【python】基于 生活方式与健康数据预测数据集(Lifestyle and Health Risk Prediction)的可视化练习,附数据集源文件。
一、数据集概述
- 1、基本定位:模拟真实世界个人生活方式与健康数据的合成数据集,旨在帮助数据科学家、机器学习- -工程师及学生安全构建和测试健康风险预测模型,无需使用敏感医疗数据。
- 2、核心规模:
行数:5000 行(可调整,支持扩展生成更多数据)
列数:12 列(含 11 个特征列 + 1 个目标变量列) - 3、数据属性:
数据类型:混合类型,包含数值型(如年龄、体重)和分类型(如运动频率、吸烟习惯)
生成工具:通过 Python 库(NumPy、Faker)完全合成 - 4、授权与作者信息:
许可证:CC0 公共领域许可证,可自由用于研究、学习或商业项目
源地址:https://www.kaggle.com/datasets/miadul/lifestyle-and-health-risk-prediction
作者:Arif Miah(身份:机器学习工程师、Kaggle 专家、数据科学家,
邮箱:arifmiahcse@gmail.com)
文件下载:链接:https://pan.quark.cn/s/9b0b1e71337e
通过网盘分享的文件:生活方式与健康
链接: https://pan.baidu.com/s/1V3iIU2y8s_MqOwV8fsK9Dg?pwd=17yp 提取码: 17yp
# 一、数据概况
# 数值型特征的描述性统计(保留两位小数)
print('数值型特征的描述性统计:')
print(df[['age', 'weight', 'height','sleep', 'bmi']].describe().round(2))# 分类型特征的描述性统计
for col in ['exercise','sugar_intake','smoking', 'alcohol','married', 'profession', 'health_risk']:print(f'\n{col}的类别分布:')print(df[col].value_counts())
1. 数值型特征
| 特征 | 计数 | 均值 | 标准差 | 最小值 | 25%分位数 | 50%分位数 | 75%分位数 | 最大值 |
|---|---|---|---|---|---|---|---|---|
| age | 5000.00 | 48.81 | 17.91 | 18.00 | 34.00 | 49.00 | 64.00 | 79.00 |
| weight | 5000.00 | 77.36 | 18.71 | 45.00 | 61.00 | 77.00 | 94.00 | 109.00 |
| height | 5000.00 | 171.93 | 15.82 | 145.00 | 158.00 | 171.50 | 186.00 | 199.00 |
| sleep | 5000.00 | 7.00 | 1.43 | 3.00 | 6.00 | 7.00 | 8.00 | 10.00 |
| bmi | 5000.00 | 26.84 | 8.25 | 11.40 | 20.30 | 26.00 | 32.40 | 51.40 |
从数值型特征的描述性统计来看:
- 年龄(
age)分布在 18 到 79 岁之间,平均年龄接近 49 岁,标准差 17.91 说明年龄分布有一定的离散程度。 - 体重(
weight)范围从 45 公斤到 109 公斤,均值为 77.36 公斤。 - 身高(
height)在 145 厘米到 199 厘米之间,平均身高约为 171.93 厘米。 - 睡眠时间(
sleep)平均为 7 小时,标准差 1.43 表明大部分人的睡眠时间相对集中在均值附近。 - 身体质量指数(
bmi)的均值为 26.84,不同个体之间的 BMI 差异较大,标准差为 8.25。
2. 分类型特征
- 运动频率(
exercise):‘medium’(中等)频率的人数最多,有 1985 人,其次是 ‘low’(低)、‘high’(高)和 ‘none’(无)。 - 糖摄入水平(
sugar_intake):‘medium’(中等)摄入水平的人数最多,为 2511 人,‘low’(低)和 ‘high’(高)依次减少。 - 吸烟习惯(
smoking):不吸烟(‘no’)的人数占比较大,有 4023 人,吸烟(‘yes’)的有 977 人。 - 饮酒习惯(
alcohol):不饮酒(‘no’)的人数为 3741 人,饮酒(‘yes’)的有 1259 人。 - 婚姻状况(
married):已婚(‘yes’)的人数为 3018 人,未婚(‘no’)的有 1982 人。 - 职业(
profession):各个职业的人数分布相对较为均匀,学生(‘student’)、农民(‘farmer’)、司机(‘driver’)等职业人数都在 600 - 644 人之间。 - 健康风险(
health_risk):高风险(‘high’)的人数较多,有 3490 人,低风险(‘low’)的有 1510 人。
二、特征相关性分析
1. 与健康风险高相关性较高的前 10 个特征
# 二、特征相关性分析
import matplotlib.pyplot as plt
import seaborn as sns
# 将分类型变量进行编码
df_encoded = pd.get_dummies(df, columns=['exercise','sugar_intake','smoking', 'alcohol','married', 'profession', 'health_risk'])
# 计算相关系数矩阵(保留两位小数)
correlation_matrix = df_encoded.corr().round(2)
# 查看与health_risk_high相关性较高的前10个特征
top_10_features = correlation_matrix['health_risk_high'].sort_values(ascending=False)[1:11]
print(top_10_features)
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei']
# 显示负号
plt.rcParams['axes.unicode_minus'] = False
# 绘制热力图
plt.figure(figsize=(12, 8))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm')
plt.title('特征相关性热力图')
plt.show()
| 特征 | 与 health_risk_high 的相关性系数 |
|---|---|
| age | 0.38 |
| bmi | 0.36 |
| weight | 0.33 |
| smoking_yes | 0.25 |
| alcohol_yes | 0.18 |
| exercise_low | 0.18 |
| sugar_intake_high | 0.16 |
| exercise_none | 0.12 |
| married_no | 0.02 |
| profession_driver | 0.02 |
年龄(age)、身体质量指数(bmi)和体重(weight)与高健康风险的相关性较强。这可能意味着随着年龄的增长、身体质量指数和体重的增加,健康风险升高的可能性更大。
吸烟(smoking_yes)和饮酒(alcohol_yes)的习惯也与高健康风险有一定的相关性,说明不良的生活习惯会增加健康风险。
运动频率低(exercise_low)和不运动(exercise_none)同样与高健康风险相关,强调了运动对健康的重要性。
而婚姻状况为未婚(married_no)和职业为司机(profession_driver)与高健康风险的相关性较弱。
2. 特征相关性热力图
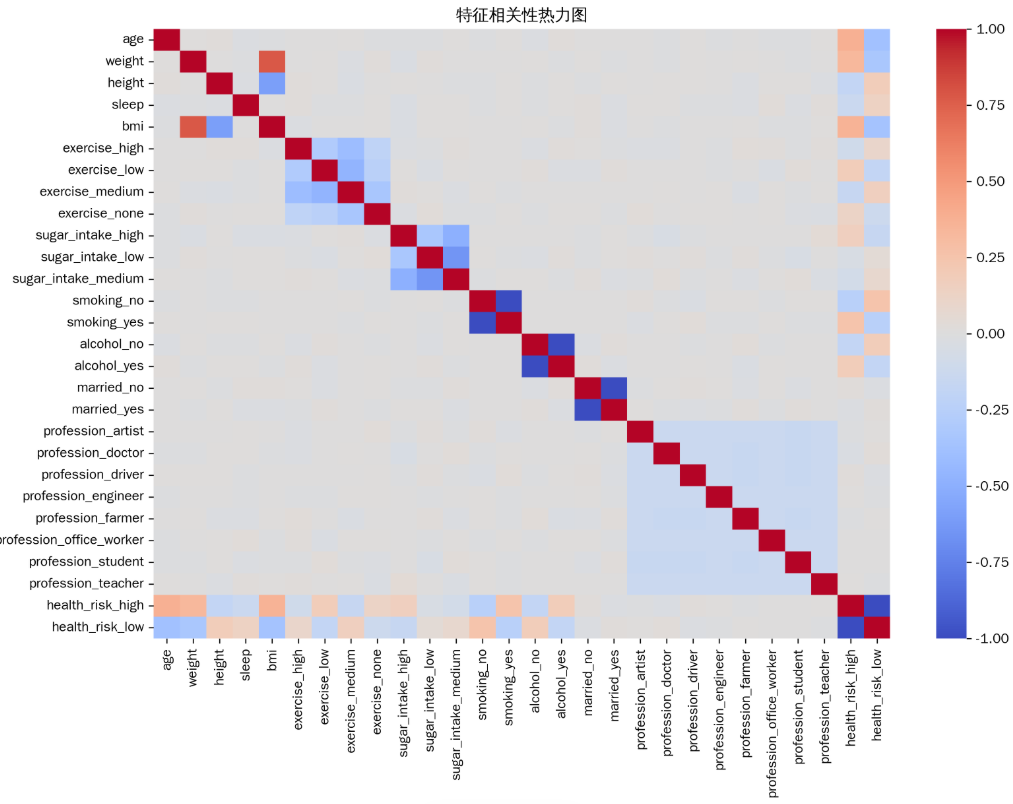
热力图可以直观地展示所有特征之间的相关性。颜色越接近暖色(如红色)表示正相关性越强,越接近冷色(如蓝色)表示负相关性越强。
三、不同类别特征下健康风险分布
# 三、不同类别特征下健康风险分布
# 定义分类特征列表
categorical_features = ['exercise','sugar_intake','smoking', 'alcohol','married', 'profession']# 绘制不同类别特征下健康风险分布条形图
for feature in categorical_features:cross_tab = pd.crosstab(df[feature], df['health_risk'])cross_tab.plot(kind='bar')plt.title(f'{feature} 与健康风险分布')plt.xlabel(feature)plt.xticks(rotation=45)plt.ylabel('数量')plt.show()
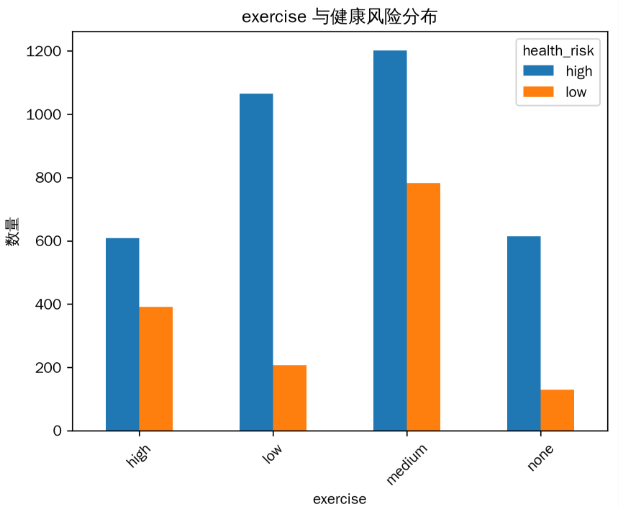
1. 运动频率(exercise)与健康风险分布
从图中可以推测,运动频率为 ‘none’(无)和 ‘low’(低)的人群中,健康风险为 ‘high’(高)的比例相对较高,而运动频率为 ‘high’(高)的人群中健康风险为 ‘low’(低)的比例相对较高。这表明增加运动频率可能有助于降低健康风险。
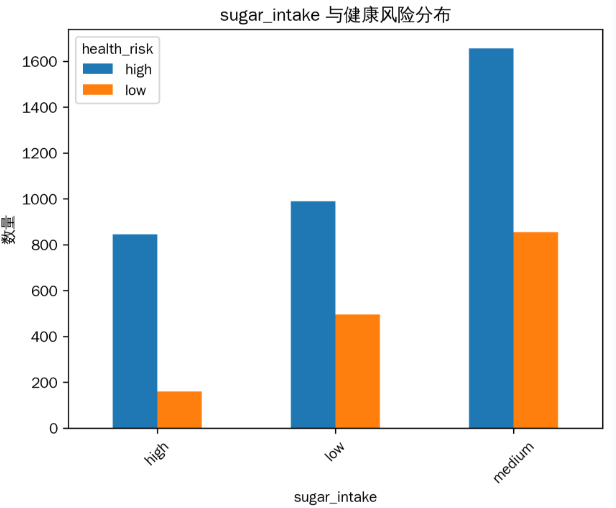
2. 糖摄入水平(sugar_intake)与健康风险分布
当糖摄入水平为 ‘high’(高)时,健康风险为 ‘high’(高)的人数较多,而糖摄入水平为 ‘low’(低)时,健康风险为 ‘low’(低)的人数相对较多。这暗示了控制糖的摄入量可能对健康有益。
3. 吸烟习惯(smoking)与健康风险分布
吸烟(‘yes’)的人群中健康风险为 ‘high’(高)的比例明显高于不吸烟(‘no’)的人群,推测吸烟对健康可能有不良影响。
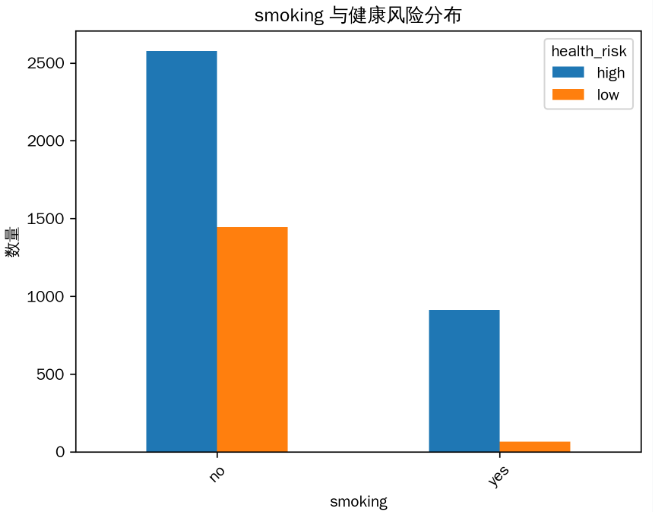
4. 饮酒习惯(alcohol)与健康风险分布
饮酒(‘yes’)的人群健康风险为 ‘high’(高)的比例相对不饮酒(‘no’)的人群要高,说明饮酒可能增加健康风险。
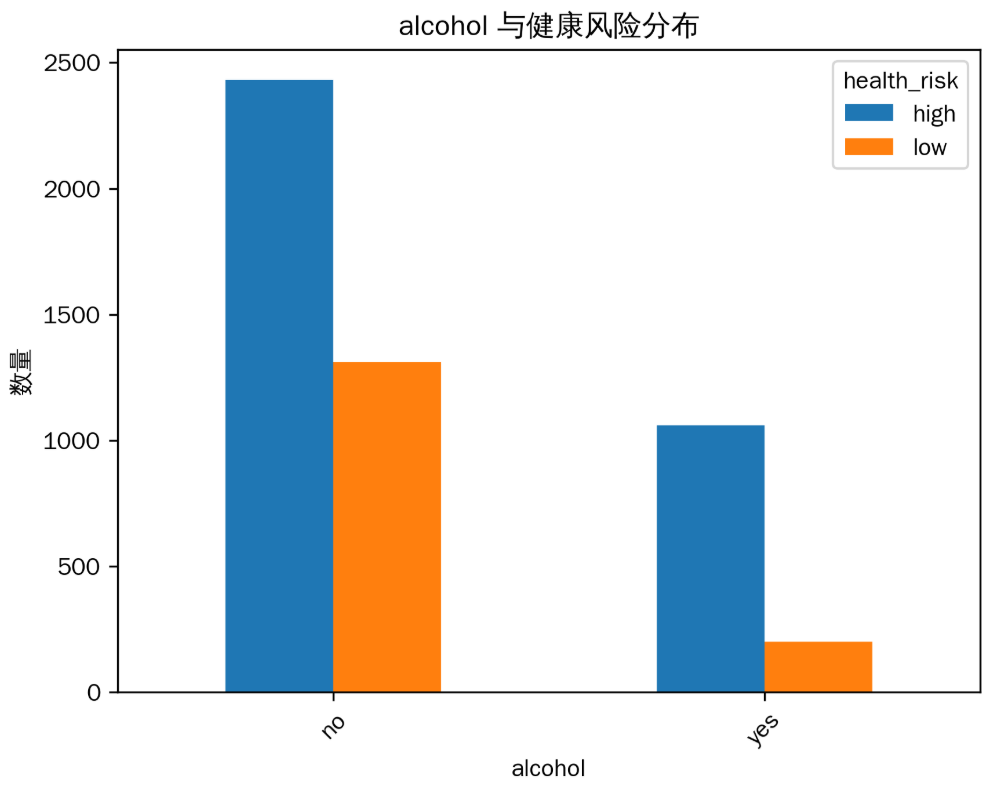
5. 婚姻状况(married)与健康风险分布
已婚(‘yes’)和未婚(‘no’)人群的健康风险分布有一定差异,已婚人群中健康风险为 ‘low’(低)的比例相对较高,推测婚姻生活可能对健康有积极影响。
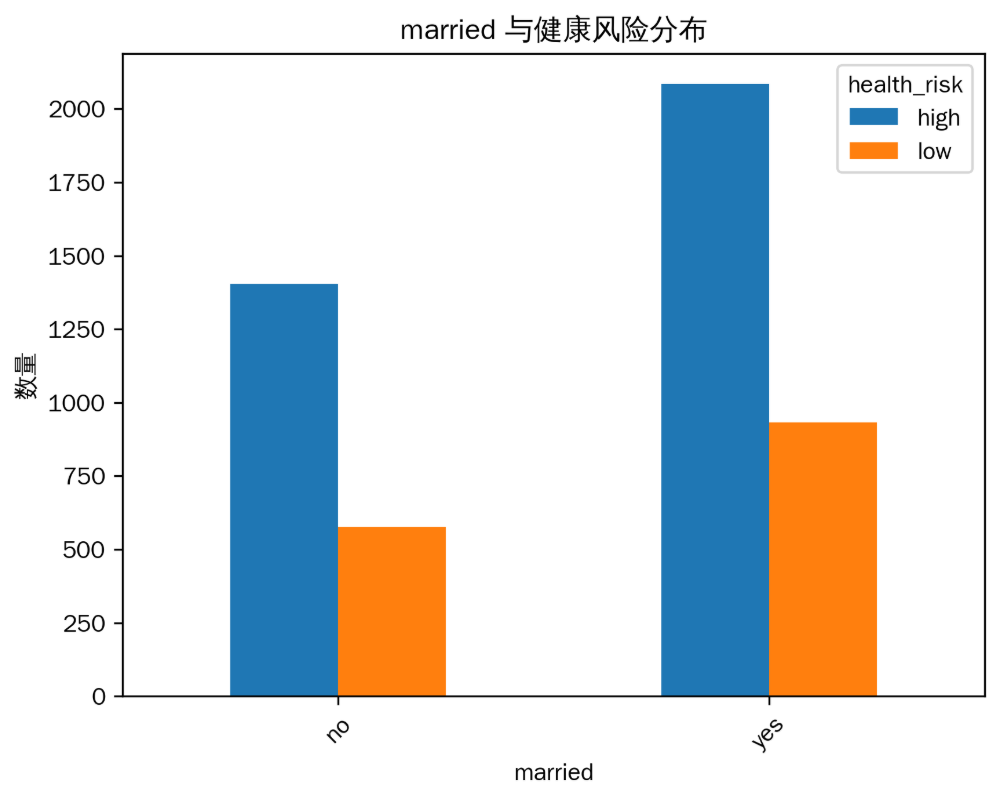
6. 职业(profession)与健康风险分布
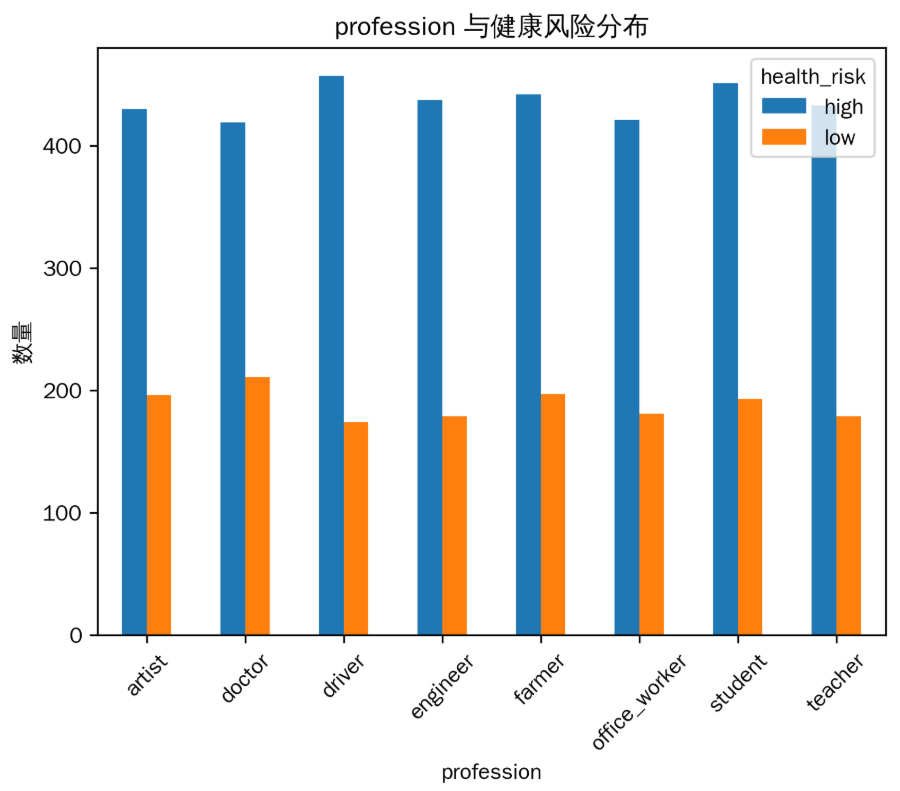
不同职业的健康风险分布有所不同,例如某些职业(如 ‘driver’ 司机)健康风险为 ‘high’(高)的比例相对较高,这可能与职业的工作环境、工作压力等因素有关。
免责声明
-
数据性质说明:本数据集为通过Python(NumPy、Faker)完全合成的模拟数据,仅包含年龄、体重、运动频率等生活方式相关特征及基于启发式规则生成的“健康风险”标签,不涉及任何真实个人的医疗记录、隐私信息或临床诊断数据,无法替代专业医疗数据的准确性与完整性。
-
用途限制:数据集仅用于数据科学学习、机器学习模型训练、数据预处理实践等非医疗场景,不得用于实际医疗诊断、健康风险评估、疾病预测等涉及人身健康决策的用途,亦不得作为医疗建议、健康干预方案制定的依据。
-
结果局限性:基于本数据集训练的模型或得出的分析结论(如特征与健康风险的关联),仅反映模拟数据中的统计规律,不代表真实世界中生活方式与健康状况的必然因果关系,其预测结果或分析结论不具备医学参考价值。
-
专业建议指引:若有健康评估、疾病诊断、医疗咨询等需求,应及时咨询具备合法资质的医疗机构或专业医护人员,以获取科学、准确的医疗服务,切勿依赖本数据集及相关分析结果做出健康决策。