【论文精读-4】RBG:通过强化学习分层解决物流系统中的大规模路径问题(Zefang Zong,2022)
论文地址:
RBG: Hierarchically Solving Large-Scale Routing Problems in Logistic Systems via Reinforcement Learning![]() https://dl.acm.org/doi/pdf/10.1145/3534678.3539037
https://dl.acm.org/doi/pdf/10.1145/3534678.3539037
🧭 一、论文总体内容与研究目标
1. 研究背景
-
VRP(车辆路径问题) 是物流系统中的核心优化问题:如何让多辆车从仓库出发、高效地为众多客户送货并返回,目的是最小化总行驶距离。
-
现实中的物流系统往往涉及上千客户,而传统算法(如 HGS、LKH3 等启发式方法)或强化学习方法通常只能处理 ≤100 个客户 的小规模问题。
-
因此,如何让强化学习在大规模 VRP 上高效、稳定地工作成为关键挑战。
2. 主要贡献(核心思想)
论文提出了一个新框架:Rewriting-by-Generating(RBG),结合了 强化学习(RL)+ 启发式优化思想。
它通过“分而治之(Divide-and-Conquer)”来解决大规模问题,核心是两个模块:
-
Generator(生成器):在局部小区域上生成路径解;
-
Rewriter(重写器):从全局角度合并、再划分区域,用强化学习优化整体结构。
通过“生成—重写—再生成”的循环,RBG 能够逐步改进全局解。
主要创新点包括:
-
一个端到端的分层强化学习框架,可在全局—局部间迭代优化;
-
“生成器”部分可灵活替换不同子算法(如 HGS、LKH3、RL-based Generator);
-
在合成数据与真实物流数据上均显著优于最优启发式算法(HGS);
-
已在中国广东某物流系统中实际部署并验证。
3. 论文结构(五大部分)
| 部分 | 内容概要 |
|---|---|
| 第1章 引言 | 介绍大规模 VRP 的挑战、传统算法与强化学习的局限,并提出 RBG 框架的总体思路。 |
| 第2章 相关工作(Related Work) | 对比传统启发式方法(如 Tabu、GA、ACO、HGS)与 RL-based 方法(如 PointerNet, ReWriter, L2I, L2D)之间的差异。指出现有 RL 方法无法扩展到上千客户规模。 |
| 第3章 预备知识(Preliminary) | 定义 CVRP 的数学模型与约束条件。 |
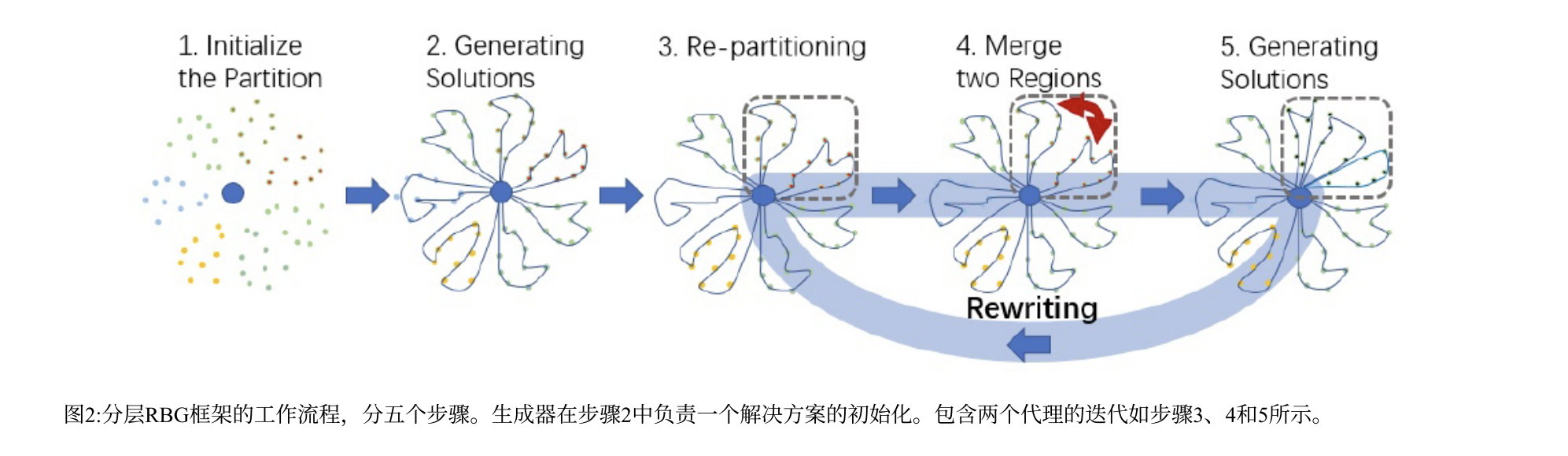
| 第4章 RBG 框架设计(核心部分) | 详细介绍 RBG 的五步流程:①区域初始化 → ②初始生成 → ③再划分(Re-partition) → ④区域选择与合并(Merge) → ⑤在合并区域上再生成解。说明强化学习如何训练 Rewriter 模块。 |
| 第5章 实验与分析 | 在合成数据与真实物流数据上与 HGS、LKH3、L2D、ReWriter 等比较,展示 RBG 的性能、泛化能力(CVRPTW、CVRPMDP)与鲁棒性。并展示在实际物流系统中的部署结果。 |
| 第6章 在线部署与结果 | 展示 RBG-HGS 在真实快递调度系统中的应用界面与性能,说明其实用性与实时响应能力。 |
| 第7章 总结与展望 | 总结方法优势与未来改进方向(如更多约束下的 VRP 扩展)。 |
4. 简要总结
RBG 是一个将“强化学习的策略优化”与“启发式算法的高效局部搜索”结合起来的层次化分治框架,可在超大规模物流路由问题中实现接近最优、且实时可用的解法。
🧩 二、RBG 框架的结构与工作机制
RBG 全称 Rewriting-by-Generating Framework,是一种分层强化学习结构(Hierarchical RL Framework),
核心思想是:
“把大规模的 VRP 问题拆分成多个小区域,在局部生成解,再用强化学习重写区域划分,从而不断优化全局解。”
这个框架由 两个核心模块 组成:
-
Generator(生成器):在局部小区域上求解 CVRP;
-
Rewriter(重写器):从全局角度控制区域的划分与合并,用 RL 学习决策。
两者在整个流程中循环协同,形成“生成—重写—再生成”的迭代过程。
🧭 1 Overall Architecture — 框架总体结构
(1)总体思想
-
RBG 遵循 “Divide and Conquer(分而治之)”:
把上千客户的整体问题分为若干小区域(region/hyper-region); -
每个区域内部由 Generator 独立求解;
-
然后 Rewriter 负责跨区域地调整结构(合并或再划分),让全局方案更优。
(2)结构组成
框架包含两个互补组件:
| 模块 | 作用 | 特点 |
|---|---|---|
| Generator(生成器) | 为每个区域生成局部路线解 | 可以是强化学习模型(Attention Model)或启发式算法(LKH3、HGS) |
| Rewriter(重写器) | 学习区域划分、合并决策 | 使用强化学习(REINFORCE)优化策略,使划分更合理、全局路线更优 |
(3)核心循环
1️⃣ 初始化区域划分;
2️⃣ 局部生成路径解;
3️⃣ 重写器基于结果重新划分并选择合并区域;
4️⃣ 在新区域上再次生成解;
5️⃣ 若新解更优 → 更新整体方案。
重复上述过程,直到模型收敛。
🟦 2 Region Initialization — 区域初始化
(1)目标
为了让 Generator 更容易工作,初始划分要空间合理,即相近客户尽量在同一区域。
(2)方法:K-means 聚类(结合空间与方向)
-
输入:所有客户坐标 (xi,yi);
-
输出:K 个初始超区域 Gk;
-
聚类距离为:
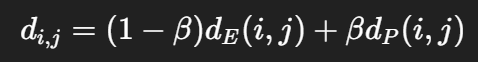
其中:
-
dE:欧氏距离;
-
dP:极坐标方向差(角度差);
-
β:权重超参数(人工设定或调优)。
-
直观解释:既考虑“距离近”,又考虑“方向相似”,因为在 VRP 中车辆通常会在一个扇区内服务客户。
🟩 3 Generating — 局部生成器 (Generator)
(1)任务
在每个小区域(hyper-region)上独立求解 CVRP 的最优或近似最优解。
(2)生成器的实现方式
论文使用了两种类型:
| 类型 | 方法 | 特点 |
|---|---|---|
| RL-based Generator | Attention Model (AM, [20]) | Encoder–Decoder 结构,能快速生成解,强化学习端到端训练 |
| 非 RL-based Generator | LKH3, HGS | 经典启发式算法,适用于 CVRP 及其变体 |
(3)灵活性
RBG 框架不依赖具体的 generator,任何能高效求解小规模 VRP 的方法都能被替换进去。
🟧 4 Rewriting — 区域重写器 (Rewriter)
Rewriter 是 RBG 的核心创新部分,它通过强化学习反复改进区域划分。
这一过程由三步构成:
(1)Partitioning(再划分)
-
将选中的超区域 Gk 按路线级别划分成两个小区域 Gi′,Gj′;
-
划分时保持路线结构不变;
-
使用路线质心 + PCA 降维分侧;
-
保证两个子区域客户数相近。
(2)Selecting(区域选择)
-
使用神经网络(MLP + LSTM + 平均池化 + FC)对每个区域生成向量表示 hih_ihi;
-
在邻域集合 Ui中,用 softmax 内积相似度:
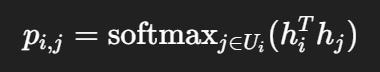
决定要与 Gi′合并的 Gj′;
-
RL 策略网络学习在何种状态下选择哪对区域最优。
(3)Merging(合并与更新)
-
合并 Gi′与 Gj′ → 新超区域 Gmerge;
-
调用 Generator 在该区域重新生成解;
-
若新解更优,则更新整体方案:
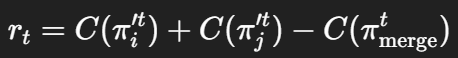
即“旧区域解”被“合并后新解”替换,这就是一次 Rewriting Step。
整个过程不断循环,灰色框区域在不同轮次动态变化。
🟥 5 Optimization via REINFORCE — 强化学习优化
(1)奖励函数
Rewriter 的学习目标是:让合并后新解比旧解更好。
奖励定义为:
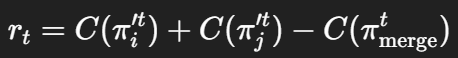
-
C(π):路径总成本(总距离);
-
若新解更短 → rt>0,反之则为负。
(2)梯度更新(策略梯度法)
采用 REINFORCE 算法更新策略参数:
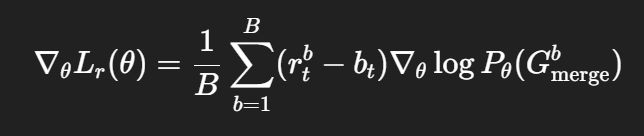
其中:
-
B:批量大小;
-
bt:基线(baseline,用奖励的移动平均减少方差)。
(3)拒绝机制(Reject Rule)
若新解比旧解差,则:
-
拒绝此次更新;
-
直接进入下一轮;
-
保证训练稳定性与解的单调改进。
🔁 小结:RBG 的五步流程
| 步骤 | 内容 | 模块 | 是否学习 |
|---|---|---|---|
| Step 1 | 区域初始化(K-means) | 预处理 | 否 |
| Step 2 | 区域内生成解 | Generator | 否 / 可选学习 |
| Step 3 | 再划分 | Rewriter | 否 |
| Step 4 | 选择+合并 | Rewriter (RL) | ✅ 学习部分 |
| Step 5 | 再生成并更新全局解 | Generator | 否 |