【Java】基于 Tabula 的 PDF 合并单元格内容提取
坑还是要填的,但是填得是否平整就有待商榷了(狗头保命…)。
本人技术有限,只能帮各位实现的这个地步了。各路大神如果还有更好的实现也可以发出来跟小弟共勉一下哈。
首先需要说一下的是以下提供的代码仅作研究参考使用,各位在使用之前务必自检,因为并不是所有 pdf 的表格格式都适合。
本次实现的难点在于 PDF 是一种视觉格式,而不是语义格式。
它只记录了“在 (x, y) 坐标绘制文本 ‘ABC’”和“从 (x1, y1) 到 (x2, y2) 绘制一条线”。它根本不“知道”什么是“表格”、“行”或“合并单元格”。而 Tabula 的 SpreadsheetExtractionAlgorithm 算法是处理这种问题的最佳起点,但它提取的结果会是“不规则”的,即每行的单元格数量可能不同。因此本次将采用后处理的方式进行解析,Tabula 更多的只是作内容提取,表格组织还是在后期处理进行的。
就像上次的文章中说到
【Java】采用 Tabula 技术对 PDF 文件内表格进行数据提取-CSDN博客
本次解决问题的核心思路就是通过计算每一个单元格完整的边界框,得到它的 top,left, bottom,right。通过收集所有单元格的 top 坐标和 bottom 坐标,推断出表格中所有“真实”的行边界。同理,通过收集所有单元格的 left 坐标和 right 坐标,可以推断出所有“真实”的列边界。最后基于这些边界构建一个完整的网格,然后将 Tabula 提取的文本块“放”回这个网格中。
为了方便测试我使用了 Deepseek 官网“模型细节”章节里面的那个表格。
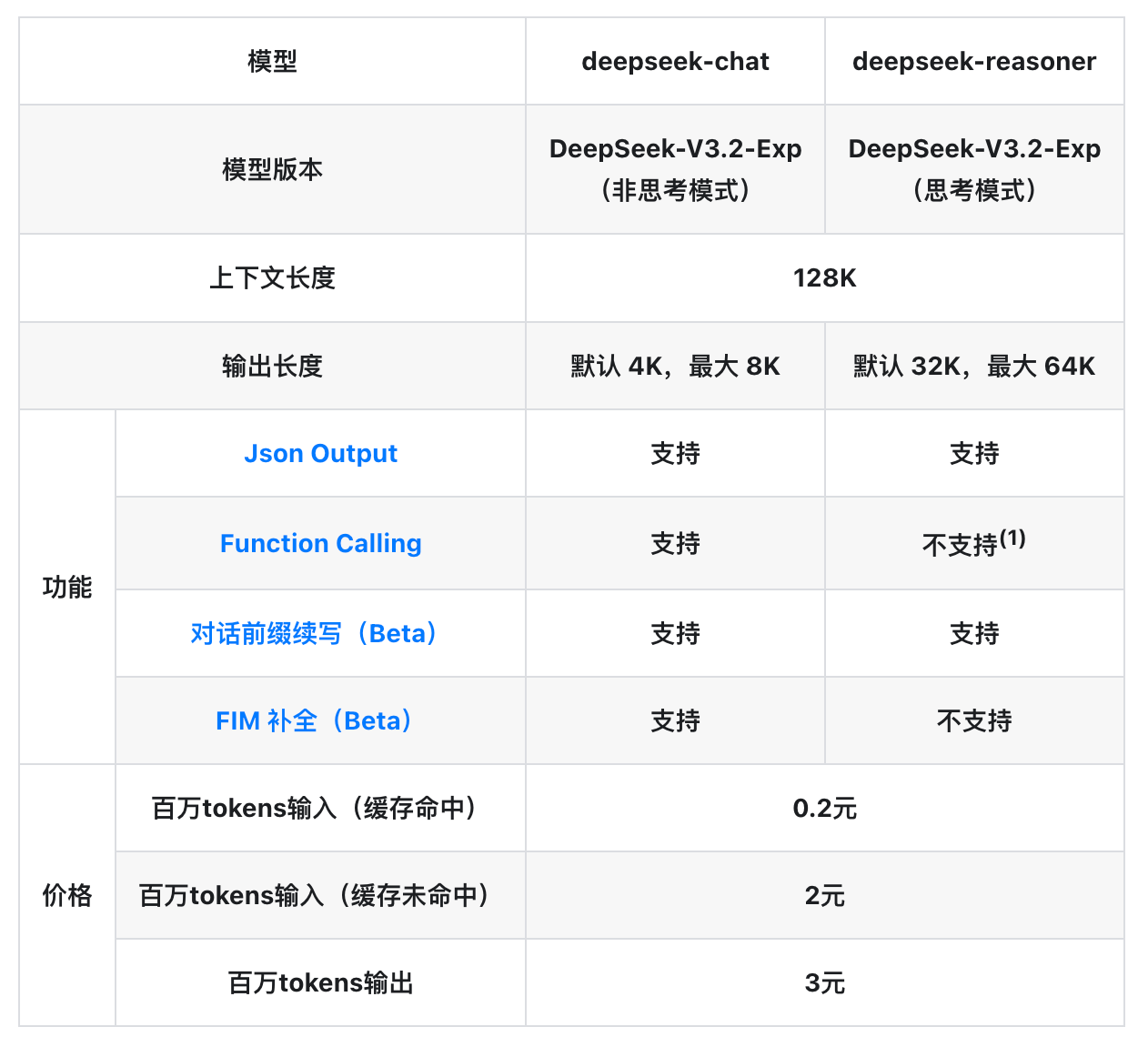
这个表格是比较经典的,既有列合并单元格,也有行合并单元格。而且表格中并没有那么多复杂的内容。
下面是我的执行代码
package cn.paohe;import java.awt.Point;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.NavigableSet;
import java.util.Set;
import java.util.TreeSet;import org.apache.pdfbox.pdmodel.PDDocument;import technology.tabula.ObjectExtractor;
import technology.tabula.Page;
import technology.tabula.PageIterator;
import technology.tabula.Rectangle;
import technology.tabula.RectangularTextContainer;
import technology.tabula.Table;
import technology.tabula.extractors.SpreadsheetExtractionAlgorithm;public class MergedCellPdfExtractor {// 浮点数比较的容差private static final float COORDINATE_TOLERANCE = 2.0f;/*** 为了样例方便,在类内部直接封装一个单元格,包含其文本和边界*/static class Cell extends Rectangle {public String text;public float top;public float left;public double width;public double height;public Cell(float top, float left, double width, double height, String text) {this.top = top;this.left = left;this.width = width;this.height = height;this.text = text == null ? "" : text.trim();}@Overridepublic float getTop() {return top;}@Overridepublic float getLeft() {return left;}@Overridepublic double getWidth() {return width;}@Overridepublic double getHeight() {return height;}@Overridepublic float getBottom() {return (float) (top + height);}@Overridepublic float getRight() {return (float) (left + width);}@Overridepublic double getX() {return left;}@Overridepublic double getY() {return top;}@Overridepublic Point[] getPoints() {return new Point[0];}@Overridepublic String toString() {return String.format("Cell[t=%.2f, l=%.2f, w=%.2f, h=%.2f, text='%s']", top, left, width, height, text);}}/*** 由于表格提取的时候会出现偏差,因此定义表格指纹,用于去重*/static class TableFingerprint {private final float top;private final float left;private final int rowCount;private final int colCount;private final String contentHash;public TableFingerprint(Table table) {this.top = roundCoordinate(table.getTop());this.left = roundCoordinate(table.getLeft());this.rowCount = table.getRowCount();this.colCount = table.getColCount();this.contentHash = generateContentHash(table);}/*** 生成表格的内容 Hash,用于快速比较两个表格是否相同* * Hash 生成规则:将每个单元格的文本内容连接起来,使用 "|" 分隔 如果单元格的数量超过 10 个,就停止生成 Hash* * @param table 需要生成 Hash 的表格* @return 生成的 Hash*/private String generateContentHash(Table table) {StringBuilder sb = new StringBuilder();int cellCount = 0;for (List<RectangularTextContainer> row : table.getRows()) {for (RectangularTextContainer cell : row) {sb.append(cell.getText()).append("|");cellCount++;if (cellCount > 10) {break;}}if (cellCount > 10) {break;}}return sb.toString();}@Overridepublic boolean equals(Object obj) {if (!(obj instanceof TableFingerprint)) {return false;}// 将要比较的对象强制转换为 TableFingerprintTableFingerprint other = (TableFingerprint) obj;// 两个表格的 top 和 left 坐差不能超过 COORDINATE_TOLERANCEboolean topMatch = Math.abs(this.top - other.top) < COORDINATE_TOLERANCE;boolean leftMatch = Math.abs(this.left - other.left) < COORDINATE_TOLERANCE;// 两个表格的行数和列数必须相同boolean rowMatch = this.rowCount == other.rowCount;boolean colMatch = this.colCount == other.colCount;// 两个表格的内容 Hash must be equalboolean contentMatch = this.contentHash.equals(other.contentHash);// 如果以上条件都满足,则返回 truereturn topMatch && leftMatch && rowMatch && colMatch && contentMatch;}@Overridepublic int hashCode() {return contentHash.hashCode();}/*** 将坐标四舍五入到指定精度,减少浮点误差* * @param coord 需要四舍五入的坐标* @return 四舍五入后的坐标*/private static float roundCoordinate(float coord) {// 将坐标乘以 10,然后将结果四舍五入,然后除以 10.0f,保留一个小数点return Math.round(coord * 10) / 10.0f;}}/*** 解析 PDF 文件中的所有表格* * 1. 使用 ObjectExtractor 将 PDF 文件中的所有表格进行提取 2. 使用 SpreadsheetExtractionAlgorithm* 基于线条检测表格,避免重复表格 3. 规范化表格,处理合并单元格* * @param pdfFile 要解析的 PDF 文件* @return 规范化的表格数据,每个 List<List<String>> 代表一个表格* @throws IOException 文件读取异常*/public List<List<List<String>>> parseTables(File pdfFile) throws IOException {List<List<List<String>>> allNormalizedTables = new ArrayList<>();Set<TableFingerprint> seenTables = new HashSet<>();InputStream bufferedStream = new BufferedInputStream(new FileInputStream(pdfFile));try (PDDocument pdDocument = PDDocument.load(bufferedStream)) {ObjectExtractor oe = new ObjectExtractor(pdDocument);PageIterator pi = oe.extract();while (pi.hasNext()) {Page page = pi.next();// 使用 SpreadsheetExtractionAlgorithm 基于线条检测表格SpreadsheetExtractionAlgorithm sea = new SpreadsheetExtractionAlgorithm();List<Table> tables = sea.extract(page);for (Table table : tables) {// 去重检查TableFingerprint fingerprint = new TableFingerprint(table);if (seenTables.contains(fingerprint)) {System.out.println("跳过重复表格: top=" + fingerprint.top + ", left=" + fingerprint.left);continue;}seenTables.add(fingerprint);List<List<String>> normalized = normalizeTable(table);if (!normalized.isEmpty()) {allNormalizedTables.add(normalized);}}}}return allNormalizedTables;}/*** 规范化表格,处理合并单元格* * @param table Tabula 提取的原始表格* @return 规范化的 List<List<String>>*/private List<List<String>> normalizeTable(Table table) {// 1. 提取所有单元格及其坐标List<Cell> allCells = new ArrayList<>();for (List<RectangularTextContainer> row : table.getRows()) {for (RectangularTextContainer tc : row) {allCells.add(new Cell(tc.getTop(), tc.getLeft(), tc.getWidth(), tc.getHeight(), tc.getText()));}}if (allCells.isEmpty()) {return new ArrayList<>();}// 2. 收集所有唯一的行起始位置和列起始位置,并添加结束位置NavigableSet<Float> rowBoundaries = new TreeSet<>();NavigableSet<Float> colBoundaries = new TreeSet<>();for (Cell cell : allCells) {rowBoundaries.add(roundCoordinate(cell.getTop()));rowBoundaries.add(roundCoordinate(cell.getBottom()));colBoundaries.add(roundCoordinate(cell.getLeft()));colBoundaries.add(roundCoordinate(cell.getRight()));}// 3. 转换为列表并去除首尾(表格外边界)List<Float> rowCoords = new ArrayList<>(rowBoundaries);List<Float> colCoords = new ArrayList<>(colBoundaries);// 移除最小和最大值(表格外边界),只保留内部网格线if (rowCoords.size() > 2) {rowCoords.remove(rowCoords.size() - 1); // 移除最大值(底边)rowCoords.remove(0); // 移除最小值(顶边)}if (colCoords.size() > 2) {colCoords.remove(colCoords.size() - 1); // 移除最大值(右边)colCoords.remove(0); // 移除最小值(左边)}// 4. 验证网格有效性if (rowCoords.isEmpty() || colCoords.isEmpty()) {return tableToListOfListOfStrings(table);}int numRows = rowCoords.size();int numCols = colCoords.size();String[][] grid = new String[numRows][numCols];// 初始化所有单元格为 nullfor (int r = 0; r < numRows; r++) {for (int c = 0; c < numCols; c++) {grid[r][c] = null;}}// 5. 将单元格内容填充到网格中for (Cell cell : allCells) {// 找到单元格在网格中的起始索引int startRow = findCellStartIndex(rowCoords, cell.getTop());int startCol = findCellStartIndex(colCoords, cell.getLeft());// 容错处理if (startRow == -1 || startCol == -1) {continue;}// 确保索引有效if (startRow >= numRows || startCol >= numCols) {continue;}// 计算单元格跨越的行数和列数int endRow = findCellEndIndex(rowCoords, cell.getBottom());int endCol = findCellEndIndex(colCoords, cell.getRight());if (endRow == -1)endRow = numRows - 1;if (endCol == -1)endCol = numCols - 1;// 将文本放置在左上角单元格if (grid[startRow][startCol] == null) {grid[startRow][startCol] = cell.text;} else {// 如果已有内容,追加(处理重叠情况)if (!grid[startRow][startCol].isEmpty() && !cell.text.isEmpty()) {grid[startRow][startCol] += " " + cell.text;} else if (!cell.text.isEmpty()) {grid[startRow][startCol] = cell.text;}}// 标记被合并覆盖的其他单元格for (int r = startRow; r <= endRow && r < numRows; r++) {for (int c = startCol; c <= endCol && c < numCols; c++) {if (r == startRow && c == startCol) {continue; // 跳过左上角已填充的单元格}if (grid[r][c] == null) {grid[r][c] = ""; // 标记为空字符串(合并单元格的一部分)}}}}// 6. 填充空单元格:优先从左侧填充,左侧为空则从上方填充for (int r = 0; r < numRows; r++) {for (int c = 0; c < numCols; c++) {if (grid[r][c] == null || grid[r][c].isEmpty()) {String fillContent = null;// 优先从左侧获取内容if (c > 0 && grid[r][c - 1] != null && !grid[r][c - 1].isEmpty()) {fillContent = grid[r][c - 1];}// 左侧为空或不存在,从上方获取内容else if (r > 0 && grid[r - 1][c] != null && !grid[r - 1][c].isEmpty()) {fillContent = grid[r - 1][c];}if (fillContent != null) {grid[r][c] = fillContent;} else if (grid[r][c] == null) {grid[r][c] = "";}}}}// 7. 将二维数组转换为 List<List<String>>List<List<String>> normalizedTable = new ArrayList<>();for (int r = 0; r < numRows; r++) {List<String> normalizedRow = new ArrayList<>();for (int c = 0; c < numCols; c++) {normalizedRow.add(grid[r][c] == null ? "" : grid[r][c]);}normalizedTable.add(normalizedRow);}return normalizedTable;}/*** 将坐标四舍五入到指定精度,减少浮点误差*/private float roundCoordinate(float coord) {return Math.round(coord * 10) / 10.0f;}/*** 查找单元格起始位置在网格中的索引*/private int findCellStartIndex(List<Float> coords, float value) {float roundedValue = roundCoordinate(value);for (int i = 0; i < coords.size(); i++) {// 单元格的起始位置应该在某个网格线上或之前if (roundedValue <= coords.get(i) + COORDINATE_TOLERANCE) {return i;}}return coords.size() - 1;}/*** 查找单元格结束位置在网格中的索引*/private int findCellEndIndex(List<Float> coords, float value) {float roundedValue = roundCoordinate(value);for (int i = coords.size() - 1; i >= 0; i--) {// 单元格的结束位置应该在某个网格线上或之后if (roundedValue >= coords.get(i) - COORDINATE_TOLERANCE) {return i;}}return 0;}/*** 将 Tabula 的 Table 对象转换为 List<List<String>>>* * @param table Tabula 的 Table 对象* @return List<List<String>>>*/public List<List<String>> tableToListOfListOfStrings(Table table) {// 创建一个列表来存储表格内容List<List<String>> list = new ArrayList<>();// 遍代表格中的每一行for (List<RectangularTextContainer> row : table.getRows()) {// 创建一个列表来存储当前行的内容List<String> rowList = new ArrayList<>();// 遍代当前行中的每一个单元格for (RectangularTextContainer tc : row) {// 将当前单元格的内容添加到行列表中String cellText = tc.getText() == null ? "" : tc.getText().trim();rowList.add(cellText);rowList.add(tc.getText() == null ? "" : tc.getText().trim());}// 将行列表添加到表格列表中list.add(rowList);}return list;}public static void main(String[] args) {// 请替换为你的 PDF 文件路径String pdfPath = "/Users/yuanzhenhui/Desktop/测试用合并单元格解析.pdf";File pdfFile = new File(pdfPath);if (!pdfFile.exists()) {System.err.println("错误: 测试文件未找到: " + pdfPath);System.err.println("请在 main 方法中替换为你本地的 PDF 文件路径。");return;}MergedCellPdfExtractor extractor = new MergedCellPdfExtractor();try {System.out.println("开始解析: " + pdfPath);List<List<List<String>>> tables = extractor.parseTables(pdfFile);System.out.println("解析完成,共找到 " + tables.size() + " 个表格。");System.out.println("========================================");int tableNum = 1;for (List<List<String>> table : tables) {System.out.println("\n表格 " + (tableNum++) + ":");System.out.println("行数: " + table.size() + ", 列数: " + (table.isEmpty() ? 0 : table.get(0).size()));System.out.println("----------------------------------------");for (List<String> row : table) {System.out.print("|");for (String cell : row) {String cellText = cell.replace("\n", " ").replace("\r", " ");if (cellText.length() > 15) {cellText = cellText.substring(0, 12) + "...";}System.out.print(String.format(" %-15s |", cellText));}System.out.println();}System.out.println("----------------------------------------");}} catch (IOException e) {System.err.println("解析 PDF 时出错: " + e.getMessage());e.printStackTrace();}}
}
关于代码的解释应该都清楚的了,由于只是用作试验我就没有很精细地封装了,大家凑合着用吧。如果面对更加复杂的表格的话我建议还是不要用这种填充的方式了,直接上大厂的 OCR 接口吧。
哦,还有东西忘了说了,关于 Maven 依赖的引入如下:
<dependency><groupId>technology.tabula</groupId><artifactId>tabula</artifactId><version>1.0.5</version>
</dependency>
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.35</version>
</dependency>
好了,该填的可能填好了。接下来的分享将继续回归到人工智能和区块链当中,欢迎您继续关注我的博客。