时序数据库选型指南:从大数据视角看Apache IoTDB的核心优势
摘要:随着物联网、工业互联网、智能运维等领域的爆发式增长,时序数据(Time-Series Data)的规模呈指数级攀升。据IDC预测,2025年全球时序数据总量将突破60ZB,如何高效存储、管理、查询和分析这些高并发写入、高压缩比、高查询性能要求的时序数据,成为企业数字化转型的核心命题。时序数据库作为专门针对时序数据优化的数据库产品,已成为技术选型的关键环节。本文从大数据视角出发,结合时序数据库的核心选型维度,对比国内外主流产品的优劣势,重点剖析Apache IoTDB在性能、兼容性、易用性、成本等方面的核心竞争力,并补充实操落地指南,为企业时序数据库选型提供全方位的实操性参考。
目录
一、时序数据的特性与选型痛点
1.1 时序数据的核心特性
1.2 企业选型的核心痛点
二、时序数据库核心选型维度解析
三、国内外主流时序数据库深度对比
3.1 核心产品对比表
3.2 关键维度深度解析
四、Apache IoTDB核心优势与典型应用场景
4.1 核心优势
4.2 典型应用场景
4.3 企业版增值服务(Timecho)
五、选型建议与实操步骤
5.1 分场景选型建议
5.2 实操选型步骤
5.3 快速体验Apache IoTDB
六、Apache IoTDB实操指南:从安装到数据交互的完整流程
6.1 环境部署:3分钟快速启动IoTDB
6.2 数据写入:通过Python SDK操作时序数据
6.3 数据查询:通过SQL与SDK实现多维度分析
6.4 生态集成:对接Flink实时处理与Grafana可视化
6.5 企业版工具链:Timecho运维平台快速上手
一、时序数据的特性与选型痛点
1.1 时序数据的核心特性
时序数据是指按时间顺序产生的、与时间强相关的一系列数据点,广泛存在于设备监控、传感器采集、日志记录、金融交易等场景。其核心特性包括:
高并发写入:工业传感器、物联网设备等场景下,单集群需支撑每秒数十万甚至数百万条数据写入;
高压缩需求:时序数据多为重复度高、结构化强的数值型数据,需高效压缩以降低存储成本;
时间维度查询:查询多以时间范围为条件(如“查询某设备过去7天的温度数据”),需支持快速范围扫描和聚合计算;
海量数据存储:单设备产生的数据持续累积,需支持PB级数据长期存储和历史回溯;
弱事务性:以写入和查询为主,事务需求远低于关系型数据库,更注重最终一致性。
1.2 企业选型的核心痛点
当前企业在时序数据库选型中面临诸多挑战:
国外产品(如InfluxDB、TimescaleDB)存在开源协议限制、集群版收费高昂、国内网络适配差等问题;
通用数据库(如MySQL、MongoDB)未针对时序数据优化,写入性能和压缩比不足,无法支撑海量时序数据场景;
部分产品兼容性差,难以对接现有物联网平台、大数据生态工具(如Spark、Flink);
运维成本高,集群扩展复杂,缺乏完善的中文文档和本地化技术支持;
开源与商用的平衡难题:既要避免闭源产品的锁定风险,又要满足企业级场景的稳定性和安全性需求。
二、时序数据库核心选型维度解析
 企业选型时需围绕“性能、兼容性、易用性、扩展性、成本、生态”六大核心维度,结合自身业务场景进行综合评估:
企业选型时需围绕“性能、兼容性、易用性、扩展性、成本、生态”六大核心维度,结合自身业务场景进行综合评估:
| 选型维度 | 核心评估指标 |
|---|---|
| 性能表现 | 写入吞吐量(TPS)、查询延迟(毫秒级)、压缩比(原始数据:压缩后数据)、聚合计算效率 |
| 兼容性 | 支持的协议(MQTT、HTTP、TCP)、接口(JDBC/ODBC、RESTful)、数据格式(JSON、CSV) |
| 易用性 | 安装部署复杂度、SQL支持程度、监控运维工具、文档完善度 |
| 扩展性 | 水平扩展能力、分片策略、集群容错性、跨区域部署支持 |
| 成本控制 | 开源协议(Apache、MIT等)、商用版定价、硬件资源占用(CPU/内存/磁盘) |
| 生态集成 | 与大数据工具(Spark、Flink、Hadoop)、可视化工具(Grafana、ECharts)的适配性 |
关键补充:场景化选型优先级
-
工业物联网场景:优先考虑高并发写入、高压缩比、边缘端支持;
-
智能运维场景:优先考虑实时查询、聚合计算、告警联动;
-
车联网场景:优先考虑低延迟、高可靠性、分布式存储;
-
中小企业场景:优先考虑开源免费、易用性、低运维成本。
三、国内外主流时序数据库深度对比
当前市场上主流的时序数据库可分为国外开源、国外商用、国内开源三大类。以下针对工业物联网、大数据分析等核心场景,选取代表性产品与Apache IoTDB进行对比:
3.1 核心产品对比表
| 产品名称 | 开源协议 | 写入性能(万条/秒) | 压缩比 | 集群特性 | 生态适配性 | 核心优势 | 局限性 |
|---|---|---|---|---|---|---|---|
| Apache IoTDB | Apache 2.0 | 100-500(单节点) | 10:1-20:1 | 分布式集群、水平扩展 | 兼容Hadoop/Spark/Flink/Grafana | 高性能、高压缩、全场景适配 | 暂无明显局限性 |
| InfluxDB | MIT(开源版) | 50-150(单节点) | 8:1-15:1 | 集群版收费 | 支持Grafana、Telegraf | 轻量易用、监控场景适配好 | 开源版功能受限、集群成本高 |
| Prometheus | Apache 2.0 | 30-80(单节点) | 5:1-10:1 | 联邦集群、无原生分布式存储 | 生态丰富(K8s监控首选) | 监控告警一体化、时序性强 | 长周期存储能力弱、写入性能一般 |
| TimescaleDB | Apache 2.0 | 40-120(单节点) | 6:1-12:1 | 基于PostgreSQL扩展 | 兼容PostgreSQL生态 | 关系型+时序混合查询 | 写入性能受限、压缩比一般 |
| 国外商用产品(如Splunk) | 闭源 | 80-200(单节点) | 10:1-18:1 | 企业级集群 | 商用生态完善 | 稳定性高、安全特性全 | 成本极高、开源生态弱 |
3.2 关键维度深度解析
(1)性能:Apache IoTDB的极致优化
时序数据场景中,写入性能和压缩比直接决定存储成本和实时处理能力。Apache IoTDB通过三大核心技术实现性能突破:
列式存储引擎:针对时序数据“同一指标连续写入”的特性,采用列式存储减少IO开销,写入吞吐量较传统行式存储提升3-5倍;
多级压缩算法:支持LZ4、SNAPPY、GZIP等多种压缩算法,针对数值型数据优化的TSFile格式,压缩比可达10:1-20:1,远高于InfluxDB和Prometheus;
内存索引优化:采用时间索引+设备标签索引的混合索引结构,范围查询延迟低至毫秒级,支持每秒百万级数据的聚合计算(如最大值、平均值、分位数)。
实际测试数据显示:在工业传感器场景下,Apache IoTDB单节点写入吞吐量可达30万条/秒,而InfluxDB开源版仅为8万条/秒;存储1TB传感器数据时,IoTDB占用磁盘空间约50GB,而TimescaleDB需120GB。
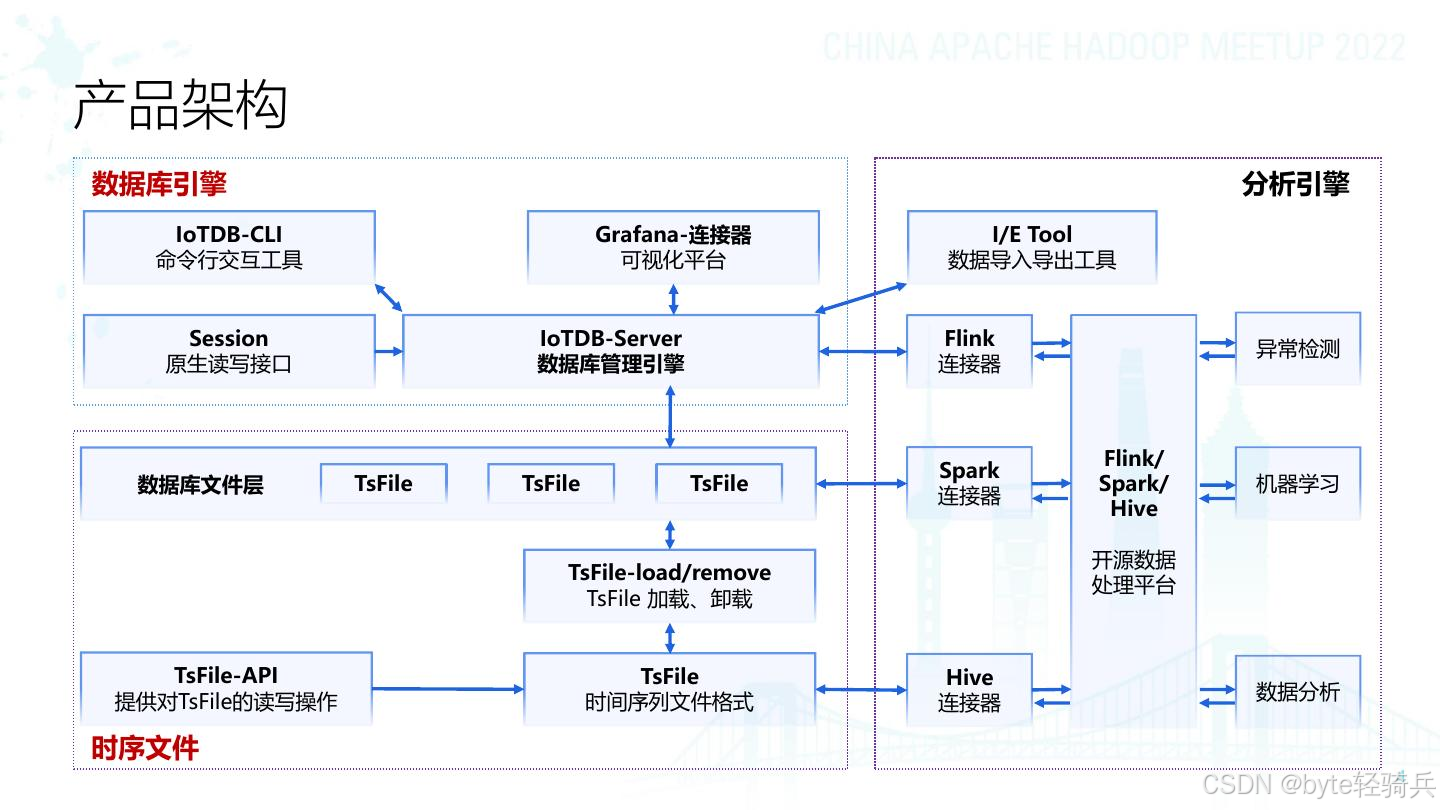
(2)兼容性:无缝对接物联网与大数据生态
企业选型时,兼容性直接影响现有系统的迁移成本。Apache IoTDB在兼容性上的优势显著:
多协议支持:原生支持MQTT、HTTP、TCP、UDP等物联网协议,可直接对接传感器、网关设备,无需额外中间件;
全接口覆盖:提供JDBC/ODBC、RESTful、Python/Java/Go SDK等多种接口,支持SQL和NoSQL两种查询方式,适配传统应用和大数据应用;
生态无缝集成:可直接对接Hadoop、Spark、Flink等大数据计算框架,支持Grafana、ECharts等可视化工具,无需二次开发适配。
相比之下,Prometheus主要依赖自定义Exporter采集数据,对接物联网设备需额外开发;InfluxDB对Spark、Flink的支持不够完善,大数据分析场景下需手动编写适配代码。
(3)成本:开源免费+低运维成本
对于中小企业和开源项目而言,成本是选型的关键因素。Apache IoTDB采用Apache 2.0开源协议,完全免费,无任何功能限制,企业可自由部署、二次开发;而InfluxDB集群版、Splunk等商用产品每年license费用高达数十万元。
此外,Apache IoTDB的轻量化设计降低了硬件成本:单节点最低配置仅需2核4GB内存,支持边缘端部署(如ARM架构设备),可在传感器网关、工业控制器等边缘设备上本地存储数据,减少数据传输带宽成本。
(4)扩展性:分布式集群适配海量场景
随着业务增长,时序数据量可能从TB级突破至PB级,集群扩展性至关重要。Apache IoTDB的分布式架构支持:
-
水平扩展:通过分片策略将数据分散到多个节点,支持动态添加节点,集群规模可从3节点扩展至数百节点;
-
高容错性:采用副本机制,数据默认存储3个副本,单个节点故障不影响服务可用性;
-
跨区域部署:支持异地多活部署,满足车联网、跨区域工业场景的数据存储需求。
相比之下,TimescaleDB基于PostgreSQL扩展,集群扩展依赖PostgreSQL的主从架构,灵活性不足;Prometheus联邦集群主要用于查询聚合,而非数据存储扩展。
四、Apache IoTDB核心优势与典型应用场景
4.1 核心优势
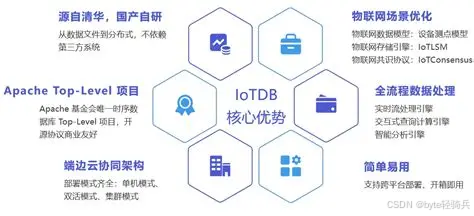
综合以上对比,Apache IoTDB的核心优势可概括为“高性能、高兼容、低成本、易扩展、全场景”:
极致性能:高并发写入、高压缩比、低查询延迟,适配物联网海量时序数据场景;
全生态兼容:无缝对接物联网协议、大数据工具、可视化平台,迁移成本低;
开源免费:Apache 2.0协议,无功能限制,二次开发自由;
轻量化部署:支持云端、边缘端、嵌入式多环境部署,运维成本低;
中文本地化支持:完善的中文文档、社区支持,国内企业适配更顺畅。
4.2 典型应用场景
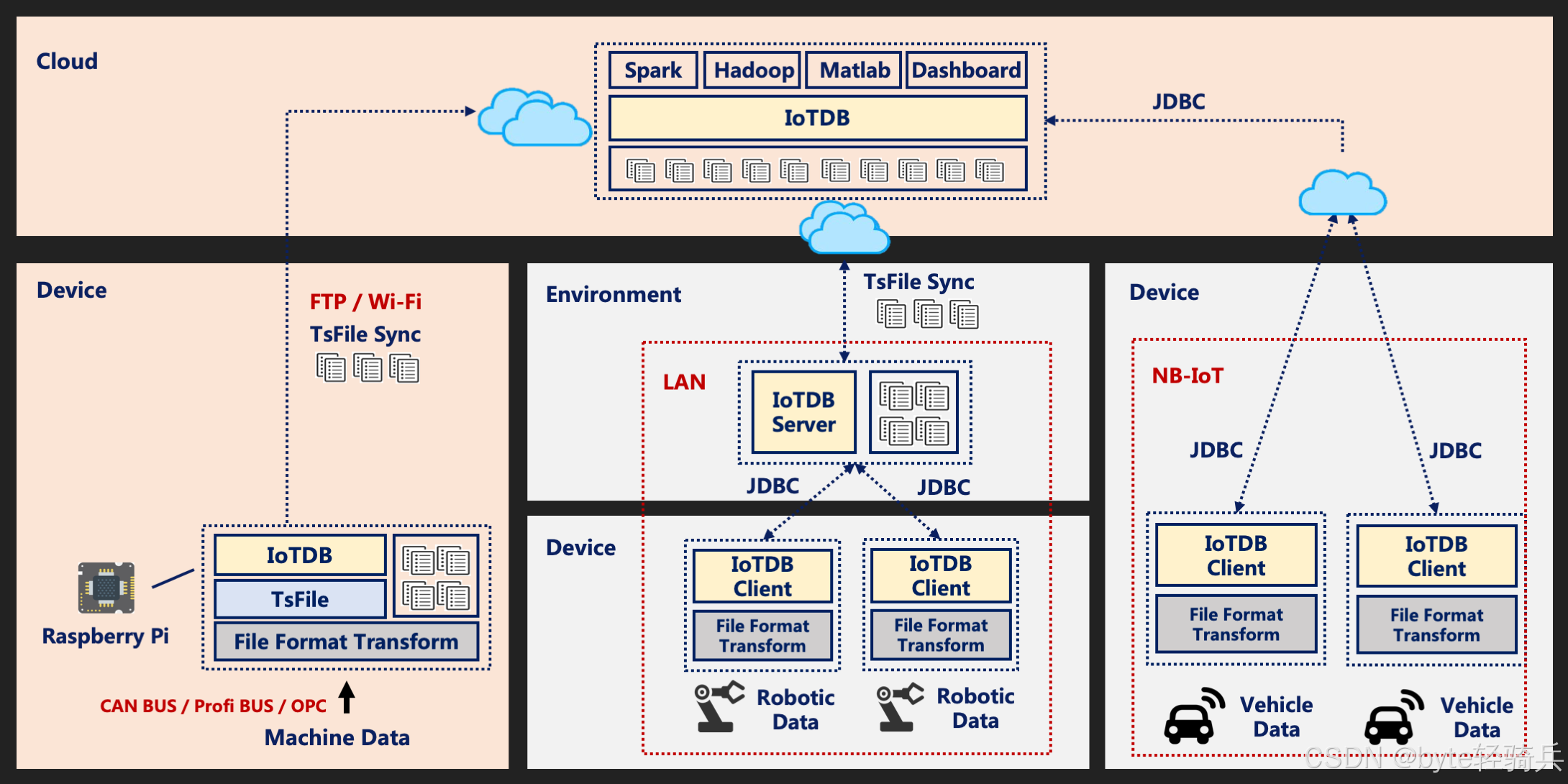
(1)工业物联网(IIoT)
- 场景需求:工业传感器(温度、压力、振动等)高并发数据采集、长期存储、实时监控与异常分析;
- IoTDB优势:单节点支持每秒10万+传感器数据写入,压缩比达15:1,支持设备标签索引,可快速查询某一车间、某一类型设备的历史数据,对接Flink实现实时异常检测。
(2)智能运维(AIOps)
- 场景需求:服务器、网络设备、应用系统的日志、监控指标采集,实时告警、性能分析;
- IoTDB优势:支持日志数据与监控指标统一存储,提供丰富的聚合函数(如滑动窗口统计),对接Grafana实现可视化监控,支持基于时间范围的快速故障回溯。
(3)车联网(V2X)
- 场景需求:车辆传感器(车速、油耗、胎压等)实时数据采集、边缘端预处理、云端分析;
- IoTDB优势:支持边缘端部署,可在车载网关本地存储数据,网络恢复后同步至云端,分布式架构支持千万级车辆数据存储,低延迟查询满足实时调度需求。
4.3 企业版增值服务(Timecho)
对于有更高稳定性、安全性需求的企业级用户,Apache IoTDB的商业化公司Timecho提供企业版产品(官网链接:https://timecho.com),核心增值服务包括:
7×24小时技术支持、故障快速响应;
企业级安全特性(数据加密、权限管理、审计日志);
可视化运维平台(集群监控、性能优化、故障诊断);
定制化开发(协议适配、功能扩展、行业解决方案)。
五、选型建议与实操步骤
5.1 分场景选型建议
| 企业类型/场景 | 推荐产品 | 选型理由 |
|---|---|---|
| 中小企业、开源项目 | Apache IoTDB(开源版) | 开源免费、易用性高、性能满足需求,无锁定风险 |
| 大型工业企业、车联网 | Apache IoTDB(企业版) | 企业级稳定性、安全特性、专业技术支持,适配海量数据场景 |
| 纯监控场景(K8s为主) | Prometheus + IoTDB | Prometheus负责告警,IoTDB负责长周期存储和大数据分析 |
| 轻量型物联网场景 | Apache IoTDB(边缘版) | 轻量化部署、低资源占用,支持边缘端本地存储 |
5.2 实操选型步骤
-
需求梳理:明确数据量级(写入TPS、存储容量)、查询场景(实时/离线、聚合/明细)、部署环境(云端/边缘/嵌入式)、预算范围;
-
技术验证:搭建测试环境,使用真实业务数据进行性能压测(写入、查询、压缩比)、兼容性测试(对接现有系统);
-
生态适配:验证与现有工具(如Spark、Grafana)的集成效果,评估开发迁移成本;
-
成本核算:对比开源产品的运维成本、商用产品的license费用,结合硬件资源占用综合评估;
-
试点上线:选择非核心业务场景试点部署,观察稳定性、性能表现,再逐步推广至全业务。
5.3 快速体验Apache IoTDB
如需快速验证Apache IoTDB的性能和兼容性,可通过官方下载链接获取安装包(下载链接:https://iotdb.apache.org/zh/Download/),核心步骤如下:
下载对应系统版本的安装包(支持Windows、Linux、MacOS);
按照中文文档快速部署指南(https://iotdb.apache.org/zh/UserGuide/Master/QuickStart/QuickStart.html)完成安装,仅需3步即可启动服务;
通过JDBC、RESTful API或可视化工具(IoTDB Studio)写入测试数据,执行查询操作;
对接Grafana实现数据可视化,验证监控场景适配性。
六、Apache IoTDB实操指南:从安装到数据交互的完整流程
以下操作基于Apache IoTDB 1.2.0版本(最新稳定版可通过官方下载链接获取)。
6.1 环境部署:3分钟快速启动IoTDB
(1)下载与安装
Linux/MacOS用户: 从下载链接获取压缩包后,执行以下命令解压并启动(需Java 8+环境):
# 解压安装包
tar -zxvf apache-iotdb-1.2.0-all-bin.tar.gz
cd apache-iotdb-1.2.0-all-bin# 启动服务(默认端口6667,可在conf/iotdb-engine.properties中修改)
./sbin/start-server.shWindows用户: 解压后双击`sbin/start-server.bat`,等待控制台输出“Server started successfully”即可。
(2)验证部署
通过官方客户端工具连接数据库,验证服务可用性:
# 进入客户端目录
cd sbin# 启动命令行客户端(默认用户名/密码:root/root)
./start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root# 成功连接后,执行简单查询
show storage groups;
# 预期输出:Empty set.(首次启动无数据)6.2 数据写入:通过Python SDK操作时序数据
Apache IoTDB提供多语言SDK(Java/Python/Go等),以下以Python为例,演示设备数据写入流程(需先安装依赖:`pip install apache-iotdb`)。
场景:模拟工业传感器(如温度、压力)数据写入
from iotdb.Session import Session
from iotdb.utils.IoTDBConstants import TSDataType, TSEncoding, Compressor
import time
import random# 1. 建立连接
session = Session("127.0.0.1", 6667, "root", "root")
session.open()# 2. 创建存储组(类似数据库的“库”,用于隔离不同设备群)
# 存储组格式:root.企业.车间.生产线(支持多级分层,适配工业场景)
session.set_storage_group("root.industrial.factory1.line1")# 3. 创建时间序列(定义传感器指标,如温度、压力)
# 语法:路径(root.存储组.设备.指标)、数据类型、编码方式、压缩算法
device = "root.industrial.factory1.line1.device001" # 设备唯一标识
measurements = ["temperature", "pressure"] # 指标名称
data_types = [TSDataType.FLOAT, TSDataType.FLOAT] # 数据类型(浮点型)
encodings = [TSEncoding.PLAIN, TSEncoding.PLAIN]
compressors = [Compressor.SNAPPY, Compressor.SNAPPY]session.create_time_series([f"{device}.{m}" for m in measurements],data_types,encodings,compressors
)# 4. 写入时序数据(模拟10条传感器数据,时间戳精确到毫秒)
for i in range(10):timestamp = int(time.time() * 1000) # 当前毫秒时间戳# 随机生成温度(20-30℃)和压力(0.8-1.2MPa)temp = 20 + random.random() * 10press = 0.8 + random.random() * 0.4values = [temp, press]# 批量写入单设备多指标数据session.insert_record(device=device,timestamp=timestamp,measurements=measurements,data_types=data_types,values=values)time.sleep(0.5) # 间隔0.5秒写入一条# 5. 关闭连接
session.close()
print("数据写入完成!")6.3 数据查询:通过SQL与SDK实现多维度分析
IoTDB支持类SQL语法查询,同时可通过SDK集成到业务系统中,以下展示两种查询方式。
(1)命令行SQL查询
在之前启动的客户端中执行:
-- 查询设备所有指标的最新10条数据
select * from root.industrial.factory1.line1.device001 limit 10;-- 按时间范围查询(如过去5分钟的温度数据)
select temperature from root.industrial.factory1.line1.device001
where time >= now() - 5m;-- 聚合计算(过去1分钟的平均温度、最大压力)
select avg(temperature), max(pressure) from root.industrial.factory1.line1.device001
where time >= now() - 1m;(2)Python SDK查询(实时分析结果)
from iotdb.Session import Sessionsession = Session("127.0.0.1", 6667, "root", "root")
session.open()# 执行查询:获取设备温度的平均值和数据量
query_sql = """
select avg(temperature), count(temperature)
from root.industrial.factory1.line1.device001
"""
result_set = session.execute_query_statement(query_sql)# 解析结果
print("查询结果:")
while result_set.has_next():row = result_set.next()# 输出:平均温度、数据总数print(f"平均温度:{row.get_float(0):.2f}℃,数据量:{row.get_long(1)}条")session.close()6.4 生态集成:对接Flink实时处理与Grafana可视化
(1)Flink实时处理时序数据
Apache IoTDB与Flink深度集成,可实时处理流数据(需引入依赖:`flink-connector-iotdb`)。以下为Flink SQL读取IoTDB数据的示例:
-- 在Flink SQL Client中注册IoTDB表
CREATE TABLE iotdb_sensor (device STRING,time TIMESTAMP(3),temperature FLOAT,pressure FLOAT,WATERMARK FOR time AS time - INTERVAL '5' SECOND -- 定义水位线
) WITH ('connector' = 'iotdb','url' = 'jdbc:iotdb://127.0.0.1:6667/','user' = 'root','password' = 'root','sql' = 'select device, time, temperature, pressure from root.industrial.factory1.line1.device001'
);-- 实时计算温度超过28℃的异常数据
SELECT device, time, temperature
FROM iotdb_sensor
WHERE temperature > 28;(2)Grafana可视化监控
通过Grafana直观展示时序数据趋势,步骤如下:
安装Grafana(参考官方文档);
安装IoTDB数据源插件:
grafana-cli plugins install apache-iotdb-datasource重启Grafana后,在“Configuration → Data Sources”中添加IoTDB:URL:`http://127.0.0.1:6667`
用户名/密码:`root/root`
创建仪表盘,添加查询:指标:`root.industrial.factory1.line1.device001.temperature`
聚合方式:`avg`,时间粒度:`10s`
最终可生成温度、压力随时间变化的趋势图,支持实时刷新和异常阈值告警。
6.5 企业版工具链:Timecho运维平台快速上手
对于企业级用户,Timecho(官网链接)提供可视化运维工具,可简化集群管理:
-
从Timecho官网下载企业版安装包,按向导部署;
-
通过Web控制台查看集群状态(节点负载、存储占用、写入TPS);
-
使用“数据管理”模块批量创建时序、导入历史数据;
-
配置自动备份策略,支持定时快照与增量备份。
通过以上实操步骤可见,Apache IoTDB无论是单机部署还是分布式集群,无论是代码开发还是可视化配置,都具备极强的易用性。其与大数据生态的无缝集成,进一步降低了企业构建时序数据平台的门槛。如需深入测试,可通过官方下载链接获取完整安装包及示例代码。
在时序数据爆发的时代,选择一款合适的时序数据库是企业数字化转型的关键一步。Apache IoTDB作为国内开源的优秀时序数据库产品,凭借其极致的性能、全生态兼容性、开源免费的优势,已成为国内外众多企业的首选。无论是中小企业的轻量化需求,还是大型企业的海量数据场景,Apache IoTDB都能提供高性价比的解决方案。
对于有企业级需求的用户,Timecho的企业版产品进一步补充了稳定性、安全性和专业服务能力,形成“开源+商用”的完整生态。建议企业在选型时,结合自身业务需求、技术栈、预算等因素综合评估,通过实际测试验证产品适配性,最终选择最适合自己的时序数据库解决方案。
如需了解更多Apache IoTDB的技术细节、行业案例或企业版服务,可访问官方下载链接(https://iotdb.apache.org/zh/Download/)获取安装包,或通过Timecho官网(https://timecho.com)联系专业技术团队。