【完整源码+数据集+部署教程】【零售和消费品&存货】食品分类检测系统源码&数据集全套:改进yolo11-RepNCSPELAN_CAA
背景意义
随着食品安全问题的日益突出,食品分类与检测技术在保障公众健康、提升食品质量监管效率方面显得尤为重要。传统的食品分类方法往往依赖人工检查,不仅效率低下,而且容易受到人为因素的影响,导致分类结果的不准确性。近年来,深度学习技术的快速发展为食品分类检测提供了新的解决方案。YOLO(You Only Look Once)系列模型因其高效的实时检测能力,已成为计算机视觉领域的热门选择。特别是YOLOv11模型,凭借其更高的精度和更快的处理速度,成为食品分类检测的理想工具。
本研究旨在基于改进的YOLOv11模型,构建一个高效的食品分类检测系统。我们将使用包含84000张图像的Groceries数据集,该数据集涵盖了多种食品类别,包括牛奶、罐头食品、巧克力、糖果、调味品等,共计100个不同的类目。这种丰富的多样性不仅能够提升模型的泛化能力,还能为实际应用提供更为全面的支持。通过对YOLOv11模型的改进,我们期望能够在提高检测精度的同时,缩短处理时间,从而实现实时食品分类检测。
此外,食品分类检测系统的成功应用将为超市、餐饮行业及食品生产企业提供强有力的技术支持,帮助其在库存管理、产品追溯及食品安全监测等方面提升效率。同时,随着智能零售的兴起,基于视觉识别的自动化系统将为消费者提供更为便捷的购物体验。因此,本研究不仅具有重要的学术价值,也具有广泛的应用前景,能够为食品行业的智能化转型提供切实可行的解决方案。
图片效果
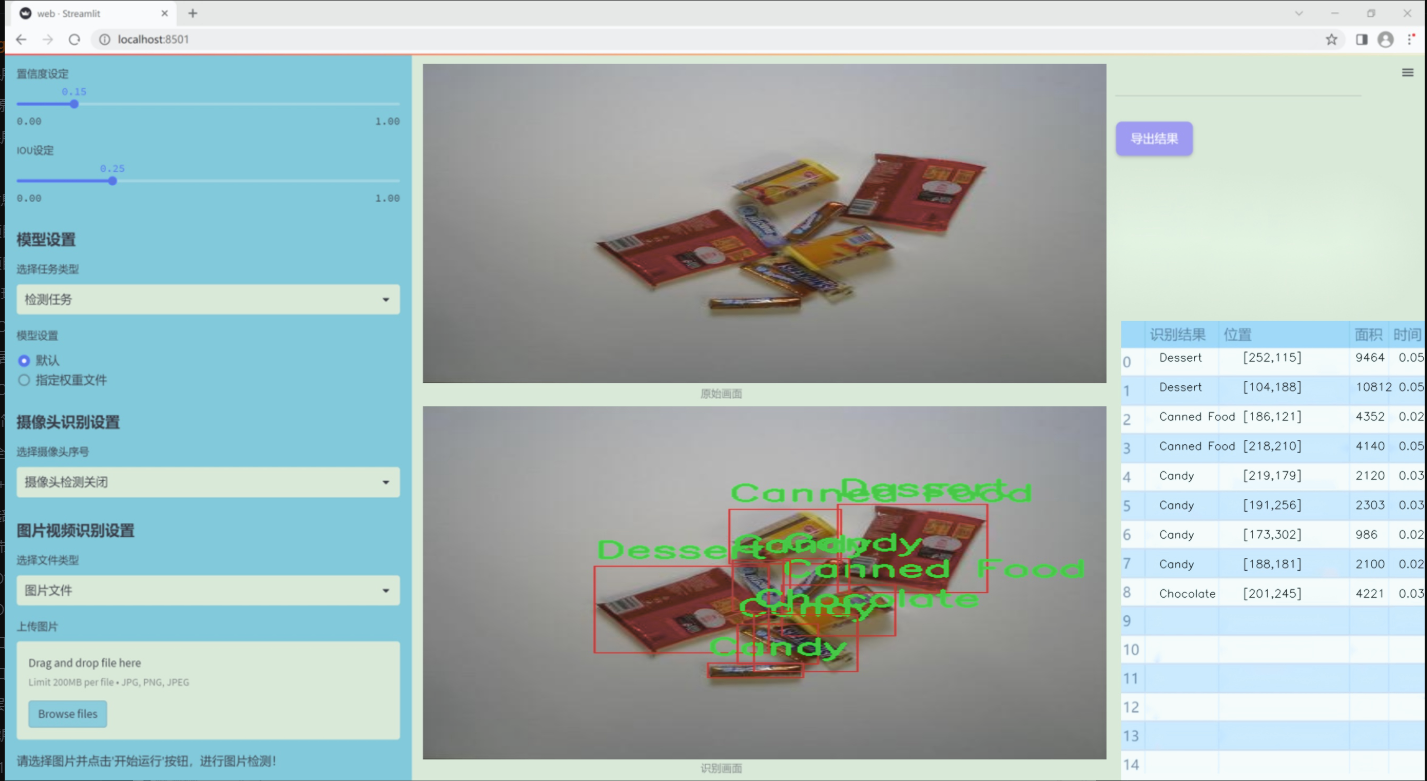
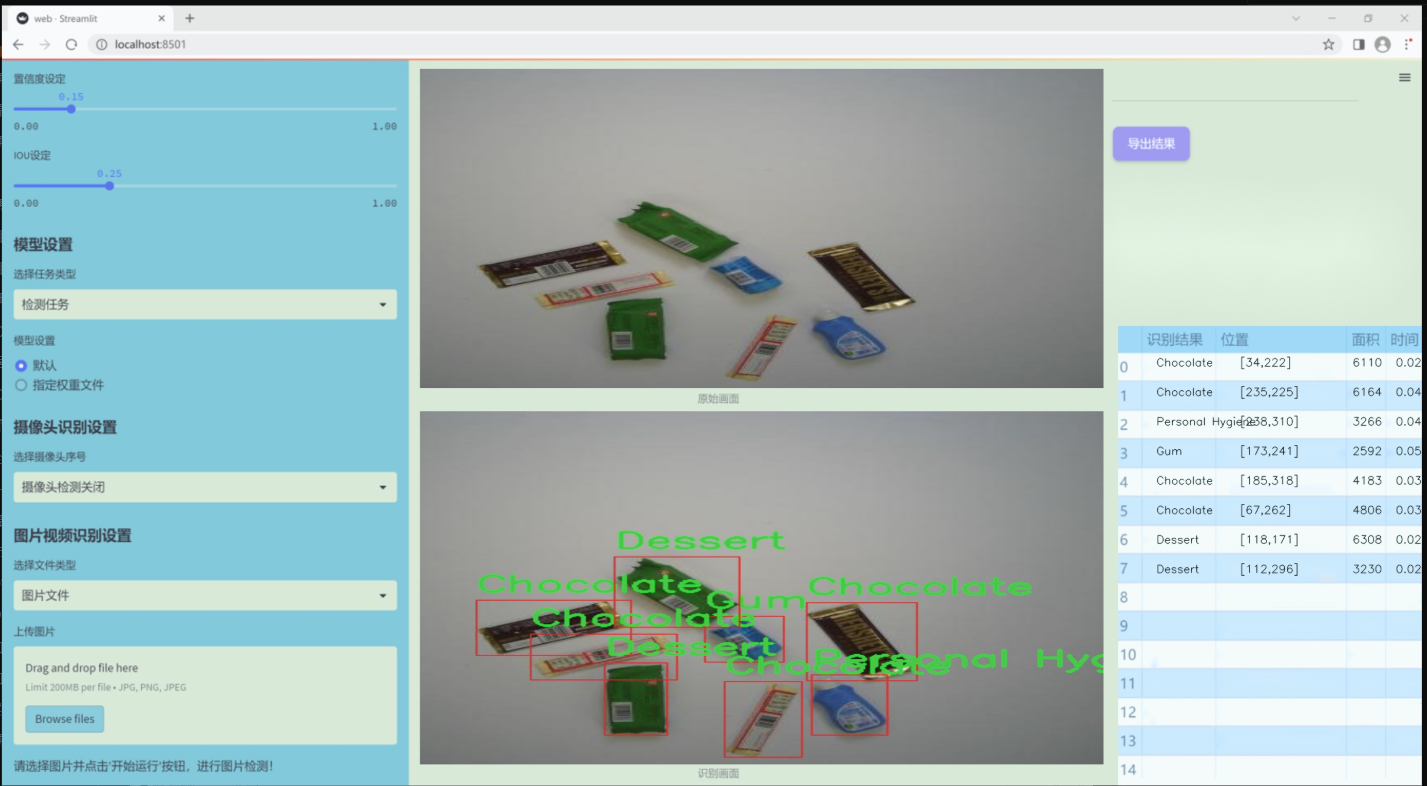
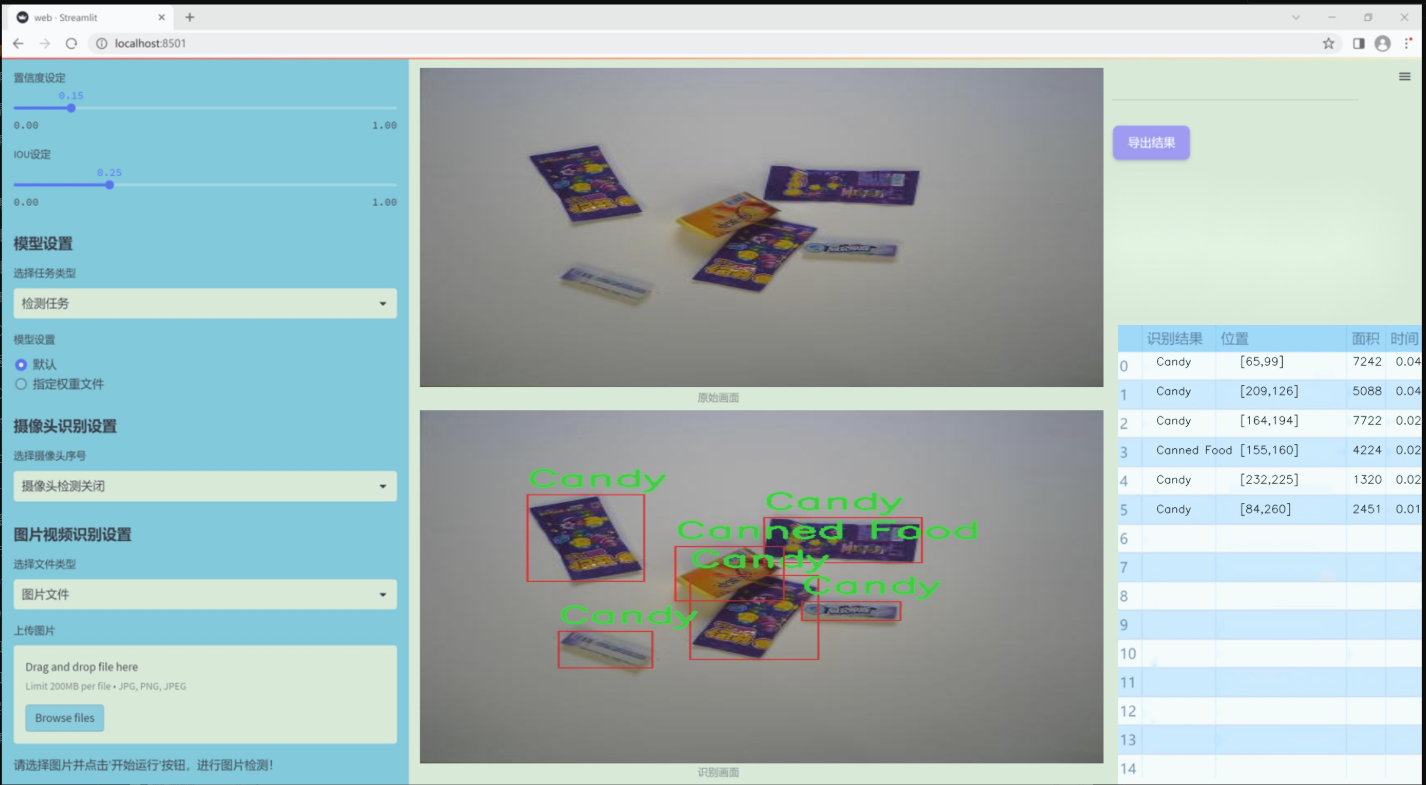
数据集信息
本项目所使用的数据集名为“Groceries”,旨在为改进YOLOv11的食品分类检测系统提供丰富的训练素材。该数据集包含17个不同的食品类别,涵盖了广泛的日常消费品,以确保模型在实际应用中的准确性和鲁棒性。具体类别包括:酒精类(Alcohol)、糖果(Candy)、罐装食品(Canned Food)、巧克力(Chocolate)、甜点(Dessert)、干货(Dried Food)、干果(Dried Fruit)、饮料(Drink)、口香糖(Gum)、即饮饮料(Instant Drink)、方便面(Instant Noodles)、牛奶(Milk)、个人卫生用品(Personal Hygiene)、膨化食品(Puffed Food)、调味品(Seasoner)、文具(Stationery)以及纸巾(Tissue)。
“Groceries”数据集的多样性不仅反映了消费者日常生活中的常见食品,还为模型提供了丰富的视觉特征,以便更好地进行分类和检测。每个类别都包含了多种样本,涵盖了不同品牌、包装和外观,确保模型能够学习到更为全面的特征表示。此外,数据集中的图像经过精心标注,确保每个样本的准确性和一致性,这对于训练高效的深度学习模型至关重要。
通过使用“Groceries”数据集,项目旨在提升YOLOv11在食品分类任务中的性能,使其能够在复杂的环境中快速、准确地识别和分类各种食品。这一改进不仅能够增强模型的实用性,还能为零售、物流等行业提供更为智能化的解决方案,推动食品检测技术的进一步发展。整体而言,“Groceries”数据集为本项目的成功实施奠定了坚实的基础。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import math
import torch
import torch.nn as nn
from typing import Optional, Sequence
class DropPath(nn.Module):
“”“随机丢弃路径(Stochastic Depth)模块,通常用于残差块的主路径中。”“”
def __init__(self, drop_prob: float = 0.1):super().__init__()self.drop_prob = drop_prob # 丢弃概率def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播,应用随机丢弃路径"""if self.drop_prob == 0. or not self.training:return x # 如果丢弃概率为0或不在训练模式,直接返回输入keep_prob = 1 - self.drop_probshape = (x.shape[0], ) + (1, ) * (x.ndim - 1) # 处理不同维度的张量random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)output = x.div(keep_prob) * random_tensor.floor() # 进行随机丢弃return output
class ConvFFN(BaseModule):
“”“使用卷积模块实现的多层感知机(MLP)”“”
def __init__(self, in_channels: int, out_channels: Optional[int] = None, hidden_channels_scale: float = 4.0,dropout_rate: float = 0., add_identity: bool = True, norm_cfg: Optional[dict] = None,act_cfg: Optional[dict] = None):super().__init__()out_channels = out_channels or in_channels # 如果未指定输出通道,则与输入通道相同hidden_channels = int(in_channels * hidden_channels_scale) # 隐藏层通道数# 定义前馈网络的层self.ffn_layers = nn.Sequential(nn.LayerNorm(in_channels), # 归一化层ConvModule(in_channels, hidden_channels, kernel_size=1, stride=1, padding=0, norm_cfg=norm_cfg, act_cfg=act_cfg),ConvModule(hidden_channels, hidden_channels, kernel_size=3, stride=1, padding=1, groups=hidden_channels, norm_cfg=norm_cfg, act_cfg=None),nn.GELU(), # 使用GELU激活函数nn.Dropout(dropout_rate), # 丢弃层ConvModule(hidden_channels, out_channels, kernel_size=1, stride=1, padding=0, norm_cfg=norm_cfg, act_cfg=act_cfg),nn.Dropout(dropout_rate), # 再次丢弃层)self.add_identity = add_identity # 是否添加恒等映射def forward(self, x):"""前向传播,添加恒等映射(如果需要)"""x = x + self.ffn_layers(x) if self.add_identity else self.ffn_layers(x)return x
class PKINet(BaseModule):
“”“多核卷积网络(Poly Kernel Inception Network)”“”
def __init__(self, arch: str = 'S', out_indices: Sequence[int] = (0, 1, 2, 3, 4), drop_path_rate: float = 0.1):super().__init__()self.out_indices = out_indices # 输出的层索引self.stages = nn.ModuleList() # 存储网络的各个阶段# 初始化网络的stem部分self.stem = Stem(3, 32) # 输入通道为3,输出通道为32self.stages.append(self.stem)# 构建各个阶段for i in range(4): # 假设有4个阶段stage = PKIStage(32 * (2 ** i), 64 * (2 ** i)) # 每个阶段的输入输出通道self.stages.append(stage)def forward(self, x):"""前向传播,依次通过各个阶段"""outs = []for i, stage in enumerate(self.stages):x = stage(x)if i in self.out_indices:outs.append(x) # 记录输出层return tuple(outs)
def PKINET_S():
“”“创建一个小型的多核卷积网络实例”“”
return PKINet(‘S’)
if name == ‘main’:
model = PKINET_S() # 实例化模型
inputs = torch.randn((1, 3, 640, 640)) # 创建输入张量
res = model(inputs) # 前向传播
for i in res:
print(i.size()) # 打印输出的尺寸
代码核心部分解释:
DropPath 类:实现了随机丢弃路径的功能,通常用于深度学习中的残差网络,以提高模型的泛化能力。
ConvFFN 类:实现了一个多层感知机(MLP),使用卷积层和激活函数来处理输入数据,并可以选择性地添加恒等映射。
PKINet 类:构建了一个多核卷积网络的框架,包含多个阶段,每个阶段可以有不同的输入和输出通道设置。前向传播时依次通过各个阶段,并记录指定的输出层。
以上代码是多核卷积网络的核心实现部分,其他辅助类和函数用于支持这些核心功能。
这个程序文件 pkinet.py 实现了一个名为 PKINet 的深度学习模型,主要用于计算机视觉任务。它的结构基于多种模块的组合,包括卷积层、注意力机制和前馈网络等。以下是对代码的详细说明。
首先,文件导入了一些必要的库,包括数学库、类型提示、PyTorch 及其神经网络模块。接着,尝试导入了一些来自 mmcv 和 mmengine 的模块,这些模块提供了卷积模块、模型基类和权重初始化的功能。如果导入失败,则使用 PyTorch 的基本模块。
接下来,定义了一些辅助函数和类。drop_path 函数实现了随机深度(Stochastic Depth),用于在训练期间随机丢弃某些路径,以提高模型的泛化能力。DropPath 类是对这个函数的封装,作为一个可训练的模块。
autopad 函数用于自动计算卷积的填充,以确保输出的尺寸符合要求。make_divisible 函数确保通道数是可被指定除数整除的,常用于调整模型的结构以适应硬件限制。
接下来,定义了一些张量维度转换的类,如 BCHW2BHWC 和 BHWC2BCHW,用于在不同的通道顺序之间转换。GSiLU 类实现了一种激活函数,结合了全局平均池化和 Sigmoid 激活。
CAA 类实现了上下文锚注意力机制,通过卷积和池化操作生成注意力因子。ConvFFN 类实现了一个多层感知机,使用卷积模块作为基础。
Stem 和 DownSamplingLayer 类分别实现了模型的初始层和下采样层。InceptionBottleneck 类实现了带有多个卷积核的瓶颈结构,结合了注意力机制和残差连接。
PKIBlock 类实现了多核的 Inception 模块,包含了前馈网络和随机深度的功能。PKIStage 类则是由多个 PKIBlock 组成的阶段,负责处理输入特征并进行下采样。
PKINet 类是整个网络的主类,定义了网络的架构和各个阶段的组合。它根据指定的架构(如 ‘T’, ‘S’, ‘B’)构建网络,并初始化权重。init_weights 方法用于初始化网络中的权重。
最后,定义了三个函数 PKINET_T、PKINET_S 和 PKINET_B,分别返回不同架构的 PKINet 模型。在主程序中,创建了一个 PKINET_T 模型实例,并对随机输入进行前向传播,输出各层的特征图尺寸。
总体来说,这个文件实现了一个复杂的深度学习模型,结合了多种现代卷积神经网络的设计理念,适用于图像处理等任务。
10.3 conv.py
以下是经过简化并添加详细中文注释的核心代码部分:
import math
import torch
import torch.nn as nn
def autopad(k, p=None, d=1):
“”“自动填充以保持输出形状不变。”“”
if d > 1:
# 如果膨胀(dilation)大于1,计算实际的卷积核大小
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
if p is None:
# 如果没有提供填充,自动计算填充
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
“”“标准卷积层,包含卷积、批归一化和激活函数。”“”
default_act = nn.SiLU() # 默认激活函数def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""初始化卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、填充、分组、膨胀和激活函数。"""super().__init__()# 创建卷积层self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2) # 批归一化层# 根据输入选择激活函数self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""前向传播,依次经过卷积、批归一化和激活函数。"""return self.act(self.bn(self.conv(x)))
class DWConv(Conv):
“”“深度可分离卷积,使用深度卷积。”“”
def __init__(self, c1, c2, k=1, s=1, d=1, act=True):"""初始化深度卷积,参数包括输入通道数、输出通道数、卷积核大小、步幅、膨胀和激活函数。"""super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
class DSConv(nn.Module):
“”“深度可分离卷积模块。”“”
def __init__(self, c1, c2, k=1, s=1, d=1, act=True):"""初始化深度可分离卷积,包含深度卷积和逐点卷积。"""super().__init__()self.dwconv = DWConv(c1, c1, 3) # 深度卷积self.pwconv = Conv(c1, c2, 1) # 逐点卷积def forward(self, x):"""前向传播,依次经过深度卷积和逐点卷积。"""return self.pwconv(self.dwconv(x))
class ConvTranspose(nn.Module):
“”“转置卷积层。”“”
default_act = nn.SiLU() # 默认激活函数def __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):"""初始化转置卷积层,包含批归一化和激活函数。"""super().__init__()self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity() # 批归一化self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""前向传播,依次经过转置卷积、批归一化和激活函数。"""return self.act(self.bn(self.conv_transpose(x)))
class ChannelAttention(nn.Module):
“”“通道注意力模块。”“”
def __init__(self, channels: int):"""初始化通道注意力模块,包含自适应平均池化和全连接层。"""super().__init__()self.pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True) # 全连接层self.act = nn.Sigmoid() # 激活函数def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播,计算通道注意力并与输入相乘。"""return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
“”“空间注意力模块。”“”
def __init__(self, kernel_size=7):"""初始化空间注意力模块,设置卷积核大小。"""super().__init__()assert kernel_size in {3, 7}, "卷积核大小必须为3或7"padding = 3 if kernel_size == 7 else 1self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 卷积层self.act = nn.Sigmoid() # 激活函数def forward(self, x):"""前向传播,计算空间注意力并与输入相乘。"""return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
“”“卷积块注意力模块。”“”
def __init__(self, c1, kernel_size=7):"""初始化CBAM模块,包含通道注意力和空间注意力。"""super().__init__()self.channel_attention = ChannelAttention(c1) # 通道注意力self.spatial_attention = SpatialAttention(kernel_size) # 空间注意力def forward(self, x):"""前向传播,依次经过通道注意力和空间注意力。"""return self.spatial_attention(self.channel_attention(x))
代码说明:
autopad:用于自动计算填充,以保持卷积输出的形状与输入相同。
Conv:标准卷积层,包含卷积、批归一化和激活函数的组合。
DWConv:深度卷积,继承自Conv,用于实现深度可分离卷积。
DSConv:深度可分离卷积模块,包含深度卷积和逐点卷积。
ConvTranspose:转置卷积层,常用于上采样。
ChannelAttention:通道注意力模块,通过自适应池化和全连接层计算通道权重。
SpatialAttention:空间注意力模块,通过卷积计算空间权重。
CBAM:结合通道注意力和空间注意力的模块,用于增强特征表示。
以上代码为YOLO模型中常用的卷积和注意力机制模块,提供了灵活的构建方式以增强特征提取能力。
这个程序文件 conv.py 定义了一系列用于卷积操作的模块,主要用于深度学习中的计算机视觉任务,特别是与 YOLO(You Only Look Once)模型相关的实现。文件中包含了多种卷积层的实现,利用 PyTorch 框架构建神经网络。
首先,文件导入了必要的库,包括 math、numpy 和 torch 及其子模块 torch.nn。然后定义了一个 autopad 函数,用于自动计算卷积操作所需的填充,以确保输出形状与输入形状相同。
接下来,定义了多个卷积类。Conv 类实现了标准的卷积操作,包含卷积层、批归一化层和激活函数。构造函数接受多个参数,包括输入通道数、输出通道数、卷积核大小、步幅、填充、分组卷积、扩张率和激活函数。forward 方法实现了前向传播过程。
Conv2 类是 Conv 类的简化版本,增加了一个 1x1 的卷积层,并在前向传播中将两个卷积的输出相加。LightConv 类实现了一种轻量级卷积结构,结合了标准卷积和深度卷积(DWConv)。
DWConv 类实现了深度卷积,即对每个输入通道独立进行卷积操作。DSConv 类则实现了深度可分离卷积,由深度卷积和逐点卷积组成。
DWConvTranspose2d 和 ConvTranspose 类实现了转置卷积操作,后者可以选择性地包含批归一化和激活函数。
Focus 类用于将空间信息聚合到通道维度,通过对输入张量进行切片和拼接来实现。GhostConv 类实现了 Ghost 卷积,结合了主卷积和廉价操作以提高特征学习的效率。
RepConv 类实现了一种重参数化卷积,允许在训练和推理阶段使用不同的卷积结构。它提供了融合卷积的功能,可以将多个卷积层合并为一个。
此外,文件中还定义了注意力机制模块,包括 ChannelAttention 和 SpatialAttention,用于增强特征图的表示能力。CBAM 类结合了这两种注意力机制,形成了卷积块注意力模块。
最后,Concat 类实现了在指定维度上连接多个张量的功能,常用于将不同特征图合并以进行后续处理。
整体而言,这个文件提供了一系列灵活且高效的卷积层和注意力机制,适用于构建现代计算机视觉模型,尤其是在 YOLO 系列模型中。
10.4 test_selective_scan.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn.functional as F
def build_selective_scan_fn(selective_scan_cuda: object = None, mode=“mamba_ssm”, tag=None):
“”"
构建选择性扫描函数的工厂函数。
参数:
selective_scan_cuda: 用于选择性扫描的CUDA实现。
mode: 选择性扫描的模式。
tag: 可选的标签,用于标识函数。返回:
selective_scan_fn: 构建的选择性扫描函数。
"""class SelectiveScanFn(torch.autograd.Function):@staticmethoddef forward(ctx, u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False, nrows=1, backnrows=-1):"""前向传播函数。参数:ctx: 上下文对象,用于保存信息以供反向传播使用。u: 输入张量。delta: 增量张量。A, B, C: 权重张量。D: 可选的张量。z: 可选的张量。delta_bias: 可选的增量偏置。delta_softplus: 是否使用softplus激活。return_last_state: 是否返回最后的状态。nrows: 行数。backnrows: 反向传播时的行数。返回:out: 输出张量,或包含输出和最后状态的元组。"""# 确保输入张量是连续的if u.stride(-1) != 1:u = u.contiguous()if delta.stride(-1) != 1:delta = delta.contiguous()if D is not None:D = D.contiguous()if B.stride(-1) != 1:B = B.contiguous()if C.stride(-1) != 1:C = C.contiguous()if z is not None and z.stride(-1) != 1:z = z.contiguous()# 确保B和C的维度符合要求if B.dim() == 3:B = rearrange(B, "b dstate l -> b 1 dstate l")ctx.squeeze_B = Trueif C.dim() == 3:C = rearrange(C, "b dstate l -> b 1 dstate l")ctx.squeeze_C = True# 确保输入的形状和类型正确assert u.shape[1] % (B.shape[1] * nrows) == 0 assert nrows in [1, 2, 3, 4] # 限制行数# 调用CUDA实现的前向函数out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, z, delta_bias, delta_softplus)# 保存用于反向传播的张量ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)# 获取最后状态last_state = x[:, :, -1, 1::2] # (batch, dim, dstate)return out if not return_last_state else (out, last_state)@staticmethoddef backward(ctx, dout):"""反向传播函数。参数:ctx: 上下文对象,包含前向传播时保存的信息。dout: 输出的梯度。返回:输入张量的梯度。"""# 从上下文中恢复前向传播时保存的张量u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors# 调用CUDA实现的反向函数du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus)return (du, ddelta, dA, dB, dC, dD if D is not None else None, ddelta_bias if delta_bias is not None else None)def selective_scan_fn(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False, nrows=1, backnrows=-1):"""封装选择性扫描函数的调用。参数:u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state, nrows, backnrows: 与前向传播函数相同的参数。返回:outs: 选择性扫描的输出。"""outs = SelectiveScanFn.apply(u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state, nrows, backnrows)return outsreturn selective_scan_fn
代码核心部分说明:
build_selective_scan_fn: 这是一个工厂函数,用于构建选择性扫描的前向和反向传播函数。它接收CUDA实现和模式作为参数,并返回一个可以调用的选择性扫描函数。
SelectiveScanFn: 这是一个自定义的PyTorch自动求导函数,包含前向和反向传播的实现。前向传播计算输出并保存中间结果,反向传播计算梯度。
forward: 前向传播的核心逻辑,处理输入张量的形状和类型,调用CUDA实现进行计算,并返回结果。
backward: 反向传播的核心逻辑,恢复前向传播时保存的张量,计算梯度并返回。
selective_scan_fn: 封装选择性扫描函数的调用,简化用户接口。
以上代码实现了选择性扫描的基本框架,允许在不同的模式下使用不同的CUDA实现,并通过PyTorch的自动求导机制支持反向传播。
这个程序文件 test_selective_scan.py 是一个用于测试选择性扫描(Selective Scan)操作的实现,主要使用 PyTorch 框架。程序中定义了一个自定义的 PyTorch 自动求导函数,并提供了多个测试用例来验证该函数的正确性和性能。
首先,程序导入了必要的库,包括 PyTorch、Einops(用于张量重排)、时间模块和 functools 模块。接着,定义了一个函数 build_selective_scan_fn,用于构建选择性扫描的前向和反向传播函数。这个函数内部定义了一个名为 SelectiveScanFn 的类,继承自 torch.autograd.Function,其中包含了静态方法 forward 和 backward。
在 forward 方法中,程序首先对输入张量进行连续性检查,并根据输入的维度进行必要的重排。然后,依据不同的模式(如 “mamba_ssm”、“ssoflex” 等),调用相应的 CUDA 后端实现进行前向计算。计算完成后,保存必要的中间结果以便在反向传播时使用。
backward 方法则实现了反向传播的逻辑,计算输入张量的梯度。根据模式的不同,调用相应的 CUDA 后端实现进行反向计算,并处理可能的类型转换。
接下来,程序定义了几个参考实现的函数,如 selective_scan_ref 和 selective_scan_ref_v2,这些函数提供了选择性扫描的标准实现,用于与自定义实现进行比较。
在文件的最后部分,程序通过 pytest 框架定义了一系列的测试用例。使用 @pytest.mark.parametrize 装饰器,程序生成了多种输入组合,包括不同的数据类型、序列长度、是否使用偏置等。每个测试用例会生成输入数据,并调用自定义的选择性扫描函数和参考实现,比较它们的输出和梯度是否一致。
程序的最后部分设置了不同的模式并打印当前使用的模式。通过这些测试,程序旨在确保选择性扫描的实现是正确的,并且在不同的配置下能够正常工作。整体上,这个文件是一个完整的测试框架,旨在验证和比较选择性扫描操作的实现。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻