ABAP 静态代码分析 - 语法分析
关于本文内容比较难,且无任何参考资料,自身能力有限只能举一些简单场景做介绍
1. 语法分析的定位
语法分析是静态代码扫描中的第二个核心步骤(在词法分析之后),在其中扮演着基础性、不可或缺的角色。
它的主要任务是:根据预定义的语法规则,检查由词法分析器生成的令牌序列是否符合该语言的语法结构。。
核心过程:
- 输入:来自词法分析器的令牌序列。
- 输出:一颗语法树。这是一种树形数据结构,清晰地展示了代码的层次结构。
主要目的:
- 检查语法正确性:发现并报告诸如括号不匹配、缺少分号、关键字使用错误等语法错误。
- 构建抽象语法树:生成一个结构化的、便于后续分析和处理的程序表示形式。这是后续所有高级分析(如语义分析、代码优化)的基础。
2. 抽象语法树(AST - Abstract syntax tree)
定义:抽象语法树是源代码抽象语法结构的树状表示。
- 树:一种数据结构,由节点组成,每个节点有零个或多个子节点。这完美地表示了代码的层次结构。
- 语法:它表示的是代码的语法(结构),而不是文本(内容)。
- 抽象:这是最关键的一点。它意味着树中省略了源代码中不重要的细节,比如:
- 空格、缩进、注释
- 括号(通过树的结构本身来隐含优先级)
- 分号等分隔符
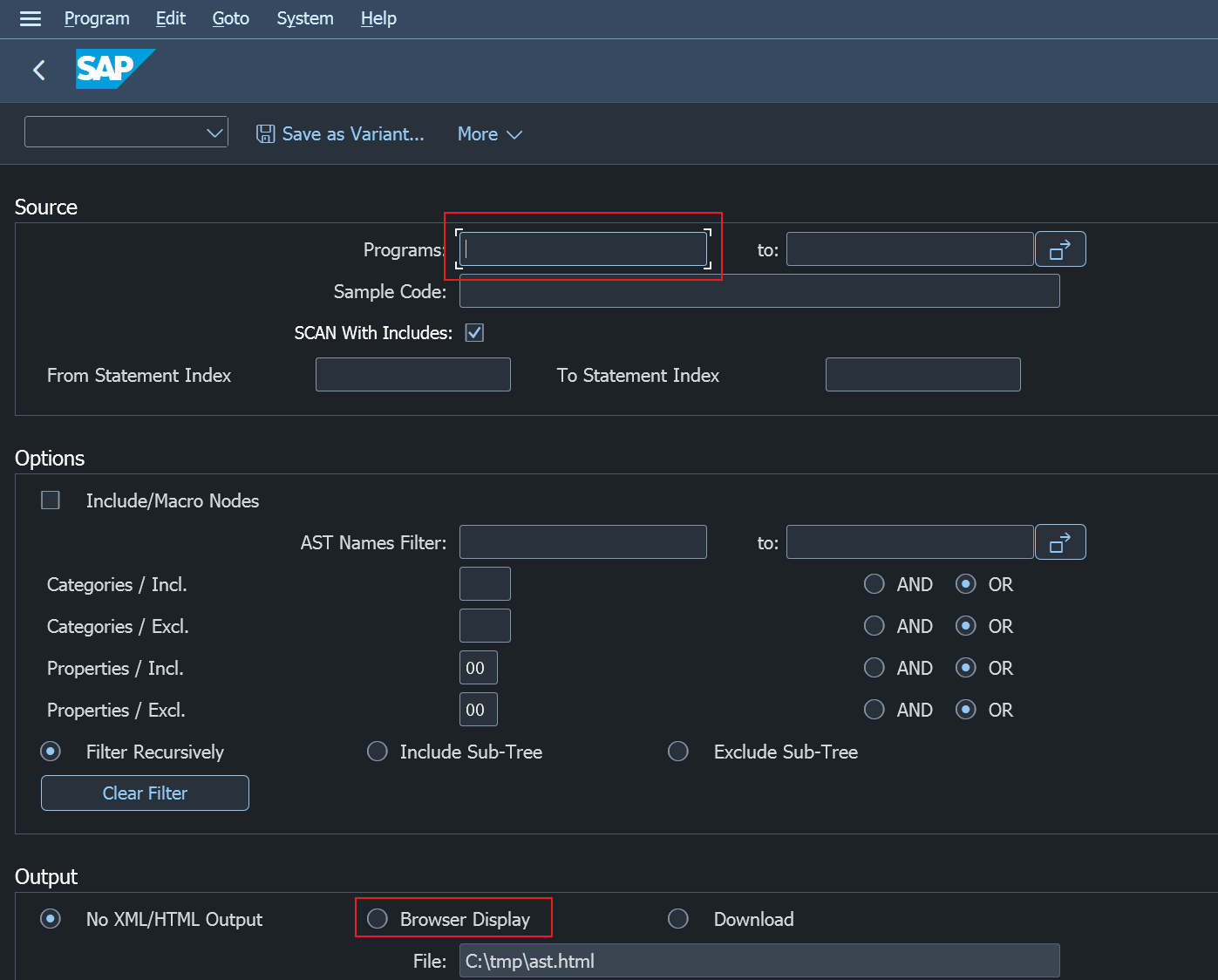
事务码SAST可以查看已激活程序转换后的AST,我常用的就下面两个参数,其他的保持原样即可
- Programs: 程序名,类和Function需要输入主程序名
- Browser Display: 浏览器视图查看XML
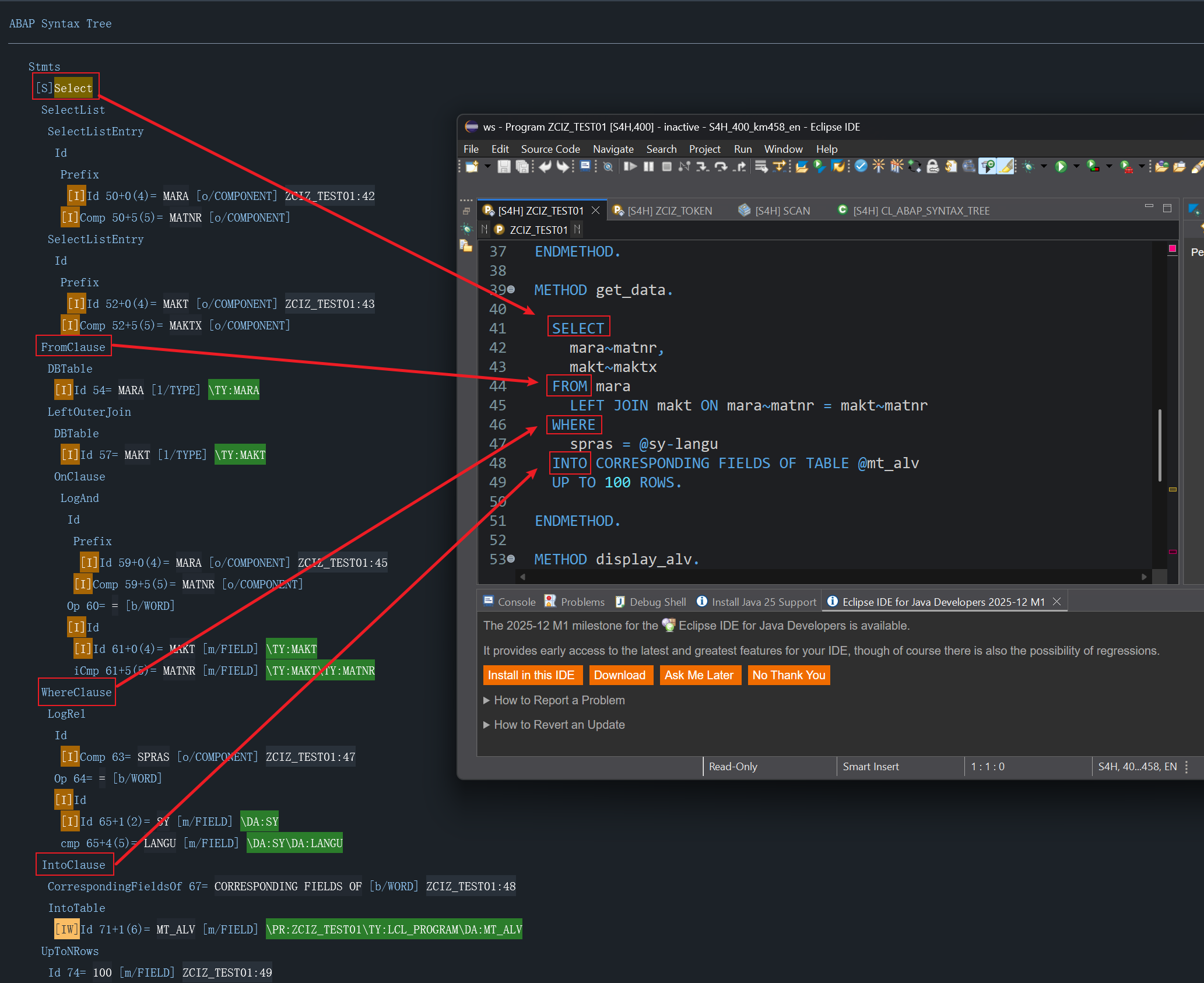
一句简单的SELECT语句,被转换为AST之后其实是相当复杂的一个结构,我仅仅将部分关键字做了标记方便读者查看
仔细查看AST的节点可以总结为三类,当然也不一定准确,只是我自己研究时大概分为了这几类
- 关键字,如Select
- 非关键字(变量),如Id
- 行为(达到什么效果),如比较操作符Op
如上所示的SAP的AST节点共有一千五百余种,可以通过CL_ABAP_SYNTAX_TREE中的属性查看,感兴趣的可以自行尝试
3. ABAP语法分析
上面关于语法分析和AST的定义不了解的可以上CSDN再搜搜看,其他博客有比我讲的更清楚的,在ABAP中这两个内容也是非常相近的,本文聚焦在ABAP如何得到上文的AST以及如何运用AST做代码检测
3.1 输入Token序列
有关此部分的Token序列如何获取,参考上文ABAP 静态代码分析 - 词法分析
3.2 输出AST抽象语法树
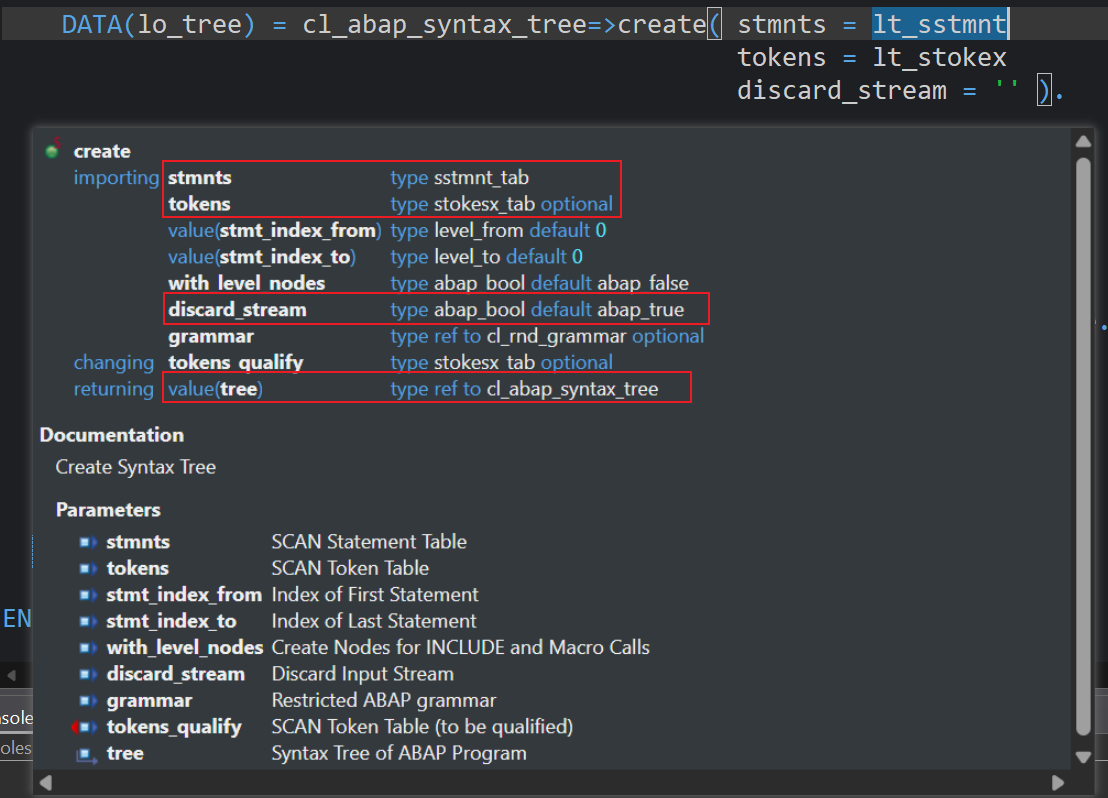
向系统标准类方法CL_ABAP_SYNTAX_TREE=>CREATE输入Statement和Token即可创建AST抽象语法树,前提是代码本身是可以通过检查的
该类中常用的就是CREATE方法,用于构建一个ABAP的AST实例对象,其次就是GET_NODES方法,用于获取遍历为Table后的AST 节点
很遗憾,该类和ABAP AST在任何搜索引擎,任何SAP官方文档,任何个人博客,均未发现任何信息,本文和ABAP AST相关的内容均为团队内部口口相传,经个人总结所得
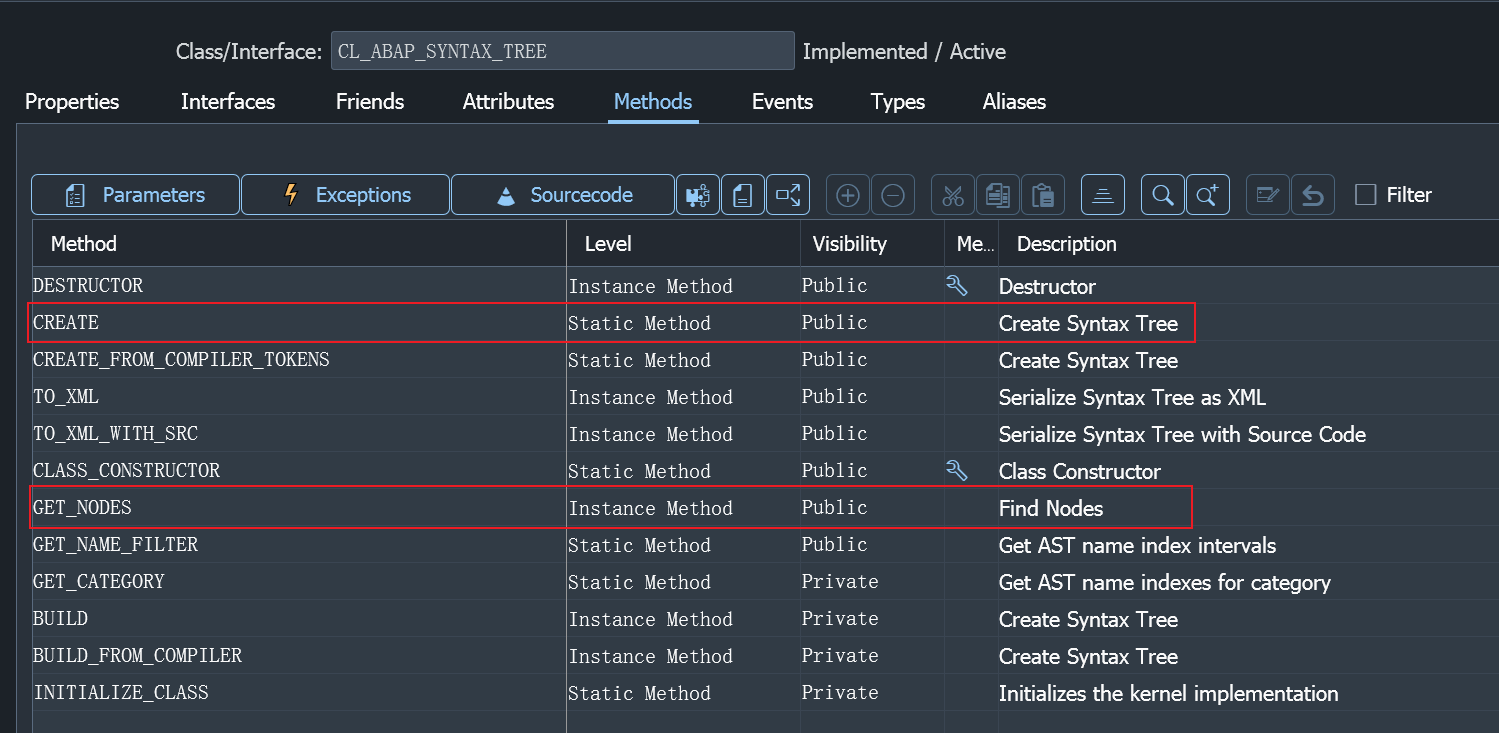
不用费心查看SAP源代码,AST的核心逻辑并未存放在ABAP代码中,而是隐藏在Kernel内核当中,无法被我们直接访问(非常欢迎分享相关文档,如果有我会再做补充)
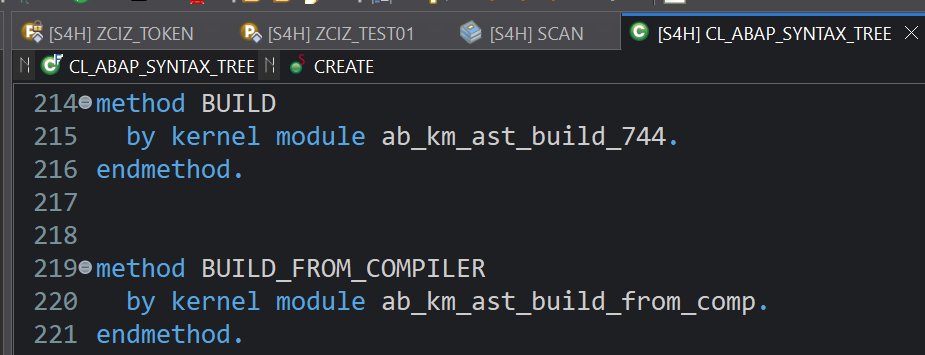
使用该类的build方法可以得到一个实例化后的AST对象,非必填参数我也没办法解释会对结果有什么影响,目前口口相传输入这三个参数即可,调试查看该对象中的属性g_astnames可以看到一千五百余条的AST Node集合
DATA(lo_tree) = cl_abap_syntax_tree=>create( stmnts = lt_sstmnttokens = lt_stokexdiscard_stream = '' ).
使用实例对象的get_nodes方法即可获得前序遍历所有AST节点后输出的AST Node内表
DATA(lt_node) = lo_tree->get_nodes( ).
该内表的结构并非在SE11中声明,而是在类内部作为局部结构声明,为了方便后续长期使用最好在SE11中定义,此处额外声明了name字段用于存放Node名称
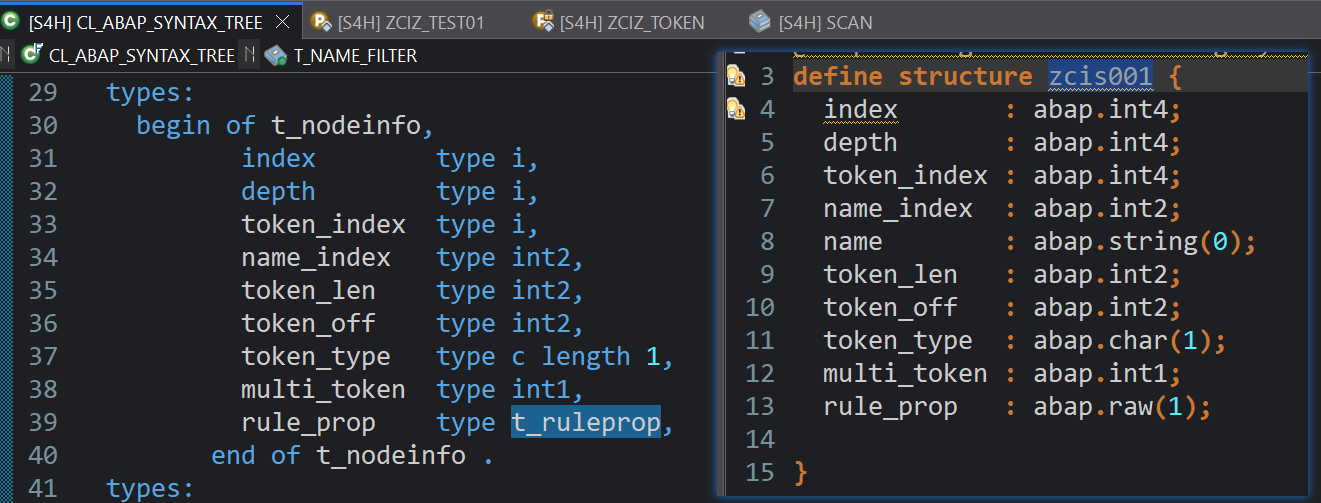
获取到所有的节点后就可以遍历到自定义的数据类型中了
LOOP AT lt_node ASSIGNING FIELD-SYMBOL(<ls_node>).MOVE-CORRESPONDING <ls_node> TO ls_ast_node." Find node name through name_indexls_ast_node-name = lo_tree->g_astnames[ <ls_node>-name_index ]-name.APPEND ls_ast_node TO lt_ast_node.ENDLOOP.
最后结果如下所示,其实可以发现和SAST的结果是一样的
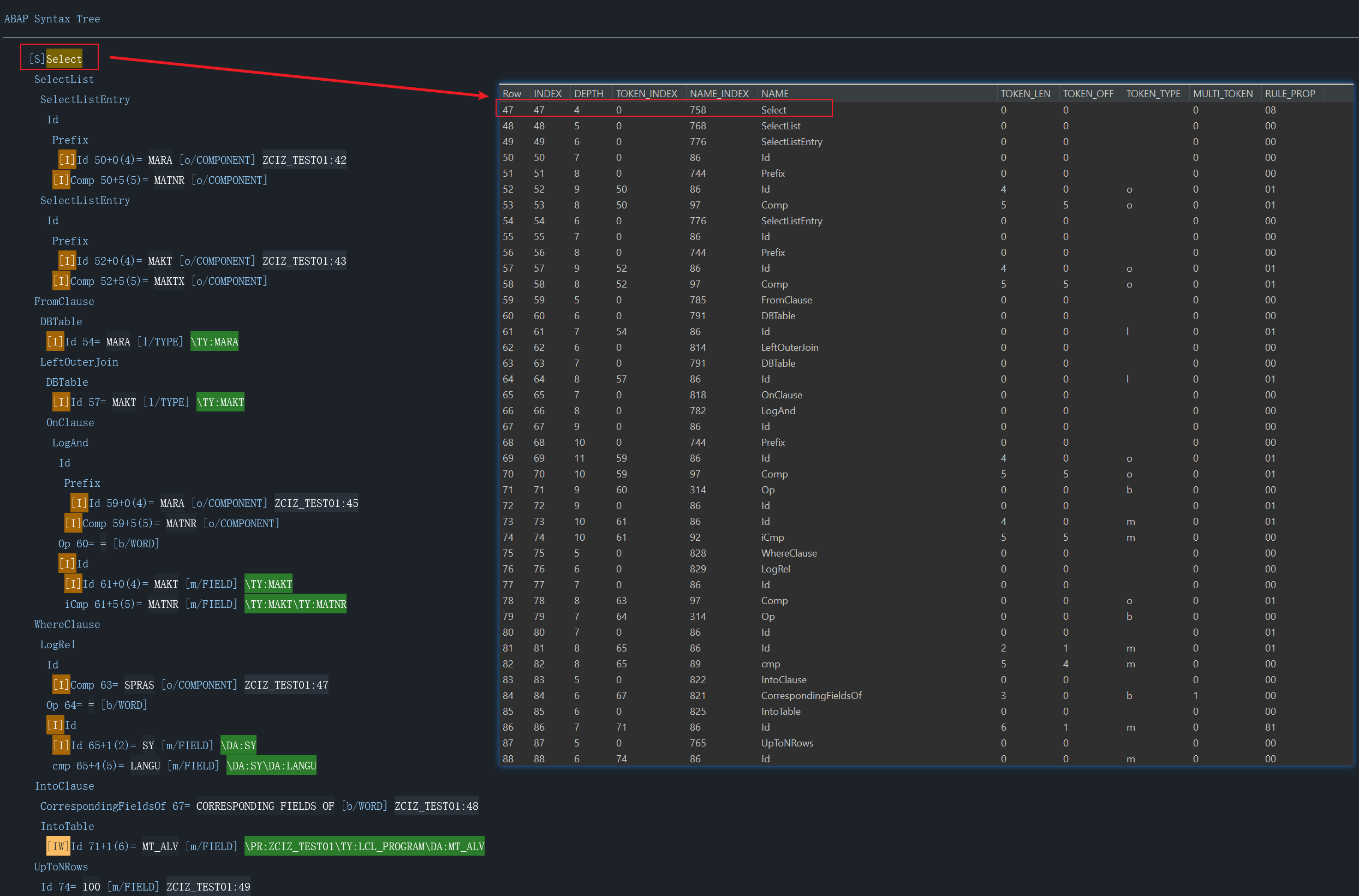
另外补充一些,非关键字一般不是操作符就是变量,如果是变量,那么就可以该AST Node就一定有相应的Token Index用于在Token表中索引到变量名称,而由于AST本身是一个树状结构,程序的层级Structure也很容易用depth字段识别。
最后还有个Statement其实也可以在AST Node中通过特殊手段找到,属性是RULE_PROP,具体方法我没记住,太麻烦了
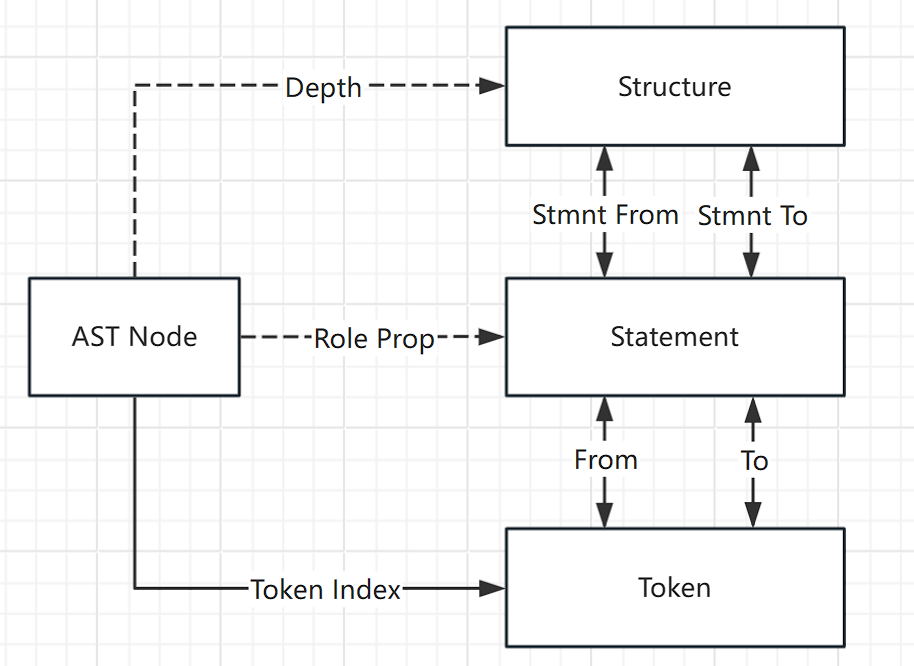
简而言之AST Node一个表就能大致匹配上前文中Structure,Statement,Token三个表的功能,但是毕竟是抽象树,细节还是得回到那三张表找答案,简单画下几个表的关系大概如下,实线是可以直接关联,虚线是间接关联
4. 代码审查场景
其实利用上文的Token,Statement和Structure已经能够做很多的检查了,为什么还要往后去研究AST呢?
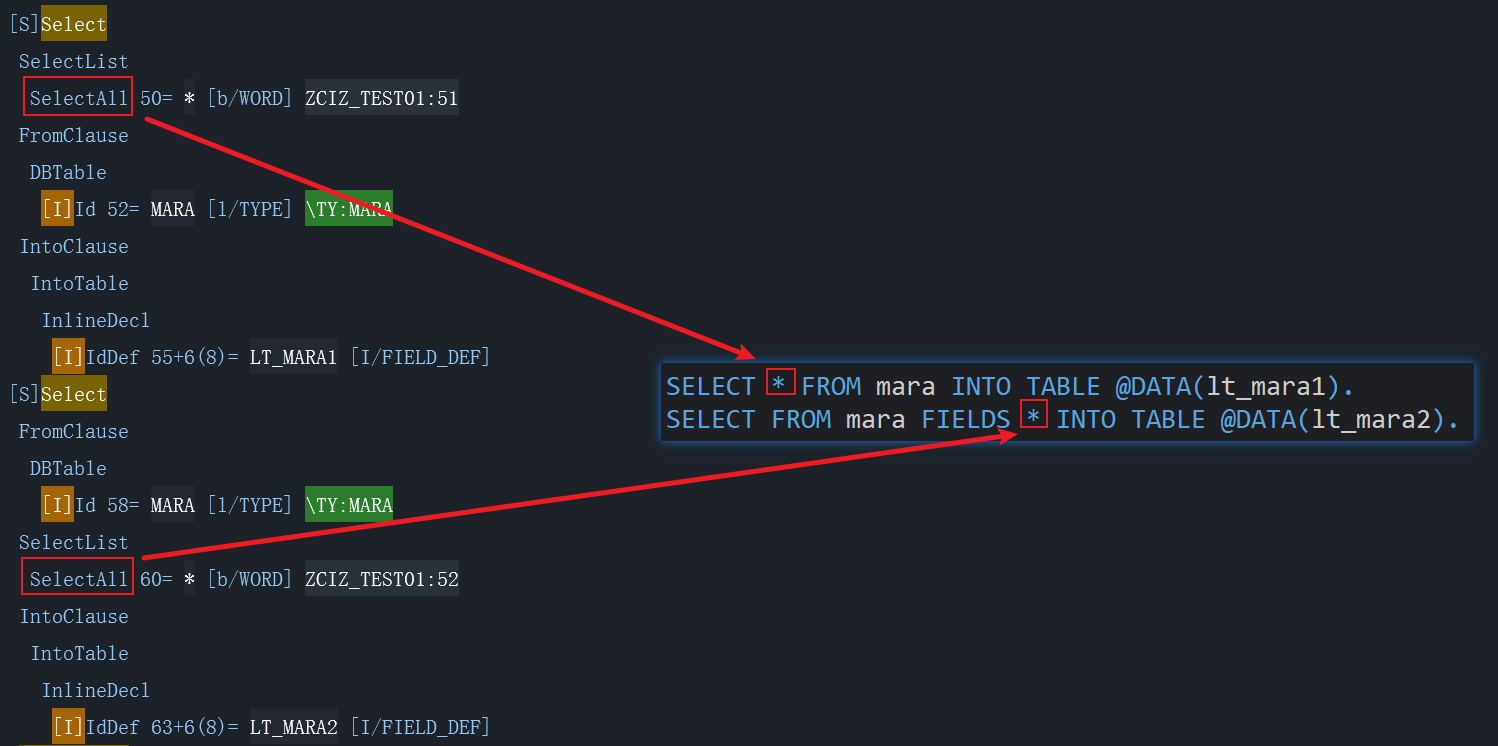
举一个场景,我需要判断SELECT语句中是否在做全表查询的操作,常规写法有
SELECT * FROM mara...SELECT FROM mara FIELDS * ...
要通过Token的方式去做判断稍微有点麻烦,要去遍历每个Token,甄别SELECT 或者FIELDS后出现的第一个字符是否是 *
如果通过AST做是什么样的呢?先简单看下两个语句转换AST后的结果
可以发现AST转换后直接就识别到了 * 操作符在此处是作为SelectAll存在,这是我们在项目中决定继续研究和使用AST的原因之一,相比于自行分析Token流,分析AST得到的结果会更精准
至于使用Token还是AST的分析方式,项目上会根据代码审查的场景做判断,两者在使用上各有千秋,并非绝对要使用AST或者Token
5. AI 总结
这篇内容主要介绍了语法分析和抽象语法树(AST)在ABAP静态代码扫描中的应用。以下是简单总结:
语法分析的作用:
- 是静态代码扫描的关键步骤,负责检查代码结构是否符合语法规则。
- 输入为词法分析生成的令牌序列,输出为抽象语法树(AST),用于后续分析。
抽象语法树(AST):
- 是代码结构的树状表示,省略了空格、注释等无关细节。
- 节点可分为关键字、变量和行为三类。
ABAP中的AST生成:
- 使用CL_ABAP_SYNTAX_TREE=>CREATE方法生成AST,输入为语句和令牌序列。
- AST节点种类丰富(约1500多种),可通过GET_NODES方法遍历。
应用场景:
- AST能更精准地识别代码模式,例如检测SELECT全表查询,比直接分析令牌更高效。
- 结合令牌和AST分析,可根据具体场景选择合适方法进行代码审查。
整体上,AST为代码分析提供了结构化视角,提升了检测的准确性和效率。