Redis分布式集群:从分区算法到扩容实战
Redis 分布式系统,官方称为 Redis Cluster,Redis 集群,其是 Redis 3.0 开始推出的分布式解决方案。其可以很好地解决不同 Redis 节点存放不同数据,并将用户请求方便地路由到不同 Redis 的问题。
一、数据分区算法
分布式数据库系统会根据不同的数据分区算法,将数据分散存储到不同的数据库服务器节点上,每个节点管理着整个数据集合中的一个子集。
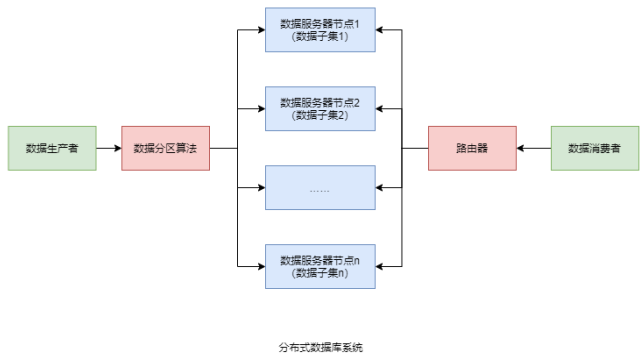
常见的数据分区规则有:顺序分区和哈希分区;
1.1 顺序分区
顺序分区规则可以将数据按照某种顺序平均分配到不同的节点。
1.1.1 轮询分区算法
每产生一个数据,就要依次分配到不同的节点。该算法适合于数据问题不确定的场景。其分配的结果是,在数据总量非常庞大的情况下,每个节点中数据是很平均的。但生产者与数据节点间的连接要长时间保持。
1.1.2 时间片轮转分区算法

1.1.3 数据块分区算法
在整体数据总量确定的情况下,根据各个节点的存储能力,可以将连接的某一整块数据分配到某一节点。
1.1.4 业务主题分区算法
1.2 哈希分区
哈希分区规则是充分利用数据的哈希值来完成分配,对数据哈希值的不同使用方式产生了不同的哈希分区算法。
1.2.1 节点取模分区算法
该算法的前提是,每个节点都已分配好了一个唯一序号,对于 N 个节点的分布式系统,其序号范围为[0, N-1]。然后选取数据本身或可以代表数据特征的数据的一部分作为 key,计算 hash(key)与节点数量 N 的模,该计算结果即为该数据的存储节点的序号。
如果分布式系统扩容或缩容,已经存储过的数据需要根据新的节点数量 N 进行数据迁移,否则用户根据 key 是无法再找到原来的数据的。生产中扩容一般采用翻倍扩容方式,以减少扩容时数据迁移的比例。
1.2.2 一致性哈希分区算法
一致性 hash 算法通过一个叫作一致性 hash 环的数据结构实现。这个环的起点是 0,终点是 ,并且起点与终点重合。环中间的整数按逆/顺时针分布,故这个环的整数分布范围是
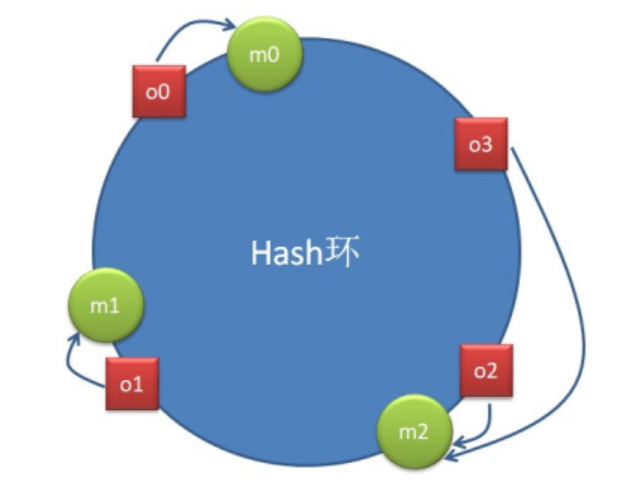
上图中存在四个对象 o0、o1、o2、o3,分别代表四个待分配的数据,红色方块是这四个数据的 hash(o)在 Hash 环中的落点。同时,图上还存在三个节点 m0、m1、m2,绿色圆圈是这三节点的 hash(m)在 Hash 环中的落点。
现在要为数据分配其要存储的节点。该数据对象的 hash(o) 按照逆/顺时针方向距离哪个节点的 hash(m)最近,就将该数据存储在哪个节点。该算法的最大优点是,节点的扩容与缩容,仅对按照逆/顺时针方向距离该节点最近的节点有影响,对其它节点无影响。
当节点数量较少时,非常容易形成数据倾斜问题,且节点变化影响的节点数量占比较大,即影响的数据量较大。所以,该方式不适合数据节点较少的场景。
1.2.3 虚拟槽分区算法
该算法首先虚拟出一个固定数量的整数集合,该集合中的每个整数称为一个 slot 槽。这个槽的数量一般是远远大于节点数量的。然后再将所有 slot 槽平均映射到各个节点之上。例如,Redis 分布式系统中共虚拟了 16384 个 slot 槽,其范围为[0, 16383]。假设共有 3 个节点,那么 slot 槽与节点间的映射关系如下图所示:
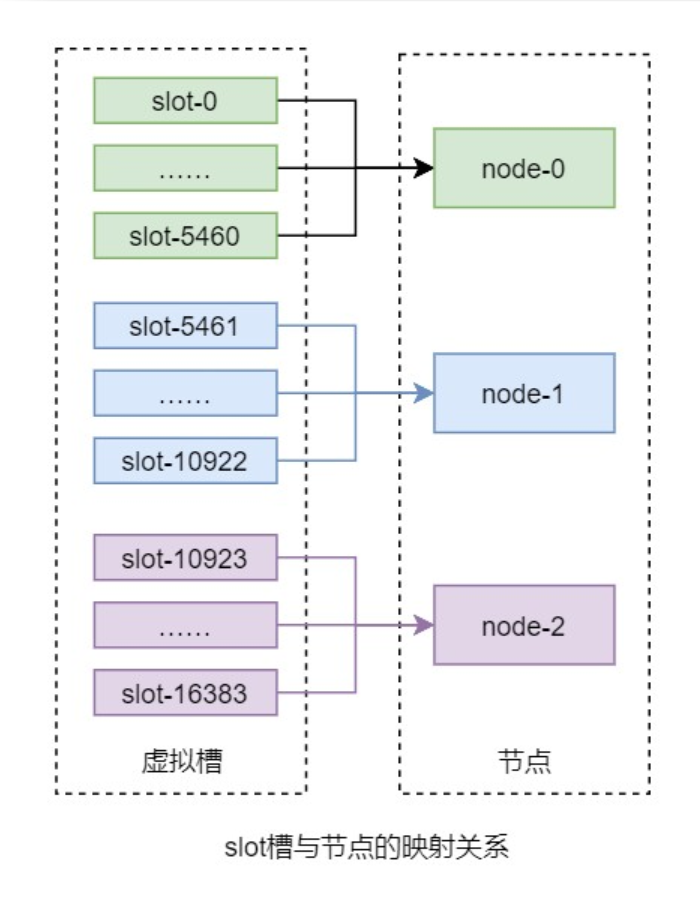
而数据只与 slot 槽有关系,与节点没有直接关系。数据只通过其 key 的 hash(key)映射到 slot 槽:slot = hash(key) % slotNums。这也是该算法的一个优点,解耦了数据与节点,客户端无需维护节点,只需维护与 slot 槽的关系即可。

二、系统搭建与运行
2.1 配置文件redis.conf修改
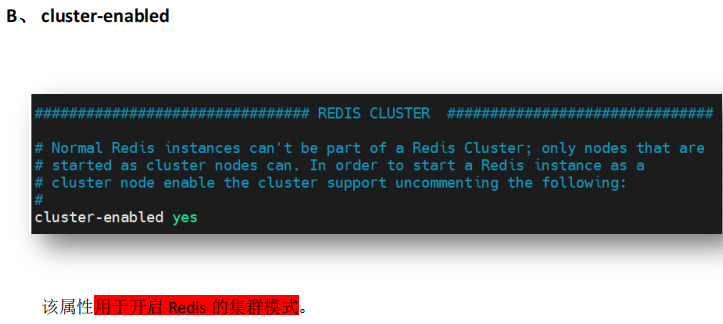
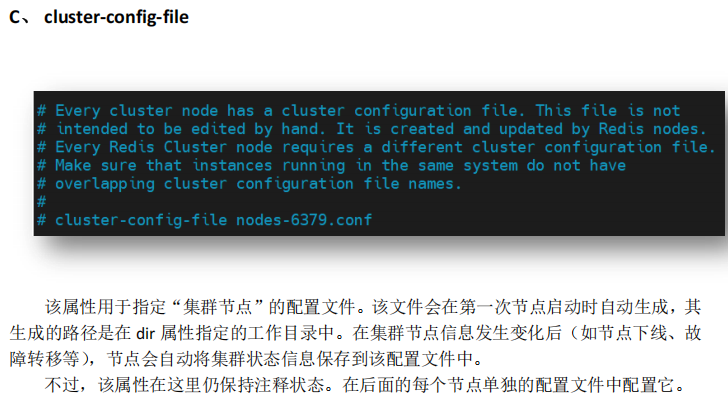
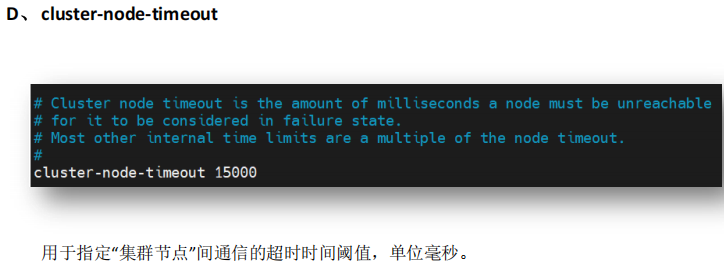
2.2 修改redis6380.conf
include redis.conf
pidfile /var/run/redis_6380.pid
port 6380
dbfilename dump6380.rdb
appendfilename appendonly6380.aof
replica-priority 90# 仅仅添加当前属性
cluster-config-file nodes-6380.conf# logfile logs/access6380.log复制配置文件
2.3 系统启动与关闭
2.3.1 启动Redis节点
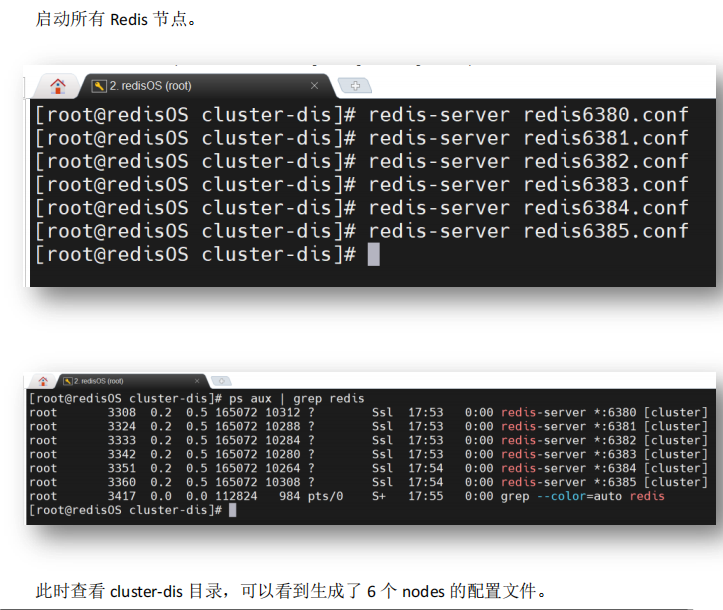
2.3.2 创建系统
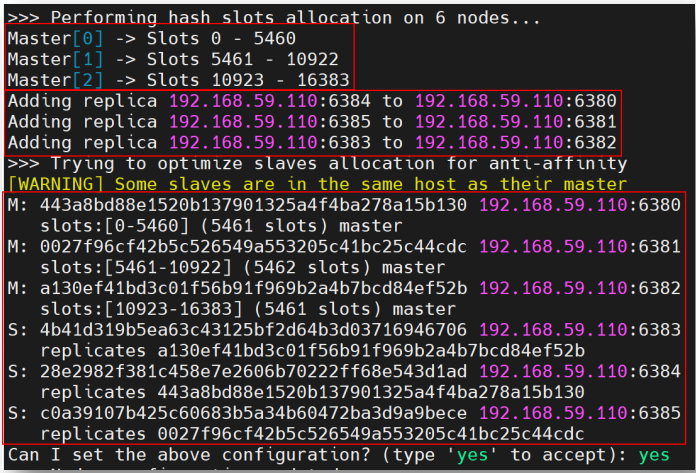
6 个节点启动后,它们仍是 6 个独立的 Redis,通过 redis-cli --cluster create 命令可将 6 个节点创建了一个分布式系统。
redis-cli --cluster create --cluster-replicas 1
# 该命令用于将指定的 6 个节点连接为一个分布式系统
# --cluster replicas 1 指定每个 master 会带有一个 slave 作为副本
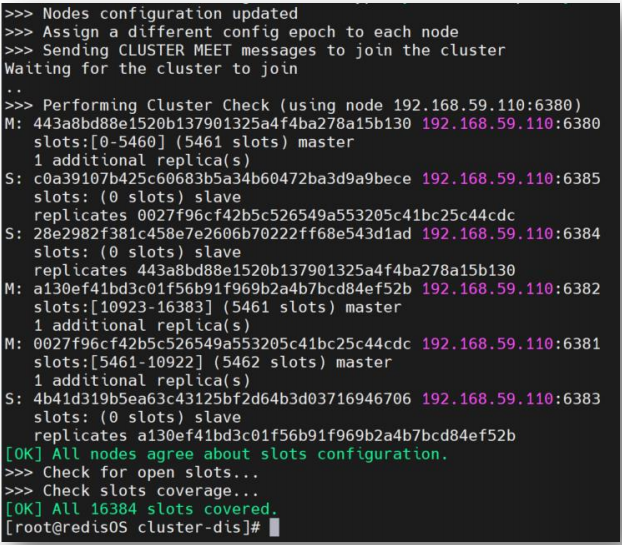
2.3.3 测试系统
redis-cli -c -p 6380 cluster nodes
# redis-cli 带有-c 参数,表示这是要连接一个“集群”,而非是一个节点
# 端口号可以使用 6 个中的任意一个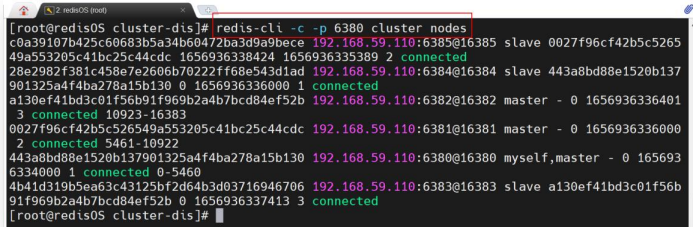
通过 cluster nodes 命令可以查看到系统中各节点的关系及连接情况。只要能看到每个节点给出 connected,就说明分布式系统已经成功搭建。
2.3.4 关闭系统
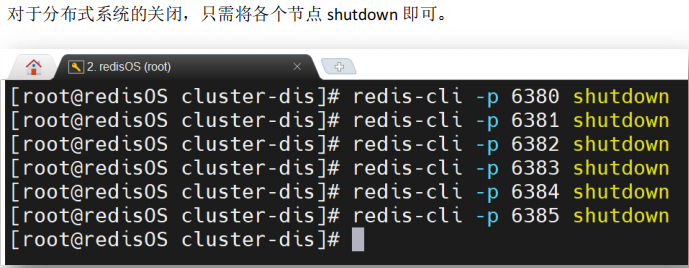
三、集群操作
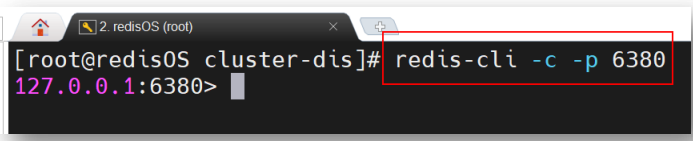
3.1 连接集群
3.2 写入数据
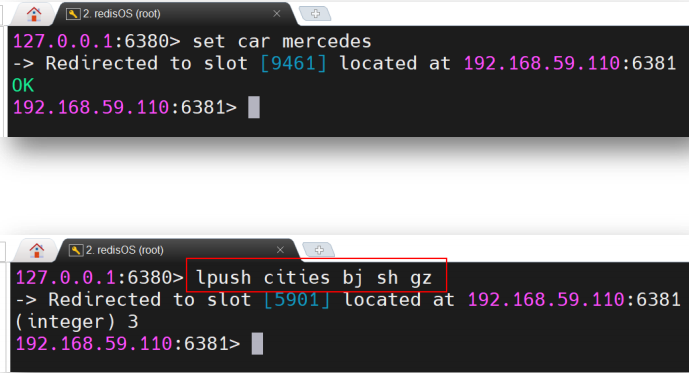
3.2.1 key单个写入
无论 value 类型为 String 还是 List、Set 等集合类型,只要写入时操作的是一个 key,那么在分布式系统中就没有问题。
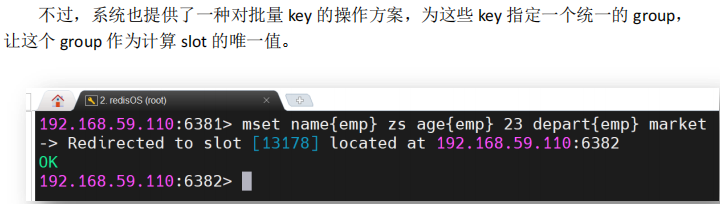
3.2.2 key批量操作
对一次写入多个 key 的操作,由于多个 key 会计算出多个 slot,多个 slot 可能会对应多个节点。而由于一次只能写入一个节点,所以该操作会报错。

3.3 集群查询
3.3.1 查询key的slot
cluster keyslot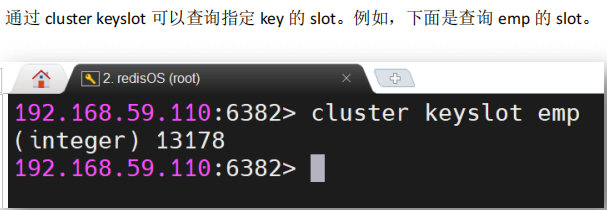
3.3.2 查询slot中key的数量
cluster countkeysinslot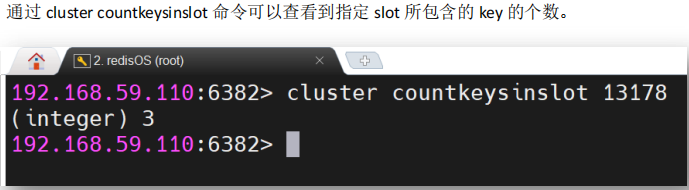
3.3.3 查询slot中的key
cluster getkeysinslot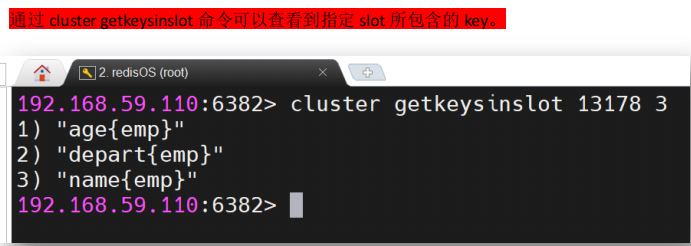
3.4 故障转移
分布式系统中的某个 master 如果出现宕机,那么其相应的 slave 就会自动晋升为master。如果原 master 又重新启动了,那么原 master 会自动变为新 master 的 slave。
3.4.1 模拟故障
通过cluster nodes 命令可以查看系统的整体结构及连接情况;
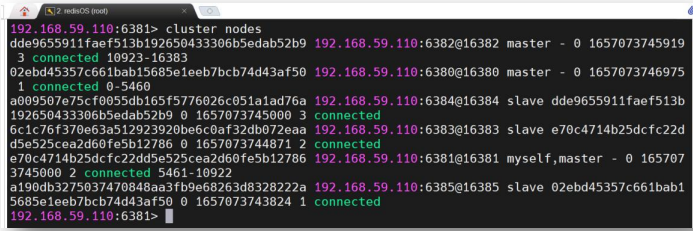
通过 info replication 查看当前客户端连接的节点的角色。可以看到,6381 节点是 master,其 slave 为 6383 节点。
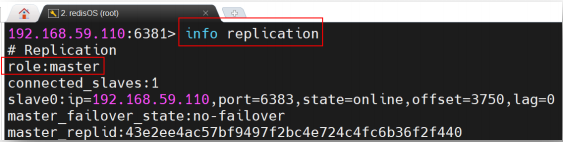
为了模拟6381宕机,直接将其shutdown;通过客户端连接上6383节点之后可以查看,其已经自动晋升为了master;重启 6381 节点后查看其角色,发现其自动成为了 6383 节点的 slave。
3.4.2 全覆盖需求
如果某slot范围对应节点的master与slave全部宕机,那么整个分布式系统是否还可以对外提供读服务,就取决于属性 cluster-require-full-coverage 的设置;
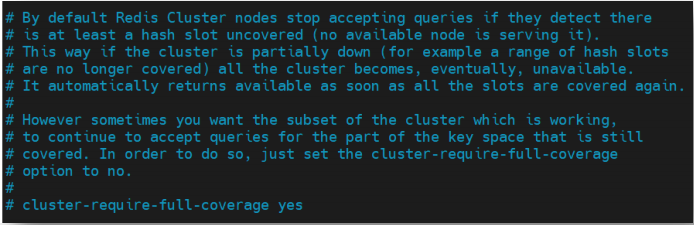
- yes:默认值,要求所有slot节点必须全覆盖的情况下系统才能运行;
- no:slot节点不全的情况下系统也可以提供查询服务;
3.5 集群扩容
分布式系统中添加两个新的节点:端口号为 6386 的节点为 master 节点,其下会有一个端口号为 6387 的 slave 节点;

要添加的两个节点是两个Redis,所以需要先将它们启动。只不过,在没有添加到分布式系统之前,它们两个孤立节点,每个节点与其他任何节点都没有关系。

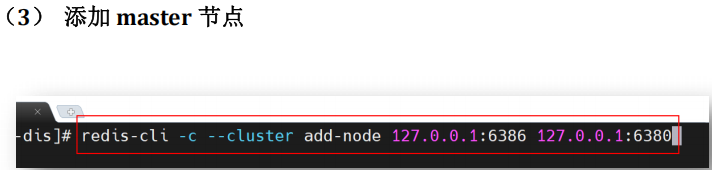
命令
redis-cli --cluster add-node {newHost}:{newPort} {existHost}:{existPort}可以将新的节点添加到系统中。其中 {newHost}:{newPort} 是新添加节点的地址,{existHost}:{existPort} 是原系统中的任意节点地址。
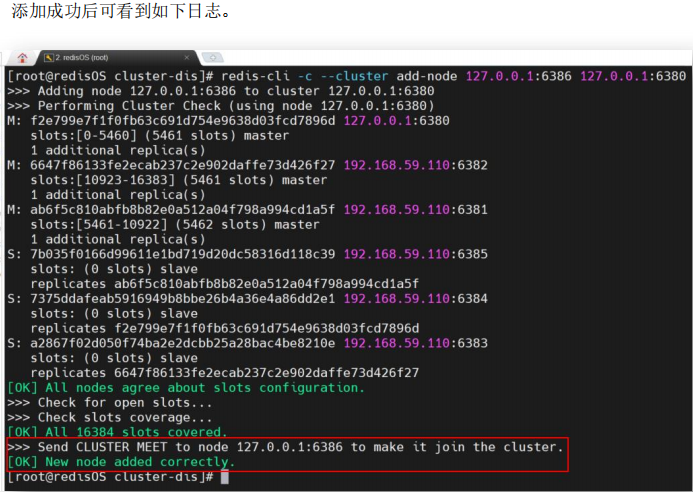
添加成功后,通过 redis-cli -c -p 6386 cluster nodes 命令可以看到其它master节点都分配有slot,只有新添加的master还没有相应的slot。同时,通过该命令也可以看到该新节点的动态ID。
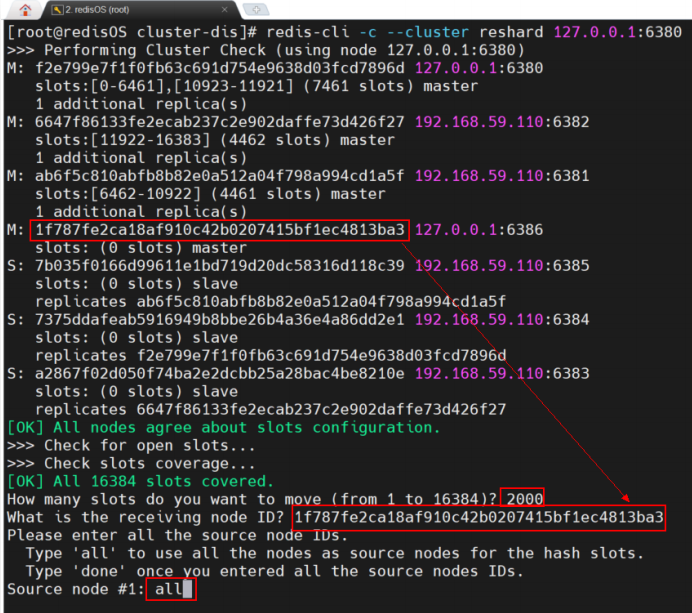

分配成功之后:分配的slot编号并不连续

3.5.5 添加slave节点
现要将 6387 节点添加为 6386 节点的 slave
1. 确保6387节点的Redis是启动状态;
2. 通过命令将新添加的节点直接添加为指定master的slave;
redis-cli --cluster add-node {newHost}:{newPort} {existHost}:{existPort} --cluster-slave
--cluster-master-id masterID
3. 通过命令可以看到其添加成功,且为指定master的slave;
redis-cli -c -p 6386 cluster nodes3.6 集群缩容
将 slave 节点 6387 与 master 节点 6386 从分布式系统中删除;
3.6.1 删除slave节点
redis-cli --cluster del-node <delHost>:<delPort> delNodeID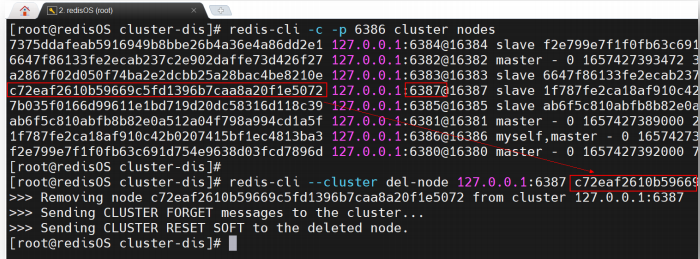
3.6.2 移出master的slot
在删除一个master之前,必须要保证该master上没有分配slot,否则无法删除。所以,在删除一个master之前,需要先将其上分配的slot移出;
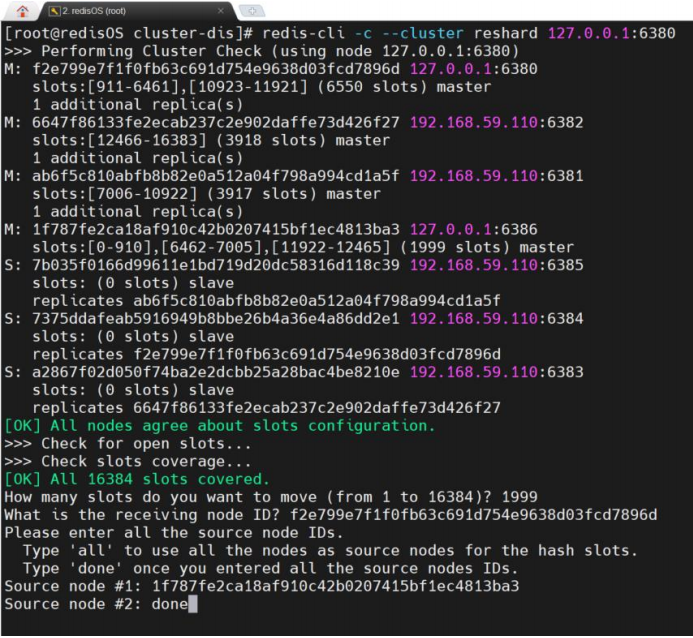
以上交互指的是将6386节点中的1999个slot移动到6380节点;
- 要删除的节点所包含的slot数量在前面检测结果中都是可以看到的,例如,6386中的并不是2000个,而是1999个;
- What is the receiving node ID? 仅能指定一个接收节点;
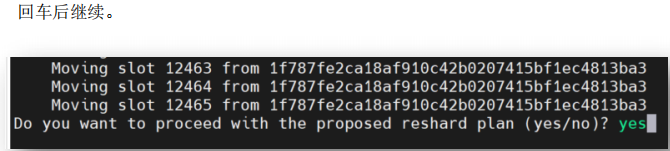
此时,再查看,6386节点已经没有slot了;

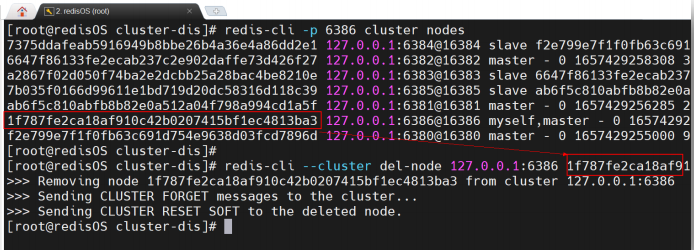
3.6.3 删除master节点6386
Redis Cluster 就像一个“连锁图书馆”,它把所有的书(数据)分成 16384 个类别(槽),每个分馆(节点)负责几个类别。读者(客户端)要借书时,先查目录(槽映射),就知道去哪个分馆找了。扩容时,只需把一些类别的书搬去新分馆,不影响其他书。
Redis Cluster 是 “分区 + 主从复制” 的结合体:既支持海量数据,又保证高可用。
