Genie Envisioner--智元机器人--世界模型框架--2025.8.7

0. 前言
最近宇树科技开源世界模型,让世界模型再一次进入大众视野,VLA也许不是提高具身智能能力的唯一路径,也不一定是指令驱动的通用具身智能的终极解决方案,关于世界模型的研究也需要重视起来。
论文页
项目页
github
1. 简要介绍
1.1 背景
能在物理世界中感知、推理并行动的具身代理,是人工智能系统的下一个前沿方向。核心的基础性研究挑战仍是:开发可扩展且鲁棒的机器人操控能力——即通过有选择的接触有目的地与物理环境交互并控制它。
尽管该领域已取得大量进展——从分析方法(Berenson 等,2009;Stilman,2007)、基于模型的框架(Ebert 等,2018;Janner 等,2019;Nagabandi 等,2020),到从大规模数据集中学习操控策略的数据驱动方法(Black 等,2024;Brohan 等,2023;Bu 等,2025b;Kim 等,2024)——现有系统通常依赖于数据采集、训练与评估的割裂流程。
每个阶段都需要定制化基础设施、人工标注与任务专用调参;由此产生的磨损会降低迭代速度、掩盖失败原因,并阻碍大规模的可复现性。这些碎片化阶段凸显了缺乏能够以统一方式学习并评估操控策略的整合式框架。
1.2 Genie Envisioner(GE)
为此,作者提出了 Genie Envisioner (GE):一个将机器人感知、策略学习与评估合并到单一闭环的视频生成世界模型中的统一平台(见图 1)。
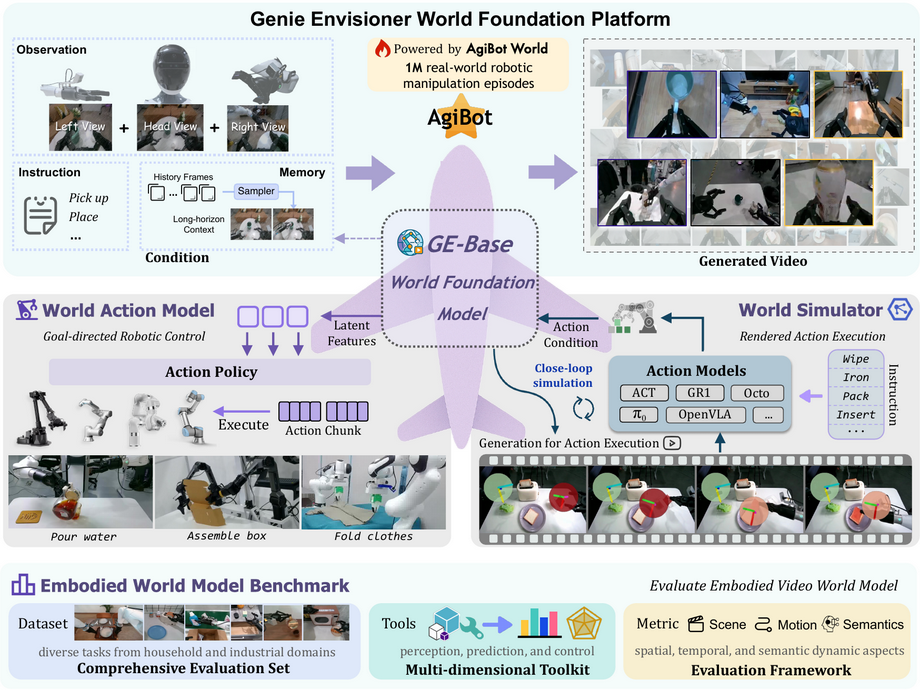
Genie Envisioner (GE):一个统一的世界基础平台,用于机器人操控,将策略学习、评测与仿真整合到单一的视频生成框架中。
在核心部分,GE-Base 是一个大规模的、可被指令条件化的视频扩散(video diffusion)模型,使用约 3,000 小时 的视频—语言对数据训练,这些数据来自 AgiBot-World-Beta 数据集(Bu 等,2025a),覆盖逾 一百万 条真实世界机器人操作 episode。它在结构化的潜在空间中捕捉真实机器人交互的空间、时间与语义动态。
在给定机器人的视觉观测条件下,GE-Base 以自回归方式生成视频片段,这些片段捕捉在高层指令驱动下 manipulation 行为随时间的演化。通过机器人领域自适应预训练,GE-Base 建立了从语言指令到具身视觉空间的映射,透过对真实交互的空间、时间与语义规律建模,捕捉了机器人操控的本质。
它通过推断潜在轨迹来实现这一点,这些轨迹同时编码机器人的感知输入与在合理动作序列下场景的预期演化。为弥合视觉表征与可执行机器人控制之间的差距,作者提出了 GE-Act:一个轻量级并行的 flow-matching 动作模型。
GE-Act 将潜在表征映射为可执行的动作轨迹,采用轻量级的flow-matching decoder,将经指令条件化的视觉潜在特征翻译为细粒度且低延迟的电机指令,从而实现从感知與指令到可执行物理动作的直接高效映射。从而在多种机体(embodiments)上以最少监督实现精确且可泛化的策略推断。
除了策略学习,仿真在实现可扩展训练、安全验证与快速迭代方面也至关重要。为支持可扩展的评估与训练,GESim 作为一个以动作为条件的神经仿真器,它利用 GE-Base 的具身视频生成能力,将其生成动态重新用于一个以动作为条件的世界模拟器。GE-Sim 通过基于视频的仿真支持闭环策略评估,其速度明显快于真实世界执行。
这就要求超越通用感知度量,评估合成行为是否既有物理根基,又与给定指令语义一致。为此平台还配备了Embodied World Model Benchmark (EWMBench) —— 一个标准化基准套件,用以衡量视觉保真度(visual fidelity)、物理一致性(physical consistency)与指令—动作对齐(instruction–action alignment)。
这些组件共同将 Genie Envisioner 打造成一个可扩展且实用的基础平台,用于指令驱动的通用具身智能(instruction-driven, general-purpose embodied intelligence)。所有代码、模型与基准将公开发布。
不同于主流的 vision–language–action (VLA) 方法(Black 等,2024;Kim 等,2024),它们依赖视觉语言模型**(VLMs)把视觉输入映射到语义语言空间并从语言中心表示学习动作策略(Abouelenin 等,2025;Bai 等,2025;Chen 等,2024),GE 则通过生成式视频建模**构建了一个以视觉为中心的空间。
该空间保留了细粒度的时空线索,使得对机器人—环境动力学的建模更为真实,并支持在单一、一致的平台内进行端到端策略学习與评估。为了全面评估 GE 在具身视频生成、策略学习与仿真方面的能力,在一组多样的真实世界机器人操控任务上做了大量实验。GE-Act 实现了低延迟端到端控制:在一块普通 GPU 上能在 200 ms 内生成 54 步 的扭矩轨迹。
它能在 in-domain 的 AgiBot G1 平台上实现精确任务执行,并以仅 1 小时 的遥操作示范,在跨机体泛化上对新系统(如 Dual Franka 与 Agilex Cobot Magic)表现出强劲能力,且超越了若干任务特定的基线(Bjorck 等,2025;Black 等,2024;Bu 等,2025b)。
GE-Act 在广泛场景与任务中证明了其有效性,包括工业应用(如基于传送带的物体搬运)以及家务任务(如烹饪、擦桌与倒水)。除了这些标准操控任务外,GE-Act 的视觉世界建模还能使其处理长时程、对记忆需求高的序列(见图 2)。

此外,GE-Sim 通过分布式集群并行化实现每小时数千条 episode 的策略 rollout 评估,从而大幅加速操控能力评估与策略训练。
EWMBench 为基于视频的世界模型提供了全面评估框架,系统地将 GE-Base 与最先进的视频生成模型进行了基准比较。结果显示 GE-Base 在机器人世界建模方面具有优越表现,并与人工评估高度一致,这凸显了其作为统一 GE 平台基础组件的作用。
综合这些贡献,Genie Envisioner 被定位为面向真实世界操控的实用且可扩展的基础设施,便于下游研究。
2. GE-Base:世界基座模型
本节介绍 GE-Base,它是 Genie-Envisioner 的核心组件。作者的目标是将通用视频生成模型的预测能力扩展到构建具身预测表征——一种统一的生成式表述,用于在任务指令条件下、并基于代理的物理具身性,预测未来机器人—环境交互。
为此,将机器人视频世界建模表述为“文本+图像→视频”的生成问题:给定一条语言指令与初始视觉观测,模型预测反映出合理且连贯机器人行为的未来视频片段。GE-Base 的一个关键设计是其稀疏记忆机制(sparse memory),它用长期历史上下文增强当前视觉输入,通过统一的视觉条件强化时序推理。
在此表述基础上,GE-Base 采用视频扩散transformer 架构,并引入机器人自适应预训练策略,将通用视频数据集的知识迁移到具身机器人领域。在真实世界的机器人操控视频生成任务上验证了 GE-Base 的有效性。实验结果表明,GE-Base 能生成与指令对齐、时间上连贯的视频序列,并在多样的操控任务与机体上具有良好泛化性。
2.1 基本结构
为了和机器人操控数据的序列特性对齐,采用自回归视频生成框架,将输出切分为若干离散视频片段(chunk),每段包含 N 帧。在每个步骤 t,世界模型 W 在三个条件下生成下一个片段 x1:N(t)x^{(t)}_{1:N}x1:N(t):初始视觉观测 x0x_0x0、语言指令 q,以及稀疏记忆 x^0:t−1x̂_{0:t-1}x^0:t−1(由先前步骤中稀疏采样的长期历史帧构成)。生成过程形式化为:
x1:N(t)=W(x^0:t−1,x0,q)x^{(t)}_{1:N} = W(x̂_{0:t-1}, x_0, q)x1:N(t)=W(x^0:t−1,x0,q)该表述使得模型能够在视觉和指令条件下逐步生成时间连贯的视频片段。通过将长期稀疏记忆纳入视觉状态(而非仅依赖最近帧),模型能有效捕获更长的时序依赖,同时在整个操控过程中保持语义对齐与视觉一致性。
为在效率与容量间取得平衡,作者采用了一个紧凑的视频生成模型作为核心架构。GE-Base 世界模型 W 以灵活性为设计目标,可与多种基于 diffusion-transformer (DiT) 的视频生成模型无缝集成,例如 LTX-Video 2B 与 COSMOS 2B。
考虑到双臂机器人系统的自我中心(egocentric)感知特点,把 W 扩展为多视角、以语言与图像为条件的生成框架,利用三路机载相机的时间同步输入:头部视角 vhv_hvh 与两个腕部视角 vl,vrv_l, v_rvl,vr。x0,x^0:t−1与xtx_0,\hat{x}_{0:t−1}与 x_tx0,x^0:t−1与xt中的每一帧,都由此三视角观测结构组成。
如图 3 所示,生成流水线首先用共享视频编码器 E 对 初始视觉观测x0x_0x0 和稀疏记忆 x^0:t−1\hat{x}_{0:t−1}x^0:t−1 的多视角观测进行编码。对每个视角,得到潜在视觉 token,记为 E(v0(i))E(v)E(v_0^{(i)})E(v)E(v0(i))E(v) 与E(vt−1(i))E(v_{t−1}^{(i)})E(vt−1(i)),其中 i∈{h,l,r}
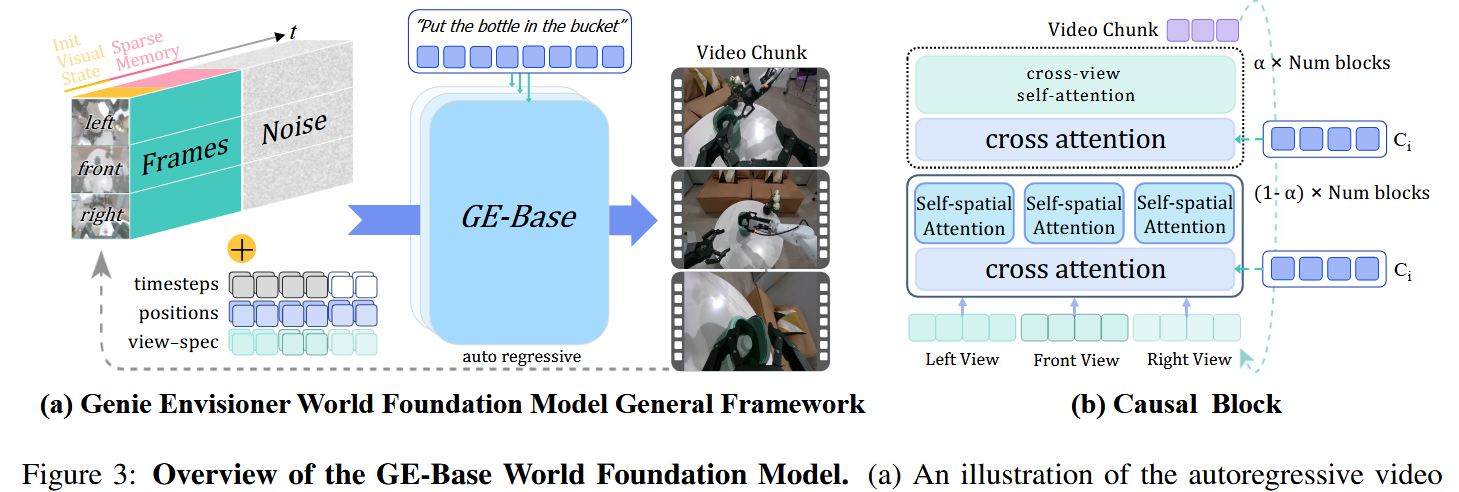
每个视角的视觉 token 序列由 x0x_0x0 与 x^0:t−1\hat{x}_{0:t−1}x^0:t−1 的 token 串接而成。对应每个视角,初始化一个独立的噪声图 z(i)z^{(i)}z(i) 来引导生成过程。为在保留时空对齐的同时区分视点特有信息,为每个 token 与噪声输入加入 2D rotary 位置嵌入嵌入epose_{pos}epos与视点可学习嵌入 eviewe_{view}eview。
把所有视角的增强 token 与噪声映射串接后,再加上时间步编码 ete_tet,并输入 DiT 主干以自回归方式生成下一个视频块。为了在多视角间实现连贯推理,作者把标准的空间自注意力(在 H,W 上)扩展为跨视角自注意力(在 N,H,W 上),其中 N 表示相机视角数量。隐状态被重塑为形状 (B,N,T,H,W,C),以支持联合的跨视角推理。
为保证计算可行性,跨视角注意力仅稀疏插入到若干 DiT block 中,剩余 block 则通过把 N 维度折叠进 batch 维(得到形状(B⋅N,T,H,W,C))来独立处理各视角。该混合注意力方案在视角一致性与计算效率之间取得了平衡。
为引入语义级任务引导,指令 q 用冻结的 T5-XXL 编码器处理,得到一组文本嵌入T(q)。文本嵌入通过 DiT 内的交叉注意力层并入视觉 token 流,使模型能把视频生成与指令语义对齐。基于该设计,世界模型 W 预测下一个视频块 x^t\hat{x}_tx^t:
x^t=W(v0(i),vt^(i),z(i))i∈(h,l,r),T(q)\hat{x}_t=W({v_0^{(i)},v_{\hat{t}}^{(i)},z^{(i)}}) i∈({h,l,r}),T(q) x^t=W(v0(i),vt^(i),z(i))i∈(h,l,r),T(q)其中 v0(i)v_0^{(i)}v0(i) 与 vt^(i)v_{\hat{t}}^{(i)}vt^(i)表示来自视角 i 的初始与历史编码 token,z(i)z^{(i)}z(i) 是对应视角的噪声图,T(q) 是编码后的指令表示。
这一统一建模范式使 W 能够联合建模空间布局、时间动力学与语义意图,从而生成连贯且可控的具身机器人行为预测。
2.2 世界模型的预训练
在为机器人操控构建基于视频的世界模型时,一个核心挑战是将通用视频生成能力适配到具身机器人领域中那种具有结构化动力学和语义的特性。为此,作者设计了一个多阶段的预训练框架,逐步将模型的时空表征与真实机器人行为的分布特征对齐。本节概述数据整理流水线以及为领域适配所采用的训练策略。
在训练过程中,会从之前的视频历史中随机采样稀疏的记忆帧作为输入,这也起到一种数据增强的作用。该设计提高了未来预测的难度并增强了模型对时间变化的鲁棒性,从而最终改善其在多样操控场景下的泛化能力。
数据整理
以 AgiBot-World-Beta(Bu 等,2025a)数据集作为预训练基础。该数据集包含约一百万条高质量的真实双臂机器人操控 episode,总计 2,967 小时,通过人类遥操作采集。数据集覆盖多种任务、物体类别和环境;每条轨迹带有自然语言指令、多视角视觉观测与结构化动作策略的标注。
为适配视频建模,从三个经校准的相机视角中提取时间同步的视频流,并确保每个视频段与其配对指令在语义上保持一致。该预处理步骤产出高质量的文本—视频对,反映连贯且可执行的操控行为。为适应各预训练阶段不同的学习目标,我们采用可变帧采样策略,在时间分辨率与训练稳定性之间进行平衡。
阶段一:Multi-Resolution Temporal Adaptation (GE-Base-MR).
第一阶段旨在弥合通用视频表征学习与机器人特定运动动力学之间的鸿沟。在 57 帧 的视频序列上预训练,序列帧率在 3 Hz 到 30 Hz 之间随机采样。每个训练样例包含 4 帧稀疏记忆帧,这些帧从此前的视频历史中随机抽取以增加时间多样性。这些片段通过预训练 VAE 编码到 8 帧 的潜在空间,在该潜在空间上加入噪声并以去噪目标进行优化。这一训练配置(称为 GE-Base-MR)让模型接触到各种运动速度与时间模式,促使其学习对采样率不变的时空表征。
在同时以视觉条件与语言指令为条件下,模型被训练将高层任务意图映射到低层视觉动力学,同时对部分观测缺失保持鲁棒。这种设计对真实世界部署至关重要,因为传感器延时、帧丢失和异步数据是常见问题。GE-Base-MR 在 AgiBot-World-Beta 数据集上端到端训练,使用 32 块 NVIDIA A100 GPU,训练时间约为 7 天。
阶段二:Low-Frequency Policy Alignment (GE-Base-LF)
为提高训练效率并更好地与下游动作建模所用的时间抽象对齐,对 GE-Base-MR 进行低帧率视频序列的微调。具体地,以固定 5 Hz 采样得到 9 帧 的片段,并提供 4 帧稀疏记忆作为时间上下文。这些序列经预训练视频编码器映射到由两帧潜变量构成的紧凑潜在空间,且该编码器参数保持冻结。
在这一阶段,仅更新视频生成相关组件(其他编码器保持冻结)。得到的模型 GE-Base-LF 被优化以在稀疏视觉采样下捕捉语义上有意义的状态转变。对生成通路(generative pathway)的训练仍然是端到端的,并在任务指令与视觉条件下进行条件化训练。该流程有效地将视频 DiT 与控制中使用的时间抽象对齐,使得能够以离散动作步长的粒度提供可靠的视频反馈。GE-Base-LF 是后续动作模型预训练的重要基础,使用 32 块 NVIDIA A100 GPU 训练约 3 天。
2.3 通过GE-Base生成机器人操控视频
使用 GE-Base 生成双臂机器人操控视频,基于 LTX-Video 2B 架构(并且还在探索其它后端架构)。这一过程采用自回归方式:每一步基于初始观测、一系列记忆帧和语言指令生成一个新的视频块。生成会迭代进行,直到指令指定的任务执行完毕,最终得到连贯无缝、精确反映完整操控过程的视频序列。
在推理时,记忆帧按固定间隔从先前视频块中均匀采样,以保证时间动力学稳定与预测一致性。作者在真实双臂操控任务上评估该流水线。如图 5 所示,GE-Base 能生成多视角视频,准确反映多样的语言指令。

结果表明模型能在多视角间保持空间一致性、保留背景与场景结构,并生成与指令语义对齐的稳定逐步执行。视频生成质量的更详细分析见基准章节(第 6 节)。
3. GE-Act: 世界动作模型
把高层世界建模和低层控制桥接起来,是将视觉-语言基础模型部署到具身机器人中的关键。作者提出 GE-Act:一个即插即用的世界动作模块,它在 GE-Base 基础上增加了一个轻量级 160M 参数 的自回归动作解码器。
GE-Act 将以多视角视觉观测与语言指令为条件的多模态潜在表征,翻译为时间结构化的动作策略,从而能够在无需显式生成视频的情况下完成指令跟随行为。该架构支持感知与控制的紧耦合,为多样环境下的实时机器人操控提供了可扩展且高效的解决方案。
3.1 基本结构
GE-Act 是一个 plug-and-play 的 world action 模块,用于扩展 GE-Base 基座模型,使其能够支持基于指令的机器人控制。在架构上,GE-Act 与 GE-Base 的视觉 backbone 并行运行,采用基于 DiT 的自回归(autoregressive)设计,将潜在的视觉表示转换为具有时间结构的动作策略。
该集成将高层感知理解与低层运动执行连接起来,支持从多视角视觉观测与语言指令平滑生成策略(policy)。如图 6 所示,GE-Act 保持与 GE-Base 的结构对齐:在 DiT block 深度上做镜像(mirroring),但采用更小的 hidden dimension 以保证计算效率。
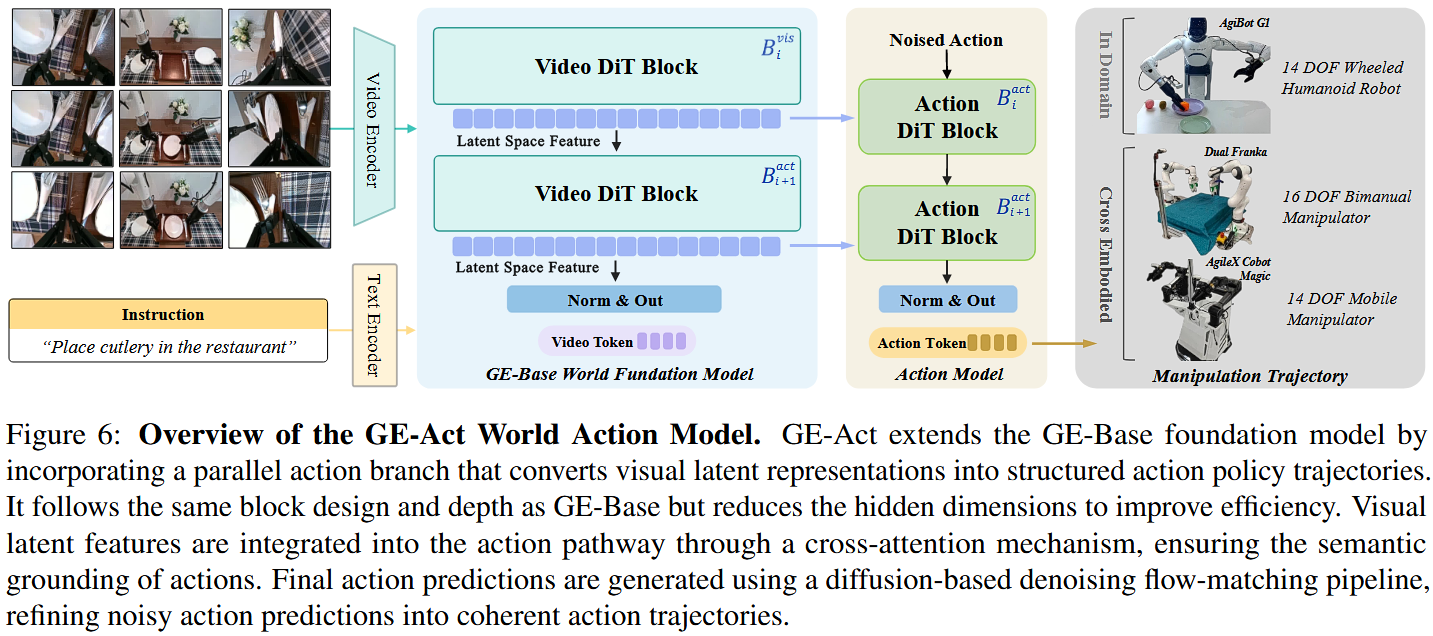
在每个时间步,基础模型处理由初始观测 x₀ 与稀疏采样的历史帧 x^t−1\hat{x}_{t-1}x^t−1 得到的 visual tokens,条件化于 instruction embeddings T(q):vi=Bivis(vin,T(q))v_i=B_i^{vis}(v_{in},T(q))vi=Bivis(vin,T(q))
其中 vinv_{in}vin 表示输入的 visual tokens,BivisB_i^{vis}Bivis 表示 GE-Base 中第 i 个 visual DiT block。
与此同时,GE-Act 的动作通路处理以噪声初始化的 action tokens zactz_{act}zact,通过对应的一组 action-specific transformer blocks BiactB_i^{act}Biact,并通过 cross-attention 将相关上下文信息(来自视觉表示)融入:ai=Biact(zact,CrossAttn(zact,vi))a_i=B_i^{act}(z_{act},CrossAttn(z_{act},v_i))ai=Biact(zact,CrossAttn(zact,vi)),其中 aia_iai 表示输出的动作表示。
该模块化架构使 GE-Act 能完全在潜在特征空间中运行,从而在部署时可以进行控制推理而无需显式生成视频帧。
3.2 训练过程
采用一个受标准 VLA 操作框架启发的两阶段训练范式:先做与任务无关的 pretraining,再进行任务特定的 adaptation(微调)。
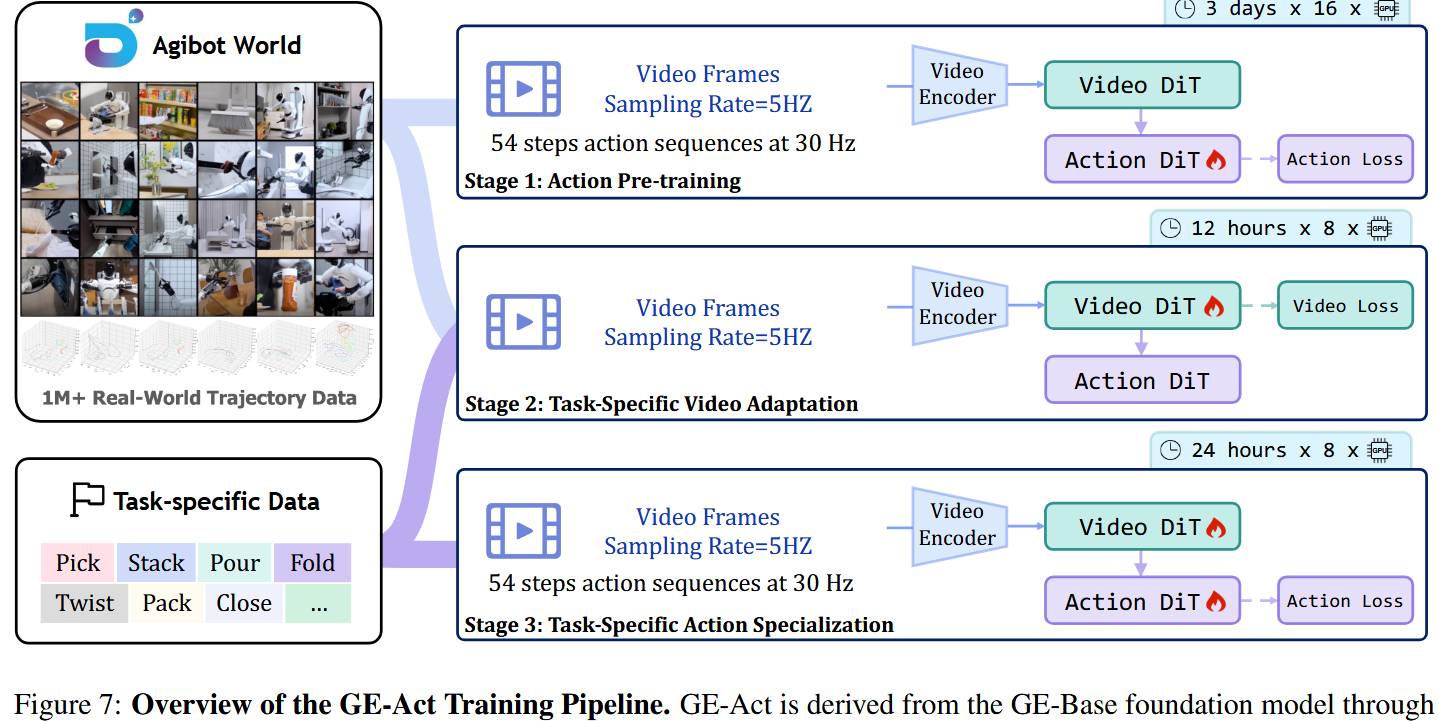
预训练
在动作模型的预训练阶段,作者利用 AgiBot-World-Beta 数据集,将预训练的视觉-语言表示专门化为动作策略学习所需的表征。
world model W 用 GE-Base-LF 的固定参数初始化以保留其时空与语义先验,只有动作解码模块的参数会被更新。为降低计算开销,训练时禁用视频生成。取而代之的是使用低帧率的视觉记忆序列(由四帧以 5 Hz 采样组成)作为条件输入,而模型要预测高频率的动作序列(共 54 步,30 Hz)。
训练仅以真实的动作轨迹为监督,使模型能够在预训练的潜在空间中学习与控制相关的动力学。该过程大约在一台包含十六块 NVIDIA A100 GPU 的集群上耗时约三天完成。
特定任务微调
为使预训练模型适配下游机器人任务,作者采用了两阶段微调流水线:video adaptation 与 action specialization,目标是在通用视觉-语言表示与任务特定执行需求之间建立对齐。
在 video adaptation 阶段,仅更新 world model W 的视频生成组件,其余参数保持冻结。微调在一个复合数据集上进行:包含完整的 AgiBot-World 语料以及任务特定子集,后者的权重提高了 10 倍,以增强任务对齐性而不牺牲泛化能力。采样协议与 GE-Base-LF 使用的一致,以保持时间连贯性。该阶段在 8 块 NVIDIA A100 GPU 上大约用时 12 小时完成。
在随后的 action specialization 阶段,对整个模型(包括 GE-Base backbone 与动作模块)仅在任务特定数据上进行微调,以捕捉细粒度的控制动力学。该过程沿用了动作预训练的设置并采用相同采样策略,以确保时间与控制层面的连贯性。该阶段在 8 块 NVIDIA A100 GPU 上训练大约耗时 36 小时。
3.3 异步推理
为弥合视觉处理与运动控制之间的时间差,作者引入了“慢—快异步推理(Slow-Fast Asynchronous Inference)”模式:该模式通过利用两个关键层面的非对称性(去噪复杂度与目标频率)来优化计算效率。
非对称去噪策略(Asymmetric Denoising Strategy):推理流水线根据各模态的不同需求分配计算资源。视频 DiT 在每次推理通路中只执行一次 flow-matching 去噪步骤以生成视觉潜在 token,然后将这些 token 缓存并在整个动作生成阶段复用。
动作模型由于需要更高的时间分辨率以实现精确控制,会执行五个去噪步骤,且所有这些步骤都以相同的已缓存视觉表示为条件。这一方法保证在安装于真实机器人上的板载 NVIDIA RTX 4090 GPU 上,完成 54 个动作步的前向传递仅需约 200 毫秒,从而实现实时推理能力。
除了优化去噪流程外,还利用视觉感知与运动控制之间固有的频率不匹配。视频 DiT 的运行频率为 5 Hz,而动作模型以 30 Hz 运作,二者的时间分辨率比为 1:6。这种解耦允许在进行稀疏的视频预测的同时,执行密集的动作生成。
通过只表示选定的未来视频帧,显著降低了视频潜在空间的维度,从而无需处理高频的视觉序列。该设计使视频 DiT 能在压缩的潜在空间中高效运行,同时动作模型保留实现精确与响应式控制所需的完整时间分辨率。这种双层优化在训练与部署两端都带来了显著优势。
在训练期间,通过用随机高斯噪声初始化隐藏状态来规避视频加载与解码造成的典型瓶颈,从而优化大规模视频模型的训练过程。在部署时,单步视频去噪与缩减潜在维度的结合,使得在机器人硬件上高效地进行实时运行成为可能,从而便于视频生成与动作执行的无缝集成。
3.4 通过GE-ACT在Agibot G1上进行动作规划
为严谨评估该方法在真实机器人操控中的效果,在五项具有代表性的任务上进行了广泛评测;每一项任务都用于测试控制精度、任务复杂度和泛化能力的不同侧面。
- 制作三明治:顺序组装面包、培根、生菜和面包——用于测试多物体协调、空间推理与步骤化任务执行能力;
- 倒一杯茶:包括抓取、精确倾倒和重新放置茶壶——凸显在流体操作中对精细运动控制与灵活性的需求;
- 擦桌子:要求机器人抓取擦布并执行一致的擦拭动作以去除表面污渍,用于评估轨迹稳定性与顺应性受力应用;
- 用微波炉加热食物:操作微波炉门、放入碗并操作按钮——挑战系统处理带关节的对象与多阶段接口操作的能力;
- 打包洗衣粉:从传送带上抓取移动的洗衣粉袋并放入箱子——用于评估动态感知、运动跟踪和工业级操控能力。
这些任务跨家庭与工业场景,提供了一个用于评估基于指令的控制、时间定位(temporal grounding)和闭环执行能力的综合基准。
采用两项评估指标:逐步成功率(Step-wise Success Rate,SR)与端到端成功率(End-to-End Success Rate,E2E)。SR 指标对每个子步骤独立评估,并将成功完成的子步骤数量除以总子步骤数得到总体成功率,从而提供对部分任务完成情况的细粒度洞察。
相较之下,E2E 指标仅评估整项任务的最终结果,它允许在执行过程中对单个子步骤进行多次尝试,这更贴近现实部署情形(机器人可从中间失误中恢复)。
在 AgiBot G1 平台上的性能比较。将 GE-Act 与两款领先的基于 VLA 的机器人操控模型进行基准比较:UniVLA(Bu 等,2025b,LIBERO 基准上的最先进方法)与 GR00T N1(Bjorck 等,2025,一款大规模 VLA 基座模型)。所有模型均在 AgiBot G1 平台上按相同任务协议评估,并使用相同的任务特定遥控示范进行微调。
如图 8 所示,GE-Act 在一系列真实日常操控任务上,在 SR 和 E2E 两项指标上均持续优于基线模型。
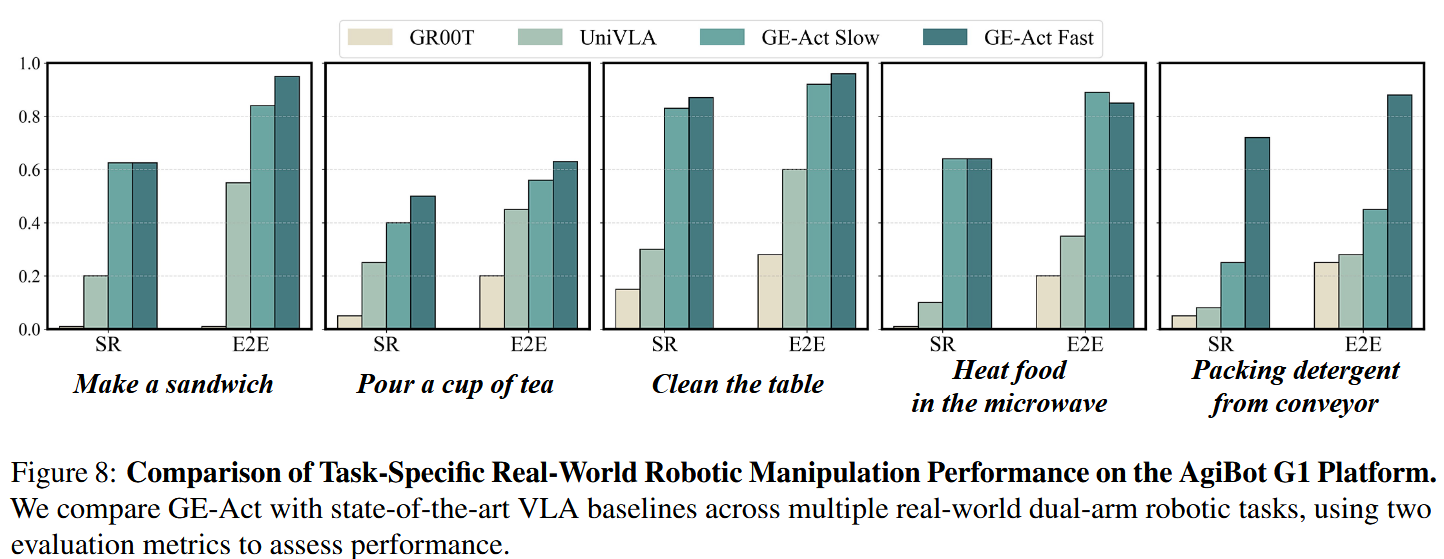
这种性能提升归因于预训练的 GE-Base world 基座模型,它提供了强大的时空先验与精确的视觉—语言对齐,从而使得向多样的下游操控场景高效且鲁棒地适配成为可能。
通过两种运行模式进一步验证该设计:标准模式(同步视觉与动作更新)与快速模式(利用时间抽象以提高效率)。如图 8 所示,快速模式在多种操控任务中取得了相当或更优的表现,尤其在延迟敏感的场景(如动态目标跟踪与反应式抓取)中表现出色。
值得注意的是,在诸如“从传送带打包洗衣粉”这样的短时任务(需要迅速生成动作)上,快速模式明显优于标准模式。定性结果见图 9,展示了 GE-Act 在真实场景中直接根据自然语言指令精准且可靠地执行复杂操控任务的能力。

4. 用Genie Envisioner进行跨机体泛化
除了在同域的 AgiBot G1 平台上验证 GE 外,作者还评估 GE 在不同身体形态(embodiments)间的泛化能力——这是开发通用机器人基础模型的关键一步。
具体地,在操控研究中常用的两个平台上评估 GE:Franka 机械臂与 Agilex Cobot Magic 系统。为保持与作者的双臂框架一致,这两种平台都作了相应配置。
由于不同身体形态的设计与动作空间存在差异,直接将预训练的 GE 模型部署到新平台上并不可行。为了解决这一点,采用少样本(few-shot)适配协议:为每项任务收集少量高质量的遥操作示范。这些示范用于微调 GE 与 GE-Act 模型,使其能有效地转移并与新平台对齐。
除了在 AgiBot G1 上的标准任务外,还在复杂的可变形物体操作任务上评估 GE,例如“折叠布料”和“折箱子”,这些任务因其现实相关性与物理挑战而被选中。该框架为评估 GE 在不同机器人平台上的可迁移性、鲁棒性和控制精度提供了全面的评价手段。
4.1 Few-shot 适配
为使 GE-Act 在新机器人形态上实现少样本适配,采用一个两阶段的任务特定微调策略(见图 7 最后的两行示意):
- 第一阶段:通过用少量新收集的、带指令的视频示范微调 video DiT 模块,将视觉生成组件适配到新形态域。在此过程中,CLIP(Radford 等,2021)和视频编码器保持冻结,以保留预训练的语义与感知先验。此步骤使模型能合成与新平台视觉特征一致、逼真的形态相关操作视频。
- 第二阶段:使用任务特定的遥操作轨迹从头训练一个新的 action DiT 模块。由于形态结构与动作空间语义存在根本差异,预训练的动作解码器不再复用。相反,保留 GE-Base 的视觉骨干,并学习一个针对新平台的控制动力学与接口量身定制的新动作 head。
该两阶段适配流水线促进了感知与运动能力的有效迁移,使得在最小的数据监督下也能实现高保真视频生成与基于指令的精确策略推断。
4.2 适配到Agilex Cobot Magic
在 Agilex Cobot Magic 平台上评估 GE 的泛化能力,使用两项复杂任务:“折箱子(box folding)”和“折布料(cloth folding)”。对每个任务,使用基于 Aloha 的遥操作系统(Fu 等,2024)收集了 250 条高质量遥控示范——约 1 小时的数据。
这些示范作为适配数据集,用于对 GE-Base 和 GE-Act 进行微调。如图 11 所示,把 GE-Act 与三种最先进的 VLA 模型做了比较:GR00T N1(Bjorck 等,2025)、π0(Black 等,2024)和 UniVLA(Bu 等,2025b)。所有模型均在相同的数据集上对这些任务进行了微调。
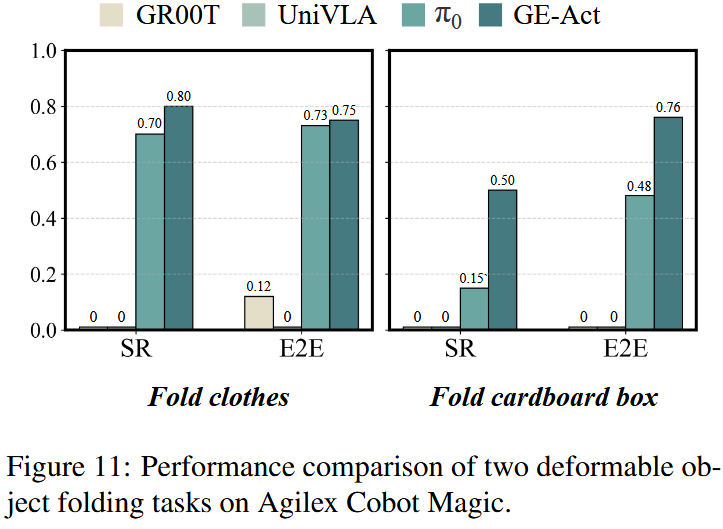
实验结果清楚地表明 GE-Act 优于这三种模型。尽管 UniVLA 与 GR00T N1 在诸如拾取放置等简单任务上表现良好,但在复杂与细粒度任务中,由于定位与执行精度不足,它们均无法完成任务,成功率为 0%。只有在人工干预下,UniVLA 才能完成少数步骤。
比之下,以在可变形物体操控上表现出色著称的 π0 在这些任务中优于 UniVLA 与 GR00T N1。然而,在复杂且细粒度的可变形物体操控任务中,GE-Act 显著优于 π0。
这种性能提升主要归功于 GE-Base 基座模型:通过在大规模真实世界数据上的预训练,GE-Base 使 GE-Act 在任务适配和胚体泛化方面表现更好。因此,GE-Act 在多种机器人平台与操控场景中都能提供更优的性能。如图 10 所示,适配后的 GE-Act 模型能够为折布与折箱任务生成连贯的、基于指令的多视角视频。

这些视频以高保真度准确呈现了刚性以及非刚性对象的动力学变化。结果展示了不同摄像头视角间的高度一致性,并证明了 GE-Act 在处理复杂物体变形方面的鲁棒性。此外,如图 12 所示,展示了使用适配后的 GE-Act 模型在真实环境下执行折布与折箱任务的实况。

这些结果确认了 GE-Act 在新机体上以高精度和高可靠性完成任务的能力,进一步强化了 GE-Base 向新胚体有效迁移的能力。该实验巩固了 GE-Base 作为可扩展、可适配的真实世界体现智能(embodied intelligence)基础模型的潜力。
4.3 适配到双臂Franka
进一步在 Dual Franka 平台上评估 GE 的跨胚体泛化能力:在折布任务上,用 250 条遥操作轨迹(约一小时)对 GE-Act 进行胚体与任务特定的适配。
由于缺少专用的遥操作接口,在 Dual Franka 上的数据采集使用了更简单的空间鼠标(space-mouse)控制系统完成。与在 Agilex Cobot 上的评估保持一致,将 GR00T N1、π0 与 UniVLA 作为对照基线,并在同样的 250 条示范数据集上对每个模型做微调。
图 13 展示了 Dual Franka 平台上的折布任务,其中既包含 GE-Base 生成的未来场景视频预测,也展示了 GE-Act 在实机上执行的操控结果。结果表明 GE 能有效建模与任务相关的视觉动力学,并能推广到新机体以实现精确操控。

如图 14 所示,GE-Act 在 Dual Franka 平台的实机执行中持续优于那些任务特定的基线模型,这与在 Agilex Cobot Magic 上观察到的趋势相一致。值得注意的是,尽管 π0 与 GR00T N1 在 Franka 形态上曾用大规模数据进行广泛训练,GE-Act 仅用一小时的适配数据便取得了更好的性能。
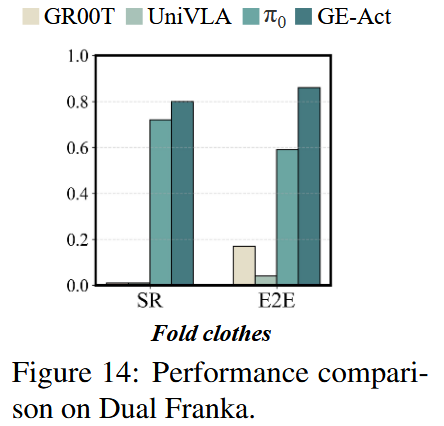
5. GE-sim:世界仿真器
为了支持与真实世界对齐的评估与闭环控制,作者开发了一个基于视频的世界神经模拟器,该模拟器能在机器人动作的条件下生成时间连贯的视觉预测。
该神经模拟器允许体现式策略模型在与物理解耦的一致视觉环境中交互,并作为一个统一的试验台,用于跨任务的策略学习与泛化评估。通过将 GE-Base 基座模型扩展为带动作条件的世界模拟器 GE-Sim 来实现这一能力。在该形式下,动作轨迹作为主要控制信号,驱动随时间变化的视频合成。
为促进生成帧之间的视觉一致性,引入了一张参考图像(由冻结的 CLIP 图像编码器编码)作为轻量的风格锚点。该图像通过 cross-attention 注入到每个 DiT block 中,补充保留的视觉观测,从而在整个序列中提供空间基准。
这一转换中的根本挑战在于调和低级控制命令与预训练世界模型所编码的高级潜在表示之间的语义差异。为了解决此问题(见图 15),引入了一种层次化的动作条件化机制,将结构化的动作表示直接整合到 GE-Base 的 token 空间中。
该架构在保留模型预训练时空语义的同时,使其能与各种策略模型无缝对接,从而促成闭环的、以动作为条件的神经模拟,并在多种机器人任务上实现稳健的泛化。
5.1 分层的动作雕件机制
为确保能兼容多种动作策略模型,采用一种通用的机器人轨迹表示方法。对于单臂,每个控制步被编码为 7 维向量
x,y,z,roll,pitch,yaw,o其中 (x, y, z) 表示末端执行器位置,(roll, pitch, yaw) 表示其姿态(滚转、俯仰、偏航),o 表示夹爪开启量(gripper openness)。
在双臂设置中,每步的控制信号由两个单臂控制向量拼接而成,成为一个 14 维向量。在 K 步的时间窗内,完整的动作轨迹记作 A∈RK×14A∈R^{K×14}A∈RK×14,为将这种低层控制信号与 GE-Base 基座模型的基于 token 的输入接口连接起来,作者提出了一种层次化的动作条件化机制,该机制同时包含空间(spatial)与时间(temporal)两个分量。
Pose2Image Conditioning(位姿到图像条件化):在每个时间步 i,位姿向量 ai=[xi,yi,zi,ri,pi,yi,oi]a_i=[x_i,y_i,z_i,r_i,p_i,y_i,o_i]ai=[xi,yi,zi,ri,pi,yi,oi] 编码空间位置、姿态与夹爪状态。位置 (xi,yi,zi)(x_i,y_i,z_i)(xi,yi,zi) 使用已标定的相机内参与外参投影为像素坐标。姿态 (ri,pi,yi)(r_i,p_i,y_i)(ri,pi,yi) 被转换为旋转矩阵,其正交轴(orthonormal axes)也被投影到图像平面以指示方向性。
夹爪开合 oio_ioi 在单位圆上渲染,采用阴影强度来反映状态——越开越亮、越闭越暗。左右机械臂用不同颜色编码以区别。该过程得到与视觉场景空间对齐的位姿图像 PiP_iPi。
每个 PiP_iPi 与对应的采样历史帧 IiI_iIi 配对,并用共享的视频编码器 E 编码;两者的潜在特征通过逐元素相加融合:vi=E(Ii)+E(Pi)v_i=E(I_i)+E(P_i)vi=E(Ii)+E(Pi).得到的融合 token viv_ivi 同时捕捉上下文视觉语义与显式位姿信息,并被插入到视觉 token 流中供下游处理。
Motion Vector Conditioning(运动增量条件化):为捕捉时间动态,我们计算连续末端位姿之间的运动增量(motion deltas)。记 ai=[pi,ri]a_i=[p_i,r_i]ai=[pi,ri] 为时间步 i 的 6 自由度位姿,其中 pi∈R3p_i∈R^3pi∈R3 为位置,ri∈R3r_i∈R^3ri∈R3 为姿态。增量定义为:Δai=ai−ai−1=[Δpi,Δri]Δa_i=a_i−a_{i−1}=[Δp_i,Δr_i]Δai=ai−ai−1=[Δpi,Δri],它同时编码位置和姿态的变化。
这些增量通过一个可学习编码器编码为运动 token,与参考图像的风格 token 串联后,通过 cross-attention 注入到每个 DiT block 中。这种具时序感知的表示为 GE-Sim 中的以动作为条件的视频生成提供了连贯的运动先验。
5.2 训练进程
为保证用于动作条件化生成的高保真视频模拟,GE-Sim 以高时间分辨率的预训练模型 GE-Base-MR 进行初始化,该模型能对机器人动力学做细粒度建模。随后模型在完整的 AgiBot-World-Beta 数据集上训练,使用真实动作轨迹作为视频生成的条件输入。
为提高泛化性与鲁棒性,训练语料扩充了多样的失败案例——包括错误执行、不完整行为与次优控制轨迹,这些样本来自人工遥操作和真实机器人的部署数据。在此阶段,VAE 和 CLIP 编码器保持冻结以保留预训练的语义与空间先验,其余参数通过作用于预测视频表示的 flow-matching 损失进行优化。
为评估动作条件化视频生成的精确度,基于真实控制序列可视化了 GE-Sim 的模拟输出。如图 16 所示,每个示例展示了当前观测帧、在其上叠加的下一步动作的投影目标位置,以及由模拟器合成的对应预测帧。

跨任务与视角,生成的末端执行器运动都与动作输入的空间意图保持一致,证明 GE-Sim 能忠实且精确地将低级控制命令转化为连贯的视觉预测。该结果进一步验证了 GE-Sim 作为面向机器人操控的高保真、动作对齐(action-aligned)视频世界模拟器的可靠性。
5.4 闭环仿真
为支持任意策略模型的闭环评估,GE-Sim 被用作基于视频的世界模拟器。给定语言指令与初始视觉观测,策略模型首先以此为输入并输出一个动作轨迹。GE-Sim 随后以初始观测与策略输出的动作序列为条件,生成一个模拟该动作结果的视频片段。该生成的视频连同原始指令一并反馈给策略模型,以产生下一步动作。
该迭代过程将持续直至指令完成,从而在一致且可控的视觉环境中实现策略模型的闭环仿真与与真实世界对齐的评估。除了策略评估外,GE-Sim 还可作为多用途的数据引擎:通过在不同初始视觉环境下执行相同动作轨迹,它能生成反映多样上下文的多种操作序列。
这个以真实数据为基础的视频世界模拟器为传统物理模拟器提供了一个有吸引力的替代方案:它在实现高视觉保真的同时显著降低了部署成本。关键在于,它实现了可扩展且灵活的仿真,而无需人工建模环境。
因此,GE-Sim 为一类新型的通用、真实感强且低成本的世界模型奠定了基础,这类模型在体现式智能中桥接了学习与评估两端。
6. EWMBench: 具身世界模型基准
一个有效的评估框架是科学进步的导航工具——它建立标准化的评判准则,并促进方法之间有意义的比较。在机器人世界建模的情境下,系统地评估一个模型是否忠实地捕捉了具身环境的结构、动力学与语义,对于推动该领域发展至关重要。
为此,作者提出了具身世界模型基准 EWMBench:一个综合评估套件,旨在衡量基于视频的世界模型在真实机器人操控中既有的表征保真性与实际效用。与那些侧重视觉保真、语言对齐或人类偏好的通用视频生成基准不同,机器人操控视频引入了更严格的结构约束。
在该领域中,背景布局、物体配置与具身结构(例如机器人形态)应保持不变,只有机器人的位姿与交互应根据指令发生变化。EWMBench 针对这些领域特性设计,提供面向任务的指标来评估视觉场景一致性、运动正确性、语义对齐度与多样性,从而能更真实且实用地评价面向操控的世界模型。
为支持这些指标,EWMBench 包含了高质量的真实世界基准数据集和一套开源评测工具,从而建立一个用于严格评估操控型视频世界模型能力的标准化框架。
6.1 基准数据集
该基准数据集从 AgiBot-World-Beta 测试集中精心挑选,包含跨家庭与工业领域的 10 个代表性任务。这些任务具有明确的操作目标和强烈的顺序依赖性,要求对可供性(affordances)与动作次序进行程序化推理。为确保公平评估,所有所选任务都与 1M 规模的预训练阶段使用的任务不重合(互不相交)。
每个任务被分解为 4–10 个原子子动作,每个子动作都配有步骤级的文字说明,从而实现视频片段、动作标签与语言描述之间的细粒度对齐。对每个任务,均匀采样 100 个视频实例来构建平衡且全面的评估集。为在每个任务内促进多样性,作者实现了基于空间变化的轨迹选择策略。
具体地,双臂末端执行器轨迹被提取并体素化为 3D 网格。使用 3D 交并比(IoU)计算成对相似度矩阵,随后采用贪心算法迭代选择重叠最小的轨迹。该方法确保了运动模式的广泛覆盖并最小化了每个任务评估集中冗余样本的存在。
6.2 评估方法
作者建立了一个统一的评估框架,用以衡量基于视频的世界模型在多大程度上准确捕捉机器人操控的空间、时间与语义动力学。
场景一致性。为了评估生成视频的结构性与视觉连贯性,我们引入了一个场景一致性度量,用于评估视觉外观、环境布局与视点随时间的稳定性。具体来说,提出了在相邻帧与初始帧上计算的补丁级(patch-level)特征相似度度量。
首先在机器人操控数据集上微调一个强大的视觉编码器 DINOv2(Oquab 等,2023),以将其表征空间对齐到具身(embodied)领域。对每帧,用该编码器提取补丁级嵌入;然后在帧之间对应补丁上计算余弦相似度,以量化时间一致性。较高的相似度得分表示在整个视频序列中对场景结构与相机视角的保持更好,表明更强的时空保真性。
动作轨迹质量。为评估对指令执行所得到的动作轨迹质量,为每条指令人工标注一条参考轨迹作为地面真值(GT)。对每个生成视频,使用训练好的末端执行器(EEF)检测器在帧间定位夹爪并重构轨迹。每条指令生成三个视频样本并提取对应轨迹。
空间对齐(SA)用对称 Hausdorff 距离(symH)来衡量——它测量生成轨迹 P 与地面真值 G 之间的最大点对点偏差。为使得更高分表示更好对齐,报告该值的倒数:SAscore=1dsymH(G,P)+εSAscore=\frac{1}{d_{symH}(G,P)+ε}SAscore=dsymH(G,P)+ε1.
为了考虑生成的随机性,选取 symH 最小(即与 GT 最接近)的那条轨迹用于进一步评估。随后用归一化动态时间规整(NDTW)评估时间对齐(TA),NDTW 同时捕获生成轨迹与真值在序列与时序上的一致性。为得到与质量正相关的分数,报告 NDTW 距离的倒数:TAscore=1dNDTW(G,P)+εTAscore=\frac{1}{d_{NDTW}(G,P)+ε}TAscore=dNDTW(G,P)+ε1
此外引入动态一致性(DYN)指标,通过比较预测轨迹与地面真值的速度与加速度谱,来评估运动动力学的真实性。具体而言,我们在相应的时间序列上计算 Wasserstein 距离 W(⋅),以捕获分布性的对齐而不要求严格的时间对应。
为了考虑运动幅度差异并在低动力学情形下防止不稳定性,用幅度感知比率对每个分量进行归一化。最终得分定义为:
这种多层次评估为空间、时间与动力学保真性提供了一个全面的测量。
运动语义指标。从两个角度评估运动语义:语义一致性与行为多样性。语义一致性衡量生成的操控行为是否与目标指令对齐;多样性衡量模型产生多样但有效轨迹的能力。在语义一致性方面,采用基于视觉语言模型 Qwen2.5-VL-7B-Instruct(Bai 等,2025)的多粒度评估框架:
- 全局级对齐:VLM 为每个生成视频生成一个简洁摘要式字幕,然后用 BLEU 分数将其与原始任务目标指令进行比较,以评估视频与预期任务语义的整体对齐度。
- 关键步骤一致性:为评估重要子任务是否被正确执行,VLM为生成视频与地面真值视频分别生成逐步描述。通过在对应步骤间计算基于 CLIP 的相似度来衡量一致性。
- 逻辑正确性:为识别违反物理或常识约束的情形,我们先用 GPT生成一套典型逻辑错误的分类(例如虚构动作、物体消失或物理上不可能的运动)。然后用基于视频的 VLM 来检测这些预定义错误在生成视频中的出现。被检测到的违规会被显式惩罚,以鼓励模型生成语义准确且物理上连贯的操控行为。
为评估模型生成多样输出的能力,用基于 CLIP 的全局视频嵌入来度量语义多样性。具体方法是计算在相同指令条件下生成视频之间的成对 CLIP 相似度,然后将多样性得分定义为 1−CLIP 相似度。得分越高表示语义变异性越大,反映模型跳出确定性执行的泛化能力。
6.3 世界模型评估
为全面评估基于视频的世界模型在机器人操控中的有效性,建立了一个综合评估框架,称为“evaluation colosseum”,以便在不同模型架构之间进行直接且可比较的对照分析。
在该框架下,对七种最先进的视频生成模型进行了基准测试,包含 Open-Sora(Zheng 等,2024)、Kling(快手,2025)、Hailuo(MiniMax,2024)、LTX-Video(HaCohen 等,2024)以及面向场景的 COSMOS(Agarwal 等,2025)等。
所有模型均在一个标准化的“文本+图像→视频生成”范式下评估:自然语言指令与头视角(head-view)视觉观测作为条件来合成视频。值得注意的是,GE-Base 建立在 LTX-Video 架构之上,使其可以专注于领域特定任务并利用针对控制的精调能力。
如图 17 所示,GE-Base 在多项评测维度上持续优于基线,尤以时间对齐(temporal alignment)与动态一致性(dynamic consistency)表现突出——这两项是生成动作合理且时间稳定的机器人行为的核心指标。虽然在运动语义(motion semantics)上的表现与通用视频生成模型相当,GE-Base 在控制感知的生成保真度方面表现更强,从而提供更精确可靠的任务执行。
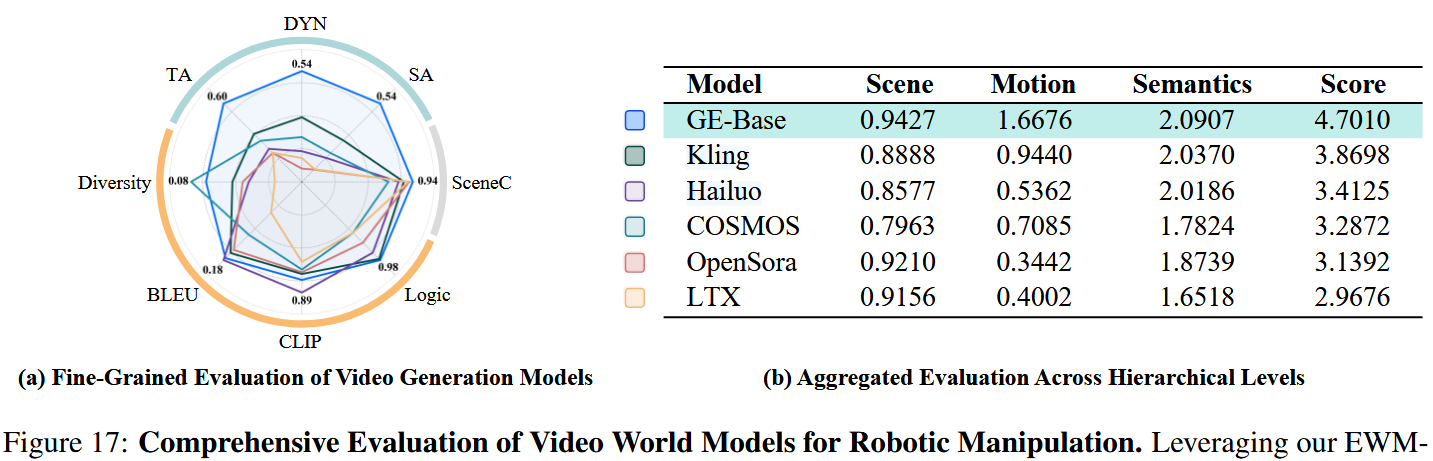
相比之下,Kling(快手,2025)在整体表现上稳健,尤其在一般视频生成任务的鲁棒性方面表现良好,但它缺乏应对细粒度控制所需的专门理解,因此在更复杂的机器人操控任务上性能受限。
Hailuo(MiniMax,2024)尽管在零样本具身场景下表现不错,但常生成卡通风格的输出,牺牲了视觉真实感,从而限制了其在真实机器人操控中的适用性。
COSMOS(Agarwal 等,2025)与 LTX-Video(HaCohen 等,2024)在以人手为中心的任务上有效,但在向机器人上下文迁移其语义理解时遇到困难,经常产生不一致的任务执行。
显著地,LTX-Video 在动作序列中会出现突发的场景跳变并倾向生成静止状态,而 COSMOS 则难以维持一致的视点与相机控制。最后,OpenSora(Zheng 等,2024)对任务场景与动作语义有部分理解,但经常出现机械臂抖动且在较复杂任务中生成静态视频。
这些结果凸显了 GE-Base 在将高层语义理解与低层控制执行衔接方面的优势。其在时间对齐、动态一致性与任务适配上的优越表现使 GE-Base 成为面向真实机器人操控的领先模型。
6.4 仿真评估
除了基于指令的评估之外,还在动作条件化情形下评估了视频式模拟器的保真性与可靠性。在给定真实动作轨迹的条件下,模拟器仅依据这些控制序列生成视觉预测。在所提的 EWMBench 框架(表 1)下,GE-Sim 在空间配置、轨迹执行与语义一致性方面持续达到高对齐度。
在固定动作输入下观察到的低视觉多样性是一种理想属性,表明动作到视频的对应关系精确且与控制动力学高度一致。这些结果表明,除效率、低成本与跨环境泛化能力外,视频式模拟器还为动作条件化评估提供了一个可靠且语义一致的平台,适用于机器人操控。
6.5 度量人类一致性
为验证所提 EWMBench 的可靠性与任务相关性,将其与人类偏好评分以及通用视频基准 VBench 进行了对比分析。对四个代表性模型(GE-Base、Kling-1.6、Hailuo I2V-01-live 与 OpenSora-2.0)生成的视频收集了人工标注,采用排序协议(annotators 给出基于感知总体质量的序数评分)。
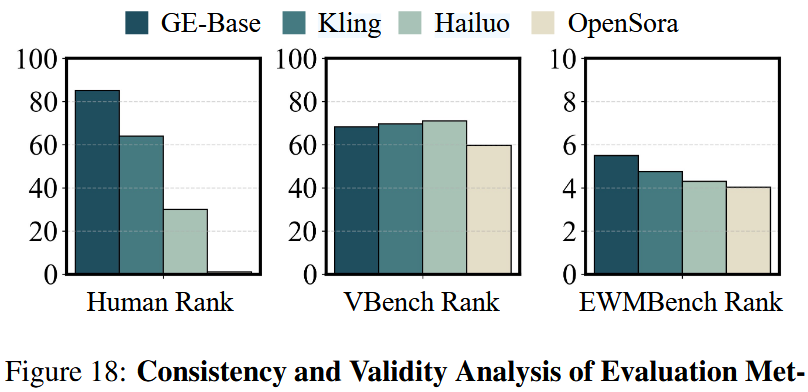
评分在标注者与样本之间进行了汇总,并进行了多轮复审以确保标注一致性。如图 18 所示,实证结果表明 EWMBench 的排序与人类判断高度一致,能有效捕捉时间对齐、语义保真与视觉连贯等维度。
相比之下,VBench 在需要具身一致性与目标条件推理的场景中表现出错位(与人类判断不一致)。这些结果证实 EWMBench 在机器人操控领域能提供更忠实、以任务为依据的评估。
7. 限制
在本文中,作者对面向真实机器人操控的世界模型进行了系统研究,覆盖视觉—运动表示、策略学习与具身评估等核心挑战。尽管 Genie Envisioner 框架为可扩展且具泛化能力的机器人智能奠定了基础,但仍存在若干局限:
- 数据覆盖与来源多样性。
尽管进行了跨机体迁移实验,但训练完全依赖 AgiBot-World-Beta——这是规模大但限于单平台的真实语料。并未使用互联网级或基于仿真的数据源,这限制了预训练期间遇到的胚体类型、传感器模态与场景配置的多样性。虽然 Genie Envisioner 通过少样本适配显示出良好泛化潜力,但其在异构数据源与低资源域上的鲁棒性仍未充分探索。后续将重要地引入大规模仿真或 Web 源示范以扩展迁移能力。 - 机体范围与灵巧度。
本研究限定于上半身桌面操控、使用并夹(parallel-jaw)夹爪。更复杂的胚体场景(例如灵巧手协调与全身运动)尚未涉及。这些能力对通用机器人至关重要,未来应把它们整合到 Genie Envisioner 中,以支持细粒度、多接触交互与全身行为。 - 评估方法
尽管 EWMBench 对视觉保真、动作一致性与语言对齐提供了结构化评估,但仍依赖代理指标与部分人工验证。尤其在多样化失败模式与语义含糊的情况下,实现完全自动且可靠的任务成功评估仍是开放挑战。构建与人类判断高度一致且可扩展的评估协议对稳健基准测试与真实部署至关重要。
Genie Envisioner 虽尚非完整解,但代表了迈向 Genie(具身 AI 系统,具有 AGI 级操控潜力)的一步有意义进展。