Linux相关概念和易错知识点(47)(五种IO模型、多路转接、select、poll、epoll)
目录
- 1.五种IO模型
- (1)理解IO和高效IO
- (2)形象认识五种IO模型
- ①阻塞IO
- ②非阻塞IO
- ③信号驱动式IO
- ④多路转接 / 多路复用IO
- ⑤异步IO
- (3)不同IO的效率对比、同步IO和异步IO
- (4)非阻塞IO的实现
- 2.多路转接
- (1)select
- ①select代码逻辑
- ②select函数
- ③fd_set、timeval
- ④select的优缺点
- (2)poll
- ①poll代码逻辑
- ②poll函数
- ③struct pollfd
- ④poll的优缺点
- (3)epoll
- ①epoll代码逻辑
- ②epoll_create
- ③epoll_ctl
- ④epoll_wait
- ⑤struct epoll_event
- ⑥epoll的优点
1.五种IO模型
(1)理解IO和高效IO
IO即input和output,网络通信的效率问题本质上是IO问题,read和write默认是阻塞式IO,对于本机IO来说,硬件收到数据就会发送硬件中断,根据中断号处理。网络通信的话就是网卡进行硬件中断,系统读取数据到数据链路层,再向上交互。因此,无论本机IO还是网络IO,input和output是站在进程角度的。
我们如何更好地理解IO?进而理解什么叫做高效的IO?
IO == 等文件缓冲区有数据 + 拷贝数据工作。 网络通信中,当我们调用read函数时,文件缓冲区不一定有数据,这个时候就会阻塞,也就是等。发送数据也要等,因为文件缓冲区满的时候要等刷新。 本机的文件操作也是这样,要等相关的文件缓冲区、inode、struct file准备好后才能写入数据,只不过本地等的时间非常短,相比而言网络IO的感知更明显。
等和不用等之间的转换中,双方涉及某个条件,如缓冲区空间变化。这种条件变化统一叫做一次IO事件,发送缓冲区为空、满都称之为IO事件就绪(分别对应可以写和可以读的标志)。
既然等是主要矛盾,那什么叫做高效的IO?首先我们要明确一个思想,在任何通信场景下,IO一定是有上限的,IO效率提升到一定程度就会受到硬件的限制,花盆里面不可能长出参天大树,我们要有预期。最高效IO ≈ 拷贝,即充分利用硬件资源、网络资源。 在网络中高效的IO就是尽量减少通信主机read和write阻塞,比如客户端发数据每次都发几字节,而服务端一直在等。我们要提高IO效率,应该怎么做?减少IO中等的比重,即单位时间内,等待的比重越低,IO效率越高。 因此就引入了如下五种IO模型。
(2)形象认识五种IO模型
以钓鱼为例子,我们把钓鱼视作一种IO,因为钓鱼 = 等 + 钓,和IO = 等 + 拷贝很相似。 对于钓鱼这件事来说,其实钓鱼佬大部分时间就在等,相比而言,高效的钓鱼等的时间比重一定低。
①阻塞IO
张三拿着鱼竿坐在岸边,静静地等,他的眼睛死死盯者鱼漂,鱼漂不动他不动,谁叫他都不好使,鱼漂动了就钓上来一条鱼(新手)。
②非阻塞IO
过了一会,来了个李四,坐在张三旁边钓鱼。李四扔出鱼竿开始等,等的时候李四玩手机、看报纸、尝试跟张三说话(张三显然不理他),再看看鱼漂,循环做这些事,有鱼了就开始钓。张三一直不动,李四一直在动。
③信号驱动式IO
王五来了,把铃铛放在鱼竿顶部,扔出鱼竿之后,一直玩手机,看都不看鱼漂,头都不抬。只有他听到铃铛响了之后,他就开始钓鱼。
④多路转接 / 多路复用IO
赵六是个有钱人,他拉了一车鱼竿(100个鱼竿),然后他把每个鱼竿都挂上鱼饵扔河里,并且来回踱步、来回检测,一直在动,有鱼就钓上来。
⑤异步IO
田七是个首富,他坐在自己的专车后座,他深刻的知道,他不是喜欢钓鱼,他喜欢吃鱼。于是看到一群人在钓鱼之后,田七一边自己开车赶着回公司开会,一边给司机小王一个鱼竿、桶、电话等设备,让小王开始钓鱼,桶满了就给田七打电话,田七就会开车回来接小王。
(3)不同IO的效率对比、同步IO和异步IO
拷贝时一致,但是它们等的方式不同,阻塞IO一直在等,而非阻塞IO等的时候在干其他事。但是,阻塞IO和非阻塞IO的效率并没有本质区别,在同样的时间里面非阻塞IO干的事情要多一点,但这个高效性是体现在“其他事情”上(包括其他IO),但如果只针对于这一单事件IO来说,两者本质上没有区别。 从一个更形象的角度来理解,你现在是一条在河里自由的鱼,你现在看到了两个钩子,一个是阻塞IO的,一个是非阻塞IO的。你咬哪个?概率一样,咬哪个都没区别。
因此,从鱼的视角上看,多路转接 / 多路复用IO的效率最高,等的时间很少,因为鱼竿数量特别多,任意一个鱼竿被咬钩的概率很高。
信号驱动式IO的特点是逆转了获取事件就绪的方式(捕捉SIGIO信号,接收到信号就去IO),即等的方式不一样。
阻塞IO、非阻塞轮询IO、信号驱动IO都是等的方式不一样(在单事件上IO效率一样),即钓鱼都要自己去干。因此,只要参与了IO过程(等或者拷贝过程)中的任意一个,都称为同步IO。包括多路转接也是同步IO的一种
同步IO vs 异步IO:
线程的同步指的是排队以及交替唤醒机制,和同步IO没有关系。同步IO和异步IO的本质区别是有没有参与IO过程,包括等和拷贝,只要有一个就叫参与,都会受到IO的影响,就是同步IO。
异步IO的话进程往往扮演IO任务的发起者,实际是让小王(操作系统)去IO,直接将数据放到对应的用户缓冲区后再通知进程,全程进程不需要等、拷贝。 如今异步IO使用率逐渐下降。
(4)非阻塞IO的实现
钓鱼就是调用系统调用、函数调用的过程。对于阻塞IO来说,在数据准备好之前,系统调用会一直等待,因为所有套接字默认都是阻塞方式。如果采用非阻塞IO的话,read不到数据会直接返回,这时就需要我们反复轮询调用。
像recv、open等很多函数参数中都有文件阻塞、非阻塞的选项,但这并不统一。 由于Linux下一切皆文件,用户的所有操作本质上都是跟fd(文件)打交道,而文件描述符默认阻塞,所以我们可以统一设置文件描述符为非阻塞,这样关于文件的一切操作都是非阻塞的了,这种方式更通用 。
int fcntl(int fd, int op, ...) // 设置文件标记位的函数,struct file里面有相应的标记字段
第二个参数op,可以有多个选项 (文件标记位相关的有F_GETFL和F_SETFL,用于非阻塞IO的设置)。后面的可变参数可以传一些set参数的值。fcntl函数失败的话返回-1,成功的话会根据op选项返回。

下面是设置非阻塞IO的函数,非常定式。
// 调用这个函数之后,关于该fd的IO均为非阻塞
void SetNonBlock(int fd)
{int flag = fcntl(fd, F_GETFL, 0); // 获取文件描述符的属性if (flag < 0)return;fcntl(fd, F_SETFL, flag | O_NONBLOCK); // 设置文件描述符为非阻塞
}
阻塞IO调用read时,如果缓冲区里面没数据会直接阻塞,对方关闭连接时或是读取到文件末尾EOF时返回0,正常读取到数据返回具体读取大小(n > 0),read失败会返回-1。非阻塞IO的返回值和阻塞IO的很相似,但在非阻塞下read失败,以及底层数据没就绪时,其返回值都会是-1,也就是没数据时不会阻塞。
但底层数据没就绪严格意义上并不算失败,人家按规矩办事,只是缺失数据没准备好,凭什么说人家犯错?因此在返回-1之后,对该fd后续的处理需要分类,这个区分的方式就是错误码。读取errno,数据没就绪对应的errno == EAGAIN | errno == EWOULDBLOCK。
// 文件操作返回-1之后的处理
if(errno == EAGAIN || errno == EWOULDBLOCK) // 数据没就绪(仅当在非阻塞IO中需要处理,阻塞IO返回-1不可能是这个情况)break;
else if(errno == EINTR) // 被信号打断,重新读(阻塞IO和非阻塞IO都需要处理)continue;
else
{Excepter(); // 触发读写错误,需要异常处理(阻塞IO和非阻塞IO都需要处理)return;
}
上述代码中,errno == EINTR(被信号打断)是什么场景呢?
无论是阻塞IO还是非阻塞IO,在返回-1之后都需要进行这个判断。 原因是进程执行阻塞式系统调用时,如果收到了一个信号,内核会强制中断该系统调用,使其返回-1,并将errno设为EINTR,表示调用被信号打断。对于阻塞IO或是非阻塞IO来说,当数据就绪需要拷贝数据时,系统调用均会阻塞,所以这两种IO都可能会被信号打断。 一般来说这种打断概率极低,几乎只存在于理论上,我们很难去验证,所以默认加上就好。
不过对于阻塞IO来说,errno == EINTR还有个作用是处理等待数据到来时被打断的情况,因为阻塞IO只要没有数据就绪会一直等待,这期间极有可能被信号唤醒,此时判断errno == EINTR之后continue是必要的,continue就意味着处理信号之后阻塞IO会重新调用阻塞函数,重新回去阻塞。
以read为例子,read是系统调用,有系统调用号。当处于read函数的阻塞状态(S状态,浅度睡眠 / 拷贝场景)时,进程可能收到信号被唤醒,这个时候函数就被打断了。 那么被唤醒处理信号后是回到阻塞状态继续拷贝数据,还是执行后续代码?
执行continue,这个时候就会重回原来的函数,如果有数据就重新读取,如果还没有数据就重新挂起(阻塞IO)。
2.多路转接
IO = 等 + 拷贝,如recv、recvfrom、read、write等系统调用都是等 + 拷贝组成的。多路转接的操作就是将等这个过程给提取出来,一次性等的fd更多。 就像有钱的钓鱼佬一次性等100个鱼竿,效率自然高很多,鱼儿咬钩的概率自然大。所以,解决对多个文件描述符进行等待,通知上层哪些fd已经就绪,这本质是一种对IO事件就绪的通知机制,这个“等 + 通知机制”就是多路转接。 多路转接一般更适合网络。
多路转接的方案有三种,select、poll、epoll,终极解决方案是epoll,集合了所有的优点并杜绝了所有的缺点,其底层自然更复杂。select、poll主要就是引子,我们了解他们的处理即可。
(1)select
①select代码逻辑
这是select启动服务后进入的处理循环,我们理解其逻辑。
Init函数
void Init()
{// 这是父类继承下来的,继承到不同子类实现不同的功能,即多态_listen_socket->BuildTcpSocketMethod(_port); // 这个时候服务端就已经搭建好了,IP + port已经被绑定好了,我们也完全不需要关心socket本身,我们面向TcpSocket这个对象操作即可// 遍历fd_setfor (int i = 0; i < MAX_FD; i++)_fd_array[i] = DefaultFd; // 遍历时只要不是-1说明这个位置的fd就是我们需要去关心的_fd_array[0] = _listen_socket->GetFd(); // 辅助数组的第0位保存监听fd,也是当前唯一能确定需要关心的fd
}
Loop函数
void Loop()
{fd_set readfds; // 获取到读事件的fd集合_isrunning = true;while (_isrunning){// 一直循环,每一次都要根据辅助数组遍历得到我们关心的fd,将其放进readfds集合中,统一交给select处理,一次性可以等待多个fd// 每次进入循环都要对readfds进行清空FD_ZERO(&readfds);struct timeval timeout = {10, 0}; // 10s的超时时间int maxfd = DefaultFd;// 遍历辅助数组,将所有的fd都添加到readfds中for (int i = 0; i < MAX_FD; i++){if (_fd_array[i] != DefaultFd) // 辅助数组中保存的fd要么是初始化时填的-1,要么就有实际的作用{FD_SET(_fd_array[i], &readfds); // 将当前要关心的fd都写进readfds集合中,便于后续统一传到select中maxfd = std::max(maxfd, _fd_array[i]); // 找出最大的fd,用于select的第1个参数}}// 调用select函数阻塞式等待多个fd,即可以一次性等待辅助数组里面关心的所有fd,目前只关心读事件,写事件、异常事件暂不关心,默认置为空// 调用select函数后,select负责阻塞式等待多个文件描述符的数据,数据准备好后recvfrom直接读就可以了。select可以传递多个文件描述符,一次等多个fdint n = select(maxfd + 1, &readfds, nullptr, nullptr, &timeout); // 等待事件发生,返回值是就绪的fd的数量。最后一个参数可以传NULL,即无限时阻塞等待,多个fd的时候至少有一个就绪的时候fd就会返回// 只要有读事件就绪了,就退出阻塞状态if (n == 0) // 表示超时了LOG(LogLevel::INFO) << "单次超时,10s内无读事件就绪";else if (n == -1) // 表示出错了perror("select出错");else{// 有读事件就绪了,根据n和输入输出参数(readfds)对每个fd进行处理。readfds输出时就表示当前就绪的fd集合,n表示就绪的fd的数量LOG(LogLevel::INFO) << n << "个读事件就绪";Dispatcher(readfds); // 将fd_set这个结构体传过去,让Dispatcher去处理里面标记好的fd// 这个函数出来后所有的读事件就处理完成了。处理完成之后在返回循环最顶部,清空readfds,根据辅助数组重新设置要关心的fd,进入select继续等待}}_isrunning = false;
}
派发函数
void Dispatcher(fd_set &readfds) // 输出型参数,fd_set里面对应的fd就都是需要进行处理的
{// fd_set能够标记的最大数量就是MAX_FD,跟辅助数组的元素个数一致,所以可以直接遍历辅助数组,结合readfds一起进行判断哪个fd是就绪的,不能直接从fd_set里面直接获取fdfor (int i = 0; i < MAX_FD; i++){if (_fd_array[i] != DefaultFd && FD_ISSET(_fd_array[i], &readfds)) // 不在辅助数组关心的fd集合里面,不需要关心{// 从这里开始根据不同的fd类型进行分发if(_fd_array[i] == _listen_socket->GetFd()) // 监听fd就绪了,说明有新的客户端连接请求Accepter(); // 连接器,监听fd就绪了就应该去建立和客户端的连接 else // 目前来讲分发器只关心监听fd和客户端连接的fd,后者就说明客户端开始发消息了,就去调用消息接收器Recver(i); // 消息接收器,客户端fd就绪了就应该去接收客户端的消息。这里只能传下标,因为Recver可能需要知道下标(关闭fd后清理辅助数组)}}
}
②select函数
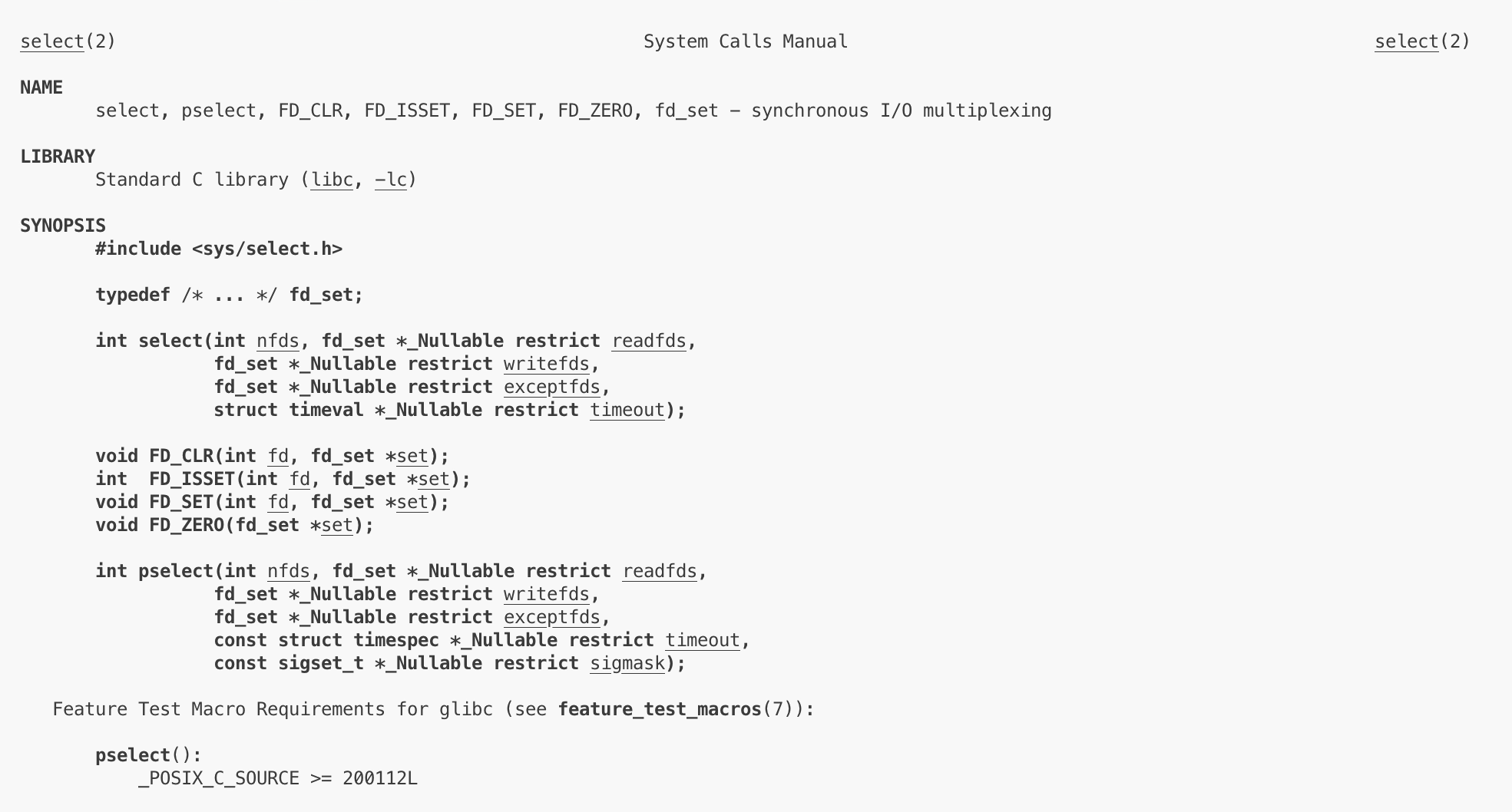
select是输入关心的fd_set(读、写、异常事件),nfds(关心的最大fd + 1),阻塞时间timeval(为空表示一直阻塞),最后数据就绪时退出阻塞,fd_set作为输出参数,因此我们可以轮询得到就绪的事件并进行派发处理。
select返回值n > 0表示就绪了n个fd,n < 0表示等待失败(有错误的fd),n == 0表示底层fd还没有就绪,也没有出错,就是超时了。
select只有第一个参数是输入型参数,其余都是输入输出型参数。
readfds做输入的时候,用户告诉内核需要关心readfds位图中被设置了的fd上的读事件,其中bit位位置可以表示fd具体值。readfds做输出的时候,内核告诉用户readfds位图中用户关心的fd中哪些fd就绪了,对我们关心的已就绪的fd对应位置置为1。但注意,返回的fd_set位图中一定是我们关心的fd,我们不关心的或者关心却没就绪的fd位置都会是0,就算我们不关心的fd就绪了。
对于服务端来说,获取新连接accept本质就是IO,listenfd只关心读事件,connect其实就是服务端向listenfd里面写数据,所以我们将listenfd添加到读事件中,只要有事件未处理就会一直通知。
每次调用select,都要重新设置fd_set,因为输出时fd_set会被修改,所以我们要有一个设置源,即辅助数组。

③fd_set、timeval
中间三个参数表示读、写、异常文件描述符集fd_set*。fd_set是集合数据类型,是OS提供给用户的,定义的变量里面可以添加多个文件描述符。那么问题来了,fd_set具体是什么数据结构(用来保存fd的)?位图!0号描述符对应位图的0号位置,该位置设置为1就表示关心该fd。
关心读事件 -> fd是否可读 -> 接收缓冲区是否有数据
关心写事件 -> fd是否可写 -> 发送缓冲区是否有空间
关心异常事件 -> fd是否出现异常
我们可以把一个fd添加到不同集合,通过参数传过去,表示我们关心该fd上的该事件。
位图结构里面是int bits[N],例如第34个fd在下标为34 / 32 = 1里存着,34 % 32 = 2表示第2个bit,即第34个fd的关心信息存储在下标为1的元素的第2个bit位。 所以我们设置或者获取关心的fd本质上都是对位图进行操作,宏方法FD_SET可以直接帮我们设置fd到位图中,不用我们自己做位移操作,FD_ISSET同理。
但是fd_set并不是一个单纯的int bits[N],它的外面是一个结构体,fd_set是作为一个结构体来处理的(包装数组位图的struct)。 为什么?使用结构体方便传参、拷贝、修改,数组的话传参操作传着传着就会变成指针。
fd_set是一个具体的数据类型,既然是一个数据类型,那就有大小,fd_set是固定大小,所以fd_set的fd个数有上限,即select能关心的fd个数是有上限的,这个值在1000级别。

timeval结构体中tv_sec表示等待秒数,tv_usec表示等待微秒数。 当等待时间超过或者有至少一个事件就绪之后会立即返回。
④select的优缺点
多路转接是一种等的手段(等多个fd + 通知上层),而等其实本身也是一个手段,我们真正需要的是数据,等就是为了得到数据。我们需要深刻体会多路转接(select、poll、epoll)只是处理等这个过程。
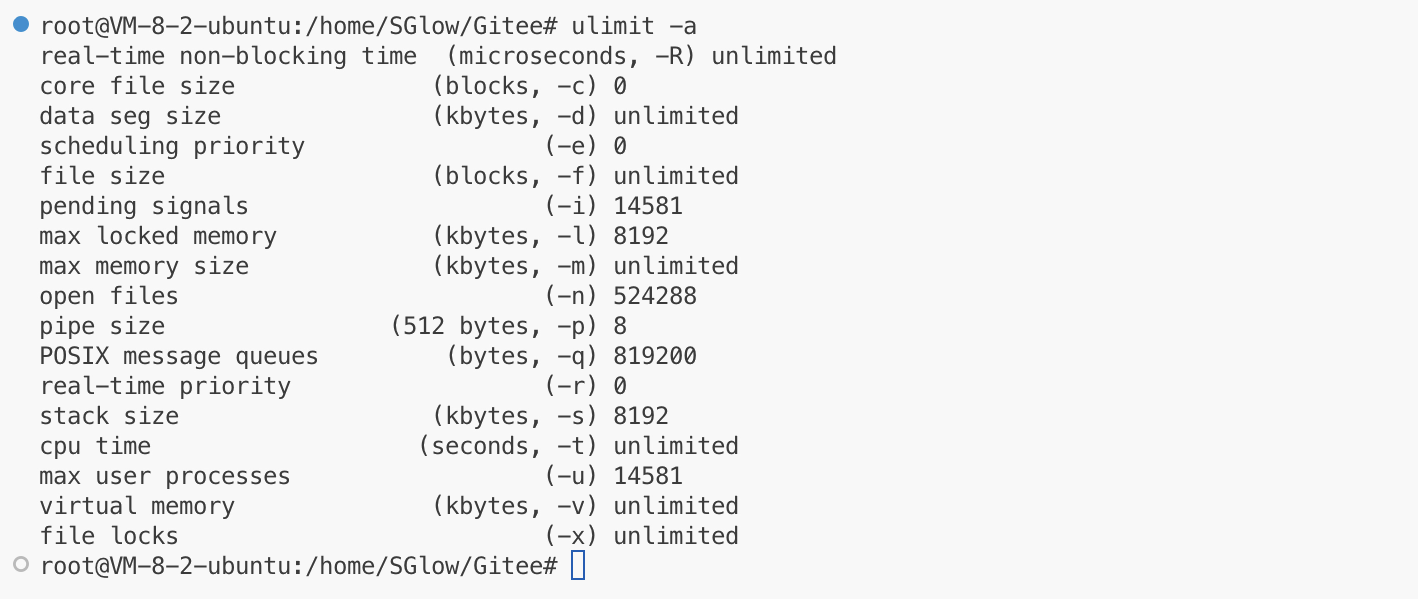
select大概能同时处理1000多个fd,这取决于sizeof(fd_set),但总的来说支持的文件太少了!进程能打开的文件有上限,select可处理的fd也有上限,这就是缺点,为什么?OS的缺点不是select有缺点的理由。况且OS能对文件描述符数量进行扩容。
ulimit -a的open files表示是一个进程能打开的文件描述符个数。
还有个缺点,每次调用select前都需要手动设置fd_set(读、写、异常三个集合),这是因为输入参数会被输出覆盖,本质上是同一个位图输入输出导致的。 select的每次调用都要将集合从用户到内核拷贝,从内核到用户拷贝,拷贝开销大。并且每次都需要遍历集合,如果我们想要关心的fd本来就少,但每次都会遍历fd_set,高频起来后消耗不小。
面对select的缺点,如fd_set多次重置,fd个数有上限,我们引入了第二种多路转接—— poll。
(2)poll
①poll代码逻辑
Init函数
void Init()
{// 这是父类继承下来的,继承到不同子类实现不同的功能,即多态_listen_socket->BuildTcpSocketMethod(_port); // 这个时候服务端就已经搭建好了,IP + port已经被绑定好了,我们也完全不需要关心socket本身,我们面向TcpSocket这个对象操作即可for (int i = 0; i < MAX_FD; i++) // 初始化辅助数组,这个辅助数组是poll关心的fd和事件,默认fd都是-1{_fds[i].fd = DefaultFd;_fds[i].events = 0; // 我们设置关心的和返回的做了参数分离,这是对select的改进_fds[i].revents = 0;}_fds[0].fd = _listen_socket->GetFd(); // 辅助数组的第0位保存监听fd,也是当前唯一能确定需要关心的fd_fds[0].events = POLLIN; // 关心读事件
}
_fds是poll中的辅助数组,这在后面会用到

Loop函数
void Loop()
{_isrunning = true;// 阻塞式等待的话poll直接传负数即可,select阻塞式等待需要传NULL// poll第三个参数timeout需要直接传整数,=0就是非阻塞,<0叫做一直阻塞式等待(select没有有这种写法)int timeout = 10 * 1000; // 10s,1表示1mswhile (_isrunning){// 有事件就绪后,revents就会被设置为就绪的事件,这是个阻塞函数int n = poll(_fds, MAX_FD, timeout); // 等待事件发生,返回值是就绪的fd的数量// 只要有读事件就绪了,就退出阻塞状态if (n == 0) // 表示超时了LOG(LogLevel::INFO) << "单次超时,10s内无读事件就绪";else if (n == -1) // 表示出错了perror("poll出错");else{LOG(LogLevel::INFO) << n << "个读事件就绪";Dispatcher(); // 遍历fds即可// 这个函数出来后所有的读事件就处理完成了。处理完成之后在返回循环最顶部}}_isrunning = false;
}
派发函数
// 处理就绪的事件,根据不同的fd进行分发处理
void Dispatcher()
{for (int i = 0; i < MAX_FD; i++){if (_fds[i].fd != DefaultFd && _fds[i].revents & POLLIN) // 必须是规范的fd并且读事件就绪{// 从这里开始根据不同的fd类型进行分发if (_fds[i].fd == _listen_socket->GetFd()) // 监听fd就绪了,说明有新的客户端连接请求Accepter(); // 连接器,监听fd就绪了就应该去建立和客户端的连接else // 目前来讲分发器只关心监听fd和客户端连接的fd,后者就说明客户端开始发消息了,就去调用消息接收器Recver(i); // 消息接收器,客户端fd就绪了就应该去接收客户端的消息。这里只能传下标,因为Recver可能需要知道下标(关闭fd后清理辅助数组)}}
}
②poll函数

第一个参数是结构体数组指针struct pollfd*,第二个是nfds表示其大小,这两个参数组成了一个数组的描述字段,因此我们可以关心多个fd,pollfd*告诉内核第一个元素地址,整数告诉数组有多少个元素。
③struct pollfd

pollfd的fd指的是用户关心的fd,short events是对应用户关心的fd的关心事件(用户 -> 内核)。revents是OS返回的,告诉这个fd哪些时间已经就绪了(内核 -> 用户),可以看到在struct pollfd层面,输入(events)输出(revents)分离,这样当我们调用poll之前我们就不需要重新设置传入的结构体。
调用poll时,用户告诉内核关心哪个fd上的哪些事件,之后内核返回告诉用户所关心的fd上所关心的事件哪些事件已经就绪了。 我们可以清晰的理解到,用户和内核之间插入了一个poll,用户到内核用poll,内核到用户用poll。 poll的定位就是对多个fd的IO事件的等待机制,poll函数只负责等,达到事件派发的目的,和select功能一致。
events和revents事件怎么组成的?
同理,这两个也是位图,用宏定义表示事件。其中最常用的是POLLPRI紧急读事件(类似紧急指针),POLLIN读事件,POLLOUT写事件。short是16位,我们最多关心16个事件,需要通过按位或设置,按位与获取,OS没有提供接口。
用户设置自己关心的事件时只管events,不管revents,revents这是内核设置的
④poll的优缺点
优点
struct pollfd是数组,nfds是数组元素的个数,这个数组理论上并没有上限,换句话说这个上限由用户 / 系统 / 硬件决定,但就是不关poll的事,因为你传多大的数组都可以。 nfds理论上你可以传无穷大,这个时候能限制你的就是系统了,但始终和poll的设计没关系,我们要深刻理解这点。
缺点
依旧需要内核在底层遍历式地访问我们的struct pollfd数组,检测所有文件描述符fd是否有事件就绪。这还是有很多循环,导致效率到一定程度上就减缓了,fd越多,遍历成本变高,效率也就越低。同时事件就绪后也需要用户完全遍历数组,每个元素判断是否就绪。 同时poll也需要不断在内核和用户之间拷贝,处理revents和events,但不是主要问题,也没有模型能解决。
基于poll的缺点,我们需要引入多路转接的终极方案,即epoll模型。它继承了select和poll的所有优点并解决了所有缺点,其底层依赖一种回调机制,后续会讲到。
(3)epoll
①epoll代码逻辑
epoll模型相关的就是epoll_create、epoll_ctl、epoll_wait三个接口,epoll的定位是关注多个fd的IO事件的等待机制,是一种就绪事件的通知机制,达到事件派发的目的。
Init函数
void Init()
{// 这是父类继承下来的,继承到不同子类实现不同的功能,即多态_listen_socket->BuildTcpSocketMethod(_port); // 这个时候服务端就已经搭建好了,IP + port已经被绑定好了,我们也完全不需要关心socket本身,我们面向TcpSocket这个对象操作即可// 创建epoll模型_epfd = epoll_create(256);if (_epfd < 0){LOG(LogLevel::FATAL) << "epoll模型创建失败";exit(static_cast<int>(myError::EPOLL_CREATE_ERROR));}LOG(LogLevel::INFO) << "epoll模型创建成功,_epfd为" << _epfd;// 将一定服务器的listenfd添加到epoll模型的红黑树中struct epoll_event ev;ev.events = EPOLLIN; // 关心读事件ev.data.fd = _listen_socket->GetFd(); // data是一个联合体,我们写入fdint n = epoll_ctl(_epfd, EPOLL_CTL_ADD, _listen_socket->GetFd(), &ev); // 将我们关心的fd和事件写入到epoll模型的红黑树中// 红黑树就相当于poll和select的辅助数组,只不过在epoll这里不需要我们进行维护。除了添加到红黑树中,ctl还会注册服务,使得后续数据准备就绪后会自动添加到就绪队列中if (n < 0){LOG(LogLevel::FATAL) << "epoll模型添加监听fd失败";exit(static_cast<int>(myError::EPOLL_CTL_ERROR));}LOG(LogLevel::INFO) << "epoll模型添加监听fd成功,监听fd为" << _listen_socket->GetFd();
}
Loop函数

void Loop(){// 阻塞式等待的话poll直接传负数即可,select阻塞式等待需要传NULL// poll、epoll的最后一个参数必须是int类型int timeout = 10 * 1000; // 10s_isrunning = true;while (_isrunning){// 有事件就绪后,revents就会被设置为就绪的事件int n = epoll_wait(_epfd, _revs, revs_num, timeout); // 阻塞函数,等待事件发生,返回值是就绪的fd的数量// 只要有读事件就绪了,就退出阻塞状态,接收到的_revs一定不会越界,传参时revs_num限制了。并且_revs里面装的全部都是就绪的事件,不需要像辅助数组那样进一步判断if (n == 0) // 表示超时了LOG(LogLevel::INFO) << "单次超时,10s内无读事件就绪";else if (n == -1) // 表示出错了perror("epoll出错");else{LOG(LogLevel::INFO) << n << "个读事件就绪";Dispatcher(n); // 告诉派发函数现在有多少个读事件就绪了,派发函数就会循环_revs处理所有读事件// 这个函数出来后所有的读事件就处理完成了。处理完成之后在返回循环最顶部}}_isrunning = false;}
派发函数
// 处理就绪的事件,根据不同的fd进行分发处理
void Dispatcher(int n)
{for (int i = 0; i < n; i++){int events = _revs[i].events; // 获取就绪事件int fd = _revs[i].data.fd; // 获取就绪fdif (events & EPOLLIN) // fd一定有效,读事件就绪{// 从这里开始根据不同的fd类型进行分发if (fd == _listen_socket->GetFd()) // 监听fd就绪了,说明有新的客户端连接请求Accepter(); // 连接器,监听fd就绪了就应该去建立和客户端的连接else // 目前来讲分发器只关心监听fd和客户端连接的fd,后者就说明客户端开始发消息了,就去调用消息接收器Recver(fd); // 消息接收器,客户端fd就绪了就应该去接收客户端的消息。}}
}
②epoll_create
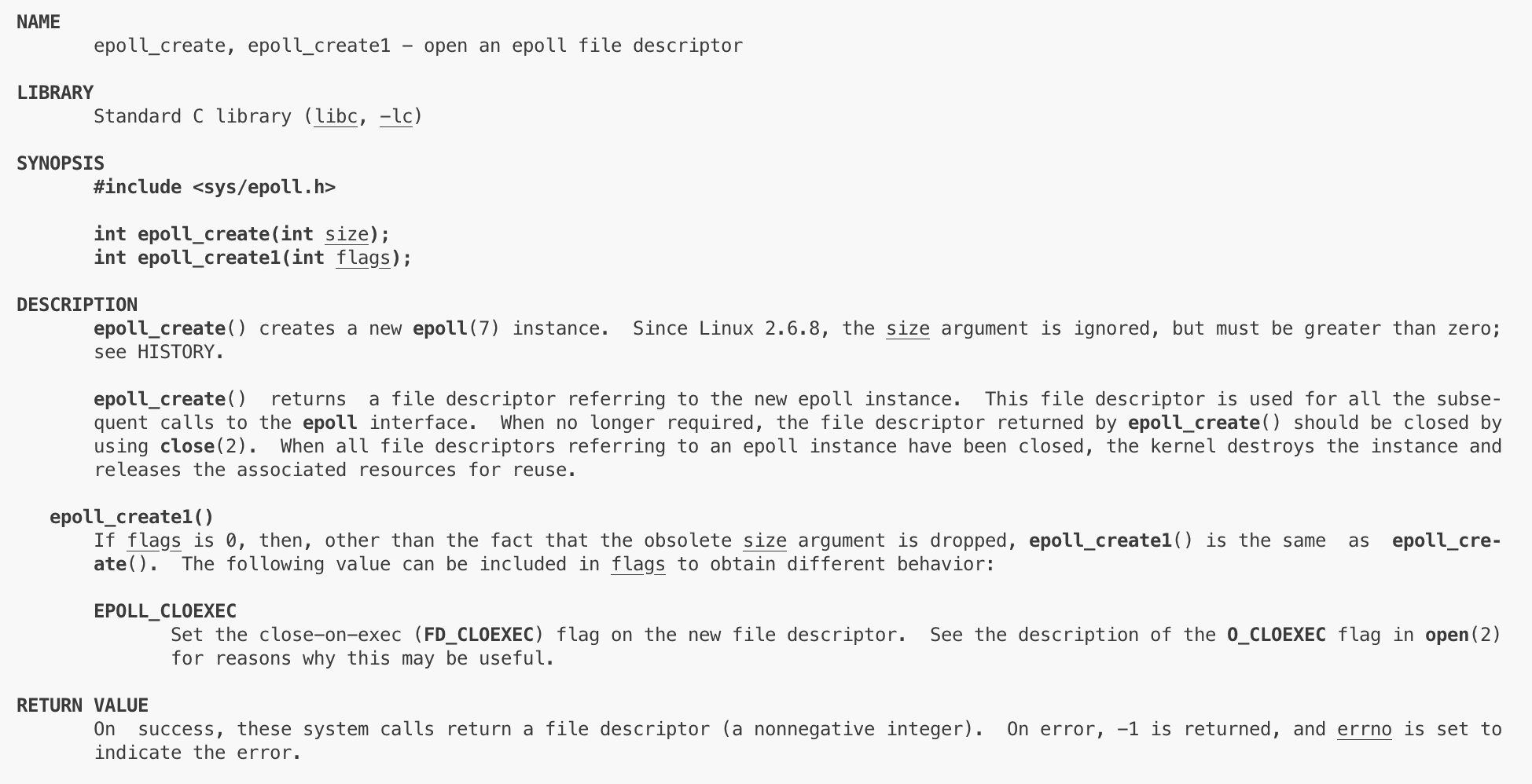
这是Init函数中需要做的,即创建epoll模型。调用epoll_create即可创建一个epoll模型,里面的int size参数被忽略无意义,我们不管它,但必须大于0。函数返回一个文件描述符fd,如果创建epoll模型失败就会返回-1,并设置错误码。
我们后续就可以通过这个fd找到模型,后续的操作都是针对该模型进行操作的。
③epoll_ctl

epoll_ctl第一个参数就是epoll模型的fd,第二个参数op操作有EPOLL_CTL_ADD、DEL、MOD(分别针对添加事件关心、删除事件关心、修改事件关心),第三个参数是我们要设置关心的fd,第四个参数是关心的事件(位图)。 这个事件需要我们用结构体传入,代码如下:
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = _listen_socket->GetFd();
int n = epoll_ctl(_epfd, EPOLL_CTL_ADD, _listen_socket->GetFd(), &ev);
EPOLLIN表示关心读,EPOLLOUT表示关心写,EPOLLPRI表示紧急读,和poll的类似。在设置和获取中,都是自己用位运算获取结果,和poll类似。
通过ctl,我们可以添加关心的fd和关心的功能,这是用户告诉内核,成功返回0,失败返回-1。
④epoll_wait
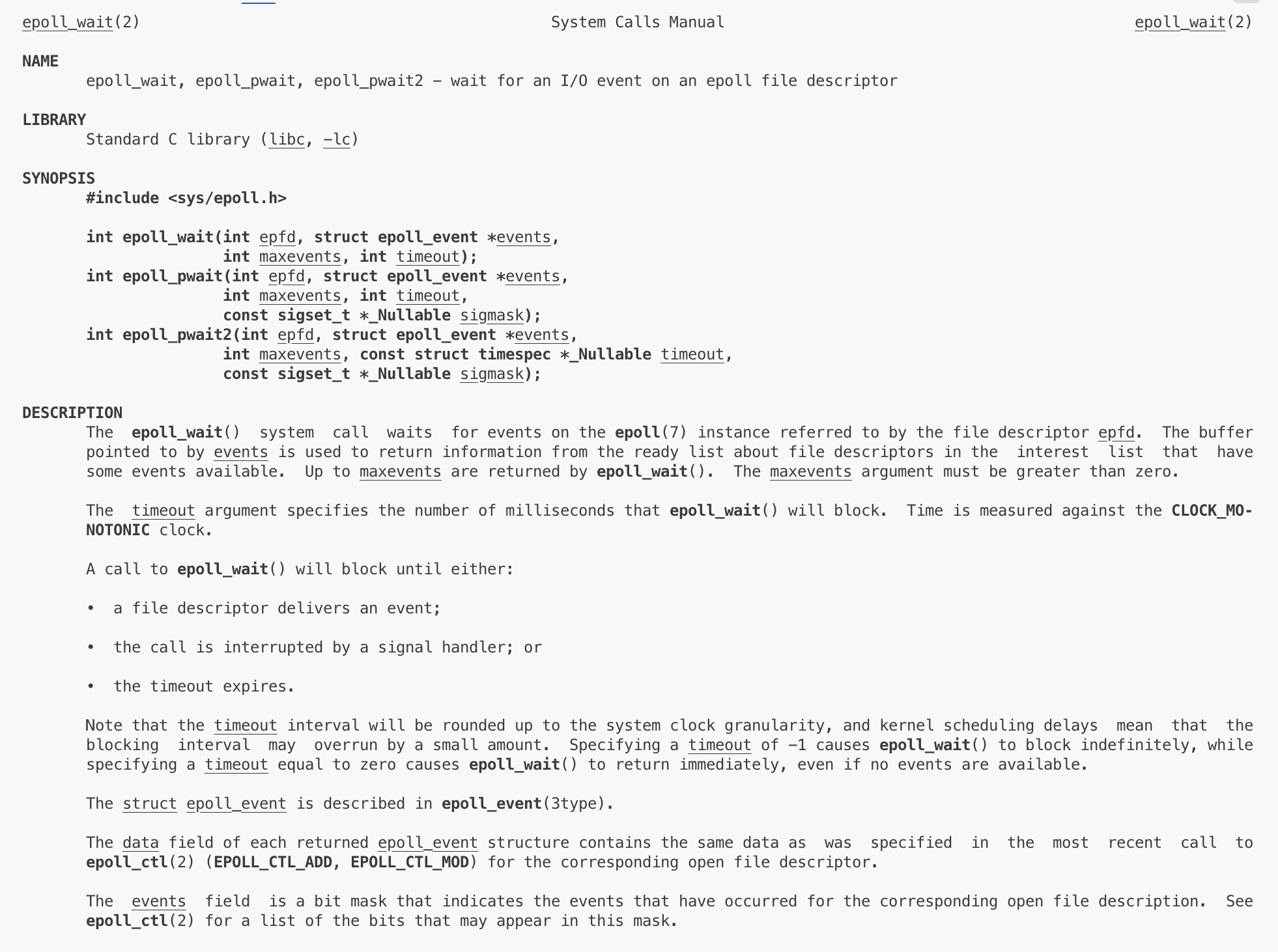
wait是内核告诉用户。 events是输出型参数,是一个数组指针,maxevents是这个数组的长度。用户传入数组和个数后,可以获取就绪的事件,并且返回值就是epoll写入的events的有效长度。
ctl是用户向内核,wait是内核向用户,在poll和select上,用户到内核、内核到用户都集成在一个函数中,但在epoll上直接从接口上做了区分,参数也进行了分离。
⑤struct epoll_event

events数组是struct epoll_event类型的指针,这个类型表示epoll事件,该结构体包含两个参数,第一个是事件类型events(输入输出都用它来进行事件表示),第二个参数data是联合体类型。

这个联合体是fd、ptr等字段联合的,我们一般就使用fd即可。
⑥epoll的优点
epoll在接口层面将用户到内核,内核到用户两个过程做了接口分离。用户设置的时候自己调用ctl即可,需要开启多路转接就阻塞在wait等待,并且能够一次性处理的fd无上限。除此之外,wait返回n后,我们的struct epoll_event数组里面所有的前n个元素全部都是有效的事件,不像poll那样我们还需要自己去判断一下当前元素有没有就绪。
if (_fds[i].fd != DefaultFd && _fds[i].revents & POLLIN) // poll中需要遍历判断
但最大的优势,在于底层epoll不会循环式遍历我们关心的fd和事件了,判断它们有没有就绪。而是利用一种回调机制,使得每次epoll调用wait时,都只会到一个就绪队列里面取数据。 至于如何到就绪队列的,完全自动触发。这个底层结构我们后续文章会讲到。