Redis哈希表渐进式rehash深度解析:为何百万数据迁移不阻塞服务?
在Redis的底层数据结构中,哈希表(hashtable)是支撑Hash类型、Set类型等核心功能的基石。而哈希表的扩容/缩容过程中,数据迁移往往是性能瓶颈——传统哈希表的“一次性全量迁移”在面对百万级数据时,会导致服务阻塞数十甚至数百毫秒,这对追求亚毫秒级响应的Redis来说是无法接受的。
为解决这一痛点,Redis设计了渐进式rehash机制,通过“分批次迁移+业务操作联动”的方式,将数据迁移的成本分摊到每次请求中,实现“边服务边迁移”的平滑过渡。这一机制不仅是Redis高可用性的核心保障,更是面试中的高频考点,其设计思想对日常开发也极具借鉴意义。本文将从触发条件、实现流程、异常处理到设计启示,全方位拆解渐进式rehash的核心逻辑。
一、前置知识:哈希表的核心困境与rehash的意义
在深入渐进式rehash之前,我们需要先明确:为何哈希表需要rehash?
Redis的哈希表采用“数组+链表”的链地址法解决哈希冲突,其性能依赖于负载因子(负载因子 = 已存储节点数used / 哈希表数组大小size)的合理控制:
- 负载因子过高:数组空间紧张,哈希冲突加剧,链表长度激增,查询性能从O(1)退化到O(n);
- 负载因子过低:数组空间闲置过多,内存浪费严重。
rehash(重新哈希)就是通过调整哈希表数组大小,将旧表中的数据重新计算哈希值后迁移到新表,从而将负载因子维持在合理范围。而渐进式rehash的核心目标,就是解决“rehash过程中服务阻塞”的问题。
二、触发条件:rehash何时会启动?
Redis会根据负载因子的阈值判断是否触发rehash,同时结合持久化操作动态调整阈值,平衡性能与内存开销。rehash分为“扩容”和“缩容”两种场景,触发条件各不相同。
2.1 扩容触发条件:规避链表过长的性能退化
扩容的核心目的是降低负载因子,减少哈希冲突。触发条件分为两种情况,主要受持久化操作(BGSAVE、BGREWRITEAOF)影响:
- 无持久化操作时:负载因子 ≥ 1 时触发扩容。此时内存无额外开销压力,可及时扩容保证性能;
- 有持久化操作时:负载因子 ≥ 5 时才触发扩容。原因是持久化会fork子进程,子进程会共享父进程的内存页。若频繁扩容导致内存写入,会触发“写时复制”机制,增加内存占用,因此Redis会提高阈值减少扩容频率。
扩容后的新表大小遵循“2的幂次”规则——新表size是第一个大于等于 2 * used 的2的幂次。例如:
- 旧表size=4,used=4 → 新表size=8(2*4=8,恰好是2的幂次);
- 旧表size=8,used=10 → 新表size=16(210=20,第一个大于20的2的幂次是32?不,2used=20,第一个大于等于20的2的幂次是32?不对,24=16,25=32,20介于两者之间,所以新表size=32?不,实际计算逻辑是“第一个大于等于used2的2的幂次”,used=10时used2=20,第一个大于20的2的幂次是32?是的。
2.2 缩容触发条件:避免内存资源浪费
当哈希表的负载因子 ≤ 0.1(默认阈值)时,触发缩容操作,释放冗余的内存空间。缩容后的新表大小是第一个大于等于 used 的2的幂次。例如:
- 旧表size=16,used=1 → 新表size=2(第一个大于1的2的幂次);
- 旧表size=8,used=3 → 新表size=4(第一个大于3的2的幂次)。
三、核心流程:渐进式rehash如何实现“边服务边迁移”?
传统哈希表的rehash是“一次性全量迁移”,而Redis的渐进式rehash通过“四步走”的流程,将迁移成本分摊到每次业务操作中,核心依赖于“双哈希表并行”和“rehashidx标识”两大设计。
3.1 步骤1:初始化新表,标记迁移开始
当触发rehash条件后,Redis会先创建一个新的哈希表ht[1](Redis的dict结构中维护了ht[0]和ht[1]两个哈希表,ht[0]为旧表,ht[1]为新表),并将全局标识rehashidx设为0——这个标识非常关键,-1表示无rehash操作,≥0时表示当前正在迁移的“桶(bucket)索引”。
核心逻辑简化如下(基于Redis源码伪代码):
// 获取Hash类型对应的dict结构
dict *d = hash_key->dict;
// 计算新表大小并创建新哈希表ht[1]
unsigned long new_size = calculate_new_size(d->ht[0].used, is_expand);
d->ht[1] = dictCreate(new_size);
// 标记rehash开始,从0号桶开始迁移
d->rehashidx = 0;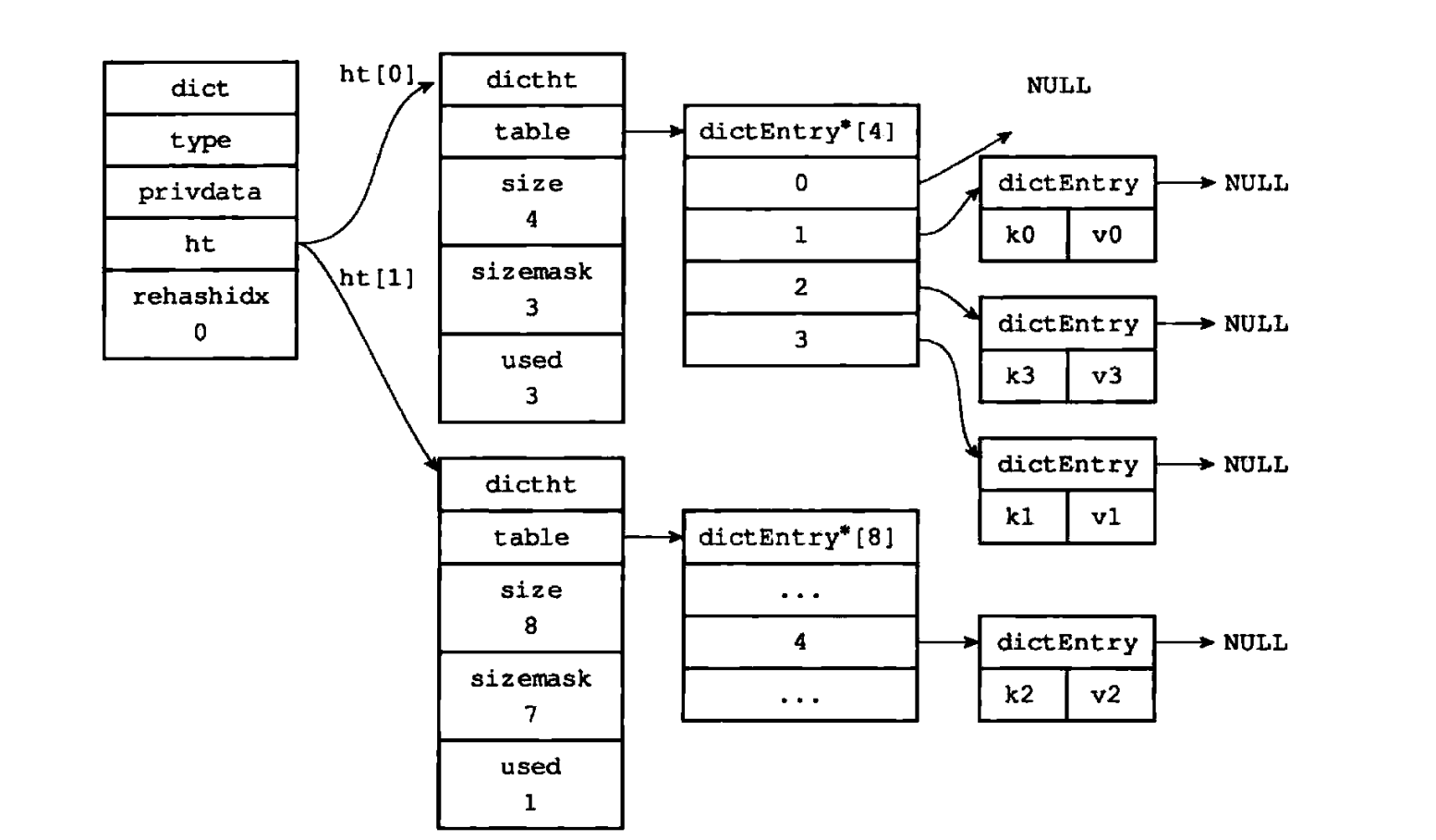
3.2 步骤2:借业务操作,渐进迁移数据
这是渐进式rehash的核心环节——Redis不主动批量迁移数据,而是在每次对该哈希表执行“增删改查”操作时,“顺手”迁移rehashidx指向的那个桶的所有数据。迁移完成后,rehashidx自增1,逐步推进迁移进度。
为了防止长时间无业务操作导致迁移停滞,Redis还会在后台定时任务中主动迁移一部分桶的数据,确保迁移能在合理时间内完成。
迁移的核心逻辑简化如下:
// n:本次要迁移的桶数量,业务操作触发时n=1,定时任务触发时n更大
void dictRehash(dict *d, int n) {// 当旧表无数据或迁移次数耗尽时退出while (n-- && d->ht[0].used > 0) {// 跳过空桶,减少无效操作if (d->ht[0].table[d->rehashidx] == NULL) {d->rehashidx++;continue;}// 迁移当前rehashidx指向的桶的所有键值对到新表ht[1]migrate_single_bucket(d, d->rehashidx);// 迁移完成,处理下一个桶d->rehashidx++;}
}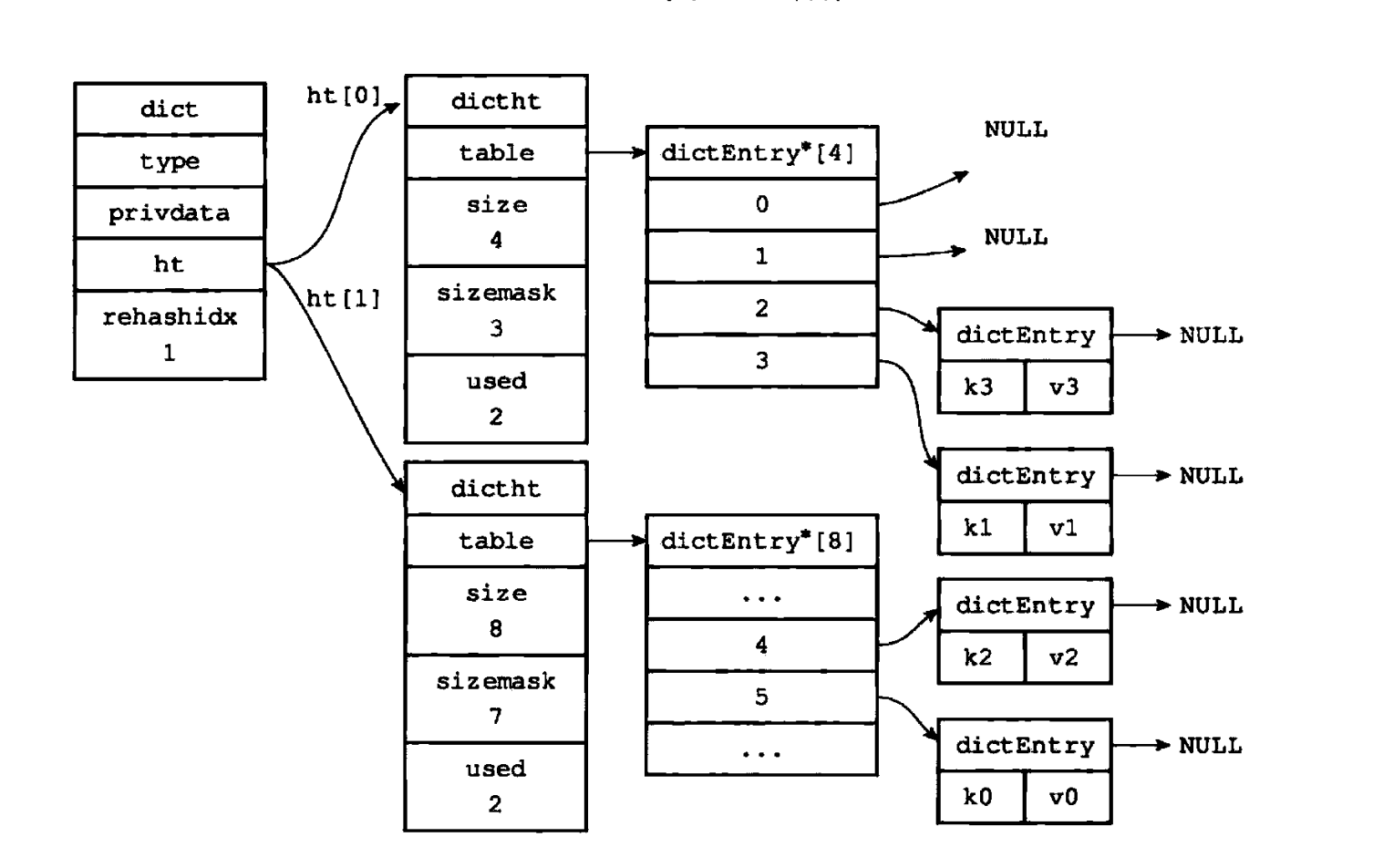
举个例子:当客户端执行HGET user:100 name时,Redis会先调用dictRehash(d, 1)迁移1个桶的数据,再执行查询操作。若有100万个数据分布在10万个桶中,就会通过10万次业务操作逐步完成迁移,单次迁移仅耗时微秒级,完全不影响服务响应。
3.3 步骤3:rehash期间的请求处理规则
rehash期间,Redis会同时维护ht[0](旧表)和ht[1](新表)两个哈希表,为了保证数据一致性和服务可用性,针对不同类型的请求制定了差异化的处理规则:
| 请求类型 | 处理逻辑 | 设计原因 |
| 查询操作(HGET、HMGET) | 先查询旧表ht[0],未找到则查询新表ht[1] | 保证数据不遗漏,迁移过程中数据可能分散在两个表中 |
| 新增操作(HSET、HMSET) | 直接写入新表ht[1] | 避免旧表刚迁移完又新增数据,减少重复迁移的开销 |
| 删除/更新操作(HDEL、HSET) | 同时操作旧表和新表,存在则执行对应操作 | 保证数据一致性,防止某张表中的数据未被处理 |
3.4 步骤4:迁移完成,新表替换旧表
当rehashidx的值超过旧表ht[0]的数组大小(即所有桶都已迁移完成)时,rehash进入收尾阶段:
- 释放旧表
ht[0]的内存空间,回收资源; - 将新表
ht[1]的地址赋值给ht[0],使新表成为主哈希表; - 重置
ht[1]为空表,等待下一次rehash使用; - 将
rehashidx设为-1,标记rehash过程正式结束。
核心逻辑简化如下:
// 释放旧表内存
zfree(d->ht[0].table);
// 新表替换旧表
d->ht[0] = d->ht[1];
// 重置新表为初始状态
dictReset(&d->ht[1]);
// 标记rehash结束
d->rehashidx = -1;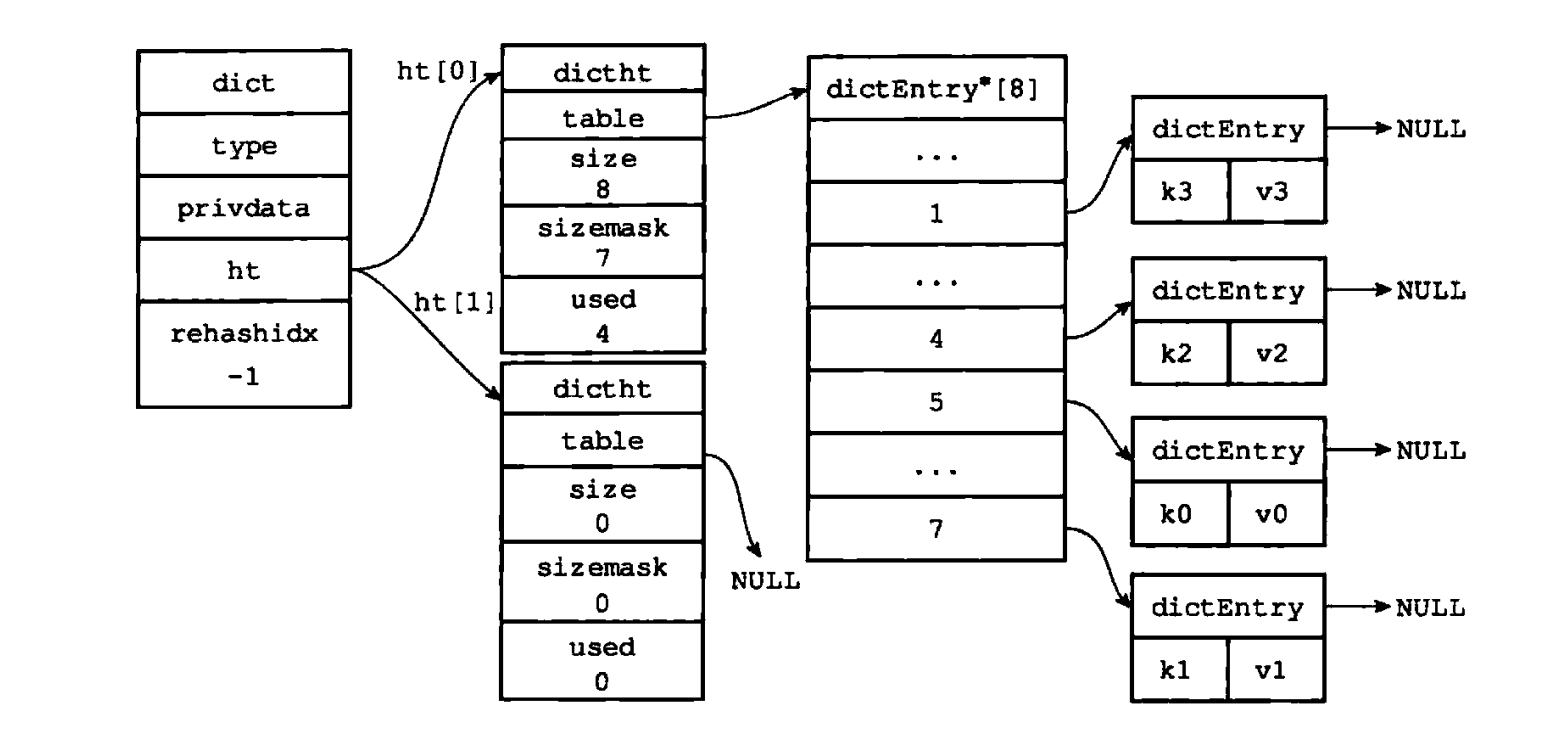
四、异常场景:渐进式rehash如何应对突发状况?
在实际运行中,rehash过程可能会遇到服务崩溃、持久化介入等异常场景,Redis通过针对性的设计保证了机制的稳定性。
4.1 服务崩溃:数据一致性如何保障?
若rehash期间Redis服务意外崩溃,由于新表ht[1]中的数据仅存储在内存中,未被持久化到RDB或AOF文件,因此重启后Redis会丢弃ht[1],仅加载旧表ht[0]的数据,恢复为未rehash的状态。
这种设计虽然会导致未完成的rehash前功尽弃,但不会造成数据丢失——后续当负载因子再次达到阈值时,Redis会重新触发rehash流程,属于“牺牲效率换一致性”的合理取舍。
4.2 持久化介入:如何避开内存开销高峰?
若rehash过程中启动了BGSAVE或BGREWRITEAOF等持久化操作,Redis会暂停rehash流程,直到持久化操作完成后再恢复迁移。
原因是持久化会fork子进程,子进程会共享父进程的内存页。rehash过程中的数据迁移会修改内存数据,触发“写时复制”机制,导致父进程和子进程各自占用一份内存页,增加内存开销。暂停rehash可避免这一问题,待持久化完成后再继续迁移。
五、设计启示:渐进式思想的落地价值
Redis的渐进式rehash不仅解决了哈希表扩容缩容的性能问题,更向我们传递了一种重要的系统设计思想:对于耗时的大型操作,不要“一次性做完”,而是拆分成无数个“微操作”,分摊到业务流程中逐步完成,实现“平滑过渡”。
这种思想在日常开发中有着广泛的应用场景,例如:
- 数据库分库分表迁移:不一次性迁移所有数据,而是通过“双写同步+逐步切换流量”的方式,先让新旧库同时写入,再逐步将读流量切换到新库,最后停止旧库写入,实现平滑迁移;
- 大文件解析与导入:不一次性将大文件加载到内存解析,而是分块读取、分块解析、分块导入数据库,避免OOM(内存溢出)和服务阻塞;
- 缓存预热:不一次性加载所有缓存数据,而是通过定时任务分批次加载,或在用户请求时“顺手”加载对应的数据,避免系统启动时的性能抖动。
六、总结
Redis渐进式rehash核心可归纳为以下三点:
- 触发条件:能区分扩容和缩容的负载因子阈值,尤其是持久化对扩容阈值的影响;
- 实现流程:掌握“双哈希表并行+rehashidx标识+分步迁移”的核心逻辑;
- 请求处理:明确rehash期间不同类型请求的处理规则,以及异常场景的应对策略。
Redis的渐进式rehash机制,通过“分而治之”的思想,将原本可能阻塞服务的大型数据迁移操作,拆解为无数个微操作融入日常业务流程,完美平衡了性能与可用性。这一机制不仅体现了Redis底层设计的精妙,更为我们提供了应对“大型操作性能瓶颈”的经典思路——与其追求“一步到位”的高效,不如追求“步步为营”的平稳,这正是分布式系统设计中“可用性优先”理念的生动体现。