Flare 少样本学习嵌入式agent
少样本学习嵌入式智能体的多模态基础规划与高效重规划
摘要
为让机器人助手学习感知与推理模块,从而依据自然语言指令规划步骤以完成复杂任务,通常需要大量自由形式的语言标注,尤其是针对简短的高层级指令。为降低标注成本,大语言模型(LLMs)被用作仅需少量数据的规划器。然而,在细化步骤时,即便采用大语言模型的最先进规划器,也大多依赖语言常识,往往忽视接收指令时的环境状态,进而生成不合适的规划。
为生成基于环境的规划,我们提出FLARE(少样本语言与环境自适应重规划嵌入式智能体,FEW-SHOT LANGUAGE WITH ENVIRONMENTAL ADAPTIVE REPLANNING EMBODIED AGENT)。该模型结合语言指令与环境感知来改进任务规划。由于语言指令常存在歧义或表述错误,我们额外提出利用智能体的视觉线索修正这些错误。
借助视觉线索,所提方案仅需少量语言对即可运行性能优于最先进。我们已公开相关代码与数据集,以助力后续研究。
1 引言
随着计算机视觉、自然语言处理和嵌入式人工智能领域的快速发展,我们见证了能够执行日常任务的机器人助手在核心功能方面的显著提升。这些功能包括导航(Anderson 等人,2018;Chaplot 等人,2017;Uppal 等人,2024)、物体操作(Zhu 等人,2017;Ryu 等人,2024)以及在模拟三维空间(Ge 等人,2024;Chang 等人,2017;Xia 等人,2018;Kim 等人,2024)中的响应式推理(Das 等人,2018;Gordon 等人,2018;Majumdar 等人,2024)。实用的机器人助手需要具备上述所有能力,才能理解语言指令并主动感知环境。
要训练一个能完成此类复杂任务的智能体,一种直接的方法是采用监督学习模式,利用大量自然语言指令与动作对来训练智能体(Shridhar 等人,2020;Ehsani 等人,2024;Pashevich 等人,2021;Blukis 等人,2021;Kim 等人,2023)。然而,对指令进行标注并提供专家动作序列(即导航轨迹)不仅成本高昂,还十分耗时,因此收集足量的语言标注数据往往难以实现。当数据不足时,上述基于数据驱动的方法将无法发挥有效作用(Min 等人,2022;Inoue 和 Ohashi,2022;Bhambri、Kim 和 Choi,2023;Song 等人,2022)。
为了利用少量标注数据训练出能完成长时程任务的智能体,近年来的研究方法(Min 等人,2022;Inoue 和 Ohashi,2022)为特定任务类型设计了人工定义的动作序列。但这类预设动作无法扩展到多种不同类型的任务中。另一类研究则借助大语言模型(LLMs)解决数据不足的问题,充分利用大语言模型中蕴含的先验知识所带来的显著优势。
大语言模型在多个领域的应用中均展现出这样的优势(Zeng 等人,2023;Singh 等人,2023;Driess 等人,2023;Song 等人,2023;Sarch 等人,2023;Wu 等人,2023)。其中,Song 等人(2023)提出将大语言模型用作高层级规划器,并在现有智能体(Blukis 等人,2021)的基础上实现动态基础重规划,该方法仅需极少的人工标注语言数据。但该方法忽略了环境状态,这可能导致生成不合理的规划——因为规划过程通常需要考虑接收指令时的环境状态(例如,智能体所处位置、其视野范围内可见的物体等)。
为修正不合理的规划,Song 等人(2023)通过包含观测物体列表的提示词,多次调用大语言模型以生成基于环境的规划。然而,这种方法对大模型的高度依赖使得其成本超出必要范围,因为即便只有部分子目标存在错误,它也会修正整个序列。
针对上述问题,我们提出了FLARE(少样本语言与环境自适应重规划嵌入式智能体,FEW-SHOT LANGUAGE WITH ENVIRONMENTAL ADAPTIVE REPLANNING EMBODIED AGENT)。该模型在开始规划子目标序列以完成家务任务时,会考虑多模态环境上下文(即视觉输入和语言指令),并且无需使用大语言模型,仅通过视觉输入就能高效地(即部分地)修正规划。
为实证验证该方法的有效性,我们采用了一个广泛使用的嵌入式指令遵循基准测试(Shridhar 等人,2020)。结果表明,仅需少量(如100个)语言与演示对,FLARE就能生成合理的规划;在实证验证中,其性能优于最先进的方法,在未见过的测试分割集上的绝对增益最高可达24.46%。
我们的贡献总结如下:
- 提出一种多模态规划器,在数据量较少的情况下,能同时考虑环境状态和语言指令,以完成长时程任务。
- 提出一种计算高效的环境自适应重规划器,通过视觉线索修正有问题的子目标,无需大语言模型就能生成与环境状态相匹配的规划。
- 在少样本设置下,于ALFRED基准测试(Shridhar 等人,2020)的所有指标上均实现了最先进的性能。
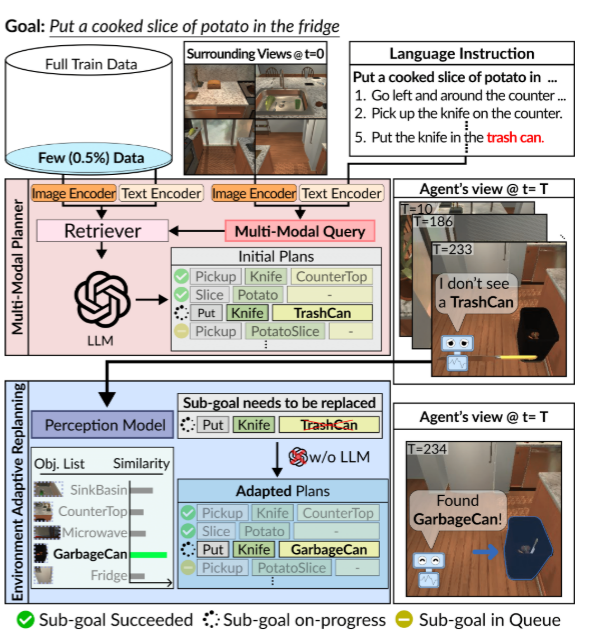
图1:所提出的FLARE的概述。我们的智能体包含(1)多模态规划器(Multi-Modal Planner, MMP),用于通过大语言模型(例如GPT-4)结合初始视角和指令生成子目标;以及(2)环境自适应重规划(EAR),用于在智能体执行计划受阻时,利用视觉线索对未落实的计划进行优化调整。
2 相关工作
我们首先回顾将大语言模型(LLMs)应用于机器人领域(尤其是任务规划方向)的相关研究尝试,随后探讨近年来针对复杂指令遵循任务的各类方法。
用于任务规划的基础模型
随着大型基础模型(即大语言模型与视觉语言模型)的最新发展(Brown 等人,2020;Chen 等人,2021;Zhang 等人,2022;Liu 等人,2023),这类模型已被用作机器人系统中推理(Zeng 等人,2023;Singh 等人,2023;Driess 等人,2023)、规划(Song 等人,2023;Sarch 等人,2023;Yang 等人,2024;Szot 等人,2024)和操作(Wu 等人,2023;Fang 等人,2024)任务的工具。
在机器人规划领域,早期采用大语言模型的方法(Huang 等人,2022)通过迭代优化输入提示词来规划子任务。例如,当智能体未能执行规划动作时,Huang 等人(2023)会利用多轮环境反馈调整初始规划,以弥补执行失败。类似地,Ahn 等人(2022)借助技能可用性价值函数,实现了机器人的规划能力。为直接生成可执行的机器人策略,Singh 等人(2023)与 Liang 等人(2023)设计了结构化的大语言模型提示词。与此同时,VIMA(Jiang 等人,2023)和 PaLM-E(Driess 等人,2023)则通过多模态提示词实现对机器人的控制。
为实现任务类型的扩展,Wang 等人(2024b)的研究表明,通过精心设计的指令,大语言模型能有效指导四足机器人完成运动任务。在开放环境的扩展应用中,相关研究(Fan 等人,2022)提出的智能体(Wang 等人,2024a;Zheng 等人,2024)借助大语言模型构建持续学习型智能体。
尽管这些方法通过大语言模型在机器人规划领域取得了显著进展,但它们需要与大语言模型进行多轮交互以优化或调整机器人行为——若以API调用形式使用,会导致推理成本过高或网络开销过大。相比之下,我们提出的FLARE 在重规划过程中不依赖大语言模型,从而提升了智能体适应当前环境的计算效率。
遵循指令的嵌入式智能体
嵌入式指令遵循任务要求智能体在给定环境中,生成与自然语言指令相符的动作序列。以往的许多研究(Singh 等人,2021;Pashevich 等人,2021;Kim 等人,2021)采用端到端的训练方式,直接从自然语言指令生成低层级动作。同时,有研究提出采用模板化方法规划长时程任务(Min 等人,2022;Inoue 和 Ohashi,2022),这种方法虽具有数据高效性,但仅适用于解决预设任务,无法泛化到新任务中。
由于层级式或模块化规划方法在指令遵循任务中被证明具有有效性(Min 等人,2022;Blukis 等人,2021;Kim 等人,2023;Xu 等人,2024),相关研究开始尝试将大语言模型用作规划器。Song 等人(2023)与 Sarch 等人(2023)的研究中,通过向大语言模型提供少样本上下文示例,将其用作此类任务的高层级规划器——这种少样本提示方式已被证明具有高效性(Brown 等人,2020)。这两种方法均通过计算语言指令嵌入向量的距离,检索若干提示示例。
3 方法
构建成功的嵌入式人工智能(AI)智能体,关键在于生成可执行的基于环境的规划(Murray & Cakmak, 2022;Inoue & Ohashi, 2022;Kim 等人, 2023)。当前最先进的方法(Kim 等人, 2023;Min 等人, 2022;Blukis 等人, 2021;Pashevich 等人, 2021)高度依赖大量数据,这意味着在数据稀缺的学习场景中,这些方法难以发挥作用。然而,考虑到标注自由形式语言指令的成本较高,开发一种仅需少量数据就能训练智能体的实用方法具有重要意义。除了已有研究尝试将大语言模型(LLMs)用作规划器(Ahn 等人, 2022;Huang 等人, 2022, 2023;Sarch 等人, 2023),Song 等人(2023)还提出利用大语言模型实现少样本学习智能体。
但如果没有合适的提示词,大语言模型并非总能生成合理的规划,可能会产生无意义或不切实际的子目标。例如,对于“将煮熟的土豆放入冰箱”这一任务,大语言模型可能会指令智能体“用锡纸包裹土豆”,而“包裹”这一动作是该智能体无法执行的。尽管大语言模型在生成可执行规划方面表现较为出色,但开放词汇描述固有的歧义性和词汇多样性,往往使得基于语言的指令与物理世界之间的关联不够清晰。具体而言,一个学过“沙发(sofa)”概念的智能体,可能无法识别“长沙发(couch)”。这可能导致生成的规划与环境脱节,使得智能体在面对真实场景时(例如,因寻找场景中不存在的物体而无意义地徘徊),无法有效应对这类脱离环境的规划。为解决这一问题,我们提出FLARE模型,该模型通过结合视觉和文本输入,改进嵌入式AI智能体的任务规划能力。此外,我们的方法还利用智能体的视觉观测,实现基于视觉自适应的环境化重规划。
最终,我们的智能体整合了两个核心组件:“多模态规划器(Multi-Modal Planner)”和“环境自适应重规划器(Environment Adaptive Replanning)”。图2展示了FLARE的架构。
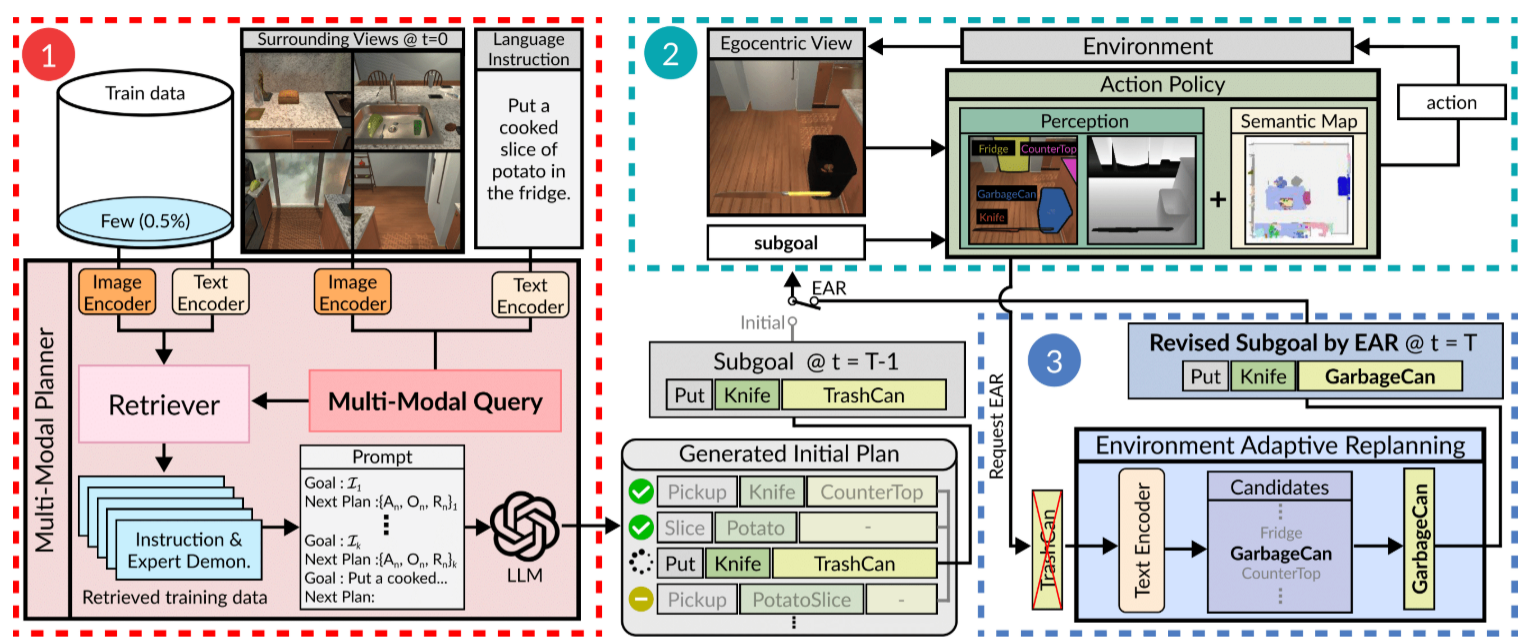
图2:FLARE的详细架构。1. “多模态规划器(MMP)”根据智能体的初始全景周围视图和语言指令,检索出最相关的k个包含指令和专家示范(标记为“专家示范”)的训练数据对,然后通过大语言模型(LLMs)结合这些示例规划出一系列动作。2. 当智能体无法定位目标物体时,会通过EAR请求重新规划。3. 利用视觉观测结果和语义相似性,“环境自适应重规划(EAR)”识别场景中可用的最相似物体,并替换原计划中缺失的物体。
3.1 多模态规划器
为了让智能体通过自然语言指令生成可解释的子目标序列,大语言模型(LLMs)得到了广泛应用(Zeng 等人,2023;Singh 等人,2023;Driess 等人,2023;Wu 等人,2023;Sarch 等人,2023)。例如,Song 等人(2023)和 Sarch 等人(2023)的研究通过计算语言指令的相似度来检索上下文示例,以此提示大语言模型生成子目标。受这些研究启发,我们提出“多模态规划器(MMP)”——该规划器仅需少量标注数据,就能在接收指令时同时考虑自然语言指令和智能体的第一视角周围环境视图,从而反映环境状态。多模态规划器的具体结构如图3所示。
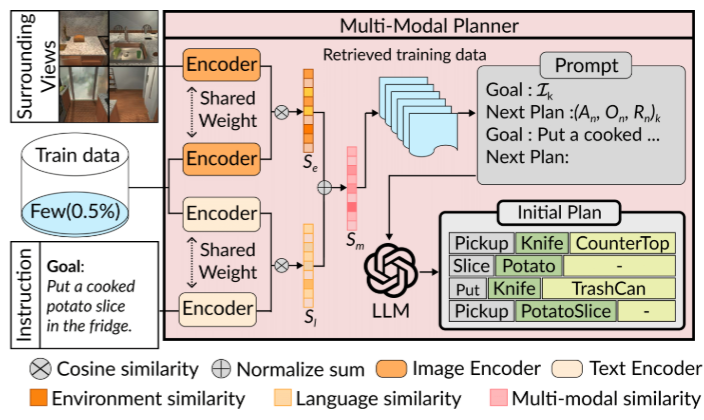
图3:多模态规划器。MMP 使用“多模态相似度”(公式 (1))选择最相似的 k 个专家示范,并将其转换为子目标三元组(An, On, Rn),这些三元组用于引导大语言模型(LLM)根据自然语言指令生成特定任务的子目标序列。
多模态相似度
大语言模型的上下文学习能显著提升其在各类语言任务中的性能(Brown 等人,2020)。这种学习方式通过在提示词中加入明确上下文,帮助模型更好地理解和响应详细的语言指令。要利用大语言模型实现少样本学习,关键在于精心筛选与当前任务相关的示例——这类相关示例能帮助大语言模型生成更合适的子目标。例如,对于“清洁抹布”这一任务,选择“清洁叉子”或“洗碗”等同类主题的示例作为提示,比选择“加热苹果”等无关任务示例更具策略合理性。
Song 等人(2023)和 Sarch 等人(2023)的研究通过计算语言指令嵌入向量的距离来筛选相关示例,但在生成规划时并未考虑环境状态(即视觉信息)。这可能导致为当前任务筛选出不合适的示例,例如在没有刀具的场景中,筛选出“用刀削苹果”的示例。
为纳入环境状态信息,我们首先获取智能体接收指令时的周围环境视图,然后利用冻结的BERT模型(Devlin 等人,2018)对文本指令进行嵌入,利用冻结的CLIP-VIT编码器(Radford 等人,2021)对图像进行嵌入,以此衡量每个训练示例与当前任务的匹配程度。
形式上,设(S_{l}={s_{l, 1}, s_{l, 2}, …, s_{l, N}})和(S_{e}={s_{e, 1}, s_{e, 2}, …, s_{e, N}})分别表示语言相似度集合和环境相似度集合,其中(s_{l, i})和(s_{e, i})分别代表当前任务与训练集中第(i)个示例之间的语言相似度和环境相似度(通过计算各嵌入向量的余弦相似度得到)。随后,我们通过对这两类相似度得分进行归一化求和,计算当前任务与训练集中任务的多模态相似度((S_{m})),公式如下:
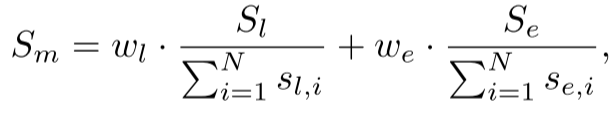
其中(w_{l})和(w_{e})分别表示语言指令相似度和环境相似度的权重。基于多模态相似度得分,我们从训练数据中检索出相似度最高的==(k)个示例==,将这些示例作为大语言模型生成子目标时的上下文学习示例,从而引导大语言模型生成更准确的子目标。
子目标表示
将语言指令转化为子目标是机器人推理的核心环节之一。例如,“将苹果从台面移到餐桌”这一任务可分解为包含导航和物体交互的子目标,如[导航至台面]、[拿起苹果]、[导航至餐桌]、[放置苹果]。为缩短指令集的总长度,我们提出一种中间子目标表示方式,即通过三元组[拿起,苹果,台面]和[放置,苹果,餐桌]来表示上述子目标。
形式上,对于给定的任务指令(I),我们将子目标表示为:
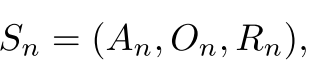
其中(n \in{1, …, K})((K)为子目标序列的总数量),(A_{n})表示高层级动作(如“拿起”或“清洁”),(O_{n})表示动作的目标物体,(R_{n})表示目标物体所在的容器/位置。与 Song 等人(2023)的方法相比,该表示方式可减少25%的 tokens 用量。
3.2 环境自适应重规划
尽管大型语言模型(LLMs)具备出色的规划能力,但它们生成的规划往往无法与智能体实际部署的环境充分适配。这一问题源于自然语言指令中固有的词汇多样性。例如,对于“将装有黄油刀和一片水果的托盘放在桌子上”这一任务,智能体需要先找到待切片的水果。然而,若智能体在训练过程中未学习过该水果类别的导航相关知识,就可能导致导航失败,进而可能使整个任务失败。
为解决这一问题,本文提出的“环境自适应重规划(EAR)”模块会将未检测到的物体替换为当前已观测到的物体中语义最相似的对象,以此修正子目标。具体而言,EAR会先维护一个列表,记录智能体在执行任务过程中已观测到的所有物体。对于每个子目标,若智能体无法到达导航目标(即公式2中的(O_{n})或(R_{n})),EAR会判定该指定物体不存在于当前环境中,并将其替换为语义相似的物体。
在替换当前不可用物体时,EAR会从候选物体(即已观测到的物体)中筛选出语义最相似的对象。为衡量语义相似度,本文计算了两个物体类别名称的语言表示之间的余弦相似度。具体步骤为:EAR首先利用预训练语言模型(Devlin et al., 2018; Raffel et al., 2020; Brown et al., 2020),分别获取当前目标物体和已观测物体名称的语言表示;随后,基于这些表示计算已观测物体与当前目标物体的相似度得分。
从数学角度,相似度得分的计算及语义最相似物体的筛选过程可表示为:
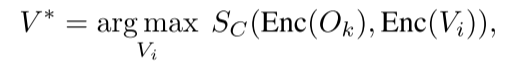
其中,(V^{*})表示使余弦相似度(S_{C}(\cdot, \cdot))最大化的物体;(O_{k})为当前目标物体;(V_{i})为截至当前已检测到的第(i)个物体;(Enc(\cdot))代表语言编码器;(S_{C}(\cdot, \cdot))代表两个嵌入向量的余弦相似度。需注意,(O_{k})既可以是公式2中的(O_{n})(动作目标物体),也可以是(R_{n})(动作接收物体)。关于EAR的详细工作流程,可参考图4。
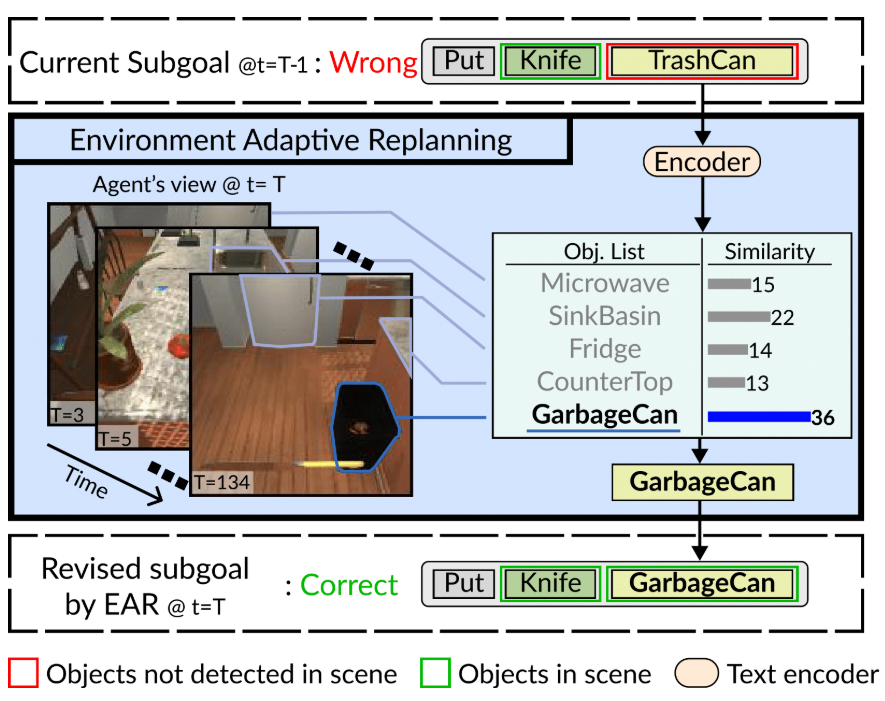
图4:环境自适应重规划。EAR 通过列出检测到的物体并计算语义相似度,来替换计划中引用不准确的物品,从而修正计划。这确保了计划与实际环境相契合
3.3 动作策略
在进行物体交互时,智能体需先导航至目标物体所在位置,并移动到其附近区域。对于导航任务,一种可行的方法是采用模仿学习(Shridhar et al., 2020; Singh et al., 2021; Pashevich et al., 2021; Nguyen et al., 2021)。然而,这种方法需要大量训练 episodes 才能实现理想性能,而收集这些训练数据往往需要耗费大量成本与时间,在本研究场景下(训练数据收集成本高、难度大),这种需求通常难以满足。
为规避这一问题,近年来的相关研究(Inoue and Ohashi, 2022; Kim et al., 2023)引入了确定性算法(如A*算法、快速行进法FMM(Sethian, 1996)等)用于无障碍物路径规划,与模仿学习相比,该方法能显著提升规划性能。基于这些研究发现,本研究采用确定性方法(Sethian, 1996)以实现高效的路径规划。

四、实验
4.1 实验设置
为验证所提方法与不同模型的兼容性,我们在FLARE中采用了四种大型语言模型,涵盖闭源模型与开源模型。具体而言,闭源模型选用GPT-4和GPT-3.5,开源模型则选用LLaMA2-13B(Touvron et al., 2023)与Vicuna-13B(Zheng et al., 2023)。为与现有研究(Song et al., 2023)进行公平对比,我们参照其设置选择9个上下文示例(即(k=9));同时,在公式(1)中将语言相似度权重(w_{l})与环境相似度权重(w_{e})设为相同值,以平等对待两种模态信息。
4.2 数据集与评估指标
我们在ALFRED基准测试(Shridhar et al., 2020)中验证FLARE的有效性。该基准测试要求智能体在交互式3D环境(Kolve et al., 2017)中,依据自然语言指令和以智能体为中心的观测信息完成家务任务。验证集与测试集均包含==“已见过”(seen)和“未见过”(unseen)两种场景==:其中“已见过”场景是训练数据的一部分,而“未见过”场景则代表用于评估的全新、陌生环境。
为评估FLARE在人类语言对稀缺场景下的效率,我们采用与先前研究(Song et al., 2023)相同的少样本设置(0.5%)。为与现有方法进行公平对比,我们使用了与(Song et al., 2023)相同数量的示例(即100个示例)。所选的100个示例涵盖了全部7种任务类型,以公平代表21,023个训练示例的整体分布。
在评估过程中,我们遵循(Shridhar et al., 2020)提出的评估协议。主要评估指标为成功率(SR),用于衡量任务完成的百分比;目标条件成功率(GC),用于衡量目标条件满足的百分比。此外,我们还通过智能体运动轨迹的路径长度对成功率和目标条件成功率进行惩罚,得到评估智能体效率的指标——路径长度加权成功率(PLWSR) 和路径长度加权目标条件成功率(PLWGC)。
4.3 与现有最优方法的对比
我们首先将所提方法与现有最优方法(Blukis et al., 2021; Min et al., 2022; Kim et al., 2023; Song et al., 2023)进行对比,并将结果汇总于表 1 中。参照(Min et al., 2022; Kim et al., 2023; Blukis et al., 2021)的评估方式,我们分别报告了智能体在两种设置下的性能:1)仅使用目标描述(记为 “仅目标指令”);2)同时使用目标描述与分步指令(记为 “目标指令 + 分步指令”)。
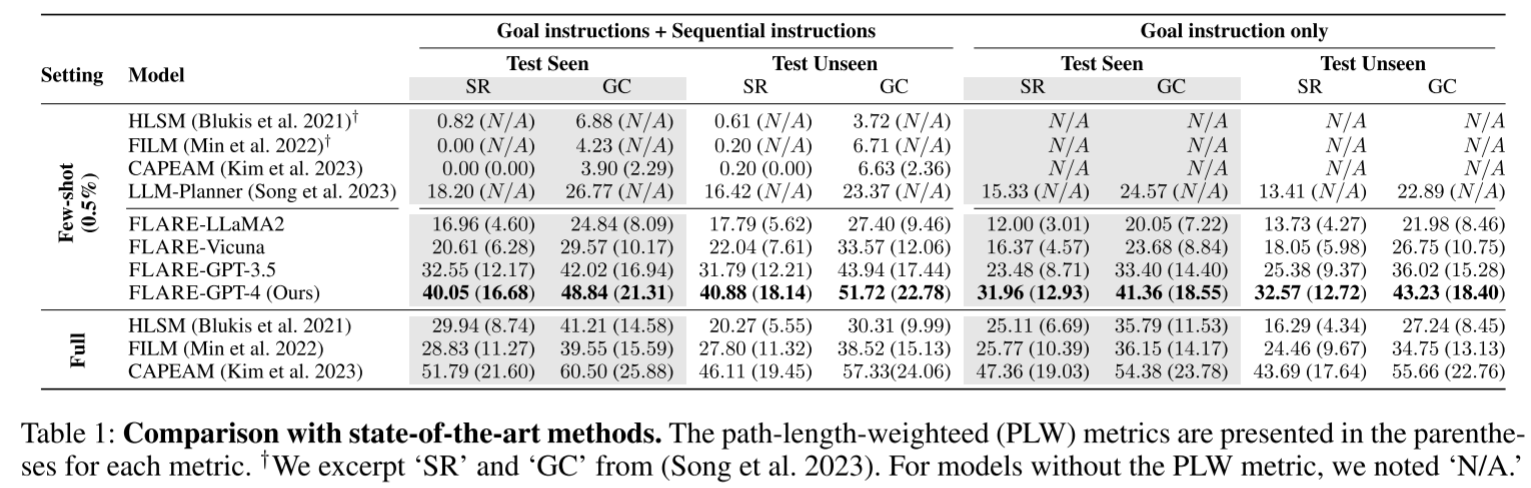
表 1:与现有最优方法的对比结果。括号内数值为路径长度加权(PLW)指标结果。†部分 “成功率(SR)” 与 “目标条件成功率(GC)” 数据摘录自(Song et al., 2023)。对于未提供路径长度加权(PLW)指标的模型,标注为 “无数据(N/A)”。
首先我们观察到,对于 HLSM、FILM 和 CAPEAM 这类需要大量数据训练规划器的方法,从全量数据设置切换到少样本设置时,性能出现了显著下降。这表明,在训练样本有限的情况下,学习具备任务执行能力的智能体面临着巨大挑战 ——因为数据稀缺问题会阻碍(智能体对相关任务知识的)学习进程。
接下来,我们将结果与近期一项采用大型语言模型(LLMs)的研究(Song et al., 2023)进行对比,该研究仅通过少量训练样本实现任务学习。正如(Zheng et al., 2023)所示,我们同时考察了闭源和开源语言模型,其中也包括性能相对较低的对比模型。
即便使用性能相对较弱的语言模型(如LLaMA2(Touvron et al., 2023)),我们所提出的智能体在“目标指令+分步指令”和“仅目标指令”两种设置下,在未见过场景的所有指标上仍表现更优,这充分证明了我们方法的有效性。此外,正如预期的那样,使用GPT-4等性能更优的语言模型,能显著提升智能体性能,提升幅度最高可达24.46%。
规划器准确率对比
为探究生成动作序列的初始规划器(即静态规划)的性能,我们移除了现有方法及我们方法中的重规划策略,将我们智能体的准确率与近期基于大型语言模型的规划方法(Song et al., 2023; Ahn et al., 2022)进行对比,并将结果汇总于表2中。
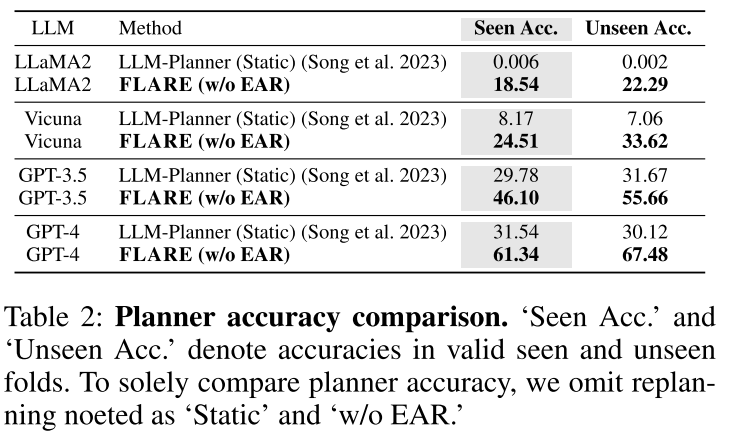
为排除大型语言模型在规划过程中的干扰因素,我们对采用不同大型语言模型的方法进行了验证。结果显示,配备了多模态规划器(MMP)、记为“FLARE(不含EAR)”的我们的智能体,在所有语言模型的测试中,无论是已见过场景还是未见过场景,其准确率均以显著优势优于先前研究(Song et al., 2023)。这表明,我们多模态规划器(MMP)所带来的性能提升,并非源于特定语言模型的选择。
4.4 消融研究
我们进行了一项定量的消融研究,以分析 FLARE 中提出的各个组件,并将结果总结在表 3 中。由于 GPT-4 的 token 生成成本显著更高,我们选择 GPT-3.5 作为语言模型。
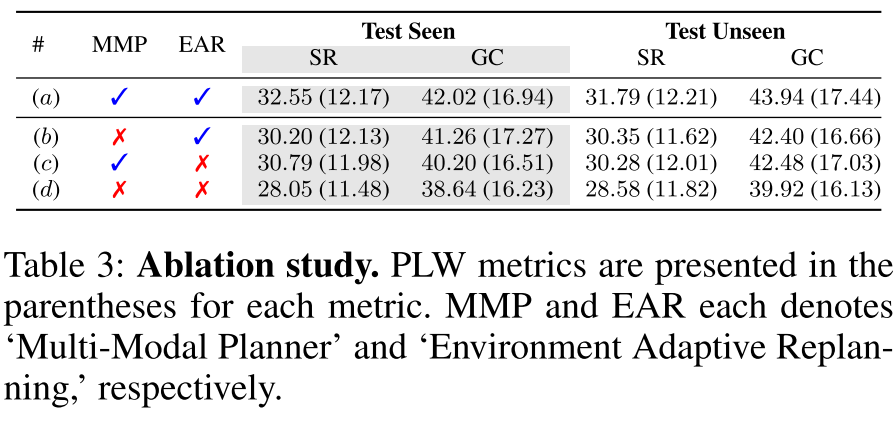 图3:消融实验。PLW 指标显示在每个指标的括号中。 MMP 和 EAR 分别表示“多模式规划器”和“环境自适应重新规划”。
图3:消融实验。PLW 指标显示在每个指标的括号中。 MMP 和 EAR 分别表示“多模式规划器”和“环境自适应重新规划”。
Path-Length-Weighted 路径长度加权。根据您提供的论文内容,PLW 是 Path-Length-Weighted 的缩写,意为“路径长度加权”。
在论文的 4.2 节 数据集与指标 (Dataset and Metrics) 中对此有明确解释:
Furthermore, we assess the efficiency of agents penalizing SR and GC (i.e., PLWSR and PLWGC) with the path length of a trajectory taken by the agents.
此外,我们通过代理所采取轨迹的路径长度来惩罚SR和GC(即PLWSR和PLWGC),以评估代理的效率。
简单来说,PLW 是一种对成功率(SR)和目标条件成功率(GC)进行“打折扣”的评估方式。如果一个智能体虽然完成了任务,但走了很长、很绕的路,那么它的 PLW 分数就会比基础的 SR 或 GC 分数低。这使得 PLW 成为一个更能衡量智能体执行效率的指标,而不仅仅是任务是否完成。
因此,在图3(应为表3,Table 3)的脚注中,“PLW metrics are presented in the parentheses for each metric” 的意思是:每个主要指标(SR 和 GC)后面的括号内的数值,是其对应的路径长度加权版本(即 PLWSR 和 PLWGC)。
无多模态规划器。 首先,我们从方法中移除“MMP”(多模态规划器),此时代理仅考虑单模态相似性,从数据集中检索上下文示例,从而在规划时忽略环境状态。在没有所提出组件的情况下,我们基于指令相似性选择上下文示例。由于提示仅反映单一模态,代理可能会忽略环境线索并误解任务需求,导致在“seen”和“unseen”两个数据集上的性能下降,如(#(a) 与 #(b) 对比)所示。
无环境自适应重规划。 接着,我们从代理中移除“EAR”(环境自适应重规划)。没有 EAR,代理无法处理语言变化,常常误解自然语言指令,从而导致错误的子目标。我们观察到,在“seen”和“unseen”两个数据集上,成功率(SR)均出现了明显的性能下降(分别为 1.76 和 1.51 个百分点),如(#(a) 与 #© 对比)所示。这表明,大型语言模型(LLM)常常无法生成与代理所处环境相匹配的计划,导致代理在寻找可能并不存在的物体时不断徘徊,最终导致任务失败。
两者皆无。 在没有任何所提出组件的情况下,代理将遵循初始计划,而该计划可能与当前任务不符。正如预期的那样,性能进一步下降,如(#(a) 与 #(d) 对比)所示。
4.5 定性分析
我们用几个定性结果分析了我们的方法,并在图 5 和图 6 中说明了结果。
多模态规划器(MMP)的效果验证
为探究多模态规划的优势,我们在图5中展示了一个定性示例。由于多模态规划器(MMP)会通过多模态查询为当前任务检索相关示例,这有助于引导大型语言模型(LLM)生成更合理的子目标。
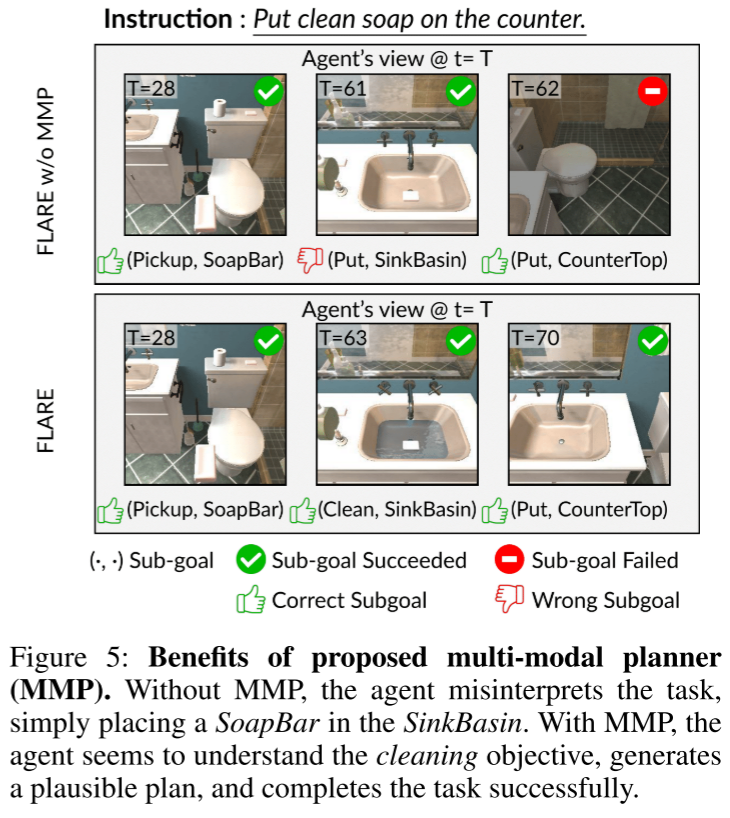
图5:所提出的多模态规划器(MMP)的优势。没有MMP时,智能体误解了任务,只是简单地将香皂放入洗漱盆中。而使用MMP后,智能体似乎理解了清洁任务的目标,生成了一个合理的计划,并成功完成了任务。
我们观察到,未配备MMP的智能体无法生成恰当的子目标——它无法理解语言指令中的任务上下文,进而出现将肥皂块(SoapBar)放置在洗手池台(SinkBasin)上的错误操作。随后,该智能体因手部无待操作物体(空手状态),无法执行“放置(Put)”动作,导致后续子目标序列无法推进。与之相反,配备了MMP的智能体能够成功从LLM中提取先验知识,生成符合任务需求的子目标序列:拿起肥皂块、在洗手池台中清洗肥皂块,最终将其放置在操作台(CounterTop)上。
环境自适应重规划(EAR)的效果验证
接着,我们验证环境自适应重规划(EAR)的作用。当智能体无法定位指定物体时,EAR会借助视觉线索对脱离环境实际的规划进行适配修正。
由于自然语言中对同一物体存在多种表述方式,LLM可能会因这种词汇多样性产生脱离环境的子目标。例如,图6展示了这样一个场景:指令要求智能体“将装有遥控器的盒子放在带有雕像的台阶上”。LLM为充分利用指令信息,生成了“(放置,盒子,带雕像的台阶(StatueStep))”这一子目标,导致智能体手持盒子却在场景中四处搜寻“带雕像的台阶(StatueStep)”,陷入执行困境。
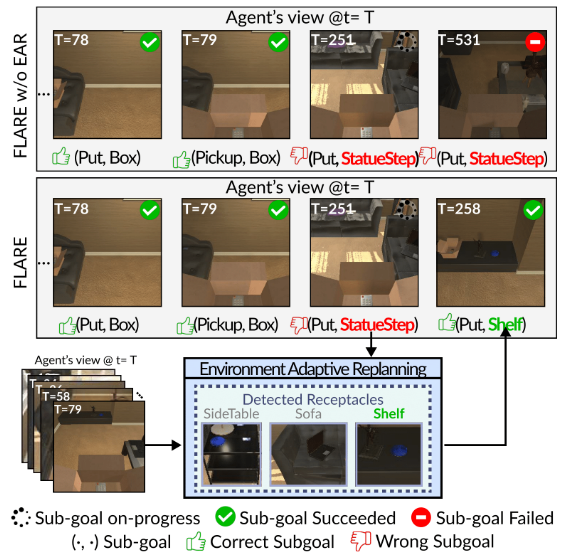
图6:所提出的环境自适应重规划(EAR)的优势。当智能体无法找到指定物体时,EAR通过选择语义上最相似的已检测到的替代物体来调整计划。
我们观察到,未配备EAR的智能体无法判断当前子目标是否恰当(即“带雕像的台阶(StatueStep)”在场景中并不存在),只能在场景中无意义地徘徊,且无法确定放置物体的目标容器。相反,配备了EAR的智能体起初虽也会搜寻“带雕像的台阶(StatueStep)”,但很快会意识到该物体可能不存在于当前场景中。随后,EAR会将这一不恰当的目标物体替换为场景中存在的、语义最相近的物体(即“带雕像的架子(StatueShelf)”替换为“架子(Shelf)”),智能体进而执行修正后的子目标,完成任务操作。
4.6 在机器人任务规划中的应用
我们展示了所提出的 FLARE 方法在其他机器人任务应用中的可扩展性。具体来说,我们使用了一个带有 UR5 机械臂的模拟桌面环境,并在图7中展示了 FLARE 与基线模型的对比。我们选择 (Zeng et al. 2023) 作为基线模型,因为它在少样本机器人规划方面表现出色。两个模型都使用 GPT-3.5 作为大语言模型(LLM)来生成子目标,并采用了一种享有特权的底层策略,该策略利用环境的元数据来预测末端执行器的姿态。
Instruction: Place a lemon and a tool in each corner.说明:在每个角落各放置一个柠檬和一个工具。
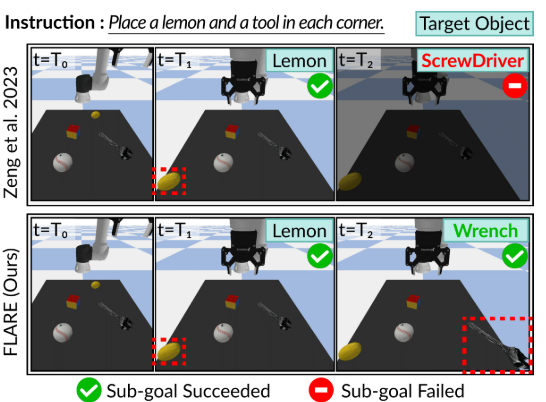
图7:机器人任务应用的一个示例。基线方法(Zeng 等,2023)由于指令模糊(例如“tool”工具),生成了一个未落实的计划;而FLARE则生成了与实际环境相符的可行计划,并成功执行了动作。
我们观察到,FLARE 成功地按照指令重新排列了物体,展示了其在为具身化执行进行规划方面的能力。相比之下,基线模型 (Zeng et al. 2023) 因规划脱离实际环境而失败(例如,试图拾取环境中并不存在的螺丝刀)。
总结
我们提出了FLARE,它配备了一种多模态规划器,能够结合视觉输入所反映的环境状态和语言指令,仅用少量数据即可生成详细的计划(即子目标),以完成长视野任务。此外,当计划出现错误时,该方法仅修正 不正确的子目标子集,从而生成符合物理环境的可行计划,且无需调用大语言模型(LLMs),实现了计算高效的重规划。我们在ALFRED数据集(Shridhar 等,2020)上对所提出方法的有效性进行了实证验证,结果表明,在少样本设置下,FLARE在所有指标上均显著优于当前最先进的方法。
局限性与未来工作。尽管我们的方法仅需极少量的训练数据(0.5%),但仍依赖于训练数据。我们的未来目标是开发一种智能体,能够在大型语言模型的辅助下,通过自主探索来学习环境知识,而无需任何预先的训练数据。