【完整源码+数据集+部署教程】【零售和消费品&存货】快递包裹条形码与二维码识别系统源码&数据集全套:改进yolo11-RFCBAMConv
背景意义
随着电子商务的迅猛发展,快递行业的业务量不断攀升,包裹的管理与追踪成为了行业内亟待解决的重要问题。条形码和二维码作为信息存储与传递的有效工具,广泛应用于快递包裹的标识与追踪中。传统的条形码与二维码识别方法在复杂环境下的准确性和实时性往往难以满足现代快递物流的需求。因此,开发一种高效、准确的快递包裹条形码与二维码识别系统显得尤为重要。
本研究基于改进的YOLOv11模型,旨在构建一个高效的快递包裹条形码与二维码识别系统。YOLO(You Only Look Once)系列模型以其快速的检测速度和较高的准确率在目标检测领域取得了显著成效。通过对YOLOv11进行改进,结合特定的快递包裹数据集,能够更好地适应快递行业的实际应用场景。该数据集包含1400张图像,专注于条形码和二维码的检测,提供了丰富的样本数据,能够有效支持模型的训练与验证。
在实际应用中,快递包裹的条形码和二维码常常受到环境光照、角度、遮挡等因素的影响,导致识别准确率下降。通过改进YOLOv11模型,增强其对不同环境条件的适应能力,将显著提升识别系统的稳定性与可靠性。此外,系统的实时性将为快递企业提供更高效的包裹处理能力,降低人工成本,提高物流效率。
综上所述,基于改进YOLOv11的快递包裹条形码与二维码识别系统的研究,不仅具有重要的理论意义,也为快递行业的智能化发展提供了实践基础,推动了物流信息化的进程。
图片效果
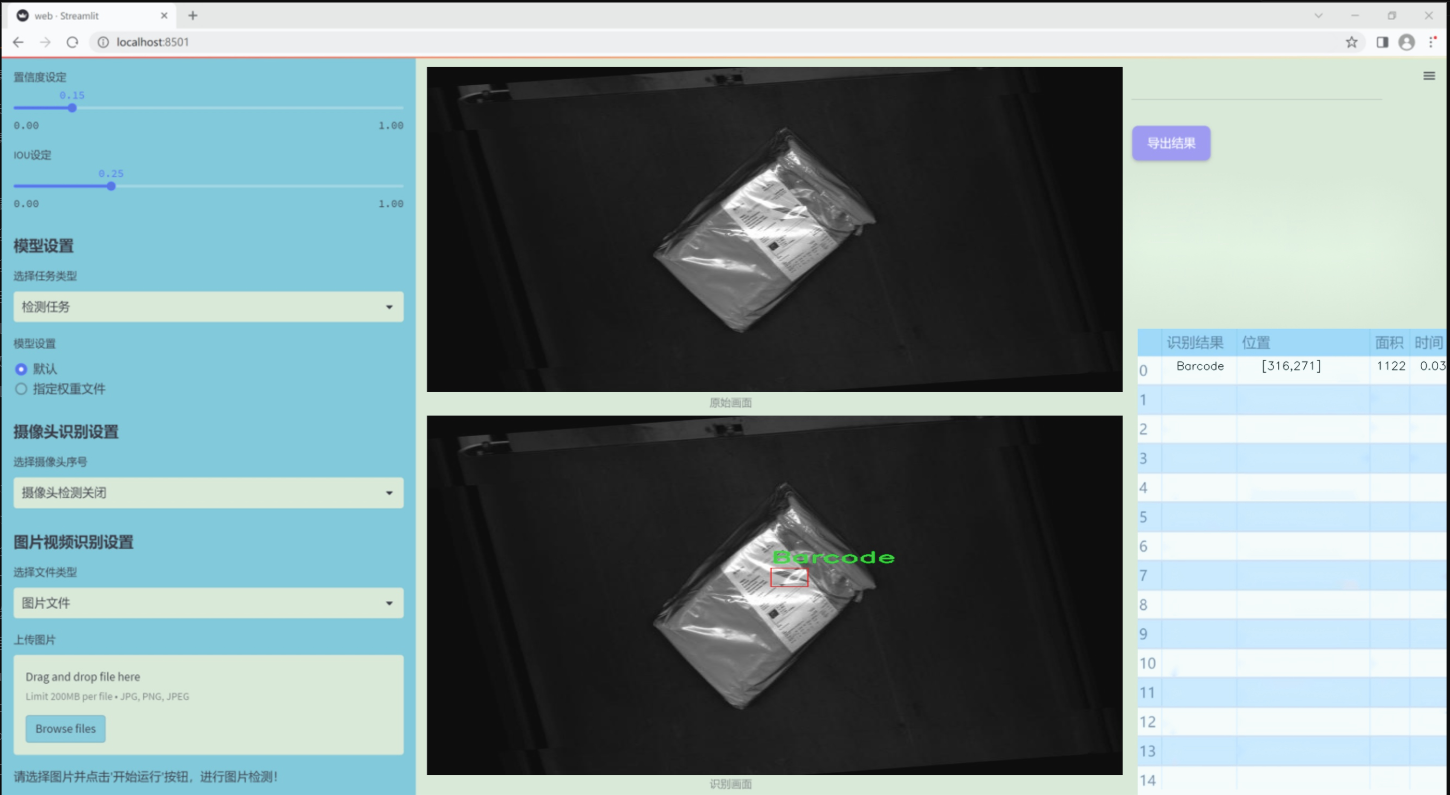
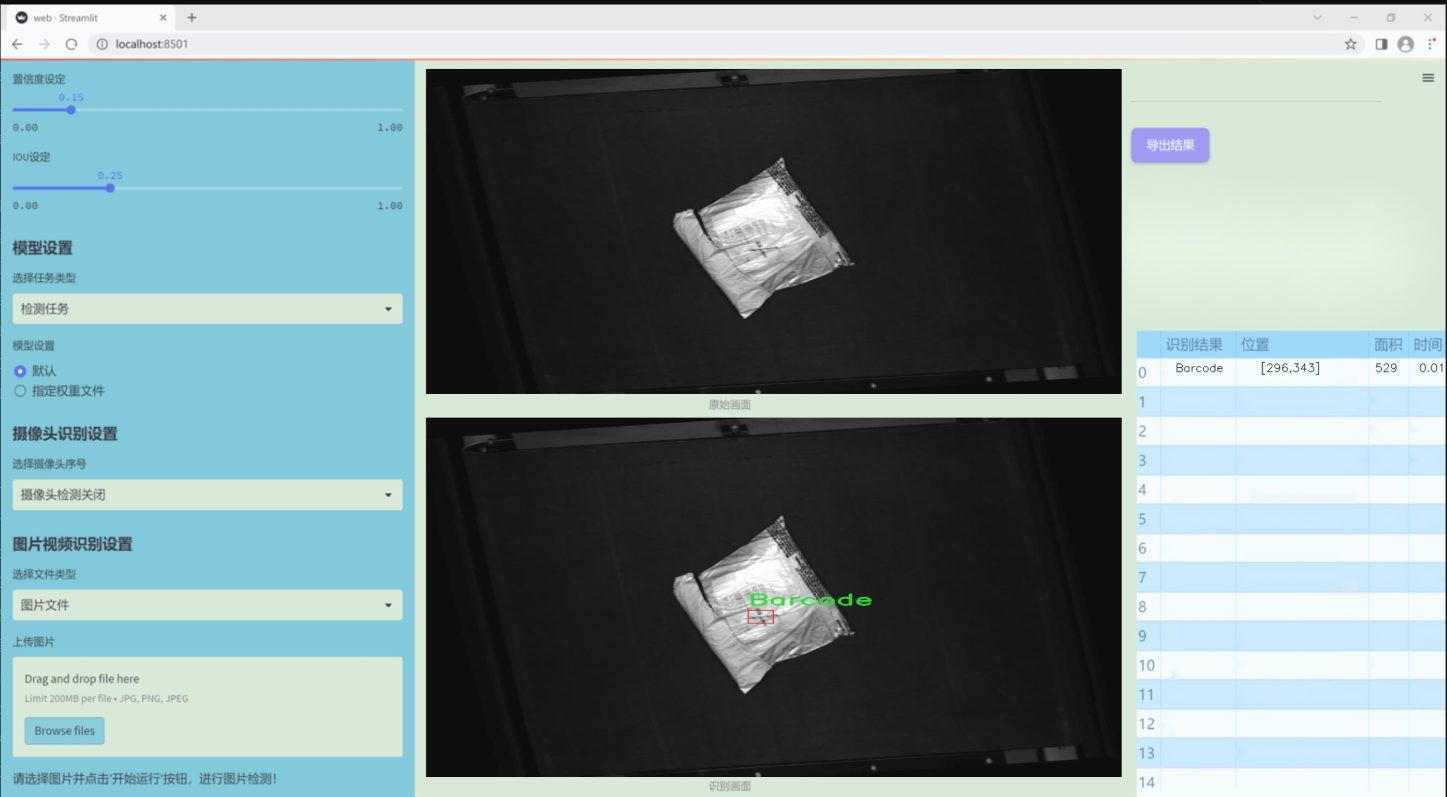
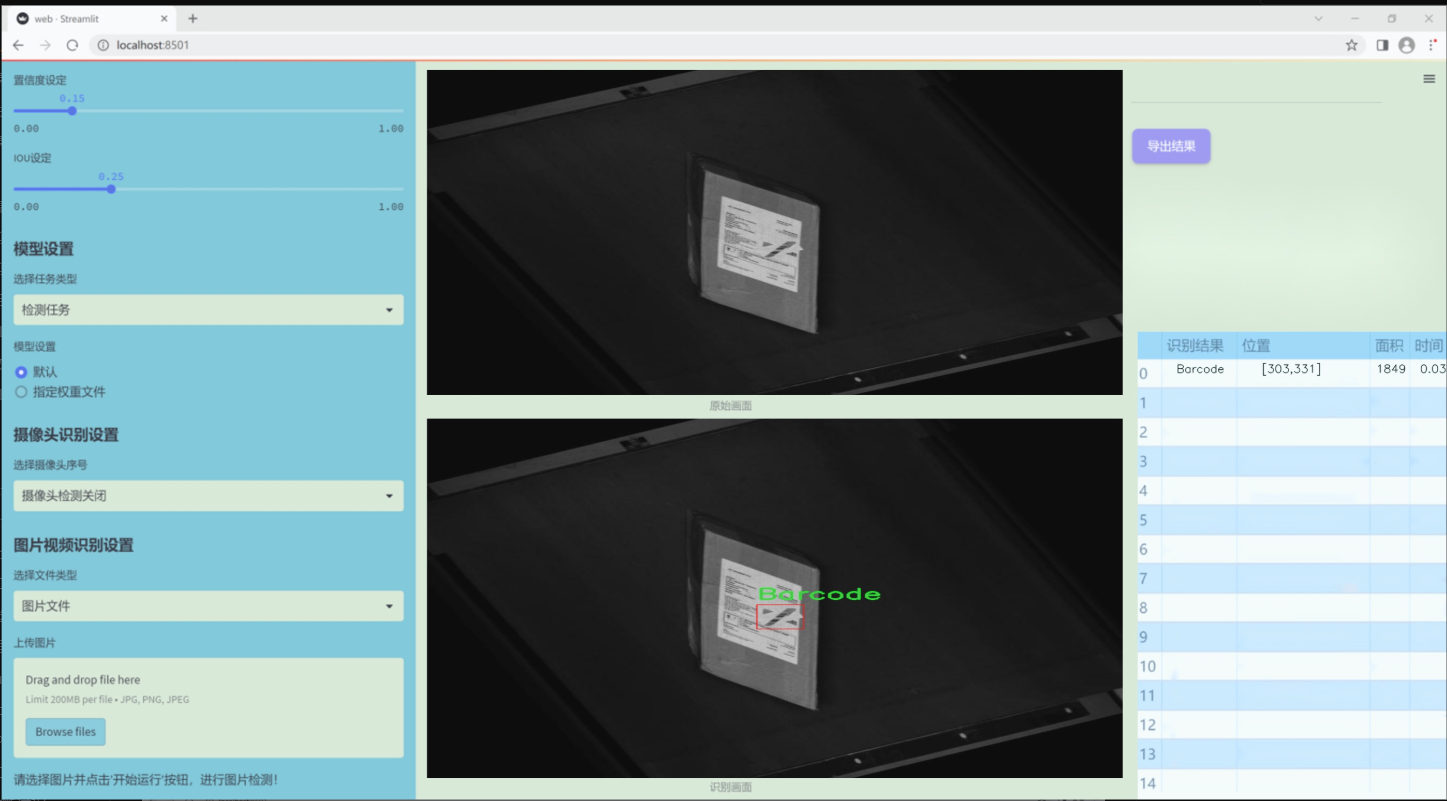
数据集信息
本项目所使用的数据集名为“qqr4j”,旨在为改进YOLOv11的快递包裹条形码与二维码识别系统提供高质量的训练数据。该数据集专注于两个主要类别的识别任务,分别是“Barcode”(条形码)和“qrcode”(二维码),总类别数量为2。这一设计使得数据集能够涵盖快递包裹中常见的标识符,进而提高系统在实际应用中的识别准确性和效率。
“qqr4j”数据集的构建过程经过精心设计,确保了数据的多样性和代表性。数据集中包含了来自不同快递公司和不同包裹类型的条形码与二维码样本,涵盖了各种尺寸、颜色和背景条件。这种多样性不仅能够帮助模型学习到更为广泛的特征,还能提高其在复杂环境下的鲁棒性。此外,数据集中的每个样本都经过标注,确保了训练过程中模型能够准确识别并区分这两种类别。
在数据集的准备过程中,研究团队还特别关注了样本的质量和清晰度,以确保每个条形码和二维码的可读性。这对于训练深度学习模型至关重要,因为高质量的输入数据直接影响到模型的学习效果和最终的识别性能。通过使用“qqr4j”数据集,研究人员期望能够显著提升YOLOv11在快递包裹条形码与二维码识别任务中的表现,使其在实际应用中能够快速、准确地处理各种快递信息,从而优化物流管理和提高工作效率。





核心代码
以下是代码中最核心的部分,并添加了详细的中文注释:
import math
import torch
from torch import nn
from einops.layers.torch import Rearrange
定义一个卷积层类 Conv2d_cd
class Conv2d_cd(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=1,
padding=1, dilation=1, groups=1, bias=False, theta=1.0):
super(Conv2d_cd, self).init()
# 初始化标准卷积层
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.theta = theta # theta参数
def get_weight(self):# 获取卷积层的权重conv_weight = self.conv.weightconv_shape = conv_weight.shape # 获取权重的形状# 重排权重形状conv_weight = Rearrange('c_in c_out k1 k2 -> c_in c_out (k1 k2)')(conv_weight)# 创建一个新的权重张量conv_weight_cd = torch.zeros(conv_shape[0], conv_shape[1], 3 * 3, device=conv_weight.device)conv_weight_cd[:, :, :] = conv_weight[:, :, :] # 复制权重conv_weight_cd[:, :, 4] = conv_weight[:, :, 4] - conv_weight[:, :, :].sum(2) # 调整权重# 重排回原来的形状conv_weight_cd = Rearrange('c_in c_out (k1 k2) -> c_in c_out k1 k2', k1=conv_shape[2], k2=conv_shape[3])(conv_weight_cd)return conv_weight_cd, self.conv.bias # 返回调整后的权重和偏置
定义一个卷积层类 Conv2d_rd
class Conv2d_rd(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=1,
padding=2, dilation=1, groups=1, bias=False, theta=1.0):
super(Conv2d_rd, self).init()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.theta = theta
def forward(self, x):# 前向传播if math.fabs(self.theta - 0.0) < 1e-8:out_normal = self.conv(x) # 如果theta接近0,使用标准卷积return out_normal else:conv_weight = self.conv.weightconv_shape = conv_weight.shape# 创建一个新的权重张量conv_weight_rd = torch.zeros(conv_shape[0], conv_shape[1], 5 * 5, device=conv_weight.device)conv_weight = Rearrange('c_in c_out k1 k2 -> c_in c_out (k1 k2)')(conv_weight)# 调整权重conv_weight_rd[:, :, [0, 2, 4, 10, 14, 20, 22, 24]] = conv_weight[:, :, 1:]conv_weight_rd[:, :, [6, 7, 8, 11, 13, 16, 17, 18]] = -conv_weight[:, :, 1:] * self.thetaconv_weight_rd[:, :, 12] = conv_weight[:, :, 0] * (1 - self.theta)conv_weight_rd = conv_weight_rd.view(conv_shape[0], conv_shape[1], 5, 5) # 重塑形状out_diff = nn.functional.conv2d(input=x, weight=conv_weight_rd, bias=self.conv.bias, stride=self.conv.stride, padding=self.conv.padding, groups=self.conv.groups)return out_diff # 返回卷积结果
定义一个解卷积网络类 DEConv
class DEConv(nn.Module):
def init(self, dim):
super(DEConv, self).init()
# 初始化多个卷积层
self.conv1_1 = Conv2d_cd(dim, dim, 3, bias=True)
self.conv1_2 = Conv2d_cd(dim, dim, 3, bias=True) # 使用 Conv2d_cd 作为示例
self.conv1_3 = Conv2d_cd(dim, dim, 3, bias=True)
self.conv1_4 = Conv2d_cd(dim, dim, 3, bias=True)
self.conv1_5 = nn.Conv2d(dim, dim, 3, padding=1, bias=True)
self.bn = nn.BatchNorm2d(dim) # 批归一化层self.act = nn.ReLU() # 激活函数def forward(self, x):# 前向传播w1, b1 = self.conv1_1.get_weight()w2, b2 = self.conv1_2.get_weight()w3, b3 = self.conv1_3.get_weight()w4, b4 = self.conv1_4.get_weight()w5, b5 = self.conv1_5.weight, self.conv1_5.bias# 合并所有卷积层的权重和偏置w = w1 + w2 + w3 + w4 + w5b = b1 + b2 + b3 + b4 + b5res = nn.functional.conv2d(input=x, weight=w, bias=b, stride=1, padding=1, groups=1) # 进行卷积操作res = self.bn(res) # 批归一化return self.act(res) # 返回激活后的结果def switch_to_deploy(self):# 切换到部署模式,合并权重和偏置w1, b1 = self.conv1_1.get_weight()w2, b2 = self.conv1_2.get_weight()w3, b3 = self.conv1_3.get_weight()w4, b4 = self.conv1_4.get_weight()w5, b5 = self.conv1_5.weight, self.conv1_5.biasself.conv1_5.weight = torch.nn.Parameter(w1 + w2 + w3 + w4 + w5)self.conv1_5.bias = torch.nn.Parameter(b1 + b2 + b3 + b4 + b5)# 删除不再需要的卷积层del self.conv1_1del self.conv1_2del self.conv1_3del self.conv1_4
代码说明:
卷积层类:Conv2d_cd 和 Conv2d_rd 类分别定义了自定义的卷积层,提供了获取权重的方法,并在前向传播中实现了特定的卷积操作。
解卷积网络类:DEConv 类是一个组合多个卷积层的网络结构,在前向传播中将各个卷积层的权重和偏置合并,进行一次卷积操作。
切换到部署模式:switch_to_deploy 方法用于在模型部署时合并所有卷积层的权重和偏置,以减少计算开销。
这个程序文件 deconv.py 定义了一系列卷积神经网络模块,主要用于实现不同类型的卷积操作,特别是针对深度学习中的反卷积(Deconvolution)和卷积层的改进。以下是对代码的详细讲解。
首先,程序导入了必要的库,包括 math、torch 和 torch.nn,以及一些特定的模块,如 Rearrange 和 Conv。这些库和模块提供了构建和操作神经网络所需的基本功能。
接下来,定义了多个卷积类,分别是 Conv2d_cd、Conv2d_ad、Conv2d_rd、Conv2d_hd 和 Conv2d_vd。每个类都继承自 nn.Module,并在初始化时创建了一个标准的 2D 卷积层 nn.Conv2d。这些类的主要功能是根据不同的需求对卷积权重进行调整。
Conv2d_cd 类的 get_weight 方法通过重排权重并进行调整,返回一个新的卷积权重和偏置。
Conv2d_ad 类同样实现了 get_weight 方法,但其权重调整方式与 Conv2d_cd 不同,使用了一个参数 theta 来影响权重的计算。
Conv2d_rd 类在 forward 方法中实现了自定义的前向传播逻辑,允许根据 theta 的值选择不同的卷积计算方式。
Conv2d_hd 和 Conv2d_vd 类则专注于一维卷积的实现,并提供了相应的权重获取方法。
然后,定义了一个名为 DEConv 的类,它整合了之前定义的多个卷积层。这个类的构造函数中创建了多个卷积层,并定义了批归一化和激活函数。forward 方法中,通过调用各个卷积层的 get_weight 方法获取权重和偏置,并将它们相加,最后通过 nn.functional.conv2d 进行卷积操作。这个过程确保了多个卷积层的输出能够合并在一起,形成最终的输出。
switch_to_deploy 方法用于在模型部署时优化性能。它将所有卷积层的权重和偏置合并到最后一个卷积层中,从而减少计算开销和内存占用。此方法还删除了不再需要的卷积层,进一步简化模型结构。
最后,在 main 部分,程序创建了一个随机输入数据,并实例化了 DEConv 模型。通过调用模型的 forward 方法,获取输出,并在调用 switch_to_deploy 方法后再次获取输出,最后比较两个输出是否相等,确保模型在优化后仍然保持相同的功能。
整体来看,这个程序文件实现了一个灵活且可扩展的卷积模块,适用于深度学习中的多种应用场景,特别是在需要对卷积操作进行细致控制和优化时。
10.3 predict.py
以下是经过简化和注释的核心代码部分:
导入必要的模块
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
“”"
DetectionPredictor类用于基于检测模型进行预测。
该类继承自BasePredictor类。
“”"
def postprocess(self, preds, img, orig_imgs):"""对预测结果进行后处理,并返回Results对象的列表。参数:preds: 模型的预测结果img: 输入图像orig_imgs: 原始图像(可能是torch.Tensor或numpy数组)返回:results: 包含后处理结果的Results对象列表"""# 应用非极大值抑制(NMS)来过滤重叠的检测框preds = ops.non_max_suppression(preds,self.args.conf, # 置信度阈值self.args.iou, # IOU阈值agnostic=self.args.agnostic_nms, # 是否使用类别无关的NMSmax_det=self.args.max_det, # 最大检测框数量classes=self.args.classes, # 需要检测的类别)# 如果输入的原始图像不是列表,则将其转换为numpy数组if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = [] # 存储后处理结果的列表for i, pred in enumerate(preds):orig_img = orig_imgs[i] # 获取对应的原始图像# 将预测框的坐标从缩放后的图像尺寸转换为原始图像尺寸pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i] # 获取图像路径# 创建Results对象并添加到结果列表中results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results # 返回后处理结果
代码注释说明:
导入模块:导入必要的类和函数,以便进行模型预测和结果处理。
DetectionPredictor类:这是一个专门用于目标检测的预测器类,继承自基本预测器类。
postprocess方法:该方法用于对模型的预测结果进行后处理,包括应用非极大值抑制(NMS)和坐标转换,最终返回处理后的结果列表。
非极大值抑制:用于过滤掉重叠的检测框,只保留置信度高的框。
坐标转换:将预测框的坐标从模型输入图像的尺寸转换为原始图像的尺寸,以便于后续的可视化或分析。
Results对象:用于存储每个图像的预测结果,包括原始图像、图像路径、类别名称和检测框信息。
这个程序文件 predict.py 是一个用于目标检测的预测模块,基于 Ultralytics YOLO(You Only Look Once)模型。文件中定义了一个名为 DetectionPredictor 的类,它继承自 BasePredictor 类,专门用于处理基于检测模型的预测任务。
在这个类中,首先提供了一个示例,展示了如何使用 DetectionPredictor 类进行预测。示例中导入了必要的模块,并创建了一个包含模型路径和数据源的参数字典。然后,实例化 DetectionPredictor 对象,并调用 predict_cli() 方法进行预测。
类中定义了一个名为 postprocess 的方法,该方法负责对模型的预测结果进行后处理。具体来说,它接收三个参数:preds(模型的预测结果)、img(输入图像)和 orig_imgs(原始图像)。在方法内部,首先调用 ops.non_max_suppression 函数对预测结果进行非极大值抑制,以减少冗余的检测框。这个过程使用了一些参数,如置信度阈值、IoU(Intersection over Union)阈值、是否进行类别无关的非极大值抑制、最大检测框数量以及需要检测的类别。
接下来,方法检查 orig_imgs 是否为列表,如果不是,则将其转换为 NumPy 数组。然后,创建一个空的 results 列表,用于存储处理后的结果。通过遍历每个预测结果,方法会将预测框的坐标进行缩放,以适应原始图像的尺寸,并将每个结果封装成 Results 对象,包含原始图像、图像路径、模型名称和预测框信息。最后,返回处理后的结果列表。
整体来看,这个文件实现了一个用于目标检测的预测流程,能够有效地处理输入图像并返回经过后处理的检测结果。
10.4 test_selective_scan_speed.py
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn.functional as F
def build_selective_scan_fn(selective_scan_cuda: object = None, mode=“mamba_ssm”):
“”"
构建选择性扫描函数,使用指定的CUDA实现和模式。
“”"
class SelectiveScanFn(torch.autograd.Function):
@staticmethod
def forward(ctx, u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False):
“”"
前向传播函数,计算选择性扫描的输出。
参数:
- u: 输入张量
- delta: 增量张量
- A, B, C: 相关权重张量
- D: 可选的额外张量
- z: 可选的张量
- delta_bias: 可选的增量偏置
- delta_softplus: 是否使用softplus激活
- return_last_state: 是否返回最后的状态
“”"
# 确保输入张量是连续的
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
if z is not None and z.stride(-1) != 1:
z = z.contiguous()
# 进行选择性扫描的前向计算out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, z, delta_bias, delta_softplus)# 保存上下文以供反向传播使用ctx.save_for_backward(u, delta, A, B, C, D, z, delta_bias, x)ctx.delta_softplus = delta_softplusctx.has_z = z is not None# 返回输出或输出和最后状态last_state = x[:, :, -1, 1::2] # 获取最后状态return out if not return_last_state else (out, last_state)@staticmethoddef backward(ctx, dout):"""反向传播函数,计算梯度。参数:- dout: 输出的梯度"""# 从上下文中恢复保存的张量u, delta, A, B, C, D, z, delta_bias, x = ctx.saved_tensors# 进行选择性扫描的反向计算du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(u, delta, A, B, C, D, z, delta_bias, dout, x, ctx.delta_softplus)# 返回各个输入的梯度return (du, ddelta, dA, dB, dC, dD if D is not None else None, None, ddelta_bias if delta_bias is not None else None)def selective_scan_fn(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False):"""包装选择性扫描函数,调用自定义的前向和反向传播方法。"""return SelectiveScanFn.apply(u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state)return selective_scan_fn
示例使用
selective_scan_fn = build_selective_scan_fn(selective_scan_cuda, mode=“mamba_ssm”)
代码注释说明:
build_selective_scan_fn: 该函数用于构建选择性扫描的自定义函数,接受一个CUDA实现和模式参数。
SelectiveScanFn: 这是一个继承自torch.autograd.Function的类,定义了前向和反向传播的方法。
forward: 前向传播方法,计算选择性扫描的输出,并保存需要在反向传播中使用的张量。
backward: 反向传播方法,计算输入张量的梯度。
selective_scan_fn: 这是一个包装函数,简化了对选择性扫描的调用。
此代码的核心功能是实现选择性扫描的前向和反向传播操作,支持多种输入和配置。
这个程序文件 test_selective_scan_speed.py 是一个用于测试选择性扫描(Selective Scan)算法性能的脚本,主要使用 PyTorch 框架实现。程序的核心部分是定义了一些选择性扫描的函数,并通过这些函数进行性能测试。
首先,文件中导入了一些必要的库,包括 torch、math、pytest 和 time 等。接着,定义了一个 build_selective_scan_fn 函数,这个函数用于构建一个选择性扫描的自定义操作(torch.autograd.Function)。在这个函数中,定义了前向传播(forward)和反向传播(backward)的方法。
在 forward 方法中,首先对输入的张量进行了一些处理,包括确保它们是连续的(contiguous),并根据需要调整维度。接着,根据不同的模式(如 mamba_ssm、sscore 等)调用相应的 CUDA 实现进行前向计算。计算完成后,保存必要的中间结果以供反向传播使用。
反向传播方法 backward 中则根据前向传播中保存的张量计算梯度。这里的实现考虑了多种情况,比如是否有额外的输入 z,以及是否需要处理 delta_bias 等。
除了选择性扫描的核心函数外,文件中还定义了一些辅助函数,如 selective_scan_ref 和 selective_scan_easy,这些函数提供了选择性扫描的参考实现和简化版本,便于进行性能比较。
在文件的最后部分,定义了 test_speed 函数,用于测试不同选择性扫描实现的速度。该函数首先设置了一些参数,包括数据类型、序列长度、批量大小等。然后,生成了一些随机输入数据,并通过不同的选择性扫描实现进行多次前向和反向传播的测试,记录每种实现的执行时间。
总的来说,这个程序文件的主要目的是实现选择性扫描算法,并通过性能测试来比较不同实现的效率,帮助开发者优化算法的执行速度。
注意:由于此博客编辑较早,上面“10.YOLOv11核心改进源码讲解”中部分代码可能会优化升级,仅供参考学习,以“11.完整训练+Web前端界面+200+种全套创新点源码、数据集获取”的内容为准。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻