transformer架构解析{模型基本测试}(含代码)-9
目录
前言
模型基本测试
学习目标
cpoy任务介绍
实现模型copy任务的四步曲
实现模型训练和测试
构建数据集
实例化模型,优化器和损失函数
前言
经过前面的学习,我们已经学完了transformer模型的各个组成部分以及实现代码,最后也实现了模型的创建,接下来我们用一个任务来测试一下模型,看它是否能将规律学到。
模型基本测试
学习目标
了解transformer模型基本测试的copy任务
掌握实现模型copy任务的四步曲
cpoy任务介绍
任务描述:针对数字序列进行学习,学习的最终目标是使输出与输入的序列相同,如输入[1,5,8,5,6]输出也是[1,5,8,5,6]
任务意义:copy任务在模型基础测试中具有重要意义,因为copy操作对于模型来讲是一条明显的规律,因此模型能否在短时间内,小数据集中学会它,可以帮助我们断定模型的所有过程是否正常,是否已具备基本的学习能力。
实现模型copy任务的四步曲
实现模型训练和测试
def train_and_evaluate(model, train_loader, val_loader, criterion, optimizer, epochs, device):
#模型的训练
''' 输入参数:
model : 模型
train_loader:训练数据
vaL_loader: 测试数据
criterion: 计算损失
optimizer: 优化器
epochs: 训练轮数
device: 加载设备
'''
T_Loss = [] #训练的损失
V_Loss = [] #测试的损失
model.train() #模型训练
for epoch in range(epochs):
running_loss = 0.0
for step,(src, tgt, src_mask, tgt_mask) in enumerate(train_loader):
src, tgt, src_mask, tgt_mask = src.to(device), tgt.to(device), src_mask.to(device), tgt_mask.to(device)
#print("第{}轮,第{}批次".format(epoch+1,step+1))
optimizer.zero_grad()
output = model(src, tgt, src_mask, tgt_mask)
loss = criterion(output.contiguous().view(-1, output.size(-1)), tgt.contiguous().view(-1))
loss.backward()
optimizer.step()
running_loss += loss.item()
#print('loss:',loss.item())
T_Loss.append(running_loss)
print('----------------------------------------------------------------------')
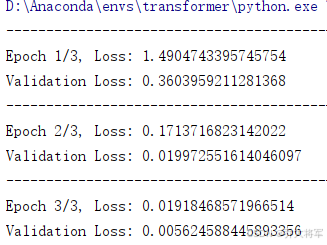
print(f'Epoch {epoch + 1}/{epochs}, Loss: {running_loss / len(train_loader)}')
# 评估模型
model.eval()
val_loss = 0.0
with torch.no_grad():
for step,(src, tgt, src_mask, tgt_mask) in enumerate(val_loader):
src, tgt, src_mask, tgt_mask = src.to(device), tgt.to(device), src_mask.to(device), tgt_mask.to(device)
output = model(src, tgt, src_mask, tgt_mask)
if step == 4:
print(src)
print(torch.argmax(output,dim=-1))
loss = criterion(output.contiguous().view(-1, output.size(-1)), tgt.contiguous().view(-1))
val_loss += loss.item()
V_Loss.append(val_loss)
print(f'Validation Loss: {val_loss / len(val_loader)}')
model.train()构建数据集
from torch.utils.data import DataLoader, TensorDataset
train_src = torch.randint(0, 11, (100, 10))
print(train_src)
print(train_src.shape)
train_src[:,0] = 1
train_tgt = train_src
train_src_mask = torch.ones((100, 1, 10))
print(train_src_mask.shape)
train_tgt_mask = torch.ones((100, 1, 10))
train_dataset = TensorDataset(train_src, train_tgt, train_src_mask, train_tgt_mask)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_src = torch.randint(0, 11, (50, 10))
val_tgt = torch.randint(0, 11, (50, 10))
val_src[:,0]=1
val_tgt = val_src
val_src_mask = torch.ones((50, 1, 10))
val_tgt_mask = torch.ones((50, 1, 10))
val_dataset = TensorDataset(val_src, val_tgt, val_src_mask, val_tgt_mask)
val_loader = DataLoader(val_dataset, batch_size=10, shuffle=False)实例化模型,优化器和损失函数
N=6
d_model=512
d_ff=2048
head=8
dropout=0.1
c = copy.deepcopy
source_vocab = 11
target_vocab = 11model = make_model(source_vocab,target_vocab,N)
#使用make_model获得模型
# 设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)