7. Prometheus告警配置-alertmanger
1. 安装alertmanger(略)
请参考Prometheus专栏第一章Prometheus安装第三部分
2. 配置Prometheus 的告警发送目标
vim /usr/local/prometheus/prometheus.yml# global 配置
global:# scrape_interval: 设置 Prometheus 拉取监控数据的时间间隔,默认为 1 分钟。这里设置为 15 秒。scrape_interval: 15s # Set the scrape interval to every 15 seconds.# evaluation_interval: 设置 Prometheus 评估告警规则的时间间隔,默认为 1 分钟。这里设置为 15 秒。evaluation_interval: 15s # Evaluate rules every 15 seconds.# scrape_timeout: Prometheus 默认的拉取超时时间是 10 秒,未做更改。# alerting 配置(告警配置部分)
alerting:# alertmanagers: 配置 Prometheus 通知告警的 Alertmanager 地址。alertmanagers:- static_configs:# 这里配置告警发送的目标地址,通常是 Alertmanager 的地址。- targets:- 192.168.80.77:9093 # 这个地址是 Prometheus 向其发送告警的目标 Alertmanager。# rule_files 配置(告警规则配置)
rule_files:# Prometheus 会加载并定期根据 global 配置的 evaluation_interval 来评估的告警规则文件。- "/usr/local/prometheus/rule/rules.yml" # 这是配置的告警规则文件路径。
3. 配置alertmanger告警(alertmanager.yml)
注:因为是内网环境,不能连接外网,只能访问自己集团的邮件服务器,我自己配置了postfix
global全局邮箱配置哪里可以忽略,从别的技术博主上看配置外网邮箱,其他部分可做参考
vim /usr/local/prometheus/alertmanager/alertmanager.yml
# 全局配置部分
global:# 告警恢复后等待5分钟再发送恢复通知,避免状态抖动resolve_timeout: 5m# SMTP服务器配置,使用本地邮件服务(localhost:25)smtp_smarthost: 'localhost:25'# 发件人邮箱地址smtp_from: '123456@aaaa.com.cn'# 不要求TLS加密连接smtp_require_tls: false# SMTP握手时使用的hello标识smtp_hello: localhost# 模板文件路径配置
templates:# 指定Alertmanager告警模板文件所在目录,支持通配符匹配- '/usr/local/prometheus/alertmanager/templates/*.tmpl'# 路由配置 - 核心配置,定义告警如何路由和处理
route:# 按主机实例进行分组,这样同一台主机的所有告警会合并为一封邮件group_by: ['instance']# 等待30秒再发送新组的告警,以便收集同一主机的多个告警group_wait: 30s# 同一分组内告警的发送间隔为10分钟group_interval: 10m# 重复告警的发送间隔为1小时repeat_interval: 1h# 默认接收器名称receiver: 'prometheus'# 子路由 - 针对不同严重级别设置不同参数routes:# 警告级别告警的路由规则- match:# 匹配严重级别为warning的告警severity: warning# 警告级别告警8小时重复一次repeat_interval: 8h# 使用相同的接收器receiver: 'prometheus'# 严重级别告警的路由规则- match:# 匹配严重级别为critical的告警severity: critical# 严重级别告警2小时重复一次repeat_interval: 2h# 使用相同的接收器receiver: 'prometheus'# 抑制规则配置 - 防止告警风暴,优化告警通知
inhibit_rules:# 规则1: 高级别告警抑制低级别告警- source_match:# 源告警条件:严重级别为criticalseverity: 'critical'target_match:# 目标告警条件:严重级别为warningseverity: 'warning'# 当同一主机同一告警名称时,critical告警会抑制warning告警equal: ['instance', 'alertname']# 规则2: 抑制短时间内频繁触发的相同告警- source_match:# 源告警条件:严重级别为criticalseverity: 'critical'target_match:# 目标告警条件:严重级别为criticalseverity: 'critical'# 当同一主机同一告警名称时,防止重复发送equal: ['instance', 'alertname']# 注:这个规则会阻止同一主机同一告警在短时间内重复发送# 接收器配置 - 定义告警发送目的地和方式
receivers:# 接收器名称- name: 'prometheus'# 邮件配置email_configs:# 邮件接收者- to: '56789@aaaa.com.cn'# 发送恢复通知send_resolved: true# 邮件头配置headers:# 使用自定义模板设置邮件主题Subject: '{{ template "custom.subject" . }}'# 使用自定义模板设置邮件HTML内容html: '{{ template "custom.html" . }}'4. 配置告警规则
mkdir /usr/local/prometheus/rule
vim /usr/local/prometheus/rule/rules.yml
groups:- name: NodeExporterrules:# 内存使用率分级告警- alert: 机器内存利用率过高-警告expr: '(1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 80'for: 2mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} 内存利用率过高 (警告级别)'description: '当前内存利用率 = {{ printf "%.2f" $value }}%,请关注'- alert: 机器内存利用率过高-严重expr: '(1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 90'for: 1mlabels:severity: criticalannotations:summary: '机器 {{ $labels.instance }} 内存利用率严重过高'description: '当前内存利用率 = {{ printf "%.2f" $value }}%,请立即处理!'# 磁盘使用率分级告警- alert: 磁盘空间利用率过高-警告expr: '(1 - node_filesystem_avail_bytes{fstype!~"^(fuse.*|tmpfs|cifs|nfs)"} / node_filesystem_size_bytes) * 100 > 80 and on (instance, device, mountpoint) node_filesystem_readonly == 0'for: 3mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} 磁盘空间利用率过高 (警告级别)'description: '挂载点 {{ $labels.mountpoint }} 使用率 = {{ printf "%.2f" $value }}%'- alert: 磁盘空间利用率过高-严重expr: '(1 - node_filesystem_avail_bytes{fstype!~"^(fuse.*|tmpfs|cifs|nfs)"} / node_filesystem_size_bytes) * 100 > 90 and on (instance, device, mountpoint) node_filesystem_readonly == 0'for: 1mlabels:severity: criticalannotations:summary: '机器 {{ $labels.instance }} 磁盘空间利用率严重过高'description: '挂载点 {{ $labels.mountpoint }} 使用率 = {{ printf "%.2f" $value }}%,请立即清理!'# 磁盘inode分级告警- alert: 磁盘inode利用率过高-警告expr: '(1 - node_filesystem_files_free / node_filesystem_files) * 100 > 80 and on (instance, device, mountpoint) node_filesystem_readonly == 0'for: 3mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} 磁盘inode利用率过高 (警告级别)'description: '挂载点 {{ $labels.mountpoint }} inode使用率 = {{ printf "%.2f" $value }}%'- alert: 磁盘inode利用率过高-严重expr: '(1 - node_filesystem_files_free / node_filesystem_files) * 100 > 90 and on (instance, device, mountpoint) node_filesystem_readonly == 0'for: 1mlabels:severity: criticalannotations:summary: '机器 {{ $labels.instance }} 磁盘inode利用率严重过高'description: '挂载点 {{ $labels.mountpoint }} inode使用率 = {{ printf "%.2f" $value }}%,请立即处理!'# CPU使用率告警(增加持续时间避免频繁告警)- alert: CPU利用率过高expr: 'avg without (mode,cpu) ( 1 - rate(node_cpu_seconds_total{mode="idle"}[2m]) ) * 100 > 85'for: 5m # 增加持续时间,避免短暂峰值labels:severity: warningannotations:summary: '机器 {{ $labels.instance }} CPU 利用率过高'description: 'CPU 利用率 = {{ printf "%.2f" $value }}%,持续5分钟'# 节点宕机告警- alert: 节点宕机expr: 'up{job="node_exporter"} == 0'for: 1mlabels:severity: criticalannotations:summary: '机器 {{ $labels.instance }} 节点宕机'description: '节点已宕机超过1分钟,请立即检查!'# 网络相关告警- alert: 网卡接收流量过高expr: '(rate(node_network_receive_bytes_total[5m]) / on(instance, device) node_network_speed_bytes) * 100 > 70'for: 3mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} 网卡接收流量过高'description: '网卡 {{ $labels.device }} 入向流量已达容量的 {{ printf "%.2f" $value }}%'- alert: 网卡发送流量过高expr: '(rate(node_network_transmit_bytes_total[5m]) / on(instance, device) node_network_speed_bytes) * 100 > 70'for: 3mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} 网卡发送流量过高'description: '网卡 {{ $labels.device }} 出向流量已达容量的 {{ printf "%.2f" $value }}%'# 系统服务告警- alert: Systemd服务异常expr: 'node_systemd_unit_state{state="failed"} == 1'for: 2mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} Systemd 服务异常'description: '服务 {{ $labels.name }} 状态异常'# 负载相关告警- alert: 系统负载过高expr: 'node_load5 / count without (cpu) (node_cpu_seconds_total{mode="system"}) > 2'for: 5mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} 系统负载过高'description: '5分钟平均负载 = {{ printf "%.2f" $value }}'# SWAP使用率告警- alert: SWAP使用率过高expr: '(1 - (node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes)) * 100 > 50'for: 3mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} SWAP 使用率过高'description: 'SWAP 使用率 = {{ printf "%.2f" $value }}%'# 磁盘IO延迟告警- alert: 磁盘读延迟过高expr: 'rate(node_disk_read_time_seconds_total[1m]) / rate(node_disk_reads_completed_total[1m]) > 0.05 and rate(node_disk_reads_completed_total[1m]) > 0'for: 2mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} 磁盘读延迟过高'description: '磁盘读延迟 = {{ printf "%.3f" $value }}秒'- alert: 磁盘写延迟过高expr: 'rate(node_disk_write_time_seconds_total[1m]) / rate(node_disk_writes_completed_total[1m]) > 0.05 and rate(node_disk_writes_completed_total[1m]) > 0'for: 2mlabels:severity: warningannotations:summary: '机器 {{ $labels.instance }} 磁盘写延迟过高'description: '磁盘写延迟 = {{ printf "%.3f" $value }}秒'# 关键硬件故障告警- alert: 软RAID磁盘故障expr: 'node_md_disks{state="failed"} > 0'for: 1mlabels:severity: criticalannotations:summary: '机器 {{ $labels.instance }} 软RAID磁盘故障'description: 'RAID阵列 {{ $labels.device }} 有 {{ $value }} 个磁盘故障'- alert: 文件系统错误expr: 'node_filesystem_device_error{fstype!~"^(fuse.*|tmpfs|cifs|nfs)"} == 1'for: 1mlabels:severity: criticalannotations:summary: '机器 {{ $labels.instance }} 文件系统错误'description: '文件系统 {{ $labels.mountpoint }} 出现设备错误'
5. 配置发送邮件的HTML格式(我喜欢的格式,大家喜欢别的格式可以自己写一个别的)
注意!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!文中我隐藏了IP地址,复制完之后请修改实际IP地址
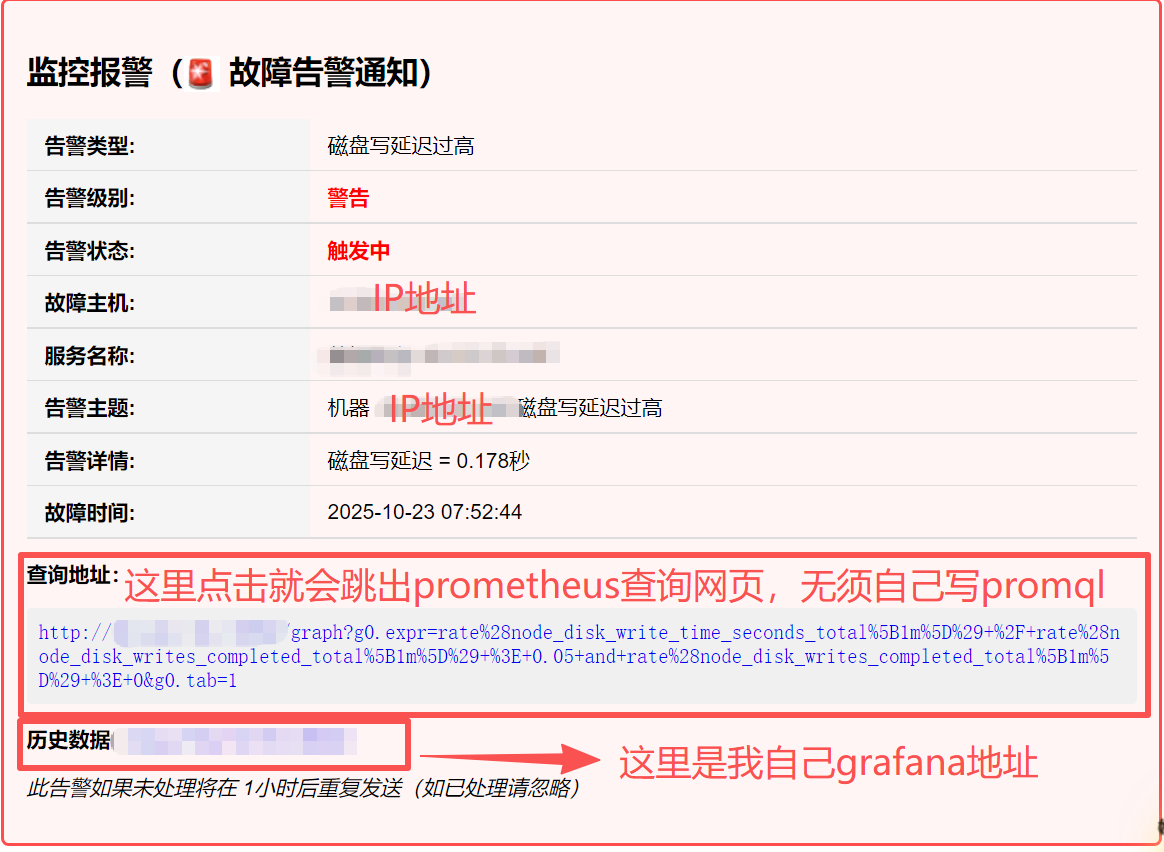
1. 告警状态部分(大约第40行):OUR_GRAFANA_SERVER_IP 替换为您的实际Grafana服务器IP地址
<p><strong>历史数据:</strong><a href="http://OUR_GRAFANA_SERVER_IP:3000">http://OUR_GRAFANA_SERVER_IP:3000</a></p>
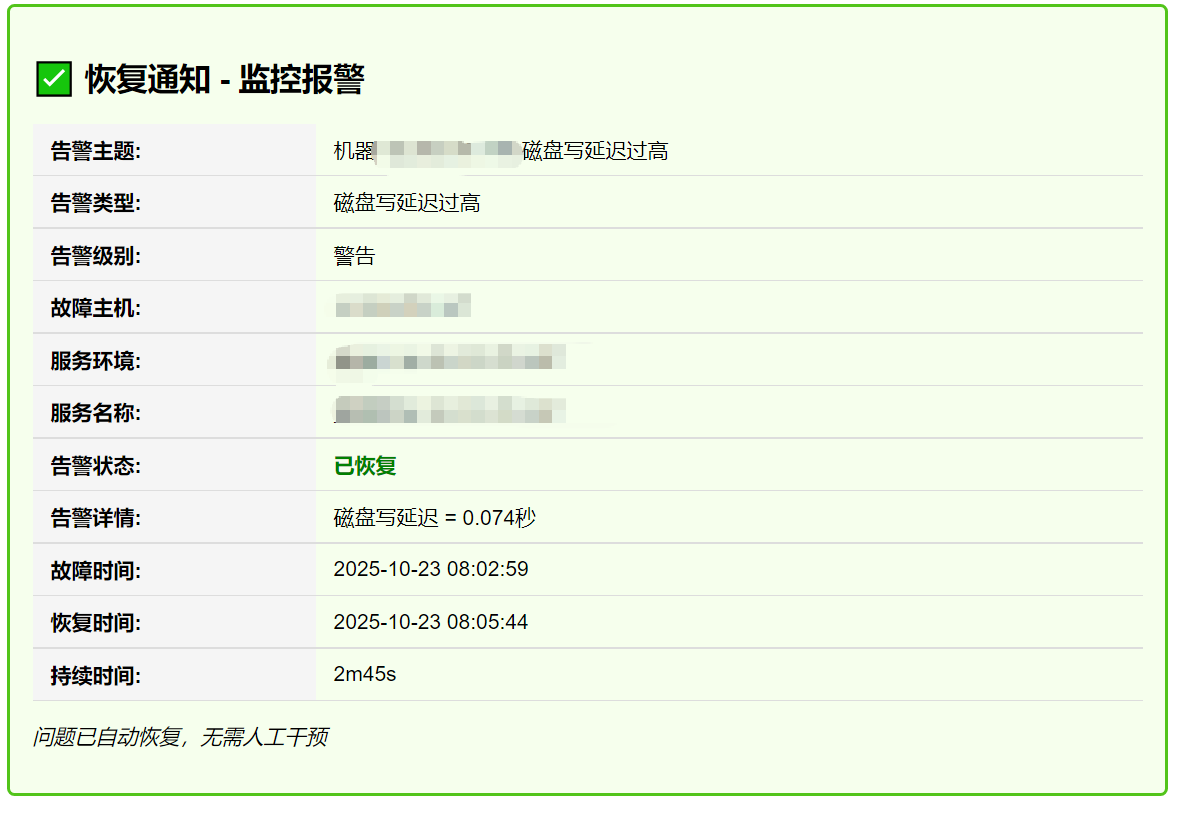
2. 恢复状态部分(大约第70行):OUR_GRAFANA_SERVER_IP 替换为您的实际Grafana服务器IP地址
<p><strong>历史数据:</strong><a href="http://OUR_GRAFANA_SERVER_IP:3000">http://OUR_GRAFANA_SERVER_IP:3000</a></p>
{{ define "custom.subject" }}
{{- if eq .Status "firing" -}}
🚨 监控报警 - {{ .GroupLabels.instance }} - {{ .CommonLabels.alertname }}
{{- else -}}
✅ 恢复通知 - {{ .GroupLabels.instance }} - {{ .CommonLabels.alertname }}
{{- end -}}
{{ end }}{{ define "custom.html" }}
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>{{ template "custom.subject" . }}</title><style>body { font-family: Arial, sans-serif; margin: 20px; }.alert-box { border: 2px solid; padding: 15px; margin: 10px 0; border-radius: 5px; }.firing { border-color: #ff4d4d; background-color: #fff5f5; }.resolved { border-color: #52c41a; background-color: #f6ffed; }table { width: 100%; border-collapse: collapse; margin: 10px 0; }th, td { padding: 8px 12px; text-align: left; border-bottom: 1px solid #ddd; }th { background-color: #f5f5f5; font-weight: bold; }.promql { background-color: #f0f0f0; padding: 8px; border-radius: 3px; font-family: monospace; word-break: break-all; }</style>
</head>
<body>{{ if eq .Status "firing" }}
<div class="alert-box firing"><h2>监控报警(🚨 故障告警通知)</h2><table><tr><th>告警类型:</th><td>{{ .CommonLabels.alertname }}</td></tr><tr><th>告警级别:</th><td><strong style="color: red;">{{- if eq .CommonLabels.severity "critical" }}严重{{- else if eq .CommonLabels.severity "warning" }}警告{{- else }}{{ .CommonLabels.severity }}{{ end -}}</strong></td></tr><tr><th>告警状态:</th><td><strong style="color: red;">{{- if eq .Status "firing" }}触发中{{- else }}已恢复{{ end -}}</strong></td></tr><tr><th>故障主机:</th><td>{{ .GroupLabels.instance }}</td></tr><tr><th>服务名称:</th><td>{{ .CommonLabels.job }}</td></tr><tr><th>告警主题:</th><td>{{ (index .Alerts 0).Annotations.summary }}</td></tr><tr><th>告警详情:</th><td>{{ (index .Alerts 0).Annotations.description }}</td></tr><tr><th>故障时间:</th><td>{{ (index .Alerts 0).StartsAt.Format "2006-01-02 15:04:05" }}</td></tr></table><p><strong>查询地址:</strong></p><div class="promql"><a href="{{ (index .Alerts 0).GeneratorURL }}">{{ (index .Alerts 0).GeneratorURL }}</a></div><p><strong>历史数据:</strong><a href="http://OUR_GRAFANA_SERVER_IP:3000">http://OUR_GRAFANA_SERVER_IP:3000</a></p><p><em>此告警如果未处理将在 1小时后重复发送(如已处理请忽略)</em></p>
</div>{{ else }}<div class="alert-box resolved"><h2>✅ 恢复通知 - 监控报警</h2><table><tr><th>告警主题:</th><td>{{ (index .Alerts 0).Annotations.summary }}</td></tr><tr><th>告警类型:</th><td>{{ .CommonLabels.alertname }}</td></tr><tr><th>告警级别:</th><td>{{- if eq .CommonLabels.severity "critical" }}严重{{- else if eq .CommonLabels.severity "warning" }}警告{{- else }}{{ .CommonLabels.severity }}{{ end -}}</td></tr><tr><th>故障主机:</th><td>{{ .GroupLabels.instance }}</td></tr><tr><th>服务环境:</th><td>{{ .CommonLabels.job }}</td></tr><tr><th>服务名称:</th><td>{{ .CommonLabels.job }}</td></tr><tr><th>告警状态:</th><td><strong style="color: green;">{{- if eq .Status "firing" }}触发中{{- else }}已恢复{{ end -}}</strong></td></tr><tr><th>告警详情:</th><td>{{ (index .Alerts 0).Annotations.description }}</td></tr><tr><th>故障时间:</th><td>{{ (index .Alerts 0).StartsAt.Format "2006-01-02 15:04:05" }}</td></tr><tr><th>恢复时间:</th><td>{{ (index .Alerts 0).EndsAt.Format "2006-01-02 15:04:05" }}</td></tr><tr><th>持续时间:</th><td>{{ (index .Alerts 0).EndsAt.Sub (index .Alerts 0).StartsAt }}</td></tr></table><p><strong>历史数据:</strong><a href="http://OUR_GRAFANA_SERVER_IP:3000">http://OUR_GRAFANA_SERVER_IP:3000</a></p><p><em>问题已自动恢复,无需人工干预</em></p>
</div>{{ end }}</body>
</html>
{{ end }}6. 重启prometheus和alertmanger
注:还需要改下alertmanager启动项添加一个参数--web.external-url=http://192.168.77.7:9090,要不然查询地址:这里会显示http://loacladmin:9090/xxxxxxxx
vim /lib/systemd/system/prometheus.service
ExecStart=/prometheus/prometheus --storage.tsdb.retention=365d --config.file=/prometheus/prometheus.yml --web.external-url=http://192.168.77.7:9090##########################################################################################
systemctl daemon-reload
systemctl restart prometheus.service
systemctl restart alertmanager.service