【论文精读】Latent-Shift:基于时间偏移模块的高效文本生成视频技术
标题:Latent-Shift: Latent Diffusion with Temporal Shift for Efficient Text-to-Video Generation
作者:Jie An, Songyang Zhang, Harry Yang, Sonal Gupta, Jia-Bin Huang, Jiebo Luo, Xi Yin(Jie An 与 Songyang Zhang 为同等贡献作者)
单位:University of Rochester(罗切斯特大学);Meta AI;niversity of Maryland, College Park(马里兰大学帕克分校),
发表:arXiv 预印本,arXiv:2304.08477v2 [cs.CV],发表时间为 2023 年 4 月 18 日
论文链接:https://arxiv.org/pdf/2304.08477
项目链接:https://latent-shift.github.io
关键词:Text-to-Video Generation(文本生成视频)、Latent Diffusion Model(潜在扩散模型)、Temporal Shift Module(时间偏移模块)、Efficient Generative AI(高效生成式人工智能)、Temporal Coherence Modeling(时间连贯性建模)
一、研究背景与挑战
1.1 T2V 技术的发展现状
在文本生成视频(T2V)领域,平衡生成质量、模型效率与功能通用性一直是核心挑战。近年来,生成式 AI 在文本生成图片(T2I)领域已取得突破,以 latent diffusion models(潜在扩散模型)为代表的技术,能通过在 latent 空间建模,高效生成高质量图像。而 T2V 技术作为延伸,面临着两大核心难题:
- 数据稀缺:高质量、大规模的文本 - 视频配对数据远少于文本 - 图像数据,限制了模型训练效果。
- 时间维度建模复杂:视频需同时处理空间信息(像素 / 特征分布)与时间信息(帧间运动连贯性),传统方法常需额外模块,导致模型复杂、计算成本高。
当前主流 T2V 框架分为两类:
| 框架类型 | 代表模型 | 核心特点 | 局限性 |
|---|---|---|---|
| Transformer+VAE | CogVideo、Phenaki | 在 latent 空间建模,参数规模大 | 生成视频分辨率低,需额外插值 / 超分模块 |
| 像素空间扩散模型 | Make-A-Video、Imagen Video | 生成质量较高 | 计算成本极高,需先生成低分辨率视频(如 64×64),再通过多阶段超分 / 插值优化 |
1.2 现有方案的效率痛点
现有 T2V 模型为实现时间建模,普遍采用 “增加模块” 的思路:
- Make-A-Video 在 ResNet 块中添加 1D 时间卷积层,在 Transformer 块中添加时间注意力层;
- MagicVideo、VDM 等在空间注意力层后额外增加时间注意力层。
这些方案虽能提升时间连贯性,但会导致两个问题:
- 参数膨胀:额外模块使模型参数规模大幅增加,如 CogVideo 整体参数达 155 亿,推理速度极慢(单 A100 GPU 需 434.53 秒生成一段视频);
- 功能单一:为 T2V 优化的模型无法再用于 T2I 生成,缺乏通用性。
Latent-Shift 的核心目标正是解决上述痛点:在不增加模型参数的前提下,让预训练 T2I 模型具备 T2V 能力,同时保留 T2I 功能,实现 “高效 + 通用” 双重价值。

二、核心方法:Latent-Shift 技术原理
Latent-Shift 基于预训练 T2I 潜在扩散模型,通过无参数时间偏移模块(Temporal Shift Module) 实现时间维度建模,整体框架分为三部分:预训练 T2I 潜在扩散模型、时间偏移模块、T2V 适配流程。
2.1 基础:T2I 潜在扩散模型回顾
T2I 潜在扩散模型分为两个训练阶段,为 T2V 适配提供基础:
-
Autoencoder(自编码器)训练:将像素空间图像
(H/W 为图像高 / 宽)通过编码器
压缩为 latent 空间表示
(h/w 为 latent 特征高 / 宽,c 为通道数),再通过解码器 D 重构回像素空间
。训练目标是最小化重构误差,使 latent 空间能高效表示图像信息。注:文中采用预训练 VAE 作为 Autoencoder,下采样因子
(m 为整数),例如 256×256 图像会被压缩为 32×32 的 latent 特征(f=8)。
-
条件潜在扩散模型训练:在 latent 空间训练基于 U-Net 的扩散模型,以文本为条件生成图像。具体流程为:
- 对 latent 特征
逐步添加高斯噪声,得到不同时间步的带噪特征
,噪声强度由
(噪声系数)和
(方差)控制;
- 将文本通过文本编码器(如 BERT)转换为特征
,通过交叉注意力机制输入 U-Net;
- 训练 U-Net 学习 “从带噪特征
” 的能力,损失函数采用均方误差(MSE):
- 对 latent 特征
2.2 核心创新:无参数时间偏移模块
Latent-Shift 的关键突破是时间偏移模块—— 无需添加任何可学习参数,仅通过特征通道的 “时间维度重排”,让当前帧特征融合前后帧信息,实现时间连贯性建模。
2.2.1 模块工作流程
假设输入到模块的视频 latent 特征为(C 为通道数,F 为帧数,H/W 为特征高 / 宽),单帧特征为
(i 为帧索引,1≤i≤F),模块分为三步操作(如图 2 所示):
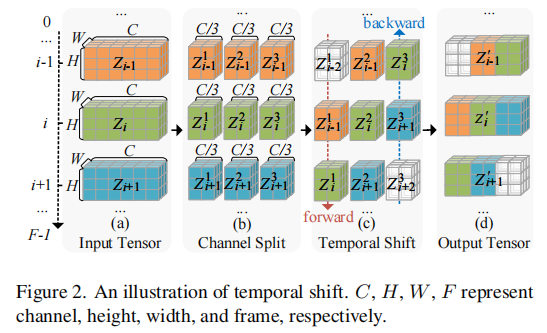
图 2 中,C 为通道数,F 为帧数,H/W 为特征高 / 宽。模块通过通道拆分、时间偏移、合并,实现帧间特征融合。
-
通道拆分(Channel Split):将每帧特征
沿通道维度平均拆分为 3 部分:
,每部分通道数为
,即
(j=1,2,3)。
-
时间偏移(Temporal Shift):
- 对
(第一部分通道)进行 “向后偏移”:第 i 帧的
;
- 对
(第三部分通道)进行 “向前偏移”:第 i 帧的
;
- 对 \(Z_i^2\)(第二部分通道)不偏移,保留当前帧信息;
- 边界处理:首帧(i=1)的 “向后偏移” 部分用零填充(0),末帧(i=F)的 “向前偏移” 部分用零填充。
- 对
-
特征合并(Merge):将偏移后的
、
,整个视频的特征变为
。
2.2.2 模块核心价值
时间偏移模块的巧妙之处在于:
- 无参数设计:仅通过通道重排实现帧间信息交互,不增加任何可学习参数,避免模型膨胀;
- 时间感受野扩展:每帧特征融合了前一帧(
- 与空间 U-Net 兼容:偏移后的特征可直接输入原 T2I U-Net 的 2D 卷积层,无需修改 U-Net 结构 ——2D 卷积会同时处理空间信息与偏移带来的时间信息,实现 “空间 - 时间联合建模”。
2.3 Latent-Shift 的 T2V 适配流程
基于上述模块,Latent-Shift 将预训练 T2I 模型适配为 T2V 模型的流程如图 3 所示,分为训练与推理两个阶段:
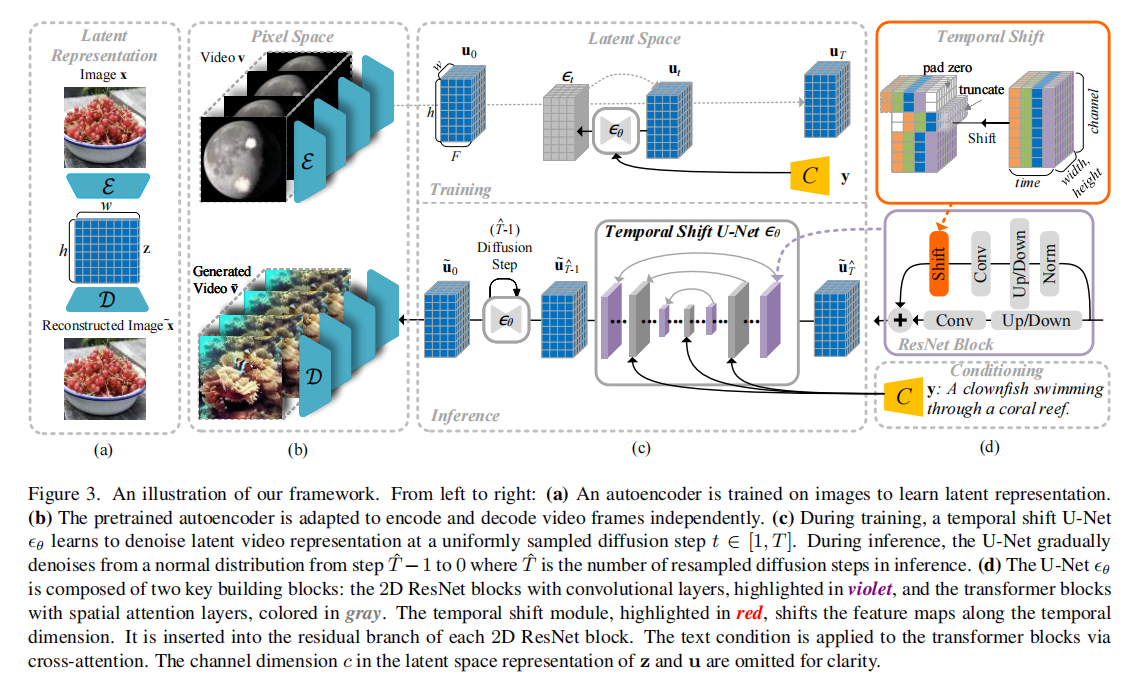
图 3 中,(a) 为预训练 Autoencoder;(b) 为 Autoencoder 适配视频帧独立编码 / 解码;(c) 为带时间偏移模块的 U-Net 训练与推理;(d) 为 U-Net 内部结构(红色为时间偏移模块)。
2.3.1 训练阶段
-
视频数据预处理:从 WebVid 数据集(10M 文本 - 视频对)中抽取 2 秒视频片段,均匀采样 16 帧,每帧 resize 并中心裁剪为 256×256;通过预训练 Autoencoder 的编码器
(F=16,h=32,w=32,c=4)。
-
时间偏移模块插入:在 U-Net 的每个 2D ResNet 块的残差分支中,插入时间偏移模块(如图 3 (d) 红色部分)—— 残差分支的特征先经过时间偏移处理,再输入后续卷积层。
-
扩散模型训练:
- 对视频 latent 表示
逐步添加高斯噪声,得到带噪特征
,噪声控制方式与 T2I 一致;
- 文本通过预训练文本编码器转换为特征
- 训练目标:让 U-Net 学习从
- 引入分类器 - free guidance:训练时以一定概率丢弃文本输入,让模型同时学习 “有条件(文本引导)” 和 “无条件(自由生成)” 的去噪能力,提升推理时文本与视频的对齐度。
- 对视频 latent 表示
2.3.2 推理阶段
- 从标准正态分布中采样初始带噪视频 latent 特征
(T=1000,推理时重采样为 100 步以提升效率);
- 文本通过文本编码器得到
- 逐步去噪:从 t=T 到 t=0,U-Net 基于
,最终得到去噪后的视频 latent 特征
;
- 解码:通过 Autoencoder 的解码器 D 将
。
2.3.3 保留 T2I 能力的关键
Latent-Shift 能同时支持 T2V 和 T2I 的核心原因是:
- 时间偏移模块对 “单帧输入” 兼容 —— 当输入为单帧(F=1)时,“向后偏移” 和 “向前偏移” 部分均为零填充,U-Net 可通过训练学习 “零填充场景下的特征处理”,从而正常生成图像;
- 对比之下,Latent-VDM(带时间注意力的基线模型)因依赖多帧上下文信息,单帧输入时会因 “上下文缺失” 导致生成失败。
三、实验验证:效果与效率评估
为验证 Latent-Shift 的有效性,团队在MSR-VTT(零样本评估)、UCF-101(微调评估) 两个标准数据集上进行测试,并通过用户研究验证主观质量,同时对比模型参数与推理速度。
3.1 实验设置
- 数据集:
- 训练集:WebVid(10M 文本 - 视频对);
- 测试集 1:MSR-VTT(零样本,用测试集所有文本生成视频,计算帧级指标);
- 测试集 2:UCF-101(微调,13320 个视频,101 个动作类别,用模板文本生成对应类别视频)。
- 评估指标:
- 客观指标:Inception Score(IS,图像质量,越高越好)、FID(帧间相似度,越低越好)、FVD(视频间相似度,越低越好)、CLIPSIM(文本 - 视频对齐度,越高越好);
- 主观指标:用户研究(AMT 平台,5 名标注员对比视频质量与文本对齐度,取多数投票)。
- 基线模型:CogVideo、Make-A-Video、VDM、Latent-VDM(带时间注意力的 Latent 扩散模型,与 Latent-Shift 同训练设置,仅替换时间偏移模块为时间注意力)。
3.2 核心实验结果
3.2.1 零样本评估(MSR-VTT)
MSR-VTT 测试无需在该数据集上微调,直接用预训练模型生成视频,更能反映模型泛化能力,结果如表 1 所示:
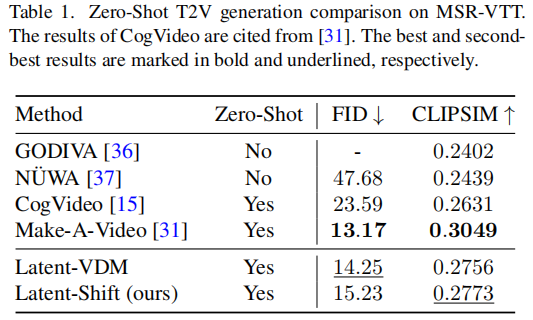
结果分析:
- Latent-Shift 的 FID(15.23)略高于 Make-A-Video(13.17),但远低于 CogVideo(23.59),说明帧级质量优于 CogVideo;
- CLIPSIM(0.2773)高于 Latent-VDM(0.2756)和 CogVideo(0.2631),文本 - 视频对齐度更优;
- 需注意:Make-A-Video 模型规模远大于 Latent-Shift(前者整体参数 97.2 亿,后者仅 15.3 亿),在参数更少的情况下,Latent-Shift 性能已接近 Make-A-Video,效率优势显著。
3.2.2 微调评估(UCF-101)
UCF-101 需在数据集上微调后评估,重点关注动作类别的视频生成质量,结果如表 2 所示:
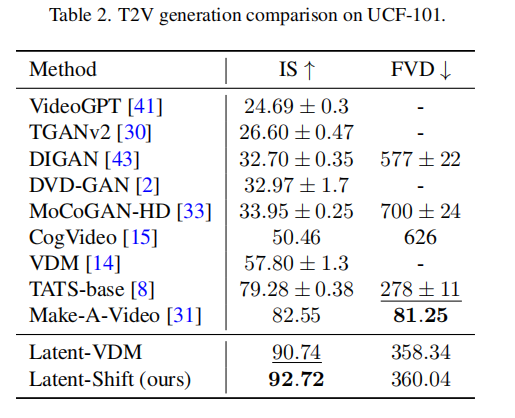
结果分析:
- Latent-Shift 的 IS 值(92.72)为所有模型中最高,说明生成视频的帧级质量最优;
- FVD 值(360.04)虽略高于 Latent-VDM(358.34),但远低于 CogVideo(626),时间连贯性仍优于传统模型;
- 这表明:即使在动作类视频(对时间连贯性要求高)上,无参数时间偏移模块的效果已接近甚至超过传统时间注意力模块。
3.2.3 用户研究(主观质量评估)
客观指标无法完全反映视频的 “观感” 与 “文本对齐度”,团队通过 AMT 平台对比 Latent-Shift、Latent-VDM 与 CogVideo 的主观表现,结果如表 3 所示(百分比为 “偏好该模型” 的标注员比例):
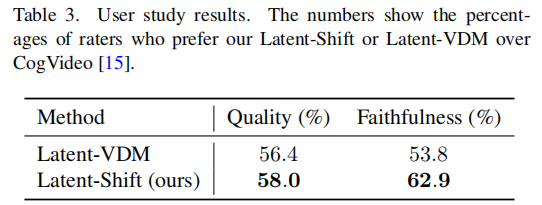
结果分析:
- Latent-Shift 在 “视频质量” 和 “文本对齐度” 上均优于 Latent-VDM 和 CogVideo,尤其在文本对齐度上优势明显(62.9% vs 53.8%);
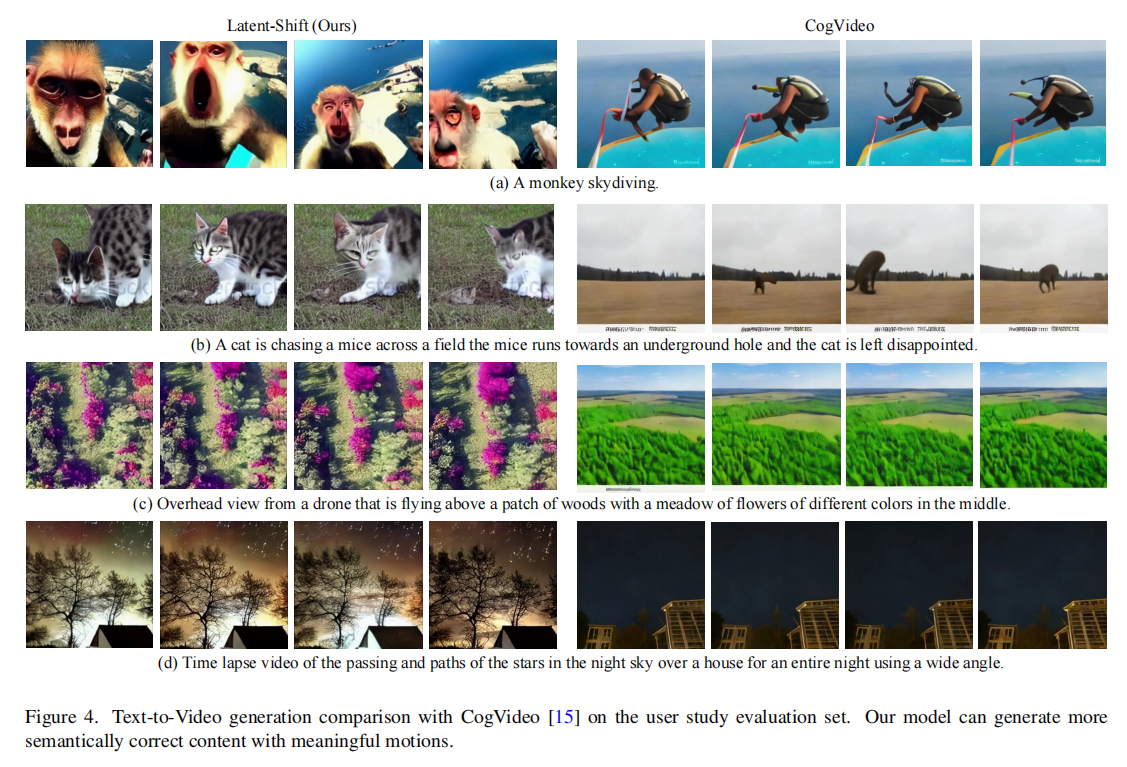
- 结合图 4、图 5 的定性对比(如 “猴子跳伞”“猫追老鼠” 等案例),Latent-Shift 能生成更符合文本描述的细节(如 “老鼠钻进地洞”“猫失望离开”),且运动更自然,无明显帧闪烁。

3.2.4 效率对比(参数与推理速度)
效率是 Latent-Shift 的核心优势,团队在单 A100(80GB)GPU 上测试模型参数规模与推理速度,结果如表 4 所示:
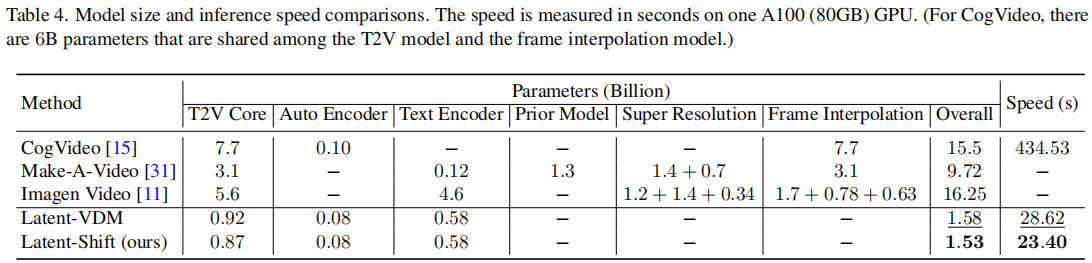
结果分析:
- 参数规模:Latent-Shift 整体参数仅 1.53 亿,远低于 CogVideo(155 亿)、Make-A-Video(97.2 亿),与 Latent-VDM(1.58 亿)基本持平,因无额外参数;
- 推理速度:Latent-Shift 推理时间仅 23.40 秒,是 CogVideo 的 18.6 倍,也快于 Latent-VDM(28.62 秒)—— 这是因为时间偏移模块无需计算注意力权重,计算成本远低于时间注意力模块。
3.3 消融实验:验证时间偏移模块的必要性
为验证时间偏移模块的核心作用,团队设计两组消融实验:
3.3.1 时间偏移 vs 时间注意力
对比 Latent-Shift(时间偏移)与 Latent-VDM(时间注意力)的关键指标:
- 性能:Latent-Shift 在 MSR-VTT 的 CLIPSIM(0.2773 vs 0.2756)、UCF-101 的 IS(92.72 vs 90.74)均更高;
- 效率:Latent-Shift 参数更少(1.53 亿 vs 1.58 亿),推理更快(23.40 秒 vs 28.62 秒);
- 结论:无参数时间偏移模块的效果优于传统时间注意力模块,且效率更高。
3.3.2 时间偏移模块对 T2I 能力的影响
测试 Latent-Shift 在 “有无时间偏移模块” 下的 T2I 生成能力,结果如图 6 所示:
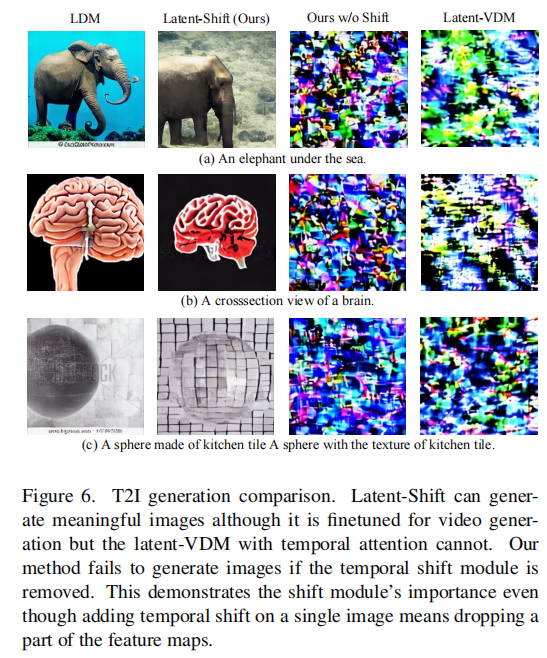
- 有时间偏移:Latent-Shift 能生成符合文本的图像(如 “海底的大象”“厨房瓷砖纹理的球体”),FID(15.64)与原 T2I 模型(LDM,15.36)接近;
- 无时间偏移:生成图像完全失效,出现明显失真;
- Latent-VDM:因时间注意力依赖多帧上下文,单帧输入时生成图像完全失效;
- 结论:时间偏移模块不仅是 T2V 的核心,也是 Latent-Shift 保留 T2I 能力的关键 —— 零填充设计让模型能处理单帧输入。
3.4 失败案例分析
Latent-Shift 虽表现优异,但仍存在三类典型失败案例(如图 8 所示),为后续优化提供方向:

- 物体失真与帧闪烁:当文本描述 “非现实场景”(如 “跳探戈的猫”)时,因训练数据中此类样本少,且 VAE 仅用图像训练,导致视频出现物体变形、帧间闪烁;
- 文本对齐不完整:对复杂文本(如 “汽车视频评测”),模型可能遗漏关键元素(如未生成 “评测界面” 或 “汽车细节”);
- 运动幅度有限:当文本描述 “细微动作”(如 “麝牛在野花上吃草”)时,生成视频的帧间运动差异小,观感接近静态图像 —— 这是当前 T2V 模型的共性问题。
四、总结与展望
4.1 研究贡献
Latent-Shift 通过创新的无参数时间偏移模块,为 T2V 技术提供了 “高效 + 通用” 的新范式,核心贡献可概括为三点:
- 无参数时间建模:首次提出通过 “特征通道时间偏移” 实现帧间信息交互,无需添加任何参数,解决传统模型参数膨胀问题;
- 双功能兼容:微调后的模型可同时用于 T2V 和 T2I 生成,打破 “T2V 模型功能单一” 的局限,提升模型实用性;
- 效率与质量平衡:在 MSR-VTT、UCF-101 数据集上,Latent-Shift 的生成质量优于 CogVideo 等模型,同时推理速度提升 18 倍以上,参数规模仅为前者的 1%。
4.2 未来优化方向
基于实验中的失败案例,Latent-Shift 的后续优化可聚焦三个方向:
- 多模态数据融合:将视频帧与图像数据联合训练 Autoencoder,让 latent 空间更好地捕捉视频特有的时间信息,缓解 “非现实场景失真” 问题;
- 细粒度文本对齐:结合更先进的文本编码器(如 GPT 系列),提升模型对复杂文本的理解能力,减少 “关键元素遗漏”;
- 运动幅度控制:引入 “运动强度预测分支”,根据文本描述动态调整视频的运动幅度,解决 “细微动作生成不足” 的问题。
4.3 行业价值
Latent-Shift 的技术思路为 T2V 落地提供了重要参考:
- 降低部署成本:小参数、快推理的特点,让 T2V 技术更易在边缘设备(如 PC、中端 GPU)上部署,推动消费级应用;
- 数据利用效率:基于预训练 T2I 模型,减少对文本 - 视频数据的依赖,为数据稀缺场景下的 T2V 模型训练提供解决方案;
- 多任务协同:双功能兼容特性可降低多模态生成系统的开发成本,例如在同一框架内实现 “文本生成图像 + 视频” 的一站式服务。
Latent-Shift 的创新在于 “以巧破重”—— 不依赖 “堆模块、加参数” 的传统思路,而是通过特征操作的优化,实现时间维度的高效建模。这种 “极简主义” 的设计哲学,或许是未来生成式 AI 在效率与质量间寻找平衡的重要方向。