为什么跨数据库业务总是慢?
这个标题有点吸引人了。好几天没写东西了,今天想到这个写一下。
单机的性能其实并不差
- 倚老卖老说一下,2003年的时候就是单机Oracle处理TB级别的数据量(虽然数据量说起来并不大,但是比如今很多企业的数据库的规模要大)
- 每秒写入量从几百到几千都有。那时候还没有SSD硬盘。内存也是从8G慢慢发展过来的。而现如今有的朋友笔记本的内存都32G了。当时的情况下,我们就充分利用数据库的能力,也平稳的做到了压力承载。
- 要说一下,过去也不需要Redis的缓存、因为SQL写的好读取的也都是内存。
- 也没有用消息队列来缓冲,因为每秒几千写入数据库又不是承载不了。要是每秒几千万,那是单机处理不了。
- 与其多一个环节,多一道流程,多一个故障点,还不如不要。
说说跨库
- 用过Oracle和DB2这样的数据库的朋友应该听过一次名词,叫DBLink。A库的本地表和通过DBLink的B库的进行关联,效果通常不太好(反正比本地查询慢,应该都有这个感觉。就是:通常在一个数据库实例中的多表关联是比跨库执行要快的)
- 我之前对不理解这个原理的场景的人讲,很多人仅仅是听过但是没有概念。可能是不太直观。
需要数字支持
- 模拟场景:
- 在一个数据库上有A和B两个表
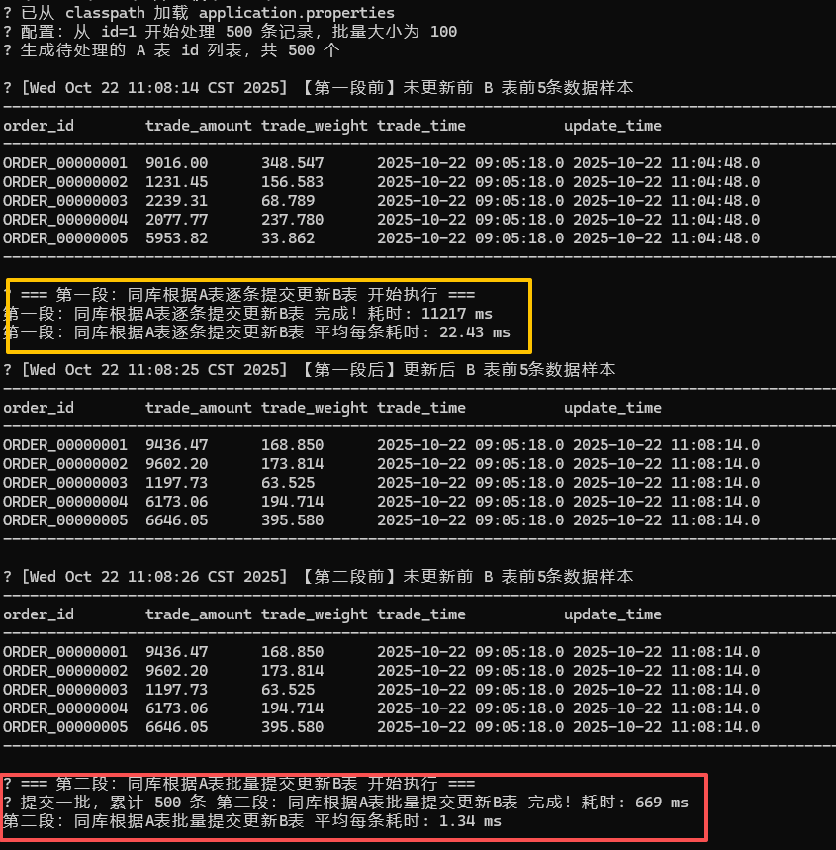
- 根据A表的数据更新B表。以500条为测试样本。(总数1万条)
-
同库根据A表逐条提交更新B表 完成耗时: 11217 ms
-
同库根据A表逐条提交更新B表 平均每条耗时: 22.43ms
-
同库根据A表批量提交更新B表 完成耗时: 669 ms
-
同库根据A表批量提交更新B表 平均每条耗时: 1.34ms
-
批量比逐条快将近15倍。这是数据库本身刷脏机制决定的。批量就是比逐条提交快。
-
那么跨数据库呢?
-
在一个数据库上有A在另外一个数据库上有B两个表
-
根据A表的数据更新B表。以500条为测试样本。(总数1万条)
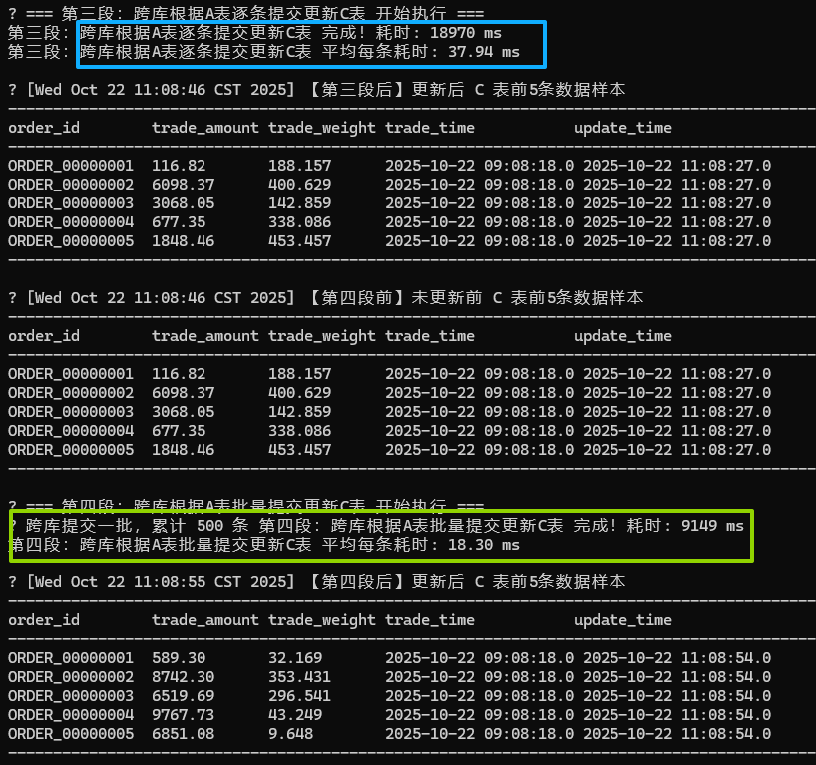
- 跨库根据A表逐条提交更新C表 完成耗时: 18970 ms
- 跨库根据A表逐条提交更新C表 平均每条耗时: 37.94 ms
- 跨库根据A表批量提交更新C表 完成耗时: 9149 ms
- 跨库根据A表批量提交更新C表 平均每条耗时: 18.30 ms
解释
- 可能会问,什么叫跨库根据A表去更新C表。我来解释一下,就是本来比如一个人买了两张车票付了一笔钱。但是退了一张车票。如果车票的表和支付的表(或者说账户的表)不是一个数据库。那么就是要从一个数据库查到了,通过接口或者服务去另外一个数据库更新。
个人观点
- 如果分很多数据库的话,如果考虑一致性和性能的话,应该以事务的维度拆分。
- 如果不考虑性能和一致性,其实怎么拆分都无所谓。
- 如果中间再夹杂其他的组件或者环节,那只能是慢上加慢。如果没有达到数据库自身写入的瓶颈,建议不要增加其他环节来添堵。