Prometheus(四)—— Alertmanager完整部署指南:邮件+钉钉告警全流程落地
文章目录
- 前言
- 一、环境准备
- 1.1 服务器角色与IP规划
- 1.2 操作系统与依赖工具
- 1.3 所需安装包及下载地址
- 1.4 网络与权限准备
- 二、Alertmanager核心概述
- 2.1 Prometheus与Alertmanager的协作关系
- 2.2 Alertmanager核心功能解析
- 三、Alertmanager邮件告警完整部署(192.168.10.17)
- 3.1 安装包上传与解压
- 3.2 配置Alertmanager邮件告警(alertmanager.yml)
- 3.3 配置Alertmanager系统服务(systemd)
- 3.4 定义Prometheus告警规则(Prometheus服务器:192.168.10.18)
- 3.5 关联Prometheus与Alertmanager(Prometheus服务器:192.168.10.18)
- 3.6 邮件告警功能测试
- 四、Alertmanager钉钉告警扩展部署(192.168.10.17)
- 4.1 钉钉告警插件(prometheus-webhook-dingtalk)部署
- 4.2 钉钉群机器人创建与配置
- 4.3 钉钉告警插件配置(config.yml)
- 4.4 启动钉钉告警插件
- 4.5 调整Alertmanager配置指向钉钉插件(192.168.10.17)
- 4.6 钉钉告警功能测试
- 补充:同时启动邮箱告警和钉钉告警
- 五、总结与注意事项
- 5.1 部署总结
- 5.2 关键注意事项
前言
在Prometheus监控体系中,告警功能是实现“监控-告警-响应”闭环的核心环节。很多小伙伴初次使用Prometheus时会发现,即便定义了告警规则也收不到通知——这是因为Prometheus Server仅负责生成告警,而具体的告警分发(如发邮件、推钉钉)需要由独立组件Alertmanager完成。
本文将从核心概念入手,带大家一步步部署Alertmanager,并实现邮件、钉钉两种主流渠道的告警通知,确保监控告警真正落地可用。
一、环境准备
在开始部署前,需确认服务器环境、网络权限及所需安装包,避免后续部署受阻。
1.1 服务器角色与IP规划
本次部署涉及两台核心服务器(可根据实际需求合并,建议生产环境分开部署以提高稳定性):
| 服务器角色 | IP地址 | 核心功能 | 需开放端口 |
|---|---|---|---|
| Alertmanager服务器 | 192.168.10.17 | 接收Prometheus告警、分发邮件/钉钉通知 | 9093(默认) |
| Prometheus服务器 | 192.168.10.18(示例) | 采集指标、定义告警规则、发送告警到Alertmanager | 9090(默认) |
| 钉钉插件服务器 | 192.168.10.17(与Alertmanager同机) | 对接钉钉机器人,转发Alertmanager告警 | 8060(默认) |
1.2 操作系统与依赖工具
- 操作系统:推荐
CentOS 7/8或Ubuntu 20.04 LTS(本文基于CentOS 7演示)。 - 依赖工具:需提前安装
tar(解压安装包)、vim(编辑配置文件)、netstat(查看端口)、systemd(管理服务),若未安装可执行以下命令:# CentOS系统安装依赖 yum install -y tar vim net-tools # Ubuntu系统安装依赖 apt update && apt install -y tar vim net-tools
1.3 所需安装包及下载地址
| 组件名称 | 版本 | 下载地址 |
|---|---|---|
| Alertmanager | 0.24.0 | https://github.com/prometheus/alertmanager/releases/tag/v0.24.0 |
| prometheus-webhook-dingtalk | 2.1.0 | https://github.com/timonwong/prometheus-webhook-dingtalk/releases/tag/v2.1.0 |
| Prometheus(已部署前提) | 2.x及以上(示例2.35.0) | https://github.com/prometheus/prometheus/releases |
1.4 网络与权限准备
1、关闭防火墙与SELinux(以CentOS 7为例):
systemctl stop firewalld
systemctl disable firewalld
setenforce 0 # 临时关闭SELinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config # 永久关闭
2、邮箱权限:若使用QQ邮箱发件,需提前开启“POP3/SMTP服务”并生成授权码(路径:QQ邮箱→设置→账户→开启服务→生成授权码)。
3、钉钉权限:需拥有钉钉群的“管理权限”,用于创建自定义机器人。
二、Alertmanager核心概述
2.1 Prometheus与Alertmanager的协作关系
Prometheus的监控告警能力分为两个独立模块,分工明确:
- Prometheus Server:负责指标采集、存储,并根据用户定义的“告警规则”判断是否触发告警(生成告警事件)。
- Alertmanager(部署在
192.168.10.17):接收Prometheus Server发来的告警事件,对其进行分组、去重、抑制、路由后,分发到指定的告警渠道(如邮件、钉钉、企业微信)。
简单来说,Prometheus负责“发现问题”,Alertmanager负责“通知到人”。
2.2 Alertmanager核心功能解析
Alertmanager之所以能高效处理告警,核心依赖以下5个功能,尤其在大规模集群场景中至关重要:
1、分组(Grouping):
将相似告警合并为单个通知。例如服务器集群宕机时,若不分组会收到上百条“实例下线”告警,分组后仅需1条通知,避免用户被“告警风暴”淹没。
2、抑制(Inhibition):
避免级联告警干扰故障定位。例如“数据库服务宕机”会导致依赖它的“API服务告警”,抑制功能可自动屏蔽后者,让用户专注于根源故障。
3、静默(Silent):
指定时间窗口内暂停告警通知。常用于系统例行维护(如凌晨升级),避免维护期间的正常告警干扰运维人员。
4、路由(Route):
按规则分发告警到不同渠道。例如“核心业务告警”推钉钉群,“非核心告警”仅发邮件,实现告警分级通知。
5、去重(Deduplication):
过滤重复的告警事件。同一告警(如“CPU使用率过高”)若多次触发,Alertmanager会按配置的“重复间隔”发送通知,避免重复打扰。
三、Alertmanager邮件告警完整部署(192.168.10.17)
邮件告警是最基础、最通用的告警方式,适合中小规模团队或非实时性告警场景。以下步骤均在192.168.10.17(Alertmanager服务器)上执行:
3.1 安装包上传与解压
首先将Alertmanager安装包(alertmanager-0.24.0.linux-amd64.tar.gz)上传至192.168.10.17的/opt目录(可通过rz工具或FTP工具上传),随后执行解压与目录迁移:
# 进入安装包存放目录
cd /opt/
# 解压Alertmanager安装包
tar xf alertmanager-0.24.0.linux-amd64.tar.gz
# 将解压后的目录迁移至标准路径(/usr/local/),便于后续管理
mv alertmanager-0.24.0.linux-amd64 /usr/local/alertmanager
3.2 配置Alertmanager邮件告警(alertmanager.yml)
Alertmanager的核心配置文件为/usr/local/alertmanager/alertmanager.yml,需在此定义邮件服务器信息、告警路由规则和收件人。执行以下命令编辑配置文件:
vim /usr/local/alertmanager/alertmanager.yml
将以下内容粘贴至文件中(关键配置已加详细注释):
# global:全局配置段,定义所有告警渠道共用的基础信息(如邮件服务器)
global:resolve_timeout: 5m # 告警超时时间:5分钟未更新则标记为“已解决”smtp_smarthost: 'smtp.qq.com:465' # QQ邮箱SMTP服务器地址+端口(465为非SSL端口)smtp_from: '132107253@qq.com' # 发件人邮箱(需与SMTP服务器匹配)smtp_auth_username: '132107253@qq.com' # 发件人邮箱账号# 注意:此处为QQ邮箱“授权码”,非登录密码!获取路径:QQ邮箱→设置→账户→生成授权码smtp_auth_password: 'yoevnefvknmqbjia'smtp_require_tls: false # 禁用TLS# route:告警路由规则,定义Alertmanager如何处理告警
route:group_by: ['alertname'] # 按“告警名称”分组(如所有“InstanceDown”告警合并)group_wait: 20s # 首次告警等待20秒:收集同组内的新告警,合并后发送group_interval: 5m # 同组告警再次发送间隔:5分钟(避免频繁通知)repeat_interval: 20m # 重复告警间隔:20分钟(同一告警触发后,每20分钟重发一次)receiver: 'my-email' # 默认告警接收器(指向下方的“my-email”)# receivers:告警接收器定义,指定告警发送到哪里
receivers:
- name: 'my-email' # 接收器名称(需与route中的receiver一致)email_configs: # 邮件接收器配置- to: '目标邮箱@139.com' # 收件人邮箱(可填写多个,用逗号分隔)send_resolved: true # 发送“已解决”通知(告警恢复后,主动告知收件人)
3.3 配置Alertmanager系统服务(systemd)
为了便于管理Alertmanager的启动、停止和自启,需配置systemd服务文件:
# 创建Alertmanager服务文件
cat > /usr/lib/systemd/system/alertmanager.service <<'EOF'
[Unit]
Description=alertmanager # 服务描述
Documentation=https://prometheus.io/ # 官方文档地址
After=network.target # 依赖:网络服务启动后再启动Alertmanager[Service]
Type=simple # 服务类型:简单类型(直接执行启动命令)
# 启动命令:指定配置文件路径,开启debug日志(便于排查问题)
ExecStart=/usr/local/alertmanager/alertmanager \
--config.file=/usr/local/alertmanager/alertmanager.yml \
--log.level=debug
ExecReload=/bin/kill -HUP $MAINPID # 重载命令:发送HUP信号,热重载配置
Restart=on-failure # 重启策略:故障时自动重启[Install]
WantedBy=multi-user.target # 开机自启:多用户模式下生效
EOF
======================================================================================
cat > /usr/lib/systemd/system/alertmanager.service <<'EOF'
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/
After=network.target[Service]
Type=simple
ExecStart=/usr/local/alertmanager/alertmanager \
--config.file=/usr/local/alertmanager/alertmanager.yml \
--log.level=debugExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF
配置完成后,启动Alertmanager并设置开机自启:
# 重新加载systemd服务(使新配置生效)
systemctl daemon-reload
# 启动Alertmanager
systemctl start alertmanager
# 设置开机自启
systemctl enable alertmanager
# 验证服务状态(确保状态为active)
systemctl status alertmanager
# 验证端口(Alertmanager默认端口为9093,需确认192.168.10.17的9093端口已监听)
netstat -natp | grep :9093
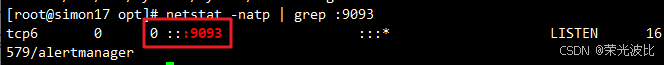
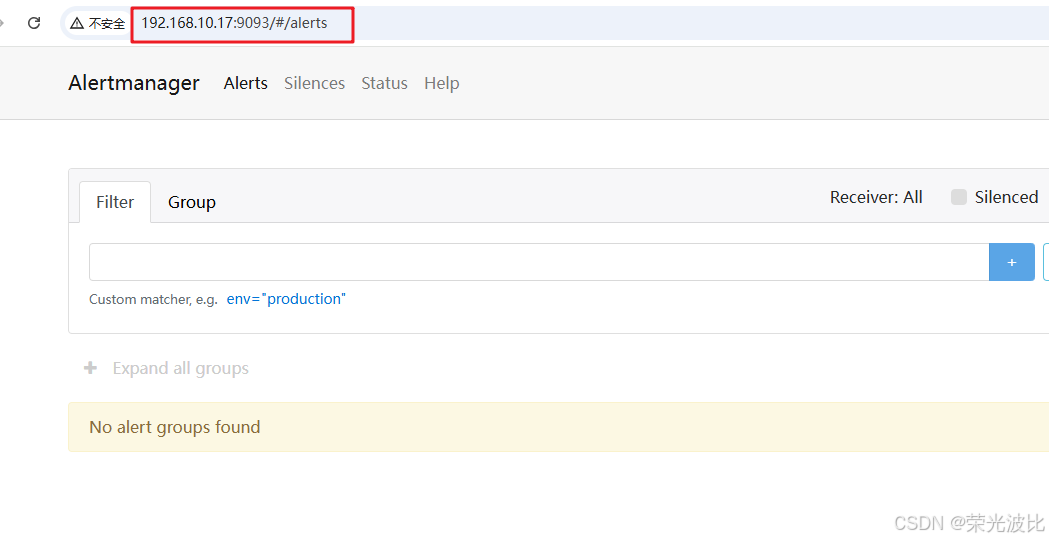
访问AlertManager Web UI:
打开浏览器,输入http://192.168.10..17:9093/#/alerts(节点的IP+9093端口),可查看当前告警状态。
3.4 定义Prometheus告警规则(Prometheus服务器:192.168.10.18)
Prometheus需要明确“什么情况下触发告警”,即告警规则。需在Prometheus服务器(示例192.168.10.18)上创建规则目录,再编写规则文件:
# 登录Prometheus服务器(192.168.10.18),创建告警规则目录
mkdir /usr/local/prometheus/alert_rules
# 编辑实例下线告警规则(InstanceDown)和CPU高使用率告警规则(cpu_alert)
vim /usr/local/prometheus/alert_rules/instance_down.yaml
规则文件内容如下(包含两种常见告警场景):
groups:
# 告警组1:所有实例下线监控
# 若某个 Instance 的 up 指标的值转为 0 持续超过 1 分钟后,将触发告警
- name: AllInstances # 告警组名称(自定义,需唯一)rules:- alert: InstanceDown # 告警名称(组内唯一)expr: up == 0 # 告警触发条件(PromQL表达式):up指标为0表示实例下线for: 1m # 持续时间:实例下线持续1分钟后才触发告警(避免瞬时抖动)# annotations:告警附加信息(会显示在告警通知中)annotations:title: 'Instance down' # 告警标题description: 'Instance has been down for more than 1 minute.' # 告警描述# labels:告警标签(用于分类、过滤,如“严重级别”)labels:severity: 'critical' # 严重级别:critical(紧急)# 告警组2:节点CPU使用率大于 80% 触发告警
- name: node_alert # 告警组名称(自定义)rules:- alert: cpu_alert # 告警名称# 告警条件:100 - 空闲CPU占比 > 80%(即CPU使用率>80%)expr: 100 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) * 100 > 80for: 5m # 持续时间:CPU使用率>80%持续5分钟后触发告警labels:level: warning # 严重级别:warning(警告)annotations:# 动态显示实例名和CPU使用率({{ $labels.instance }} 为PromQL变量)description: "instance: {{ $labels.instance }} ,cpu usage is too high ! value: {{ $value }}"summary: "cpu usage is too high" # 告警摘要
告警条件表达式注意点:
- 表达式值为true,但其持续时间未能满足for定义的时长时,相关的告警状态为pending
- 满足该时长之后,相关的告警将被触发,并转为firing状态
- 表达式的值为false时,告警将处于inactive状态
3.5 关联Prometheus与Alertmanager(Prometheus服务器:192.168.10.18)
Prometheus需要知道“告警事件发送到哪个Alertmanager”(即192.168.10.17:9093),因此需修改Prometheus配置文件:
# 在Prometheus服务器(192.168.10.18)上编辑配置文件
vim /usr/local/prometheus/prometheus.yml
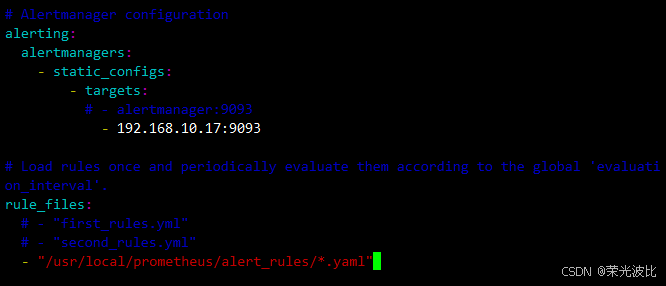
修改alerting(指定Alertmanager地址)和rule_files(指定告警规则路径):
# alerting:配置Alertmanager实例地址(192.168.10.17:9093)
alerting:alertmanagers:- static_configs:- targets:- 192.168.10.17:9093 # 关键修改:指向Alertmanager服务器(192.168.10.17)的9093端口# rule_files:配置Prometheus加载的告警规则文件路径
rule_files:- "/usr/local/prometheus/alert_rules/*.yaml" # 加载规则目录下所有yaml文件
配置完成后,重载Prometheus使配置生效:
systemctl reload prometheus
3.6 邮件告警功能测试
为验证邮件告警是否生效,可在被监控实例(如安装了node_exporter的服务器)上手动停止node_exporter(模拟实例下线),触发“InstanceDown”告警:
# 在被监控实例上停止node_exporter(若未安装node_exporter,可停止其他被Prometheus监控的服务)
systemctl stop node_exporter

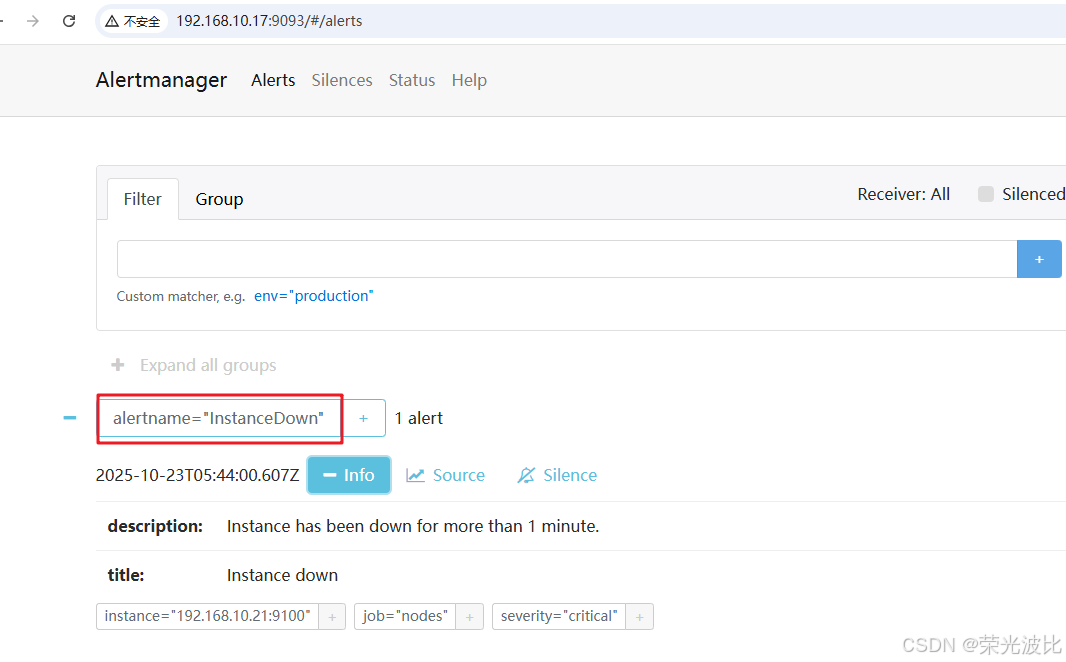
等待1分钟(与告警规则中for: 1m一致)后,查看收件人邮箱。若配置正确,会收到类似以下内容的告警邮件:
- 标题:[FIRING:1] InstanceDown (critical)
- 内容:包含实例名称、告警时间、告警描述等信息。
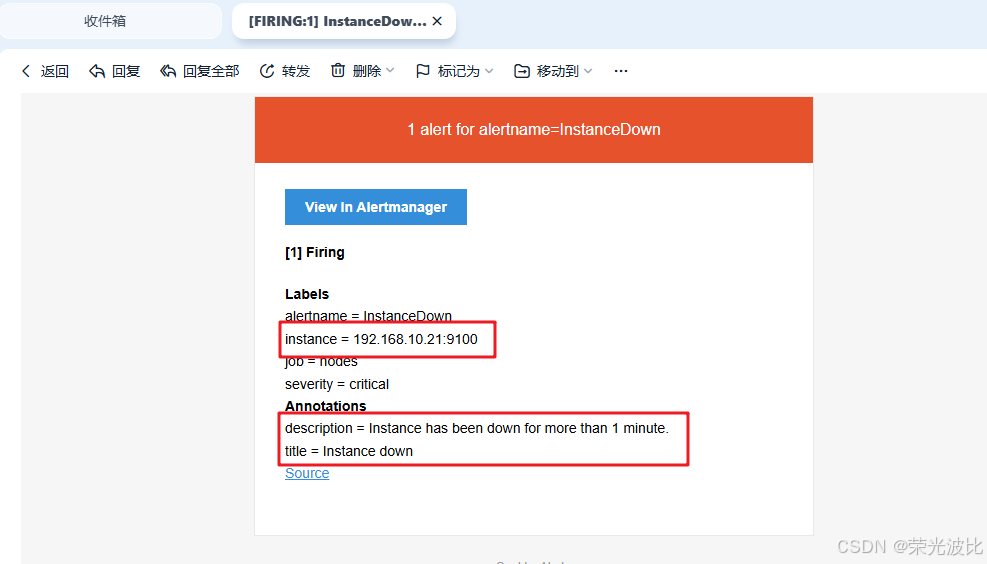
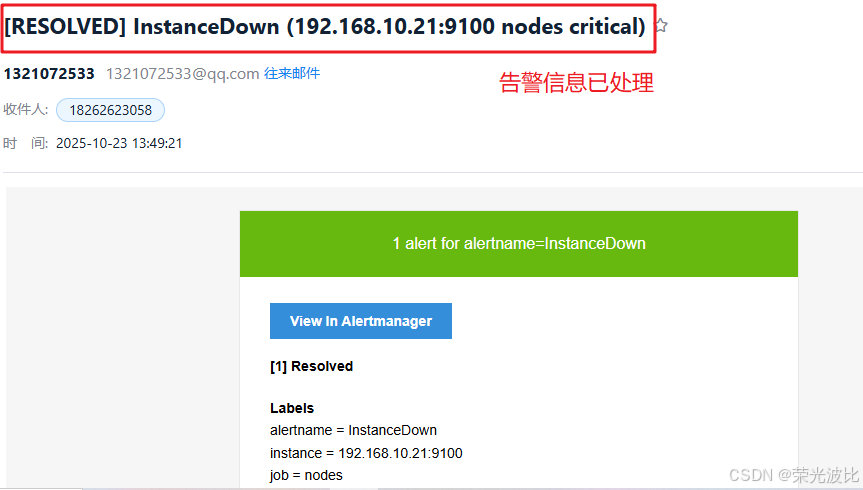
告警测试完成后,重启node_exporter恢复监控:
systemctl start node_exporter
等待5分钟(与resolve_timeout: 5m一致)后,会收到“告警已解决”的邮件通知。

四、Alertmanager钉钉告警扩展部署(192.168.10.17)
邮件告警实时性较弱,钉钉告警更适合需要“即时响应”的场景(如核心业务故障)。实现钉钉告警需依赖prometheus-webhook-dingtalk插件(Alertmanager不直接支持钉钉,需通过Webhook对接),以下步骤均在192.168.10.17(Alertmanager服务器)上执行:
4.1 钉钉告警插件(prometheus-webhook-dingtalk)部署
首先将prometheus-webhook-dingtalk安装包(prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz)上传至192.168.10.17的/opt目录,随后执行解压与目录迁移:
# 进入安装包存放目录
cd /opt/
# 解压插件安装包
tar xf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz
# 迁移目录至标准路径
mv prometheus-webhook-dingtalk-2.1.0.linux-amd64 /usr/local/dingtalk
4.2 钉钉群机器人创建与配置
需在钉钉群中创建“自定义机器人”,获取Webhook地址和加签密钥(用于插件对接):
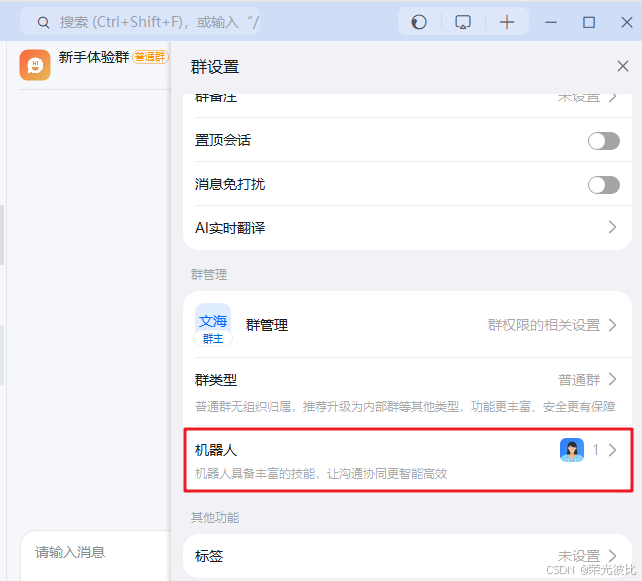
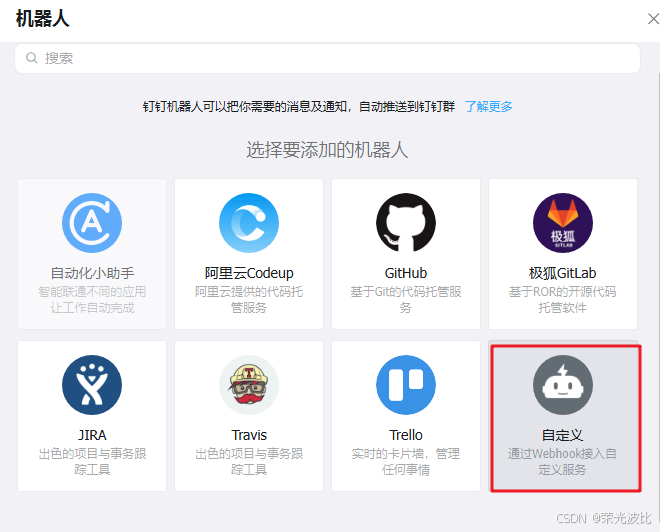
1、打开钉钉,进入目标告警群,点击「群设置」→「智能群助手」→「添加机器人」→「自定义机器人」。
2、填写机器人名称(如“Prometheus告警”),勾选“消息推送”,点击「下一步」。
3、安全设置:勾选「加签」,复制页面显示的“加签密钥”(后续配置config.yml需用到),点击「复制」Webhook地址(格式:https://oapi.dingtalk.com/robot/send?access_token=xxx)。
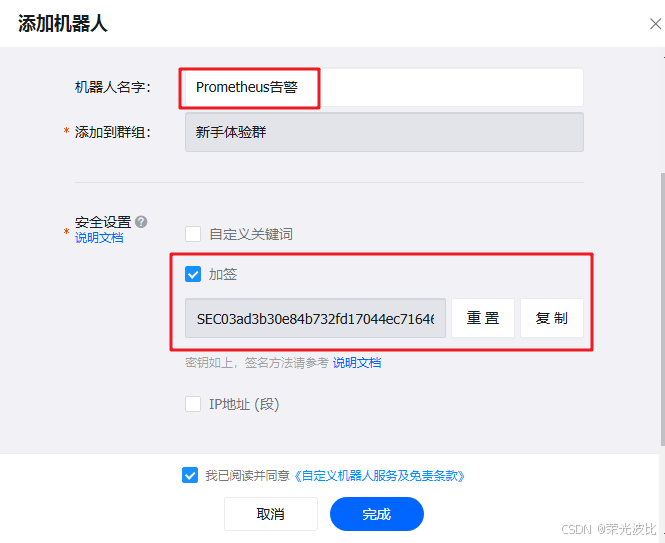
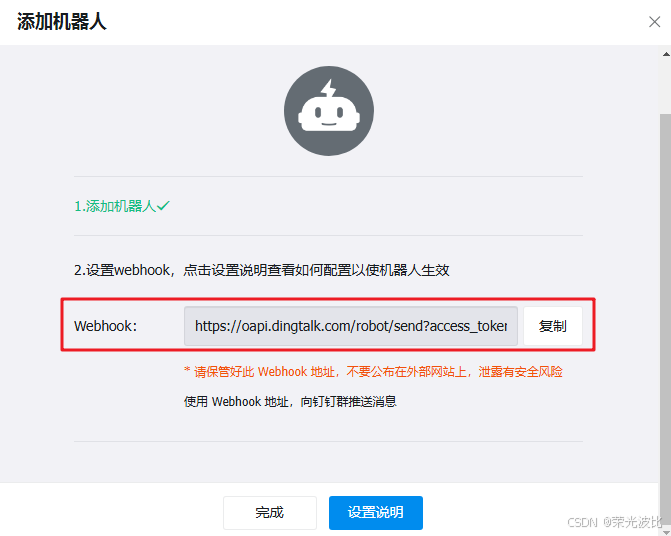
4、点击「完成」,机器人创建成功。
4.3 钉钉告警插件配置(config.yml)
进入插件目录,复制默认配置文件并修改:
# 进入钉钉插件目录(192.168.10.17)
cd /usr/local/dingtalk
# 复制默认配置文件(避免直接修改原文件)
cp -p config.example.yml config.yml
# 编辑配置文件
vim config.yml
修改以下关键配置(其他配置保持默认):
timeout: 5s # 插件请求超时时间# 告警模板路径(使用插件自带的legacy模板)
templates:- contrib/templates/legacy/template.tmpl# 默认告警消息模板(使用legacy模板格式)
default_message:title: '{{ template "legacy.title" . }}'text: '{{ template "legacy.content" . }}'# 告警目标(对应钉钉机器人)
targets:webhook1: # 自定义目标名称(后续Alertmanager配置需用到)url: <粘贴步骤4.2获取的Webhook地址> # 替换为你的钉钉机器人Webhooksecret: <粘贴步骤4.2获取的加签密钥> # 替换为你的钉钉机器人加签密钥
4.4 启动钉钉告警插件
插件支持直接启动,也可配置为systemd服务(本文先演示直接启动,适合测试):
# 进入插件目录(192.168.10.17)
cd /usr/local/dingtalk
# 后台启动插件(默认端口为8060,需确认192.168.10.17的8060端口已监听)
nohup ./prometheus-webhook-dingtalk --config.file=config.yml &
# 验证端口(确保8060端口已监听)
netstat -natp | grep :8060
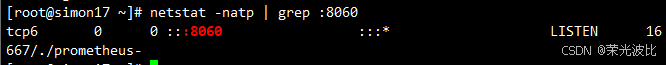
若需配置开机自启,可参考步骤3.3创建dingtalk.service文件,示例如下:
cat > /usr/lib/systemd/system/dingtalk.service <<'EOF'
[Unit]
Description=prometheus-webhook-dingtalk
After=network.target[Service]
Type=simple
WorkingDirectory=/usr/local/dingtalk
ExecStart=/usr/local/dingtalk/prometheus-webhook-dingtalk --config.file=config.yml
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF
创建后执行启动与自启配置:
systemctl daemon-reload
systemctl start dingtalk
systemctl enable dingtalk
4.5 调整Alertmanager配置指向钉钉插件(192.168.10.17)
需修改alertmanager.yml,将默认告警接收器从“邮件”改为“钉钉插件”(若需同时保留邮件告警,可通过路由规则配置,本文先演示仅钉钉告警):
vim /usr/local/alertmanager/alertmanager.yml
修改后的配置文件内容如下(仅保留核心配置,全局配置与步骤3.2一致):
global:resolve_timeout: 5m# 此处可保留邮件配置(若需同时发送邮件),也可删除(仅保留钉钉)# 路由规则:默认指向钉钉接收器
route:group_by: [alertname]group_wait: 10s # 缩短等待时间,加快钉钉告警推送group_interval: 15srepeat_interval: 20mreceiver: 'dingding.webhook1' # 指向钉钉接收器# 钉钉接收器配置(通过Webhook对接插件,插件与Alertmanager同机,故用127.0.0.1)
receivers:
- name: 'dingding.webhook1' # 接收器名称webhook_configs:# 插件地址:http://127.0.0.1:8060/dingtalk/<target名称>/send(同机用127.0.0.1更稳定)- url: 'http://127.0.0.1:8060/dingtalk/webhook1/send'send_resolved: true # 发送“已解决”通知
配置完成后,重载Alertmanager使配置生效:
systemctl reload alertmanager
4.6 钉钉告警功能测试
同样通过停止node_exporter触发告警,验证钉钉通知:
# 在被监控实例上停止node_exporter
systemctl stop node_exporter
等待10秒(与group_wait: 10s一致)后,查看钉钉群。若配置正确,会收到类似以下内容的告警消息:
- 标题:[FIRING:1] InstanceDown (critical)
- 内容:包含实例名称、告警时间、CPU使用率(若触发CPU告警)等信息,格式清晰。
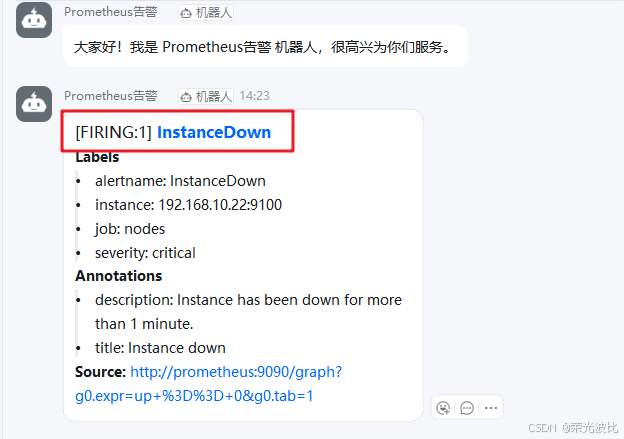
测试完成后,重启node_exporter,等待5分钟会收到“告警已解决”的钉钉通知。

补充:同时启动邮箱告警和钉钉告警
如果希望Alertmanager 同时把告警推送到「钉钉」和「邮箱」,可以直接在 receivers 里配置多个接收器,然后通过 route 的 receivers 列表一起触发。
vim /usr/local/alertmanager/alertmanager.ymlglobal:resolve_timeout: 5m # 告警超时时间:5分钟未更新则标记为“已解决”smtp_smarthost: 'smtp.qq.com:465' # QQ邮箱SMTP服务器地址+端口(465为非SSL端口)smtp_from: '132107253@qq.com' # 发件人邮箱(需与SMTP服务器匹配)smtp_auth_username: '132107253@qq.com' # 发件人邮箱账号# 注意:此处为QQ邮箱“授权码”,非登录密码!获取路径:QQ邮箱→设置→账户→生成授权码smtp_auth_password: '你的授权码'smtp_require_tls: false # 禁用TLSroute:group_by: ['alertname']group_wait: 10sgroup_interval: 5mrepeat_interval: 20mreceiver: 'combo'receivers:
- name: 'combo' # 接收器名称email_configs:- to: '目标邮箱@139.com'send_resolved: truewebhook_configs:# 插件地址:http://127.0.0.1:8060/dingtalk/<target名称>/send(同机用127.0.0.1更稳定)- url: 'http://127.0.0.1:8060/dingtalk/webhook1/send'send_resolved: true # 发送“已解决”通知
五、总结与注意事项
5.1 部署总结
本文完整覆盖了Alertmanager的核心部署流程:
1、环境准备:明确服务器角色、IP规划、依赖工具及权限,为部署打好基础。
2、邮件告警:从Alertmanager安装、配置到Prometheus关联,形成“生成告警-分发邮件”闭环。
3、钉钉告警:通过prometheus-webhook-dingtalk插件对接钉钉机器人,实现即时告警通知。
5.2 关键注意事项
- 配置文件语法:YAML语法对缩进敏感,若告警不生效,可通过
systemctl status alertmanager或nohup.out(钉钉插件日志)查看错误信息,排查缩进或参数错误。 - 敏感信息保护:QQ邮箱授权码、钉钉加签密钥等敏感信息,建议通过
EnvironmentFile(systemd服务)或加密工具存储,避免明文写在配置文件中。 - 告警规则优化:生产环境中需根据业务调整
for(持续时间)和repeat_interval(重复间隔),例如核心业务for设为30秒、非核心设为5分钟,避免“误告警”和“告警风暴”。 - 日志排查:Alertmanager日志路径默认在
/var/log/messages(CentOS),钉钉插件日志在/usr/local/dingtalk/nohup.out,遇到问题时优先查看日志定位原因。
如果在部署过程中遇到“端口占用”“钉钉消息发送失败”“邮件无法送达”等问题,欢迎在评论区留言讨论!