MySQL(四) - 数据查询操作
文章目录
- 一、准备数据
- 1. 重新创建之前的三个表
- 2. 分别向三个表中插入数据
- 二、查询语法、运算符和函数
- 1. 语法及解释
- 2. 条件查询运算符
- 3. 函数
- 三、数据查询
- 1. 简单查询
- 1.1 查询表中全部数据
- 1.2 查询表中指定字段的数据
- 1.3 查询表中指定字段的数据并起别名
- 1.4 查询表中指定字段不重复的数据
- 1.5 查询表中前10条数据
- 2. 条件查询
- 2.1 比较运算符查询
- 2.1.1 查询表中分数大于90的数据
- 2.1.1 查询表中选课无效的数据
- 2.2 范围运算符查询
- 2.2.1 查询表中分数大于等于80且小于等于90的数据
- 2.2.2 查询表中分数不是大于等于80且小于等于90的数据
- 2.3 空值判断运算符查询
- 2.3.1 查询表中分数为空的数据
- 2.3.2 查询表中分数不为空的数据
- 2.4 逻辑运算符查询
- 2.4.1 查询表中分数大于等于80且小于等于90的数据
- 2.4.2 查询表中专业是数学或计科的数据
- 2.4.3 查询表中专业不是数学或计科的数据
- 2.5 集合运算符查询
- 2.5.1 查询表中专业是数学或计科的数据
- 2.5.2 查询表中专业不是数学或计科的数据
- 2.6 模式匹配运算符查询
- 2.6.1 查询表中姓吴的同学的数据
- 2.6.2 查询表中姓名包含娟字的同学的数据
- 2.6.3 查询表中专业为两个字且第二个字为学的数据
- 3. 函数查询
- 3.1 聚合函数查询
- 3.1.1 查询表中的最高分和最低分
- 3.1.2 查询指定学生的总分和平均分
- 3.1.3 查询指定学生所选课程数
- 3.1.4 查询指定表数据量
- 4. 分组、排序和限制查询
- 4.1 查询每个专业的学生人数
- 4.2 查询每个专业的学生人数并筛选
- 4.3 按学号升序查询
- 4.4 按学号降序查询
- 4.5 按学号升序查询并限制返回20条数据
一、准备数据
1. 重新创建之前的三个表
该部分代码用于在test001数据库中重新创建学生表(student)、课程表(course)和学生课程关系表(student_course),并为各表设置了主键、唯一约束、外键约束及检查约束等,确保数据的完整性和规范性,同时指定了存储引擎、字符集等表属性。
-- 创建数据库
CREATE DATABASE IF NOT EXISTS test001;
-- 切换数据库
USE test001;
-- 删除数据表
DROP TABLE IF EXISTS student_course;
DROP TABLE IF EXISTS student;
DROP TABLE IF EXISTS course;-- 1. 学生表(主表)
CREATE TABLE IF NOT EXISTS `student` (student_id INT NOT NULL AUTO_INCREMENT COMMENT '学生ID(主键)',student_no VARCHAR(20) NOT NULL COMMENT '学号(唯一标识,如2024001)',student_name VARCHAR(50) NOT NULL COMMENT '学生姓名',gender CHAR(1) NOT NULL COMMENT '性别(男/女)',birth_date DATE NULL COMMENT '出生日期',major VARCHAR(50) NOT NULL COMMENT '所属专业',enroll_date DATE NOT NULL COMMENT '入学时间',create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',-- 列级约束PRIMARY KEY (student_id),UNIQUE KEY uk_student_no (student_no), -- 学号唯一CHECK (gender IN ('男', '女')) -- 限制性别只能是男或女
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_general_ci
AUTO_INCREMENT = 1001 -- 学生ID从1001开始
COMMENT = '学生信息表';
-- 2. 课程表(主表)
CREATE TABLE IF NOT EXISTS `course` (course_id INT NOT NULL AUTO_INCREMENT COMMENT '课程ID(主键)',course_no VARCHAR(20) NOT NULL COMMENT '课程编号(如CS101)',course_name VARCHAR(100) NOT NULL COMMENT '课程名称',credit TINYINT NOT NULL COMMENT '学分(1-6分)',teacher_name VARCHAR(50) NOT NULL COMMENT '授课教师',course_hours INT NOT NULL COMMENT '课时数',create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',-- 列级约束PRIMARY KEY (course_id),UNIQUE KEY uk_course_no (course_no), -- 课程编号唯一CHECK (credit BETWEEN 1 AND 6), -- 学分范围限制CHECK (course_hours > 0) -- 课时必须为正数
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_general_ci
AUTO_INCREMENT = 101 -- 课程ID从101开始
COMMENT = '课程信息表';
-- 3. 选课表(关系表,关联学生表和课程表)
CREATE TABLE IF NOT EXISTS `student_course` (id INT NOT NULL AUTO_INCREMENT COMMENT '选课记录ID(主键)',student_id INT NOT NULL COMMENT '学生ID(外键关联学生表)',course_id INT NOT NULL COMMENT '课程ID(外键关联课程表)',select_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '选课时间',score DECIMAL(5,2) NULL COMMENT '课程成绩(0-100分,NULL表示未考试)',is_valid TINYINT NOT NULL DEFAULT 1 COMMENT '是否有效(1-有效,0-已退课)',-- 表级约束PRIMARY KEY (id),-- 联合唯一约束:同一学生不能重复选同一门课UNIQUE KEY uk_stu_course (student_id, course_id),-- 外键约束:关联学生表CONSTRAINT fk_sc_student FOREIGN KEY (student_id)REFERENCES `student`(student_id)ON DELETE CASCADE -- 学生记录删除时,关联的选课记录自动删除ON UPDATE CASCADE, -- 学生ID更新时,选课记录同步更新-- 外键约束:关联课程表CONSTRAINT fk_sc_course FOREIGN KEY (course_id)REFERENCES `course`(course_id)ON DELETE CASCADE -- 课程记录删除时,关联的选课记录自动删除ON UPDATE CASCADE,-- 检查约束:成绩范围限制(0-100分)CONSTRAINT chk_score CHECK (score IS NULL OR (score BETWEEN 0 AND 100)),-- 检查约束:is_valid只能是0或1CONSTRAINT chk_is_valid CHECK (is_valid IN (0, 1))
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_general_ci
COMMENT = '学生选课关系表';
2. 分别向三个表中插入数据
此部分通过存储过程向上述三个表中批量插入示例数据,为后续的数据查询操作提供基础。
使用存储过程InsertStudents向student表插入 500 条学生数据,包括学号、姓名、性别、出生日期、专业、入学时间等信息,数据通过随机方式生成,模拟真实学生信息。
-- 插入 500 条学生数据
DELIMITER $$
CREATE PROCEDURE InsertStudents()
BEGINDECLARE i INT DEFAULT 1;DECLARE gender CHAR(1);DECLARE year_start DATE;DECLARE birth DATE;DECLARE major_name VARCHAR(50);-- 常见专业列表SET @majors = '计算机科学与技术,软件工程,电子信息工程,数学与应用数学,物理学,化学,生物技术,机械工程,自动化,通信工程,''土木工程,环境工程,经济学,金融学,会计学,法学,汉语言文学,英语,新闻传播学,临床医学,护理学';WHILE i <= 500 DOSET gender = IF(RAND() > 0.5, '男', '女');-- 随机入学年份:2020 - 2024SET year_start = MAKEDATE(2020 + FLOOR(RAND() * 5), 1 + FLOOR(RAND() * 365));-- 出生日期:入学时 17~23 岁SET birth = DATE_SUB(year_start, INTERVAL FLOOR(17 + RAND() * 7) YEAR);-- 随机选择专业SET major_name = ELT(CEILING(RAND() * 21), '计算机科学与技术','软件工程','电子信息工程','数学与应用数学','物理学','化学','生物技术','机械工程','自动化','通信工程','土木工程','环境工程','经济学','金融学','会计学','法学','汉语言文学','英语','新闻传播学','临床医学','护理学');INSERT INTO `student` (student_no, student_name, gender, birth_date, major, enroll_date)VALUES (CONCAT('20', LPAD(FLOOR(RAND() * 90 + 24), 2, '0'), LPAD(i, 3, '0')), -- 如 2024001CONCAT(ELT(CEILING(RAND() * 10), '张','李','王','刘','陈','杨','黄','赵','周','吴'),ELT(CEILING(RAND() * 10), '伟','芳','敏','静','勇','磊','洋','娟','强','军')),gender,birth,major_name,year_start);SET i = i + 1;END WHILE;
END$$
DELIMITER ;-- 执行并清理
CALL InsertStudents();
DROP PROCEDURE IF EXISTS InsertStudents;
使用存储过程InsertCourses向course表插入 500 条课程数据,涵盖课程编号、名称、学分、授课教师、课时数等内容,同样通过随机方式生成,模拟实际课程信息。
-- 插入 500 条课程数据
DELIMITER $$
CREATE PROCEDURE InsertCourses()
BEGINDECLARE i INT DEFAULT 1;DECLARE course_name_prefix VARCHAR(50);DECLARE teacher_name VARCHAR(50);SET @prefixes = '高等数学,线性代数,概率统计,C语言程序设计,Java编程,Python数据分析,数据结构,算法设计,操作系统,''计算机网络,数据库原理,软件工程,电路分析,模拟电子技术,数字逻辑,信号与系统,电磁场与波,自动控制原理,''大学物理,大学化学,马克思主义基本原理,中国近代史纲要,英语读写,体育健康,艺术鉴赏,心理学导论,经济学基础';WHILE i <= 500 DOSET course_name_prefix = ELT(CEILING(RAND() * 27),'高等数学','线性代数','概率统计','C语言程序设计','Java编程','Python数据分析','数据结构','算法设计','操作系统','计算机网络','数据库原理','软件工程','电路分析','模拟电子技术','数字逻辑','信号与系统','电磁场与波','自动控制原理','大学物理','大学化学','马克思主义基本原理','中国近代史纲要','英语读写','体育健康','艺术鉴赏','心理学导论','经济学基础');SET teacher_name = CONCAT(ELT(CEILING(RAND() * 10), '张','李','王','刘','陈','杨','黄','赵','周','吴'),'老师');INSERT INTO `course` (course_no, course_name, credit, teacher_name, course_hours)VALUES (CONCAT('CS', LPAD(i, 3, '0')), -- CS001, CS002...CONCAT(course_name_prefix, '(', CEILING(RAND() * 10), '期)'),CEILING(RAND() * 6), -- 1~6 学分teacher_name,CASE CEILING(RAND() * 5)WHEN 1 THEN 32WHEN 2 THEN 48WHEN 3 THEN 64WHEN 4 THEN 80ELSE 96END);SET i = i + 1;END WHILE;
END$$
DELIMITER ;-- 执行并清理
CALL InsertCourses();
DROP PROCEDURE IF EXISTS InsertCourses;
使用存储过程InsertStudentCourse向student_course表插入 500 条不重复的选课记录,包含学生 ID、课程 ID、选课时间、成绩、是否有效等信息,随机生成以模拟学生选课情况。
-- 插入 500 条不重复的选课记录
DELIMITER $$
CREATE PROCEDURE InsertStudentCourse()
BEGINDECLARE i INT DEFAULT 1;DECLARE sid INT;DECLARE cid INT;DECLARE retry_count INT DEFAULT 0;DECLARE max_retries INT DEFAULT 2000;WHILE i <= 500 DO-- 随机学生ID:1001 ~ 1500SET sid = FLOOR(1001 + RAND() * 500);-- 随机课程ID:101 ~ 600SET cid = FLOOR(101 + RAND() * 500);-- 尝试插入,跳过已存在的组合BEGINDECLARE CONTINUE HANDLER FOR 1062 BEGIN END; -- 忽略重复键错误INSERT INTO `student_course` (student_id, course_id, select_time, score, is_valid)VALUES (sid,cid,NOW() - INTERVAL FLOOR(RAND() * 365) DAY, -- 近一年内选课IF(RAND() > 0.2, ROUND(40 + RAND() * 60, 2), NULL), -- 80% 有成绩IF(RAND() > 0.1, 1, 0) -- 90% 有效,10% 已退课);-- 成功插入才计数SET i = i + 1;END;SET retry_count = retry_count + 1;IF retry_count > max_retries THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = '插入失败:可能可用的 (student_id, course_id) 组合已耗尽';END IF;END WHILE;
END$$
DELIMITER ;-- 执行并清理
CALL InsertStudentCourse();
DROP PROCEDURE IF EXISTS InsertStudentCourse;
检查数据数量是否正确,该 SQL 语句用于查询student、course和student_course三个表中的数据条数,以验证各表数据插入数量是否符合预期。
-- 检查每张表的数据量
SELECT 'student' AS table_name, COUNT(*) AS count FROM student
UNION ALL
SELECT 'course' AS table_name, COUNT(*) AS count FROM course
UNION ALL
SELECT 'student_course' AS table_name, COUNT(*) AS count FROM student_course;
二、查询语法、运算符和函数
1. 语法及解释
该部分详细拆解 MySQL 基础查询语句的完整结构,对 SELECT 到 LIMIT 的每个子句进行定义,明确各子句的必填 / 可选属性、核心功能及使用规则,同时标注关键注意事项(如 WHERE 子句使用函数对索引的影响),帮助理解各子句在查询流程中的作用和执行顺序。
SELECT [ALL | DISTINCT] <字段名> [AS 别名] [, <字段名> [AS 别名]] ...
FROM <表名或者视图名> [AS 表别名]
[WHERE <检索条件>]
[GROUP BY <字段名> [HAVING <条件表达式>>]]
[ORDER BY <字段名> [ASC | DESC]]
[LIMIT 子句];
-
SELECT: 查询语句的必选起始关键字,用于指定要从数据库中检索哪些数据。[ALL | DISTINCT]: 可选的修饰符。ALL: 返回所有匹配的行,包括重复的行。这是默认行为。DISTINCT: 去除结果集中完全相同的重复行,只返回唯一的结果。
<字段名>: 指定要查询的具体列名。可以查询一个或多个列。[AS 别名]: 可选的列别名。为查询出的列指定一个临时的、更易读或更简短的名称。AS关键字通常可以省略,直接写字段名 别名。
-
FROM: 查询语句的必选关键字,用于指定数据的来源。<表名或者视图名>: 指明数据来自哪个数据库表或视图。[AS 表别名]: 可选的表别名。为表或视图指定一个临时的简称,在查询(尤其是多表连接)中可以简化书写和引用。
-
[WHERE <检索条件>]: 可选子句,用于对数据行进行筛选。<检索条件>: 一个布尔表达式,只有满足此条件的行才会被包含在结果集中。它在分组 (GROUP BY) 之前执行。常用操作符包括:=、<>/!=、<、>、<=、>=、IN、BETWEEN ... AND ...、LIKE、IS NULL以及逻辑运算符AND、OR、NOT。- 注意:
WHERE中一般不建议使用函数,在WHERE中使用函数会使索引失效。
-
[GROUP BY <字段名>]: 可选子句,用于将结果集中的行根据一个或多个列的值进行分组。<字段名>: 用于分组的列名。通常与聚合函数(如COUNT()、SUM()、AVG()、MAX()、MIN())结合使用,以对每个分组进行统计计算。在SELECT子句中出现的非聚合函数字段,通常也必须出现在GROUP BY子句中。
-
[HAVING <条件表达式>]: 可选子句,用于对分组后的结果进行筛选。<条件表达式>: 一个布尔表达式,但与WHERE不同,HAVING可以引用聚合函数(如COUNT(*) > 1,SUM(salary) < 10000)。它在分组 (GROUP BY) 之后执行,用于过滤分组。
-
[ORDER BY <字段名> [ASC | DESC]]: 可选子句,用于对最终的查询结果集进行排序。<字段名>: 指定排序所依据的列。[ASC | DESC]: 指定排序方式。ASC表示升序(从小到大),DESC表示降序(从大到小)。默认为ASC。可以按多个字段排序,用逗号分隔。
-
[LIMIT 子句]: 可选子句,用于限制返回结果的行数。- 这对于分页显示数据非常有用。常见格式有:
LIMIT N: 返回结果集的前 N 行。LIMIT M, N或LIMIT N OFFSET M: 跳过前 M 行,返回接下来的 N 行。
- 这对于分页显示数据非常有用。常见格式有:
2. 条件查询运算符
此处以表格形式分类整理 MySQL 常用条件查询运算符,涵盖比较、范围、集合、模式匹配、空值判断、逻辑 6 大类别,每个运算符均搭配语法示例和功能说明,清晰展示不同运算符的使用场景和判断逻辑,为编写筛选条件提供直观参考。
| 运算符类别 | 运算符 | 语法示例 | 说明 |
|---|---|---|---|
| 比较运算符 | = | WHERE age = 25 | 等于。检查两个值是否相等。 |
<> 或 != | WHERE status <> 'inactive' | 不等于。检查两个值是否不相等。 | |
< | WHERE price < 100 | 小于。检查左边的值是否小于右边的值。 | |
> | WHERE score > 90 | 大于。检查左边的值是否大于右边的值。 | |
<= | WHERE quantity <= 5 | 小于或等于。 | |
>= | WHERE salary >= 5000 | 大于或等于。 | |
<=> | WHERE column <=> NULL | 安全等于。与 = 类似,但可以正确比较 NULL 值(NULL <=> NULL 返回 TRUE)。 | |
| 范围运算符 | BETWEEN ... AND ... | WHERE age BETWEEN 18 AND 60 | 在指定范围内。包含边界值,等价于 >= 和 <= 的组合。 |
NOT BETWEEN ... AND ... | WHERE price NOT BETWEEN 10 AND 50 | 不在指定范围内。 | |
| 集合运算符 | IN | WHERE city IN ('Beijing', 'Shanghai', 'Guangzhou') | 在给定的值列表中。如果字段值匹配列表中的任何一个,则返回 TRUE。 |
NOT IN | WHERE status NOT IN ('deleted', 'blocked') | 不在给定的值列表中。 | |
| 模式匹配运算符 | LIKE | WHERE name LIKE 'Li%' | 模糊匹配字符串。 - % 代表零个、一个或多个任意字符。- _ 代表一个任意字符。 |
NOT LIKE | WHERE email NOT LIKE '%@qq.com' | 不匹配指定的模式。 | |
REGEXP / RLIKE | WHERE phone REGEXP '^1[3-9][0-9]{9}$' | 使用正则表达式进行更复杂的模式匹配。 | |
NOT REGEXP / NOT RLIKE | WHERE content NOT REGEXP 'spam' | 不匹配指定的正则表达式。 | |
| 空值判断运算符 | IS NULL | WHERE end_date IS NULL | 判断字段值是否为 NULL。注意:不能用 = NULL 来判断! |
IS NOT NULL | WHERE email IS NOT NULL | 判断字段值是否不为 NULL。 | |
| 逻辑运算符 | AND | WHERE age > 18 AND city = 'Beijing' | 逻辑与。只有当所有条件都为 TRUE 时,结果才为 TRUE。 |
OR | WHERE department = 'IT' OR department = 'HR' | 逻辑或。只要有一个条件为 TRUE,结果就为 TRUE。 | |
NOT | WHERE NOT (status = 'inactive') | 逻辑非。将条件的结果取反。 |
3. 函数
此处按功能类别(字符串、数值、日期和时间、条件、聚合、加密与哈希、系统与信息)梳理 MySQL 常用函数,每个函数均包含语法示例和详细说明,明确函数的参数要求、返回结果及使用场景,覆盖数据处理、计算、格式化、统计等各类需求,方便查询时按需选用。
| 类别 | 函数 | 语法示例 | 说明 |
|---|---|---|---|
| 字符串函数 | CONCAT(str1,str2,...) | SELECT CONCAT(first_name, ' ', last_name) FROM users; | 将多个字符串连接成一个字符串。 |
CONCAT_WS(separator, str1,str2,...) | SELECT CONCAT_WS('-', '2025', '10', '21'); | 使用指定的分隔符连接字符串。WS 意为 “With Separator”。 | |
UPPER(str) / UCASE(str) | SELECT UPPER('hello'); -- HELLO | 将字符串转换为大写。 | |
LOWER(str) / LCASE(str) | SELECT LOWER('WORLD'); -- world | 将字符串转换为小写。 | |
LENGTH(str) | SELECT LENGTH('MySQL'); -- 6 | 返回字符串的字节长度。注意:对于多字节字符(如中文),一个字符可能占多个字节。 | |
CHAR_LENGTH(str) | SELECT CHAR_LENGTH('你好'); -- 2 | 返回字符串的字符长度。 | |
SUBSTRING(str, pos, len)SUBSTR()MID() | SELECT SUBSTRING('MySQL', 2, 3); -- ySQ | 从字符串 str 的第 pos 个字符开始,截取长度为 len 的子串。位置从 1 开始。 | |
LEFT(str, len) / RIGHT(str, len) | SELECT LEFT('MySQL', 3); -- MyS | 分别返回字符串左边/右边的 len 个字符。 | |
TRIM(str) | SELECT TRIM(' MySQL '); -- MySQL | 移除字符串首尾的空格。 | |
LTRIM(str) / RTRIM(str) | SELECT LTRIM(' MySQL'); -- MySQL | 分别移除字符串左边/右边的空格。 | |
REPLACE(str, from_str, to_str) | SELECT REPLACE('hello world', 'world', 'MySQL'); | 将字符串中的 from_str 替换为 to_str。 | |
REVERSE(str) | SELECT REVERSE('abc'); -- cba | 反转字符串。 | |
INSTR(str, substr) | SELECT INSTR('MySQL', 'SQL'); -- 3 | 返回子串 substr 在字符串 str 中第一次出现的位置(从1开始)。未找到返回0。 | |
LOCATE(substr, str, pos) | SELECT LOCATE('SQL', 'MySQL', 2); -- 3 | 与 INSTR 类似,但可以指定搜索的起始位置 pos。 | |
FORMAT(X, D) | SELECT FORMAT(1234567.89, 2); -- 1,234,567.89 | 将数字 X 格式化为带有千位分隔符的字符串,保留 D 位小数。 | |
| 数值函数 | ABS(X) | SELECT ABS(-5); -- 5 | 返回 X 的绝对值。 |
CEIL(X) / CEILING(X) | SELECT CEIL(3.2); -- 4 | 返回不小于 X 的最小整数(向上取整)。 | |
FLOOR(X) | SELECT FLOOR(3.8); -- 3 | 返回不大于 X 的最大整数(向下取整)。 | |
ROUND(X, D) | SELECT ROUND(3.14159, 2); -- 3.14 | 将 X 四舍五入到 D 位小数。D 可省略,默认为0。 | |
TRUNCATE(X, D) | SELECT TRUNCATE(3.14159, 3); -- 3.141 | 将 X 截断到 D 位小数(直接舍去,不四舍五入)。 | |
MOD(N, M) / N % M | SELECT MOD(10, 3); -- 1 | 返回 N 除以 M 的余数。 | |
POWER(X, Y) / POW(X, Y) | SELECT POWER(2, 3); -- 8 | 返回 X 的 Y 次幂。 | |
SQRT(X) | SELECT SQRT(16); -- 4 | 返回 X 的平方根。 | |
RAND() | SELECT RAND(); | 返回一个 0 到 1 之间的随机浮点数。 | |
SIGN(X) | SELECT SIGN(-10); -- -1 | 返回 X 的符号:-1 (负), 0 (零), 1 (正)。 | |
| 日期和时间函数 | NOW() / SYSDATE() | SELECT NOW(); | 返回当前的日期和时间。NOW() 返回语句开始执行的时间,SYSDATE() 返回函数执行的实时时间。 |
CURDATE() | SELECT CURDATE(); | 返回当前日期(不包含时间)。 | |
CURTIME() | SELECT CURTIME(); | 返回当前时间(不包含日期)。 | |
DATE(expr) | SELECT DATE('2025-10-21 10:30:45'); -- 2025-10-21 | 提取日期时间表达式中的日期部分。 | |
TIME(expr) | SELECT TIME('2025-10-21 10:30:45'); -- 10:30:45 | 提取日期时间表达式中的时间部分。 | |
YEAR(date) / MONTH(date) / DAY(date)HOUR(time) / MINUTE(time) / SECOND(time) | SELECT YEAR('2025-10-21'); -- 2025 | 分别返回日期中的年、月、日,或时间中的时、分、秒。 | |
DATEDIFF(date1, date2) | SELECT DATEDIFF('2025-10-25', '2025-10-21'); -- 4 | 返回 date1 减去 date2 的天数差。 | |
TIMEDIFF(time1, time2) | SELECT TIMEDIFF('10:30:00', '09:15:00'); -- 01:15:00 | 返回 time1 减去 time2 的时间差。 | |
DATE_ADD(date, INTERVAL expr unit)DATE_SUB() | SELECT DATE_ADD('2025-10-21', INTERVAL 7 DAY); -- 2025-10-28 | 在日期上增加/减去一个时间间隔。unit 可以是 SECOND, MINUTE, HOUR, DAY, MONTH, YEAR 等。 | |
DATE_FORMAT(date, format) | SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s'); | 按指定格式字符串 format 格式化日期。常用格式符:%Y(4位年), %m(月), %d(日), %H(24小时), %i(分), %s(秒)。 | |
STR_TO_DATE(str, format) | SELECT STR_TO_DATE('2025/10/21', '%Y/%m/%d'); | 将字符串按指定格式解析为日期时间。是 DATE_FORMAT 的逆操作。 | |
| 条件函数 | IF(condition, value_if_true, value_if_false) | SELECT IF(score >= 60, 'Pass', 'Fail') FROM grades; | 如果 condition 为真,返回 value_if_true,否则返回 value_if_false。 |
IFNULL(expr1, expr2) | SELECT IFNULL(price, 0) FROM products; | 如果 expr1 不是 NULL,返回 expr1,否则返回 expr2。 | |
NULLIF(expr1, expr2) | SELECT NULLIF(column1, column2); | 如果 expr1 等于 expr2,返回 NULL,否则返回 expr1。 | |
CASE | <br>SELECT <br> name,<br> CASE <br> WHEN score >= 90 THEN 'A'<br> WHEN score >= 80 THEN 'B'<br> ELSE 'C'<br> END AS grade<br>FROM students; | 实现多分支条件判断,类似于编程语言中的 switch 或 if-else if。 | |
| 聚合函数 | COUNT(*)/COUNT(1) | SELECT COUNT(*) FROM table; | 返回结果集的总行数(包含 NULL 值)。 |
COUNT(表达式) | SELECT COUNT(column) FROM table; | 返回指定表达式非 NULL 值的行数。 | |
COUNT(DISTINCT 表达式) | SELECT COUNT(DISTINCT column) FROM table; | 返回指定表达式中不同(去重)且非 NULL 值的数量。 | |
SUM(数值表达式) | SELECT SUM(price * qty) FROM sales; | 计算数值表达式的总和。忽略 NULL。 | |
SUM(DISTINCT 数值表达式) | SELECT SUM(DISTINCT price) FROM products; | 计算不同数值表达式的总和。 | |
AVG(数值表达式) | SELECT AVG(score) FROM students; | 计算数值表达式的平均值。忽略 NULL。 | |
AVG(DISTINCT 数值表达式) | SELECT AVG(DISTINCT salary) FROM employees; | 计算不同数值表达式的平均值。 | |
MAX(表达式) | SELECT MAX(age) FROM users; | 返回表达式的最大值(数值、字符串、日期)。忽略 NULL。 | |
MIN(表达式) | SELECT MIN(price) FROM products; | 返回表达式的最小值(数值、字符串、日期)。忽略 NULL。 | |
GROUP_CONCAT([DISTINCT] expr [,expr ...] [ORDER BY ...] [SEPARATOR str]) | SELECT GROUP_CONCAT(name ORDER BY name SEPARATOR ', ') FROM users GROUP BY dept; | 将分组内的值连接成一个字符串。可去重、排序、自定义分隔符。 | |
STD(expr) / STDDEV() / STDDEV_POP() | SELECT STD(salary) FROM employees; | 返回表达式的总体标准差。 | |
STDDEV_SAMP(expr) | SELECT STDDEV_SAMP(salary) FROM employees; | 返回表达式的样本标准差。 | |
VAR_POP(expr) | SELECT VAR_POP(salary) FROM employees; | 返回表达式的总体方差。 | |
VAR_SAMP(expr) | SELECT VAR_SAMP(salary) FROM employees; | 返回表达式的样本方差。 | |
BIT_AND(数值表达式) | SELECT BIT_AND(flags) FROM config; | 对分组内所有值的二进制表示执行按位与(AND)操作。 | |
BIT_OR(数值表达式) | SELECT BIT_OR(flags) FROM config; | 对分组内所有值的二进制表示执行按位或(OR)操作。 | |
BIT_XOR(数值表达式) | SELECT BIT_XOR(id) FROM temp_table; | 对分组内所有值的二进制表示执行按位异或(XOR)操作。 | |
JSON_ARRAYAGG(表达式) | SELECT JSON_ARRAYAGG(name) FROM users; | 将值聚合成一个 JSON 数组。 | |
JSON_OBJECTAGG(key, value) | SELECT JSON_OBJECTAGG(id, name) FROM users; | 将键值对聚合成一个 JSON 对象。 | |
| 加密与哈希函数 | MD5(str) | SELECT MD5('password'); | 返回字符串的 MD5 128位校验和(十六进制字符串)。注意:MD5 已不安全,不应用于密码存储。 |
SHA1(str) / SHA(str) | SELECT SHA1('password'); | 返回字符串的 SHA-1 160位校验和。同样不推荐用于密码。 | |
SHA2(str, hash_length) | SELECT SHA2('password', 256); | 返回字符串的 SHA-2 系列哈希值。hash_length 可为 224, 256, 384, 512。比 MD5/SHA1 更安全。 | |
AES_ENCRYPT(str, key)AES_DECRYPT(crypt_str, key) | SELECT AES_DECRYPT(AES_ENCRYPT('data', 'key'), 'key'); | 使用 AES 算法对数据进行加解密。需要密钥。 | |
| 系统与信息函数 | VERSION() | SELECT VERSION(); | 返回 MySQL 服务器的版本号。 |
DATABASE() / SCHEMA() | SELECT DATABASE(); | 返回当前选定的数据库名。 | |
USER() / CURRENT_USER() | SELECT USER(); | 返回当前 MySQL 用户的用户名和主机名。 | |
LAST_INSERT_ID() | SELECT LAST_INSERT_ID(); | 返回最后一个 AUTO_INCREMENT 值(在当前会话中)。 |
三、数据查询
1. 简单查询
1.1 查询表中全部数据
通过 SELECT * 语法查询 course 表的所有字段和完整数据。
select * from course;
1.2 查询表中指定字段的数据
指定 course 表的 course_no、course_name、teacher_name 三个字段进行查询。
select course_no, course_name, teacher_name from course;
1.3 查询表中指定字段的数据并起别名
在查询 course 表指定字段的基础上,通过 AS 关键字(部分场景可省略)为字段设置中文别名,提升查询结果的可读性,展示字段别名的使用技巧。
select course_no as '课程号', course_name as '课程名', teacher_name '授课教师' from course;
1.4 查询表中指定字段不重复的数据
使用 DISTINCT 关键字对 course 表的 teacher_name 字段去重查询,仅返回该字段的唯一值,适用于获取无重复的字段信息场景。
select distinct teacher_name from course;
1.5 查询表中前10条数据
借助 LIMIT 子句限制 course 表的查询结果,仅返回前 10 条数据,展示快速获取表内部分数据的方法,常用于数据预览。
select * from course limit 10;
2. 条件查询
2.1 比较运算符查询
2.1.1 查询表中分数大于90的数据
使用 > 比较运算符,筛选 student_course 表中 score 字段值大于 90 的记录,展示通过比较运算筛选符合数值条件的数据。
select * from student_course where score > 90;
2.1.1 查询表中选课无效的数据
使用 = 比较运算符,筛选 student_course 表中 is_valid 字段值为 0(代表无效)的记录。
select * from student_course where is_valid = 0;
2.2 范围运算符查询
2.2.1 查询表中分数大于等于80且小于等于90的数据
使用 BETWEEN … AND … 范围运算符,筛选 student_course 表中 score 字段值在 80-90(含边界)范围内的记录,简化连续数值范围的筛选逻辑。
select * from student_course where score between 80 and 90;
2.2.2 查询表中分数不是大于等于80且小于等于90的数据
在 BETWEEN … AND … 基础上添加 NOT 关键字,筛选 student_course 表中 score 字段值不在 80-90 范围内的记录,展示反向范围筛选的实现方式。
select * from student_course where score not between 80 and 90;
2.3 空值判断运算符查询
2.3.1 查询表中分数为空的数据
使用 IS NULL 空值判断运算符,筛选 student_course 表中 score 字段值为 NULL(代表未考试)的记录,明确空值筛选的正确语法(区别于 = NULL)。
select * from student_course where score is null;
2.3.2 查询表中分数不为空的数据
使用 IS NOT NULL 空值判断运算符,筛选 student_course 表中 score 字段值非空的记录,展示排除空值数据的查询方法。
select * from student_course where score is not null;
2.4 逻辑运算符查询
2.4.1 查询表中分数大于等于80且小于等于90的数据
通过 AND 逻辑运算符连接两个比较条件,筛选 student_course 表中 score 字段值同时满足 “≥80” 和 “≤90” 的记录,实现多条件的 “且” 逻辑筛选。
select * from student_course where score >= 80 and score <= 90;
2.4.2 查询表中专业是数学或计科的数据
使用 OR 逻辑运算符连接两个等值条件,筛选 student 表中 major 字段为 “数学与应用数学” 或 “计算机科学与技术” 的记录,实现多条件的 “或” 逻辑筛选。
select * from student where major = '数学与应用数学' or major = '计算机科学与技术';
2.4.3 查询表中专业不是数学或计科的数据
在 OR 组合条件外添加 NOT 关键字,筛选 student 表中 major 字段既不是 “数学与应用数学” 也不是 “计算机科学与技术” 的记录,实现多条件的反向逻辑筛选。
select * from student where not (major = '数学与应用数学' or major = '计算机科学与技术');
2.5 集合运算符查询
2.5.1 查询表中专业是数学或计科的数据
使用 IN 集合运算符,将 “数学与应用数学”“计算机科学与技术” 作为值列表,筛选 student 表中 major 字段在该列表内的记录,简化多值 “或” 逻辑的筛选语法。
select * from student where major in ('数学与应用数学', '计算机科学与技术');
2.5.2 查询表中专业不是数学或计科的数据
在 IN 基础上添加 NOT 关键字,筛选 student 表中 major 字段不在指定值列表内的记录,实现多值的反向筛选。
select * from student where major not in ('数学与应用数学', '计算机科学与技术');
2.6 模式匹配运算符查询
2.6.1 查询表中姓吴的同学的数据
使用 LIKE 模式匹配运算符结合通配符 %(匹配任意字符),筛选 student 表中 student_name 字段以 “吴” 开头的记录,实现按姓氏模糊查询。
select * from student where student_name like '吴%';
2.6.2 查询表中姓名包含娟字的同学的数据
通过 LIKE 搭配 % 通配符(前后均加),筛选 student 表中 student_name 字段包含 “娟” 字的记录,适用于查询姓名中含特定字符的场景。
select * from student where student_name like '%娟%';
2.6.3 查询表中专业为两个字且第二个字为学的数据
使用 LIKE 结合通配符 _(匹配单个字符),筛选 student 表中 major 字段长度为 2 且第二个字是 “学” 的记录,展示精确字符位置的模糊查询方法。
select * from student where major like '_学';
3. 函数查询
3.1 聚合函数查询
3.1.1 查询表中的最高分和最低分
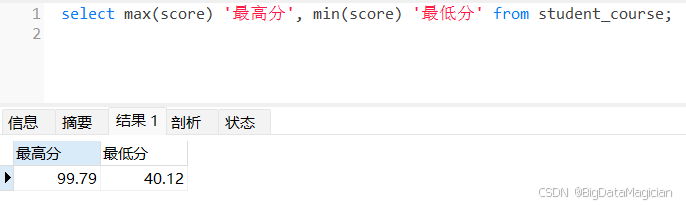
使用 MAX() 和 MIN() 聚合函数,分别计算 student_course 表 score 字段的最大值(最高分)和最小值(最低分),实现对数值字段极值的统计。
select max(score) '最高分', min(score) '最低分' from student_course;
3.1.2 查询指定学生的总分和平均分
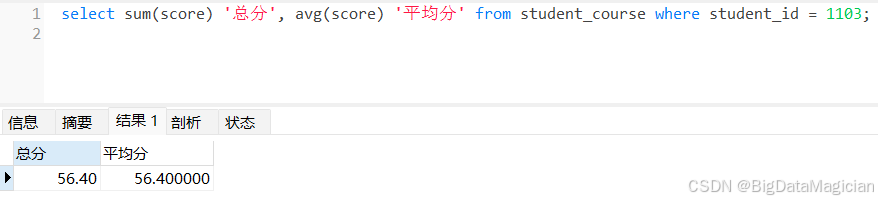
针对 student_course 表中 student_id = 1103 的特定学生,使用 SUM() 计算其 score 字段总和(总分),AVG() 计算平均值(平均分),展示对单个对象的数值统计。
select sum(score) '总分', avg(score) '平均分' from student_course where student_id = 1103;
3.1.3 查询指定学生所选课程数
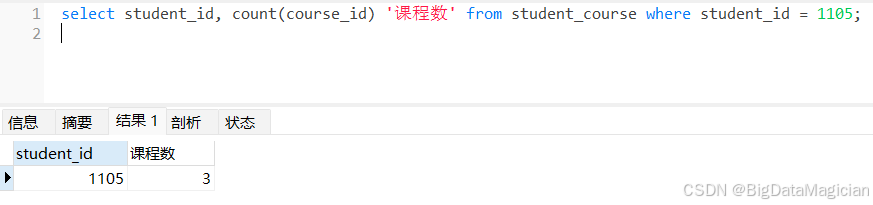
筛选 student_course 表中 student_id = 1105 的记录,通过 COUNT() 统计该学生的 course_id 字段数量,得到其选课总数,示例按条件统计记录数的方法。
select student_id, count(course_id) '课程数' from student_course where student_id = 1105;
3.1.4 查询指定表数据量
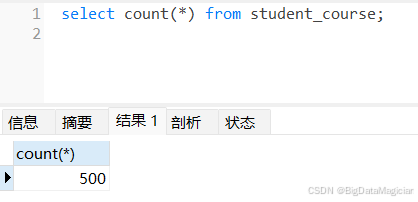
分别使用 COUNT(*) 和 COUNT(1) 两种语法,统计 student_course 表的总行数,展示两种常用的表数据量统计方式,两种方法结果一致且均包含所有记录。
select count(*) from student_course;
或
select count(1) from student_course;
4. 分组、排序和限制查询
4.1 查询每个专业的学生人数
使用 GROUP BY 按 student 表的 major 字段分组,结合 COUNT(*) 统计每个专业的学生数量,实现按指定字段分组并统计各组数据量的需求。
select major, count(*) '学生人数' from student group by major;
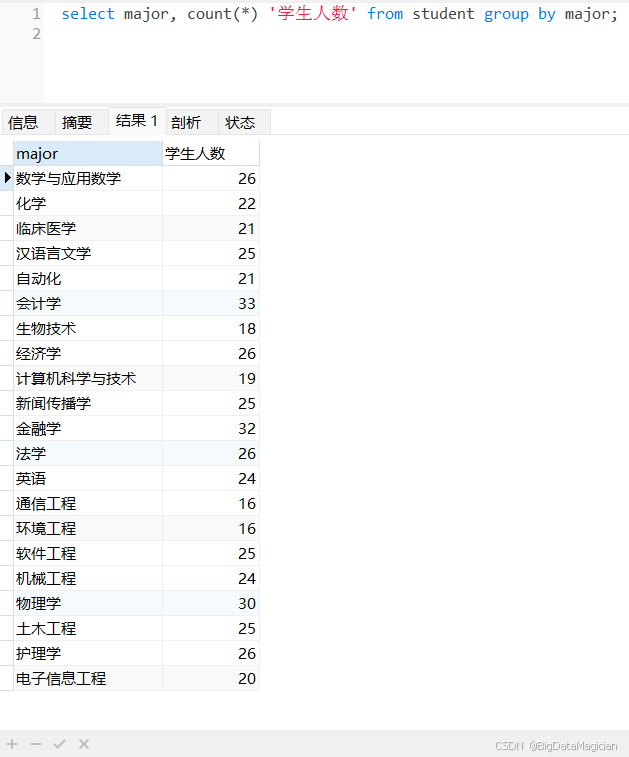
4.2 查询每个专业的学生人数并筛选
在按 major 分组统计学生人数的基础上,通过 HAVING 子句筛选出人数≥25 的专业,展示对分组结果进行二次条件过滤的方法(区别于 WHERE 对原始数据的筛选)。
select major, count(*) '学生人数' from student group by major having count(*) >= 25;
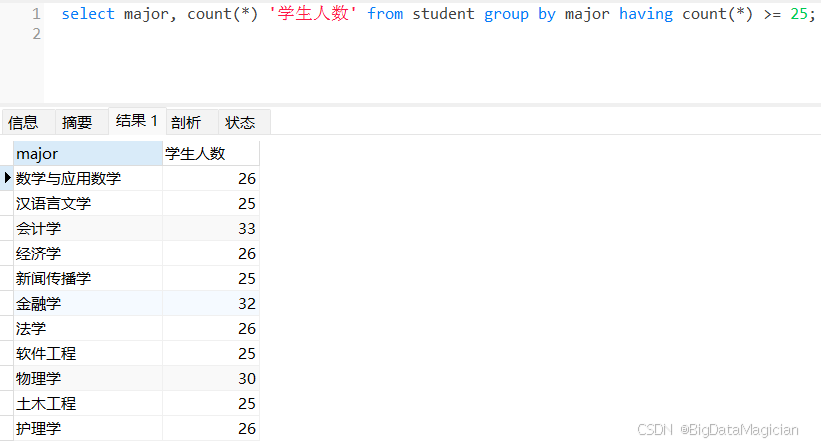
4.3 按学号升序查询
使用 ORDER BY 子句按 student 表的 student_no 字段升序(ASC,默认可省略)排列查询结果,实现数据按指定字段从小到大的排序。
select * from student order by student_no asc;
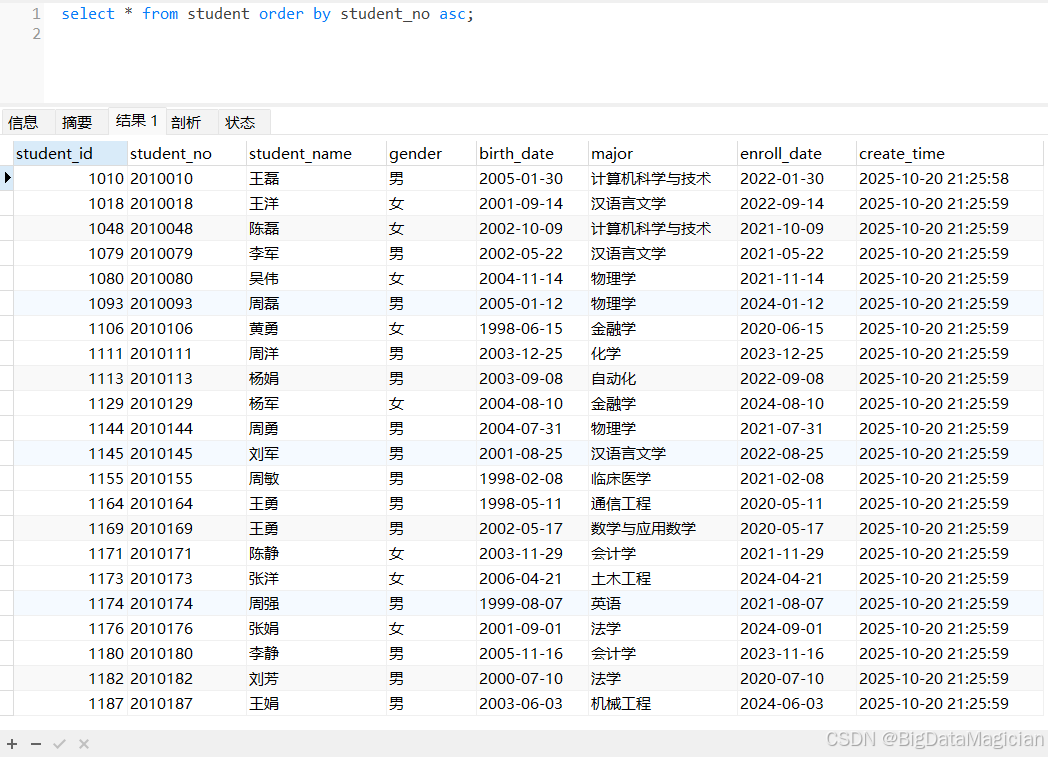
4.4 按学号降序查询
通过 ORDER BY 结合 DESC 关键字,按 student 表的 student_no 字段降序排列查询结果,实现数据按指定字段从大到小的排序。
select * from student order by student_no desc;
4.5 按学号升序查询并限制返回20条数据
在按 student_no 升序排序的基础上,通过 LIMIT 子句限制仅返回前 20 条数据,结合排序和数量限制,适用于分页展示等场景。
select * from student order by student_no asc limit 20;