22.unordered_map和unordered_set的封装
代码会贴在最后面
一.模拟map和set进行封装
#pragma once#include "HashTable.h"namespace ltw
{template<class K,class V>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K,V>& kv){return kv.first;}};private:};
}#pragma once#include "HashTable.h"namespace ltw
{template<class K>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:bool insert(const K& key){return _ht.Insert(key);}public:HashTable<K,K,SetKeyOfT> _ht;};
}和map,set一样,我们可以对HashTable进行增加一个模板参数

下面是目前哈希结构代码
#pragma once
#include <iostream>
#include <vector>using namespace std;
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};template <>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hashi = 0;for(auto e : s){hashi *= 31;hashi += e;}return hashi;}
};namespace ltw
{template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data),_next(nullptr){}};template<class K,class T,class KeyOfT,class Hash = HashFunc<K>>class HashTable{typedef HashNode<T> Node;public:HashTable(){_tables.resize(10,nullptr);}~HashTable(){//只要把我们的_tables下的链表释放掉for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];while(cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const T& data){KeyOfT kot;Hash hs;size_t hashi = hs(kot(data)) % _tables.size();// 负载因子==1 --> 扩容if(_n == _tables.size()){vector<Node*> newtables(_tables.size() * 2,nullptr);for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];while(cur){Node* next = cur->_next;//旧表中的节点,挪动到新表的重新映射的位置size_t hashi = hs(kot(cur->_data)) % newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}//头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}Node* Find(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while(cur){if(kot(cur->_data) == key){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while(cur){if(kot(cur->_data) == key){if(prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables;size_t _n = 0; //表中存储数据个数};
}
二.封装unordered_xxx的Insert函数
哈希表中,我们将KeyOfT套一层,即可
bool Insert(const T& data){KeyOfT kot;Hash hs;size_t hashi = hs(kot(data)) % _tables.size();// 负载因子==1 --> 扩容if(_n == _tables.size()){vector<Node*> newtables(_tables.size() * 2,nullptr);for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];while(cur){Node* next = cur->_next;//旧表中的节点,挪动到新表的重新映射的位置size_t hashi = hs(kot(cur->_data)) % newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}//头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}
"unordered_map"bool insert(const pair<K,V>& kv){return _ht.Insert(kv);}"unordered_set"bool insert(const K& key){return _ht.Insert(key);}测试:
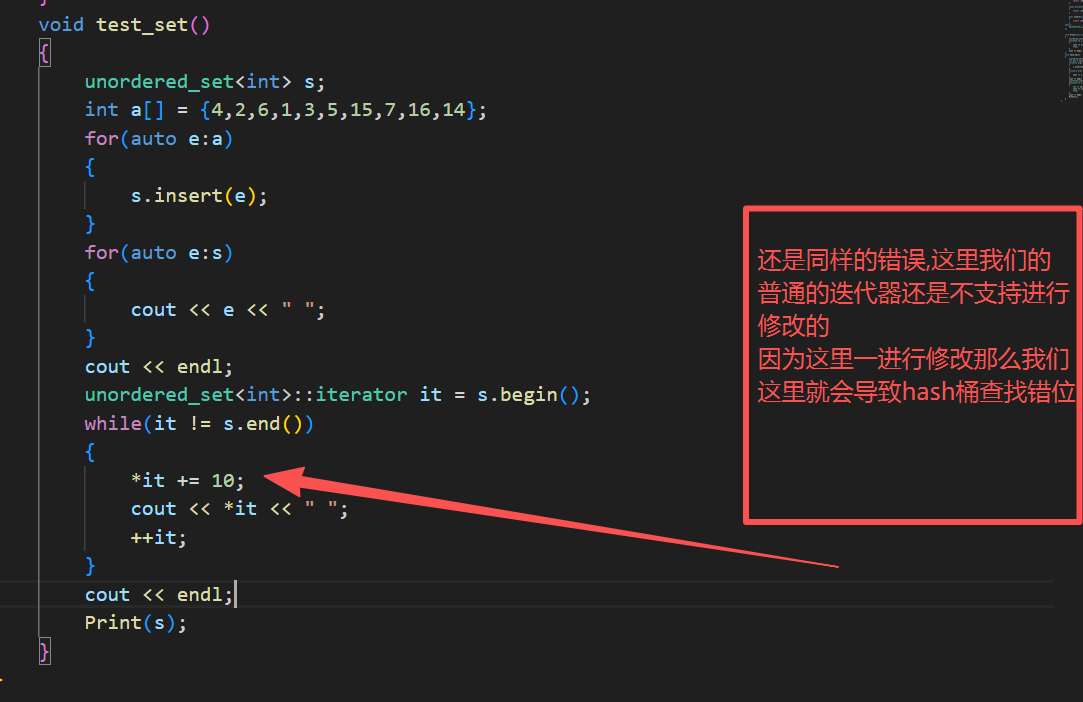
void test_set(){unordered_set<int> s;int a[] = {4,2,6,1,3,5,15,7,16,14};for(auto e:a){s.insert(e);}}这样跑完没报错,那么就基本没有问题
三.封装哈希表的迭代器
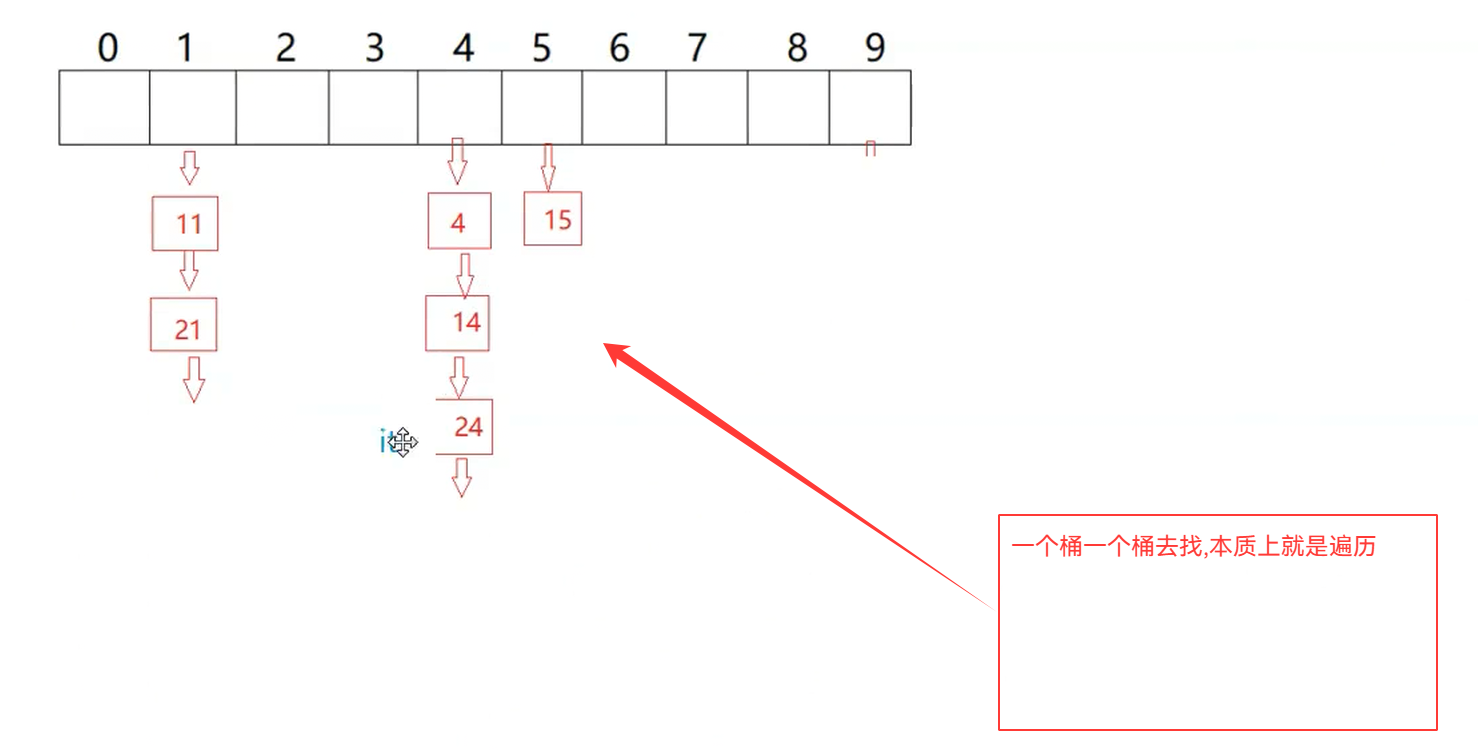
1.迭代器的基础实现
template<class K,class T,class KeyOfT,class Hash>struct HTIterator{typedef HashNode<T> Node;typedef HTIterator<K,T,KeyOfT,Hash> Self;Node* _node;HashTable<K,T,KeyOfT,Hash>* _pht;HTIterator(Node* node,HashTable<K,T,KeyOfT,Hash>* pht):_node(node),_pht(pht){}}这里我们要传入我们的这个哈希的指针,为了找下一个桶
2.operator++的实现
Self& operator++(){if(_node->_next){//当前桶还要节点_node = _node->_next;}else{//当前桶没节点了,找下一个不为空桶KeyOfT kot;Hash hs;size_t hashi = hs(kot(cur->_data)) % _pht->_tables.size();++hashi;while(hashi < _pht->_tables.size()){if(_pht->_tables[hashi]){break;}++hashi;}if(hashi == _pht->_tables.size()){_node = nullptr; //end()}else{_node = _pht->_tables[hashi];}}return *this;}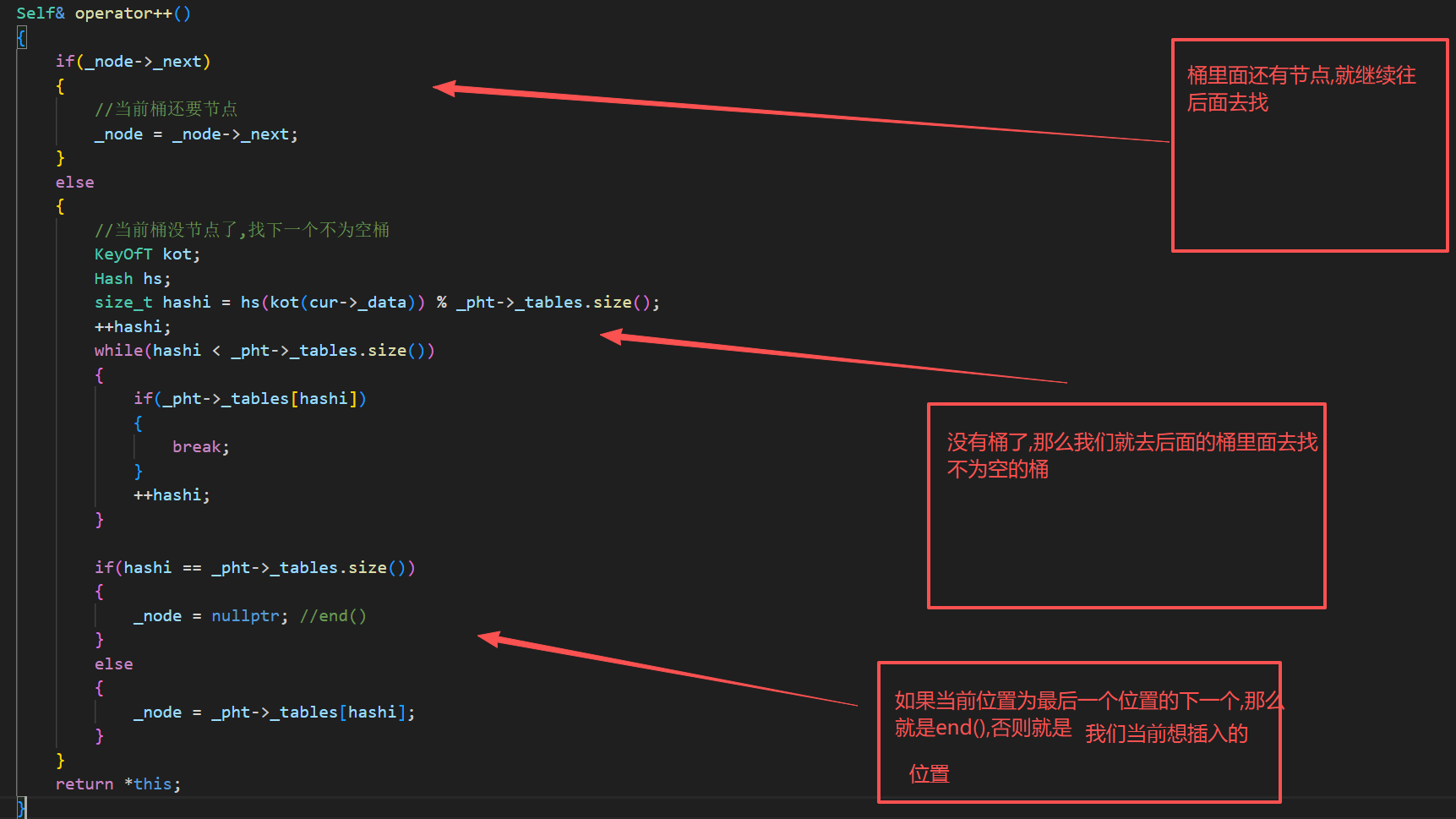
3.哈希表进行封装迭代器
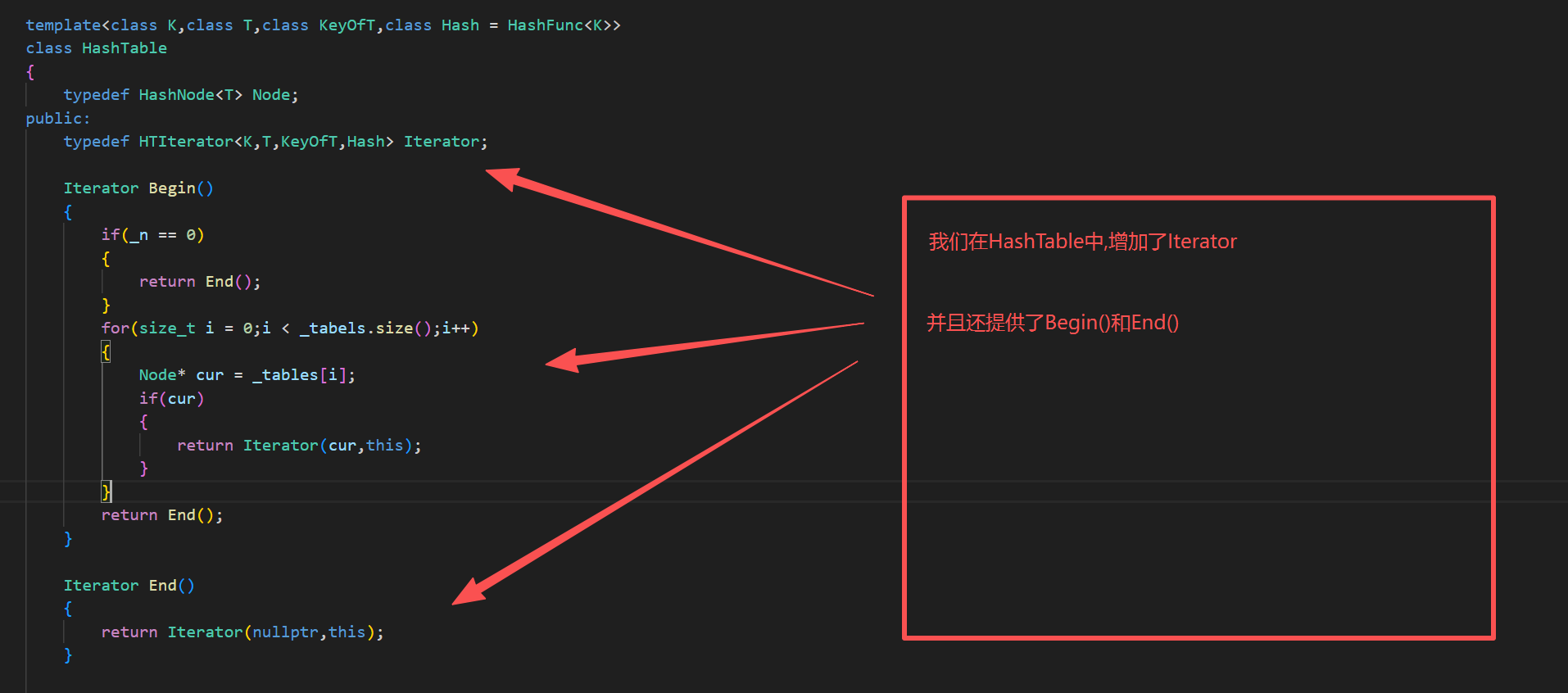
typedef HTIterator<K,T,KeyOfT,Hash> Iterator;Iterator Begin(){if(_n == 0){return End();}for(size_t i = 0;i < _tabels.size();i++){Node* cur = _tables[i];if(cur){return Iterator(cur,this);}}return End();}Iterator End(){return Iterator(nullptr,this);}4.unordered_xxx的上层封装
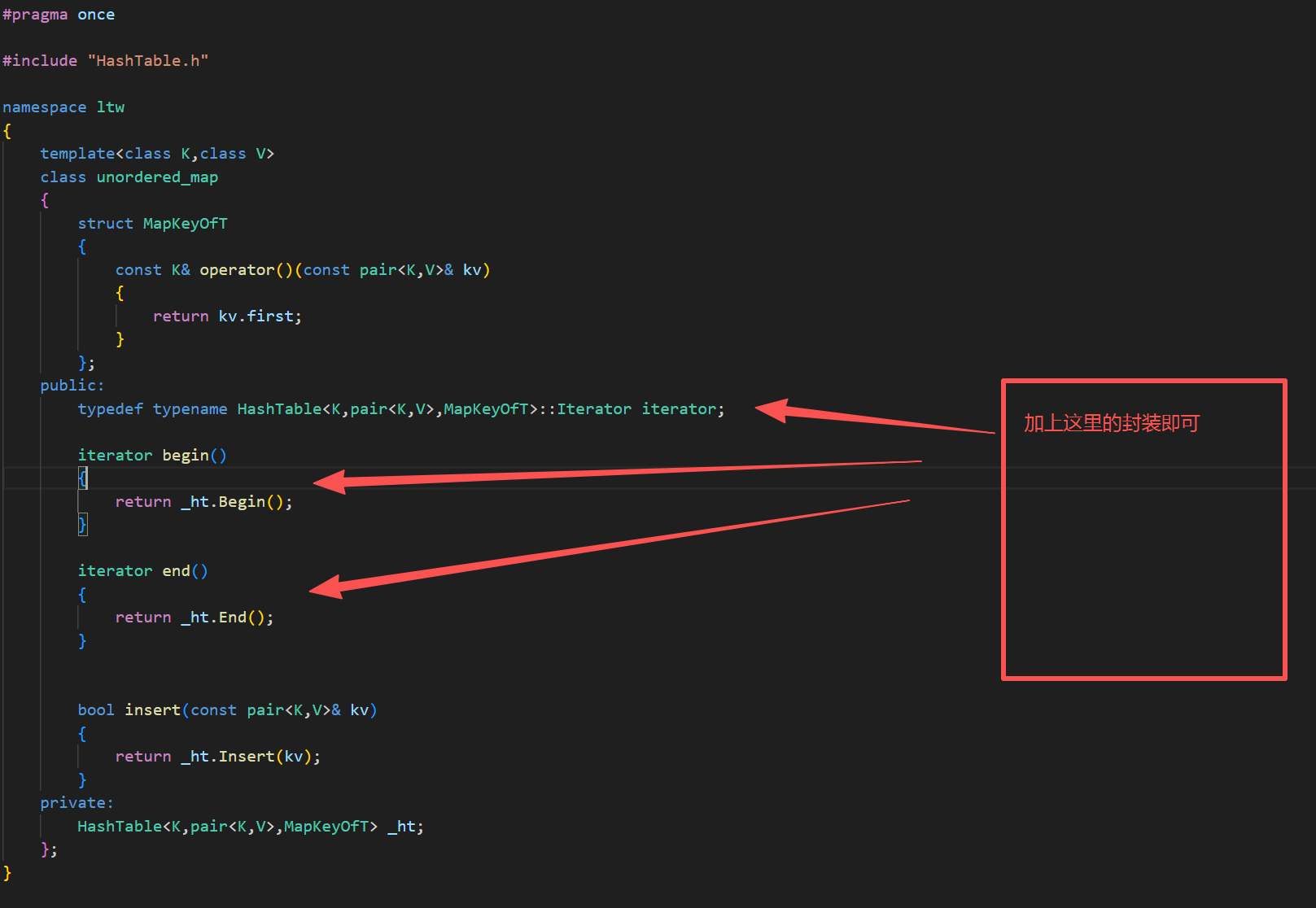
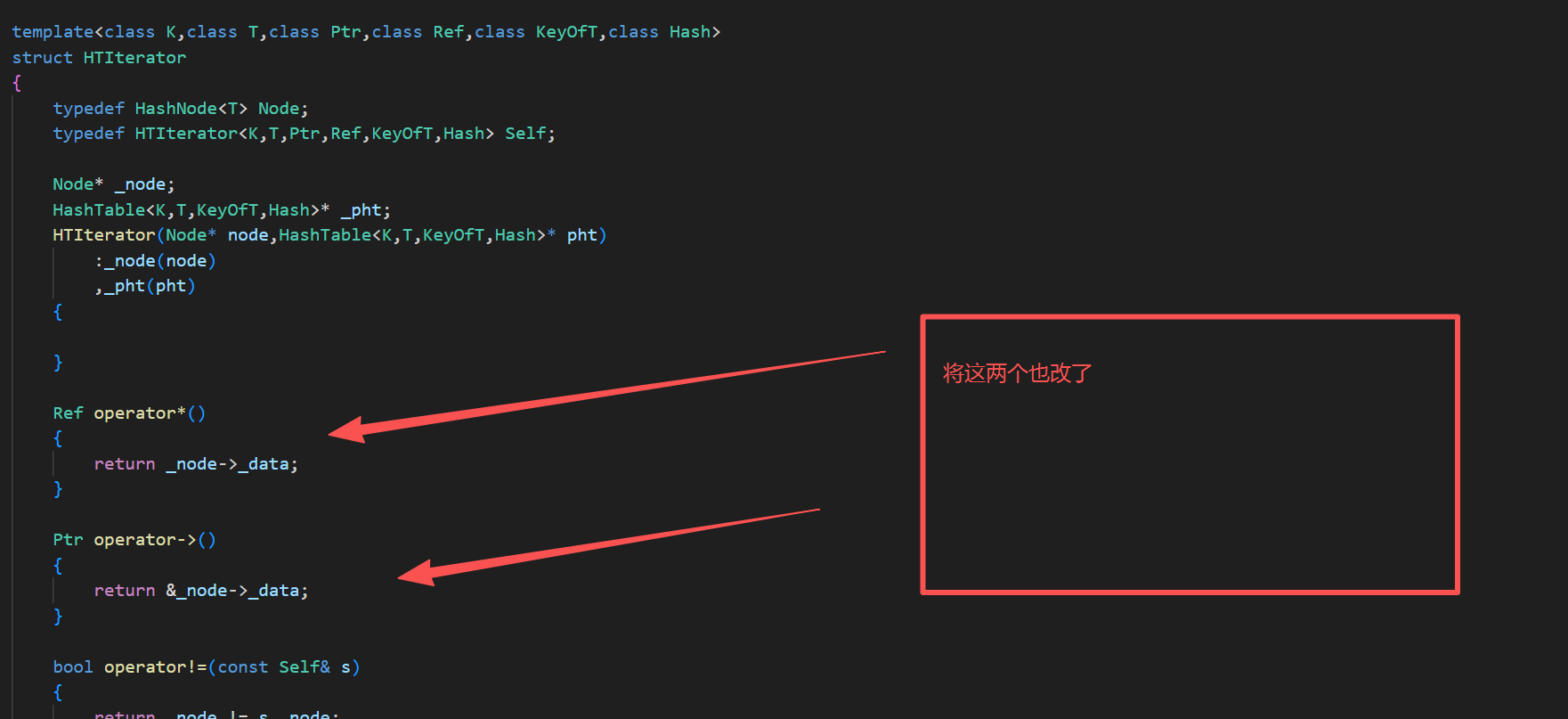
5.实现迭代器的operator->()和operator*()
T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator!=(const Self& s){return _node != s._node;}6.编译
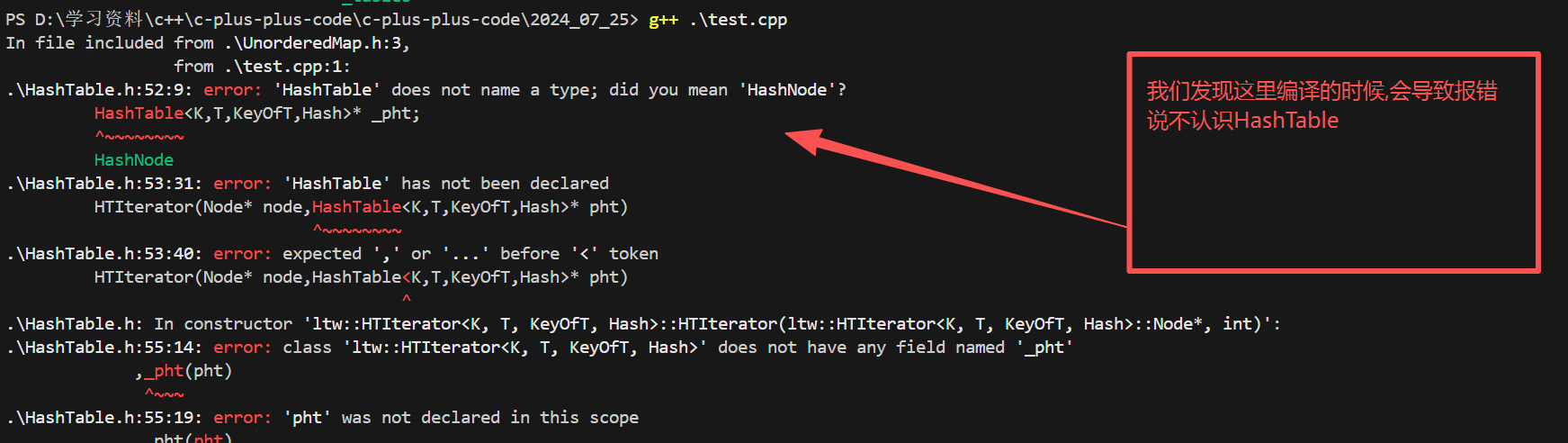
原因是我们的迭代器依赖HashTable,而HashTable又依赖迭代器,这里就产生了相互依赖
这里我们可以采取前置声明的方式进行解决:
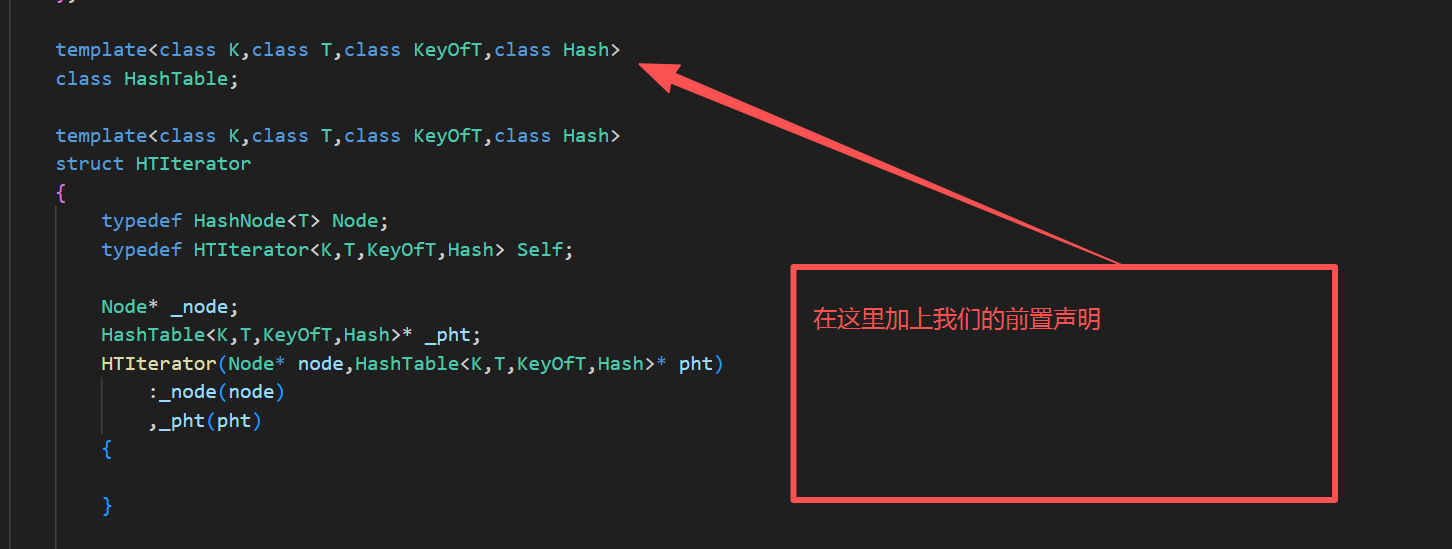
这样就能编译通过了
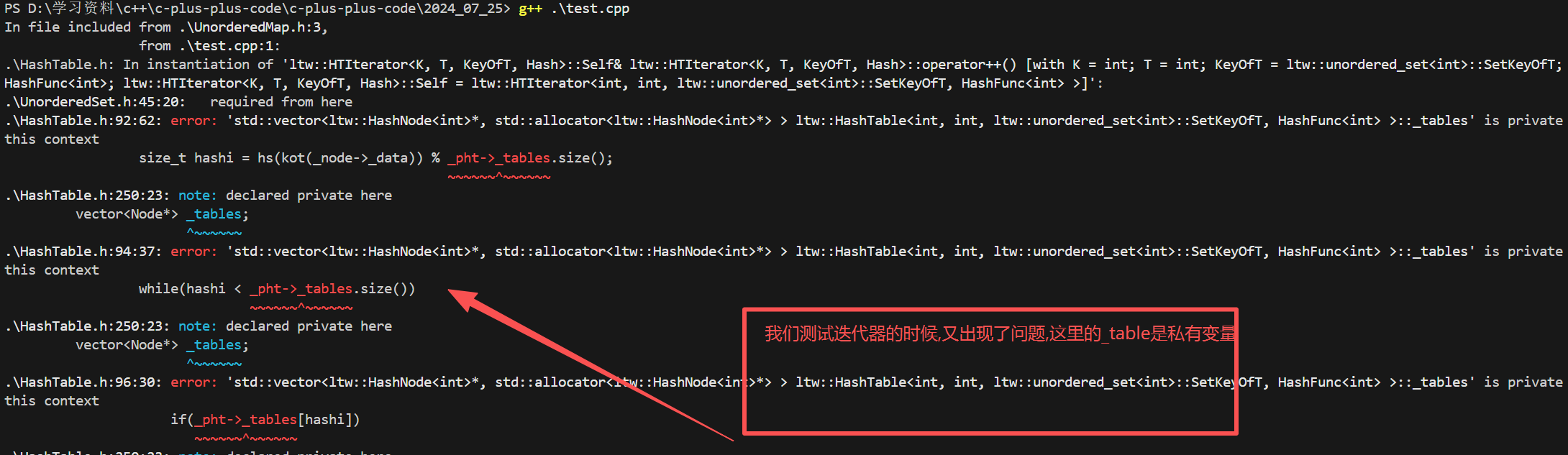
解决方式1 : 提供get_table()
解决方式2 : 在HashTable里面加上友元声明
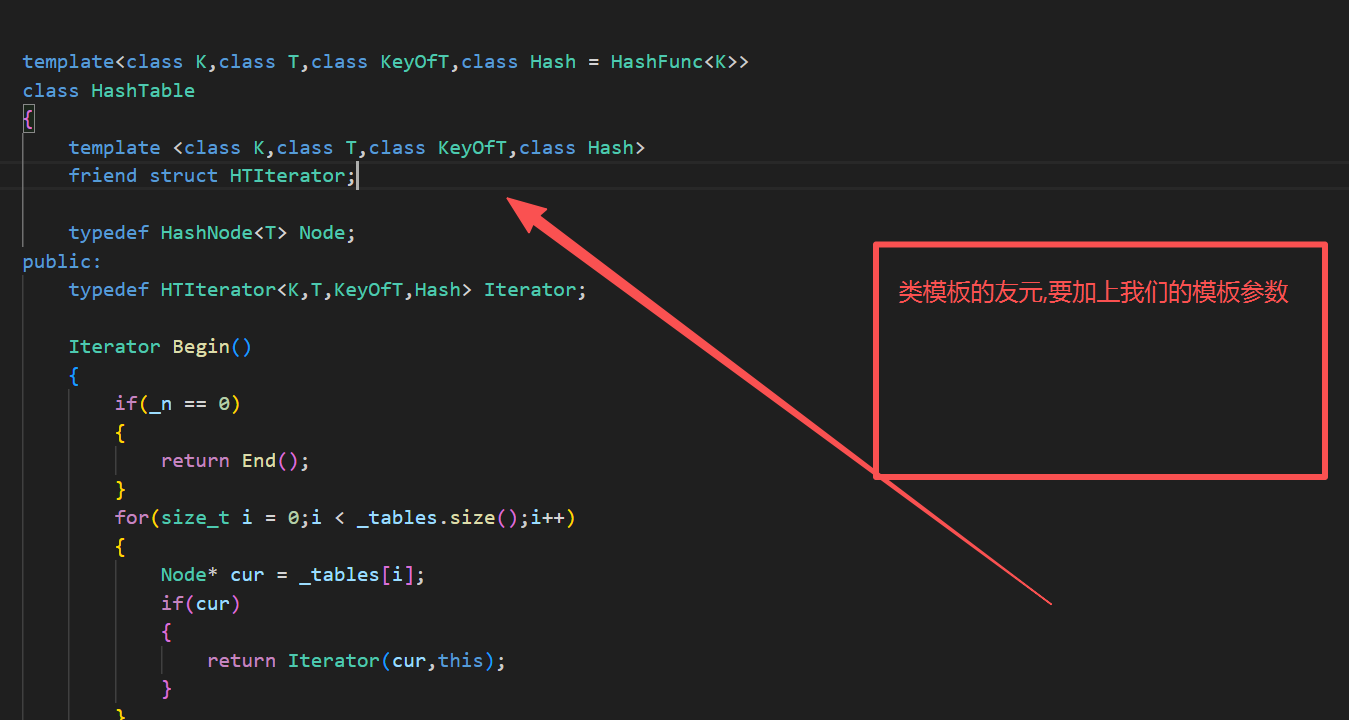
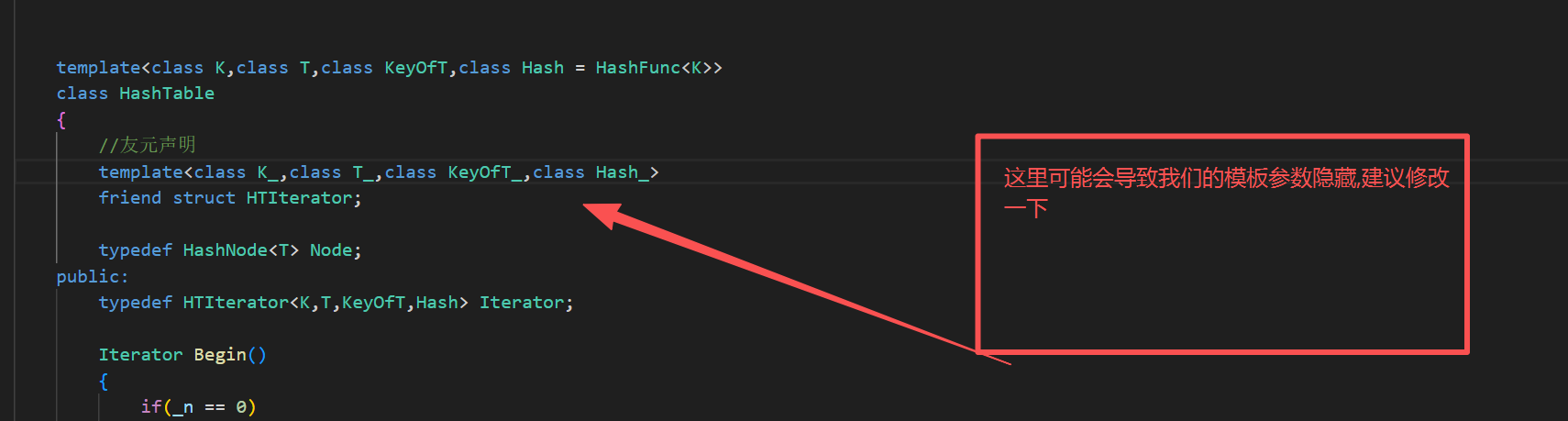

7.const迭代器的封装
和链表那个地方类似,链表博客 链接如下:
https://blog.csdn.net/weixin_60668256/article/details/153393453?fromshare=blogdetail&sharetype=blogdetail&sharerId=153393453&sharerefer=PC&sharesource=weixin_60668256&sharefrom=from_link

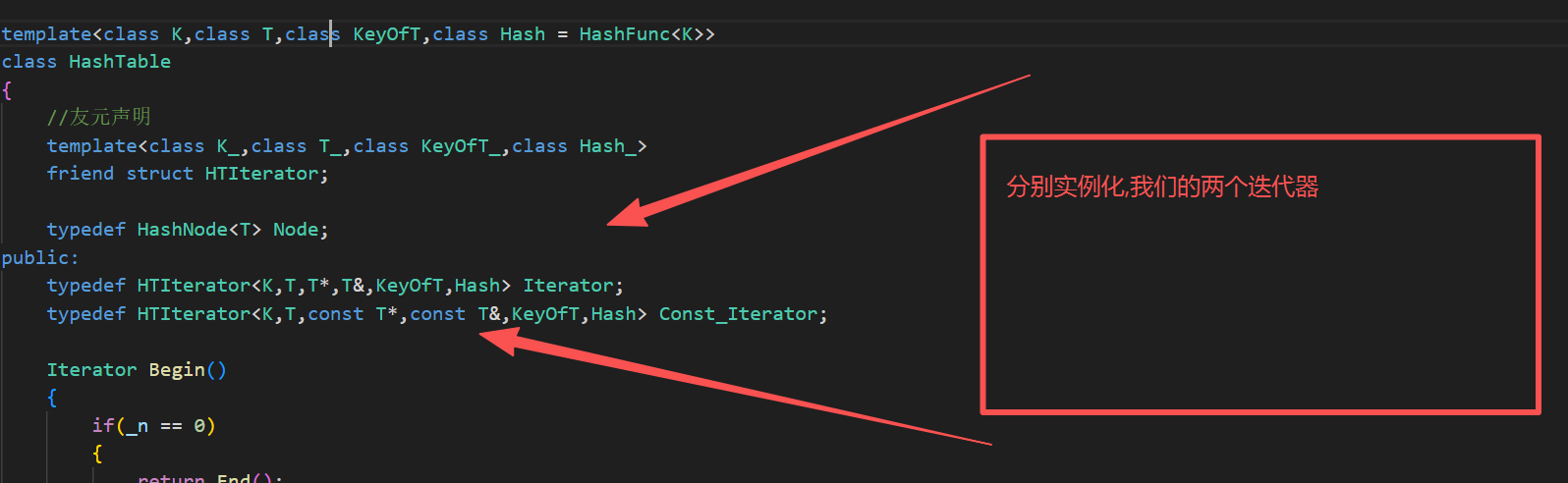
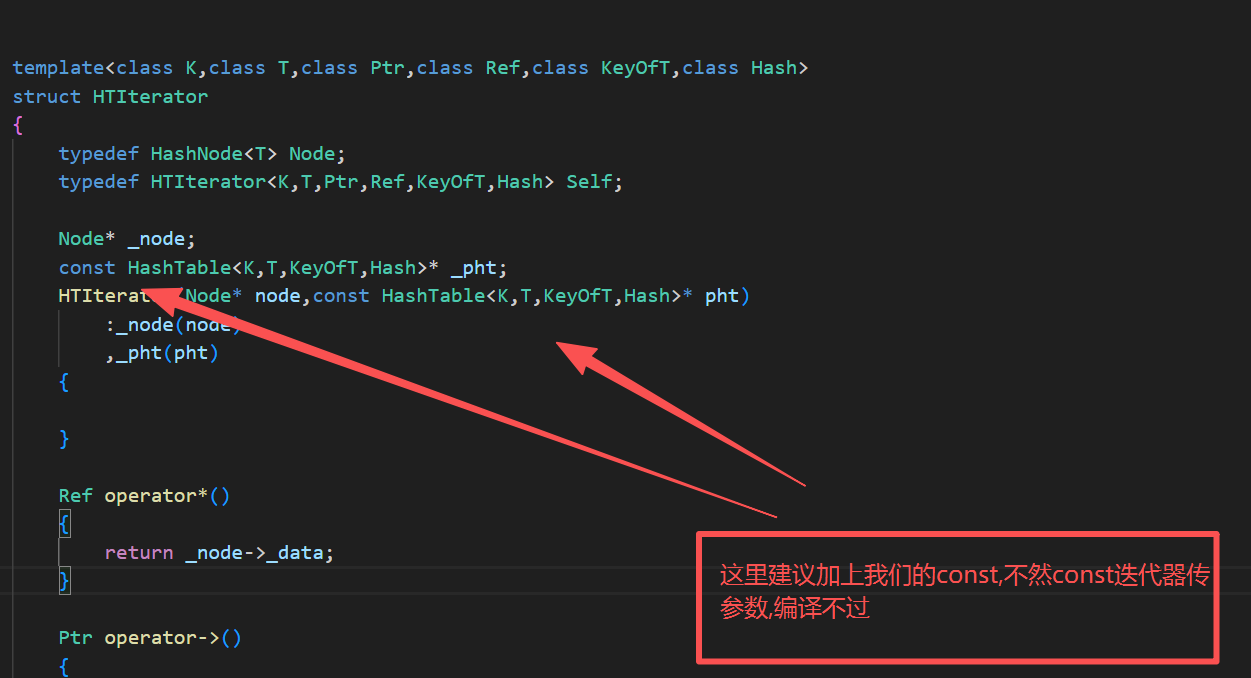
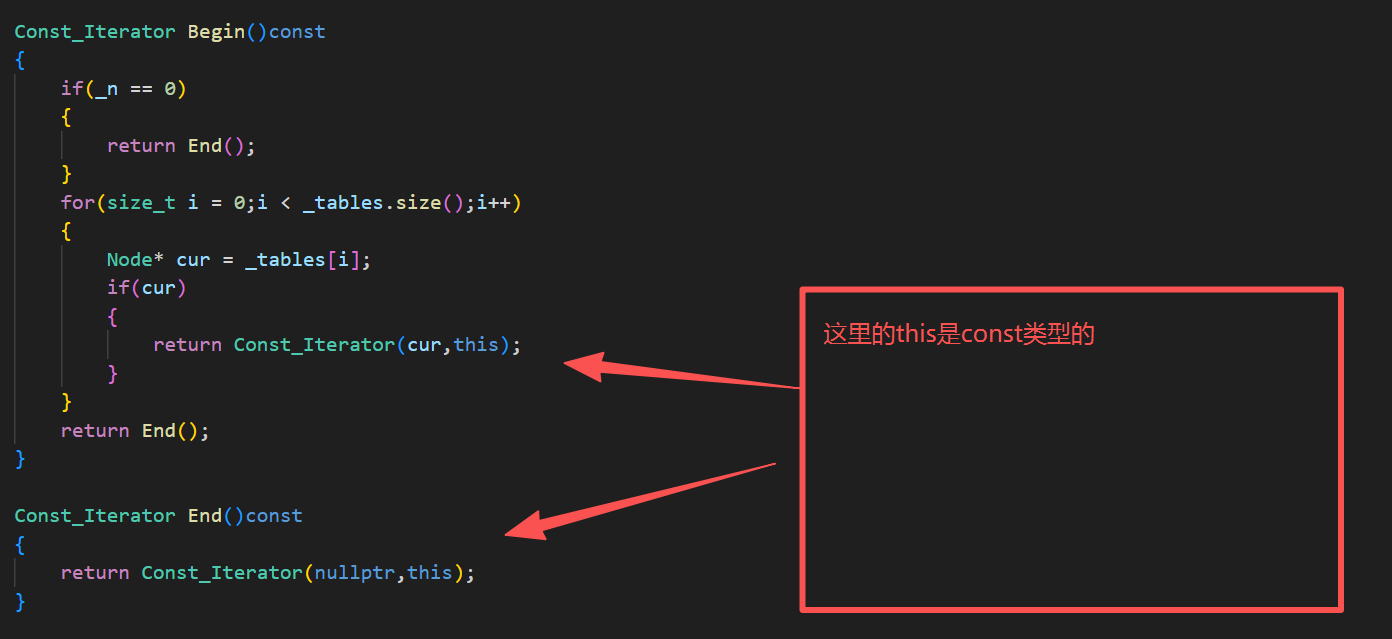
8.const的begin()和end()的封装
Const_Iterator Begin()const{if(_n == 0){return End();}for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];if(cur){return Const_Iterator(cur,this);}}return End();}Const_Iterator End()const{return Const_Iterator(nullptr,this);}
"unordered_set"#pragma once#include "HashTable.h"namespace ltw
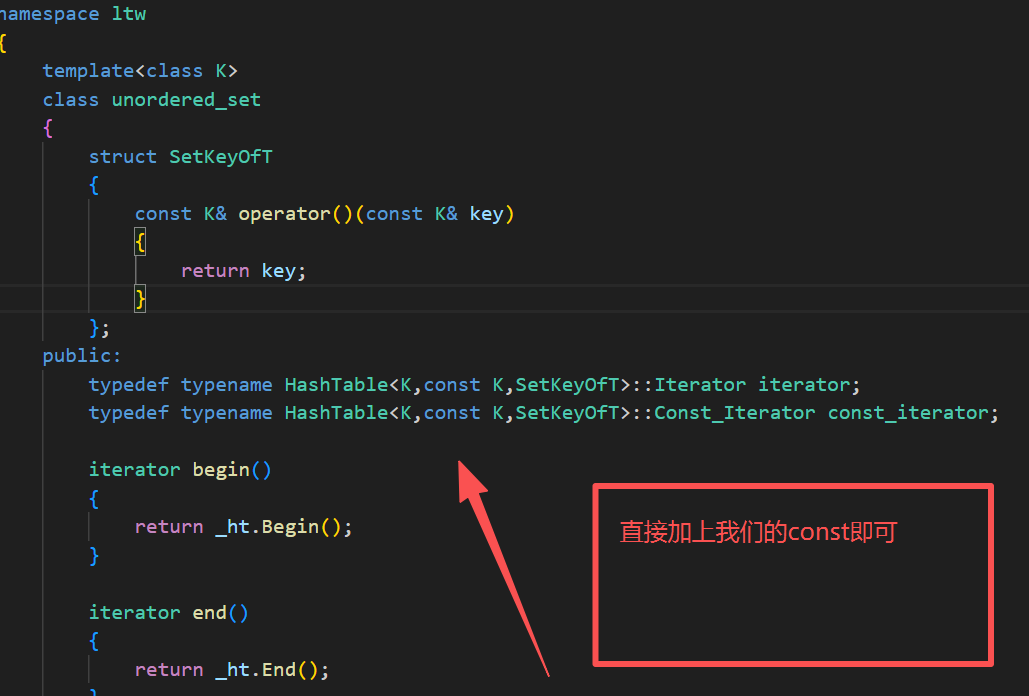
{template<class K>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename HashTable<K,const K,SetKeyOfT>::Iterator iterator;typedef typename HashTable<K,const K,SetKeyOfT>::Const_Iterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin()const{return _ht.Begin();}const_iterator end()const{return _ht.End();}bool insert(const K& key){return _ht.Insert(key);}public:HashTable<K,K,SetKeyOfT> _ht;};void Print(const unordered_set<int>& s){unordered_set<int>::const_iterator it = s.begin();while(it != s.end()){cout << *it << " ";++it;}cout << endl;}void test_set(){unordered_set<int> s;int a[] = {4,2,6,1,3,5,15,7,16,14};for(auto e:a){s.insert(e);}for(auto e:s){cout << e << " ";}cout << endl;unordered_set<int>::iterator it = s.begin();while(it != s.end()){// *it += 10;cout << *it << " ";++it;}cout << endl;Print(s);}
}四.将unordered_map搭建出来
#pragma once#include "HashTable.h"namespace ltw
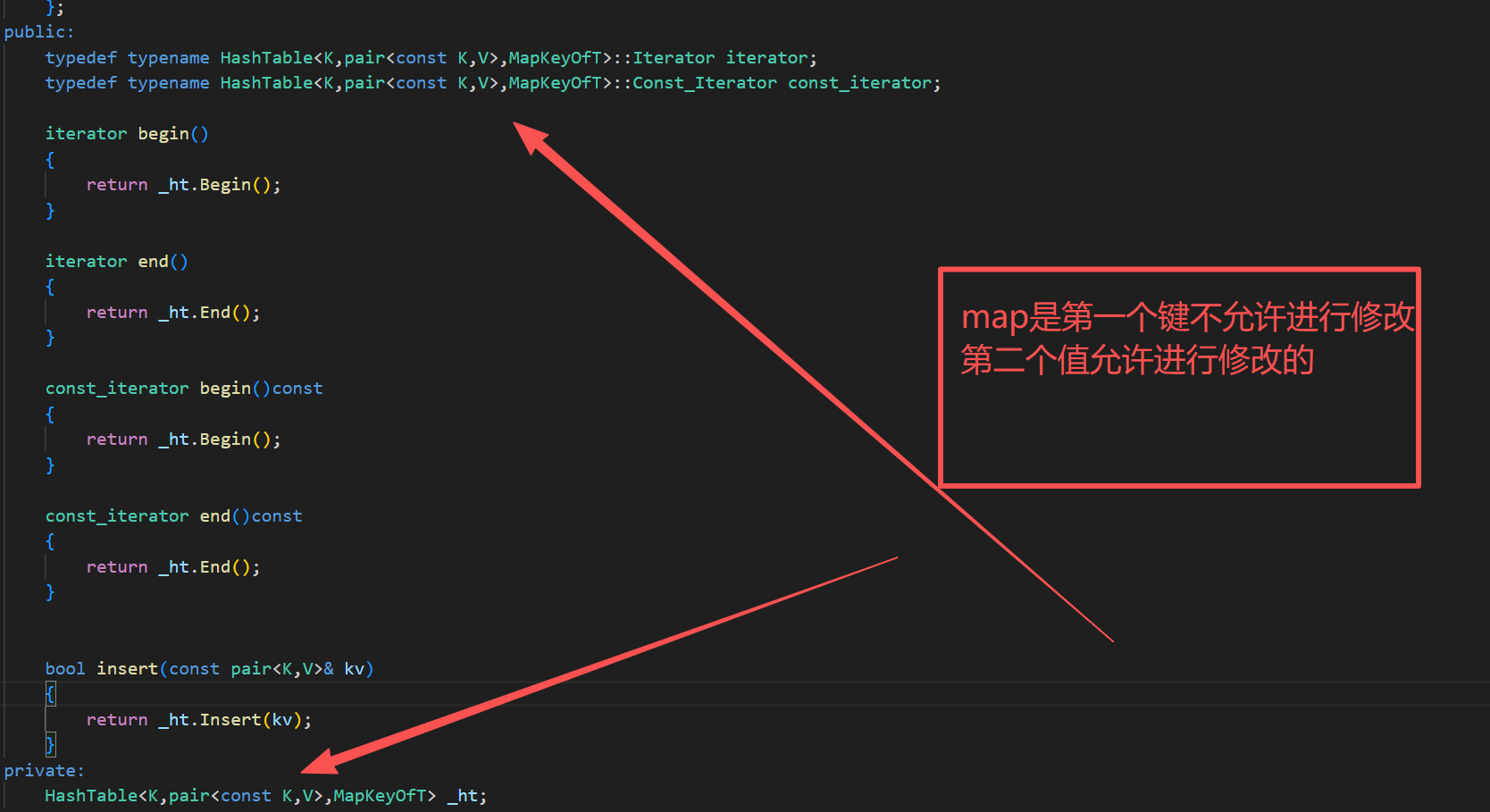
{template<class K,class V>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K,V>& kv){return kv.first;}};public:typedef typename HashTable<K,pair<K,V>,MapKeyOfT>::Iterator iterator;typedef typename HashTable<K,pair<K,V>,MapKeyOfT>::Const_Iterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin()const{return _ht.Begin();}const_iterator end()const{return _ht.End();}bool insert(const pair<K,V>& kv){return _ht.Insert(kv);}private:HashTable<K,pair<K,V>,MapKeyOfT> _ht;};void test_map(){unordered_map<string, string> dict;dict.insert({ "sort", "haha_rsort" });dict.insert({ "left", "haha_left" });dict.insert({ "right", "haha_right" });// dict["left"] = "左边,剩余";// dict["insert"] = "插入";// dict["string"];unordered_map<string, string>::iterator it = dict.begin();while (it != dict.end()){// 不能修改first,可以修改second//it->first += 'x';// it->second += 'x';cout << it->first << ":" << it->second << endl;++it;}cout << endl;}
}
1.Find()的实现
Iterator Find(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while(cur){if(kot(cur->_data) == key){return Iterator(cur,this);}cur = cur->_next;}return End();}2.Insert()的实现
这里,我们在插入的时候,要加上我们的查重
bool Insert(const T& data){KeyOfT kot;if(Find(kot(data)) != End()){return false;}Hash hs;size_t hashi = hs(kot(data)) % _tables.size();// 负载因子==1 --> 扩容if(_n == _tables.size()){vector<Node*> newtables(_tables.size() * 2,nullptr);for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];while(cur){Node* next = cur->_next;//旧表中的节点,挪动到新表的重新映射的位置size_t hashi = hs(kot(cur->_data)) % newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}//头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}3.operator[]的实现
实现operator[]的时候,要修改我们的Insert()
pair<Iterator,bool> Insert(const T& data){KeyOfT kot;Iterator it = Find(kot(data));if(it != End()){return {it,false};}Hash hs;size_t hashi = hs(kot(data)) % _tables.size();// 负载因子==1 --> 扩容if(_n == _tables.size()){vector<Node*> newtables(_tables.size() * 2,nullptr);for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];while(cur){Node* next = cur->_next;//旧表中的节点,挪动到新表的重新映射的位置size_t hashi = hs(kot(cur->_data)) % newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}//头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return {Iterator(newnode,this),true};}将返回值变成我们的pair类型
operator[]重载实现:
1.如果插入成功,那么说明原来不在,插入的就是默认的V()的构造
2.插入失败,说明原来是存在的,那么就返回原来的值
V& operator[](const K& key){pair<iterator,bool> ret = _ht.Insert({key,V()});return ret.first->second;}测试代码:
void test_map(){unordered_map<string, string> dict;dict.insert({ "sort", "haha_rsort" });dict.insert({ "left", "haha_left" });dict.insert({ "right", "haha_right" });dict["left"] = "left,last";dict["insert"] = "insert_ahah";dict["string"];unordered_map<string, string>::iterator it = dict.begin();while (it != dict.end()){// 不能修改first,可以修改second//it->first += 'x';// it->second += 'x';cout << it->first << ":" << it->second << endl;++it;}cout << endl;}
4.自定义类型操作

我们需要进行,自己传入我们的模板参数
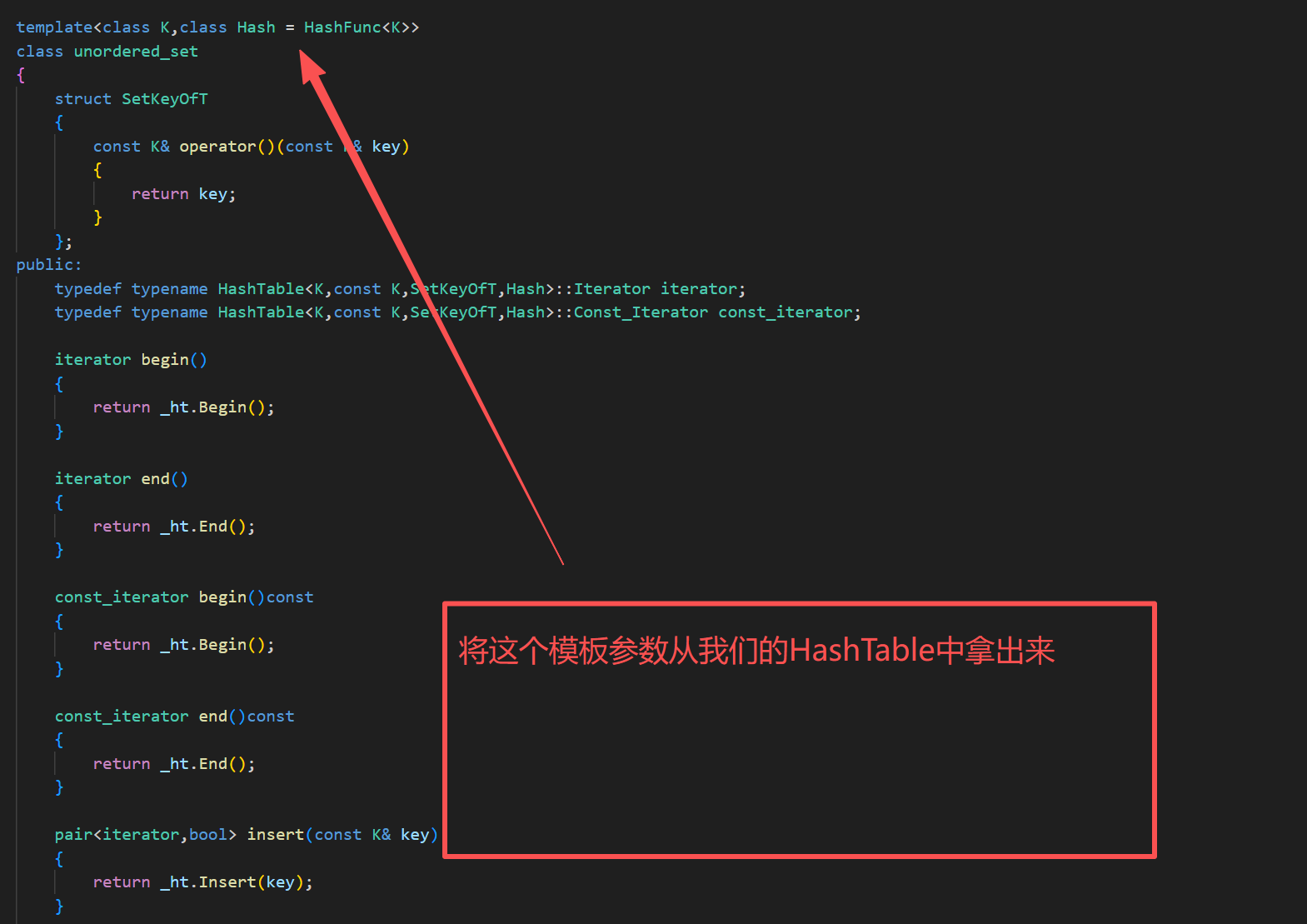
struct Date{int _year;int _month;int _day;};struct HashDate{size_t operator()(const Date& key){return (key._year * 31 + key._month) * 31 + key._day;}};void test_set_1(){unordered_set<Date,HashDate> us;us.insert({2024,7,25});}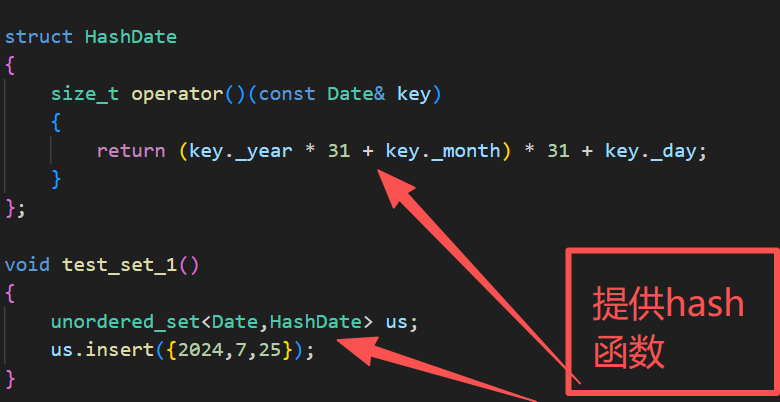

我们还要重载一个等于
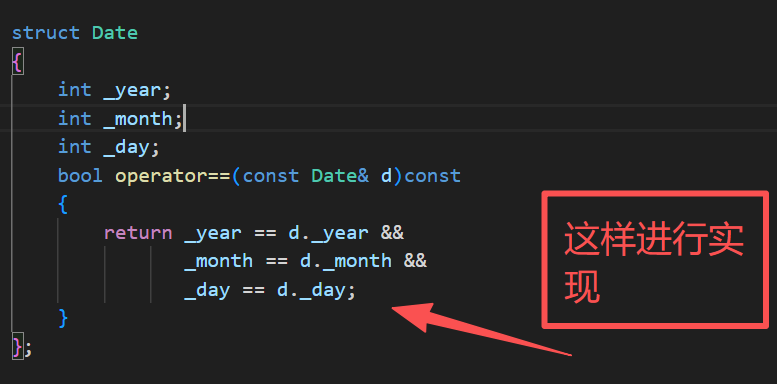
五.补充说明
void test_set1()
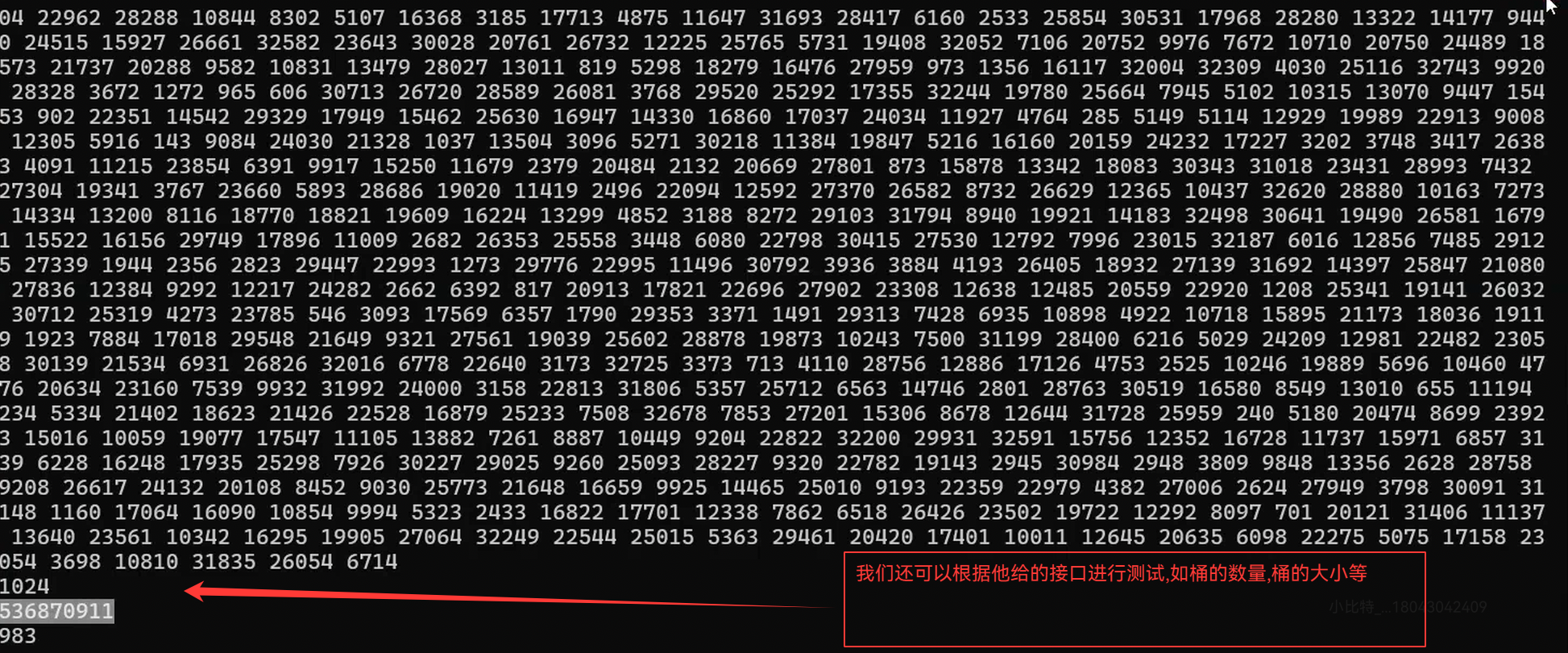
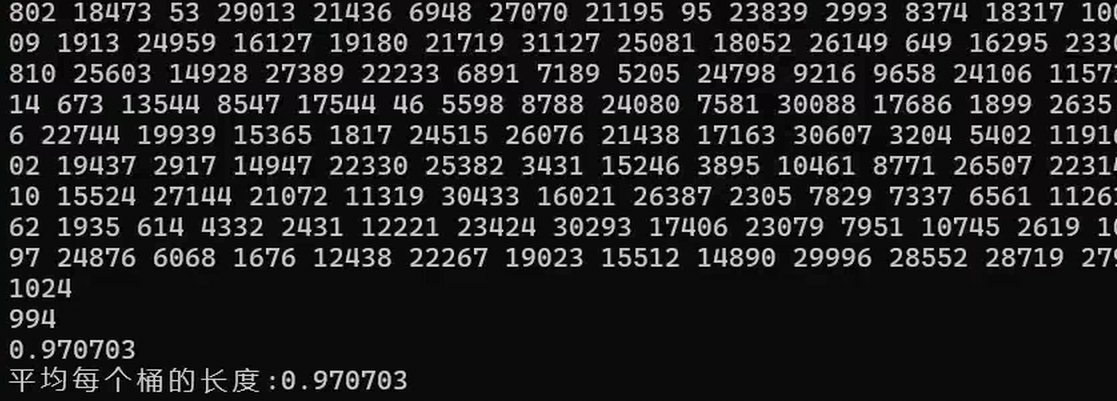
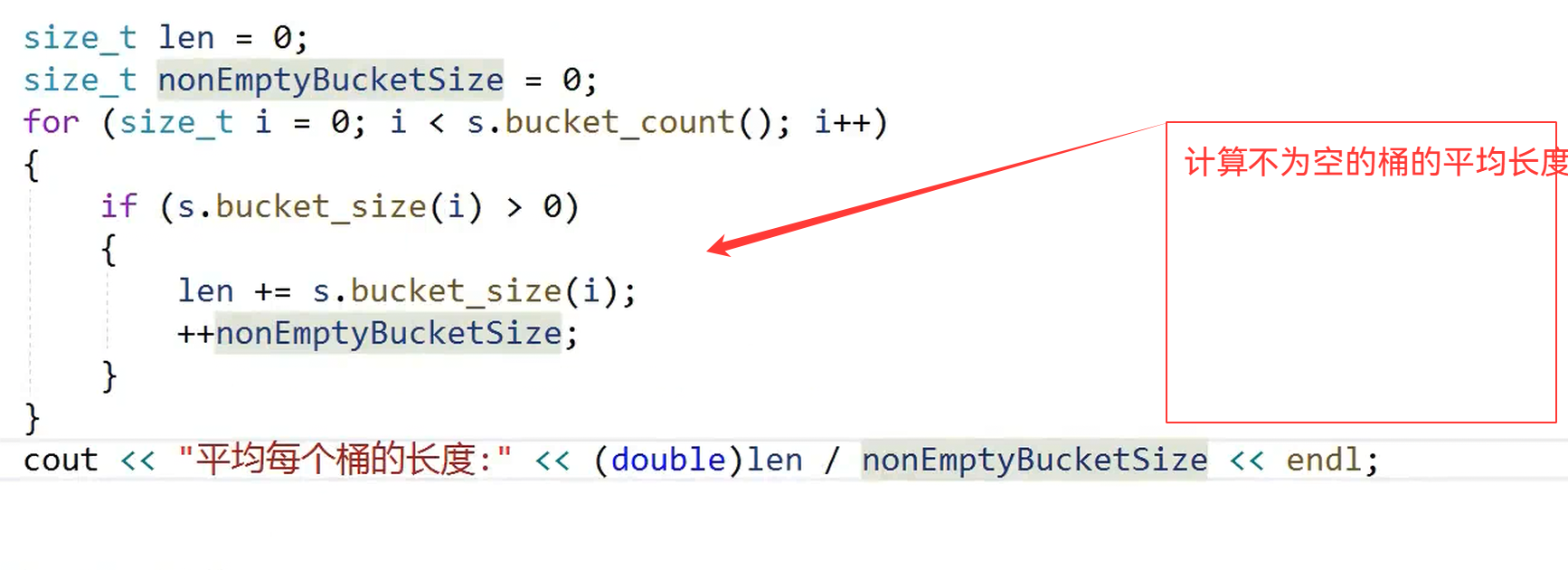
{unordered_set<int> s = { 3,1,6,7,8,2 };/*unordered_set<int>::iterator it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;*/srand(time(0));for (size_t i = 0; i < 1000; ++i){s.insert(rand()); // N比较大时,重复值比较多//v.push_back(rand()+i); // 重复值相对少//v.push_back(i); // 没有重复,有序}/*for (auto e : s){cout << e << " ";}cout << endl;*/cout << s.bucket_count() << endl;//cout << s.max_bucket_count() << endl;cout << s.size() << endl;cout <<"负载因子:" << s.load_factor() << endl;cout <<"最大负载因子:" << s.max_load_factor() << endl;size_t len = 0;size_t nonEmptyBucketSize = 0;size_t maxLen = 0;for (size_t i = 0; i < s.bucket_count(); i++){if (s.bucket_size(i) > 0){if (s.bucket_size(i) > maxLen)maxLen = s.bucket_size(i);len += s.bucket_size(i);++nonEmptyBucketSize;}}cout << "平均每个桶的长度:" << (double)len / nonEmptyBucketSize << endl;cout << "最大的桶的长度:" << maxLen << endl;
}
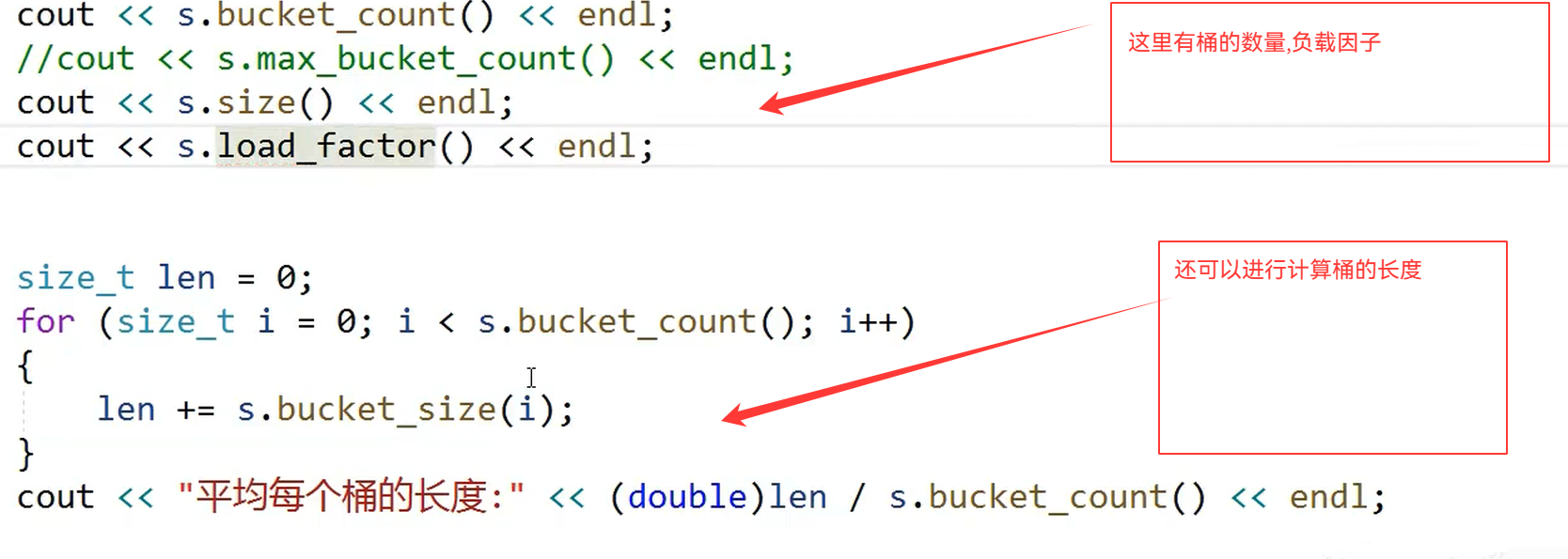
![]()

const size_t N = 1000000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); // N比较大时,重复值比较多v.push_back(rand()+i); // 重复值相对少//v.push_back(i); // 没有重复,有序}// 21:15size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();us.reserve(N);for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;int m1 = 0;size_t begin3 = clock();for (auto e : v){auto ret = s.find(e);if (ret != s.end()){++m1;}}size_t end3 = clock();cout << "set find:" << end3 - begin3 << "->" << m1 << endl;int m2 = 0;size_t begin4 = clock();for (auto e : v){auto ret = us.find(e);if (ret != us.end()){++m2;}}size_t end4 = clock();cout << "unorered_set find:" << end4 - begin4 << "->" << m2 << endl;cout << "插入数据个数:" << s.size() << endl;cout << "插入数据个数:" << us.size() << endl << endl;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;return 0;
}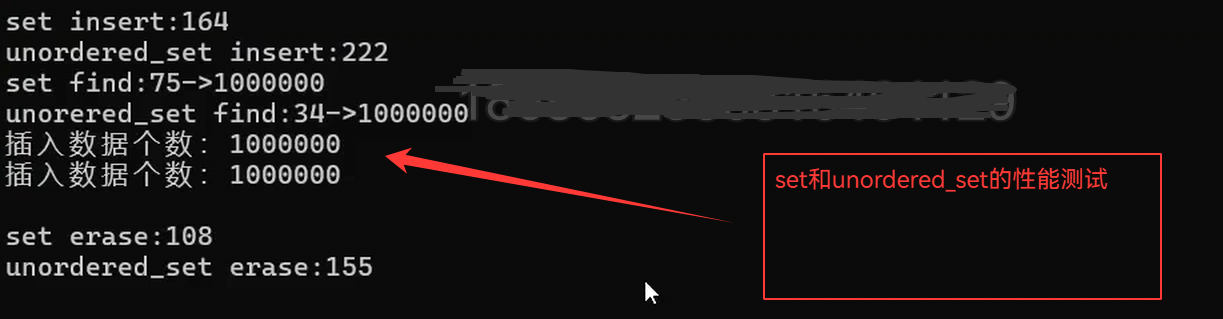
unordered_map和unordered_set大部分情况下,比map和set要更快
六.unordered_map全部代码
#pragma once#include "HashTable.h"namespace ltw
{template<class K,class Hash = HashFunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename HashTable<K,const K,SetKeyOfT,Hash>::Iterator iterator;typedef typename HashTable<K,const K,SetKeyOfT,Hash>::Const_Iterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin()const{return _ht.Begin();}const_iterator end()const{return _ht.End();}pair<iterator,bool> insert(const K& key){return _ht.Insert(key);}iterator Find(const K& key){return _ht.Find(key);}bool Erase(const K& key){return _ht.Erase(key);}public:HashTable<K,const K,SetKeyOfT,Hash> _ht;};void Print(const unordered_set<int>& s){unordered_set<int>::const_iterator it = s.begin();while(it != s.end()){cout << *it << " ";++it;}cout << endl;}void test_set(){unordered_set<int> s;int a[] = {4,2,6,1,3,5,15,7,16,14};for(auto e:a){s.insert(e);}for(auto e:s){cout << e << " ";}cout << endl;unordered_set<int>::iterator it = s.begin();while(it != s.end()){// *it += 10;cout << *it << " ";++it;}cout << endl;// Print(s);}struct Date{int _year;int _month;int _day;bool operator==(const Date& d)const{return _year == d._year && _month == d._month && _day == d._day;}};struct HashDate{size_t operator()(const Date& key){return (key._year * 31 + key._month) * 31 + key._day;}};void test_set_1(){unordered_set<Date,HashDate> us;us.insert({2024,7,25});}
}七.unordered_set全部代码
#pragma once#include "HashTable.h"namespace ltw
{template<class K,class V,class Hash = HashFunc<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K,V>& kv){return kv.first;}};public:typedef typename HashTable<K,pair<const K,V>,MapKeyOfT,Hash>::Iterator iterator;typedef typename HashTable<K,pair<const K,V>,MapKeyOfT,Hash>::Const_Iterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin()const{return _ht.Begin();}const_iterator end()const{return _ht.End();}pair<iterator,bool> insert(const pair<K,V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){pair<iterator,bool> ret = _ht.Insert({key,V()});return ret.first->second;}iterator Find(const K& key){return _ht.Find(key);}bool Erase(const K& key){return _ht.Erase(key);}private:HashTable<K,pair<const K,V>,MapKeyOfT,Hash> _ht;};void test_map(){unordered_map<string, string> dict;dict.insert({ "sort", "haha_rsort" });dict.insert({ "left", "haha_left" });dict.insert({ "right", "haha_right" });dict["left"] = "left,last";dict["insert"] = "insert_ahah";dict["string"];unordered_map<string, string>::iterator it = dict.begin();while (it != dict.end()){// 不能修改first,可以修改second//it->first += 'x';// it->second += 'x';cout << it->first << ":" << it->second << endl;++it;}cout << endl;}
}八.HashTable全部代码
#pragma once
#include <iostream>
#include <vector>using namespace std;
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};template <>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hashi = 0;for(auto e : s){hashi *= 31;hashi += e;}return hashi;}
};namespace ltw
{template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data),_next(nullptr){}};//前置声明template<class K,class T,class KeyOfT,class Hash>class HashTable;template<class K,class T,class Ptr,class Ref,class KeyOfT,class Hash>struct HTIterator{typedef HashNode<T> Node;typedef HTIterator<K,T,Ptr,Ref,KeyOfT,Hash> Self;Node* _node;const HashTable<K,T,KeyOfT,Hash>* _pht;HTIterator(Node* node,const HashTable<K,T,KeyOfT,Hash>* pht):_node(node),_pht(pht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self& s){return _node != s._node;}Self& operator++(){if(_node->_next){//当前桶还要节点_node = _node->_next;}else{//当前桶没节点了,找下一个不为空桶KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _pht->_tables.size();++hashi;while(hashi < _pht->_tables.size()){if(_pht->_tables[hashi]){break;}++hashi;}if(hashi == _pht->_tables.size()){_node = nullptr; //end()}else{_node = _pht->_tables[hashi];}}return *this;}};// 1、实现哈希表// 2、封装unordered_map和unordered_set 解决KeyOfT// 3、iterator// 4、const_iterator// 5、修改key的问题// 6、operator[]template<class K,class T,class KeyOfT,class Hash>class HashTable{//友元声明template<class K_,class T_,class Ptr,class Ref,class KeyOfT_,class Hash_>friend struct HTIterator;typedef HashNode<T> Node;public:typedef HTIterator<K,T,T*,T&,KeyOfT,Hash> Iterator;typedef HTIterator<K,T,const T*,const T&,KeyOfT,Hash> Const_Iterator;Iterator Begin(){if(_n == 0){return End();}for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];if(cur){return Iterator(cur,this);}}return End();}Iterator End(){return Iterator(nullptr,this);}Const_Iterator Begin()const{if(_n == 0){return End();}for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];if(cur){return Const_Iterator(cur,this);}}return End();}Const_Iterator End()const{return Const_Iterator(nullptr,this);}HashTable(){_tables.resize(10,nullptr);}~HashTable(){//只要把我们的_tables下的链表释放掉for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];while(cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}pair<Iterator,bool> Insert(const T& data){KeyOfT kot;Iterator it = Find(kot(data));if(it != End()){return {it,false};}Hash hs;size_t hashi = hs(kot(data)) % _tables.size();// 负载因子==1 --> 扩容if(_n == _tables.size()){vector<Node*> newtables(_tables.size() * 2,nullptr);for(size_t i = 0;i < _tables.size();i++){Node* cur = _tables[i];while(cur){Node* next = cur->_next;//旧表中的节点,挪动到新表的重新映射的位置size_t hashi = hs(kot(cur->_data)) % newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}//头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return {Iterator(newnode,this),true};}Iterator Find(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while(cur){if(kot(cur->_data) == key){return Iterator(cur,this);}cur = cur->_next;}return End();}bool Erase(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while(cur){if(kot(cur->_data) == key){if(prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables;size_t _n = 0; //表中存储数据个数};
}
代码链接:
c++代码: c++代码......