工业级时序数据库选型指南:技术架构与场景化实践
本文目录:
- 一、引言:时序数据管理的核心挑战
- 二、时序数据库选型的五大核心维度
- 2.1 写入性能与乱序处理能力
- 2.2 存储压缩效率与成本优化
- 2.3 查询性能与分析能力
- 2.4 架构扩展性与高可用性
- 2.5 生态兼容性与国产化适配
- 三、Apache IoTDB的技术创新与场景化实践
- 3.1 天然适配工业层级关系
- 3.2 极致的写入性能和存储效率
- 3.3 物联网友好的数据模型
- 四、选型实施与风险规避
- 4.1 概念验证(PoC)的关键指标
- 4.2 长期成本评估
- 4.3 社区与厂商支持
- 五、总结:技术选型决策矩阵
一、引言:时序数据管理的核心挑战
在数据爆炸的时代,企业每天都在面临一个共同的挑战:如何高效地处理海量时间序列数据。例如,单台风力发电机每秒可生成200KB数据,一座中等规模的风电场每秒数据量超过4.5GB。传统关系型数据库在处理这类高频写入、长期存储、复杂查询需求时面临严重瓶颈,具体表现为:
- 写入性能不足:传统行式存储架构难以支撑每秒百万级数据点的并发写入。
- 存储成本高昂:未压缩的时序数据占用大量磁盘空间,导致3年TCO(总拥有成本)激增。
- 查询效率低下:复杂窗口聚合、降采样分析等操作需全表扫描,延迟高达秒级。
- 架构扩展性差:单机部署无法应对亿级设备接入,分布式扩展需复杂的分片管理。

为应对海量工业物联网数据管理,更好地实现工业数字化、智能化发展,专门管理时序数据的时序数据库产品应运而生。那么如果需要使用时序数据库,该如何衡量时序数据库的性能表现?好用的时序数据库,又该满足哪些条件?本文将梳理时序数据库的性能选型标准,供大家参考。
二、时序数据库选型的五大核心维度
2.1 写入性能与乱序处理能力
工业场景中,弱网环境常导致30%-50%的数据乱序到达。高性能时序数据库需满足:
- 高吞吐量:单节点支持每秒100万级以上数据点写入,高频场景(如传感器秒级上报)需达到500万点/秒以上。
- 乱序容忍性:在50%乱序率下,性能下降需低于20%,避免数据丢失或查询失真。
Apache IoTDB通过IoTLSM顺乱序分离存储引擎实现了技术突破:
- 双通道写入:顺序数据直接写入主存储区,乱序数据路由至独立缓冲区,避免传统LSM树频繁合并带来的性能损耗。
- 异步合并机制:后台线程按时间窗口重组乱序数据,写入吞吐量达千万数据点/秒,较传统方案提升3倍。
- 预写日志(WAL):确保即使系统故障,乱序数据仍可完整恢复,数据持久性达99.99%。
IoTDB乱序数据写入
-- 插入乱序数据(时间戳3 < 时间戳4)
INSERT INTO root.ln.wf02.wt02(timestamp, status, hardware) VALUES (3, false, 'v3'), (4, true, 'v4')
IoTDB会自动将乱序数据缓存至独立缓冲区,待时间窗口闭合后合并至主存储区,确保查询结果的时序一致性。
2.2 存储压缩效率与成本优化
时序数据的高冗余性(如传感器稳态值)为压缩提供了巨大空间。优秀的时序数据库需实现:
- 高压缩比:无损压缩比达5-10倍,有损压缩比可至100倍以上,显著降低存储成本。
- 冷热数据分层:自动将低频历史数据迁移至廉价存储介质(如S3),保留高频数据在SSD中。
IoTDB的TsFile列式存储格式通过三重压缩技术链实现极致存储效率:
- 动态编码优化:
- 浮点数据采用Gorilla编码,压缩率提升5倍。
- 整型数据适用RLE(游程编码),重复序列压缩比达30:1。
- 无损压缩层:支持SNAPPY、LZ4等算法二次压缩,整体存储成本降低85%。
- 死区处理(SDT):过滤稳态数据点,进一步提升存储密度。
技术对比:
| 数据库 | 无损压缩比 | 存储成本(3年TCO) |
|---|---|---|
| Apache IoTDB | 1:10 | 100万元 |
| InfluxDB | 1:4 | 250万元 |
| TimescaleDB | 1:3 | 300万元 |
(数据来源:某汽车制造企业实测)
2.3 查询性能与分析能力
时序数据的价值在于通过分析挖掘业务洞察。理想的时序数据库需支持:
- 毫秒级响应:TB级数据复杂查询延迟低于50ms。
- 丰富的时序函数:覆盖异常检测、频域分析、预测建模等工业场景需求。
- SQL兼容性:降低开发门槛,支持与现有SQL生态工具(如Grafana、Spark)集成。
IoTDB的原生时序计算引擎提供70+内置函数,并支持用户自定义UDF:
- 窗口聚合:
SELECT AVG(temperature) FROM devices WHERE time > now() - 1h GROUP BY T(10m) - 降采样查询:
SELECT MAX(speed) FROM vehicles RESAMPLE BY 1h - 异常检测:
SELECT ANOMALY_DETECTION(pressure, 'IQR', 3) FROM sensors
基于UDF的设备健康度评估
-- 注册自定义UDF
CREATE FUNCTION health_score AS 'com.example.HealthScoreUDF' LANGUAGE JAVA;-- 实时计算设备健康度
SELECT health_score(vibration, temperature) AS score FROM machines
该查询通过调用Java编写的UDF,实时分析振动和温度数据,输出设备健康评分(0-100分),为预测性维护提供依据。
2.4 架构扩展性与高可用性
随着业务增长,时序数据库需具备弹性扩展能力:
- 分布式集群支持:水平扩展至千节点以上,容忍节点失效。
- 端边云协同:边缘轻量化部署(如树莓派),云端大规模分析,实现数据分级处理。
IoTDB的分布式弹性架构通过以下技术实现:
- 存算分离:DataNode专注数据处理,ConfigNode通过Raft协议管理元数据,支持独立扩容。
- 动态分区:数据按设备哈希值自动分区,默认以7天为粒度划分DataRegion,新节点加入后秒级接管数据。
- 多副本机制:每个数据分区默认3副本,节点宕机时自动切换,故障恢复时间<30秒。
应用案例:某国家级新能源监控平台接入5000万+测点,通过IoTDB分布式集群实现:
- 写入峰值:2270万数据点/秒(TPCx-IoT全球第一纪录)。
- 查询延迟:99%的聚合查询在10ms内完成。
- 存储成本:较传统方案降低80%,年节省硬件投入超500万元。
2.5 生态兼容性与国产化适配
工业场景对稳定性和合规性要求极高:
- 信创适配:兼容麒麟、OpenEuler等国产操作系统,通过工信部信通院测评。
- 工具链集成:无缝对接主流工业协议(如OPC UA、Modbus)和大数据平台(如Flink、Hadoop)。
IoTDB的全栈国产化能力已通过40+认证:
- 操作系统:麒麟V10、统信UOS。
- 芯片架构:飞腾、龙芯、鲲鹏。
- 中间件:Tomcat、ActiveMQ。
OPC UA协议数据接入
// 使用IoTDB的OPC UA客户端库
OPCUAClient client = new OPCUAClient("opc.tcp://server:4840");
client.connect();
List<DataValue> values = client.read("ns=2;s=Temperature");// 批量写入IoTDB
BatchWriteExecutor executor = new BatchWriteExecutor("jdbc:iotdb://localhost:6667", "root", "root");
executor.write("root.factory.line1.sensor1", System.currentTimeMillis(), values.get(0).getValue());
该代码通过OPC UA协议实时采集温度数据,并批量写入IoTDB,支持毫秒级延迟。
三、Apache IoTDB的技术创新与场景化实践
Apache IoTDB作为首个由中国高校发起的Apache顶级时序数据库项目,在工业物联网领域展现出独特优势:
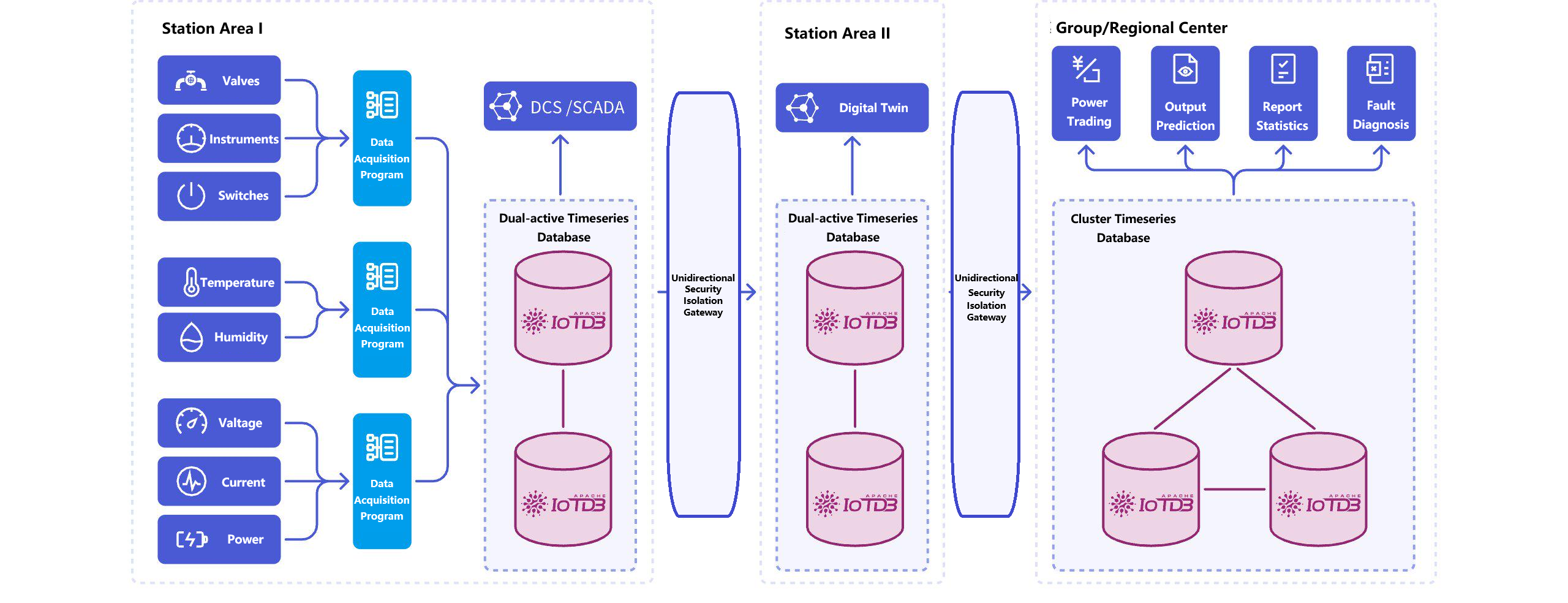
3.1 天然适配工业层级关系
传统时序数据库多采用标签(Tag)方式组织数据,难以管理复杂的设备层级。IoTDB的树状元数据模型直接映射“集团-工厂-产线-设备”的物理结构:
root
├── ln
│ ├── wf01
│ │ ├── wt01
│ │ │ ├── status (BOOLEAN)
│ │ │ └── temperature (FLOAT)
│ │ └── wt02
│ └── wf02
└── bj└── plant1└── machine1└── pressure (INT32)
这种模型将设备元数据存储成本降低50%,并支持高效的层级查询:
-- 查询北京工厂所有设备的温度数据
SELECT * FROM root.bj.** WHERE time > now() - 1h AND measurement LIKE '%temperature'
3.2 极致的写入性能和存储效率
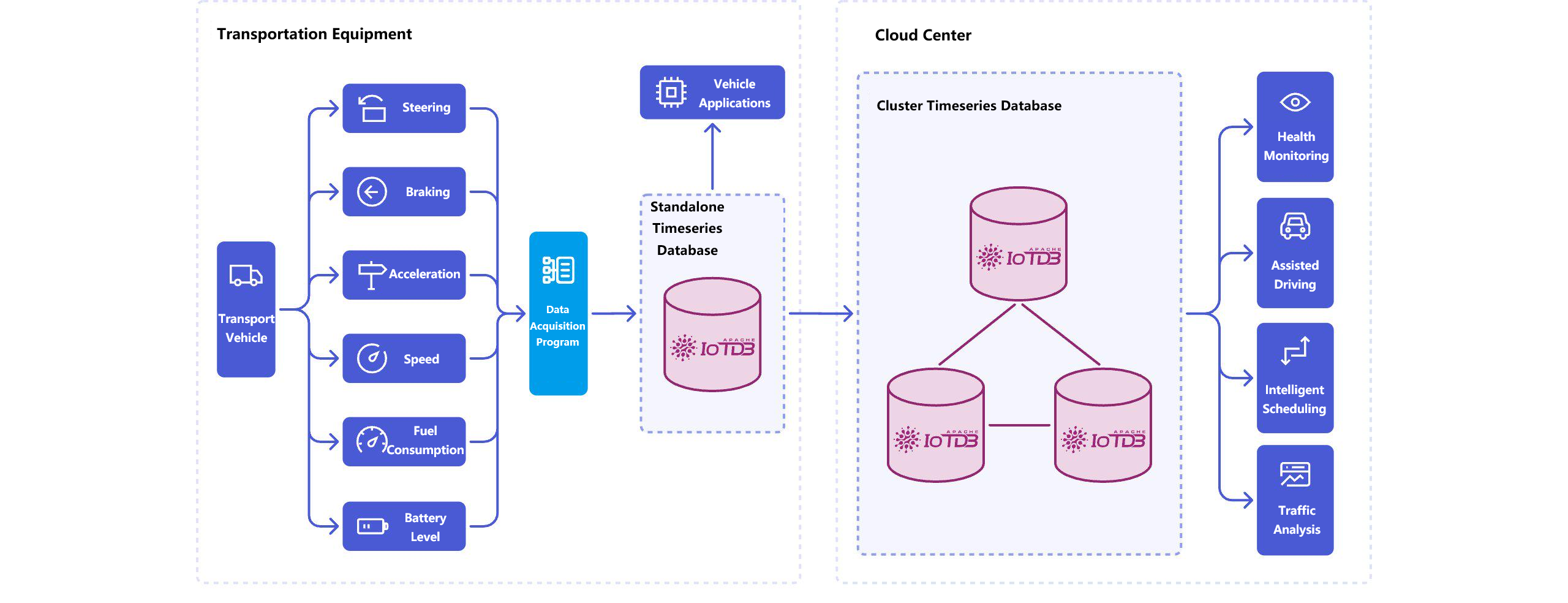
IoTDB采用了一种称为"时间序列优化的存储模型"的架构。每个时间序列(device+measurement的组合)都被视为一个独立的数据流,系统为每条流单独维护索引和统计信息。这与传统行存储模式完全不同。当设备数量达到百万级、指标数量达到千万级时,这种设计的优势尤其明显。
在压缩算法上,IoTDB集成了针对不同数据类型的多种压缩策略。对于浮点数据,它使用戈蒂压缩算法;对于整数,采用自适应的帧压缩;对于布尔值和枚举类型,使用位级压缩。实际测试表明,在典型工业场景中,IoTDB的压缩率可以达到10:1到20:1,这意味着存储成本相比传统方案可以降低90%以上。
// IoTDB中的时间序列写入示例
Session session = new Session.Builder().host("127.0.0.1").port(6667).username("root").password("root").build();
session.open();List<String> measurements = Arrays.asList("temperature", "humidity");
List<TSDataType> types = Arrays.asList(TSDataType.FLOAT, TSDataType.FLOAT);
session.createTimeseries("root.factory.device01.temperature",TSDataType.FLOAT,TSEncoding.GORILLA,CompressionType.SNAPPY);long timestamp = System.currentTimeMillis();
session.insertRecord("root.factory.device01", timestamp, measurements, types, Arrays.asList(25.5f, 65.2f));
相比其他时序数据库,IoTDB的批量写入接口设计得更加紧凑高效。在实际部署中,单机IoTDB实例可以稳定支持100万条/秒以上的写入吞吐量,这对于工业物联网场景已经完全足够。
3.3 物联网友好的数据模型
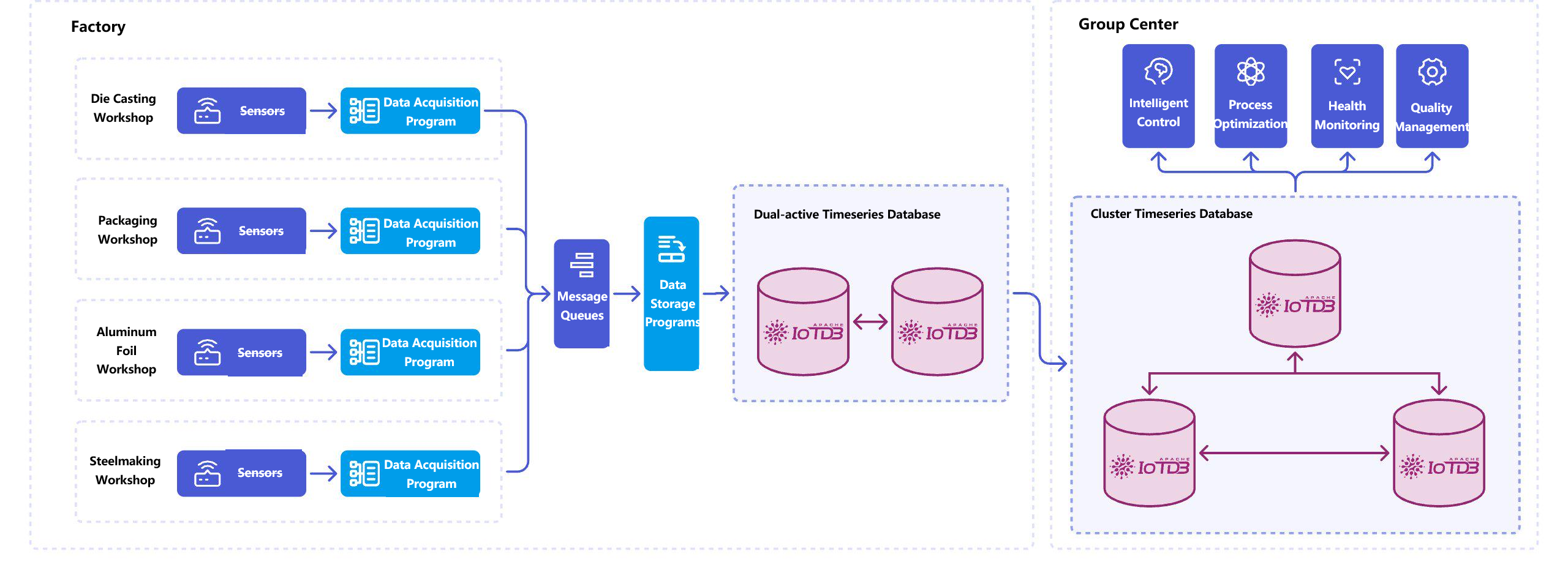
在数据模型设计上,IoTDB充分考虑了物联网场景的特殊性。它引入了"设备-测点"的二层结构,与物理世界中设备及其属性的对应关系更加直观。一个工厂可能有多个生产区域,每个区域有多台设备,每台设备有多个传感器。IoTDB的树状时间序列命名空间能够自然地映射这种层级结构。
-- 查询2024年10月某工厂所有设备的平均温度
SELECT avg(temperature) FROM root.factory.*.*
WHERE time >= 1730000000000 AND time < 1730086400000
这种通配符查询能力在处理大规模设备群体时效率很高。相比需要手动拼接OR条件或进行复杂JOIN操作的通用数据库,IoTDB的查询表达力明显更强。
四、选型实施与风险规避
4.1 概念验证(PoC)的关键指标
- 写入峰值测试:使用真实业务数据模拟50%乱序率,验证系统在高并发下的稳定性。
- 查询P99延迟:执行1000次复杂聚合查询,确保99%的请求在50ms内完成。
- 压缩率验证:对比原始数据与压缩后的数据量,确保达到预期的存储成本节省。
- 高可用测试:模拟节点宕机,观察数据一致性与恢复时间。
4.2 长期成本评估
- 硬件成本:根据数据量与压缩比,测算3年所需服务器数量。
- 许可费用:商业版按核心/节点收费,需对比开源版与企业版的性价比。
- 运维人力:分布式集群的管理复杂度直接影响运维成本,需评估工具链的易用性。
对比建议:
- 中小规模场景(<10万测点):选择开源版,成本低且功能足够。
- 大规模工业场景(>100万测点):优先考虑企业版,享受原厂技术支持与高级功能(如智能运维、审计日志)。
4.3 社区与厂商支持
- 优先选择Apache顶级项目:如IoTDB、InfluxDB,保障持续迭代与社区活跃度。
- 国产化服务团队:工业场景需快速响应,优先选择拥有本地技术支持的厂商。
五、总结:技术选型决策矩阵
| 应用场景 | 核心需求 | 推荐方案 |
|---|---|---|
| 工业物联网(IIoT) | 千万级设备接入、端边云协同、工业协议直连 | Apache IoTDB |
| IT运维监控 | 容器/K8s生态集成、多维度标签查询 | InfluxDB或VictoriaMetrics |
| 金融高频分析 | 纳秒级延迟、复杂窗口计算 | QuestDB |
| 混合事务/分析(HTAP) | 强一致性事务、复杂关联查询 | TimescaleDB |
Apache IoTDB凭借树形设备模型、TsFile高效存储、端边云协同、原生AI集成等核心技术,成为工业物联网场景的首选。其在TPCx-IoT基准测试中创造的2270万数据点/秒写入纪录,以及在国家电网、中国中车等企业的成功实践,充分验证了其技术领先性与可靠性。
立即体验:
- 开源版下载:https://iotdb.apache.org/zh/Download/
- 企业版官网:https://timecho.com