量操作
信号量是协调进程间资源使用的 “计数器”,核心操作包括 P 操作(申请资源)和 V 操作(释放资源),具体规则如下:
- P 操作(申请资源):
- 信号量 S 的值减 1(S = S - 1)。
- 若 S ≥ 0:进程申请资源成功,继续执行。
- 若 S <0:进程申请资源失败,转为阻塞态,插入 “阻塞队列”,等待其他进程释放资源。
- V 操作(释放资源):
- 信号量 S 的值加 1(S = S + 1)。
- 若 S > 0:进程释放资源成功,继续执行(无其他进程等待该资源)。
- 若 S ≤ 0:说明有进程在阻塞队列中等待该资源,唤醒一个阻塞进程,将其转为就绪态,插入 “就绪队列”,当前进程继续执行。
2.4.3 生产者和消费者问题
“生产者 - 消费者问题” 是进程同步与互斥的典型场景:生产者进程生产商品放入仓库,消费者进程从仓库取出商品,需通过三个信号量协调,具体如下:
- 信号量定义:
- S0(互斥信号量):控制仓库的 “独立使用权”,初值为 1—— 确保同一时间只有一个进程(生产者或消费者)操作仓库,避免商品存放 / 取出混乱。
- S1(同步信号量):记录仓库的 “空闲空间数量”,初值为仓库最大容量(如 10)—— 生产者生产商品前需申请空闲空间,空闲空间不足时阻塞。
- S2(同步信号量):记录仓库的 “商品数量”,初值为 0—— 消费者取出商品前需申请商品,无商品时阻塞。
- 执行流程:
生产者流程 消费者流程 1. 生产一个商品 1. P (S0)(申请仓库使用权) 2. P (S0)(申请仓库使用权) 2. P (S2)(申请商品) 3. P (S1)(申请空闲空间) 3. 从仓库取出一个商品 4. 将商品放入仓库 4. V (S1)(释放空闲空间) 5. V (S2)(增加商品数量) 5. V (S0)(释放仓库使用权) 6. V (S0)(释放仓库使用权) -
2.5 死锁
死锁是 “多个进程互相等待对方资源,无法继续执行” 的状态,需从 “产生条件、解决办法、计算” 三方面理解,具体如下:
2.5.1 死锁产生的四个必要条件
死锁的产生必须同时满足以下四个条件,缺一不可:
- 资源互斥:资源同一时间只能被一个进程使用(如打印机、扫描仪等独占资源)。
- 持有并等待:进程持有已分配的资源,同时等待其他进程的资源(如进程 P1 持有 R1 资源,等待 P2 的 R2 资源;P2 持有 R2 资源,等待 P1 的 R1 资源)。
- 不可剥夺:操作系统不能强制剥夺进程已持有的资源(如进程 P1 持有 R1 资源,系统不能强行收回 R1 分配给 P2)。
- 循环等待:进程间形成 “资源请求循环”(如 P1→R2→P2→R1→P1),每个进程都在等待循环中的下一个进程释放资源。
2.5.2 死锁的解决措施
针对死锁的四个必要条件,可通过 “预防、避免、检测、解除” 四种方式处理,具体如下:
- 死锁预防:破坏四个必要条件中的任意一个,从源头避免死锁。例如:
- 破坏 “资源互斥”:将独占资源改为共享资源(如用网络打印机代替本地打印机,支持多进程同时提交打印任务)。
- 破坏 “持有并等待”:要求进程启动时一次性申请所有所需资源,申请不到则不启动;若启动后需要新资源,需先释放已持有的资源。
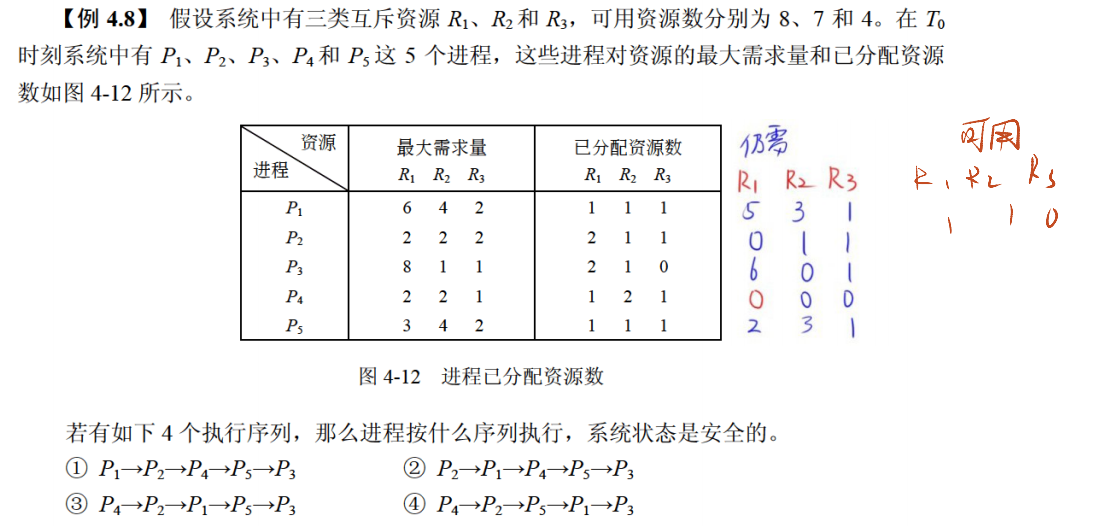
- 死锁避免:允许进程动态申请资源,但通过算法判断 “资源分配是否安全”,仅在安全时分配资源。最典型的是 “银行家算法”—— 类比银行放贷,需确保 “贷款后银行仍有足够资金满足其他客户的贷款需求”,操作系统需确保 “资源分配后,仍存在一条让所有进程都能完成的执行序列”,否则拒绝分配资源。

- 死锁检测:允许死锁产生,系统定时运行 “死锁检测程序”(如检查进程资源图是否存在循环等待),若检测到死锁,触发后续处理。
- 死锁解除:死锁检测到后,通过两种方式恢复系统:
- 强制剥夺资源:从死锁进程中强行收回部分资源,分配给其他死锁进程,直至死锁解除(如终止一个进程,释放其资源)。
- 撤销进程:按优先级或 “最小代价” 撤销部分死锁进程,释放资源(如撤销优先级低、占用资源少的进程)。
2.5.3 死锁计算问题
已知 “系统内有 n 个进程,每个进程需 R 个同类资源”,可通过公式计算 “死锁边界”:
- 发生死锁的最大资源数:n×(R-1)—— 每个进程都持有 “R-1 个资源”,此时所有进程都无法完成,且互相等待最后 1 个资源,系统死锁。例如,3 个进程,每个需 2 个资源,死锁最大资源数 = 3×(2-1)=3(每个进程持有 1 个资源,共 3 个,都等待第 2 个)。
- 不发生死锁的最小资源数:n×(R-1)+1—— 在死锁最大资源数的基础上增加 1 个资源,此时至少有一个进程能获得 “R 个资源” 并完成,释放资源后其他进程可继续执行。例如,3 个进程,每个需 2 个资源,不死锁最小资源数 = 3×(2-1)+1=4(1 个进程获得 2 个资源完成,释放后其他进程各获得 1 个,可继续执行)。
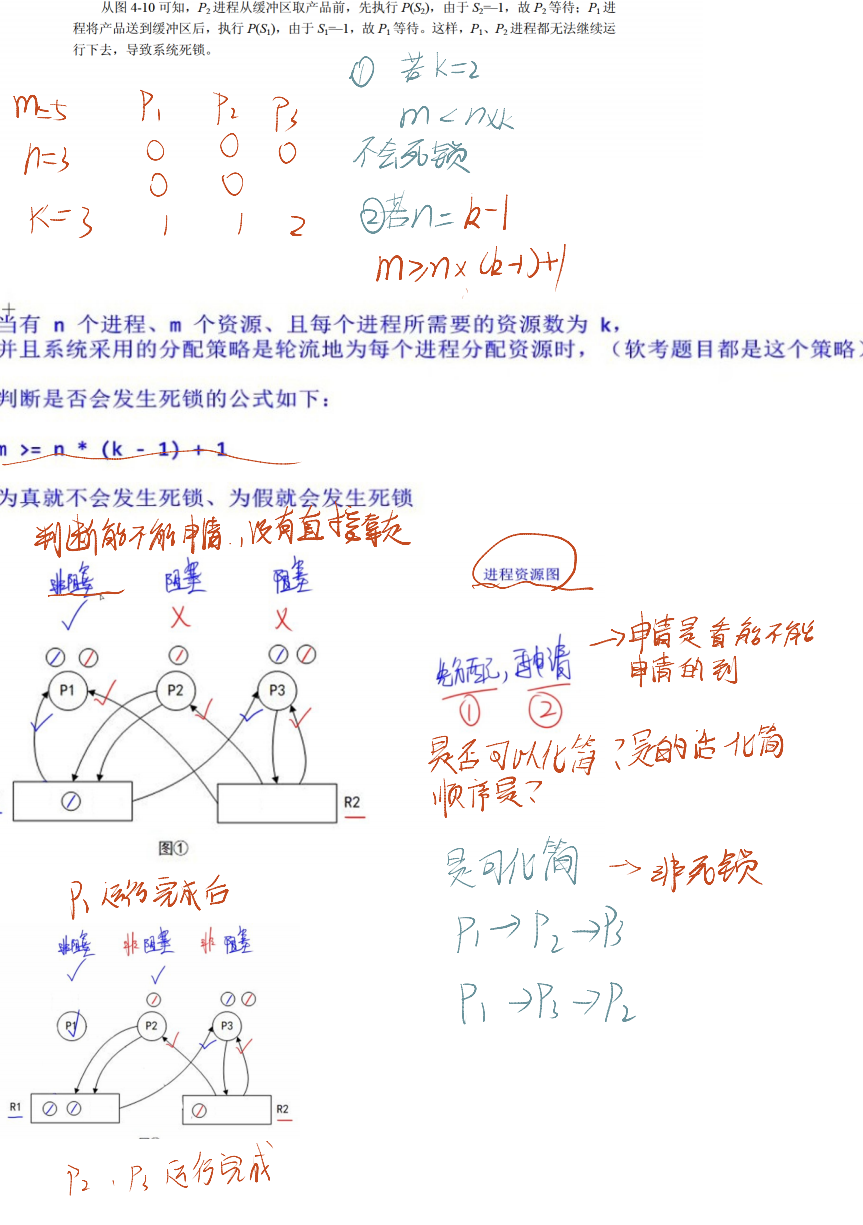
2.6 进程资源图
进程资源图是分析 “进程与资源分配关系” 的工具,用于判断系统是否存在死锁,具体如下:
- 图形组成:
- 进程(P):用 “圆形” 表示,代表正在运行或等待资源的进程。
- 资源(R):用 “方框” 表示,方框内的 “圆球” 数量代表该类资源的总数(如 R1 方框内有 2 个球,说明 R1 资源总数为 2)。
- 分配关系:用 “从 R 指向 P 的有向边” 表示,说明资源已分配给进程(如 R1 指向 P1,代表 R1 的 1 个资源已分配给 P1)。
- 请求关系:用 “从 P 指向 R 的有向边” 表示,说明进程需要申请该资源(如 P1 指向 R2,代表 P1 需要申请 1 个 R2 资源)。
- 关键概念:
- 阻塞节点:进程申请的资源已全部分配完毕,无法获取所需资源,只能等待(如 P2 申请 R1 资源,但 R1 已全部分配给 P1,P2 为阻塞节点)。
- 非阻塞节点:进程申请的资源仍有剩余,可分配资源继续执行(如 P1 申请 R2 资源,R2 仍有剩余,P1 为非阻塞节点)。
- 死锁状态:当进程资源图中所有进程都是阻塞节点时,系统陷入死锁 —— 没有进程能继续执行,也无法释放资源,需手动干预(如终止进程)。
2.7 线程
线程是 “进程内的执行单元”,引入线程后,操作系统的调度和资源管理更精细,具体如下:
- 传统进程与线程的属性对比:
特性 传统进程 线程 资源持有 可拥有资源的独立单位(资源归进程所有) 不可独立持有资源,共享进程的资源(如代码、数据、文件) 调度单位 可独立调度的基本单位(早期操作系统以进程为调度单位) 独立调度的最小单位(现代操作系统以线程为调度单位) - 线程的资源共享:
- 可共享的进程资源:进程的代码段、全局变量、公共数据、打开的文件、网络连接等 —— 例如,一个浏览器进程的多个线程(网页渲染线程、下载线程)可共享浏览器的代码和打开的网络连接。
- 不可共享的线程独有资源(线程不可共享):线程的栈指针、程序计数器(记录线程执行的指令位置)、线程 ID 等 —— 这些资源确保线程独立执行,互不干扰。
- 核心优势:线程切换速度比进程快(无需切换进程的内存地址空间、打开的文件等),多线程程序的并发效率更高。例如,一个视频播放程序,用 “音频线程” 播放声音、“视频线程” 渲染画面,比用两个独立进程更高效。
3. 存储管理
存储管理负责 “内存和外存的分配、回收、地址转换”,核心管理方式包括页式、段式、段页式,具体如下:
3.1 页式存储管理
页式存储管理将 “进程空间和物理内存” 都划分为等大的 “页”,实现 “按需加载”,具体如下:
3.1.1 基本原理
- 分页划分:
- 进程空间(逻辑地址):划分为多个 “逻辑页”(简称 “页”),每个页大小固定(如 4KB、8KB,由系统决定),用 “页号” 标识(如 0、1、2...)。
- 物理内存:划分为多个 “物理块”(简称 “块”),块大小与页大小相同,用 “块号” 标识(如 0、1、2...)。
- 地址转换:
- 逻辑地址格式:“页号 + 页内偏移”—— 例如,逻辑地址为 16 位,页大小 4KB(2¹²),则页号占 4 位(标识 0-15 号页),页内偏移占 12 位(标识页内 0-4095 字节)。
- 页表:每个进程有一张 “页表”,记录 “页号与块号的对应关系”(如页 0 对应块 5、页 1 对应块 3)。操作系统通过页表将逻辑地址的 “页号” 转换为物理地址的 “块号”,再结合 “页内偏移” 得到最终物理地址(物理地址 = 块号 × 页大小 + 页内偏移)。
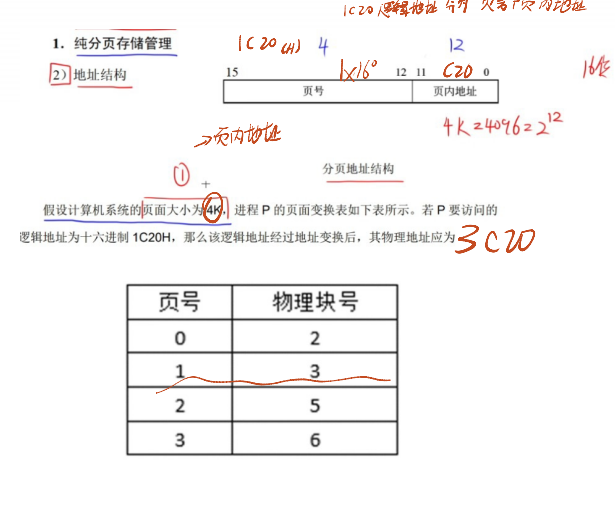
- 核心优势:无需将整个进程加载到内存,只需加载当前执行的页,节省内存空间;内存分配时只需分配空闲块,管理简单。
3.1.2 页面置换算法
当进程需要的页不在内存(称为 “缺页”)时,需从外存调入内存,若内存无空闲块,需 “置换” 已在内存的页,常用算法如下:
- 最优算法(OPT):理论最优算法,选择 “未来最长时间内不被访问的页” 置换 —— 能最小化缺页率,但无法实现(需预知未来页面访问顺序),仅用于衡量其他算法的性能。
- 先进先出算法(FIFO):选择 “最早调入内存的页” 置换,实现简单。但存在 “Belady 异常”—— 当内存块数量增加时,缺页率反而升高(例如,页面访问序列为 “1,2,3,4,1,2,5,1,2,3,4,5”,内存块从 3 增加到 4,缺页率反而上升)。
- 最近最少使用算法(LRU):选择 “最近一段时间内最少被访问的页” 置换,符合 “局部性原理”(进程近期访问的页面,未来仍可能访问)。例如,页面访问序列为 “1,2,3,4,1,2,5”,内存块为 3 时,LRU 会置换 “3”(最近最少访问),缺页率低于 FIFO,无 Belady 异常,是实际中常用的算法。
3.1.3 快表
快表是 “高速缓冲存储器(Cache)中的页表”,用于加速地址转换,具体如下:
- 问题背景:传统页表存储在内存中,地址转换需 “访问内存查页表→访问内存取数据” 两次内存访问,速度慢。
- 快表原理:将当前访问频繁的 “页号 - 块号” 对应关系存入快表(容量小,如 64 项、128 项,访问速度是内存的 10-100 倍)。地址转换时,先查快表:
- 若找到对应页号(快表命中):直接获取块号,结合页内偏移得到物理地址,只需一次内存访问(取数据)。
- 若未找到(快表未命中):访问内存查页表,获取块号后更新快表(替换不常用的项),再进行数据访问。
- 核心优势:大幅减少地址转换的时间,提升系统运行效率。
3.2 段式存储管理
段式存储管理按 “进程的逻辑结构” 划分 “段”,而非固定大小的页,具体如下:
3.2.1 基本原理
- 分段划分:按进程的逻辑功能划分段,如 “代码段”(存储程序指令)、“数据段”(存储常量、变量)、“堆栈段”(存储函数调用信息、局部变量)—— 每个段的大小不同,由逻辑功能决定,用 “段号” 标识(如 0、1、2...)。
- 地址转换:
- 逻辑地址格式:“段号 + 段内偏移”—— 例如,逻辑地址为 16 位,段内偏移最大为 4KB(2¹²),则段号占 4 位(标识 0-15 号段),段内偏移占 12 位(标识段内 0-4095 字节)。
- 段表:每个进程有一张 “段表”,记录 “段号、段基址(段在内存的起始地址)、段长(段的大小)”。地址转换时,先查段表:
- 检查段内偏移是否超过段长 —— 若超过,触发 “段越界中断”(非法访问)。
- 若合法,物理地址 = 段基址 + 段内偏移。
- 核心优势:符合进程的逻辑结构,程序模块化清晰(如修改代码段时不影响数据段);便于共享(如多个进程共享同一代码段,无需重复加载)。
3.2.2 优缺点
- 优点:
- 程序逻辑完整性好,模块间独立性强,便于维护和修改。
- 支持段的共享和保护(如代码段设为 “只读”,防止被修改)。
- 缺点:
- 内存利用率低,易产生 “外部碎片”(段大小不同,内存中无法利用的小空闲块)。
- 段的大小可能超过物理内存,需依赖虚拟内存技术。
3.3 段页式存储管理
段页式存储管理结合 “段式的逻辑完整性” 和 “页式的内存高效利用”,流程为 “先分段、后分页”,具体如下:
3.3.1 基本原理
- 分段:将进程按逻辑功能分为多个段(如代码段、数据段),每个段有段号。
- 分页:将每个段进一步划分为固定大小的页(与物理内存块大小相同),每个页有页号。
- 地址转换:
- 逻辑地址格式:“段号 + 段内页号 + 页内偏移”。
- 地址转换步骤:
- 查 “段表”:根据段号获取该段的 “页表基址”(段的页表在内存的起始地址)。
- 查 “段的页表”:根据段内页号获取对应的 “物理块号”。
- 计算物理地址:物理块号 × 页大小 + 页内偏移。
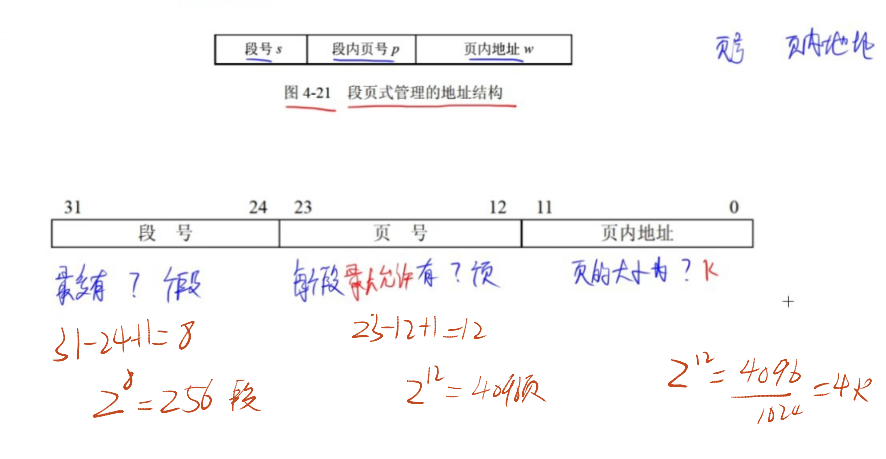
- 核心结构:系统需维护 “段表” 和 “每个段的页表”—— 段表记录段的页表基址,页表记录页与块的对应关系。
3.3.2 优缺点
- 优点:
- 结合段式和页式的优势:既符合进程逻辑结构(便于维护、共享),又避免外部碎片(分页管理内存),空间浪费小。
- 缺点:
- 管理复杂:需维护段表和多个页表,地址转换需多次查表(段表→页表),执行速度慢。
- 系统开销大:表格存储、地址转换都需更多资源。
4. 设备管理
设备管理负责 “外部设备的分配、驱动、I/O 控制”,核心包括设备分类、I/O 软件层次、输入输出技术、虚设备技术、磁盘管理,具体如下:
4.1 设备的分类方式
根据不同维度,外部设备可分为以下几类:
按数据组织分类:
- 块设备:以 “块” 为单位传输数据,块大小固定(如 512 字节、4KB),存储容量大,可随机访问。例如,硬盘、U 盘、光盘 —— 用户读取文件时,按块读取数据,可直接定位到任意块。
- 字符设备:以 “字符” 为单位传输数据,无固定块大小,不可随机访问,通常为输入 / 输出设备。例如,键盘(按字符输入)、鼠标(按坐标传输)、打印机(按字符或行打印)。
按资源分配角度分类:
- 独占设备:同一时间只能被一个进程使用,使用后释放。例如,打印机、扫描仪 —— 若多个进程同时使用打印机,会导致打印内容混乱,需独占使用。
- 共享设备:可被多个进程同时使用,通过分时技术实现。例如,硬盘、U 盘 —— 多个进程可同时读取硬盘中的不同文件,操作系统通过调度确保数据不冲突。
- 虚拟设备:通过 “SPOOLING 技术” 将独占设备虚拟为共享设备,多个进程可 “同时” 使用。例如,虚拟打印机 —— 多个进程将打印任务放入输出井,打印机按顺序打印,每个进程感觉在使用专属打印机。
按数据传输速率分类:
- 低速设备:传输速率低(通常为字节 / 秒或千字节 / 秒),响应时间长。例如,键盘(10-100 字符 / 秒)、鼠标、打印机(几页 / 分钟)。
- 中速设备:传输速率中等(通常为千字节 / 秒或兆字节 / 秒)。例如,扫描仪(几兆字节 / 秒)、U 盘(几十兆字节 / 秒)。
- 高速设备:传输速率高(通常为兆字节 / 秒或千兆字节 / 秒),响应时间短。例如,硬盘(几百兆字节 / 秒)、固态硬盘(上千兆字节 / 秒)、网卡(千兆 / 秒)。
4.2 I/O 软件层次结构
I/O 软件从 “用户进程” 到 “硬件” 分为五层,每层负责不同功能,逐层协作完成 I/O 操作,具体如下:
| 层次 | 核心功能 | 示例 |
|---|---|---|
| 用户进程层 | 发起 I/O 请求,处理 I/O 结果(如读取键盘输入、显示文件内容) | 文档软件发起 “读取文件” 请求,音乐软件发起 “播放音频” 请求 |
| 设备无关软件层 | 提供统一的 I/O 接口,屏蔽设备差异;负责文件命名、缓冲管理、设备分配 | 为不同品牌的打印机提供统一的 “打印” 接口,用户无需关注打印机型号;设置缓冲区,暂存 I/O 数据,减少硬件访问次数 |
| 设备驱动程序层 | 与硬件直接交互,将上层请求转换为硬件指令;控制设备寄存器,检查设备状态 | 打印机驱动程序将 “打印文档” 请求转换为打印机能识别的指令(如打印分辨率、纸张大小);硬盘驱动程序控制硬盘磁头移动 |
| 中断处理程序层 | 当 I/O 操作完成(如文件读取完成、打印完成),触发中断,唤醒对应的设备驱动程序;保存 / 恢复 CPU 上下文 | 硬盘读取完成后,触发中断,中断处理程序唤醒硬盘驱动程序,通知其处理读取到的数据 |
| 硬件层 | 执行具体的 I/O 操作(如磁盘读写、键盘信号采集) | 硬盘磁头移动到指定磁道,读取数据;键盘采集用户按下的键,生成信号 |
4.3 输入输出技术
输入输出技术是 “CPU 与外设之间数据传输的方式”,根据效率和复杂度分为三类:
程序控制(查询)方式:
- 原理:CPU 主动、循环查询外设的 “就绪状态”—— 若外设未就绪(如打印机未准备好),CPU 继续查询;若就绪,CPU 执行数据传输(如将数据写入打印机缓存)。
- 特点:实现简单,无需复杂硬件支持;但 CPU 利用率极低 ——CPU 大部分时间在 “等待外设就绪”,无法执行其他任务。例如,早期的简单打印机控制,CPU 需一直查询打印机状态,期间不能做其他操作。
程序中断方式:
- 原理:CPU 发起 I/O 请求后,继续执行其他任务;外设完成 I/O 操作后,向 CPU 发送 “中断信号”;CPU 收到中断后,暂停当前任务,处理 I/O 结果(如读取外设传输的数据),处理完成后返回原任务。
- 特点:CPU 利用率高(无需等待外设),响应及时;适用于实时性要求较高的场景(如键盘、鼠标)。例如,用户通过键盘输入字符时,CPU 发起 “读取键盘” 请求后继续执行其他任务;键盘输入完成后触发中断,CPU 处理输入的字符,处理完后回到原任务。
- 关键概念:
- 中断响应时间:从外设发送中断信号到 CPU 开始处理中断的时间(包括保存 CPU 上下文、查找中断服务程序地址)。
- 中断处理时间:CPU 处理中断的时间(如读取数据、通知上层程序)。
- 中断向量:存储中断服务程序入口地址的表格,CPU 通过中断向量快速找到对应中断的处理程序。
DMA 方式(直接主存存取):
- 原理:CPU 仅负责 “初始化 I/O 请求”(如指定数据传输的源地址、目标地址、传输长度),之后数据传输由 “DMA 控制器” 直接完成(无需 CPU 干预);DMA 完成传输后,向 CPU 发送中断,CPU 处理后续工作(如释放 DMA 资源)。
- 特点:CPU 利用率极高(仅初始化和处理中断时参与),数据传输速度快;适用于高速外设(如硬盘、网卡)。例如,读取硬盘文件时,CPU 初始化 DMA(指定硬盘扇区、内存地址、传输字节数)后继续执行其他任务;DMA 控制器直接将硬盘数据传输到内存,完成后触发中断,CPU 通知文件系统处理数据。
- 响应时机:CPU 在 “总线周期结束时” 响应 DMA 请求(总线周期是 CPU 访问内存或外设的基本单位);而程序中断方式在 “指令执行结束时” 响应 ——DMA 响应更及时,适合高速数据传输。
缓冲技术
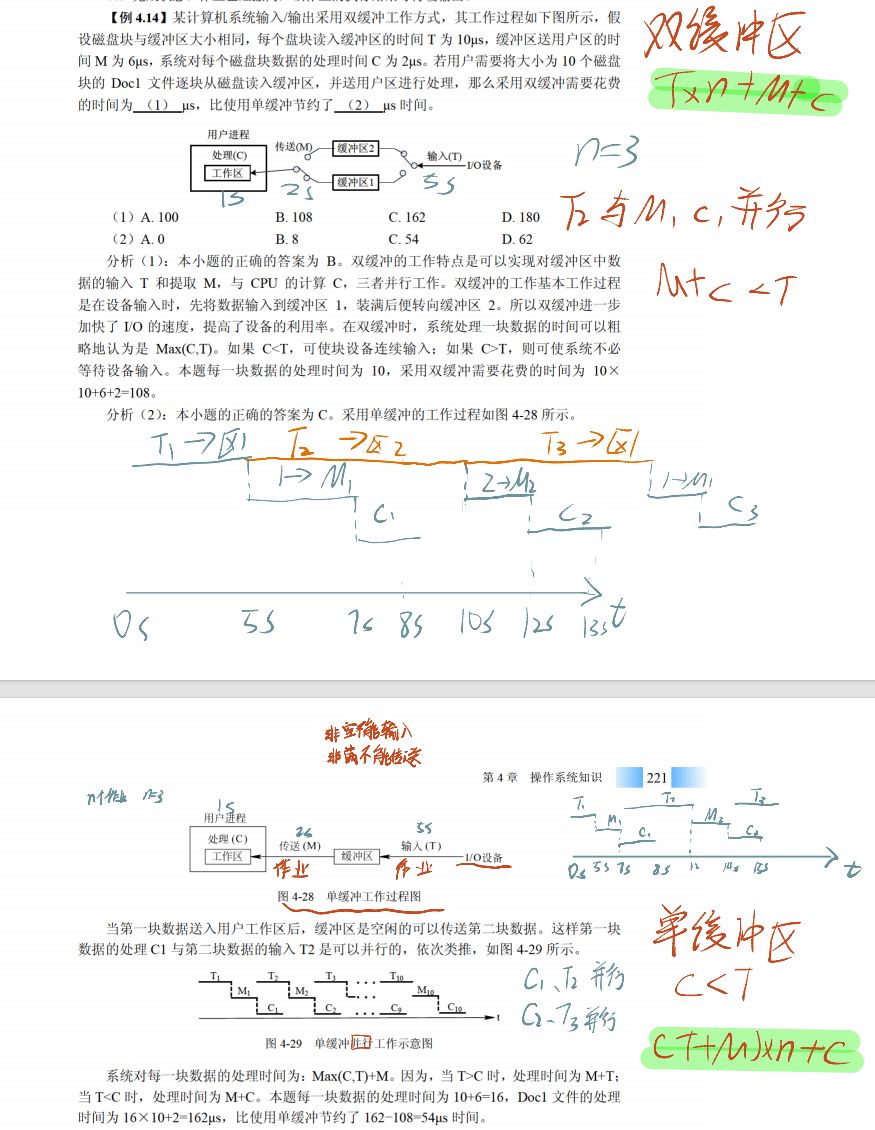
4.4 磁盘结构与调度
磁盘是计算机主要的外存设备,其结构和调度算法直接影响数据读写速度,具体如下:
4.4.1 磁盘物理结构
磁盘的物理结构由 “盘面、磁道、扇区” 组成,具体如下:
- 盘面:磁盘通常有多个盘片,每个盘片有两个盘面(正面和反面),每个盘面有一个 “磁头”(用于读取 / 写入数据)。例如,一个硬盘有 4 个盘片,共 8 个盘面,对应 8 个磁头。
- 磁道:每个盘面上的 “同心圆” 称为磁道,从外向内编号(如 0、1、2...)。磁道之间有间隙,避免数据干扰。
- 扇区:每个磁道被划分为多个 “扇区”,是磁盘的最小存储单位(通常为 512 字节、4KB),扇区按圆周方向编号(如 0、1、2...)。例如,一个磁道有 64 个扇区,每个扇区 512 字节,则一个磁道可存储 64×512=32KB 数据。
- 柱面:所有盘面上 “半径相同的磁道” 组成一个柱面 —— 磁头移动时,所有磁头同步移动到同一柱面的不同磁道,减少寻道时间。
4.4.2 磁盘读写时间组成
磁盘读写数据的时间由三部分组成,其中 “寻道时间” 占比最大,是优化的关键:
- 寻道时间:磁头从当前磁道移动到目标磁道所需的时间(通常为几毫秒到几十毫秒)—— 是磁盘读写时间的主要部分,磁头移动距离越远,寻道时间越长。
- 旋转延迟时间:磁盘旋转,使目标扇区转到磁头下方所需的时间(通常为几毫秒)—— 取决于磁盘转速(如 7200 转 / 分钟的磁盘,旋转一圈需 8.3 毫秒,平均旋转延迟为 4.15 毫秒)。
- 传输时间:磁头读取 / 写入扇区数据的时间(通常为微秒级)—— 取决于数据量和磁盘转速,数据量越小、转速越快,传输时间越短。
4.4.3 磁盘调度算法
磁盘调度算法的目标是 “减少寻道时间”,提高磁盘读写效率,常用算法如下:
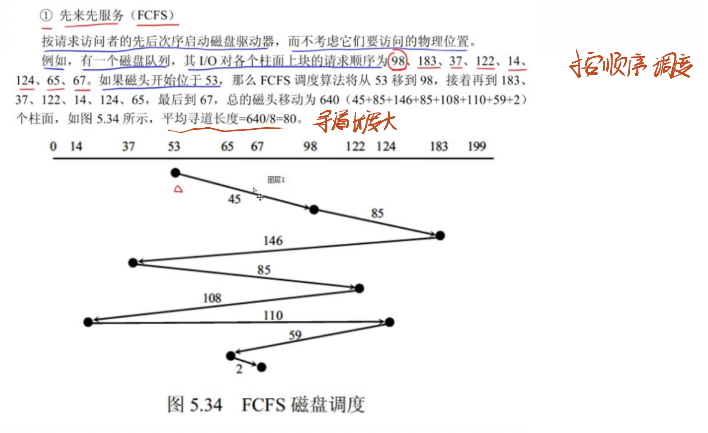
先来先服务(FCFS):
- 原理:按进程请求访问磁盘的 “先后顺序” 调度磁头。例如,请求序列为 “磁道 10→磁道 20→磁道 5”,磁头从当前磁道(如 0)先到 10,再到 20,最后到 5。
- 优点:实现简单,公平对待所有请求;缺点:寻道时间长(可能频繁在远磁道间移动),效率低,适用于请求量少的场景。
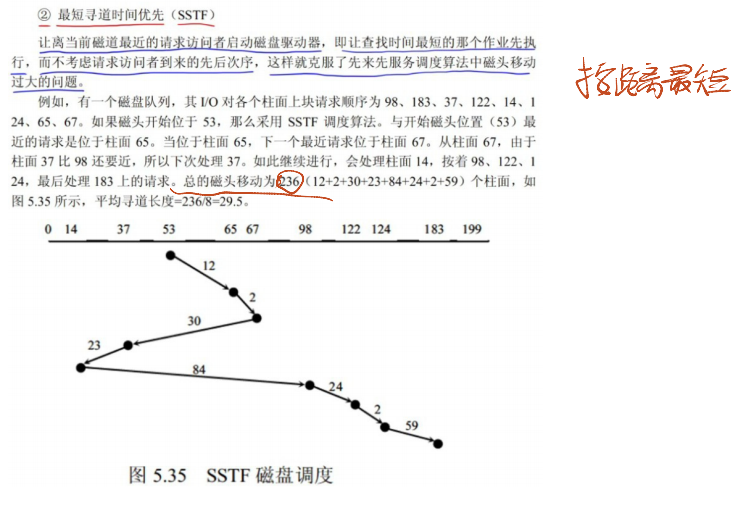
最短寻道时间优先(SSTF):
- 原理:选择 “与当前磁道距离最近的请求” 调度,最小化每次寻道时间。例如,当前磁道为 10,请求序列为 “20→5→25”,SSTF 先调度 5(距离 5),再调度 20(距离 15),最后调度 25(距离 5)。
- 优点:平均寻道时间短,效率高于 FCFS;缺点:可能导致 “饥饿”—— 远磁道的请求长期得不到调度(如频繁有近磁道请求,远磁道请求一直被忽略)。
扫描算法(SCAN,“电梯算法”):
- 原理:磁头沿一个方向(如从外向内)移动,途中处理所有经过磁道的请求;到达最内磁道后,反向(从内向外)移动,继续处理请求,类似电梯上下运行。例如,当前磁道为 10,方向向外,请求序列为 “5→20→15→25”,磁头先到 5(处理请求),再到 0(最内磁道),反向后到 15(处理)、20(处理)、25(处理)。
- 优点:无饥饿问题(所有请求都会被处理),平均寻道时间短;缺点:磁头到达边界后需反向,可能增加部分请求的等待时间。

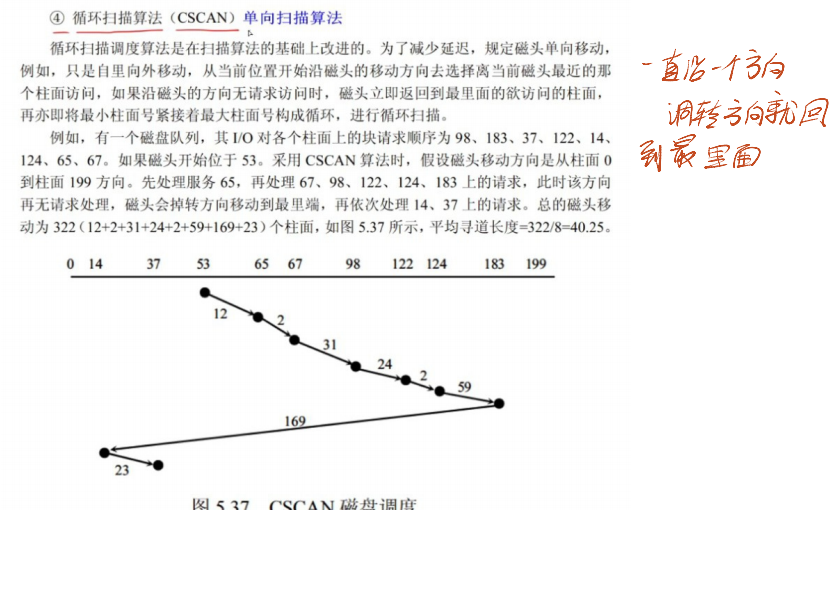
单向扫描调度算法(CSCAN):
- 原理:磁头仅沿一个方向(如从外向内)移动,途中处理请求;到达最内磁道后,直接跳转到最外磁道(不处理途中请求),继续沿原方向移动处理请求。例如,当前磁道为 10,方向向外,请求序列为 “5→20→15→25”,磁头先到 5(处理)、0(最内),跳转到最外磁道(如 30),再到 15(处理)、20(处理)、25(处理)。
- 优点:请求的等待时间更均匀(避免反向时的等待);缺点:磁头跳转时浪费时间,适用于对等待时间均匀性要求高的场景(如服务器磁盘)。
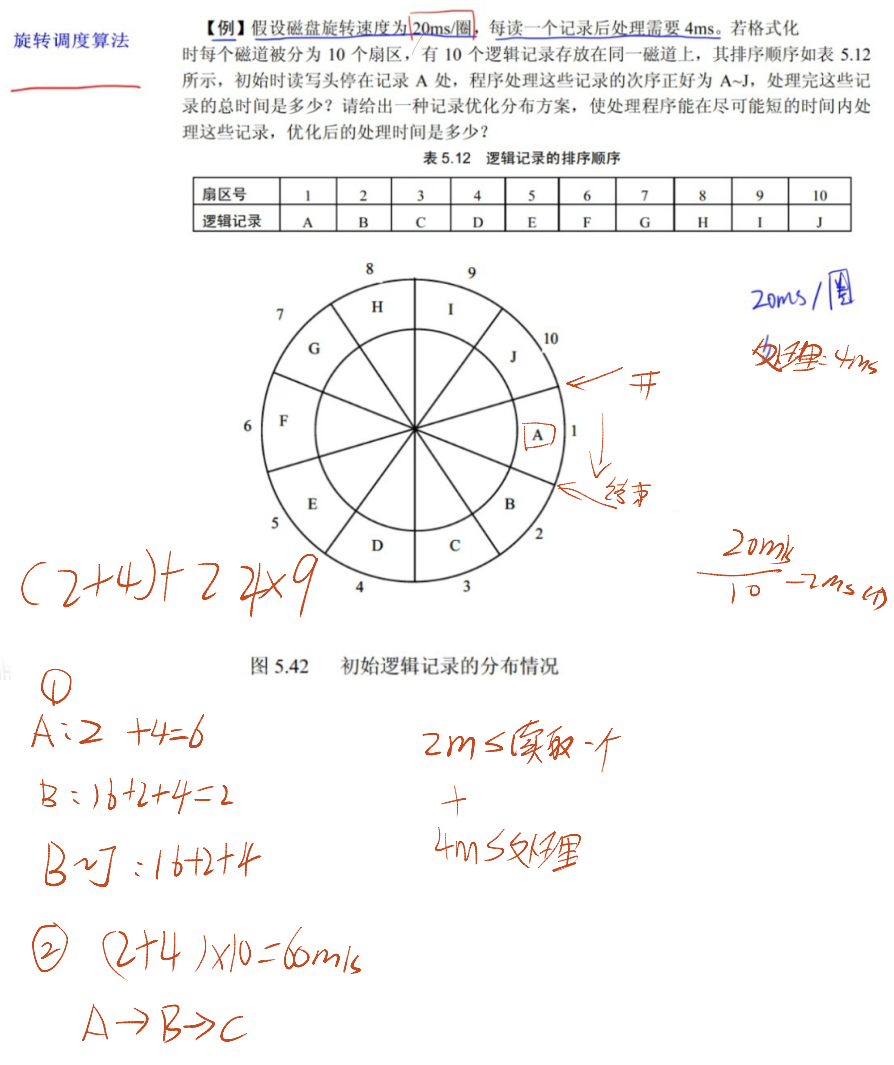
4.5 旋转调度算法
5. 文件管理
文件管理负责 “文件的组织、存储、访问”,核心包括文件结构、目录管理、空闲空间管理,具体如下:
5.1 文件结构
文件结构指 “文件数据在磁盘上的存储方式”,常用 “索引文件结构”,通过 “索引节点” 管理文件数据,具体如下:
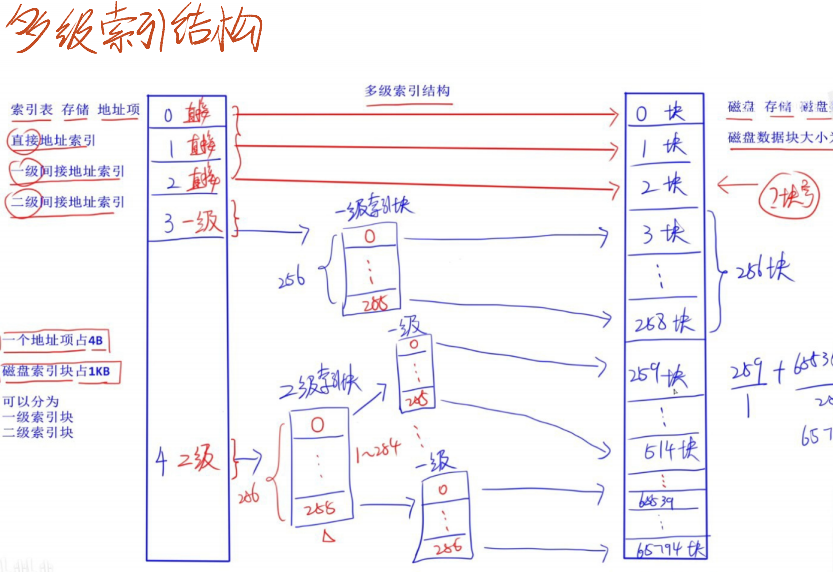
- 索引节点(inode):每个文件有一个索引节点,存储文件的关键信息 —— 包括文件大小、创建时间、权限、数据块的地址等。系统通过索引节点定位文件数据,而非文件名(文件名与索引节点通过目录关联)。
- 13 个索引节点的分工(以 Unix/Linux 系统为例):
- 0-9 号索引节点:直接索引 —— 存储文件数据块的物理地址,每个节点对应一个数据块(如每个数据块 4KB)。若文件小于 40KB(10×4KB),只需通过直接索引就能定位所有数据块,访问速度快。
- 10 号索引节点:一级间接索引 —— 不直接存储数据块地址,而是存储 “间接块的地址”,间接块中存储多个数据块地址(如间接块 4KB,每个地址 4 字节,可存储 1024 个数据块地址)。一级间接索引可管理 1024×4KB=4096KB(4MB)的数据。
- 11 号索引节点:二级间接索引 —— 存储 “一级间接块的地址”,一级间接块存储 “二级间接块的地址”,二级间接块存储数据块地址。可管理 1024×1024×4KB=4096MB(4GB)的数据。
- 12 号索引节点:三级间接索引 —— 存储 “二级间接块的地址”,可管理 1024×1024×1024×4KB=4TB 的数据(适用于超大文件)。
- 核心优势:支持不同大小的文件,小文件通过直接索引快速访问,大文件通过多级间接索引扩展存储容量。
5.2 文件目录

5.3 树形文件目录
树形文件目录采用 “树状结构” 组织文件和文件夹,便于用户分类管理和访问,具体如下:
- 核心概念:
- 根目录:树的 “根节点”,是所有文件和文件夹的起点(如 Windows 的 “C 盘”“D 盘”,Linux 的 “/”)。
- 子目录(文件夹):树的 “中间节点”,用于分类存储文件或其他子目录(如 “文档” 文件夹下的 “工作文档”“学习文档”)。
- 文件:树的 “叶子节点”,存储具体数据(如 “报告.docx”“照片.jpg”)。
- 路径表示:
- 绝对路径:从根目录开始的完整路径,唯一标识文件位置。例如,Windows 系统中 “C:\ 用户 \ 张三 \ 文档 \ 报告.docx”,Linux 系统中 “/home/zhangsan/doc/report.docx”。
- 相对路径:从 “当前目录” 开始的路径,依赖当前所在位置。例如,当前目录为 “C:\ 用户 \ 张三”,则 “文档 \ 报告.docx” 是相对路径,等价于绝对路径 “C:\ 用户 \ 张三 \ 文档 \ 报告.docx”。
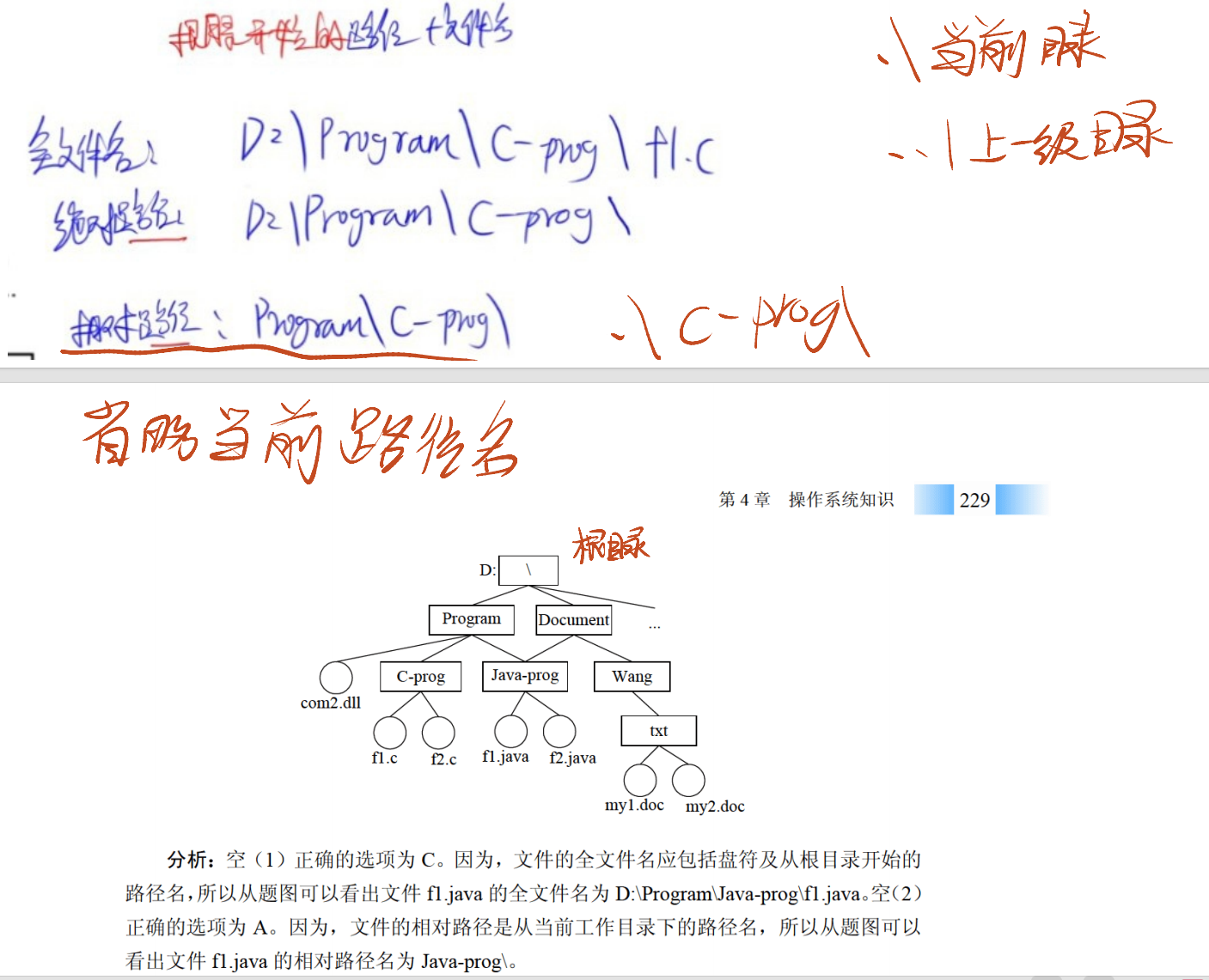
- 全文件名:绝对路径 + 文件名,用于唯一定位文件。例如,全文件名为 “C:\ 用户 \ 张三 \ 文档 \ 报告.docx”,其中 “C:\ 用户 \ 张三 \ 文档” 是绝对路径,“报告.docx” 是文件名。
- 文件属性:每个文件有属性标识,常见属性如下:
- R(只读):文件只能读取,不能修改或删除。
- A(存档):文件已存档,备份软件会识别该属性决定是否备份。
- S(系统):系统文件,默认隐藏,用于系统运行(如 Windows 的 “ntoskrnl.exe”)。
- H(隐藏):默认不显示,需手动设置 “显示隐藏文件” 才能看到。
5.4 空闲存储空间管理
空闲存储空间管理负责 “记录和分配磁盘中的空闲空间”,避免空间浪费,常用方法如下:
空闲区表法:
- 原理:用一张 “空闲区表” 记录所有空闲空间的信息,包括 “空闲区起始地址、空闲区大小、状态(空闲 / 已分配)”。
- 分配:当需要分配空间时,按 “首次适应”“最佳适应” 等策略从空闲区表中选择合适的空闲区 —— 例如,首次适应策略选择 “第一个大小满足需求的空闲区”。
- 回收:当文件删除释放空间时,检查相邻空间是否空闲,若空闲则合并为一个大空闲区,更新空闲区表。
- 优点:实现简单,适用于空闲区数量少的场景;缺点:空闲区表占用内存,空闲区数量多时查询效率低。
空闲链表法:
- 原理:将所有空闲区用 “链表” 连接,每个空闲区节点存储 “空闲区起始地址、大小、下一个空闲区节点地址”。
- 分配:遍历链表,找到大小满足需求的空闲区,分割后更新链表(剩余部分仍为空闲区节点)。
- 回收:将释放的空间节点插入链表,检查相邻节点是否空闲,若空闲则合并节点。
- 优点:无需存储整张表,内存占用少;缺点:遍历链表效率低,适用于中小规模磁盘。
成组链接法:
- 原理:结合 “空闲区表法” 和 “空闲链表法”,将空闲区分为多组,每组用链表连接,同时用 “组描述符” 记录每组的起始地址和空闲区数量。
- 分配:先从当前组中分配空闲区,当前组无空闲区时,加载下一组的组描述符,继续分配。
- 回收:将释放的空间加入当前组,当前组满时,新建一组并更新组描述符。
- 优点:兼顾效率和内存占用,适用于大规模磁盘(如 Unix 系统采用此方法)。
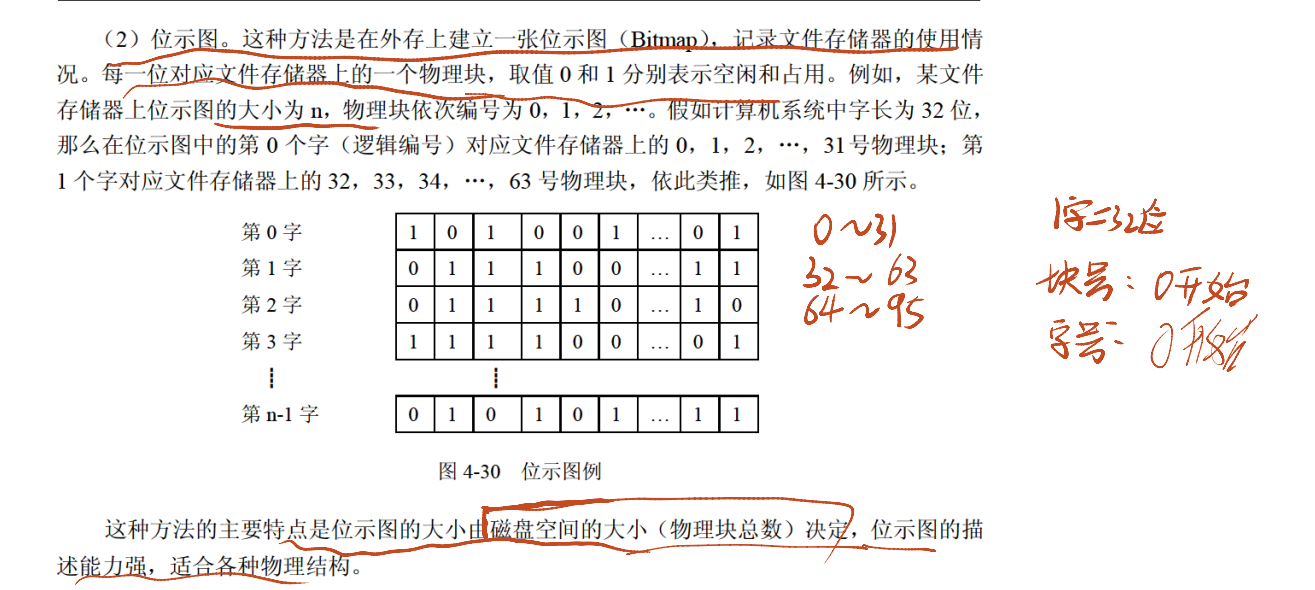
位示图法:
- 原理:用 “位(bit)” 表示磁盘块的状态 ——1 表示 “已分配”,0 表示 “空闲”。例如,磁盘有 1024 个块,需 1024 位(128 字节)的位示图记录状态。
- 分配:查找位示图中值为 0 的位,将其设为 1,计算对应的磁盘块地址(磁盘块地址 = 位的位置 × 块大小)。
- 回收:找到文件对应的磁盘块位,将其设为 0,更新位示图。
- 优点:查询速度快(可按位运算快速找到空闲块),内存占用少;缺点:需预先计算位与磁盘块的对应关系。