【论文精读】GenTron:基于 Transformer 的扩散模型革新图像与视频生成
标题:GenTron: Diffusion Transformers for Image and Video Generation
作者:Shoufa Chen, Mengmeng Xu, Jiawei Ren, Yuren Cong, Sen He, Yanping Xie, Animesh Sinha, Ping Luo, Tao Xiang, Juan-Manuel Perez-Rua
单位:1.The University of Hong Kong(香港大学);2.Meta
发表:CVPR 2024,且为 Open Access 版本,由 Computer Vision Foundation 提供
论文链接:https://arxiv.org/abs/2312.04557
项目链接:https://www.shoufachen.com/gentron_website/
代码链接:https://github.com/lavinal712/GenTron
关键词:Diffusion Models(扩散模型)、Transformers(Transformer 架构)、Text-to-Image Generation(文本到图像生成)、Text-to-Video Generation(文本到视频生成)、Motion-Free Guidance(无运动引导)、T2I-CompBench(文本到图像组合生成基准)
本文是对CVPR 2024 论文《GenTron: Diffusion Transformers for Image and Video Generation》的深度解读。该研究由香港大学与 Meta 团队合作完成,首次系统性将 Transformer 架构深度融入扩散模型,同时覆盖文本到图像(T2I)与文本到视频(T2V)生成场景,填补了视觉生成领域 Transformer 应用的空白,且在多项指标上超越主流模型 SDXL。
一、研究背景与动机:为何需要 GenTron?
1.1 扩散模型的架构 “割裂” 现状
扩散模型已成为内容生成领域的核心技术,在图像生成(如 Stable Diffusion)、视频生成(如 Imagen Video)、图像编辑等任务中表现突出,但长期依赖CNN-based U-Net作为核心骨干网络。与之形成鲜明对比的是,自然语言处理(NLP,如 GPT 系列)和计算机视觉感知(如目标检测、图像分类)领域,Transformer 架构凭借灵活的注意力机制、强大的全局信息捕捉能力与优异可扩展性,早已成为绝对主流。
这种架构选择的 “割裂”,导致视觉生成领域无法充分利用 Transformer 的技术优势,也使得跨领域(NLP - 视觉生成)的模型迁移与技术复用受限。因此,探索 Transformer 在扩散模型中的深度应用,成为连接视觉生成与其他 AI 领域的关键突破口。
1.2 现有 Transformer 扩散模型的两大局限
此前最具代表性的 Transformer 扩散模型是 DiT(Diffusion Transformers),但它存在两大核心局限,无法满足开放域文本驱动生成需求:
- 条件约束单一:仅支持预定义类别(如 ImageNet 的 1000 类)的 one-hot 编码输入,无法处理开放域、自由文本描述的生成任务(如 “夕阳下在海上冲浪的熊猫” 这类复杂文本);
- 模型规模不足:最大的 DiT-XL 模型仅 6.75 亿参数,远小于 NLP 领域(如 PaLM 达 5400 亿参数)、视觉感知领域(如 ViT 达 220 亿参数)的 Transformer 模型,更落后于同期 U-Net 架构的扩散模型(如 SDXL 达 26 亿参数),难以通过规模提升生成质量。
1.3 研究目标:GenTron 的三大核心任务
针对上述问题,GenTron 设定三大研究目标:
- 将 DiT 从 “类别条件” 扩展到 “文本条件”,探索高效的文本嵌入与 Transformer 融合机制;
- 规模化扩展模型参数(从约 9 亿提升至 30 亿 +),验证 Transformer 扩散模型的 “规模 - 性能” 正相关特性;
- 延伸至文本到视频(T2V)生成,提出创新策略解决 T2V 领域 “帧质量低”“时空不一致” 的核心痛点,并通过实验验证模型优越性。

二、核心方法:GenTron 的技术架构详解
GenTron 的技术方案围绕 “T2I 基础架构→模型规模化→T2V 扩展” 三步展开,每个环节均针对具体问题提出了创新设计,以下逐一拆解。
2.1 基础铺垫:扩散模型与 Latent Diffusion 原理
GenTron 基于Latent Diffusion Model(LDM) 框架构建,核心是通过 “latent 空间压缩” 降低计算成本,其流程与数学原理如下:
- Latent 空间压缩:利用预训练变分自编码器(VAE)将高分辨率像素图像(如 512×512)压缩到低维 latent 空间(如 32×32×4),减少扩散过程的计算量;
- 扩散过程:
- 前向过程:向 latent 向量逐步添加高斯噪声,经过 T 步后,latent 向量变为纯噪声,数学表达式为:
,其中
为噪声调度参数,控制每步噪声添加强度;
- 反向过程:训练 denoising 网络(GenTron 中为 Transformer)从噪声中逐步恢复与文本匹配的 latent 向量,恢复公式为:
,其中
,
,
为 denoising 网络,
为随机高斯噪声;
- 前向过程:向 latent 向量逐步添加高斯噪声,经过 T 步后,latent 向量变为纯噪声,数学表达式为:
- 解码生成:将恢复的 latent 向量通过 VAE 解码器转换为像素级图像。
2.2 T2I GenTron:文本条件注入与模型优化
GenTron-T2I 以 DiT-XL/2 为基础,核心改进是文本条件注入机制与模型规模化设计,解决 DiT 无法处理自由文本的问题。
2.2.1 文本条件注入:两大关键组件的选择与对比
文本条件注入需解决两个核心问题:“用什么模型编码文本”(文本编码器)、“如何将文本嵌入融入 Transformer”(嵌入整合方式)。GenTron 通过大量实验,确定了最优技术组合。
(1)文本编码器:多模态模型 vs 大语言模型
研究对比了三类文本编码器,并验证其对生成性能的影响(表2):
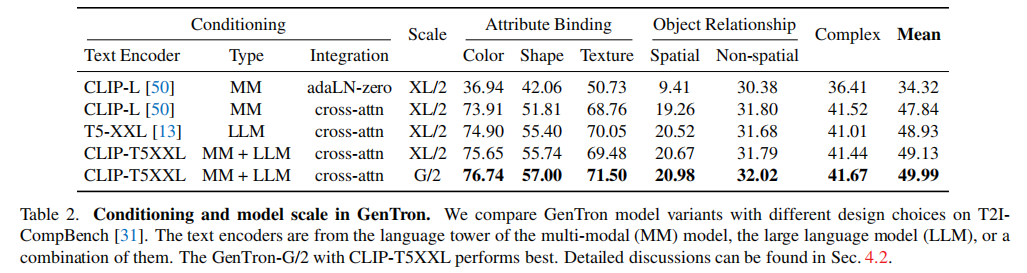
- 多模态文本塔(MM):如 CLIP-L,擅长捕捉文本与图像的跨模态对齐关系,但对复杂文本的语法、属性理解能力较弱;
- 纯大语言模型(LLM):如 Flan-T5-XXL,擅长理解文本的逻辑关系、属性描述(如 “红色的车”“圆形的桌子”),但缺乏跨模态对齐能力;
- 组合方案(CLIP-T5XXL):同时融合 CLIP 与 T5 的文本嵌入,兼顾跨模态对齐与复杂文本理解能力。
实验结论:组合方案(CLIP-T5XXL)在 T2I-CompBench 所有指标上表现最优,平均得分达 49.13(XL/2 规模),显著高于单一编码器方案,成为 GenTron 的默认文本编码器。
(2)嵌入整合方式:adaLN-Zero vs 交叉注意力
GenTron 对比了两种将文本嵌入融入 Transformer 的机制(图2),并分析其适用场景:
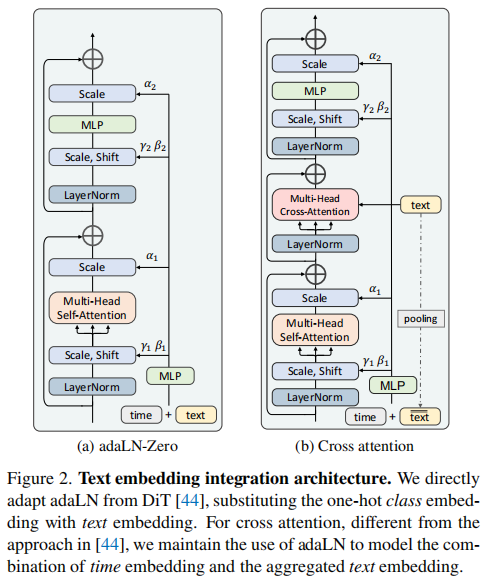
- adaLN-Zero(自适应层归一化):源自 DiT,将文本嵌入转换为层归一化(LN)的缩放(\(\gamma\))和偏移(\(\beta\))参数,对图像特征进行全局调制。优点是计算高效,但空间粒度粗,无法实现文本与图像局部区域的精准对齐(如 “红色的车” 中 “红色” 与车的对应);
- 交叉注意力(Cross-Attention):将图像特征作为查询(Query),文本嵌入作为键(Key)和值(Value),通过注意力权重实现文本与图像局部区域的精准匹配。同时,GenTron 保留 adaLN 处理 “时间嵌入”(扩散步长信息),避免时间信息与文本信息的干扰。
关键验证:在自由文本条件下,交叉注意力显著优于 adaLN-Zero。如下图(图4)所示,生成 “夕阳下在海上冲浪的熊猫” 时,adaLN-Zero 无法准确渲染 “冲浪板”“夕阳” 等元素,而交叉注意力能精准匹配文本描述;定量上,如前面的表2中第一行和第二行对比数据所示,交叉注意力在 T2I-CompBench 的平均得分比 adaLN-Zero 高 13.5 分(47.84 vs 34.32)。

2.2.2 模型规模化:GenTron-G/2 的 30 亿参数设计
为验证 Transformer 扩散模型的 “规模 - 性能” 正相关特性,GenTron 遵循 ViT 的规模化策略,从三个维度扩展模型(表 1):
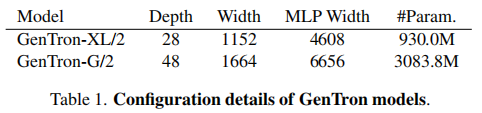
- 深度(Depth):Transformer 块数量从 28(XL/2)增加到 48(G/2);
- 宽度(Width):patch 嵌入维度从 1152 增加到 1664;
- MLP 宽度(MLP Width):Transformer 块中 MLP 的隐藏层维度从 4608 增加到 6656。
最终,GenTron-G/2 的参数规模达到 30.8 亿,成为当时最大的 Transformer 扩散模型。规模化带来的性能提升体现在两方面(图 5):
- 细节渲染:生成 “读报纸的猫” 时,G/2 能清晰渲染报纸文字、猫的毛发纹理,而 XL/2 细节模糊;
- 布局合理性:G/2 能正确处理 “猫” 与 “报纸” 的空间关系(猫爪搭在报纸上),XL/2 则出现布局混乱。
定量上(表 2中最后一行数据),G/2 在 T2I-CompBench 的平均得分达 49.99,比 XL/2(49.13)高 0.86 分,验证了规模对生成质量的正向影响。
2.3 T2V GenTron:时序建模与 Motion-Free Guidance
GenTron-T2V 在 T2I 基础上扩展,核心挑战是 “保证帧内视觉质量的同时,实现帧间时空一致性”。现有 T2V 模型普遍存在 “帧质量低于 T2I” 的问题,GenTron 通过 “轻量化时序建模” 与 “Motion-Free Guidance(MFG)” 两大创新解决这一痛点。
2.3.1 T2V 架构:仅添加时序自注意力的轻量化设计
GenTron 避免传统 T2V 模型添加 3D 卷积和复杂时序块的高成本做法,仅在 T2I 的每个 Transformer 块中插入时序自注意力(TempSelfAttn)层(图 3),实现高效时序建模。
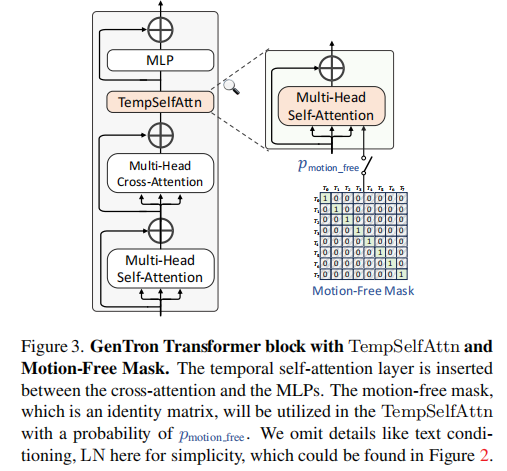
具体流程为:
- 维度重排:将视频的 “帧维度(
)” 与 “批次维度(
)” 重组,从
变为
,
为每帧的 patch 数量,
为嵌入维度。(使用 einops 库中的 rearrange 函数);
- 时序注意力计算:在重组后的维度上计算自注意力,捕捉帧间运动信息(如 “行走的狗” 的肢体动作变化);
- 维度恢复:将注意力输出重组回原维度,接入后续 MLP 层。
这种设计的优势在于:
- 轻量化:仅增加少量计算量,避免 3D 卷积的高显存占用;
- 可开关性:通过掩码可灵活启用 / 禁用时序建模,为 MFG 奠定基础;
- 初始化策略:新添加的 TempSelfAttn 层输出投影权重初始化为 0,确保微调初期与 T2I 模型性能一致,避免帧质量骤降。
2.3.2 Motion-Free Guidance(MFG):平衡帧质量与时空一致性
现有 T2V 模型帧质量低的核心原因有二:
- 数据质量差距:视频数据集(如 WebVid-10M 仅 1070 万视频文本对)的规模和质量远低于图像数据集(如 LAION-5B 达 20 亿图像文本对),且视频帧常存在运动模糊、水印等问题;
- 微调目标冲突:T2V 微调时过度关注时序一致性,导致空间质量(如纹理、颜色)退化。
GenTron 提出MFG 策略,结合 “联合图像 - 视频训练”,从数据与训练目标两方面解决上述问题:
(1)MFG 核心思想
将时序运动视为 “可调节的条件信号”,类比文本条件的 “无分类器引导(Classifier-Free Guidance)”,通过随机禁用时序建模,迫使模型保留 T2I 的空间质量。
(2)训练阶段:随机禁用时序建模
训练时,以概率将 TempSelfAttn 的注意力掩码设为单位矩阵(仅关注当前帧,禁用帧间注意力),此时:
- 若禁用时序建模:加载图像 - 文本对,将单张图像重复 T-1 次生成 “伪视频”,用 T2I 的目标优化空间质量;
- 若启用时序建模:加载真实视频剪辑(8 帧,4 FPS),优化时序一致性。
(3)推理阶段:可控运动强度
推理时,通过引导权重调节运动强度,公式如下:
,其中,
为文本条件,
为运动条件;
(默认 7.5)控制文本对齐强度,
(1.0-1.3)控制运动强度,取值越大,视频运动越剧烈。
效果验证(图 8):启用 MFG 后,生成 “夕阳下在海上冲浪的狮子” 时,狮子轮廓更清晰,冲浪板与海水细节更丰富,且帧间运动平滑,避免了无 MFG 时的模糊和变形。

2.4 训练细节:多阶段策略与优化技巧
GenTron 采用多阶段训练策略,结合显存优化技术,确保模型收敛与性能:
- T2I 训练:分低分辨率(256×256,2048 batch size,50 万步)和高分辨率(512×512,784 batch size,30 万步)两阶段,使用 AdamW 优化器(学习率 1e-4);
- T2V 训练:基于预训练 T2I 模型微调,使用 3400 万视频数据集(短边 512,24 FPS),批次大小 128(每批次含 8 帧视频剪辑);
- 显存优化:GenTron-G/2 采用完全分片数据并行(FSDP)和激活检查点(AC),降低 GPU 显存占用。
三、实验验证:GenTron 的性能优势
GenTron 从定量指标(T2I-CompBench、FID、CLIP-Score)、人类评估(视觉质量、文本对齐)、视频生成质量三方面验证性能,对比对象包括 SDXL、DALL・E 2、PixArt-α 等主流模型。
3.1 图像生成性能(T2I)
3.1.1 T2I-CompBench:compositional 生成能力领先
T2I-CompBench 是评估文本 - 图像 “组合生成能力” 的权威基准,涵盖属性绑定(颜色、形状、纹理)、物体关系(空间、非空间)、复杂组合三大维度。
关键结果(表 3):
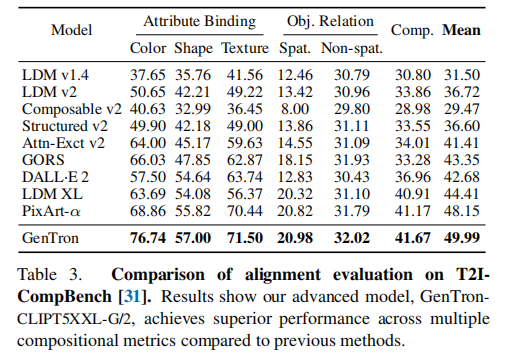
- GenTron 在所有维度排名第一,平均得分 49.99,远超 SDXL(44.41)和 PixArt-α(48.15);
- 优势最显著的是颜色绑定:GenTron 得 76.74,比 PixArt-α 高 7.88 分,说明其能精准匹配文本中的颜色描述(如 “蓝色的天空”“红色的玫瑰”);
- 物体关系建模上,GenTron 在空间关系(如 “猫在桌子上”)得 20.98,略高于 PixArt-α(20.82),验证了交叉注意力的局部对齐能力。
3.1.2 零样本性能:数据效率优势
GenTron 使用 5.5 亿图像文本对(仅为 SDv1.4 的 1/4),但在零样本任务上表现优异(表 4):
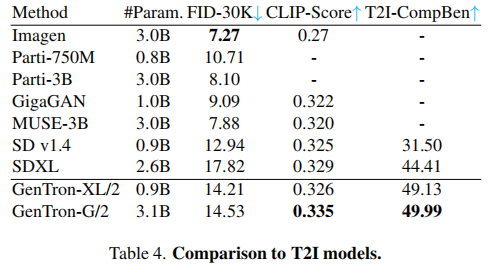
- CLIP-Score:GenTron-G/2 得 0.335,高于 SDXL(0.329)和 SDv1.4(0.325),说明文本 - 图像对齐更优;
- FID-30K:GenTron-G/2 得 14.53,虽高于 SDv1.4(12.94),但作者指出 FID 与人类审美偏好存在负相关(如 SDXL 的 FID 更低但人类偏好低于 GenTron),需结合人类评估综合判断。
3.1.3 人类评估:显著超越 SDXL
GenTron 与 SDXL 进行盲测对比,使用 100 个 PartiPrompts 生成图像,收集 3000 份人类反馈(图 7):
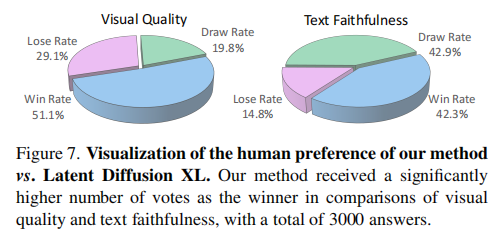
- 视觉质量:GenTron 的胜率达 51.1%(平局 19.8%),SDXL 胜率仅 29.1%;
- 文本对齐:GenTron 的胜率达 42.3%(平局 42.9%),SDXL 胜率仅 14.8%;
- 结论:人类更偏好 GenTron 生成的图像,认为其视觉更真实、与文本描述更匹配。
3.2 视频生成性能(T2V)
GenTron-T2V 的核心优势是 “帧质量高” 且 “时空一致”,具体表现为:
- 视觉质量:生成的视频帧(如 “海滩上的巨型陆龟”“游泳的狗”)细节丰富,接近 T2I 模型的帧质量,避免了传统 T2V 模型的模糊和纹理丢失(图 6);
- 时空一致性:通过 TempSelfAttn 和 MFG,视频帧间运动平滑(如陆龟的爬行、狗的划水动作),无明显跳帧或变形;
- 可控性:调节
可灵活控制运动强度,满足不同场景需求(如 “缓慢行走的人” vs “快速奔跑的人”)。

四、创新点与研究价值
4.1 核心创新点
- 首次系统性探索文本条件的 Transformer 扩散模型:通过对比文本编码器(CLIP/T5 / 组合)和嵌入整合方式(adaLN / 交叉注意力),确定 “CLIP-T5XXL + 交叉注意力” 的最优方案,为后续 Transformer 扩散模型提供范式;
- 验证了 Transformer 扩散模型的规模收益:GenTron-G/2(30 亿参数)的性能提升证明,通过扩大深度、宽度和 MLP 维度,Transformer 扩散模型可持续提升生成质量,打破 “扩散模型不适合大规模扩展” 的认知;
- MFG 策略解决 T2V 帧质量问题:通过随机禁用时序建模和联合图像 - 视频训练,平衡帧内质量与帧间一致性,为 T2V 模型提供新的训练范式;
- 数据效率优势:使用更少的训练数据(5.5 亿 vs 20 亿)实现优于 SDXL 的性能,降低模型训练的数据源依赖。
4.2 研究价值与未来方向
- 理论价值:填补了 Transformer 在扩散模型中的应用空白,为视觉生成领域的架构选择提供新方向,推动 “Transformer 化” 趋势;
- 应用价值:GenTron 可直接用于高 - quality 图像生成(如设计、创意)和视频生成(如短视频、动画),且支持运动强度调节,适配不同场景需求;
- 未来方向:
- 进一步扩大模型规模(如 100 亿参数),验证规模收益的上限;
- 优化 T2V 的推理速度,降低显存占用,实现实时生成;
- 扩展到 3D 生成、图像编辑等更多视觉任务。
五、总结
GenTron 作为 CVPR 2024 的代表性工作,通过 “文本条件注入 - 模型规模化 - T2V 扩展” 的技术路径,首次全面验证了 Transformer 在扩散模型中的优越性。其核心贡献不仅在于提出性能领先的图像与视频生成模型,更在于为视觉生成领域提供了一套可复用的 Transformer 扩散模型设计范式 —— 从文本编码器选择、嵌入整合方式,到模型规模化策略、T2V 时序建模,每一步均有明确的实验支撑,为后续研究提供了清晰的技术参考。
从实际应用角度,GenTron 的高文本对齐性和视觉质量,使其在创意设计、内容创作等领域具有巨大潜力;从研究角度,它打破了 U-Net 在扩散模型中的垄断地位,推动视觉生成向 “Transformer 化” 发展,为跨领域技术融合(如 NLP 的大模型能力迁移到视觉生成)奠定了基础。