C++:类和对象_bite

类:class 名称{ };类的成员变量没开空间,只有类实例化出对象时才开空间。类实例化出对象,存储类的成员变量,不存储成员函数,函数被编译后只是一段指令,这些指令单独存储在代码区,如果非要存储,只能是成员函数的指针,其实成员函数指针是一个地址,编译时链接,不是在运行时找(动态多态在运行时找)。
内存对齐规则:面试考点:
1.为啥要内存对齐:(内存对齐不是会浪费空间,为啥还有对齐):
2.对象内存对齐的核心目的是匹配CPU读取数据的整数倍规则,避免CPU多次读取同一数据,从而极大提升程序运行效率。
简单来说,若对象数据未对齐(比如本应存在64位地址的字段,偏存在65位),CPU就需要分两次读取再拼接,耗时且耗资源;对齐后,数据刚好落在CPU单次能读的整数倍地址上,一次就能取完,效率直接拉满。例子如下:
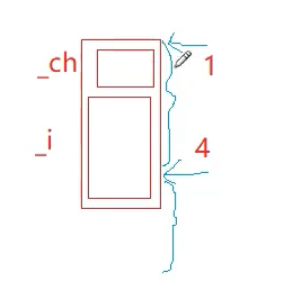
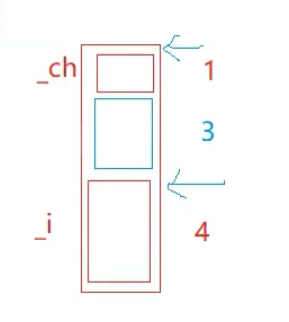
我们以常见的 64位CPU(默认按8字节整数倍读取)和一个包含“int(4字节)+ char(1字节)”的对象为例,直观对比内存对齐前后的差异:
1. 未对齐的内存布局(假设强制紧凑排列)
- 内存地址:0-3字节存int,4字节存char,总占用5字节。
- CPU读取过程:
1. 读取0-7字节(第一次):获取到完整的int(0-3)和char(4),但同时读取了无用的5-7字节。
2. 由于数据跨了“0-7”这个8字节块,部分场景下CPU可能需要额外校验或处理,本质是“不符合硬件读取习惯”,存在隐性耗时。
2. 对齐后的内存布局(按8字节整数倍补齐)
- 内存地址:0-3字节存int,4字节存char,5-7字节自动填充“空数据”(padding),总占用8字节。
- CPU读取过程:
1. 仅需读取0-7字节(一次完成):直接获取到完整的int和char,无需处理无用数据,也无需二次读取。
2. 数据完全落在CPU单次读取的8字节块内,硬件可直接高效处理,没有任何额外开销。
简单讲,对齐用“浪费3字节内存”的小代价,换来了“CPU少干活、速度翻倍”的大收益,是典型的“空间换时间”优化。
3.没有成员的类,默认为一字节:为啥不为0?
核心原因:避免 “空对象地址重叠”
C++ 标准规定,任何两个不同的对象必须拥有不同的内存地址(即 “每个对象都要有唯一标识”)。如果空类的大小为 0,会导致以下矛盾:
- 当创建多个空类的对象时(如
EmptyClass a, b;),a和b的大小都是 0,编译器无法为它们分配不同的内存地址,会出现 “两个对象地址完全重叠” 的情况,违反了对象唯一性的规则。
类的特性:1.封装 方法和成员结合在一起
类中的变量称为类的属性或成员变量,为了区分可加_或者_m
类中的函数称为类的方法或成员函数,默认为inline,展不展看编译器
类和struct的区别:如果没有访问限定符修饰的话,struct成员默认是公有的,class是私有的。
类域,全局域,命名空间域,局部域:
1.不同的域可以有同名变量,不同的域不能有。
2.命名空间域,类域不会影响生命周期,局部域和全局域影响。
3.声明和定义分离的时候需要指定类域,声明开空间,定义不开空间。
4.缺省参数声明时给,定义时就不用给
this指针:
1.编译器编译后,类的成员函数默认会在形参第一个位置,增加一个当前类类型指针,叫做this指针。比如Date类的Init的真实原型为:void Init(Date* const this)这里的const修饰的是指针本身。
2.c++规定不能在实参和形参的位置显示写this指针,但是可以在函数体内显示使用this指针。
stack类的实现:
#include <iostream>
#include <assert.h>
using namespace std;
class Stack
{
public://初始化void Init(int n = 4){array=(int*)malloc(sizeof(int) * n);if (nullptr == array){perror("mallc申请空间失败");return;}capacity = n;top = 0;}void Push(int x){//array[top++] = x;}void Top(){assert(top > 0);return array[top - 1];}void Destory(){free(array);array = nullptr;top = capacity = 0;}
private:int* array;size_t capacity;size_t top;};int main()
{Stack st;//类名字就是类型st.Init();st.Push(1);st.Push(2);cout << st.Top() << endl;st.Destory();return 0;
}struct例子:
struct Person
{void Init(const char* name, int age, int tel){strcpy_s(_name, name);_age = age;_tel = tel;}void print(){cout << "姓名" << _name << endl;cout << "年龄"<<_age<< endl;cout << "电话" <<_tel<< endl;}char _name[10];int _age;int _tel;
};int main()
{ Person p1;p1.Init("张三", 18, 15719599053);p1.print();return 0;
}1.默认成员函数就是用户没有显示实现,编译器会自动生成的成员函数。6个默认成员函数,构造,析构函数,拷贝赋值,取地址重载(普通对象和const对象)取地址。
2.构造函数的特点:
函数名与类名相同
无返回值
对象实例化时系统会自动调用对应的构造函数
构造函数可以重载
如果类中没有显示定义构造函数,则C++编译器会自动生成一个无参的默认构造函数,一旦用户显示定义编译器将不会再生成。
无参构造函数,全缺省构造函数,我们不写构造时编译器默认生成的构造函数,都叫默认构造函数。但是这三个函数同时只能有且仅有一个存在,不能同时存在,无参构造函数和全缺省构造函数虽然构成函数重载,但是调用时会存在歧义。总之不传实参的就可以调用的构造就叫默认构造。
我们不写编译器默认生成的构造,对内置类型成员变量的初始化没有要求,也就是说是是否初始化是不确定的,看编译器。对于自定义类型成员变量,要求调用这个成员变量的默认构造函数初始化。如果这个成员变量,没有默认构造,就会报错,我们要初始化这个成员变量,需要用初始化列表才能解决。
c++把类型分成内置类型(基本类型)和自定义类型。内置类型就是语言提供的原生数据类型,如:int/char/double/指针等,自定义类型就是我们使用class/struct等关键字自己定义的类型。