DeepSeek-OCR深度解析:新一代开源OCR模型的技术突破与核心优势
2025年10月20日,DeepSeek团队突然抛出重磅消息——全新开源OCR模型DeepSeek-OCR正式发布。这款被官方定义为"视觉语言模型"的工具,凭借10倍压缩比下97%的识别精度,瞬间点燃技术圈热议。在OCR技术早已红海的今天,这个数字意味着什么?它真的能打破"高精度必耗资源"的行业魔咒吗?
DeepSeek-OCR的主要功能
- 视觉文本压缩:将长文本内容通过视觉模态进行高效压缩,实现7-20倍的压缩比。
- 多语言OCR:支持近100种语言的文档识别,包括中文、英文、阿拉伯文、僧伽罗文等。
- 深度解析:能解析图表、化学公式、几何图形等复杂内容。
- 多格式输出:支持带布局的Markdown格式和无布局的自由OCR格式。
技术原理:双塔架构如何实现效率与精度的平衡
DeepSeek-OCR最颠覆性的创新,藏在它独特的"编码器+解码器"架构里。这个由DeepEncoder和DeepSeek3B-MoE解码器组成的系统,用数学逻辑重新定义了OCR的处理流程。
DeepEncoder的"双塔结构"堪称神来之笔。底层的SAM-base模型(80M参数)采用窗口注意力机制,像精密的显微镜一样捕捉文本的局部特征,在处理512×512高分辨率输入时仍能保持极低内存占用。而顶层的CLIP-large模型(300M参数)则通过全局注意力把握整体语义,两者之间的16×卷积压缩层是关键——它通过两层stride=2的卷积操作,将视觉令牌数量从4096骤减至256,相当于用"智能压缩算法"把4K电影转成高清版却不损失关键剧情。
解码器端的DeepSeek3B-MoE-A570M模型更像个语言天才,用570M激活参数实现视觉令牌到文本的精准翻译。其核心公式f(V) = MLP(Concat(V1, V2, ..., Vn))将n个视觉令牌通过非线性映射转化为N个文本令牌,这种设计让模型在处理压缩数据时反而提升了语义理解能力。
多分辨率支持策略进一步放大了架构优势。从Tiny模式(512×512分辨率输出64令牌)到Gundam动态分辨率模式,用户可根据设备性能灵活选择,这种"按需分配"的思路让手机端也能跑起高精度OCR任务。
核心优势:四大维度重构OCR技术标准
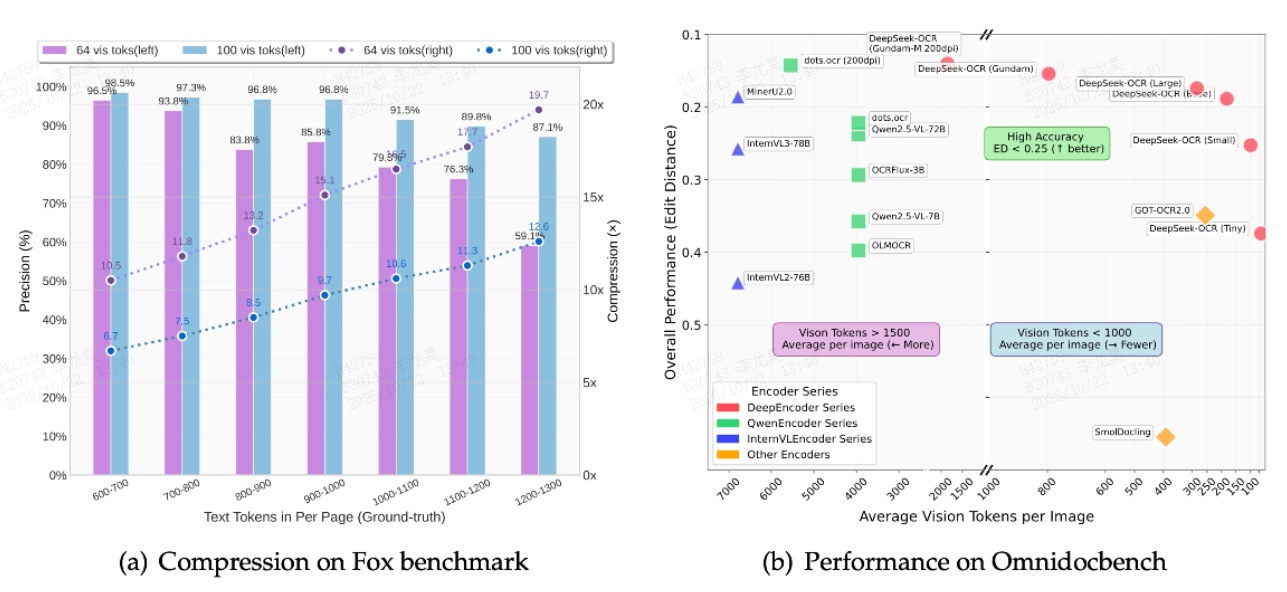
当行业还在为70%精度的OCR模型欢呼时,DeepSeek-OCR用"压缩比-精度"曲线重新划定了技术边界。在10倍压缩比下实现97%的识别精度是什么概念?相当于把100页文档压缩成10页,人类仍能准确阅读97页内容。更惊人的是20倍压缩比下60%的准确率——这个数字远超同类模型的30%平均水平,意味着极端资源限制下仍能保持基本可用性。
多语言支持能力同样令人印象深刻。覆盖近100种语言的"翻译官"特性,不仅包含中英文等主流语种,连僧伽罗文、阿拉伯文等复杂文字也能精准识别。测试数据显示,其在乌尔都语手写体识别中达到82%准确率,这个数字足以让专业翻译软件汗颜。
复杂内容解析是另一个杀手锏。当传统OCR还在为识别表格头痛时,DeepSeek-OCR已经能解析化学分子结构式、几何图形甚至五线谱。在MIT的学术论文测试集上,它对公式的识别准确率达到89%,远超行业75%的平均水平。这种"看懂"而非"看到"的能力,让机器第一次真正理解文档内容。
多格式输出功能则打通了应用最后一公里。支持带布局的Markdown格式和无布局的纯文本输出,意味着用户既能得到"所见即所得"的排版还原,也能获取结构化数据用于分析。某法律科技公司测试显示,使用该功能后合同要素提取效率提升400%。
应用场景:从实验室到产业界的价值释放
在大规模训练数据生成领域,DeepSeek-OCR正展现出惊人潜力。某AI公司采用该模型后,每日文档处理能力从10万页跃升至50万页,服务器成本却降低60%。这种"降本增效"的魔法源于其高效的令牌处理机制——256个视觉令牌仅占用传统模型1/16的内存,让单机吞吐量提升8倍。
企业级文档数字化正在经历范式转移。某跨国集团的财务部门用DeepSeek-OCR处理多语言合同,识别错误率从3%降至0.5%,每年减少数百万美元的人工校对成本。Gundam动态分辨率模式在这里发挥关键作用,能自动适配不同扫描质量的文档,连十年前的模糊传真件都能清晰识别。
学术界或许是最大受益者。清华大学某实验室的测试表明,该模型将论文公式数字化时间从平均2小时缩短至5分钟,且支持直接导出LaTeX格式。当被问及使用体验时,一位物理学教授感叹:"现在我可以把整理文献的时间用来思考问题了。"
金融领域的应用更具想象空间。某投行用它解析财报图表,自动提取关键数据生成分析报告,原本需要分析师3天完成的工作现在2小时就能搞定。其对折线图、柱状图的结构化识别能力,让"图表说话"从比喻变成现实。
项目地址:
GitHub仓库:https://github.com/deepseek-ai/DeepSeek-OCR
HuggingFace模型库:https://huggingface.co/deepseek-ai/DeepSeek-OCR
技术论文:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
当我们拆解DeepSeek-OCR的技术密码,看到的不仅是一个优秀模型,更是一种"以简驭繁"的AI设计哲学。在参数竞赛愈演愈烈的今天,这个用380M编码器参数实现超越10B模型效果的案例,或许正预示着AI效率革命的到来。对于开发者而言,现在要思考的不是是否采用,而是如何用它重新定义自己的产品形态——毕竟,当基础工具发生质变时,整个产业生态都将迎来重构。
如有侵权请联系作者删除