MLLM技术报告 核心创新一览
MLLM技术报告创新点整理
- MLLM技术报告创新点整理
- Qwen3-VL
- InternVL3.5
- GLM4.5
- Seed1.5-VL
- ERNIE4.5
- Mimo-VL
- Keye-VL
整理不同厂商的多模态模型的核心创新(有即更新)
MLLM技术报告创新点整理
Qwen3-VL
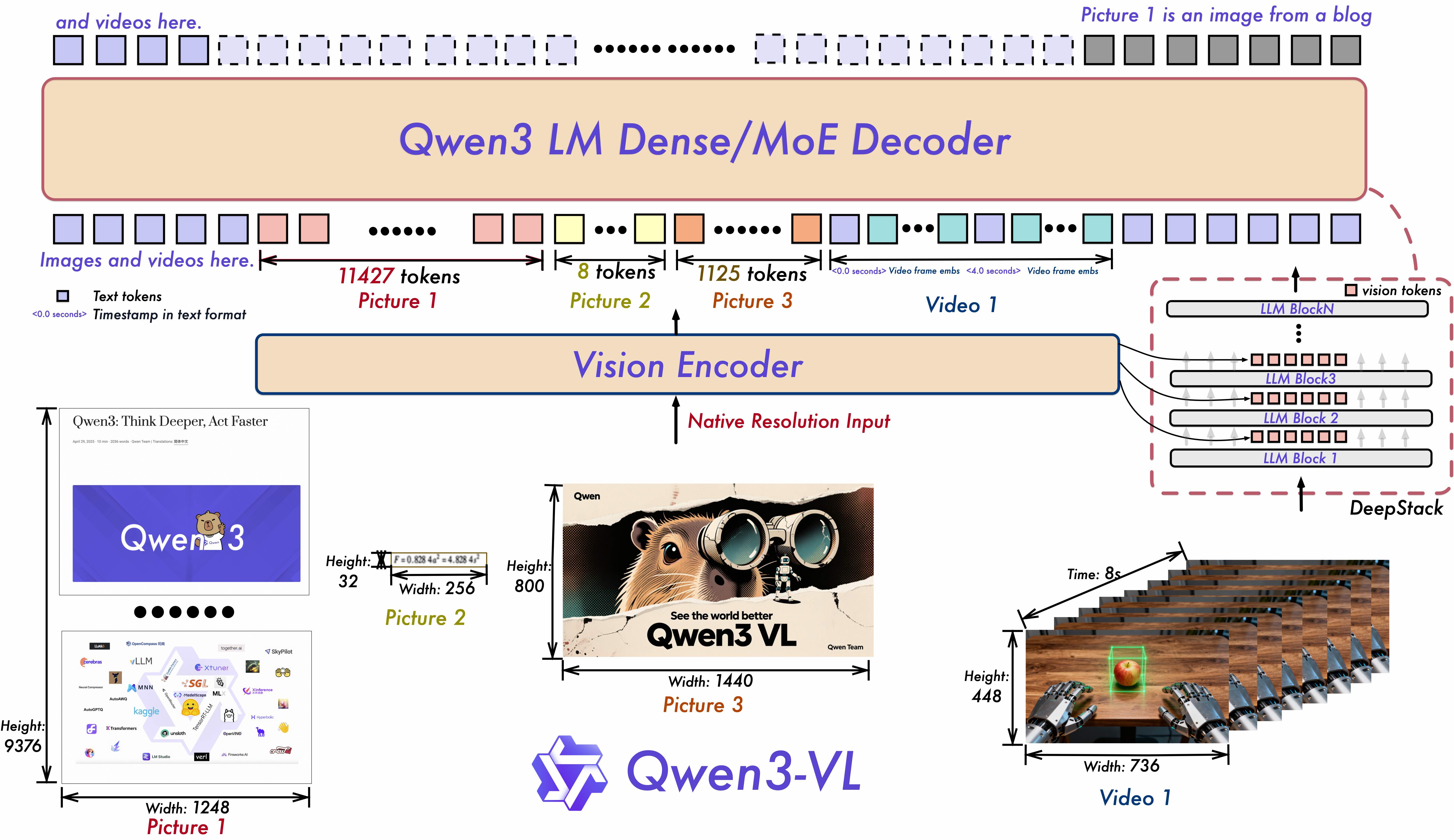
模型架构:
- 交错MRoPE:原始MRoPE将特征维度按照时间(t)、高度(h)和宽度(w)的顺序分块划分,使得时间信息全部分布在高频维度上。我们在 Qwen3-VL 中采取了 t,h,w 交错分布的形式,实现对时间,高度和宽度的全频率覆盖,这样更加鲁棒的位置编码能够保证模型在图片理解能力相当的情况下,提升对长视频的理解能力
- DeepStack:经典架构:ViT的视觉特征处理成patch embedding,和文本token embedding一起输入LLM backbone;DeepStack:ViT的不同层的token embedding注入LLM backbone的不同层
- 文本时间戳建模机制:对于视频时序建模,T-RoPE升级为“时间戳-视频帧”交错的输入形式,实现帧级别的时间信息与视觉内容的细粒度对齐。同时,模型原生支持“秒数”与“时:分:秒”(HMS)两种时间输出格式。这一改进显著提升了模型对视频中动作、事件的语义感知与时间定位精度,使其在复杂时序推理任务——如事件定位、动作边界检测、跨模态时间问答等——中表现更稳健、响应更精准
(paper is coming soon)
InternVL3.5

训练算法:
级联强化学习(Cascade Reinforcement Learning):解决稳定性差、效率低、性能上限有限的问题
传统RL方法难以同时满足“高效训练”“稳定收敛”“高性能”三大需求:
- 离线RL(如DPO、MPO):
- 优势:基于已有样本(Rollouts)训练,无需实时采样,训练效率高、计算成本低,且参数更新与样本采集解耦,不易出现Reward Hacking等不稳定问题。
- 劣势:性能上限低,依赖固定的离线数据集,难以自适应优化模型输出分布,无法充分挖掘模型推理潜力。
- 在线RL(如PPO、GSPO):
- 优势:基于模型实时生成的样本动态优化,能持续修正输出分布,性能上限更高,尤其适合复杂推理任务(如数学、多模态逻辑)。
- 劣势:计算成本极高(需实时采样大量Rollouts),训练过程敏感(易因样本质量波动导致收敛不稳定),且对初始模型性能要求高(弱模型易生成低质量样本,导致训练崩溃)。
Cascade RL的核心思路是融合两者优势:用离线RL解决“稳定预热”和“高效基础训练”问题,用在线RL解决“性能精调”和“上限突破”问题,形成“粗调→精调”的级联训练流程。
Cascade RL分为离线RL(MPO阶段) 和在线RL(GSPO阶段) 两个互补子阶段,两阶段无缝衔接,且后一阶段依赖前一阶段的成果(高质量模型与样本),具体流程如下:
-
第一阶段:离线RL(MPO,Mixed Preference Optimization)通过离线RL为模型打下坚实的推理基础,生成高质量的初始Rollouts(推理样本),避免在线RL阶段因初始模型过弱导致的训练不稳定。
LMPO=wpLp+wqLq+wgLgLp=−logσ(βlogπθ(yc∣x)π0(yc∣x)−βlogπθ(yr∣x)π0(yr∣x))Lq=Lq++Lq−Lq+=−logσ(βlogπθ(yc∣x)π0(yc∣x)−δ)Lq−=−logσ(−(βlogπθ(yr∣x)π0(yr∣x)−δ))Lg=−logπθ(yc∣x)∣yc∣\mathcal{L}_{MPO}=w_{p}\mathcal{L}_{p}+w_{q}\mathcal{L}_{q}+w_{g}\mathcal{L}_{g}\\ \mathcal{L}_p = -\log \sigma \left( \beta \log \frac{\pi_\theta(y_c \mid x)}{\pi_0(y_c \mid x)} - \beta \log \frac{\pi_\theta(y_r \mid x)}{\pi_0(y_r \mid x)} \right)\\ \mathcal{L}_q = \mathcal{L}_q^{+} + \mathcal{L}_q^{-}\\ \mathcal{L}_q^{+} = -\log \sigma \left( \beta \log \frac{\pi_\theta(y_c \mid x)}{\pi_0(y_c \mid x)} - \delta \right)\\ \mathcal{L}_q^{-} = -\log \sigma \left( -\left( \beta \log \frac{\pi_\theta(y_r \mid x)}{\pi_0(y_r \mid x)} - \delta \right) \right)\\ \mathcal{L}_g = - \frac{\log \pi_\theta (y_c | x)}{|y_c|} LMPO=wpLp+wqLq+wgLgLp=−logσ(βlogπ0(yc∣x)πθ(yc∣x)−βlogπ0(yr∣x)πθ(yr∣x))Lq=Lq++Lq−Lq+=−logσ(βlogπ0(yc∣x)πθ(yc∣x)−δ)Lq−=−logσ(−(βlogπ0(yr∣x)πθ(yr∣x)−δ))Lg=−∣yc∣logπθ(yc∣x)- 稳定收敛:离线RL阶段无需实时采样,参数更新与样本采集解耦,避免在线RL中常见的“样本质量波动→参数震荡”问题。
- 高效预热:Rollouts可在不同模型间共享(如1B、8B、38B模型复用同一批离线样本),大幅降低采样成本,训练效率比纯在线RL高3~5倍。
- 基础能力保障:经过MPO训练后,模型已具备初步的推理逻辑(如分步计算、多模态关联),为后续在线RL精调提供高质量起点
-
第二阶段:在线RL(GSPO,Group Sequence Policy Optimization)——性能精调与上限突破,基于第一阶段训练后的模型,通过在线RL动态优化输出分布,进一步突破性能上限,尤其提升复杂任务(如MMMU、MathVista)的推理能力,并依赖 MPO 阶段的高质量初始模型降低采样成本。
-
算法选择:采用GSPO(组序列策略优化,这里有GRPO-DAPO-GSPO的优化路线:从 GRPO 到 DAPO 和 GSPO:是什么、为什么以及如何做),这是一种无参考模型约束的在线RL算法,适合 dense 模型与MoE(混合专家)模型(如InternVL3.5-241B-A28B),且对超参数敏感度低,训练稳定性高。
-
核心机制:
-
优势函数(Advantage)计算:通过“同一查询的多响应对比”归一化奖励,避免单一响应的奖励偏差,更精准反映输出质量:
A^i=r(x,yi)−mean({r(x,yi)}i=1G)std({r(x,yi)}i=1G)\hat{A}_{i}=\frac{r\left(x, y_{i}\right)-mean\left(\left\{r\left(x, y_{i}\right)\right\}_{i=1}^{G}\right)}{std\left(\left\{r\left(x, y_{i}\right)\right\}_{i=1}^{G}\right)} A^i=std({r(x,yi)}i=1G)r(x,yi)−mean({r(x,yi)}i=1G)- xxx:输入查询(如多模态问题);yiy_iyi:模型为xxx生成的第iii个响应;r(x,yi)r(x,y_i)r(x,yi):yiy_iyi的奖励(由VisualPRM-v1.1等过程奖励模型计算);GGG:响应总数(通常取4~8)。
-
重要性采样比(Importance Sampling Ratio):采用“每token比率的几何平均”,避免单一token偏差对整体优化的影响,提升长序列推理的稳定性:
si(θ)=exp(1∣yi∣∑t=1∣yi∣logπθ(yi,t∣x,yi,<t)πθold(yi,t∣x,yi,<t))s_{i}(\theta )=exp \left( \frac {1}{\left | y_{i}\right | }\sum _{t=1}^{\left| y_{i}\right| }log \frac {\pi _{\theta }\left( y_{i,t}\left| x,y_{i,<t}\right) \right.}{\pi _{\theta _{old}}\left( y_{i,t} | x,y_{i,<t}\right) }\right) si(θ)=exp∣yi∣1t=1∑∣yi∣logπθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t)- πθ\pi_\thetaπθ:当前模型的生成概率;πθold\pi_{\theta_{old}}πθold:上一轮模型的生成概率;∣yi∣|y_i|∣yi∣:响应yiy_iyi的token长度。
-
训练目标:通过“裁剪(Clip)”机制限制参数更新幅度,避免训练震荡,确保稳定收敛:
LGSPO(θ)=E[1G∑i=1Gmin(si(θ)A^i,clip(si(θ),1−ε,1+ε)A^i)]\mathcal{L}_{GSPO}(\theta)=\mathbb{E}\left[\frac{1}{G} \sum_{i=1}^{G} min \left(s_{i}(\theta) \hat{A}_{i}, clip\left(s_{i}(\theta), 1-\varepsilon, 1+\varepsilon\right) \hat{A}_{i}\right)\right] LGSPO(θ)=E[G1i=1∑Gmin(si(θ)A^i,clip(si(θ),1−ε,1+ε)A^i)]- ε\varepsilonε:裁剪系数(通常取0.2),控制每轮参数更新的最大幅度。
-
-
数据来源:基于第一阶段MPO生成的高质量Rollouts,筛选“模型准确率在0.2~0.8”的查询(避免过易/过难样本),并补充最新多模态数据集(如MathVerse、LogicVista),构建MMPR-Tiny数据集(约7万组查询),确保在线训练数据的挑战性与多样性
-
token消耗控制:
Visual Resolution Router(ViR)与 Visual Consistency Learning(ViCO):目标是在不损失模型性能的前提下,减少视觉 token 的数量(Flash版本):
- 一致性训练:冻结参考模型(InternVL3.5),通过最小化不同压缩率(1/4 或 1/16)视觉 token 的输出分布差异来进行训练,差异度量使用 KL 散度。此阶段确保模型在不同分辨率下的输出一致性。
- 路由器训练:将 ViR 视为一个二分类器,通过交叉熵损失进行训练。基于压缩前后损失比ri=L∗VCO(I∗1/16)L∗VCO(I∗1/4)r_{i}=\frac{\mathcal{L}*{VCO}(I*{1/16})}{\mathcal{L}*{VCO}(I*{1/4})}ri=L∗VCO(I∗1/4)L∗VCO(I∗1/16)标注标签,当ri<τr_{i}<\tauri<τ时选择 1/16 压缩率,反之选择 1/4 压缩率。
模型部署:
Decoupled Vision-Language Deployment(DvD):传统模型部署中,视觉编码器(通常具有并行计算特性)与语言模型(自回归计算)串行执行,容易导致资源阻塞,降低推理效率
- 分离部署:将视觉服务器(包含 ViT、MLP 和 ViR 模块)和语言服务器(仅运行 LLM)分离,视觉服务器处理图像并生成 BF16 特征,通过 TCP/RDMA 协议传输至语言服务器。
- 流水线优化:采用异步并行的方式处理视觉处理、特征传输和语言解码过程,减少处理过程中的 stalls,提高整体推理效率。