手搓一个CUDA JIT编译器
文章目录
- 1. 前言
- 2. 背景介绍
- 3. 示例
- 4. Kernel Cache
1. 前言
最近在看一些开源项目,CUDA通过pybind绑定到python接口时,常常需要设计一个JIT编译器来满足对kernel的即时编译调用。受此启发,决定一探究竟,这篇文章将教会搓一个JIT编译组件
2. 背景介绍
要实现一个CUDA JIT编译器,至少有两条路线:
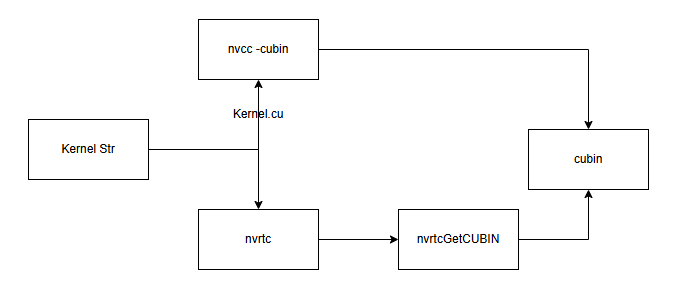
- 线路1:使用
nvcc,需要先将kernel字符串写入到临时文件kernel.cu中,再使用nvcc -cubin编译出cubin file - 线路2:使用
nvrtc, 则可以直接使用字符串,通过nvrtcCompileProgram编译,并使用nvrtcGetCUBIN获得cubin data,写入cubin file
3. 示例
假设我们要运行的Kernel函数是:
const kernelStr = "__global__ void empty() {}";
使用线路1:
先将字符写入kernel.cu
nvcc -dc -cubin --gpu-architecture=sm_90 -O3 kernel.cu -o kernel.cubin
使用线路2:
#include <nvrtc.h>#include <assert.h>
#include <fstream>
#include <sstream>
#include <string.h>
#include <string>
#include <vector>const char kernelStr[] = "__global__ void empty() {}";int main() {const char flags[] = "--gpu-architecture=sm_90";const char cubin_path[] = "kernel.cubin";std::istringstream iss(flags);std::vector<std::string> options;std::string option;while (iss >> option)options.push_back(option);std::vector<const char *> option_cstrs;for (const auto &opt : options)option_cstrs.push_back(opt.c_str());nvrtcProgram program;nvrtcCreateProgram(&program, kernelStr, "kernel.cu", 0, nullptr, nullptr);const auto &compile_result = nvrtcCompileProgram(program, static_cast<int>(option_cstrs.size()), option_cstrs.data());size_t log_size;nvrtcGetProgramLogSize(program, &log_size);if (compile_result != NVRTC_SUCCESS) {if (log_size > 1) {std::string compilation_log(log_size, '\0');nvrtcGetProgramLog(program, compilation_log.data());printf("NVRTC log: %s\n", compilation_log.c_str());}nvrtcDestroyProgram(&program);return 1;}size_t cubin_size;nvrtcGetCUBINSize(program, &cubin_size);std::string cubin_data(cubin_size, '\0');nvrtcGetCUBIN(program, cubin_data.data());std::ofstream out(cubin_path, std::ios::binary);nvrtcDestroyProgram(&program);out.write(cubin_data.data(), cubin_data.size());return 0;
}
编译是需要加入-I/usr/local/cuda/include -lnvrtc -L/usr/local/cuda/lib64 来保证正确link rtc的library和找到头文件
4. Kernel Cache
可以看出一个问题,我们每次运行时,都会去编译这个cubin函数,那么有什么方式可以优化这个操作呢?我们可以使用hash_map来将编译好的cubin file缓存起来,当第二次再次调用时,可以直接从hash_map中获取,从而实现zero compiler.