AI服务器工作之显卡测试
显卡测试基础命令
nvidia-smi --query-gpu=vbios_version 查看vbios_version版本
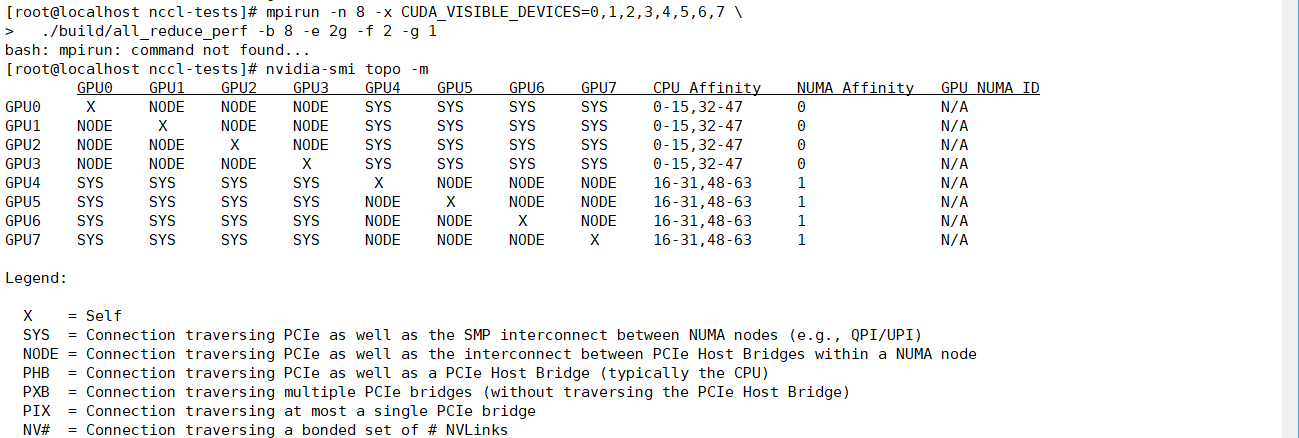
nvidia-smi topo -m // NVIDIA GPU 系统拓扑查看命令
nvidia-smi --query-gpu=pcie.link.width.current --format=csv
// 查询当前系统中每块 NVIDIA GPU 实际运行的 PCIe 通道宽度(Lane Width)
nvidia-smi --query-gpu=vbios_version --format=csv // NVIDIA 显卡的 VBIOS 版本信息📌 什么是 VBIOS?
VBIOS(Video BIOS)是显卡上固化的底层固件,类似于主板的 BIOS。它在系统启动初期初始化 GPU 硬件,负责:
- 显卡的基本初始化
- 显示输出的启动(如开机 LOGO)
- 功耗、频率、风扇等初始设置
- 与 UEFI/BIOS 协同工作
✅ 主要用途
1. 查看 GPU 之间的连接方式
- 判断 GPU 是否通过 NVLink、PCIe 或其他方式互联。
- 了解带宽和延迟差异。
2. 查看 GPU 与 CPU 插槽(Socket)的亲和性
- 多路 CPU(如双路 EPYC/至强)服务器中,每个 GPU 连接在哪个 CPU 下。
- 对性能敏感的应用(如深度学习训练)应尽量让 GPU 和进程绑定在同一 NUMA 节点上。
3. 优化多 GPU 并行计算性能
- 若两个 GPU 处于同一 PCIe 根下或通过 NVLink 直连,则通信更快。
- 可据此决定 GPU 分配策略(如 PyTorch 的 CUDA_VISIBLE_DEVICES)。
4. 排查性能瓶颈
- 如果两个需要频繁通信的 GPU 实际上跨了多个 PCIe 层级或 CPU 插槽,性能会下降。
- 此命令可帮助识别此类问题。
显卡压力测试
CPU 温度≤85℃,显卡≤90℃,硬盘≤60℃
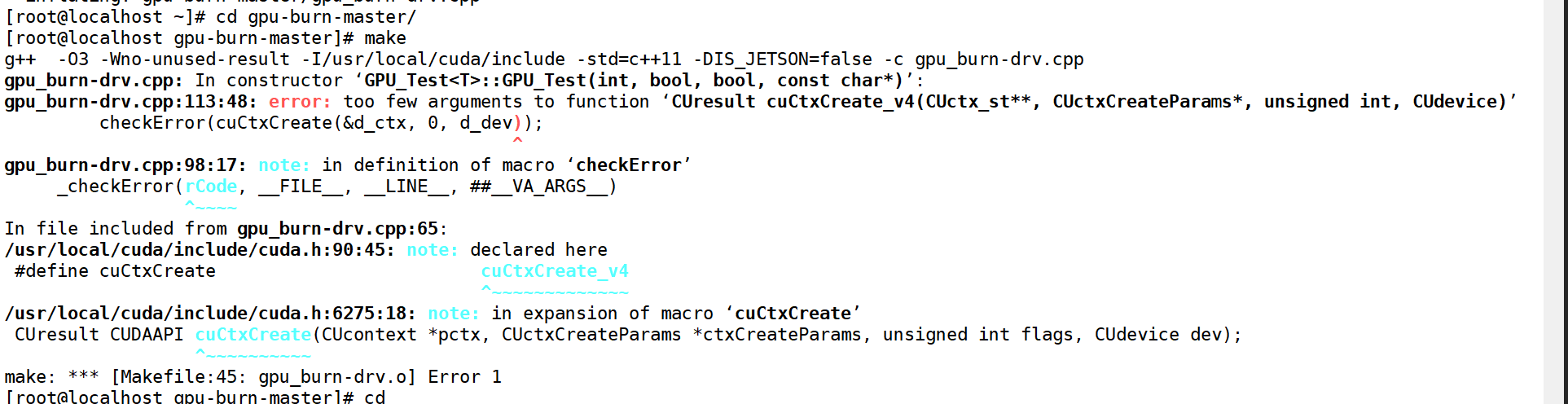
Stress-ng / gpu_burn(Linux服务器首选)
- 适用平台:Linux(尤其适用于GPU服务器、云计算环境)
- gpu_burn
- 轻量命令行工具,专为NVIDIA GPU设计。
- 可打满GPU算力和显存,输出温度、负载、错误率等关键指标。
- 支持Docker部署,适合自动化测试。
- GitHub:https://github.com/wilicc/gpu-burn
🔄 总结:三者依赖关系
| 关系 | |
| 🔹 显卡 → 驱动 | 显卡型号决定你需要哪个驱动(太老的驱动可能不支持新卡) |
| 🔹 驱动 → CUDA Runtime | 驱动版本决定你最多能运行哪个版本的 CUDA 程序 |
| 🔹 CUDA Toolkit | 只要 ≤ 驱动支持的版本,就可以安装和使用 |
显卡NCCL测试
- 下载nccl所需工具包 https://developer.nvidia.com/nccl
以cuda13.0+centos8系统为例:
| 包名 | 作用 |
| libnccl | 运行时库( .so 文件),运行 NCCL 程序必需 |
| libnccl-devel | 开发头文件和符号链接,编译程序时需要 |
| libnccl-static | 静态库( .a 文件),用于静态链接 |
下载nccl官方测试工具包
git clone https://github.com/NVIDIA/nccl-tests.git
./build/all_reduce_perf -b 8 -e 128m -f 2 -g 8 | 参数 | 含义 | 说明 |
| ./build/all_reduce_perf | NCCL AllReduce 性能测试程序 | 编译 nccl-tests 后生成的可执行文件 |
| -b 8 | 起始大小(bytes) | 从 8 字节开始测试 |
| -e 128M | 结束大小(bytes) | 最大测试到 128 MB 数据(⚠️ 非常大!) |
| -f 2 | 步长因子(factor) | 每次数据大小 ×2(指数增长) |
| -g 8 | 每进程 GPU 数量 | 每个进程绑定 8 个 GPU(通常用于单节点多 GPU) |
即使 PCIe 支持动态调整,你的 NCCL 失败(unhandled system error)仍然可能与 链路训练、电源状态切换延迟、或 BIOS 配置不当 有关。
可能原因:
| 原因 | 说明 |
| 🔹 BIOS 未启用 Resizable BAR | GPU 无法直接访问大块主机内存,影响 IPC |
| 🔹 CSM 开启(Legacy Mode) | 强制 PCIe 降速或禁用现代功能 |
| 🔹 电源管理太激进 | GPU 未完全唤醒,NCCL 初始化失败 |
| 🔹 NUMA/CPU 亲和性问题 | 多 GPU 跨 NUMA 访问内存延迟高 |
| BIOS 选项✅ 推荐优化步骤(确保动态 PCIe 正常工作) 1. 进入 BIOS 启用关键选项 即使 PCIe 支持动态调整,也建议启用: | 值 |
| PCIe Speed | Auto |
| Resizable BAR | Enabled ✅(最重要) |
| Above 4G Decoding | Enabled ✅ |
| CSM | Disabled ✅ |
| PCIe Power Management | Disabled 或 Moderate |
- Resizable BAR 能显著提升 GPU 显存访问效率,尤其对 NCCL 通信有帮助。
Advanced → PCIe Configuration → Resizable BAR → enable
Advanced → PCIe Configuration → Above 4G Decoding
PCI-E ASPM Support (Global): [Disabled]
显卡带宽测试
测试工具sample要选择适合cuda版本的测试工具:
https://github.com/NVIDIA/cuda-samples/releases (英伟达官方github资料库)
Nvbandwidth测试(适用于cuda-sample v12.9和v13.0)
1️⃣ Memcpy CE 测试(Copy Engine)
host_to_device_memcpy_ce
- 方向:CPU 主机 → 单个 GPU
- 意义:衡量从主机内存拷贝数据到某一块 GPU 显存的速度。
device_to_host_memcpy_ce
- 方向:单个 GPU → CPU 主机
*_bidirectional_memcpy_ce
- 双向同时传输:CPU ↔ GPU 同时读写
- 带宽下降:因总线竞争
all_to_host_memcpy_ce 和 host_to_all_memcpy_ce
- all_to_host:所有 GPU 同时向 CPU 传数据(汇聚瓶颈)
- 带宽降至 ~34–35 GB/s per GPU,总和 279.4 GB/s
- 原因:CPU 内存控制器/PCIe 根复合体(Root Complex)成为瓶颈
- host_to_all:CPU 同时向所有 GPU 发送数据
- ~48.8–49.3 GB/s per GPU,总和 391.79 GB/s
- 比“all to host”稍好,但仍有瓶颈
*_bidirectional_memcpy_ce(all-to-one 或 one-to-all 双向)
- 更真实反映并发负载
- 带宽进一步下降至 ~19 GB/s per link,说明系统在高并发下严重受限
2️⃣ Memcpy SM 测试(Streaming Multiprocessor)
使用 GPU 的 CUDA 核心(SM) 执行内存拷贝,模拟实际程序中 kernel 自己搬运数据的行为(如 pinned memory + custom memcpy kernel)
host_to_device_memcpy_sm
- 用 SM 实现 memcpy,带宽 ~51.4 GB/s
- 略低于 CE(56.4 GB/s),合理,因为 SM 要做更多控制逻辑
device_to_host_memcpy_sm
- ~52.7 GB/s,略高,可能是缓存或调度优化
bidirectional_memcpy_sm
- 双向并发,带宽 ~42.5 GB/s,比 CE 模式略好?可能与实现有关,总体合理
all_to_host_memcpy_sm 和 host_to_all_memcpy_sm
- 类似 CE 模式,但:
- all_to_host: ~34.3–35.0 GB/s
- host_to_all: ~46.6–46.9 GB/s
- 表明 SM 模式下仍受系统瓶颈限制
host_to_all_bidirectional_memcpy_sm
- 亮点:带宽回升至 ~33–34.7 GB/s per GPU,总和 271.5 GB/s
- 说明在某些并发场景下,SM 模式反而更高效(可能避免了 CE 资源争抢)
3️⃣ Latency 测试
host_device_latency_sm
- 测量 CPU 与 GPU 之间的内存访问延迟
- 单位:纳秒(ns)
- 结果:~550 ns
- 解读:
- 典型 PCIe 4.0/5.0 系统延迟为 500–800 ns
- 550 ns 属于非常优秀的水平,说明系统优化良好(如启用 cudaHostRegister、使用 pinned memory)
4️⃣ Device Local Copy(GPU 内部带宽)
device_local_copy
- GPU 显存内部拷贝速度(同一 GPU 内)
- 结果:~760 GB/s
- 解读:
- RTX 4090 显存带宽约 1 TB/s,RTX 5090 若达 760 GB/s,属于合理范围
- 表示 GPU 内部 GDDR6X/GDDR7 显存子系统性能强劲
✅ 可以安装多个 CUDA Toolkit(通过 NSIGHT 或手动切换),但只能有一个驱动。
export PATH=/usr/local/cuda-11.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH注意!
- 驱动nvidia-smi输出是推荐cuda版本,最高兼容版本的cuda
- 测试工具要选择适合的cuda版本,早期的测试工具和cuda版本的目录是在一起的,12.x版本将测试工具和版本目录分隔开,12.9和13.0在原有的基础上将带宽的性能测试分隔开