自然语言处理分享系列-词语和短语的分布式表示及其组合性(二)
上一篇文章:自然语言处理分享系列-词语和短语的分布式表示及其组合性(一)
一、skip-gram:
1.1 负采样
作为分层softmax的替代方案,噪声对比估计(Noise Contrastive Estimation, NCE)由Gutmann和Hyvarinen提出[4],并被Mnih和Teh应用于语言建模[11]。NCE的核心思想是:优秀模型应能通过逻辑回归区分真实数据与噪声。这与Collobert和Weston使用的合页损失类似[2],后者通过将真实数据排名高于噪声来训练模型。
尽管NCE可被证明近似最大化softmax的对数概率,但Skip-gram模型仅关注学习高质量的向量表示,因此只要向量表示的质量得以保持,可自由简化NCE。负采样(Negative Sampling, NEG)的目标函数定义为:
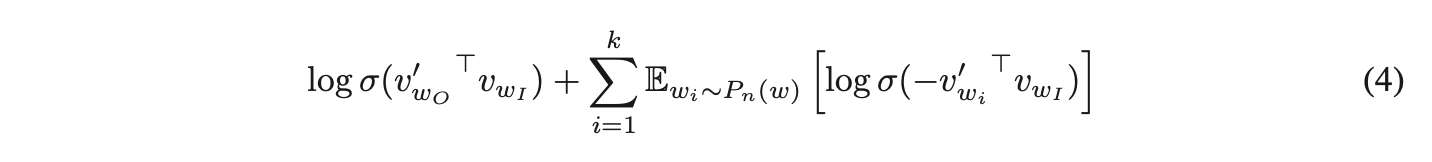
负采样与噪声对比估计的区别
负采样方法用于替代Skip-gram目标函数中的每一项log P(wO|wI)。其核心任务是通过逻辑回归,从噪声分布Pn(w)的采样中区分目标词wO。每个真实数据样本对应k个负样本,实验表明:小规模数据集适合k值范围为5-20,而大规模数据集k值可降至2-5。
关键技术差异
负采样与噪声对比估计(NCE)的主要区别在于:NCE需要噪声分布的样本及其数值概率,而负采样仅需样本。NCE近似最大化softmax的对数概率,但这一特性在本应用中并非关键。
噪声分布优化
两种方法均将噪声分布Pn(w)作为自由参数。研究发现,将unigram分布U(w)的3/4次方(即U(w)^(3/4)/Z)作为噪声分布时,效果显著优于原始unigram分布和均匀分布。该结论在包括语言建模在内的多项任务中均得到验证(部分实验未展示)。
1.2 高频词子采样
在超大规模语料库中,高频词(如“in”“the”“a”)可能出现数亿次,其信息价值通常低于低频词。例如,Skip-gram模型从“France”和“Paris”的共现中获益,但从“France”和“the”的频繁共现中获益甚微,因为几乎所有词都会与“the”在句子中共现。类似地,高频词的向量表示在数百万次训练后变化不显著。
采样方法
为平衡高频词与低频词的不均衡性,采用以下子采样策略:训练集中的每个词 被丢弃的概率由公式计算得出:
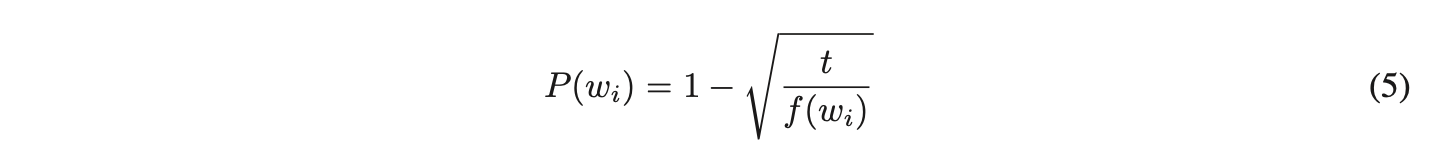
其中 表示单词
的频率,
为预设阈值(通常设为
左右)。该子采样公式的设计动机是:对频率显著高于
的单词进行激进降采样,同时保持词频的原始排序关系。尽管公式的选择具有经验性,但实践证明其效果显著——既能加速模型训练,又能显著提升低频词向量的学习精度(具体效果将在后续章节展示)。
二、实证结果
本节评估了分层Softmax(HS)、噪声对比估计(NCE)、负采样(Negative Sampling)以及训练词子采样方法的效果。实验采用Mikolov等人提出的类比推理任务,该任务包含诸如“德国 : 柏林 :: 法国 : ?”的类比问题,通过计算向量与
的余弦距离来求解(搜索时排除输入词)。若
为“巴黎”,则视为正确答案。任务分为两大类别:句法类比(如“quick : quickly :: slow : slowly”)和语义类比(如国家与首都的关系)。
Skip-gram模型的训练数据来自包含大量新闻文章的内部谷歌数据集(约十亿词)。词汇表中剔除了出现次数少于5次的低频词,最终词汇量为69.2万。表1展示了不同Skip-gram模型在类比测试集上的表现,结果表明负采样在类比推理任务上优于分层Softmax,且略胜于噪声对比估计。对高频词子采样不仅将训练速度提升数倍,还显著提高了词向量的准确性。
尽管Skip-gram模型的线性特性使其向量更适合线性类比推理,但Mikolov等人的研究也表明,标准sigmoid循环神经网络(高度非线性)的词向量随着训练数据量的增加,在该任务上表现显著提升,暗示非线性模型同样倾向于词向量的线性结构。
三、学习短语
短语的含义通常并非其组成单词意义的简单组合。为学习短语的向量表示,需先识别经常共同出现且在其他语境中较少出现的词语组合。例如,“New York Times”和“Toronto Maple Leafs”在训练数据中被替换为唯一标记,而二元组“this is”则保持不变。
这种方法可在不显著增加词汇量的前提下生成大量合理短语;理论上,可使用所有n-gram训练Skip-gram模型,但这会导致内存消耗过高。此前已有多种文本短语识别技术,但比较这些技术超出了研究范围。研究采用了一种基于数据驱动的简单方法,通过单字词和二元组的统计频率来构建短语。
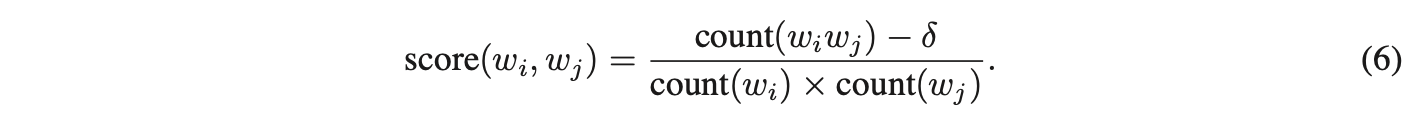
δ用作折扣系数,防止形成过多由低频词组成的短语。得分超过选定阈值的高频二元词组会被保留为短语。通常会对训练数据进行2-4轮处理,逐步降低阈值,从而允许形成由多个单词组成的更长短语。
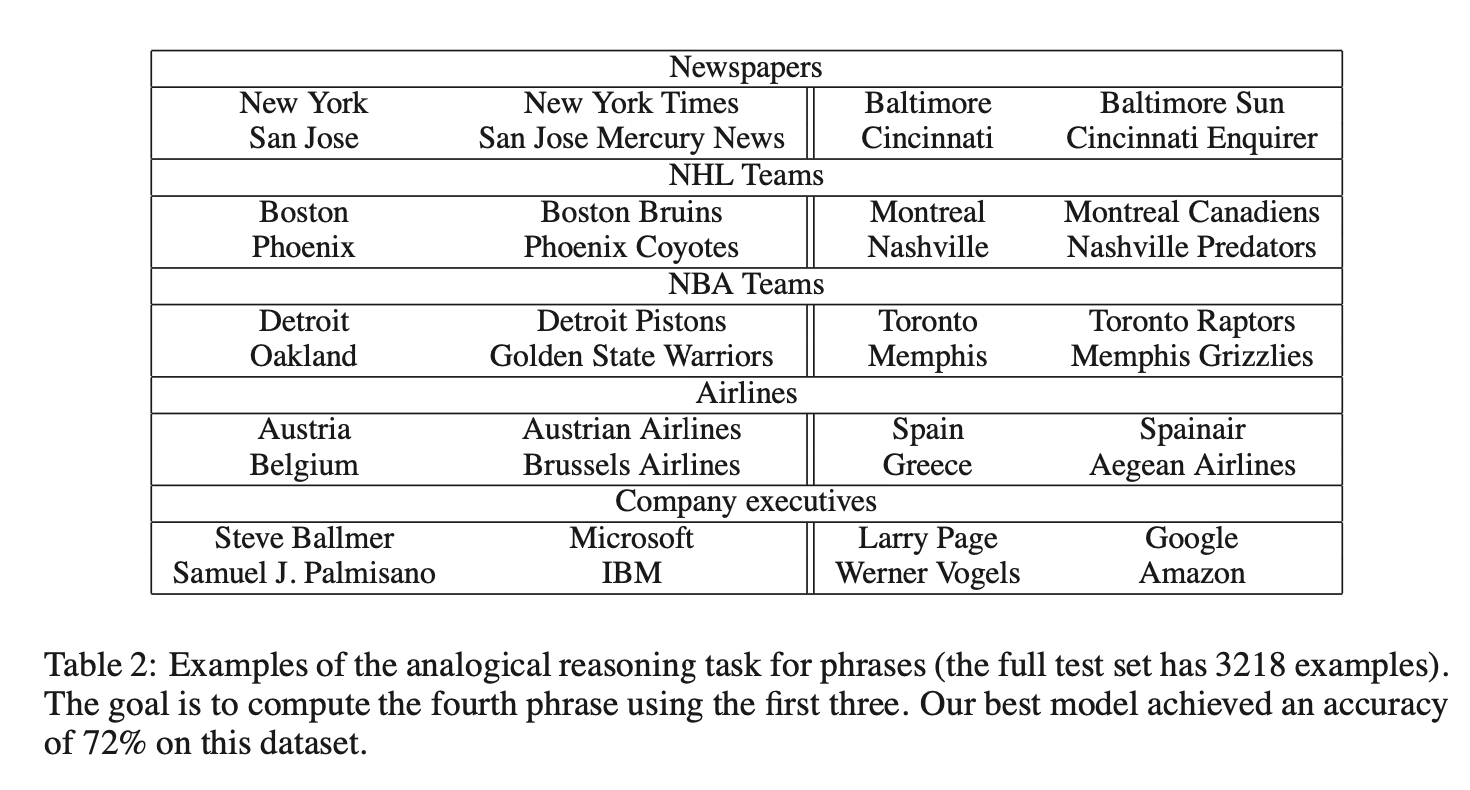
通过一个新的短语类比推理任务评估短语表示的质量。表2展示了该任务中使用的五种类比示例。该数据集已在网上公开。
3.1 短语Skip-Gram实验结果


基于相同的新闻数据,首先构建了基于短语的训练语料库,随后使用不同超参数训练了多个Skip-gram模型。实验沿用向量维度300和上下文窗口大小5的配置,该设置在短语数据集上已表现良好,并能快速对比负采样(Negative Sampling)与分层Softmax(Hierarchical Softmax)的性能差异,包括是否采用高频词降采样(subsampling)。结果汇总于表3。
实验表明,负采样在k=5时已能达到不错准确率,但k=15时性能显著提升。值得注意的是,分层Softmax在不采用降采样时表现较差,而引入高频词降采样后成为最佳方法。这说明降采样不仅能加速训练,在某些情况下还能提高准确率。
为在短语类比任务中实现最高准确率,通过使用约330亿单词的数据集扩大训练数据规模。采用分层Softmax、1000维向量及完整句子上下文,最终模型准确率达到72%。若将训练数据缩减至60亿单词,准确率降至66%,表明海量训练数据至关重要。
为进一步分析不同模型学到的表征差异,手动检查了低频短语在不同模型中的最近邻结果(示例见表4)。与先前结论一致,采用分层Softmax和降采样的模型能学习到最佳的短语表征。
四、加性组合性

Skip-gram模型学习到的词和短语表征展现出一种线性结构,使得通过简单的向量运算即可实现精确的类比推理。有趣的是,Skip-gram表征还呈现另一种线性结构,使得通过词向量的逐元素相加能够有意义地组合词语。这一现象在表5中得以展示。
向量的加性特性可通过训练目标来解释。词向量与softmax非线性层的输入呈线性关系。由于词向量被训练用于预测句子中的上下文词语,这些向量可视为词语出现上下文的分布表征。这些值与输出层计算的概率呈对数关系,因此两个词向量的和与两个上下文分布的乘积相关。乘积在此处起到“与”函数的作用:被两个词向量同时赋予高概率的词语将获得高概率,其余词语则保持低概率。
例如,若“伏尔加河”频繁与“俄罗斯”和“河”出现在同一句子中,这两个词向量的和将生成一个接近“伏尔加河”向量的特征向量。
五、与已发布的词表示方法对比
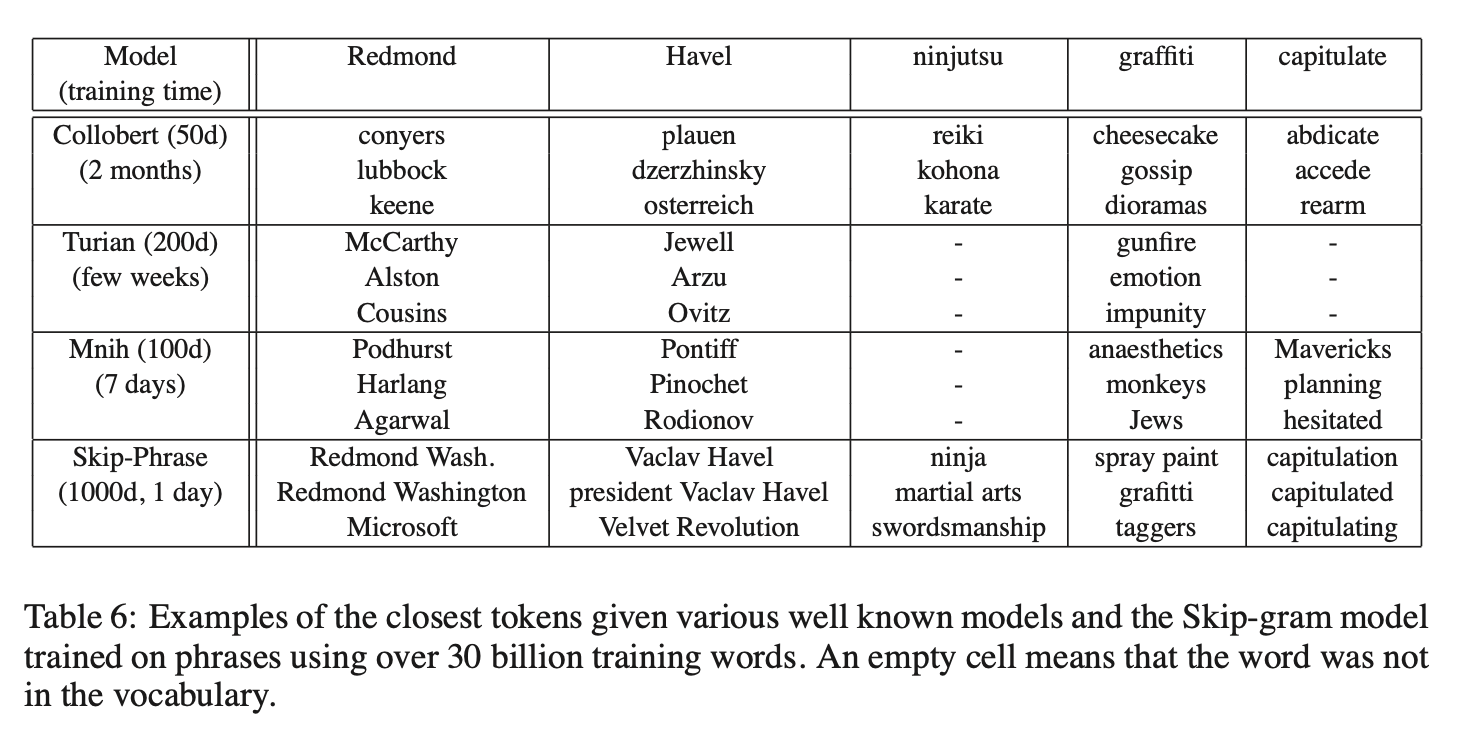
多位研究者曾基于神经网络开发词表示模型,并将训练结果公开发布以供后续使用和比较,其中最知名的包括Collobert和Weston [2]、Turian等 [17] 以及Mnih和Hinton [10] 的工作。相关词向量可从网络获取。Mikolov等 [8] 已通过词语类比任务评估这些词表示方法,其中Skip-gram模型以显著优势取得最佳性能。
为更直观展示不同模型学习到的词向量质量差异,表6通过低频词的最近邻示例进行实证对比。结果显示,基于大规模语料训练的大型Skip-gram模型在词表示质量上明显优于其他所有模型。这一优势部分归因于该模型的训练数据规模(约300亿单词),比先前研究通常使用的数据量高出两到三个数量级。值得注意的是,尽管训练集规模大幅增加,Skip-gram模型的训练时间反而远低于此前模型架构所需的时间复杂度。
六、主要贡献
本研究包含多项关键成果。通过Skip-gram模型训练词与短语的分布式表示,并证明这些表示具备线性结构,可实现精确的类比推理。所提出的技术同样适用于训练先前提出的连续词袋模型(参见文献[8])。
得益于高效的计算架构,模型成功训练于比以往公开研究规模大数个数量级的数据集上,显著提升了词与短语表示的质量,尤其是低频实体。研究发现,对高频词进行子采样能加速训练,同时大幅改善罕见词的表示效果。另一贡献是负采样算法,这种极简训练方法能高效学习高频词的精准表示。
算法与超参数
训练算法和超参数的选择需针对具体任务,不同问题存在不同的最优配置。实验表明,影响性能的核心因素包括模型架构选择、向量维度、子采样率及训练窗口大小。
词向量组合与短语表示
研究发现,词向量通过简单向量加法即可实现一定程度的语义组合。另一种短语表示方法是将短语视为单一标记。两种方法结合能以极低计算复杂度高效表示长文本,与现有基于递归矩阵-向量操作的短语表示方法(文献[16])形成互补。
开源共享
基于本研究的词与短语向量训练代码已作为开源项目发布。
https://code.google.com/archive/p/word2vec/
本篇论文内容就分享到这里啦~