Hadoop High Availability 简介
目录
引入HA
针对HDFS的高可用
核心组件
故障转移流程
针对YARN的高可用
核心组件
故障转移流程
引入HA
在早期的Hadoop版本中,核心组件存在单点故障问题:
HDFS:NameNode是唯一的主节点,存储了整个文件系统的元数据。如果它宕机,那么整个HDFS将不可用。
YARN:ResourceManager是唯一的全局资源调度器。如果它宕机,所有新的作业无法提交,正在运行中的作业也可能失败。
为了解决单点故障问题,就需要部署备用主节点,来确保集群在主节点发生故障时能够快速恢复,对外提供不间断的服务,这正是高可用的目的。所谓高可用,是为解决单点故障设计的架构方案。
针对HDFS的高可用
HDFS HA通过配置Active-Standby(主-备)两个NameNode来实现高可用,其中主要通过QJM方式来实现状态同步。
核心组件
Active NameNode:对外提供服务的主节点,处理客户端的请求。
Standby NameNode:热备份节点。它的状态必须与Active NameNode实时同步,以便在发生故障时能够无缝衔接。
JournalNode:通常3个活以上奇数个来组成共享存储系统。所有对namespace的修改,Active NN都会先将操作日志(editslog)写入共享存储,然后Standby NN持续地从其中读取并应用这些日志。
DataNode:所有DataNode通过心跳机制向Active NN和Standby NN发送心跳和块报告,所以数据块存储在哪个DN上不需要同步到共享存储中。
ZKFC(Zookeeper Failover Controller):一个运行在每个NN节点上的独立进程,用于监控NN的健康状态并管理故障转移。
故障转移流程
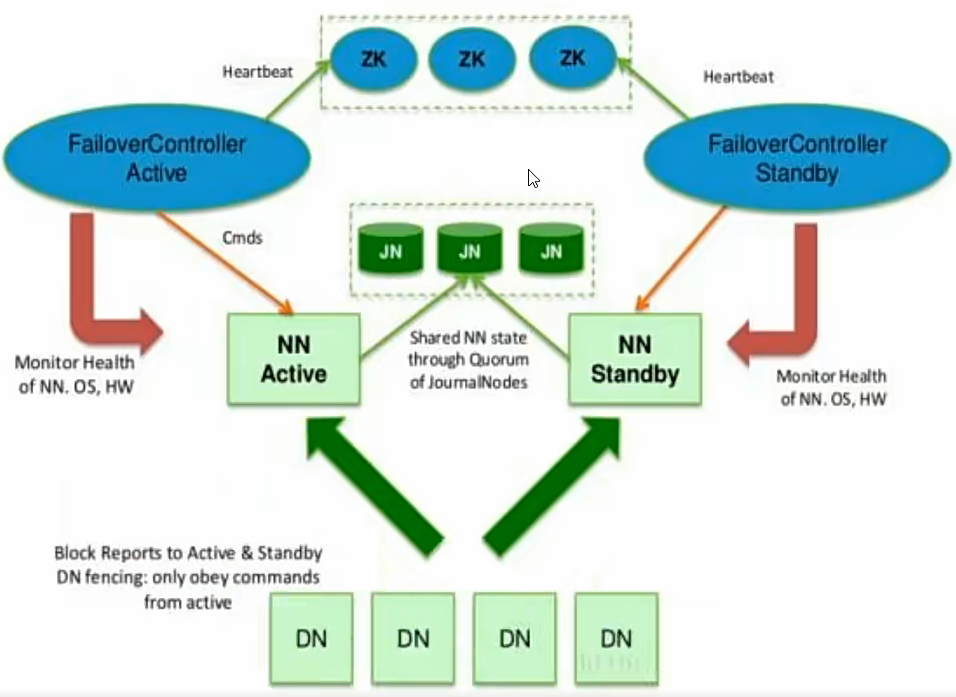
①Active NN的ZKFC检测到Active节点无响应,尝试在zookeeper中删除该临时节点;
②Standby NN的ZKFC监控到这个节点消失,立即尝试创建该节点以宣告自己为新的Active;
③创建成功后,Standby NN的ZKFC会执行一个fence(隔离)命令,强制杀死原Active进程,防止出现脑裂;
④新Active NN从JournalNode中读取编辑日志,并开始接收DN的心跳和块报告;
⑤客户端通过重试机制自动连接新Active,业务无感知。
针对YARN的高可用
YARN HA 的原理与 HDFS HA 非常相似,也是基于 Active-Standby 模式和 ZooKeeper 的自动故障转移。
核心组件
Active ResourceManager:处理所有客户端的请求,管理整个集群的资源。
Standby ResourceManager:热备份节点,随时准备接管。
状态存储:将RM的状态持久化(状态信息)存储在zookeeper中或HDFS文件。
ZooKeeper:用于领导选举和存储YARN集群的状态。多个RM通过竞争,一个成为Active,其余成为Standby
故障转移流程
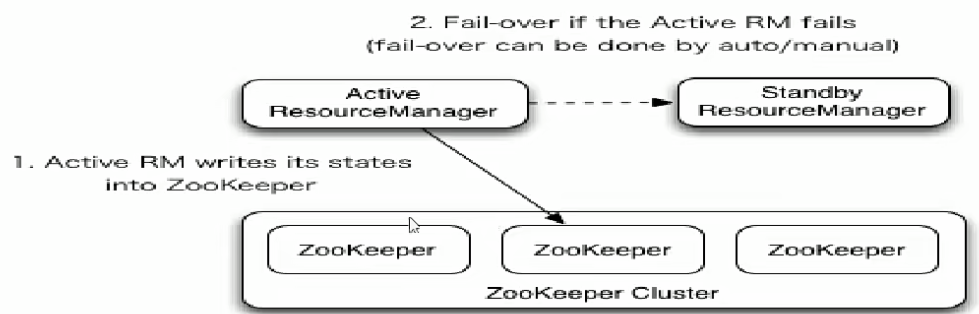
①zookeeper检测到Active ResourceManager故障,相关临时节点被删除;
②所有Standby ResourceManager监测到这一变化,开始新一轮的选举;
③其中一个Standby RM成功在zookeeper创建了代表Active状态的临时节点,成为新的Active RM;
④新的Active RM从状态存储(ZK或HDFS)中重演出故障前的集群状态;
⑤所有NM会通过心跳机制发现Active RM变更,向新王重新注册;所有运行在container的applicationmaster也会重新注册并汇报任务状态,不受影响。