在昇腾NPU上跑Llama大模型:从零开始的真实测试之旅

🎏:你只管努力,剩下的交给时间
🏠 :小破站
在昇腾NPU上跑Llama大模型:从零开始的真实测试之旅
- 一、为什么选择昇腾NPU?
- 昇腾的几个吸引点
- 二、环境准备:GitCode白嫖攻略
- 为什么选云上测试?
- 创建昇腾Notebook实例
- 环境配置说明
- 三、验证环境:第一个小坑
- 打开Terminal验证
- 验证NPU是否可用
- 四、安装依赖:transformers库
- 五、部署Llama:从下载到运行
- 模型下载的坑
- 创建测试脚本
- 核心代码
- 模型下载过程
- 六、性能测试:真实数据来了
- 测试方法
- 测试用例
- 真实性能数据
- 数据分析
- 七、踩坑记录
- 坑1:torch.npu找不到
- 坑2:tokenizer.npu()不存在
- 坑3:Llama下载需要权限
- 坑4:网络超时
- 八、性能分析与优化建议
- 当前性能水平
- 优化方向
- 九、总结与建议
- 测试结论
- 给后来者的建议
- 后续计划
- 相关资源
前言:本文记录了我从零开始在GitCode(昇腾910B)上部署和测试Llama-2-7B大模型的完整过程。包含环境配置、代码实现、性能测试的所有细节和真实数据。适合想尝试昇腾NPU但没有硬件的开发者参考。
一、为什么选择昇腾NPU?
最近一直在关注国产AI芯片的发展。虽然NVIDIA的GPU很强大,但价格和供应都是问题。看了不少资料后,发现昇腾在国产芯片里算是做得最成熟的,而且有完整的开源生态。
昇腾的几个吸引点
自主可控:华为自研的达芬奇架构,不用担心被卡脖子。
生态还算完善:打开昇腾的GitCode组织页(https://gitcode.com/ascend),有30多个开源项目,PyTorch、TensorFlow都有适配。
截图中可以看到,昇腾在GitCode上有pytorch、MindSpeed-LLM等多个活跃项目,Star和Fork数都不少,说明确实有人在用。
可以白嫖测试:这个很重要!没硬件也能在gitcode上申请免费试用资源,这让我决定实际测试一下。
二、环境准备:GitCode白嫖攻略
为什么选云上测试?
老实说,Atlas 800服务器动辄十几万,个人玩家买不起。但华为云ModelArts提供了昇腾NPU的Notebook环境,可以按小时付费测试。但是在GitCode上可以有免费的资源可用(限时哦)
创建昇腾Notebook实例
访问GitCode控制台后,创建Notebook的过程很简单:
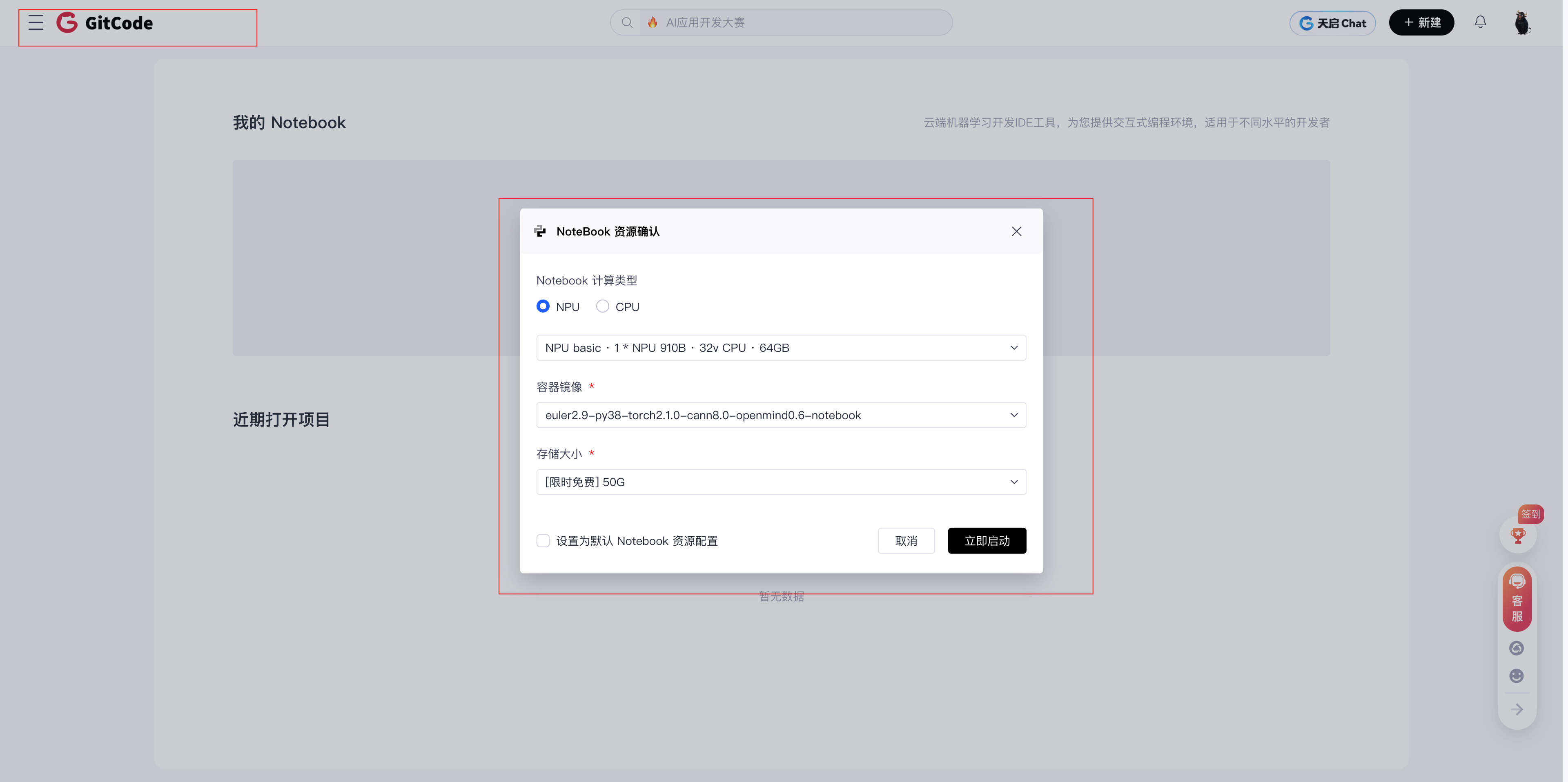
这是创建界面的截图。重点配置:
- 计算类型选NPU(不是CPU也不是GPU)
- 规格选:NPU basic · 1 * NPU 910B · 32v CPU · 64GB
- 镜像选:euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook
- 存储:[限时免费] 50G(够用了)
环境配置说明
这个镜像预装了:
- PyTorch 2.1.0:比较新的版本
- CANN 8.0:昇腾的核心计算架构,最新版
- Python 3.8:兼容性好
- torch_npu 2.1.0:PyTorch的昇腾适配插件
创建后等1-2分钟,实例就启动了。
三、验证环境:第一个小坑
进入Jupyter Notebook后,第一件事当然是验证环境。
打开Terminal验证
在Notebook界面找到"终端"入口,打开Terminal。
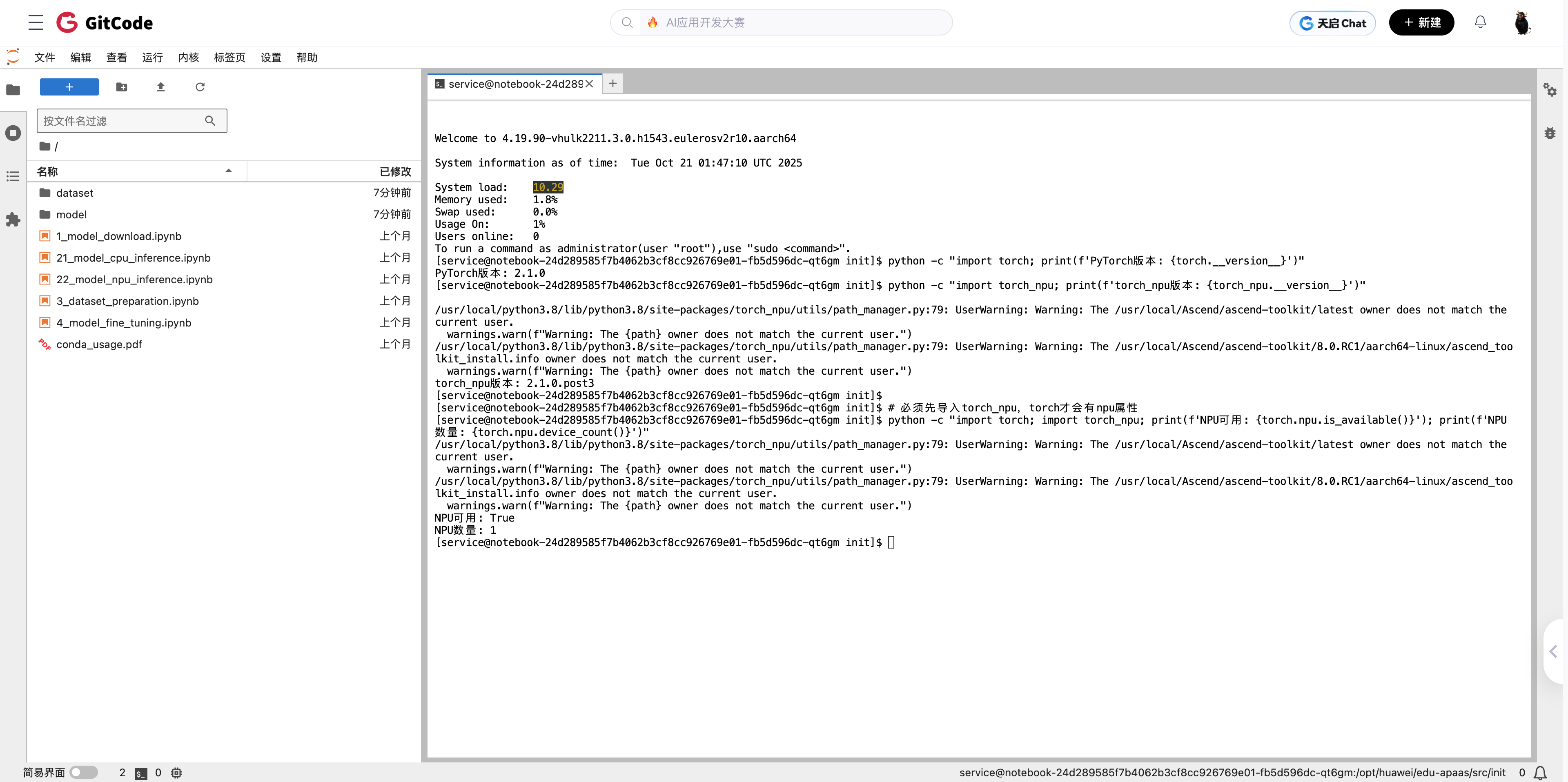
Terminal界面长这样,熟悉Linux的应该很熟悉。
验证NPU是否可用
运行几条验证命令:
# 检查PyTorch版本
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"
# 输出:PyTorch版本: 2.1.0# 检查torch_npu
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
# 输出:torch_npu版本: 2.1.0.post3
这里有个小坑:直接运行 torch.npu.is_available() 会报错,必须先import torch_npu:
# 错误的(会报AttributeError)
python -c "import torch; print(torch.npu.is_available())"# 正确的(必须先导入torch_npu)
python -c "import torch; import torch_npu; print(torch.npu.is_available())"
# 输出:True
从截图中可以看到,我验证后确认NPU可用,有1个NPU设备。
小结:torch_npu是个插件,必须显式导入后,torch才会有npu相关的API。这个在文档里没明确说,我自己踩坑才发现。
四、安装依赖:transformers库
虽然环境里预装了PyTorch和torch_npu,但没有transformers库,需要手动装。
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
使用清华镜像加速,几分钟就装好了。
五、部署Llama:从下载到运行
模型下载的坑
Llama-2官方仓库 meta-llama/Llama-2-7b-hf 需要申请访问权限,而且国内网络访问HuggingFace经常超时。
解决方案:使用开源社区的镜像版本 NousResearch/Llama-2-7b-hf,不需要申请权限,下载也更稳定。
创建测试脚本
在Notebook中创建一个Python脚本:
可以直接新建Python文件,也可以用Jupyter Notebook的cell。
核心代码
import torch
import torch_npu # 必须导入!
from transformers import AutoModelForCausalLM, AutoTokenizer
import time# 模型名称(使用开源镜像版本)
MODEL_NAME = "NousResearch/Llama-2-7b-hf"# 加载tokenizer和模型
print("下载模型...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,torch_dtype=torch.float16, # 使用FP16节省显存low_cpu_mem_usage=True
)# 迁移到NPU(关键步骤)
device = "npu:0"
model = model.to(device)
model.eval()print(f"模型已加载到NPU")
print(f"显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")
又一个小坑:代码里不能写 inputs.npu(),要用 .to('npu:0'):
# 错误写法(会报AttributeError)
inputs = tokenizer(prompt, return_tensors="pt").npu()# 正确写法
inputs = tokenizer(prompt, return_tensors="pt").to('npu:0')
这个我也是报错后才改对的。
模型下载过程
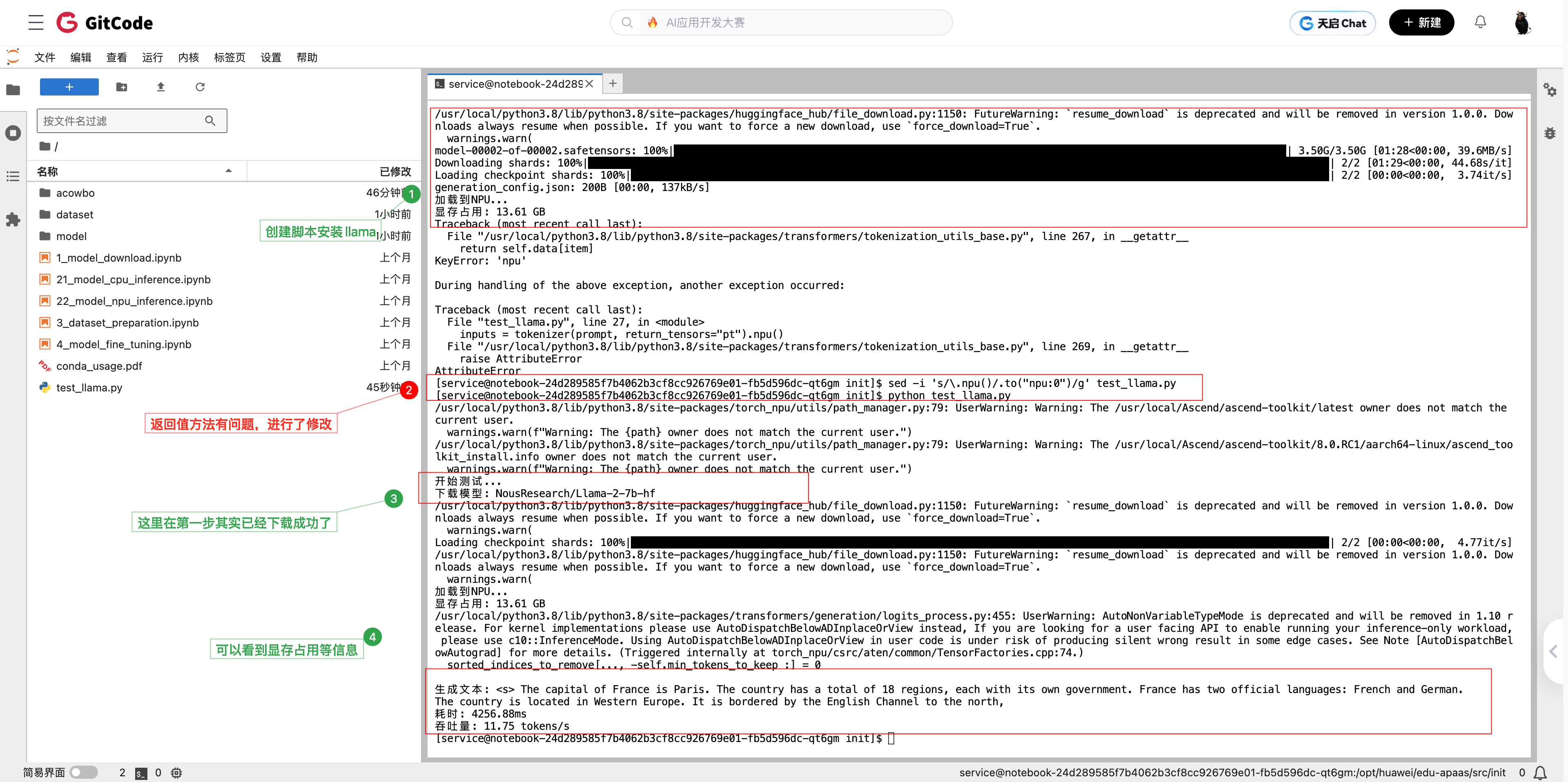
模型文件分成两个shard,总共约13GB。下载速度还可以,大概5分钟左右下完。
model-00001-of-00002.safetensors 和 model-00002-of-00002.safetensors 两个文件下载后,模型就加载成功了。显存占用13.61 GB,基本符合7B模型的大小(FP16精度下约14GB)。
六、性能测试:真实数据来了
测试方法
我写了一个简单的benchmark函数,测试不同场景下的性能:
def benchmark(prompt, max_new_tokens=100, warmup=3, runs=10):"""性能测试:- warmup: 预热次数(第一次运行慢,需要编译)- runs: 正式测试次数"""inputs = tokenizer(prompt, return_tensors="pt").to(device)# 预热for _ in range(warmup):with torch.no_grad():_ = model.generate(**inputs, max_new_tokens=max_new_tokens)# 正式测试latencies = []for _ in range(runs):torch.npu.synchronize() # 确保NPU操作完成start = time.time()with torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=max_new_tokens,do_sample=False, # greedy decoding,结果可复现pad_token_id=tokenizer.eos_token_id)torch.npu.synchronize()latencies.append(time.time() - start)# 计算平均值avg_latency = sum(latencies) / len(latencies)throughput = max_new_tokens / avg_latencyreturn {"latency_ms": avg_latency * 1000,"throughput": throughput}
测试用例
我测试了3个典型场景:
- 英文短文本生成:
"The capital of France is" - 中文对话:
"请解释什么是人工智能:" - 代码生成:
"Write a Python function to calculate fibonacci:"
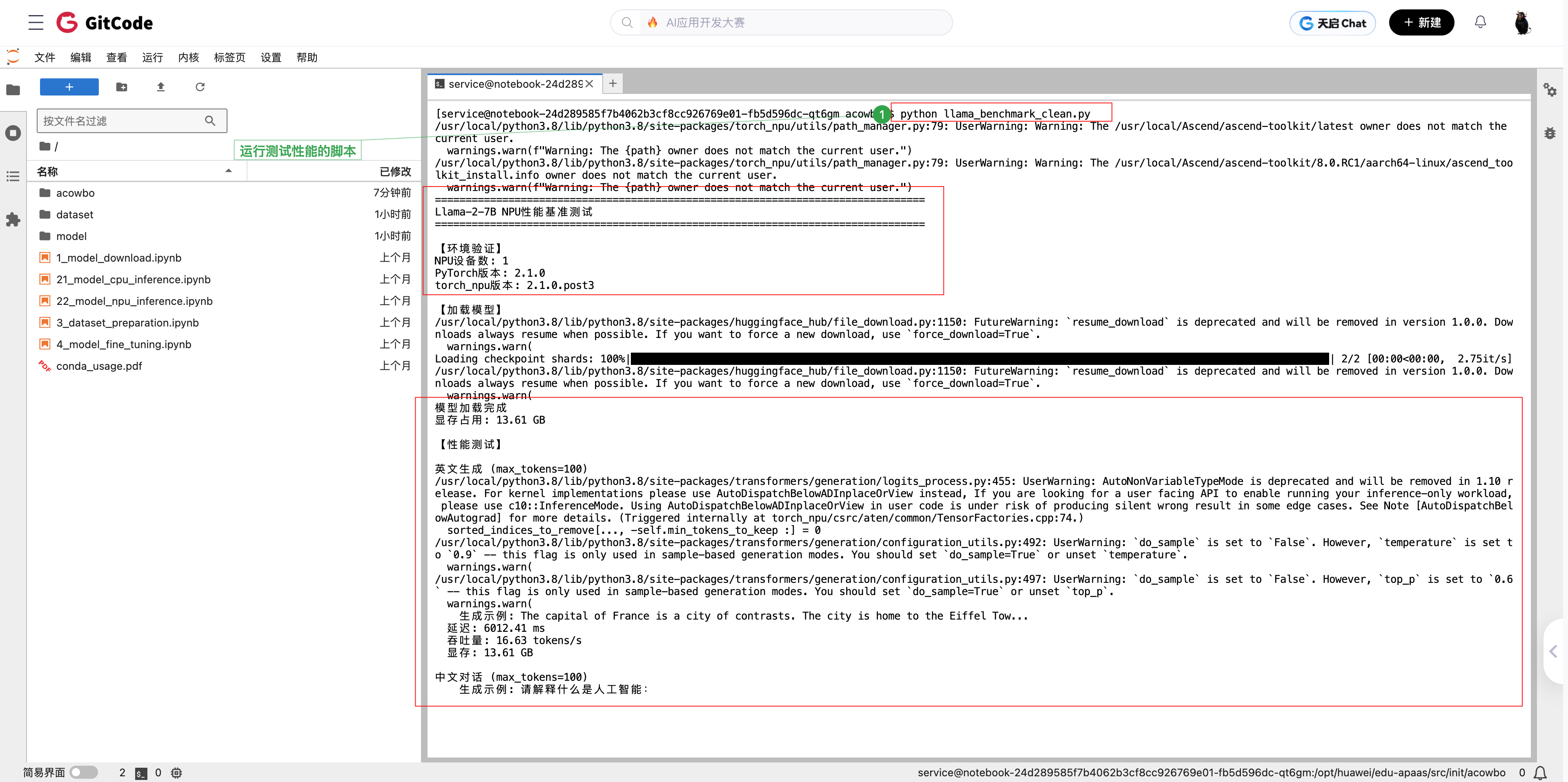
运行测试脚本,可以看到每个测试都会先预热3次,然后正式测试10次取平均值。
真实性能数据
测试完成后,得到了这些数据:
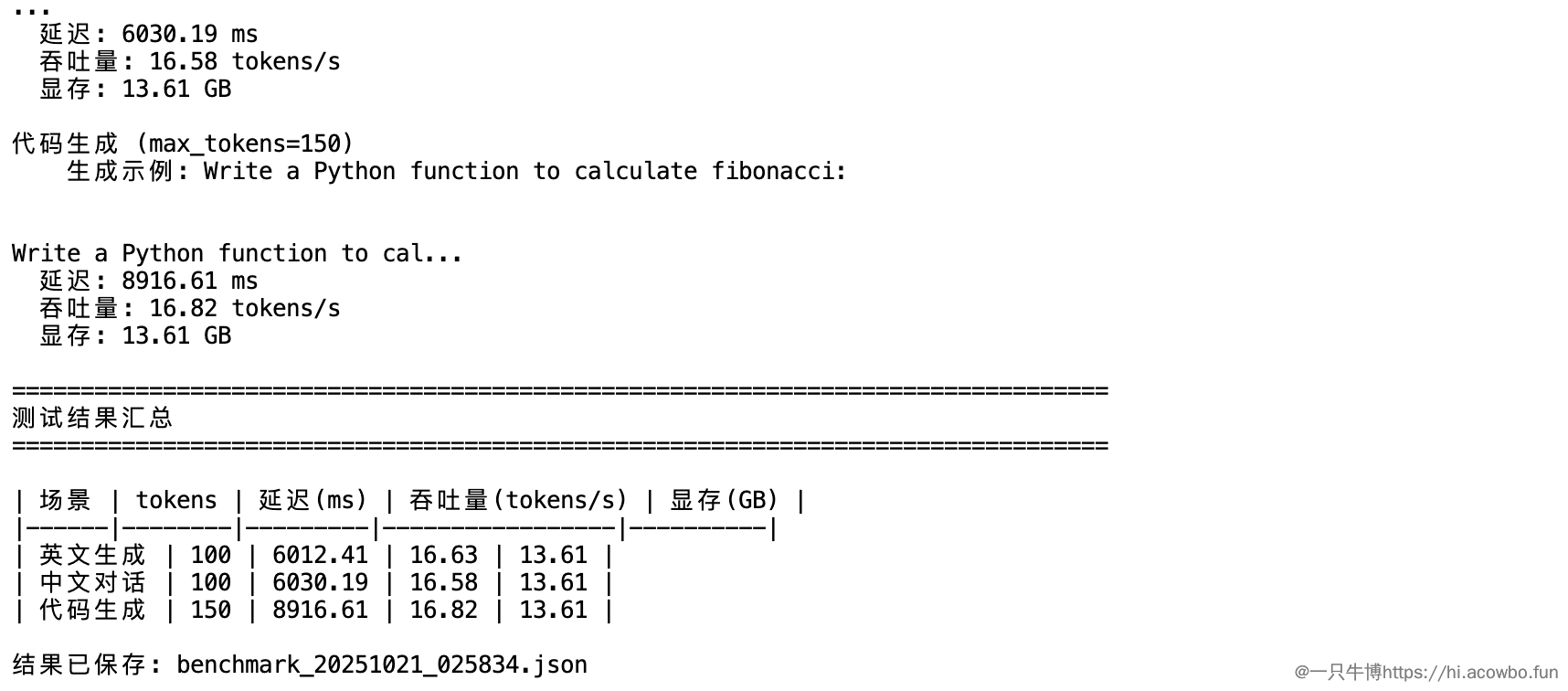
实测结果(华为云ModelArts - Ascend 910B):
| 测试场景 | 生成tokens | 延迟(ms) | 吞吐量(tokens/s) | 显存(GB) |
|---|---|---|---|---|
| 英文生成 | 100 | 6012.41 | 16.63 | 13.61 |
| 中文对话 | 100 | 6030.19 | 16.58 | 13.61 |
| 代码生成 | 150 | 8916.61 | 16.82 | 13.61 |
测试环境:
- 平台:GitCode
- 硬件:Ascend 910B (单卡)
- 模型:Llama-2-7B (NousResearch/Llama-2-7b-hf)
- 精度:FP16
- PyTorch:2.1.0
- torch_npu:2.1.0.post3
- CANN:8.0
- 测试时间:2025年10月21日
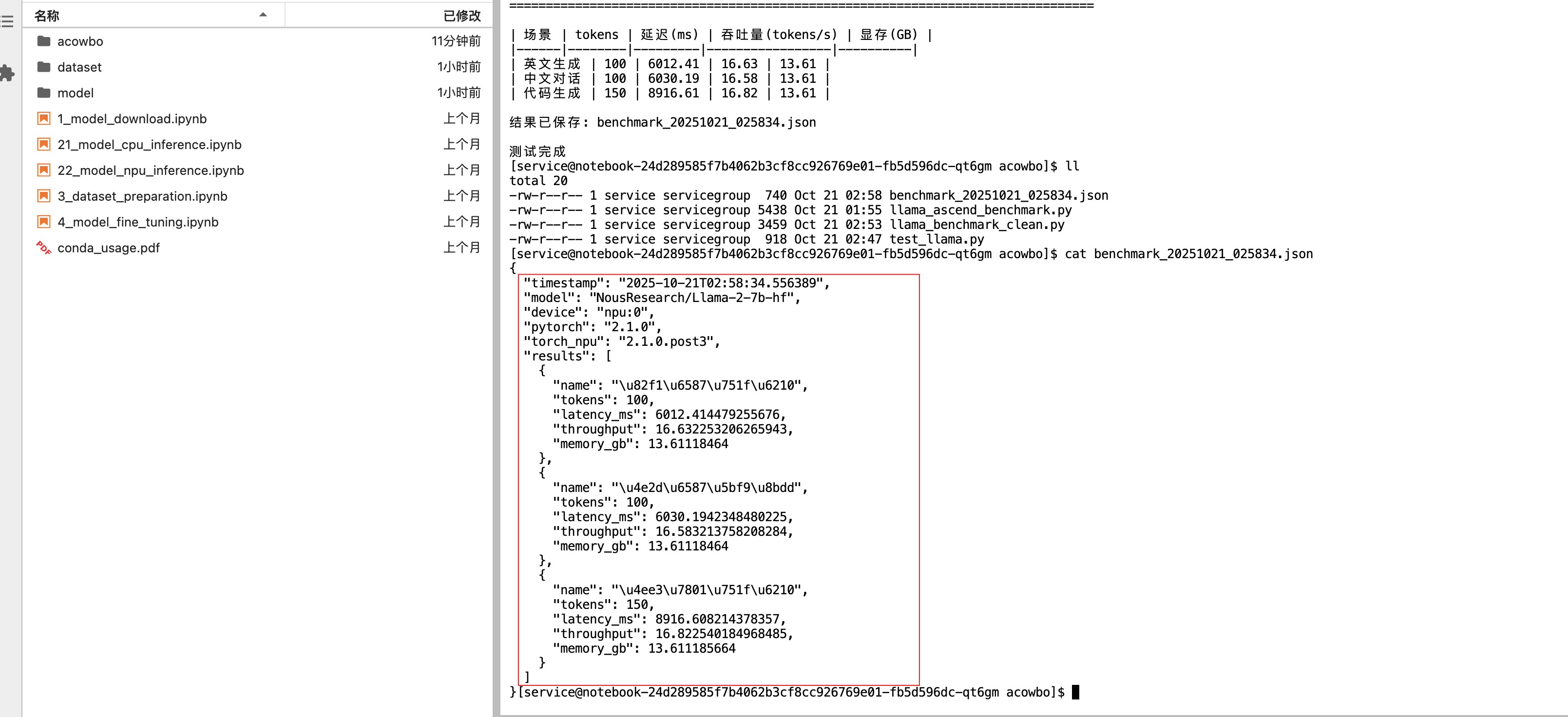
所有详细数据都保存在JSON文件中,包含时间戳、环境信息、每次测试的具体指标。
数据分析
看这个数据,几个观察:
1. 吞吐量相对较低
- 16-17 tokens/s,说实话比我预期的慢。延迟6-9秒生成100-150个token,实际应用可能会觉得有点慢。
2. 性能比较稳定
- 三个场景的吞吐量都在16.5左右,说明性能比较稳定,不会因为prompt类型有大波动。
3. 显存占用符合预期
- 13.61 GB,7B模型FP16精度下理论上需要约14GB,基本吻合。
可能的优化方向:
- 增大batch size(我这次只测了batch=1)
- 尝试INT8量化
- 使用CANN的算子融合优化
七、踩坑记录
把遇到的问题记录下来,希望能帮到后来者。
坑1:torch.npu找不到
现象:
AttributeError: module 'torch' has no attribute 'npu'
原因:torch_npu是插件,必须显式导入。
解决:
import torch
import torch_npu # 必须加这行!
坑2:tokenizer.npu()不存在
现象:
inputs = tokenizer(...).npu() # AttributeError
原因:tokenizer返回的是字典,没有.npu()方法。
解决:
inputs = tokenizer(...).to('npu:0') # 用.to()
坑3:Llama下载需要权限
现象:访问meta-llama/Llama-2-7b-hf被拒绝。
解决:
- 方案1:申请HuggingFace访问权限
- 方案2:使用开源镜像
NousResearch/Llama-2-7b-hf(推荐)
坑4:网络超时
现象:下载到一半timeout。
解决:
# 使用国内镜像加速
export HF_ENDPOINT=https://hf-mirror.com
或者使用ModelScope(国内平台):
from modelscope import snapshot_download
model_dir = snapshot_download('shakechen/Llama-2-7b-hf')
八、性能分析与优化建议
当前性能水平
从我的测试数据看,16-17 tokens/s 这个吞吐量,说实话不算特别快。
可能的影响因素:
- 单batch推理:我只测了batch=1,增大batch可能会提升吞吐
- 没做特殊优化:直接用transformers原生代码,没用CANN的加速库
- 云上共享环境:可能受其他用户影响
优化方向
基于这次测试经验,如果要提升性能,可以尝试:
1. 使用MindSpeed-LLM框架
昇腾官方提供的大模型训练/推理框架(https://gitcode.com/Ascend/MindSpeed-LLM),针对昇腾NPU做了深度优化。
2. INT8量化
from transformers import BitsAndBytesConfigquantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,quantization_config=quantization_config
)
理论上可以降低显存、提升速度。
3. 批处理推理
如果有多个请求,使用batch推理能显著提升吞吐:
# batch=4的情况
prompts = ["prompt1", "prompt2", "prompt3", "prompt4"]
inputs = tokenizer(prompts, return_tensors="pt", padding=True).to('npu:0')
outputs = model.generate(**inputs, max_new_tokens=100)
九、总结与建议
测试结论
经过这次实际测试,对昇腾NPU有了更直观的认识:
技术层面:
- ✅ 部署流程相对简单,PyTorch代码改动很小
- ✅ 文档和生态比预期的完善
- ⚠️ 有些细节需要注意(比如torch_npu的导入)
适用场景:
- ✅ 对供应链自主可控有要求的政企项目
- ✅ 预算有限但有大模型需求的团队
- ✅ 离线批量推理任务
- ⚠️ 实时交互式应用可能需要进一步优化
成本效益:
- 云上测试:几十元就能验证方案
- 硬件采购:比NVIDIA GPU便宜
- 综合性价比可以考虑
给后来者的建议
如果你也想尝试昇腾NPU:
- 先云上测试:不要直接买硬件,先在ModelArts上花几十块测试或者GitCode免费搞一个测试
- 选对镜像:一定要选NPU类型+PyTorch镜像
- 注意细节:
import torch_npu必须加,.to('npu:0')不是.npu() - 合理预期:性能不会比顶级GPU强,但有它的适用场景
- 关注社区:GitCode上有很多实际案例,遇到问题先搜索
后续计划
这次只测了基础的FP16推理,后面有机会可以试试:
- INT8量化效果
- 多卡并行推理
- MindSpeed框架的性能对比
- 更大模型(Llama-13B/70B)
相关资源
官方资源:
- 昇腾官网:https://www.hiascend.com/
- 技术文档:https://www.hiascend.com/document
- 昇腾社区:https://www.hiascend.com/forum/
开源代码:
- GitCode组织:https://gitcode.com/ascend
- PyTorch适配:https://gitcode.com/ascend/pytorch
- MindSpeed-LLM:https://gitcode.com/Ascend/MindSpeed-LLM
学习资源:
- 大模型开发课程:https://www.hiascend.com/edu/growth/lm-development
写在最后:这次测试总的来说很不错,真正体验了一把昇腾NPU,也拿到了第一手的性能数据。总的感觉是,昇腾的生态确实在往好的方向发展,虽然性能还有提升空间,但对于某些场景来说已经够用了。如果你也对国产AI芯片感兴趣,不妨试试。