Rust语言特性深度解析:所有权、生命周期与模式匹配之我见
目录
- 一、引言
- 二、所有权系统
- 2.1 所有权概念
- 2.2 所有权规则
- 2.3 Rust的内存管理模型
- 2.4 移动语义
- 2.5 克隆(Clone)
- 三、借用与生命周期
- 3.1 借用概念
- 3.2 不可变借用
- 3.3 可变借用
- 3.4 借用规则
- 3.5 生命周期
- 3.6 生命周期省略
- 3.7 'static生命周期
- 四、模式匹配
- 4.1 match语句
- 4.2 if let表达式
- 4.3 while let表达式
- 4.4 for循环中的模式
- 4.5 let语句中的模式
- 4.6 函数参数中的模式
- 4.7 高级模式
- 五、实战应用:综合案例
- 5.1 字符串处理器
- 5.2 自定义数据结构与模式匹配
- 5.3 迭代器与闭包组合
- 六、常见陷阱与最佳实践
- 6.1 所有权问题
- 6.2 生命周期问题
- 6.3 模式匹配问题
- 6.4 最佳实践
- 七、结语
- 八、参考资料
一、引言
在当今软件开发领域,系统级编程语言面临着前所未有的挑战。开发者需要在性能、安全性和开发效率之间找到平衡点。Rust语言作为一种新兴的系统级编程语言,通过其独特的所有权系统、生命周期管理和强大的模式匹配能力,为解决这些挑战提供了新的思路和方法。
Rust由Mozilla开发,于2010年首次发布,2015年发布1.0版本。它的设计目标是提供内存安全、并发安全和高性能的编程环境,同时保持良好的开发体验。Rust特别适合系统编程、WebAssembly应用、网络服务开发和嵌入式系统等对性能和安全性要求较高的场景。
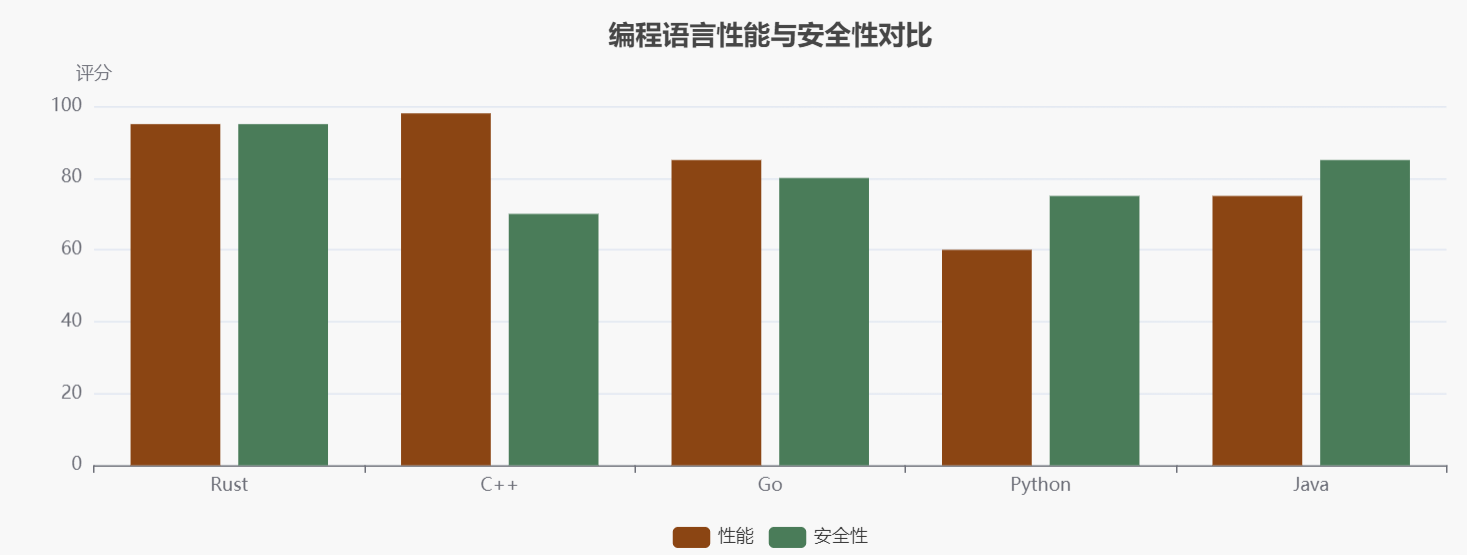
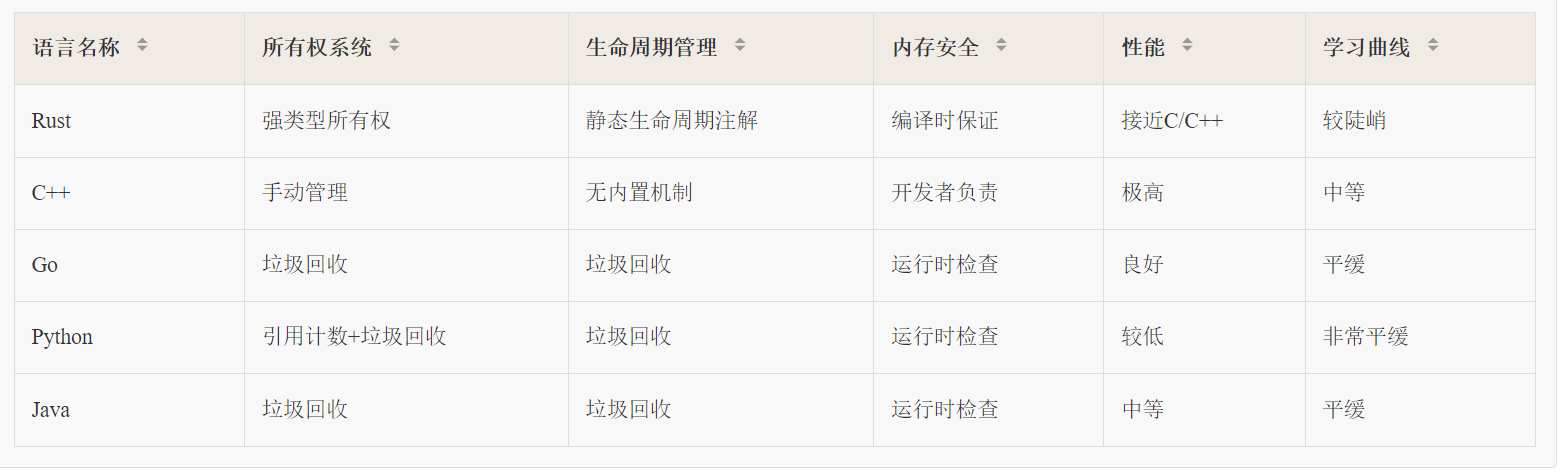
本文将深入探讨Rust语言的三个核心特性:所有权系统(Ownership)、生命周期(Lifetimes)和模式匹配(Pattern Matching)。这些特性不仅是Rust语言设计哲学的体现,也是Rust能够在编译时保证内存安全的关键所在。通过深入理解这些概念,开发者能够更好地利用Rust的优势,编写出高效、安全的代码。编程语言性能与安全性对比如下所示:
二、所有权系统
所有权系统是Rust语言最独特、最重要的特性之一,它是Rust无需垃圾回收即可保证内存安全的核心机制。理解所有权系统是掌握Rust编程的关键一步。
2.1 所有权概念
所有权(Ownership)是Rust管理内存的一组规则,它允许Rust在编译时进行内存安全检查,而无需在运行时进行垃圾回收或引用计数。每个值在Rust中都有一个"所有者"变量,当所有者变量离开作用域时,该值将被自动清理。
2.2 所有权规则
Rust的所有权系统遵循以下三个核心规则:
- 每个值都有一个变量,这个变量是该值的所有者。
- 同一时间,一个值只能有一个所有者。
- 当所有者超出作用域时,该值将被自动销毁。
Rust所有权规则与常见错误如下:

2.3 Rust的内存管理模型
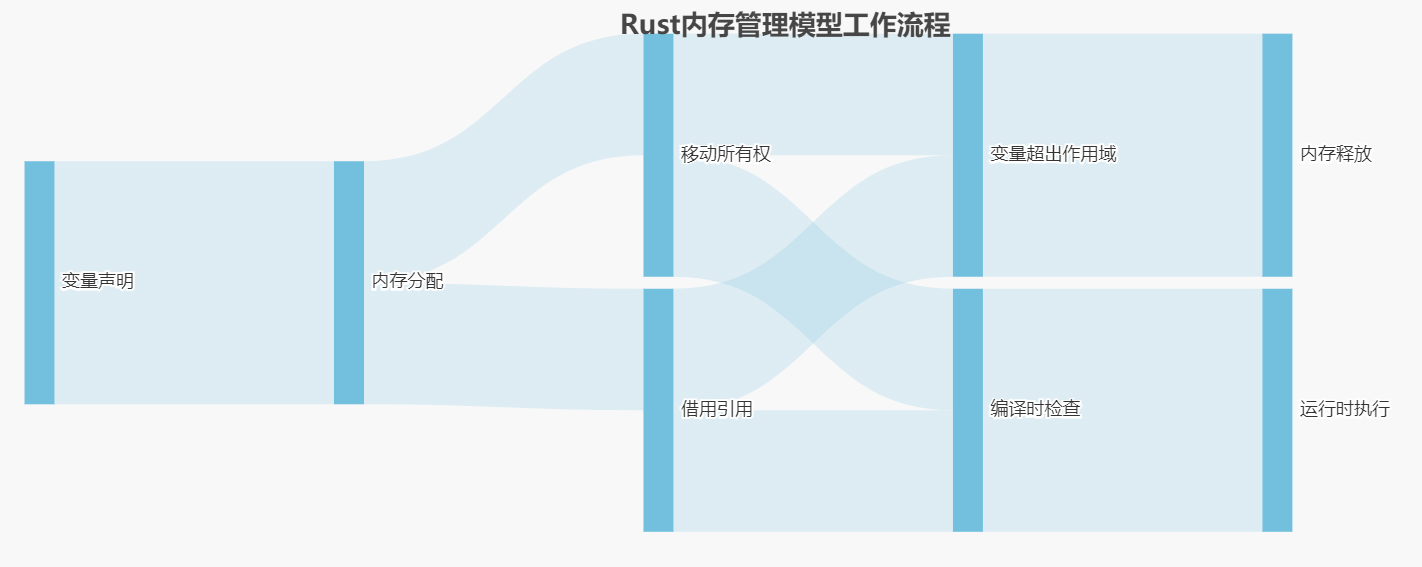
与其他语言不同,Rust采用了一种独特的内存管理模型,结合了编译时检查和确定性的资源释放。当变量进入作用域时,内存被分配;当变量离开作用域时,内存被自动释放。这个过程是通过一个名为drop的特殊函数实现的。Rust内存管理模型工作流程如图所示:
示例:作用域与内存管理复制
fn main() {{ // s 不可用,尚未声明let s = "hello"; // s 可用,被声明println!("{}", s); // 使用 s} // s 离开作用域,内存被释放// println!("{}", s); // 错误!s 不再可用
}2.4 移动语义
Rust的移动语义是其所有权系统的重要组成部分。当一个值从一个变量移动到另一个变量时,原变量将不再有效,这防止了悬垂指针和双重释放等问题。
示例:移动语义复制
fn main() {let s1 = String::from("hello"); // s1 是字符串 "hello" 的所有者let s2 = s1; // 移动发生,s2 成为 "hello" 的新所有者// println!("{}, world!", s1); // 错误!s1 不再有效println!("{}, world!", s2); // 正确,s2 是有效的所有者
}在上面的代码中,当我们将s1赋值给s2时,发生了移动操作。此时,s1不再拥有字符串数据的所有权,Rust将确保我们不能再使用s1,这样就避免了双重释放的问题。
2.5 克隆(Clone)
如果我们确实需要复制数据而不是移动所有权,可以使用clone方法。克隆会创建数据的完整副本,而不仅仅是移动引用。
示例:克隆操作复制
fn main() {let s1 = String::from("hello");let s2 = s1.clone(); // 创建字符串的深拷贝println!("s1 = {}, s2 = {}", s1, s2); // 两个变量都有效
}需要注意的是,克隆操作通常比较昂贵,因为它需要复制底层的数据。在性能敏感的场景中,应该谨慎使用克隆。
三、借用与生命周期
所有权系统虽然能够保证内存安全,但如果每次使用数据都需要转移所有权,会使代码变得冗长且难以使用。为了解决这个问题,Rust引入了借用(Borrowing)机制,允许我们引用数据而不获取其所有权。
3.1 借用概念
借用是Rust中引用数据的一种方式,它允许我们使用值但不获取其所有权。借用通过引用操作符&实现,引用默认是不可变的。
3.2 不可变借用
不可变借用允许我们读取但不能修改数据。我们可以同时拥有多个不可变引用,这支持了数据的共享读取。
示例:不可变借用复制
fn main() {let s1 = String::from("hello");let len = calculate_length(&s1); // 传递 s1 的不可变引用println!("'{}' 的长度是 {}", s1, len);
}fn calculate_length(s: &String) -> usize { // 函数接受字符串引用s.len() // 可以读取但不能修改 s
}3.3 可变借用
可变借用允许我们修改数据,但为了保证内存安全,Rust对可变借用有严格的限制:在同一时间,对同一数据只能有一个可变引用,或者可以有多个不可变引用,但不能同时拥有可变引用和不可变引用。
示例:可变借用复制
fn main() {let mut s = String::from("hello");change(&mut s); // 传递可变引用println!("修改后的字符串: {}", s);
}fn change(some_string: &mut String) { // 函数接受可变引用some_string.push_str(", world"); // 修改引用的字符串
}示例:错误的借用复制
fn main() {let mut s = String::from("hello");let r1 = &mut s; // 第一个可变引用// let r2 = &mut s; // 错误!同一时间只能有一个可变引用println!("{}", r1); // r1 在此处使用完毕let r2 = &mut s; // 此时可以创建新的可变引用println!("{}", r2);
}3.4 借用规则
Rust的借用系统遵循以下规则:
- 在任意给定时间,要么可以有一个可变引用,要么可以有任意数量的不可变引用,但不能同时拥有。
- 引用必须总是有效的,不能引用已经被释放的数据。
3.5 生命周期
生命周期是Rust中一个重要的概念,它定义了引用的有效期。通过生命周期注解,我们可以告诉编译器引用之间的关系,以确保引用总是有效的。
生命周期注解使用单引号(')后跟标识符来表示,最常用的标识符是'a。生命周期注解不会改变引用的实际生命周期,它们只是告诉编译器如何检查引用的有效性。
示例:生命周期注解复制
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { // 生命周期注解if x.len() > y.len() {x} else {y}
}在上面的代码中,我们使用生命周期注解'a表示函数参数和返回值的引用都必须具有相同的生命周期。这样编译器就能确保返回的引用在函数调用者使用它时仍然有效。
3.6 生命周期省略
为了简化代码,Rust编译器在特定情况下可以自动推断生命周期,这称为生命周期省略(Lifetime Elision)。Rust有一套规则来自动推断函数签名中的生命周期:
- 每个引用参数获得自己的生命周期参数。
- 如果只有一个输入生命周期参数,它会被赋予给所有输出生命周期参数。
- 如果方法有多个输入生命周期参数,但其中一个是
&self或&mut self,则self的生命周期会被赋予给所有输出生命周期参数。
示例:生命周期省略复制
// 原始函数,带有生命周期注解
fn first_word<'a>(s: &'a str) -> &'a str {let bytes = s.as_bytes();for (i, &item) in bytes.iter().enumerate() {if item == b' ' {return &s[0..i];}}&s[..]
}// 编译器可以推断生命周期,简化为
fn first_word(s: &str) -> &str {let bytes = s.as_bytes();for (i, &item) in bytes.iter().enumerate() {if item == b' ' {return &s[0..i];}}&s[..]
}3.7 'static生命周期
'static是一个特殊的生命周期注解,表示引用可以在程序的整个生命周期内有效。字符串字面量默认具有'static生命周期。
示例:'static生命周期复制
let s: &'static str = "这是一个字符串字面量";fn returns_static() -> &'static str {"返回一个'static生命周期的字符串"
}四、模式匹配
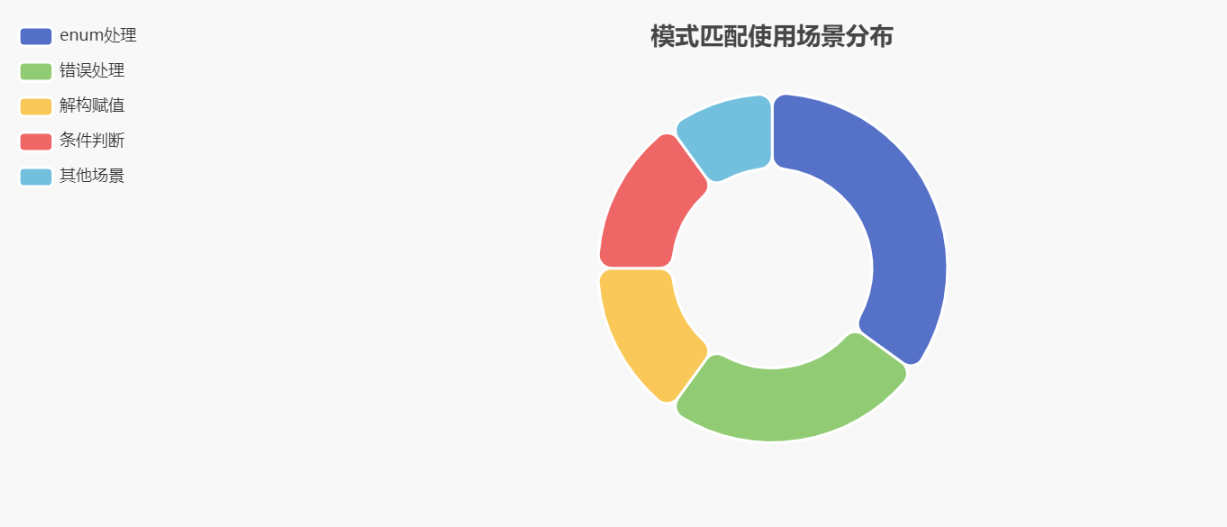
模式匹配是Rust语言中一种强大的功能,它允许我们根据值的结构来执行不同的代码路径。Rust的模式匹配比许多其他语言更加灵活和强大,它可以与各种数据类型配合使用。模式匹配使用场景分布如图:
4.1 match语句
match语句是Rust中最基本也是最强大的模式匹配结构。它类似于其他语言中的switch语句,但功能更加强大,要求必须穷尽所有可能的情况。
示例:match语句复制
enum Coin {Penny,Nickel,Dime,Quarter,
}fn value_in_cents(coin: Coin) -> u8 {match coin {Coin::Penny => {println!("幸运便士!");1},Coin::Nickel => 5,Coin::Dime => 10,Coin::Quarter => 25,}
}4.2 if let表达式
当我们只关心一种模式而忽略其他所有模式时,可以使用if let表达式来简化match语句。它结合了if和let,提供了一种更加简洁的语法。
示例:if let表达式复制
let some_u8_value = Some(3);// 使用match
match some_u8_value {Some(3) => println!("值是3"),_ => (),
}// 使用if let简化
if let Some(3) = some_u8_value {println!("值是3");
}4.3 while let表达式
while let表达式允许我们在模式匹配成功时重复执行代码块,直到模式匹配失败为止。这在处理迭代器或其他需要重复尝试的情况时非常有用。
示例:while let表达式复制
let mut stack = Vec::new();
stack.push(1);
stack.push(2);
stack.push(3);// 当pop()返回Some值时继续循环
while let Some(top) = stack.pop() {println!("栈顶元素: {}", top);
}
// 输出:
// 栈顶元素: 3
// 栈顶元素: 2
// 栈顶元素: 14.4 for循环中的模式
在for循环中,我们也可以使用模式来解构集合中的元素。
示例:for循环中的模式复制
let v = vec![1, 2, 3];// 解构元组中的索引和值
for (index, value) in v.iter().enumerate() {println!("索引 {} 的值是: {}", index, value);
}
// 输出:
// 索引 0 的值是: 1
// 索引 1 的值是: 2
// 索引 2 的值是: 34.5 let语句中的模式
在Rust中,let语句本身就是一种模式匹配。这允许我们使用模式来解构复杂的数据结构。
示例:let语句中的模式复制
// 解构元组
let (x, y, z) = (1, 2, 3);
println!("x = {}, y = {}, z = {}", x, y, z); // 输出: x = 1, y = 2, z = 3// 解构结构体
struct Point { x: i32, y: i32 }
let p = Point { x: 10, y: 20 };
let Point { x: a, y: b } = p;
println!("a = {}, b = {}", a, b); // 输出: a = 10, b = 20// 简写形式
let Point { x, y } = p;
println!("x = {}, y = {}", x, y); // 输出: x = 10, y = 204.6 函数参数中的模式
函数参数也可以使用模式来解构传入的值。
示例:函数参数中的模式复制
// 解构元组参数
fn print_coordinates(&(x, y): &(i32, i32)) {println!("当前坐标: ({}, {})", x, y);
}let point = (3, 5);
print_coordinates(&point); // 输出: 当前坐标: (3, 5)// 解构结构体参数
struct Rectangle { width: u32, height: u32 }
fn area(Rectangle { width, height }: Rectangle) -> u32 {width * height
}let rect = Rectangle { width: 10, height: 20 };
println!("矩形面积: {}", area(rect)); // 输出: 矩形面积: 2004.7 高级模式
Rust还支持一些高级的模式匹配技术,如通配符、范围匹配、守卫条件等。
示例:高级模式复制
// 通配符
let numbers = (2, 4, 8, 16, 32);
let (first, _, third, _, fifth) = numbers;
println!("first = {}, third = {}, fifth = {}", first, third, fifth);// 范围匹配
let x = 5;
match x {1..=5 => println!("x 在1到5之间"),6..=10 => println!("x 在6到10之间"),_ => println!("x 在其他范围内"),
}// 守卫条件
let y = Some(8);
match y {Some(x) if x % 2 == 0 => println!("偶数: {}", x),Some(x) => println!("奇数: {}", x),None => println!("没有值"),
}五、实战应用:综合案例
现在,让我们通过几个综合案例来展示Rust的所有权系统、生命周期和模式匹配如何协同工作,以解决实际编程问题。
5.1 字符串处理器
下面的例子展示了如何创建一个字符串处理器,它可以根据不同的命令对字符串进行操作。
示例:字符串处理器复制
enum Command {Uppercase,Lowercase,Trim,Append(String),
}struct StringProcessor {content: String,
}impl StringProcessor {fn new(content: &str) -> Self {Self { content: content.to_string() }}fn process(&mut self, cmd: Command) {match cmd {Command::Uppercase => {self.content = self.content.to_uppercase();},Command::Lowercase => {self.content = self.content.to_lowercase();},Command::Trim => {self.content = self.content.trim().to_string();},Command::Append(s) => {self.content.push_str(&s);},}}fn get_content(&self) -> &str {&self.content}
}fn main() {let mut processor = StringProcessor::new(" Hello, Rust! ");processor.process(Command::Trim);println!("裁剪后: '{}'", processor.get_content());processor.process(Command::Uppercase);println!("大写后: '{}'", processor.get_content());processor.process(Command::Append(". Welcome to Rust world!"));println!("追加后: '{}'", processor.get_content());// 输出:// 裁剪后: 'Hello, Rust!'// 大写后: 'HELLO, RUST!'// 追加后: 'HELLO, RUST!. Welcome to Rust world!'
}5.2 自定义数据结构与模式匹配
这个例子展示了如何创建一个自定义的数据结构,并使用模式匹配来处理不同的情况。
示例:自定义数据结构与模式匹配复制
// 定义一个简单的表达式枚举
enum Expression {Constant(i32),Add(Box, Box),Subtract(Box, Box),Multiply(Box, Box),Divide(Box, Box),
}impl Expression {// 计算表达式的值fn evaluate(&self) -> Result {match self {Expression::Constant(value) => Ok(*value),Expression::Add(left, right) => {let left_val = left.evaluate()?;let right_val = right.evaluate()?;Ok(left_val + right_val)},Expression::Subtract(left, right) => {let left_val = left.evaluate()?;let right_val = right.evaluate()?;Ok(left_val - right_val)},Expression::Multiply(left, right) => {let left_val = left.evaluate()?;let right_val = right.evaluate()?;Ok(left_val * right_val)},Expression::Divide(left, right) => {let left_val = left.evaluate()?;let right_val = right.evaluate()?;if right_val == 0 {Err("除数不能为零".to_string())} else {Ok(left_val / right_val)}},}}
}fn main() {// 创建表达式: (2 + 3) * (5 - 1)let expr = Expression::Multiply(Box::new(Expression::Add(Box::new(Expression::Constant(2)),Box::new(Expression::Constant(3)),)),Box::new(Expression::Subtract(Box::new(Expression::Constant(5)),Box::new(Expression::Constant(1)),)),);match expr.evaluate() {Ok(result) => println!("表达式结果: {}", result), // 输出: 表达式结果: 20Err(err) => println!("计算错误: {}", err),}// 创建一个会导致错误的表达式: 10 / (5 - 5)let invalid_expr = Expression::Divide(Box::new(Expression::Constant(10)),Box::new(Expression::Subtract(Box::new(Expression::Constant(5)),Box::new(Expression::Constant(5)),)),);match invalid_expr.evaluate() {Ok(result) => println!("表达式结果: {}", result),Err(err) => println!("计算错误: {}", err), // 输出: 计算错误: 除数不能为零}
}5.3 迭代器与闭包组合
这个例子展示了如何使用Rust的迭代器和闭包,结合所有权系统,来处理数据集合。
示例:迭代器与闭包组合复制
fn main() {let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];// 使用迭代器和闭包处理数据let result: Vec = numbers.iter().filter(|&x| x % 2 == 0) // 过滤偶数.map(|&x| x * x) // 计算平方.collect(); // 收集结果println!("偶数的平方: {:?}", result); // 输出: 偶数的平方: [4, 16, 36, 64, 100]// 计算平均值(处理可能为空的情况)let avg = if numbers.is_empty() {None} else {Some(numbers.iter().sum::() as f64 / numbers.len() as f64)};if let Some(average) = avg {println!("平均值: {:.2}", average); // 输出: 平均值: 5.50} else {println!("集合为空,无法计算平均值");}// 使用模式匹配处理元组let pairs = vec![(1, "one"), (2, "two"), (3, "three")];for (num, word) in pairs {println!("数字 {} 的英文是 '{}'", num, word);}// 输出:// 数字 1 的英文是 'one'// 数字 2 的英文是 'two'// 数字 3 的英文是 'three'
}六、常见陷阱与最佳实践
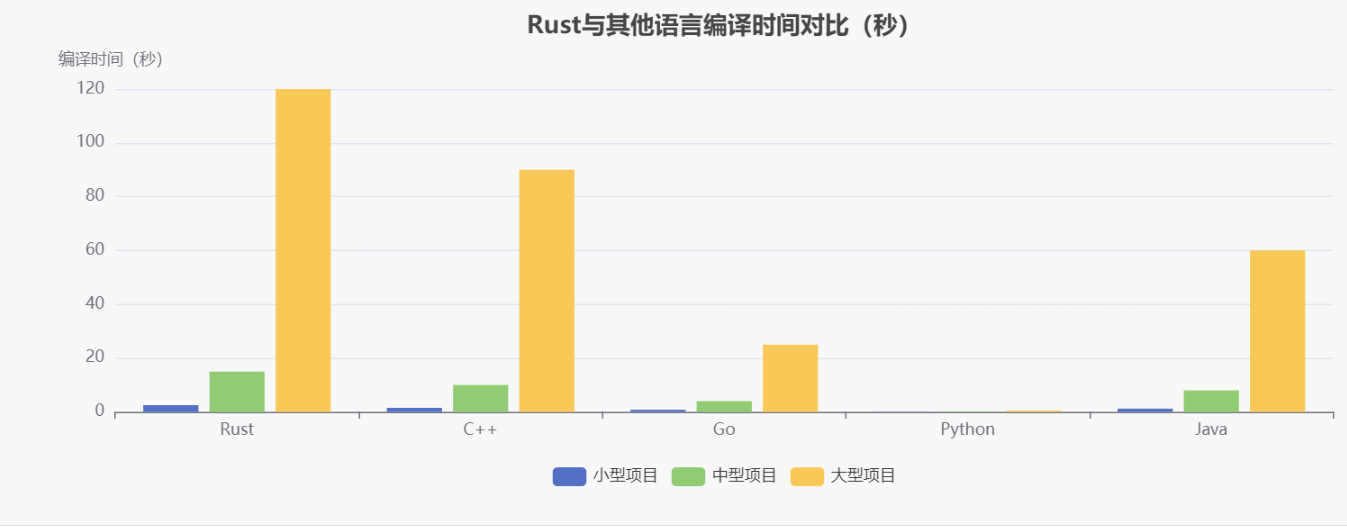
在使用Rust的过程中,开发者常常会遇到一些与所有权、生命周期和模式匹配相关的问题。下面列出了一些常见的陷阱和相应的最佳实践。Rust与其他语言编译时间对比如下:
6.1 所有权问题
6.1.1 移动后使用
最常见的错误是在变量的所有权被移动后仍然尝试使用该变量。
错误示例复制
fn main() {let s1 = String::from("hello");let s2 = s1; // s1 的所有权被移动到 s2println!("{}", s1); // 错误:s1 不再有效
}解决方案:如果需要在移动后继续使用原变量,可以使用clone方法创建深拷贝,或者使用借用(引用)而不是移动。
6.1.2 返回局部变量的引用
另一个常见错误是尝试返回对局部变量的引用,这会导致悬垂引用。
错误示例复制
fn get_str() -> &str {let s = String::from("hello");&s // 错误:返回对局部变量的引用
} // s 在这里被释放,返回的引用将无效解决方案:返回拥有所有权的值而不是引用,或者确保引用指向的内存仍然有效。
正确示例复制
fn get_str() -> String {let s = String::from("hello");s // 返回拥有所有权的字符串
}6.2 生命周期问题
6.2.1 生命周期不匹配
当函数参数和返回值的生命周期不匹配时,会导致编译错误。
错误示例复制
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &'a str {// 错误:返回的引用可能指向 y,但生命周期注解指定它指向 'aif x.len() > y.len() {x} else {y // 这里的生命周期不匹配}
}解决方案:确保所有可能的返回路径都与返回值的生命周期注解兼容。
正确示例复制
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {if x.len() > y.len() {x} else {y // 现在 x 和 y 都有相同的生命周期 'a}
}6.3 模式匹配问题
6.3.1 模式未穷尽
Rust要求match语句必须穷尽所有可能的情况,否则会导致编译错误。
错误示例复制
enum Color {Red,Green,Blue,
}fn print_color(color: Color) {match color {Color::Red => println!("红色"),Color::Green => println!("绿色"),// 错误:缺少 Color::Blue 的处理}
}解决方案:确保覆盖所有可能的情况,或者使用通配符_来处理未明确列出的情况。
正确示例复制
fn print_color(color: Color) {match color {Color::Red => println!("红色"),Color::Green => println!("绿色"),Color::Blue => println!("蓝色"),}
}// 或者使用通配符
fn print_color_simple(color: Color) {match color {Color::Red => println!("红色"),_ => println!("非红色"), // 处理 Green 和 Blue}
}6.4 最佳实践
6.4.1 所有权最佳实践
- 优先使用借用(引用)而不是移动,以提高代码的灵活性。
- 仅在必要时使用
clone,因为它可能带来性能开销。 - 考虑使用
Cow<str>等智能指针类型,它们可以在需要时自动进行克隆。 - 理解
Copy和Clone特征的区别,对于简单类型(如整数、浮点数),Rust默认实现了Copy特征,它们的赋值是复制而不是移动。
6.4.2 生命周期最佳实践
- 利用生命周期省略规则简化代码,避免不必要的注解。
- 在结构体中持有引用时,明确指定生命周期约束。
- 对于复杂的生命周期问题,考虑使用智能指针(如
Rc、Arc)来共享所有权。 - 避免返回对函数内部创建的临时值的引用。
6.4.3 模式匹配最佳实践
- 使用
if let和while let来简化单一模式的匹配。 - 在函数参数和
let语句中使用模式解构,提高代码的可读性。 - 利用守卫条件(guard clauses)为模式添加额外的条件。
- 使用
@绑定来同时进行模式匹配和解构。
七、结语
通过本文的深入探讨,我们了解了Rust语言的三个核心特性:所有权系统、生命周期和模式匹配。这些特性是Rust能够在编译时保证内存安全和并发安全的关键所在,同时又不牺牲性能。
所有权系统通过严格的规则管理内存,避免了悬垂指针、双重释放等常见的内存错误。生命周期注解则帮助编译器确保引用总是有效的,防止了悬垂引用的问题。模式匹配则提供了一种强大而灵活的方式来处理不同的数据结构和情况。
虽然这些概念在刚开始学习时可能会感到有些复杂和限制,但一旦掌握,它们将成为你编写安全、高效代码的强大工具。Rust的设计哲学是"所有权优先",它要求开发者在编译时就思考清楚资源的管理方式,而不是依赖运行时的垃圾回收。这种设计虽然在初期可能会增加一些学习成本,但长期来看,它能够帮助开发者编写出更加健壮、安全的代码。
随着Rust生态系统的不断发展和完善,越来越多的项目开始采用Rust进行开发,特别是在系统编程、WebAssembly、网络服务等领域。掌握Rust的核心特性,将为你的职业发展开辟新的可能性。
最后,学习Rust是一个持续的过程,建议通过实践项目来加深对这些概念的理解。尝试将Rust应用到实际的开发中,解决真实的问题,这样才能真正掌握这门强大的语言。
八、参考资料
- Rust官方网站
- Rust程序设计语言(中文版)
- Rust语言参考手册
- Rust Nomicon(深入理解Rust内存安全)
- Rust By Example
- Clippy:Rust代码质量工具
- crates.io:Rust包管理网站
- Tokio异步运行时教程
- Actix-web框架文档
- Rust源码仓库
如果这篇文章对你有帮助,请点赞,收藏,加关注支持!
👍 喜欢 ⭐ 收藏 🔗 分享