GPTBots 工作流:让AI从“会说“到“会做“的技术演进引言:企业AI化的瓶颈在哪里?
当我们谈论企业AI应用时,大多数人想到的是智能对话、问答助手这类"会说话"的AI。然而在真实的企业场景中,AI的价值远不止于此——企业更需要"会做事"的AI。
想象这样的场景:
- 市场部需要每周自动生成竞品分析报告
- HR需要从数百份简历中自动筛选候选人并生成面试问题
- 客服需要自动处理订单查询、退款申请等标准化流程
这些任务都有一个共同特征:需要多个步骤串联、需要调用多个系统、需要按照固定流程执行。传统的做法是编写代码、对接接口、部署上线,这个过程往往需要数周甚至数月。
GPTBots 工作流正是为了解决这个问题而生——让复杂的AI任务流程化、可视化、零代码化。
一、核心设计理念:三个关键突破
1.1 从编程到搭积木:可视化流程设计
传统的自动化开发需要写代码、调试、部署,而工作流将这一切简化为"画布式编排":
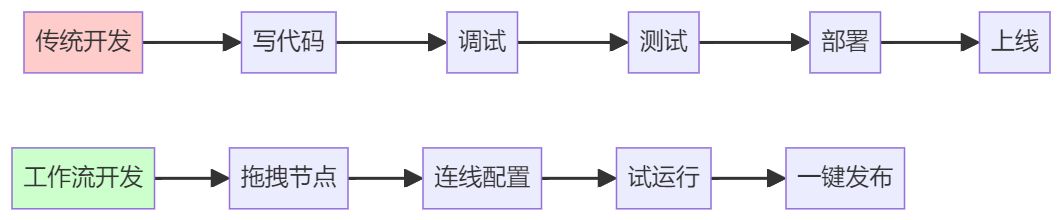
关键创新:
- 节点化思维:每个功能是一个节点(LLM推理、API调用、数据处理等)
- 连线即逻辑:节点间的连线代表数据流动和执行顺序
- 所见即所得:画布上看到的就是实际执行的流程
1.2 从数据孤岛到数据流动:变量系统
工作流最强大的地方在于其变量系统——它让数据在不同节点间自由流动:

变量引用示例:
- {{START.user_id}} - 引用开始节点的输入
- {{database_node.user_name}} - 引用数据库节点的输出
- {{llm_node.result.summary}} - 引用嵌套字段
这种设计让非技术人员也能理解数据如何在流程中传递。
1.3 从单一模式到多场景适配:灵活执行
工作流支持多种执行模式,适应不同场景:

二、技术架构:四层设计支撑复杂场景
2.1 整体架构一览
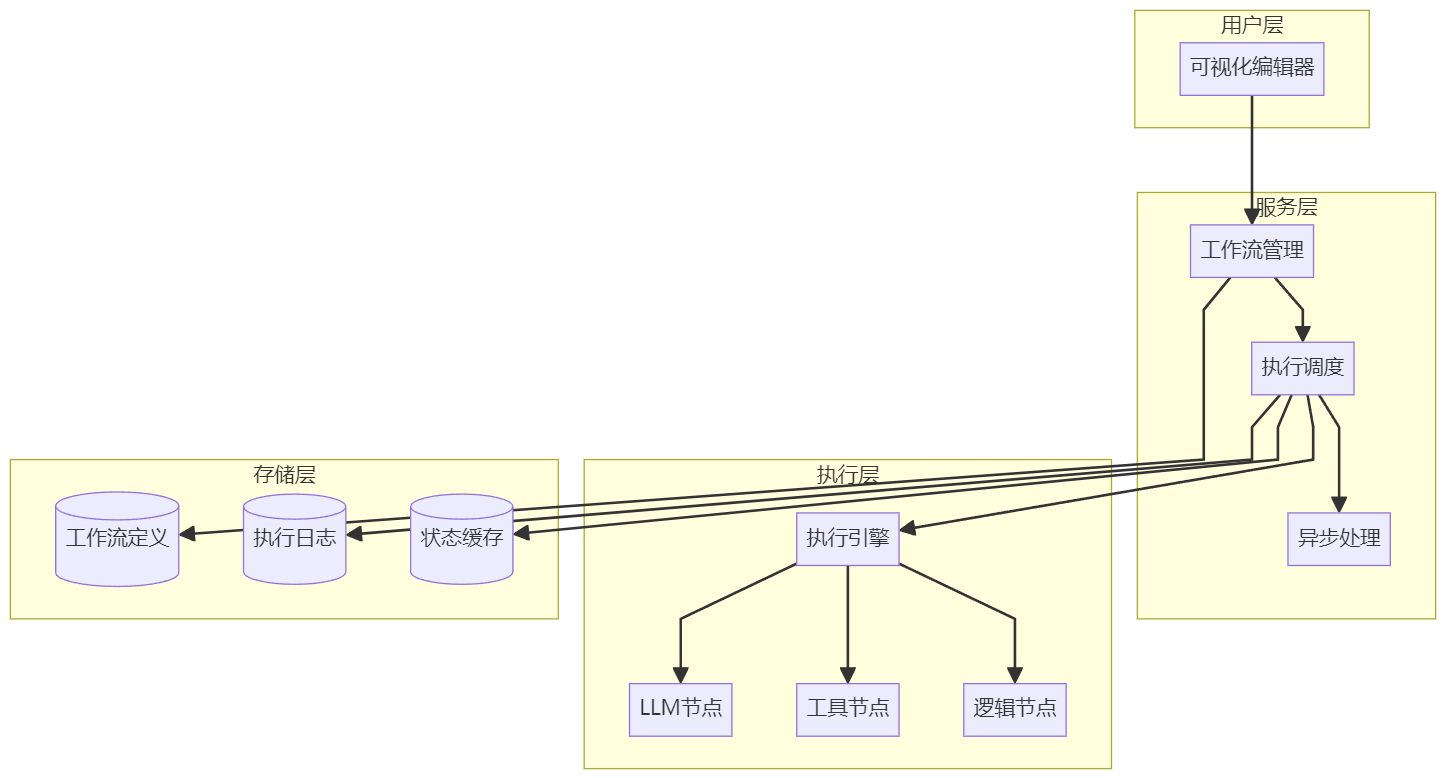
分层职责:
- 用户层:提供拖拽式界面,零代码设计流程
- 服务层:处理流程管理、权限控制、执行调度
- 执行层:真正执行各类节点的业务逻辑
- 存储层:持久化流程定义和执行记录
2.2 执行流程:从请求到结果
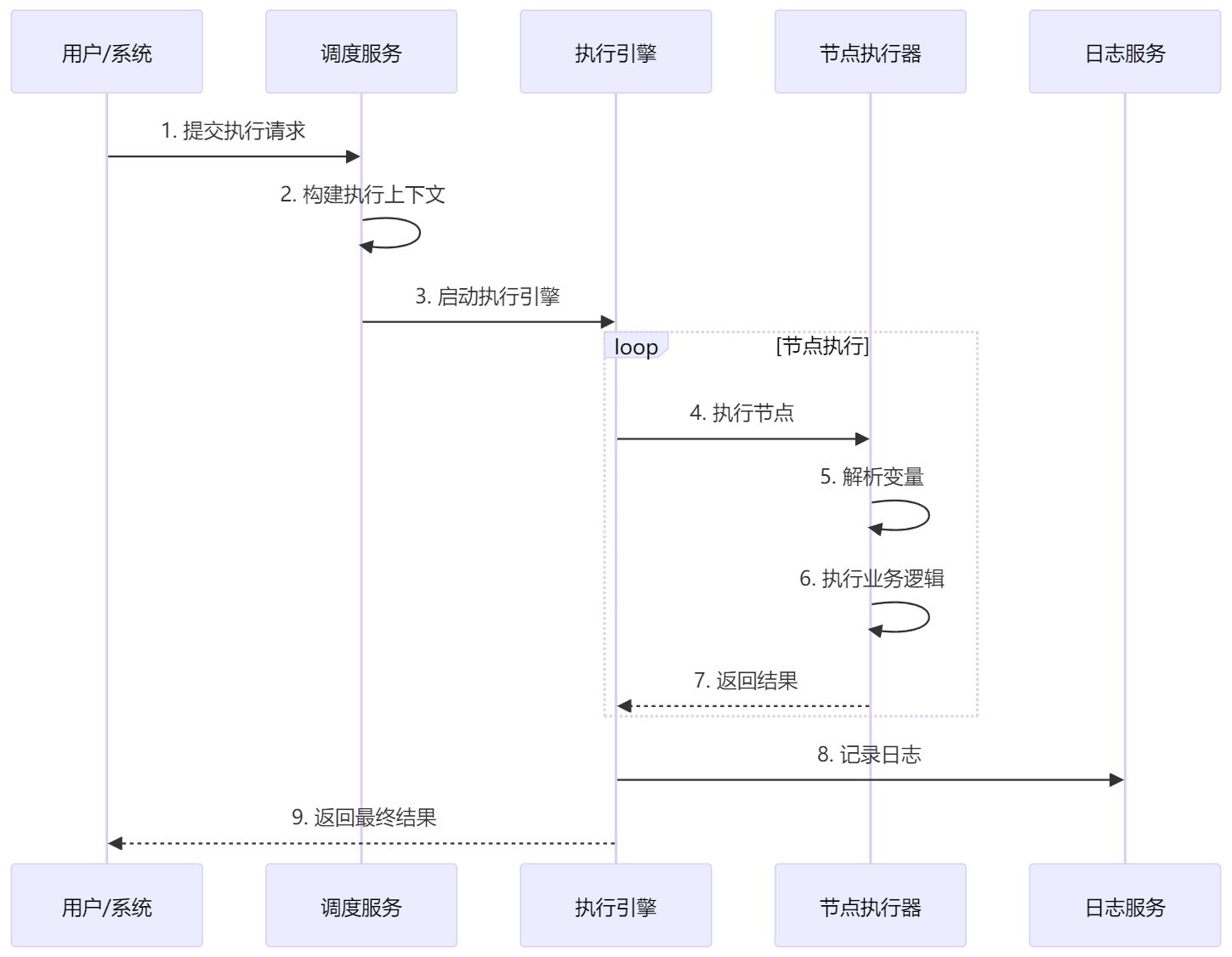
关键步骤解析:
- 上下文构建:加载流程定义、初始化变量、建立节点映射
- 变量解析:将 {{nodeId.field}} 替换为实际值
- 节点执行:根据节点类型调用对应执行器
- 状态管理:记录执行状态、成本消耗、错误信息
2.3 拓扑排序:工作流执行的核心算法
工作流本质上是一个有向无环图(DAG,Directed Acyclic Graph)——节点代表任务,边代表依赖关系。如何保证节点按正确顺序执行,同时最大化并行度?答案是拓扑排序算法。
2.3.1 为什么工作流是DAG?
DAG的三个关键特征:
- 有向:节点间有明确的执行顺序(从A到B,不能从B到A)
- 无环:不能出现循环依赖(A→B→C→A这种情况被禁止)
- 可并行:无依赖关系的节点可以同时执行(B和C可以并行)
2.3.2 拓扑排序算法原理
Kahn算法是工作流引擎最常用的拓扑排序算法:
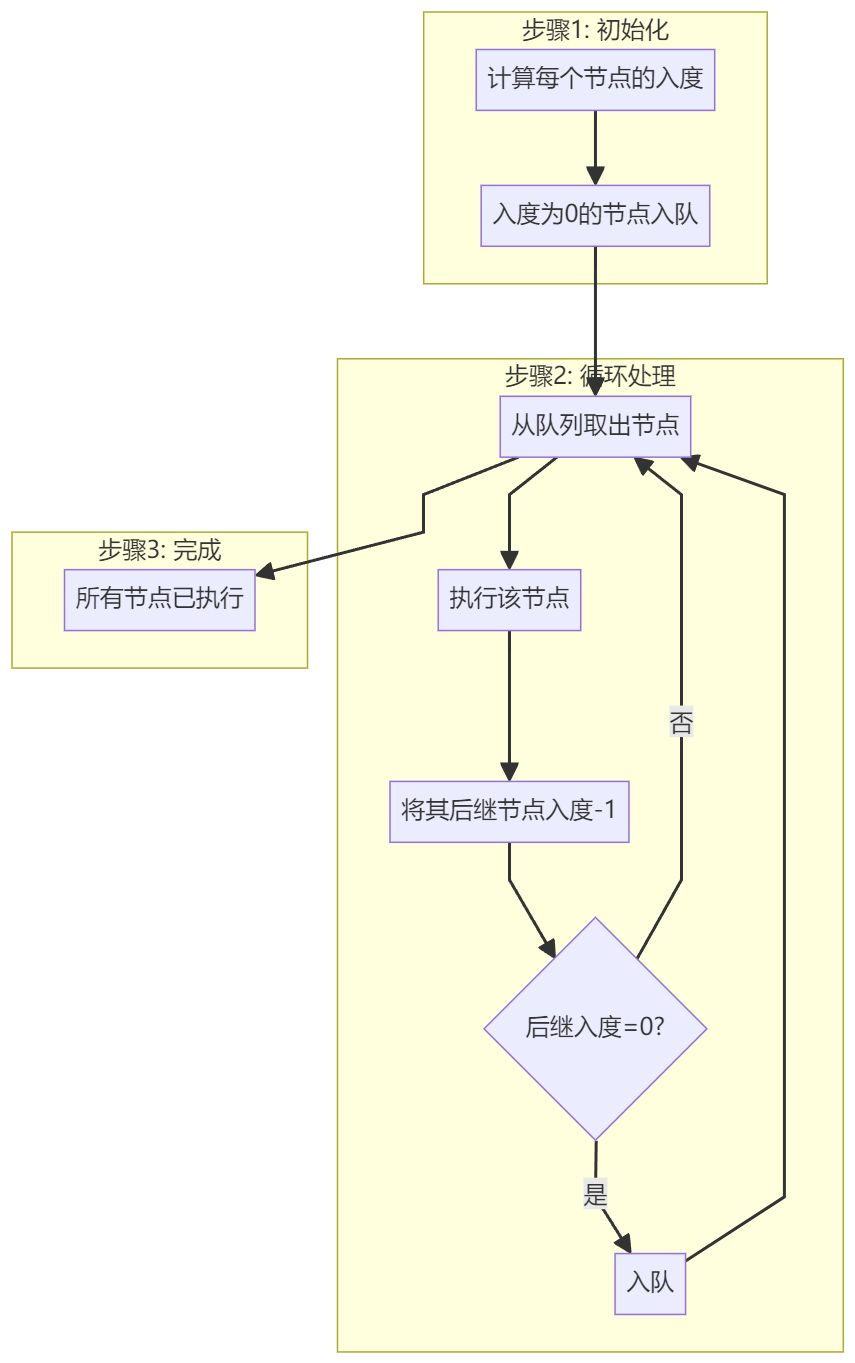
算法详解:
- 入度计算:
- 开始节点入度=0(没有前置依赖)
- 其他节点入度=指向它的边的数量
- 执行队列:
- 将所有入度为0的节点加入执行队列
- 这些节点可以立即执行(无依赖)
- 逐步执行:
- 从队列取出节点并执行
- 执行完成后,将其所有后继节点的入度-1
- 如果某个后继节点入度变为0,说明其前置依赖已全部完成,可以加入执行队列
- 并行优化:
- 队列中的所有节点可以并行执行
- 这就是工作流实现高性能的关键
2.3.3 实例演示:并行执行的提升
假设有这样一个工作流:
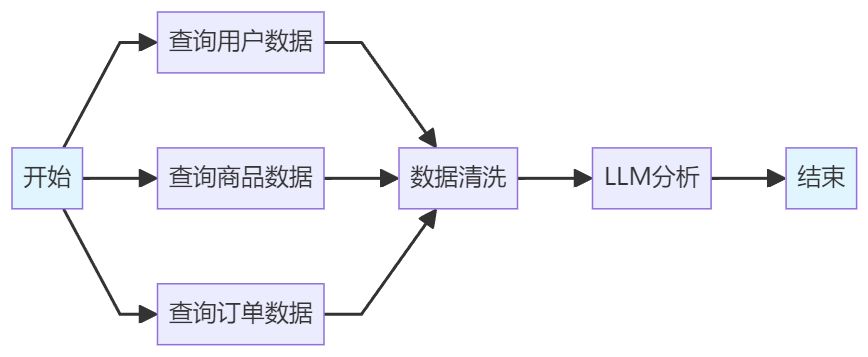
执行过程分析:
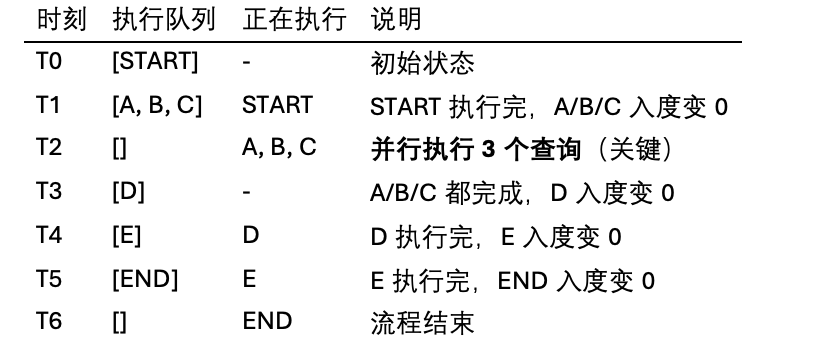
性能对比:
串行执行:START(1s) → A(2s) → B(2s) → C(2s) → D(3s) → E(4s) → END(1s) = 15秒
并行执行:START(1s) → [A/B/C并行2s] → D(3s) → E(4s) → END(1s) = 11秒
性能提升:36%
2.3.4 循环依赖检测
拓扑排序还有一个重要作用:检测循环依赖。
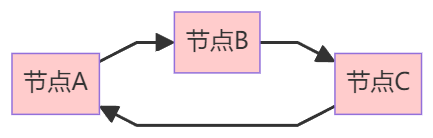
检测原理:
- 如果执行完所有入度为0的节点后,仍有节点未被访问
- 说明存在循环依赖,这些节点永远无法被执行
- 系统在保存工作流时就会报错,拒绝保存
错误提示示例:
❌ 检测到循环依赖:节点A → 节点B → 节点C → 节点A
⚠️ 请调整节点连线,确保流程不存在循环
2.4 节点类型:12种能力覆盖全场景

节点能力说明:
- AI节点:调用大模型进行推理、生成、分析
- 集成节点:对接外部系统和API
- 数据节点:处理结构化/非结构化数据
- 逻辑节点:实现复杂的流程控制
三、核心能力:三大技术亮点
3.1 智能变量系统:让数据流动起来
变量系统是工作流的"神经网络",它解决了节点间数据传递的问题。
变量解析流程:
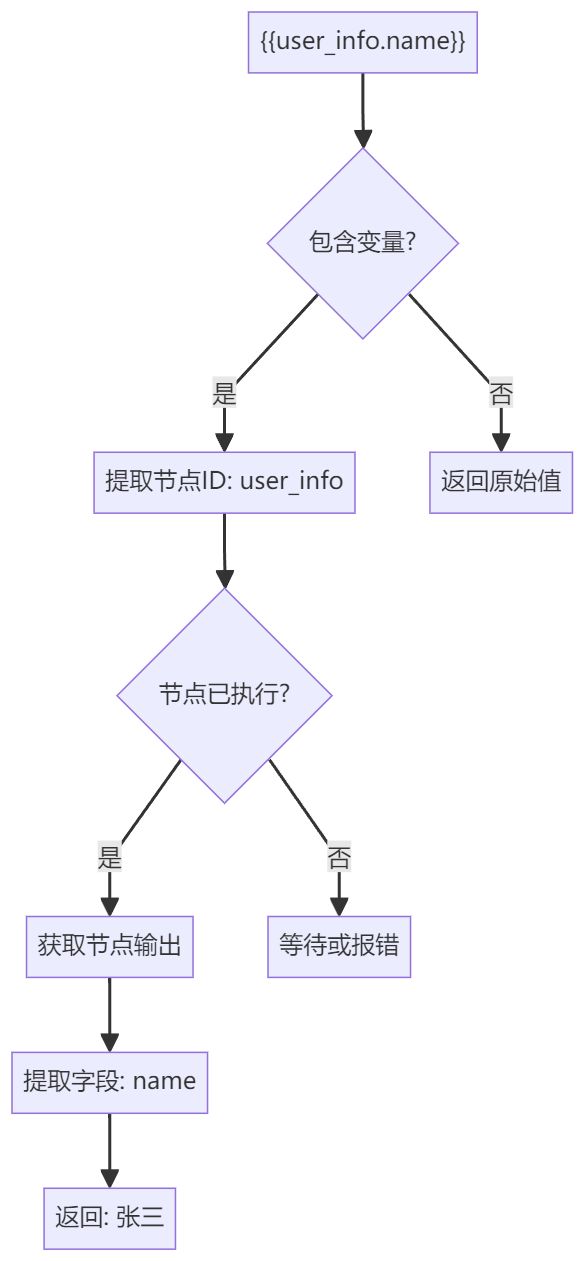
实际应用示例:
假设有一个"客户跟进"工作流:
- START节点输入客户ID:customer_001
- 数据库节点查询客户信息,输出:{name: "张三", last_contact: "2024-01-15"}
- LLM节点生成跟进文案,Prompt中使用:请为客户{{db_query.name}}生成跟进邮件
- 邮件节点发送,收件人:{{db_query.email}}
这种设计让流程既灵活又直观。
3.2 异步执行架构:支撑长时任务
对于耗时较长的任务(如批量数据处理、大文件分析),工作流提供了完善的异步执行方案:

异步模式特性:
- 快速响应:秒级返回执行ID
- 主动通知:支持配置多个Webhook(最多5个)
- 状态查询:随时通过RunID查询执行状态
- 安全校验:禁止Webhook指向内网地址
3.3 版本管理机制:生产环境的稳定保障
工作流支持草稿-发布的版本管理策略:
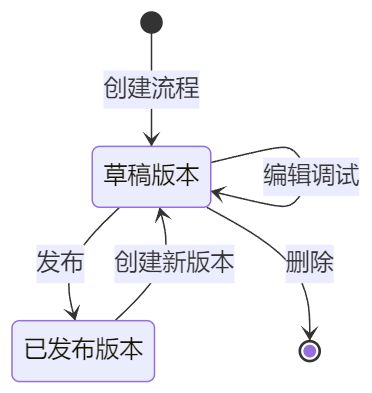
版本策略的价值:
- 开发环境:使用草稿版本进行开发和测试
- 生产环境:API调用和智能体调用只使用已发布版本
- 平滑升级:新版本发布前旧版本持续服务
- 快速回滚:发现问题可立即回滚到历史版本
四、实战场景:从理论到落地
4.1 场景一:智能客户分析报告
业务需求:每周自动生成客户行为分析报告
工作流设计:
开始 → 查询数据库(本周客户数据) → LLM分析(生成洞察) → 数据可视化 → 生成PDF → 邮件发送 → 结束
关键节点配置:
- 数据库节点:查询近7天客户交易记录
- LLM节点:分析消费趋势、识别高价值客户
- 条件节点:如果发现异常数据,触发告警分支
执行方式:定时任务触发(每周一早上8点)
4.2 场景二:智能简历筛选
业务需求:从海量简历中自动筛选匹配候选人
工作流设计:
开始(岗位JD) → 循环(遍历简历) → 文件解析(提取简历信息) → LLM评估(匹配度打分) → 条件判断 → 生成面试问题 → 结束
关键技术点:
- 循环节点:批量处理100+份简历
- 文件解析节点:支持PDF、Word、图片格式
- LLM节点:根据JD对简历进行结构化评估
- 变量聚合:收集所有高分候选人
执行方式:API调用(HR系统集成)
4.3 场景三:多渠道数据聚合
业务需求:整合多个数据源生成统一报表
工作流设计:
开始 → [并行] HTTP节点(Google Analytics) + HTTP节点(广告平台) + 数据库查询(内部数据) →
变量聚合 → LLM总结 → 生成Excel → 上传到云盘 → 结束
关键技术点:
- 并行执行:3个数据源同时查询,提升效率
- 变量聚合节点:合并不同格式的数据
- 异步模式:报表生成完成后Webhook通知
执行方式:异步API调用
五、工作流 vs 智能体:选型指南
很多人会困惑:什么时候用工作流?什么时候用智能体(Agent)?
对比分析

协同使用
工作流和智能体可以完美协同:
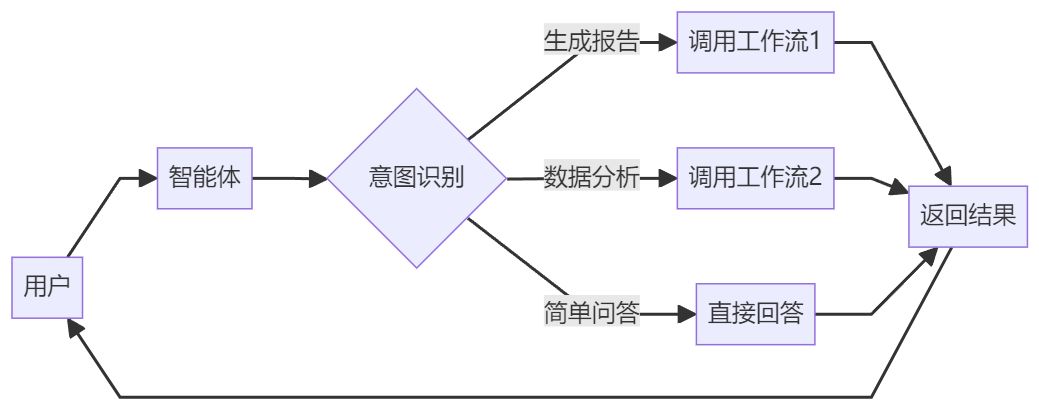
典型场景:
- 用户对智能体说:"帮我生成本月销售报告"
- 智能体识别意图,调用"销售报告生成"工作流
- 工作流执行:查数据 → 分析 → 生成图表 → 生成PDF
- 智能体返回:"报告已生成,请查收"
结语:让AI真正创造价值
GPTBots 工作流的本质,是让AI从"展示能力"变为"创造价值"。
我们相信,未来的企业AI应用不会是单一的聊天机器人,而是由无数个智能工作流编织而成的自动化网络。每一个工作流都是一个智能节点,它们互相协作、数据流动,最终构成企业的"智能神经系统"。
这就是工作流的使命:让AI不仅会说,更要会做;不仅能回答,更要能执行;不仅是工具,更是伙伴。
当业务人员也能设计AI流程、当市场人员也能调用大模型、当每个员工都能构建自己的AI助手时,企业的真正AI化才刚刚开始。
关于GPTBots
GPTBots 是企业级AI应用平台,提供智能体构建、工作流编排、知识库管理等全栈能力。我们的使命是让每个企业都能拥有自己的AI基础设施。