使用 DrissionPage——实现同花顺股票数据自动化爬虫
目录
引言
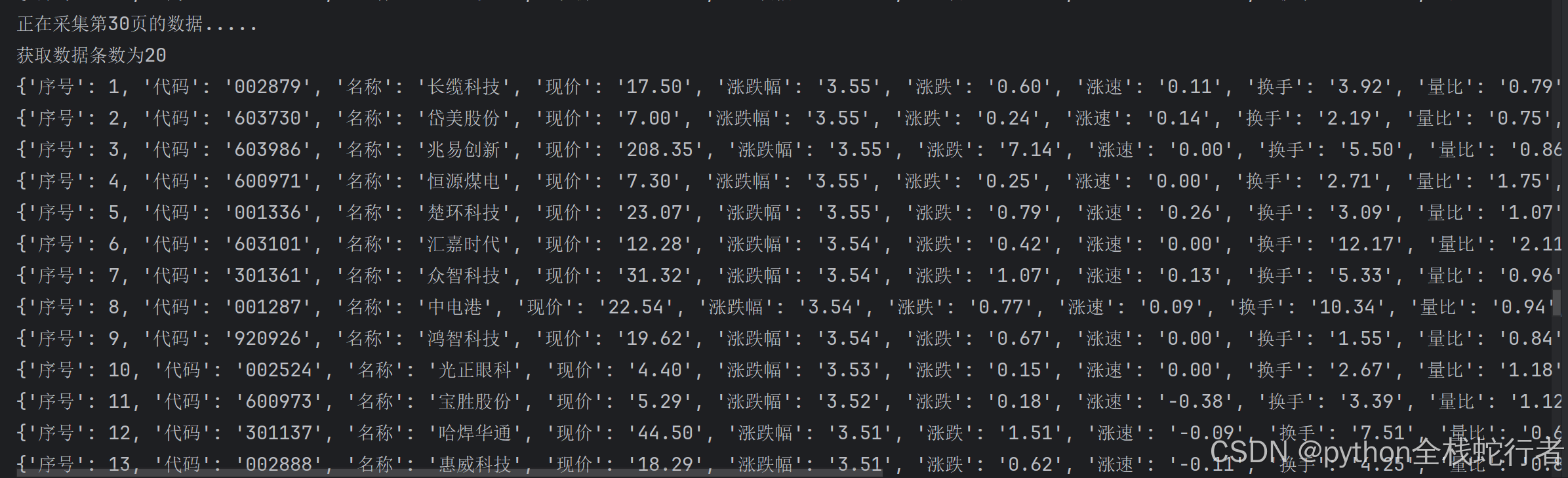
数据展示
项目目标
需求分析
实现步骤
步骤1:环境准备和库导入
步骤2:初始化浏览器并访问目标网站
步骤3:创建CSV文件并设置表头
步骤4:分页爬取数据
步骤5:定位和提取股票数据
步骤6:解析单个股票数据
步骤7:提取具体字段数据
步骤8:数据保存和输出
步骤9:页面导航和延时控制
完整代码
代码详细讲解
DrissionPage 的优势
关键技术点解析
数据处理流程
字段含义说明
应用场景与价值
法律和道德声明
总结
引言
在当今信息爆炸的数字经济时代,数据已经成为决策的核心要素,特别是在瞬息万变的股票市场中。传统的手工收集和分析股票数据方式已经无法满足现代投资者的需求。无论是个人投资者还是专业机构,都需要快速、准确地获取大量市场数据,以便做出明智的投资决策。正是在这样的背景下,网络爬虫技术应运而生,成为金融数据分析领域不可或缺的工具。
网络爬虫技术能够自动化地从互联网上收集数据,大大提高了数据获取的效率和准确性。特别是在股票市场分析中,及时获取全面的股票数据对于识别投资机会、评估风险和制定交易策略至关重要。本文将详细介绍如何使用 Python 的 DrissionPage 库构建一个高效、稳定的同花顺股票数据爬虫,帮助读者掌握这一实用的金融数据获取技能。
数据展示