【完整源码+数据集+部署教程】【天线&空中农业】蜜蜂检测系统源码&数据集全套:改进yolo11-ASF
背景意义
随着全球生态环境的变化和人类活动的影响,蜜蜂作为重要的授粉昆虫,其数量和种群健康状况日益受到关注。蜜蜂不仅在农业生产中扮演着不可或缺的角色,还对维持生态系统的平衡具有重要意义。然而,蜜蜂种群的减少已成为全球范围内的一个严峻问题,影响了作物的产量和生物多样性。因此,开发有效的蜜蜂监测与保护系统显得尤为重要。近年来,计算机视觉技术的快速发展为蜜蜂的检测与监测提供了新的思路。
本研究旨在基于改进的YOLOv11模型,构建一个高效的蜜蜂检测系统。YOLO(You Only Look Once)系列模型因其实时性和高精度的特点,广泛应用于物体检测领域。通过对YOLOv11的改进,我们可以提高蜜蜂检测的准确性和速度,从而实现对蜜蜂种群动态的实时监测。该系统将利用一个包含909张图像的数据集,专注于蜜蜂的不同种类,包括工蜂、雄蜂、花粉蜂和蜂后。这一数据集的多样性为模型的训练提供了丰富的样本,有助于提升模型的泛化能力。
通过本研究,期望能够为蜜蜂的保护与管理提供技术支持,促进蜜蜂种群的监测与研究。同时,构建的蜜蜂检测系统也可以为农业生产提供科学依据,帮助农民更好地理解蜜蜂的行为和生态需求,进而采取相应的保护措施。总之,本研究不仅具有重要的学术价值,也对生态保护和可持续农业发展具有深远的现实意义。
图片效果
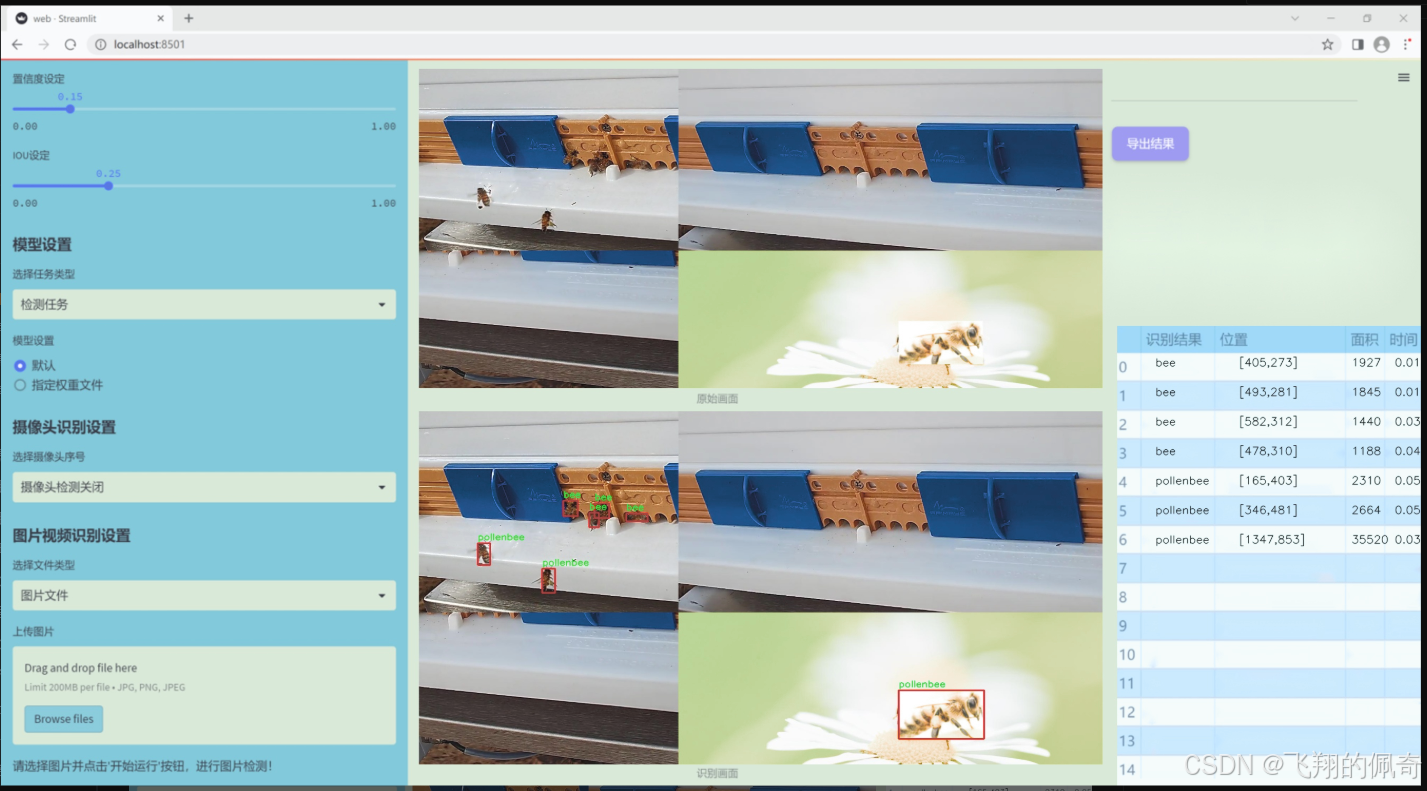
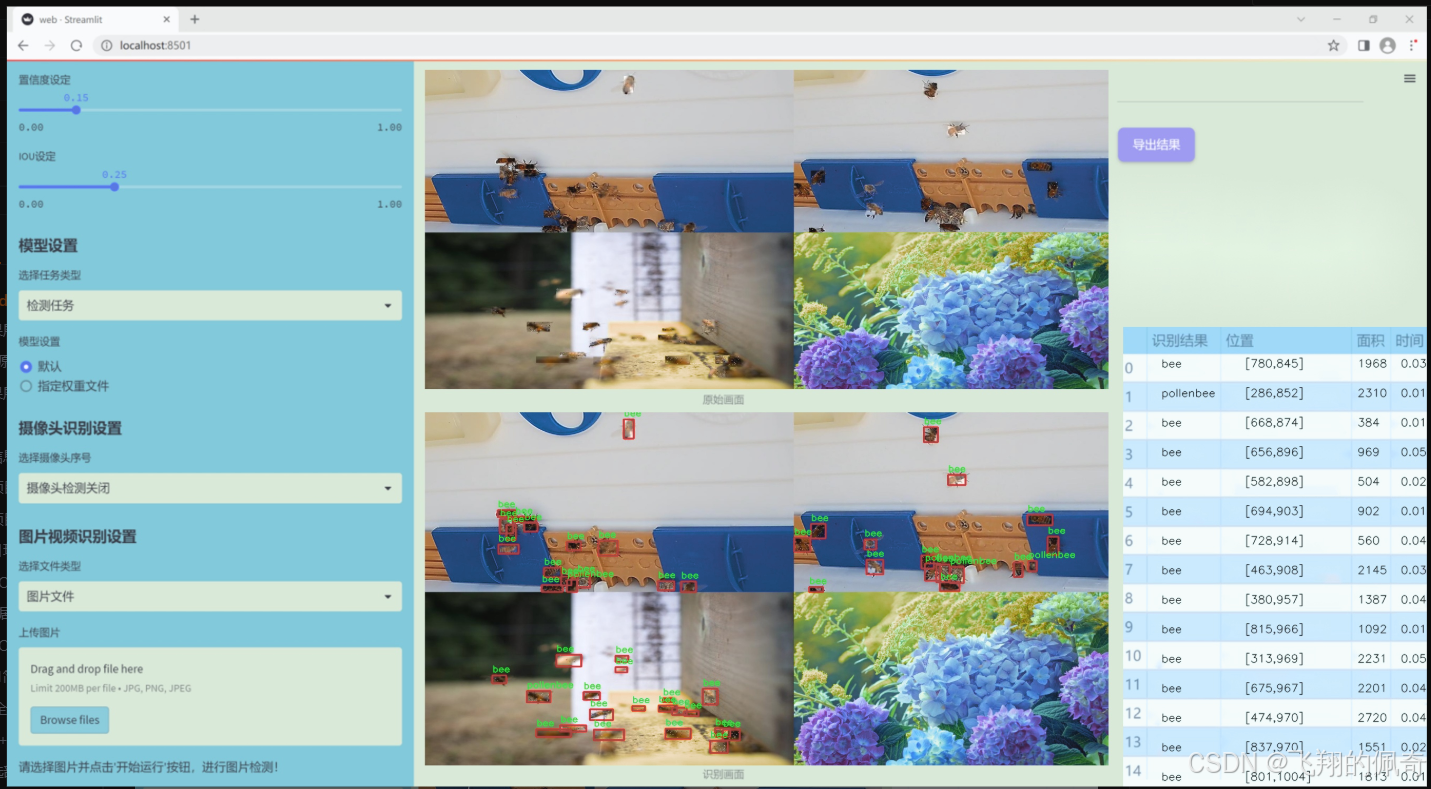
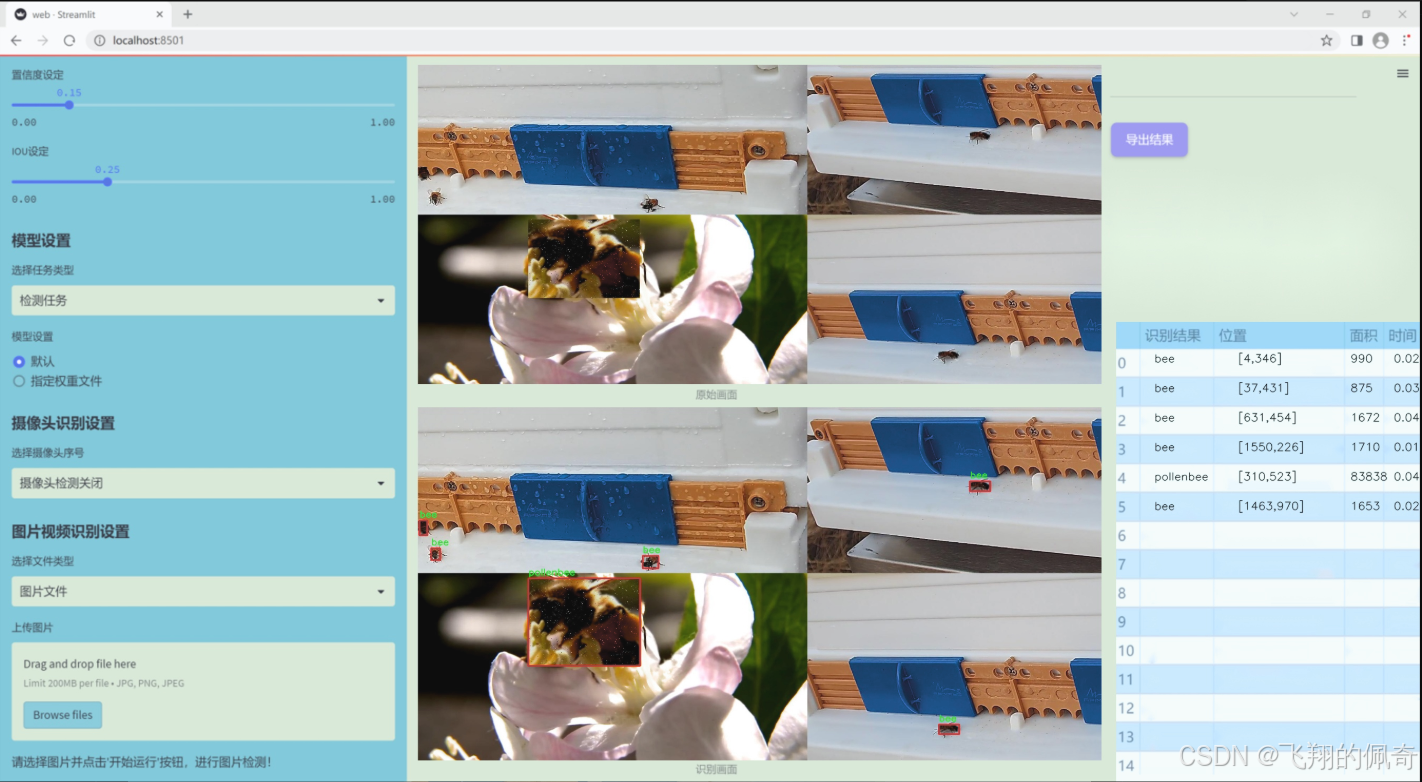
数据集信息
本项目旨在改进YOLOv11的蜜蜂检测系统,所使用的数据集名为“Honey Bee Detection Model”。该数据集专门针对蜜蜂及其相关种类进行标注,具有丰富的多样性和高质量的图像数据,适合用于深度学习模型的训练与评估。数据集中包含四个主要类别,分别为“bee”(工蜂)、“drone”(雄蜂)、“pollenbee”(采花蜂)和“queen”(蜂后)。这些类别的选择不仅反映了蜜蜂群体的基本构成,也为蜜蜂行为和生态研究提供了重要的基础。
数据集中的图像涵盖了不同环境、不同光照条件下的蜜蜂,确保了模型在实际应用中的鲁棒性。每个类别的样本数量经过精心设计,以保证模型在训练过程中能够有效学习到各类蜜蜂的特征。工蜂作为蜜蜂群体中最为常见的成员,其在花朵上采蜜的行为被广泛记录;雄蜂则在繁殖季节扮演着重要角色,而采花蜂则是蜜蜂生态系统中不可或缺的一部分,负责授粉和蜜源的获取。蜂后作为整个蜂群的核心,其独特的生理特征和行为模式也被充分捕捉并标注。
通过使用“Honey Bee Detection Model”数据集,研究人员能够训练出更为精准的蜜蜂检测系统,进而推动蜜蜂保护和生态监测的相关研究。该数据集不仅为蜜蜂的分类和识别提供了基础数据支持,还为未来的蜜蜂行为分析和生态研究奠定了坚实的基础。随着数据集的不断扩展和优化,期望能够在蜜蜂保护和农业可持续发展方面发挥更大的作用。





核心代码
以下是提取后的核心代码部分,并添加了详细的中文注释:
import torch
import torch.nn as nn
from typing import List
from torch import Tensor
class Partial_conv3(nn.Module):
“”“部分卷积层,用于在训练和推理中处理输入特征图。”“”
def __init__(self, dim, n_div, forward):super().__init__()self.dim_conv3 = dim // n_div # 计算部分卷积的通道数self.dim_untouched = dim - self.dim_conv3 # 计算未改变的通道数self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False) # 定义卷积层# 根据forward类型选择前向传播方法if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedErrordef forward_slicing(self, x: Tensor) -> Tensor:"""推理时的前向传播,仅对部分通道进行卷积操作。"""x = x.clone() # 克隆输入以保留原始输入x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :]) # 进行卷积return xdef forward_split_cat(self, x: Tensor) -> Tensor:"""训练和推理时的前向传播,分割和拼接特征图。"""x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1) # 分割特征图x1 = self.partial_conv3(x1) # 对分割的部分进行卷积x = torch.cat((x1, x2), 1) # 拼接特征图return x
class MLPBlock(nn.Module):
“”“多层感知机块,包含卷积、归一化和激活函数。”“”
def __init__(self, dim, n_div, mlp_ratio, drop_path, layer_scale_init_value, act_layer, norm_layer, pconv_fw_type):super().__init__()self.dim = dimself.mlp_ratio = mlp_ratioself.drop_path = nn.Identity() if drop_path <= 0 else nn.Dropout(drop_path) # 根据drop_path值选择是否使用dropoutself.n_div = n_divmlp_hidden_dim = int(dim * mlp_ratio) # 计算隐藏层维度# 定义MLP层mlp_layer: List[nn.Module] = [nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),norm_layer(mlp_hidden_dim),act_layer(),nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)]self.mlp = nn.Sequential(*mlp_layer) # 将MLP层组合成序列# 定义空间混合层self.spatial_mixing = Partial_conv3(dim, n_div, pconv_fw_type)def forward(self, x: Tensor) -> Tensor:"""前向传播,包含残差连接和dropout。"""shortcut = x # 保存输入以进行残差连接x = self.spatial_mixing(x) # 进行空间混合x = shortcut + self.drop_path(self.mlp(x)) # 添加残差连接return x
class FasterNet(nn.Module):
“”“FasterNet模型,包含多个阶段和嵌入层。”“”
def __init__(self, in_chans=3, num_classes=1000, embed_dim=96, depths=(1, 2, 8, 2), mlp_ratio=2., n_div=4,patch_size=4, patch_stride=4, patch_norm=True, drop_path_rate=0.1, norm_layer='BN', act_layer='RELU'):super().__init__()# 选择归一化层和激活函数norm_layer = nn.BatchNorm2d if norm_layer == 'BN' else NotImplementedErroract_layer = nn.ReLU(inplace=True) if act_layer == 'RELU' else NotImplementedErrorself.num_stages = len(depths) # 计算阶段数量self.embed_dim = embed_dim # 嵌入维度self.patch_norm = patch_norm # 是否使用归一化self.mlp_ratio = mlp_ratio # MLP比率self.depths = depths # 各阶段深度# 定义嵌入层self.patch_embed = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_stride, bias=False)# 构建各个阶段stages_list = []for i_stage in range(self.num_stages):stage = BasicStage(dim=int(embed_dim * 2 ** i_stage), n_div=n_div, depth=depths[i_stage],mlp_ratio=self.mlp_ratio, drop_path=0, norm_layer=norm_layer, act_layer=act_layer)stages_list.append(stage)self.stages = nn.Sequential(*stages_list) # 将所有阶段组合成序列def forward(self, x: Tensor) -> Tensor:"""前向传播,输出各阶段特征。"""x = self.patch_embed(x) # 进行嵌入outs = []for stage in self.stages:x = stage(x) # 通过每个阶段outs.append(x) # 保存输出return outs
用于加载模型的函数
def fasternet_t0(weights=None, cfg=‘path/to/config.yaml’):
“”“加载FasterNet T0模型。”“”
model = FasterNet() # 创建模型实例
if weights is not None:
pretrain_weight = torch.load(weights, map_location=‘cpu’) # 加载预训练权重
model.load_state_dict(pretrain_weight) # 更新模型权重
return model
代码说明:
Partial_conv3: 这个类实现了部分卷积的功能,允许在训练和推理时以不同的方式处理输入特征图。
MLPBlock: 这个类实现了多层感知机块,包含卷积、归一化和激活函数,并支持残差连接。
FasterNet: 这个类是整个网络的主干,负责定义网络的结构,包括嵌入层和多个阶段的堆叠。
fasternet_t0: 这个函数用于加载FasterNet T0模型,支持加载预训练权重。
通过这些核心部分的实现,FasterNet能够有效地处理输入数据并进行特征提取。
这个程序文件 fasternet.py 实现了一个名为 FasterNet 的深度学习模型,主要用于图像处理任务。代码中使用了 PyTorch 框架,并包含了多个模块和类来构建这个模型。
首先,文件导入了必要的库,包括 PyTorch、YAML 解析库以及一些用于构建神经网络的模块。接着,定义了一些辅助类,例如 Partial_conv3、MLPBlock、BasicStage、PatchEmbed 和 PatchMerging,这些类构成了 FasterNet 的基础组件。
Partial_conv3 类实现了一个部分卷积层,支持两种前向传播方式:切片(slicing)和拼接(split_cat)。在切片模式下,仅对输入的部分通道进行卷积,而在拼接模式下,则将输入分为两部分,分别进行处理后再拼接。
MLPBlock 类实现了一个多层感知机模块,包含两个卷积层和一个激活函数。它还支持残差连接和可选的层级缩放。BasicStage 类则由多个 MLPBlock 组成,形成模型的一个阶段。
PatchEmbed 类用于将输入图像分割成不重叠的补丁,并通过卷积层进行嵌入。PatchMerging 类则用于在模型的不同阶段合并补丁,减少特征图的尺寸。
FasterNet 类是整个模型的核心,它接收多个参数来配置模型的结构,包括输入通道数、类别数、嵌入维度、每个阶段的深度等。模型的构建过程中,首先进行补丁嵌入,然后依次通过多个阶段的处理,并在每个阶段后添加归一化层。
文件中还定义了一些函数,如 update_weight 用于更新模型权重,fasternet_t0、fasternet_t1、fasternet_t2 等函数用于加载不同配置的 FasterNet 模型。这些函数会读取 YAML 配置文件并根据配置构建模型,同时支持加载预训练权重。
最后,在 main 块中,示例代码展示了如何使用 fasternet_t0 函数加载模型并进行推理,打印出模型的输出特征图的尺寸。
总体而言,这个文件实现了一个灵活且可扩展的深度学习模型,适用于各种图像处理任务,并提供了多种配置选项以满足不同需求。
10.3 revcol.py
以下是经过简化和注释的核心代码部分,主要包括了反向传播和前向传播的关键功能:
import torch
import torch.nn as nn
class ReverseFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, run_functions, alpha, *args):
# 提取前向传播所需的函数和参数
l0, l1, l2, l3 = run_functions
alpha0, alpha1, alpha2, alpha3 = alpha
ctx.run_functions = run_functions
ctx.alpha = alpha
# 保存当前的随机数生成状态ctx.cpu_states_0, ctx.gpu_states_0 = torch.get_rng_state(), get_gpu_states(get_gpu_device(*args))# 执行前向传播x, c0, c1, c2, c3 = argsc0 = l0(x, c1) + c0 * alpha0c1 = l1(c0, c2) + c1 * alpha1c2 = l2(c1, c3) + c2 * alpha2c3 = l3(c2, None) + c3 * alpha3# 保存中间结果以便后向传播使用ctx.save_for_backward(x, c0, c1, c2, c3)return x, c0, c1, c2, c3@staticmethod
def backward(ctx, *grad_outputs):# 提取保存的中间结果x, c0, c1, c2, c3 = ctx.saved_tensorsl0, l1, l2, l3 = ctx.run_functionsalpha0, alpha1, alpha2, alpha3 = ctx.alpha# 计算梯度gx_right, g0_right, g1_right, g2_right, g3_right = grad_outputs# 反向传播计算g3_up = g3_rightg3_left = g3_up * alpha3 # shortcutoup3 = l3(c2, None)torch.autograd.backward(oup3, g3_up, retain_graph=True)# 反向传播中间结果的计算c3_left = (1 / alpha3) * (c3 - oup3) # feature reverseg2_up = g2_right + c2.gradg2_left = g2_up * alpha2 # shortcutc2_left = (1 / alpha2) * (c2 - l2(c1, c3_left)) # feature reverseg1_up = g1_right + c1.gradg1_left = g1_up * alpha1 # shortcut# 继续反向传播g0_up = g0_right + c0.gradg0_left = g0_up * alpha0 # shortcut# 返回最终的梯度return None, None, gx_up, g0_left, g1_left, g2_left, g3_left
class SubNet(nn.Module):
def init(self, channels, layers, kernel, first_col, save_memory) -> None:
super().init()
# 初始化网络层和参数
self.alpha0 = nn.Parameter(torch.ones((1, channels[0], 1, 1)), requires_grad=True)
self.alpha1 = nn.Parameter(torch.ones((1, channels[1], 1, 1)), requires_grad=True)
self.alpha2 = nn.Parameter(torch.ones((1, channels[2], 1, 1)), requires_grad=True)
self.alpha3 = nn.Parameter(torch.ones((1, channels[3], 1, 1)), requires_grad=True)
# 定义各层self.level0 = Level(0, channels, layers, kernel, first_col)self.level1 = Level(1, channels, layers, kernel, first_col)self.level2 = Level(2, channels, layers, kernel, first_col)self.level3 = Level(3, channels, layers, kernel, first_col)def forward(self, *args):# 根据内存保存策略选择前向传播方式if self.save_memory:return self._forward_reverse(*args)else:return self._forward_nonreverse(*args)
class RevCol(nn.Module):
def init(self, kernel=‘C2f’, channels=[32, 64, 96, 128], layers=[2, 3, 6, 3], num_subnet=5, save_memory=True) -> None:
super().init()
self.num_subnet = num_subnet
self.channels = channels
self.layers = layers
# 定义网络的输入层self.stem = Conv(3, channels[0], k=4, s=4, p=0)# 添加子网络for i in range(num_subnet):first_col = (i == 0)self.add_module(f'subnet{str(i)}', SubNet(channels, layers, kernel, first_col, save_memory=save_memory))def forward(self, x):# 执行前向传播c0, c1, c2, c3 = 0, 0, 0, 0x = self.stem(x) for i in range(self.num_subnet):c0, c1, c2, c3 = getattr(self, f'subnet{str(i)}')(x, c0, c1, c2, c3) return [c0, c1, c2, c3]
代码说明:
ReverseFunction: 这是一个自定义的反向传播函数,负责处理前向和反向传播的逻辑。forward方法执行前向计算并保存中间结果,backward方法计算梯度。
SubNet: 这是一个子网络模块,包含多个层和可学习的参数(alpha)。根据内存策略选择不同的前向传播方式。
RevCol: 这是整个网络的主体,包含多个子网络,并定义了输入层。前向传播时依次调用每个子网络。
以上代码展示了如何在深度学习模型中实现反向传播和前向传播的核心逻辑,适用于需要高效内存管理的场景。
这个程序文件 revcol.py 是一个基于 PyTorch 的深度学习模型实现,主要用于构建一种反向传播优化的网络结构。文件中定义了多个类和函数,主要功能包括获取和设置 GPU 状态、实现反向传播的自定义函数、以及构建网络的不同层级和模块。
首先,文件导入了必要的 PyTorch 库和自定义模块,包括卷积层和不同的网络块。接着,定义了一些辅助函数,比如 get_gpu_states 用于获取当前 GPU 的随机数生成状态,get_gpu_device 用于获取输入张量所在的 GPU 设备,set_device_states 用于设置 GPU 的随机数生成状态,detach_and_grad 用于处理输入的张量并使其可求导,get_cpu_and_gpu_states 则是获取 CPU 和 GPU 的状态。
核心部分是 ReverseFunction 类,它继承自 torch.autograd.Function,实现了自定义的前向和反向传播逻辑。在前向传播中,它接收多个函数和参数,通过一系列的计算得到输出,并保存中间结果以供反向传播使用。在反向传播中,使用保存的中间结果和输入的梯度信息,逐层计算梯度并更新状态。
接下来是 Fusion 类和 Level 类,前者负责融合不同层的特征,后者则构建网络的不同层级,使用卷积操作和上采样操作来处理输入数据。SubNet 类是一个子网络的实现,包含多个层级,并在前向传播中根据设定的条件选择是否使用反向传播。
最后,RevCol 类是整个模型的主类,负责初始化网络结构,包括输入层、多个子网络和最终的输出。它在前向传播中依次调用每个子网络,并返回各层的输出。
整体来看,这个文件实现了一个复杂的神经网络结构,结合了反向传播优化技术,旨在提高模型的训练效率和性能。通过合理的模块化设计,代码易于扩展和维护,适合用于各种深度学习任务。
10.4 afpn.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from …modules.conv import Conv # 导入自定义卷积模块
class BasicBlock(nn.Module):
“”“基本块,包含两个卷积层和残差连接”“”
def init(self, filter_in, filter_out):
super(BasicBlock, self).init()
# 第一个卷积层,使用3x3卷积
self.conv1 = Conv(filter_in, filter_out, 3)
# 第二个卷积层,使用3x3卷积,不使用激活函数
self.conv2 = Conv(filter_out, filter_out, 3, act=False)
def forward(self, x):residual = x # 保存输入以便后续的残差连接out = self.conv1(x) # 通过第一个卷积层out = self.conv2(out) # 通过第二个卷积层out += residual # 添加残差return self.conv1.act(out) # 通过激活函数返回结果
class Upsample(nn.Module):
“”“上采样模块”“”
def init(self, in_channels, out_channels, scale_factor=2):
super(Upsample, self).init()
# 定义上采样的序列,包括卷积和双线性插值上采样
self.upsample = nn.Sequential(
Conv(in_channels, out_channels, 1),
nn.Upsample(scale_factor=scale_factor, mode=‘bilinear’)
)
def forward(self, x):return self.upsample(x) # 直接返回上采样结果
class Downsample_x2(nn.Module):
“”“2倍下采样模块”“”
def init(self, in_channels, out_channels):
super(Downsample_x2, self).init()
# 定义2倍下采样的卷积
self.downsample = Conv(in_channels, out_channels, 2, 2, 0)
def forward(self, x):return self.downsample(x) # 直接返回下采样结果
class ASFF_2(nn.Module):
“”“自适应特征融合模块,处理两个输入”“”
def init(self, inter_dim=512):
super(ASFF_2, self).init()
self.inter_dim = inter_dim
compress_c = 8 # 压缩通道数
# 定义权重卷积层self.weight_level_1 = Conv(self.inter_dim, compress_c, 1)self.weight_level_2 = Conv(self.inter_dim, compress_c, 1)self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1, stride=1, padding=0)self.conv = Conv(self.inter_dim, self.inter_dim, 3) # 最后的卷积层def forward(self, input1, input2):# 计算每个输入的权重level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)# 将权重拼接并计算最终权重levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1) # 使用softmax归一化权重# 融合输入特征fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \input2 * levels_weight[:, 1:2, :, :]out = self.conv(fused_out_reduced) # 通过卷积层return out # 返回融合后的结果
class BlockBody_P345(nn.Module):
“”“处理3个尺度的特征块”“”
def init(self, channels=[64, 128, 256, 512]):
super(BlockBody_P345, self).init()
# 定义不同尺度的卷积和下采样、上采样模块self.blocks_scalezero1 = nn.Sequential(Conv(channels[0], channels[0], 1))self.blocks_scaleone1 = nn.Sequential(Conv(channels[1], channels[1], 1))self.blocks_scaletwo1 = nn.Sequential(Conv(channels[2], channels[2], 1))self.downsample_scalezero1_2 = Downsample_x2(channels[0], channels[1])self.upsample_scaleone1_2 = Upsample(channels[1], channels[0], scale_factor=2)self.asff_scalezero1 = ASFF_2(inter_dim=channels[0])self.asff_scaleone1 = ASFF_2(inter_dim=channels[1])# 定义更多的卷积块和下采样、上采样模块self.blocks_scalezero2 = nn.Sequential(BasicBlock(channels[0], channels[0]), ...)self.blocks_scaleone2 = nn.Sequential(BasicBlock(channels[1], channels[1]), ...)# 省略的部分...def forward(self, x):x0, x1, x2 = x # 输入的三个尺度特征# 通过不同的块处理特征x0 = self.blocks_scalezero1(x0)x1 = self.blocks_scaleone1(x1)x2 = self.blocks_scaletwo1(x2)# 自适应特征融合scalezero = self.asff_scalezero1(x0, self.upsample_scaleone1_2(x1))scaleone = self.asff_scaleone1(self.downsample_scalezero1_2(x0), x1)# 继续处理和融合特征x0 = self.blocks_scalezero2(scalezero)x1 = self.blocks_scaleone2(scaleone)# 省略的部分...return x0, x1, x2 # 返回处理后的特征
class AFPN_P345(nn.Module):
“”“自适应特征金字塔网络,处理3个输入通道”“”
def init(self, in_channels=[256, 512, 1024], out_channels=256, factor=4):
super(AFPN_P345, self).init()
# 定义输入通道的卷积层self.conv0 = Conv(in_channels[0], in_channels[0] // factor, 1)self.conv1 = Conv(in_channels[1], in_channels[1] // factor, 1)self.conv2 = Conv(in_channels[2], in_channels[2] // factor, 1)# 定义特征块self.body = nn.Sequential(BlockBody_P345([in_channels[0] // factor, in_channels[1] // factor, in_channels[2] // factor]))# 定义输出通道的卷积层self.conv00 = Conv(in_channels[0] // factor, out_channels, 1)self.conv11 = Conv(in_channels[1] // factor, out_channels, 1)self.conv22 = Conv(in_channels[2] // factor, out_channels, 1)def forward(self, x):x0, x1, x2 = x # 输入的三个特征图# 通过卷积层处理输入特征x0 = self.conv0(x0)x1 = self.conv1(x1)x2 = self.conv2(x2)# 通过特征块处理特征out0, out1, out2 = self.body([x0, x1, x2])# 通过输出卷积层处理特征out0 = self.conv00(out0)out1 = self.conv11(out1)out2 = self.conv22(out2)return [out0, out1, out2] # 返回处理后的特征
代码说明:
BasicBlock: 定义了一个基本的卷积块,包含两个卷积层和残差连接。
Upsample/Downsample: 定义了上采样和下采样模块,使用卷积和插值方法调整特征图的尺寸。
ASFF: 自适应特征融合模块,能够根据输入特征的权重进行加权融合。
BlockBody_P345: 处理3个尺度特征的模块,包含多个卷积块和自适应特征融合。
AFPN_P345: 自适应特征金字塔网络,整合多个输入通道的特征,输出融合后的特征图。
以上是核心部分的代码和详细注释,帮助理解各个模块的功能和作用。
这个程序文件 afpn.py 实现了一个自适应特征金字塔网络(AFPN),用于计算机视觉任务中的特征提取和融合。该网络结构包含多个模块,主要包括卷积层、上采样和下采样操作,以及自适应特征融合(ASFF)模块。以下是对代码的详细说明。
首先,程序导入了一些必要的库,包括 torch 和 torch.nn,以及自定义的卷积和块模块。接着,定义了几个基本的神经网络模块,例如 BasicBlock、Upsample、Downsample_x2、Downsample_x4 和 Downsample_x8。这些模块分别用于构建网络的基本单元,进行特征的上采样和下采样。
BasicBlock 类实现了一个基本的残差块,包含两个卷积层,并将输入与卷积输出相加,以便保留输入特征。Upsample 和 Downsample 类则用于调整特征图的尺寸,分别进行上采样和下采样操作。
接下来,定义了多个自适应特征融合模块(ASFF),如 ASFF_2、ASFF_3 和 ASFF_4。这些模块通过计算输入特征的权重来融合不同尺度的特征图,使用了 softmax 函数来确保权重的归一化,从而使得不同特征图的贡献可以动态调整。
BlockBody_P345 和 BlockBody_P2345 类是网络的主体结构,分别处理三层和四层特征图的融合与处理。它们通过组合多个卷积层和自适应特征融合模块来实现特征的提取和融合。在 forward 方法中,输入特征图经过各个处理模块后,输出经过处理的特征图。
AFPN_P345 和 AFPN_P2345 类是完整的特征金字塔网络结构,分别对应三层和四层输入特征图。它们首先通过卷积层调整输入特征图的通道数,然后通过主体结构进行特征处理,最后再通过卷积层输出最终的特征图。
此外,BlockBody_P345_Custom 和 BlockBody_P2345_Custom 类允许用户自定义块类型,以便在构建网络时使用不同的基本块。这样可以提高网络的灵活性和适应性。
最后,整个网络的初始化过程中,使用了 Xavier 初始化方法来初始化卷积层的权重,以确保训练的稳定性和收敛速度。
总体来说,这个程序实现了一个灵活且高效的特征金字塔网络,适用于多种计算机视觉任务,特别是在处理多尺度特征时表现出色。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻