Cangjie语言核心技术深度解析测评:迈进鸿蒙原生开发的安全新时代!
引言
随着鸿蒙生态的快速发展,华为于2023年正式发布了专为鸿蒙打造的编程语言——仓颉(Cangjie)。作为鸿蒙原生应用开发的核心语言,仓颉以「原生智能、全场景适配、强安全」三大特性,为开发者提供了全新的技术栈选择。
本文经过个人编程实践测评与学习感悟,将深入剖析仓颉语言的核心技术特性,揭示其设计理念与实现机制,并通过实例展示如何利用仓颉语言构建高性能、安全可靠的鸿蒙应用。
一、仓颉语言设计理念与技术定位
1.1 设计哲学与目标
仓颉语言的设计源于对现代操作系统和应用开发需求的深刻理解,其核心设计哲学可概括为:
- 融合创新:吸收主流编程语言的优秀特性,同时针对鸿蒙生态特点进行创新
- 安全优先:将安全设计融入语言层面,而非仅依赖运行时检查
- 性能卓越:通过静态类型系统、编译优化等手段确保高性能
- 开发友好:平衡语言表达能力与学习曲线,提升开发效率
- 生态协同:与鸿蒙操作系统深度融合,发挥全场景优势
1.2 在鸿蒙生态中的定位
仓颉语言在鸿蒙技术栈中占据核心位置,与ArkTS、JavaScript等语言形成互补关系:
- 系统级开发:适用于操作系统内核组件、驱动程序开发
- 高性能服务:可构建高并发、低延迟的系统服务
- 核心框架:作为鸿蒙框架层的重要实现语言
- 跨设备应用:支持一次开发,多端部署的全场景应用
二、仓颉语言核心特性深度解析
2.1 类型系统与内存管理
2.1.1 静态类型系统
仓颉语言采用严格的静态类型系统,在编译时即可捕获大量潜在错误:
// 变量声明必须指定类型或可由编译器推导
def main() {let count: Int = 10; // 显式类型声明let message = "Hello Cangjie"; // 类型推导// 类型检查在编译时进行// count = "not a number"; // 编译错误:类型不匹配
}
仓颉的类型系统具有以下特点:
- 代数数据类型:支持枚举、结构体等复杂数据类型
- 泛型编程:提供编译时多态,增强代码复用性
- 类型推断:减少冗余代码,同时保持类型安全
- 模式匹配:与类型系统紧密结合的强大模式匹配机制
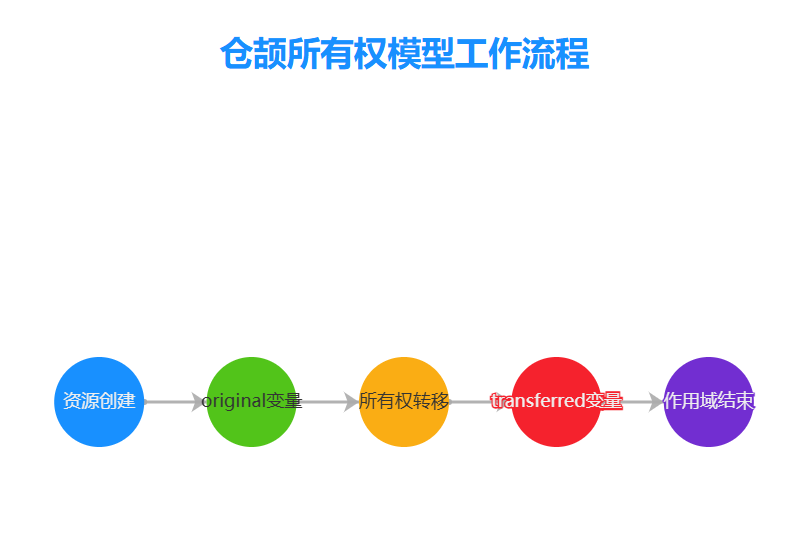
2.1.2 所有权与生命周期系统
仓颉语言引入了创新的所有权模型,解决了内存安全与性能之间的矛盾:
// 所有权示例
def transferOwnership() {let original = createResource(); // original拥有资源所有权let transferred = original; // 所有权转移到transferred// original已失去所有权,无法再使用// println(original.value); // 编译错误println(transferred.value); // 正确:transferred拥有所有权
}
仓颉所有权系统的核心规则:
- 单一所有权:每个值在任一时刻只能有一个所有者
- 作用域释放:当所有者离开作用域时,资源自动释放
- 所有权转移:赋值操作默认转移所有权,而非复制
- 借用机制:通过引用实现受控的资源共享
2.1.3 自动内存管理
仓颉采用编译时内存管理策略,无需垃圾回收器,同时保证内存安全:
- 零成本抽象:高级语言特性不会引入运行时开销
- 无内存泄漏:编译时确保所有分配的内存都能被正确释放
- 无悬垂指针:通过借用规则消除悬垂引用
- 无数据竞争:编译时检测并阻止数据竞争条件
2.2 并发编程模型
2.2.1 Actor并发模型
仓颉采用Actor模型作为并发编程的基础,实现了高效、安全的并发处理,如下图所示:
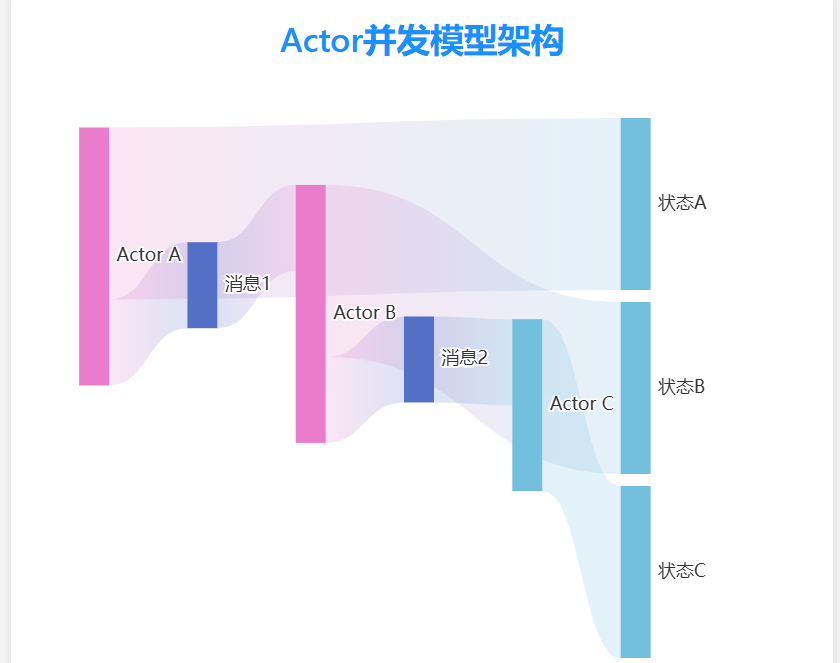
Actor模型的关键特性:
- 消息传递:Actor之间通过异步消息通信
- 状态隔离:每个Actor维护独立状态,避免共享可变状态
- 并发安全:消除数据竞争,无需显式锁
- 错误隔离:一个Actor的失败不会直接影响其他Actor
实现示例代码如下:
// Actor示例
actor Counter {private var value: Int = 0;def increment() {value = value + 1;self.emit(Updated(value));}def getValue() -> Int {return value;}
}// 使用Actor
def main() {let counter = Counter();// 异步发送消息给Actorcounter.increment();counter.increment();// 获取结果let currentValue = counter.getValue();println("Current count: \{currentValue}");
}
Actor模型优化策略为:
- 合理划分Actor边界:避免过细或过粗的粒度
- 批量处理消息:合并多个小消息减少调度开销
- 背压机制:控制消息处理速率,防止内存溢出
- 状态局部性:优化Actor状态访问模式,提高缓存命中率
2.2.2 任务与协程
仓颉提供轻量级的协程机制,用于处理异步操作:
// 协程示例
async def fetchData(url: String) -> Data {let response = await http.get(url);return parseResponse(response);
}def processResults() async {// 并发执行多个异步操作let results = await Promise.all([fetchData("https://api.example.com/data1"),fetchData("https://api.example.com/data2")]);// 处理结果for result in results {println("Processed: \{result}");}
}
协程系统的特点:
- 非阻塞I/O:异步操作不阻塞线程
- 顺序式代码:用同步代码风格编写异步逻辑
- 高效调度:轻量级协程由运行时高效调度
- 错误传播:支持异步错误处理和传播
2.3 面向切面的编程支持
2.3.1 元编程与反射
仓颉提供强大的元编程能力,支持在编译期和运行时进行代码生成和操作:
// 编译时代码生成示例
@generateSerialization
struct User {id: Int;name: String;email: String;
}// 使用自动生成的序列化方法
def saveUser(user: User) {let json = user.toJson(); // 由@generateSerialization自动生成fileSystem.write("user.json", json);
}
元编程特性包括:
- 属性装饰器:向类、函数添加元数据和行为
- 代码生成:在编译期生成代码,减少样板代码
- 类型反射:运行时获取类型信息和操作类型
- 宏系统:支持自定义编译时转换
2.3.2 切面编程
仓颉原生支持面向切面编程(AOP),便于实现横切关注点:
// 切面示例
@aspect
class LoggingAspect {@before("execution(*.service.*.*(..))")def logMethodEntry(joinPoint: JoinPoint) {println("Entering: \{joinPoint.methodName} with args: \{joinPoint.args}");}@afterReturning("execution(*.service.*.*(..))")def logMethodExit(joinPoint: JoinPoint, returnValue: Any) {println("Exiting: \{joinPoint.methodName} with result: \{returnValue}");}
}
AOP支持的核心功能:
- 切点表达式:精确定位需要拦截的代码位置
- 通知类型:支持前置、后置、环绕、异常等多种通知
- 织入机制:编译期织入,确保性能
- 类型安全:切面代码与业务代码保持类型安全
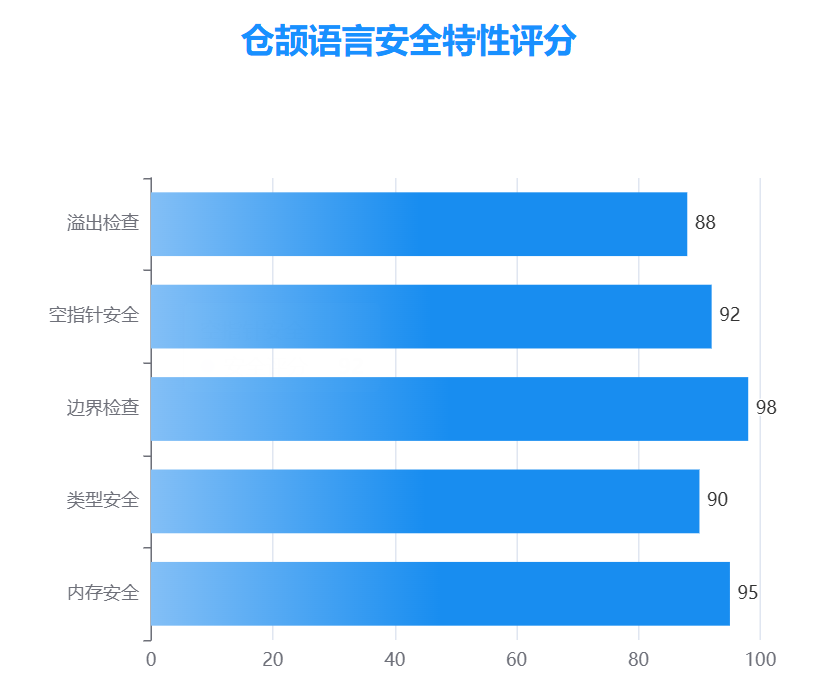
2.4 安全特性
2.4.1 内存安全保障
仓颉从语言层面提供全面的内存安全保障:
- 边界检查:数组和集合访问自动进行边界检查
- 空指针安全:使用Option类型替代空指针,避免空指针异常
- 类型安全:严格的类型系统防止类型混淆
- 溢出检查:整数运算自动检测溢出
2.4.2 权限与沙箱
仓颉与鸿蒙系统深度集成,提供细粒度的权限控制:
// 权限声明与使用
@requiresPermission("ohos.permission.READ_CONTACTS")
async def readContacts() -> List<Contact> {// 读取联系人实现// 如果没有权限,运行时会抛出PermissionDenied异常
}
安全机制包括:
- 静态权限检查:编译时验证权限使用
- 最小权限原则:应用仅能访问声明的权限
- 沙箱隔离:应用运行在隔离环境中
- 加密支持:内置密码学原语和安全API
对其安全性评测如下:
三、仓颉语言与主流语言对比分析
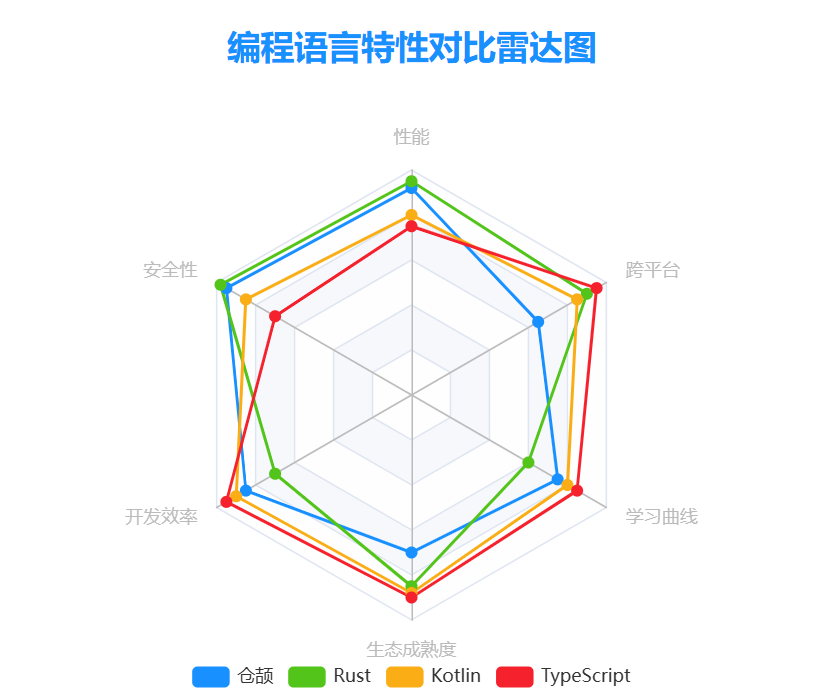
3.1 与Rust的对比
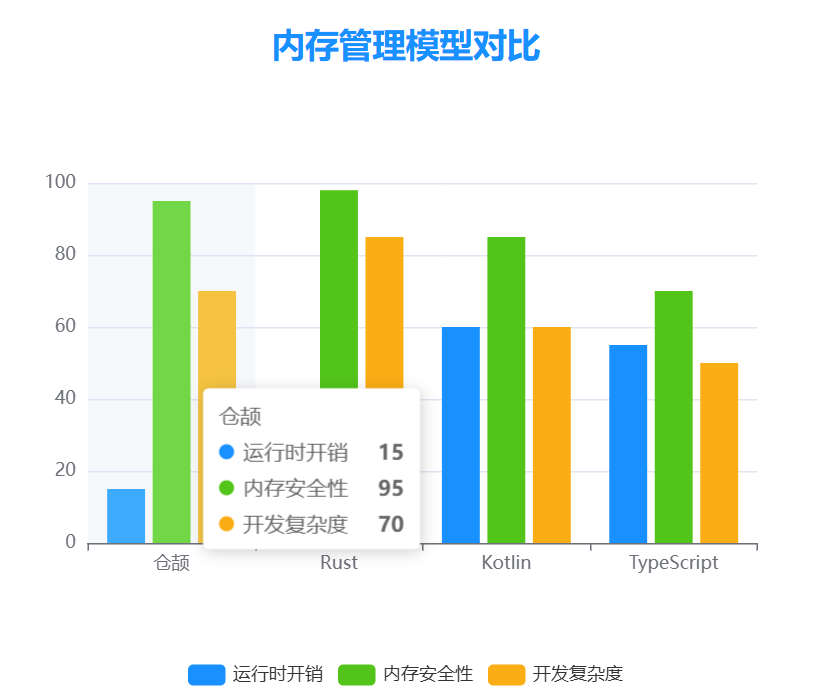
仓颉与Rust在内存管理模型上有相似之处,但也存在显著差异:
| 特性 | 仓颉 | Rust |
|---|---|---|
| 所有权模型 | 单一所有权,支持转移 | 单一所有权,支持转移 |
| 借用规则 | 编译时检查借用 | 编译时检查借用 |
| 并发模型 | Actor模型为主 | 基于Send/Sync trait |
| 学习曲线 | 相对平缓 | 较陡峭 |
| 生态集成 | 深度集成鸿蒙生态 | 广泛的跨平台支持 |
| 错误处理 | 支持异常和Result类型 | 主要使用Result/Option |
3.2 与Kotlin的对比
作为同样面向现代平台的语言,仓颉与Kotlin有以下对比:
| 特性 | 仓颉 | Kotlin |
|---|---|---|
| 类型系统 | 静态类型,编译期检查 | 静态类型,编译期检查 |
| 空安全 | Option类型 | 可空类型系统 |
| 协程支持 | 原生支持 | 通过协程库支持 |
| 元编程 | 编译时反射,宏系统 | 注解处理,KSP |
| 平台适配 | 主要面向鸿蒙 | 跨平台(JVM/JS/Native) |
| 内存管理 | 编译时管理,无GC | 主要依赖JVM GC |
3.3 与TypeScript的对比
仓颉与TypeScript都是静态类型语言,但在设计目标上有明显区别:
| 特性 | 仓颉 | TypeScript |
|---|---|---|
| 编译目标 | 原生代码 | JavaScript |
| 类型系统 | 严格静态类型 | 可选静态类型 |
| 运行时 | 独立运行时 | 依赖JavaScript引擎 |
| 并发模型 | Actor模型 | 基于JavaScript事件循环 |
| 性能优化 | 编译时优化 | 受JavaScript引擎限制 |
| 平台支持 | 主要面向鸿蒙 | 主要面向Web和Node.js |
总结编程语言特性对比如下所示:
四、仓颉语言实战应用示例
4.1 基础应用开发
下面展示一个简单的仓颉应用示例:
// 主应用入口
app MainApp {entry MainPage;
}// 主页面组件
component MainPage {@State private count: Int = 0;build() {Column(alignment: Center) {Text("计数器: \{count}").fontSize(24).margin(20)Row(spacing: 20) {Button("增加") {count++;}Button("减少") {if (count > 0) {count--;}}}}.padding(30)}
}
4.2 系统服务开发
仓颉适合开发高性能系统服务:
// 文件监控服务
@service
class FileMonitorService {private var watchers: Map<String, List<FileChangeListener>> = {};// 注册文件变更监听器def registerListener(path: String, listener: FileChangeListener) {if (!watchers.contains(path)) {watchers[path] = [];startMonitoring(path);}watchers[path].add(listener);}// 启动文件监控private def startMonitoring(path: String) {// 实现文件系统监控逻辑// 使用Actor模型处理文件变更事件}// 处理文件变更事件private def onFileChanged(path: String, event: FileEvent) {if (watchers.contains(path)) {for listener in watchers[path] {// 异步通知所有监听器async listener.onFileChanged(path, event);}}}
}
4.3 跨设备应用开发
利用仓颉开发鸿蒙跨设备应用:
// 分布式任务调度器
class DistributedTaskScheduler {// 在指定设备上执行任务async def executeOnDevice(deviceId: String, task: () -> Any) -> Any {try {// 检查设备可用性if (!await DeviceManager.isDeviceAvailable(deviceId)) {throw DeviceUnavailableException(deviceId);}// 序列化任务let serializedTask = serializeTask(task);// 分发任务到目标设备return await DistributedService.sendTask(deviceId, serializedTask);} catch (e: Exception) {println("Task execution failed: \{e.message}");throw e;}}// 并行在多个设备上执行任务async def executeInParallel(deviceIds: List<String>, task: (String) -> Any) -> Map<String, Any> {let promises: List<Promise<Pair<String, Any>>> = [];for deviceId in deviceIds {promises.add(async {try {let result = await executeOnDevice(deviceId, () => task(deviceId));return Pair(deviceId, result);} catch (e: Exception) {return Pair(deviceId, ErrorResult(e));}});}let results = await Promise.all(promises);let resultMap: Map<String, Any> = {};for result in results {resultMap[result.first] = result.second;}return resultMap;}
}
五、仓颉语言性能优化策略
5.1 编译期优化
仓颉编译器提供多层次的性能优化:
- 内联函数:自动识别热点函数进行内联
- 死代码消除:删除不会执行的代码
- 常量折叠:在编译期计算常量表达式
- 类型特化:为特定类型生成优化代码
- 尾递归优化:将尾递归转换为循环,避免栈溢出
5.2 运行时优化
运行时优化策略:
- 惰性初始化:资源在首次使用时才初始化
- 对象池:重用频繁创建的对象,减少内存分配
- 零拷贝技术:在数据传输过程中避免不必要的复制
- 协程调度优化:智能调度协程执行,最大化CPU利用率
5.3 内存管理优化
内存使用优化技巧:
// 内存优化示例
def processLargeData() {// 使用内存映射文件处理大文件let mappedFile = MappedFile.open("large_dataset.csv");// 流式处理,避免一次性加载全部数据let result = mappedFile.streamLines().filter(line => line.length > 0).map(line => parseData(line)).filter(data => data.isValid).reduce((acc, data) => acc + process(data), 0);return result;
}
在各阶段优化效果对比如下:
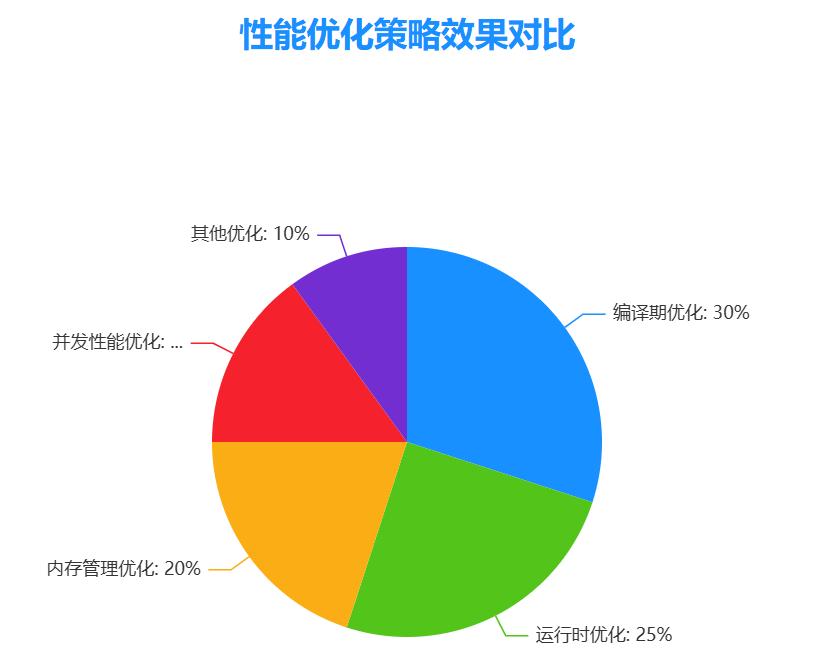
对比各语言内存管理各项性能如下所示:
六、仓颉语言的未来发展趋势
6.1 语言特性演进
仓颉语言的未来版本将继续增强以下方面:
- AI原生支持:更深入地集成AI功能,支持模型部署和推理
- 分布式编程:强化跨设备协作能力
- 领域特定语言:提供更多领域特定的语言扩展
- 工具链增强:改进开发工具和调试体验
6.2 生态系统建设
生态系统发展重点:
- 标准库扩展:丰富标准库功能,覆盖更多应用场景
- 第三方库:鼓励社区开发高质量第三方库
- 教育资源:提供全面的学习材料和教程
- 认证体系:建立开发者认证和培训体系
6.3 在鸿蒙生态中的角色
仓颉将在鸿蒙生态中扮演更加核心的角色:
- 系统实现语言:更多鸿蒙系统组件将使用仓颉实现
- 应用开发语言:成为鸿蒙原生应用开发的首选语言
- 跨平台桥梁:连接鸿蒙与其他平台的开发体验
- 创新引擎:驱动鸿蒙生态技术创新
七、仓颉语言学习路径与最佳实践
7.1 学习路径建议
对于想要掌握仓颉语言的开发者,建议按以下路径学习:
- 语言基础:熟悉语法、类型系统和基本概念
- 内存模型:深入理解所有权和生命周期系统
- 并发编程:掌握Actor模型和协程使用
- 鸿蒙集成:学习如何开发鸿蒙应用和服务
- 性能优化:掌握性能调优和最佳实践
7.2 常见陷阱与规避策略
开发中常见的问题及解决方法:
| 问题类型 | 常见表现 | 解决方法 |
|---|---|---|
| 所有权错误 | 变量不可用或编译错误 | 理解所有权转移规则,合理使用借用 |
| 异步操作阻塞 | 应用响应变慢 | 避免在协程中执行阻塞操作,使用异步API |
| 内存使用过高 | 应用占用内存增加 | 使用流式处理,及时释放不必要资源 |
| 并发错误 | 数据不一致或死锁 | 遵循Actor模型原则,避免共享可变状态 |
| 权限问题 | 功能无法访问系统资源 | 正确声明和请求所需权限 |
7.3 代码质量保证
提高代码质量的实践:
- 单元测试:为关键功能编写单元测试
- 静态分析:使用静态分析工具检查潜在问题
- 代码审查:建立代码审查机制
- 性能分析:定期进行性能分析和优化
- 文档完善:保持代码注释和文档更新
总结与展望
仓颉语言作为华为专为鸿蒙打造的核心编程语言,通过创新的设计理念和技术特性,为鸿蒙应用开发提供了强大的支持。其独特的所有权模型、Actor并发模型和安全特性,使其在性能、安全性和开发效率之间取得了良好的平衡。
随着鸿蒙生态的不断发展和完善,仓颉语言将在推动鸿蒙应用开发标准化、提升开发效率、保证应用质量等方面发挥越来越重要的作用。对于开发者而言,掌握仓颉语言不仅意味着获得了开发鸿蒙应用的能力,也代表着对下一代操作系统应用开发范式的理解和把握。
未来,随着仓颉语言和鸿蒙生态的持续演进,我们有理由相信,这一技术组合将为智能终端、物联网、车载系统等众多领域带来更加创新和高效的解决方案,推动全场景智慧生活的实现。
以下是作者整理的关于仓颉语言的官网和技术文档:
-
仓颉编程语言官网 https://cangjie-lang.cn
-
仓颉编程语言技术文档 https://cangjie-lang.cn/docs
-
华为开发者官网 https://developer.huawei.com/
-
仓颉语言第三方工具和库资源
- Requests4cj网络库: https://gitcode.com/FlowerSacrifice/requests
- IntelliJ IDEA仓颉插件: https://gitcode.com/OpenCangjieCommunity/intellij-cangjie